La verifica delle ipotesi statistiche
Problema pratico:
Quale, tra diverse situazioni possibili, riferite alla popolazione, è
quella meglio sostenuta dalle evidenze empiriche?
Coerenza del
popolazione:
risultato
campionario
con
un’ipotesi
specificata
per
la
se il risultato campionario si verrà a trovare talmente lontano dal valore
teorizzato per da cadere in un insieme di valori ritenuti non “coerenti” (in
quanto troppo poco probabili) con l’ipotesi su , tale risultato avvalorerà la
possibilità di ipotesi alternative a quella specificata.
Test statistico
=
regola di decisione
che ad ogni valore campionario associa una decisione sul parametro
.
La logica della verifica delle ipotesi
Punto di partenza:
Informazione su un parametro
Campione
Ipotesi sul parametro: = 0
• Conferma l’ipotesi
• Non conferma l’ipotesi
Punto di arrivo:
Decisione sul valore del parametro ipotizzato
H0: l’ipotesi sul parametro è vera
La vera distribuzione è centrata su 0
0
H1: l’ipotesi sul parametro è falsa
La vera distribuzione non è centrata su 0
1
TEST
Richiamando gli intervalli di confidenza:
Dati:
un campione X1, …, Xn,
un parametro ed
una statistica Tn, il cui valore calcolato sul campione è tn
La probabilità:
P tn 1
ha un senso solo se il valore di è noto (nel qual caso non ha utilità)
A meno che…
Se è noto:
Prima di estrarre il campione tn non è fisso bensì una v.c. campionaria (Tn),
quindi si può ragionare sulla probabilità che Tn assuma valore compreso
(ossia che tn cada) in un certo intervallo intorno a .
A che scopo?
Per stabilire se la nostra conoscenza su è avvalorata dall’evidenza empirica
(cioè dal campione)
Esempio: tn = media campionaria
x
2
N ,
n
P z
Xn z
1
2
2
n
n
x
z 2
n
L’intervallo è fisso, perché è centrato su
x varia al variare del campione tra tutti i possibili campioni,
è fisso
z 2
n
X
Le ipotesi statistiche
Ipotesi statistica:
affermazione che specifica completamente o parzialmente
la distribuzione di probabilità di una v.c. X.
Ipotesi nulla H0:
Informazione sulla popolazione riconosciuta come valida fino a prima all’esperimento
campionario (valida fino a prova contraria):
H0 : = 0
Ipotesi alternativa H1:
Complemento all’ipotesi nulla. È costituita da un singolo valore o da un insieme di valori
possibili per e considerati alternativi a 0:
H1 : = 1
Ipotesi
semplice
H1 : < 0
H1 : > 0
Ipotesi unidirezionale
Le ipotesi H0 e H1 sono esaustive e disgiunte: o vale l’una o vale l’altra.
In ogni caso la decisione è presa rispetto ad H0
H1 : 0
Ipotesi
bidirezionale
Test e regole di decisione
Il test permette di stabilire se le osservazioni campionarie
debbano ritenersi coerenti con l’ipotesi nulla oppure no
Da un punto di vista operativo, effettuare il test significa definire una
statistica, detta statistica-test Tn, la cui distribuzione campionaria sia
nota, così che:
campione casuale
(X1, …, Xn)
un valore numerico
Spazio campionario: insieme dei valori che la
statistica-test può assumere
Distribuzione campionaria: Distribuzione di probabilità
della statistica-test
coerente con H0
non coerente con H0
Errori di I e II specie
Indipendentemente dalla regola adottata, il test porta sempre a dover
scegliere tra due possibili decisioni, H0 e H1 e a poter commettere due
possibili errori:
• rifiutare un’ipotesi vera
• accettare un’ipotesi falsa
H0
Vera
Falsa
Accetto
Ok
Errore di II specie
Rifiuto
Errore di I specie
Ok
Esempio:
H0: piove
Piove
Non piove
Ombrello
SI
Ok
Danno meno grave
Ombrello
NO
Danno più grave
Ok
N.B.: non esiste la decisione “giusta”!!!
c’è sempre il rischio di sbagliare, ma è possibile gestirlo e controllarlo
QUANTIFICANDOLO
Rischio di errori di I e II specie
H0
Vera
Falsa
Accetto
Ok
Errore di II
specie
Rifiuto
Errore di I
specie
Ok
Vera
Falsa
1-
H0
Accetto
H0 : = 0
H1 : = 1
H0 vera
0
H0 falsa
Rifiuto
1-
1
Definizioni:
= probabilità di errore di I specie = livello di significatività del test
1 - = probabilità di accettare correttamente (affidabilità del test)
= probabilità di errore di II specie
1 - = potenza del test = probabilità di rifiutare correttamente (varia al
variare di 1, quindi può essere determinato solo se H1 è un’ipotesi
“semplice”)
Approccio “conservativo” del test
L’ipotesi nulla è quella che, se vera, lascia invariate le cose
L’errore di I specie è considerato più grave di quello di II specie
Mai lasciare la via vecchia (H0) per la nuova (H1)…
… fino ad EVIDENTE prova contraria
Esempi:
H0: vecchio farmaco migliore del nuovo
H0: Tizio è innocente
H1: nuovo farmaco migliore del vecchio
H1: Tizio è colpevole
H0
Vecchio
Nuovo
Il vecchio
è migliore
Il nuovo è
migliore
Ok
Danno meno
grave
Danno più
grave
ok
H0
Assolvo
Condanno
Innocente
Colpevole
Ok
Danno meno
grave
Danno più
grave
ok
È per questo che:
L’ipotesi nulla e l’ipotesi alternativa non sono equivalenti ai fini della decisione, nel senso
che il test non è mai conclusivo circa H1, ma concerne solo la possibilità che dal campione si
possa pervenire al rifiuto o al non rifiuto di H0.
Come prendere la decisione
Una volta calcolato il valore campionario tn della statistica-test, detto valoretest, si può seguire una delle due seguenti procedure alternative:
Livello di significatività osservato
(approccio di Fisher):
si cerca (sulle tavole) il p-value, ossia la
probabilità di ottenere un valore di Tn
maggiore del valore osservato tn (P[Tn > tn])
p-value
p-value = grado di coerenza di H0
tn
Regione critica (approccio di NeymannPearson):
si fissa “a priori” il livello di significatività del
test 1 - , che identifica sulla distribuzione
della statistica-test due regioni:
?
Tn
tn
1-
Regione di accettazione:
insieme dei valori di Tn coerenti con H0
Regione di rifiuto (o regione critica):
insieme di valori di Tn non coerenti con H0
t
Tn
Accettazione
Rifiuto
Regione critica per un test statistico con
ipotesi alternativa unidirezionale:
?
tn
1-
H0 : = 0
H1 : > 0
0
t
Tn
Accettazione
Rifiuto
Regione critica per un test statistico con
ipotesi alternativa bidirezionale:
tn
H0 : = 0
H1 : 0
1-
/2
/2
-t/2
0
t/2
Tn
Accettazione
Rifiuto
Rifiuto
Verifica di ipotesi sulla media
X ~ N(, 2)
2 nota
La decisione si basa sui valori critici
Con essi va confrontato il valore-test (valore della statistica-test calcolata sul
campione)
I valori critici sono ottenuti dalla distribuzione della statistica-test, fissato il
livello di significatività desiderato per il test
Per la media:
X
P z n
z 1
2
2
n
Valori critici
Statistica-test
Esempio
La frequenza cardiaca dei maschi giovani sani segue una distribuzione Normale con media
= 72 battiti al minuto (bpm) e varianza 2 = 64.
Si misura la frequenza cardiaca su un campione di 25 atleti maschi e si ottiene una media
pari a 68,7 bpm.
Si verifichi, ad un livello di significatività del 5%, che la frequenza cardiaca degli atleti non
sia diversa da quella della popolazione di tutti i maschi sani.
Soluzione
test sulla media, bilaterale
distribuzione normale, varianza nota
Ipotesi
Statistica test
Valori critici
Regola di decisione
=8
x 68,7
= 0,05
/2 = 0,025
n = 25
H0: = 72
H1: ≠ 72
X test
x
n
z 2 1,96
- 1,96 ≤ vtest ≤ 1,96
vtest < -1,96 oppure vtest > 1,96
Valore test (vtest)
vtest
Decisione
2 = 64
68,7 72
8 25
-2,06 < -1,96
2,06
si rifiuta H0
si accetta H0
si rifiuta H0
Esempio
La quantità di merci in transito negli aeroporti italiani si distribuisce normalmente con una
media pari a 18,7 (migliaia di tonnellate) e uno scarto quadratico medio pari a 8.
In un campione di 20 aeroporti viene registrato un valore medio pari a 15.
Utilizzando un livello di significatività dell’1%:
a) Verificare l’ipotesi che il transito medio di merci sia rimasto invariato;
b) Verificare l’ipotesi che il transito medio di merci non sia diminuito
Soluzione
a)
test sulla media, bidirezionale
distribuzione normale, varianza nota
Ipotesi
Statistica test
Valori critici
Regola di decisione
Valore test (vtest)
Decisione
=8
x 15
= 0,01
/2 = 0,005
n = 20
H0: = 18,7
H1: 18,7
X test
x
n
z 2 z0,005 2,58
- 2,58 ≤ vtest ≤ 2,58
vtest < - 2,58 oppure vtest > 2,58
vtest
15 18,7
8
20
si accetta H0
si rifiuta H0
2,07
- 2,58 ≤ -2,07 ≤ 2,58
si accetta H0
b)
test sulla media, unidirezionale
distribuzione normale, varianza nota
Ipotesi
Statistica test
H0: = 18,7
H1: < 18,7
X test
x
n
Valore critico
z z0,01 2,33
Regola di decisione
vtest ≥ - 2,33
vtest < - 2,33
Valore test (vtest)
Decisione
vtest
15 18,7
8
20
- 2,07 ≥ - 2,33
si accetta H0
si rifiuta H0
2,07
si accetta H0
Verifica di ipotesi sulla media
X ~ N(, 2)
2 non nota
X
P t n1 n
t n1 1
s
2
2
n
Valori critici
Statistica-test
Come scegliere la statistica-test per
la media?
X~N
no
n > 30
no
???
si
si
noto
si
X
n
~ N 0,1
no
X
~ tn 1
s
n
Esempio
La frequenza cardiaca dei maschi giovani sani segue una distribuzione Normale con media
= 72 battiti al minuto (bpm).
Si misura la frequenza cardiaca su un campione di 12 atleti maschi e si ottiene una media
pari a 68,7 bpm ed una varianza corretta pari a 75,12.
Si verifichi, ad un livello di significatività del 5%, che la frequenza cardiaca degli atleti non
sia diversa da quella della popolazione di tutti i maschi sani.
Soluzione
test sulla media, bidirezionale
distribuzione normale,
varianza non nota
Ipotesi
H0: = 72
H1: ≠ 72
Statistica test
xtest
Valori critici
Regola di decisione
Valore test (vtest)
Decisione
2
s 75,12
= 0,05
s = 8,67
x 68,7
/2 = 0,025
n = 12
x 0
s
n
t0,025;11 2,201
- 2,201 ≤ vtest ≤ 2,201
vtest ≤ -2,201 oppure vtest ≥ 2,201
vtest
68,7 72
8,67
12
si accetta H0
si rifiuta H0
3,3
1,32
2,5
- 2,201 ≤ -1,32 ≤ 2,201
si accetta H0
Verifica di ipotesi sulla proporzione
P z
2
p
z 1
2
1
n
Valori critici
Statistica-test
Esempio
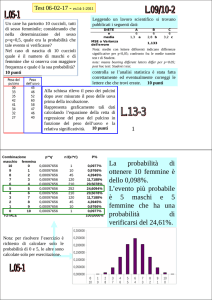
In una scommessa con un amico, lanciando 100 volte una moneta si sono ottenute 54 teste.
Abbiamo il sospetto che l’amico ci abbia ingannati utilizzando una moneta truccata.
Si verifichi questa ipotesi ad un livello di significatività del 10%.
Soluzione
test sulla proporzione, bidirezionale
(unidirezionale)
Ipotesi
H0: = 0,5
H1: ≠ 0,5
p 0
= 0,10
x test
Valori critici
z0,05 1,645
Regola di decisione
- 1,645 ≤ vtest ≤ 1,645
vtest ≤ -1,645 oppure vtest ≥ 1,645
0 1 0
n
z
0,1
1,28
( vv
test
test
0,54 0,50
0,50 1 0,50
si accetta H0
si rifiuta H0
≤ 1,28
> 1,28
0, 80
-1,645 ≤ -0,8 ≤ 1,645
(0,80 < 1,28
)
si accetta H0
si rifiuta H0
100
Decisione
n=100
(H1: > 0,5)
Statistica test
Valore test (vtest)
p =0,54
si accetta H0
si accetta H0)
Verifica di ipotesi sulla differenza tra 2 medie
XeY~N
no
no
nx e ny
> 30
???
si
si
X e
note
Y
no
X =
X Y
no
Y
x
2
s2x sy
nx ny
y
~ t n n 2
x
y
si
X Y
X =
no
Y
si
x
y
1
1
nx ny
y
1
1
s
nx ny
si
X Y
x
~ N 0,1
X Y
x
y
2
2x y
nx ny
~ t n n 2
x
y
~ N 0,1
s
s2X nX 1 s2Y nY 1
nx ny 2
Stimatore corretto dello sqm comune
A cosa serve il test sulla differenza tra 2 medie?
Se su due campioni X ed Y su cui si osserva lo stesso fenomeno si
calcolano le rispettive medie (campionarie) esse presenteranno
quasi certamente due valori numericamente diversi.
Il problema è: tale differenza è “significativa”, cioè dovuta ad una
differenza strutturale tra i due campioni, oppure è dovuta ad una
naturale oscillazione della media, data la variabilità del fenomeno?
Esempio
Gli pneumatici di due diverse marche, X e Y, di uguale prezzo, sono garantiti dalle case
costruttrici per la stessa durata media di 35.000 km e una deviazione standard di 2.000
km, uguale per le due marche.
Da un campione di 14 utilizzatori della marca X risulta una durata media di 33.500 Km,
mentre da uno di 9 utilizzatori della marca Y risulta una durata media di 36.000 Km.
Supponendo che la durata degli pneumatici si distribuisca secondo una legge Normale, si
verifichi se esiste tra le due marche una differenza significativa al 5%.
Soluzione
test sulla differenza tra medie, bidirezionale
distribuzione Normale, varianze note uguali
Ipotesi
H0: x = Y
H1: X ≠ Y
Statistica test
x test
X Y
x
y
y 36.000
nX=14
X = Y = 2.000
1
1
nx ny
Regola di decisione
- 1,96 ≤ vtest ≤ 1,96
vtest ≤ -1,96 oppure vtest ≥ 1,96
Decisione
x 33.500
z0,025 1,96
v test
X, Y ~ N
nY=9
Valori critici
Valore test (vtest)
= 0,05
33500 36000
1
1
2000
14 9
- 2,93 < -1,96
2, 93
si rifiuta H0
si accetta H0
si rifiuta H0
Esempio
Gli pneumatici di due diverse marche, X e Y, di uguale prezzo, sono garantiti dalle case
costruttrici per la stessa durata media di 35.000 km e la stessa varianza incognita.
Da un campione di 14 utilizzatori della marca X risulta una durata media di 33.500 Km ed
una varianza pari a 4.326.400, mentre da uno di 9 utilizzatori della marca Y risulta una
durata media di 36.000 Km ed una varianza pari a 3.880.900.
Supponendo che la durata degli pneumatici si distribuisca secondo una legge Normale, si
verifichi se esiste tra le due marche una differenza significativa al 5%.
Soluzione
test sulla differenza tra medie, bidirezionale
distribuzione Normale,
varianze non note uguali
= 0,05
X~N
x 33.500
y 36.000
nY=9
s2X 4.326.400
nX=14
s2Y 3.880.900
Ipotesi
Statistica test
H0: x = Y
H1: X ≠ Y
x test
X Y
x
y
con: s
1
1
s
nx ny
Valori critici
t0,025;21 2,08
Regola di decisione
- 2,08 ≤ vtest ≤ 2,08
vtest ≤ - 2,08 oppure vtest ≥ 2,08
s
Valore test (vtest)
Decisione
s2X nX 1 s2Y nY 1
nx ny 2
si accetta H0
si rifiuta H0
13 4.326.400 8 3.880.900
2038,8
14 9 2
v test
33.500 36.000
1
1
2038, 8
14 9
- 2,87 < -2,08
2500
1
1
2038, 8
14 9
si rifiuta H0
2, 87
Esempio
Gli pneumatici di due diverse marche, X e Y, di uguale prezzo, sono garantiti dalle case
costruttrici per la stessa durata media di 35.000 km ma con varianze diverse e
incognite.
Da un campione di 14 utilizzatori della marca X risulta una durata media di 33.500 Km ed
una varianza pari a 4.326.400, mentre da uno di 9 utilizzatori della marca Y risulta una
durata media di 36.000 Km ed una varianza pari a 3.880.900.
Supponendo che la durata degli pneumatici si distribuisca secondo una legge Normale, si
verifichi se esiste tra le due marche una differenza significativa al 5%.
Soluzione
test sulla differenza tra medie, bidirezionale
distribuzione Normale,
varianze non note diverse
= 0,05
X~N
x 33.500
y 36.000
nY=9
s2X 4.326.400
nX=14
s2Y 3.880.900
Ipotesi
H0: x = Y
H1: X ≠ Y
Statistica test
xtest
X Y
x
y
2
s2x sy
nx ny
Valori critici
t0,025;21 2,08
Regola di decisione
- 2,08 ≤ vtest ≤ 2,08
vtest ≤ - 2,08 oppure vtest ≥ 2,08
Valore test (vtest)
Decisione
v test
33.500 36.000
4.326.400 3.880.900
14
9
- 2,91 < -2,08
si accetta H0
si rifiuta H0
2, 91
si rifiuta H0
Esempio
Nelle 22 regioni italiane si misura il livello di inquinamento ambientale con il numero di
denunce emesse dalla popolazione residente.
Nelle 10 regioni del Nord risultano in media 29.21 denunce con s.q.m. 6, mentre nelle
12 del Centro-Sud la media è 33.06 con s.q.m. 6.
Ipotizzando che il numero di denunce segua una distribuzione Normale, verificare
l’ipotesi che le due aree geografiche siano caratterizzate dallo stesso livello di
inquinamento al livello di significatività del 5%
xy
3.85
Valore test
1.499
Valore critico
1.725
g.d.l.
a
Decisione:
20
0.05
Si accetta H0
H0: |x - Y|= 0
H1: |X - Y|> 0
IC95%(|mx-my|) = [ -1.4 ; 9.1 ]
Contiene lo 0
La spezzata delle medie
Y
X
AREA
Geografica
Classi di REDDITO
Totale
20-30
Medie
30-40
NORD
2
6
8
32.5
CENTRO
2
4
6
31.7
SUD
6
0
6
25
10
10
20
30
Totale
Decomposizione della varianza
La varianza di X è data dalla somma di due componenti:
• varianza esterna = varianza delle medie di gruppo
• varianza interna = media delle varianze di gruppo
Quanto differiscono
le medie tra loro e
rispetto alla media
generale?
Se:
G = numero di gruppi;
j = media dell’j-esimo gruppo;
nj = numerosità dell’j-esimo gruppo (j = 1,….,G);
allora:
2
1 G 2
1 G
j nj
j
n j 1
n j 1
VARIANZA
INTERNA
ossia:
2
2TOT 2INT EX
T
VARIANZA
ESTERNA
2
nj
A cosa serve scomporre la varianza?
n. bot
Media e varianza costanti
• Varianza delle medie 2ext = 0
• Media delle varianze 2int = 2
Stesso comportamento tra le
due distribuzioni:
CH
MM
scelta
il numero di bottiglie acquistate è
lo stesso per chi sceglie le due
marche
Medie diverse, varianza costante
n. bot
• Varianza delle medie 2ext ≠ 0
• Media delle varianze 2int < 2
Diverso comportamento tra le
due distribuzioni:
CH
MM
scelta
il numero di bottiglie acquistate è
diverso a seconda della marca
scelta
Rapporto di correlazione di Pearson
X
x0 – x1
x1 – x2
…
Classe jma
…
xh-1 - xh
tot
y1
n11
n12
…
…
…
n1h
n1.
y2
.
.
.
yi
.
.
.
n21
n22
…
…
n2h
.
.
.
.
.
.
.
.
.
…
.
.
.
nij
.
.
.
.
.
.
.
.
.
n2.
.
.
.
ni.
.
.
.
yk
nk1
nk2
…
…
…
nkh
nk.
tot
n.1
n.2
…
n.j
…
n.h
n
Y
Quando X è quantitativo:
r
X|Y
2
EXT
X
2X
i
i 1
j 1
2
j
X n j
2
c
x ni
2
c
x̂
Quando Y è quantitativo:
Y|X
2
EXT
Y
2Y
j 1
j
r
y
i 1
i
Y n j
2
Y ni
N.B.:
Su una tabella mista è possibile misurare anche l’indipendenza assoluta con
l’indice del 2
Proprietà e interpretazione
0 X|Y 1
X|Y 0
Perfetta indipendenza in media:
le medie delle distribuzioni condizionate di X sono tutte
uguali tra loro ed uguali alla media generale (μX)
X|Y 1
Perfetta dipendenza in media:
le varianze delle distribuzioni condizionate di X sono nulle. Ad
ogni modalità di Y corrisponde una sola intensità di X che
presenta frequenza non nulla
Y|X X|Y
L’indice non è simmetrico (salvo eccezioni)
Esempio
Fatturato (Y)
Settore
Merceologico (X)
≤ 200
Alimentari
200-|300
300-|400
400-|500
>500
Totale
11
1
5
1
3
21
Bevande
1
1
0
1
0
3
Healt Care
6
1
1
2
2
12
Ice Packaging
7
2
1
1
3
14
25
5
7
5
8
50
Totale
X 4 modalità
r
Y 5 classi (2 aperte)
Y|X
2
EXT
Y
2Y
i
i 1
j 1
Y ni
2
c
ŷ
2
j
Y n j
1. Media generale di Y:
1
Y
n
h
ŷ n
j 1
j j
150 25 250 5 350 7 450 5 1256 8
50
394,96
Nota:
Il valore centrale della prima classe (aperta) è stato ottenuto considerando che, nella successione di
valori del carattere fatturato, i valori più bassi sono di poco superiori a 100 (che si assume, quindi,
come estremo inferiore della classe); quello dell’ultima classe è ottenuto considerando come estremo
superiore della classe il valore massimo effettivamente osservato:
(2012 + 500)/2 = 1256
2. Medie di Y condizionate alle modalità di X
1
1
n1
c
ŷ jn1j
1
4
n4
21
j 1
1
2
n2
1
3
n3
150 11 250 1 350 5 450 1 1256 3
c
ˆy jn2j
j 1
c
ŷ jn3j
ŷ jn4j
j 1
3
266,67
150 6 250 1 350 1 450 2 1256 2
j 1
c
150 1 250 1 450 1
12
384,33
150 7 250 2 350 1 450 1 1256 3
14
348, 48
412
3. Confronto tra le medie condizionate
1 348, 48
2 266,67
3 384,33
4 412
Commento: si può vedere che le medie delle distribuzioni condizionate differiscono
dalla media generale di Y, quindi i due caratteri non sono indipendenti in media.
Ma quanto è forte il legame di dipendenza in media?
4. Calcolo del numeratore dell’indice
r
i 1
i
2
Y ni 348, 48 394,96 21 266,67 394,96 3
2
2
384,33 394,96 12 412 394, 96 14 99.464,14
2
2
5. Calcolo del denominatore dell’indice
c
j 1
2
ŷ j Y n j 150 394,96 25 250 394,96 5
2
2
350 394,96 7 450 394,96 5 1.256 394,96 8 7.565.618
2
2
2
6. Calcolo dell’indice
r
Y|X
2
EXT
Y
2Y
i 1
i
j 1
Y ni
2
c
ŷ
2
j
Y n j
99.464,14
0, 013
7.565.618
La dipendenza in media del carattere FATTURATO dal carattere SETTORE MERCEOLOGICO
è praticamente nulla
ossia:
il fatturato in media non dipende dal settore merceologico
Il test F
Ipotesi:
H0: mi = mj
i,j = 1, …, G
le medie sono uguali in tutti i gruppi
H1: mi mj
H0
H1
almeno una media differisce
dalle altre
Se le medie sono uguali, la varianza tra i gruppi è nulla:
Più le medie differiscono, più:
DevEXT Dev TOT
DevEXT 0
DevINT Dev TOT
DevINT 0
Statistica test:
DevEXT / G 1
P
FG 1;n G; 1
DevINT / n G
Statistica-test
Valore critico
Più basso è il rapporto, più realistica è l'ipotesi nulla
Più elevato è il rapporto, meno realistica è l'ipotesi nulla
Il test F
Ipotesi:
H0: mi = mj
i,j = 1, …, G
H1: mi mj
H0:
H1:
DevEXT / G 1
DevINT / n G
DevEXT / G 1
DevINT / n G
le medie sono uguali in tutti i gruppi
almeno una media differisce
dalle altre
0
H0: = 0
H1: > 0
0
Fatturato e settore merceologico
H0: mi = mj
i,j = 1, …, G
le vendite medie sono uguali in tutti i settori
H1: mi mj
almeno una media differisce dalle altre
ANOVA
Source
Fra gruppi
DF
Sum of squares
Mean squares
3
99464.14
33154.71
Entro gruppi
46
162307.7
Totale
49
7466153.86
7565618.00
F
0.204271
F
Decisione:
Il p-value è molto alto:
0,89
0,204
2
EXT
2INT
Basso valore di F = bassa 2EXT = medie vicine
Si accetta l’ipotesi di vendite medie
uguali tra i settori, confermata dal
campione osservato.
Pr > F
0.892917
Y
X
AREA
Geografica
Classi di REDDITO
Totale
20-30
Medie
30-40
NORD
2
6
8
32.5
CENTRO
2
4
6
31.7
SUD
6
0
6
25
10
10
20
30
Totale
Source
Fra gruppi
Il p-value è basso:
Si rifiuta l’ipotesi
reddito medio uguale
nelle tre le aree
geografiche.
ANOVA
Sum of
squares
DF
Mean
squares
2
217.34
108.67
Entro gruppi
17
282.66
16.63
Totale
19
500
F
6.5357
Pr > F
0.0078
Verifica dell’ipotesi di indipendenza
H0: X ed Y sono indipendenti
H1: X ed Y non sono indipendenti
Ipotesi di indipendenza in media
ANOVA: test F H0: = 0
H1: > 0
Ipotesi di indipendenza assoluta
Test del 2 H0: 2 = 0
H1: 2 > 0
Ipotesi di indipendenza lineare
Test su
H0: = 0
H1: > 0
Test su
R2
H0: R2 = 0
H1: R2 > 0
Verifica di ipotesi sull’indipendenza assoluta tra due caratteri
nij nij
2
i
j
nij nij
P
i j
nij
2
r 1 c 1
nij
2
Statistica-test
2
;r 1 c 1
1
Valore critico
0.5
La variabile 2 è continua, non può
essere negativa e varia tra zero e
0.4
infinito. La sua forma e il suo centro
dipendono dal numero di gradi di libertà.
La sua forma funzionale è:
f(x;g)
1
x
exp
2 x
g
g
22
2
0.3
0.2
g
1
2
g=2
g=4
0.1
g=8
0.0
5
10
15
20
Verifica di ipotesi sull’indipendenza tra due caratteri
Conteggio
VOTO
VOTO Meno di 96
96-105
106-110
110 e lode
Totale
OCCUPAZIONEATTUALE
ATTUALE
OCCUPAZIONE
Non occupato
Precario
Occ. stabile
22
19
29
61
57
51
25
23
25
22
20
28
130
119
133
Totale
70
169
73
70
382
2
i
n
ij
nij
2
3,84
nij
j
= 0,05
H0: X ed Y indipendenti
H1: X ed Y non indipendenti
Ipotesi
Distribuzione del chi-quadro
2
0,05;6
12,59
1-
3,84
Zona di
accettazione
12,59
i
Zona di rifiuto
j
n
ij
nij
nij
2
H0: 2 = 0
H1: 2 > 0
n
Statistica
test
x test
Valore
critico
20,05; 6
Regola di
decisione
vtest 12,59
vtest > 12,59
i
ij
nij
2
nij
j
12,59
n
Valore test
(vtest)
vtest
Decisione
3,84 < 12,59
i
si accetta H0
si rifiuta H0
j
ij
nij
2
nij
3, 84
si accetta H0
Verifica dell’ipotesi di indipendenza lineare
Modello di regressione lineare semplice
Fasi del modello:
Specificazione del modello:
scelta del tipo di funzione da utilizzare per descrivere un fenomeno;
definizione delle ipotesi di base
Stima dei parametri:
uso di stimatori dei parametri caratteristici della funzione scelta
Verifica:
della significatività delle stime
del rispetto delle ipotesi di base (rimozione delle ipotesi,
analisi dei residui)
Uso del modello:
ai fini per i quali è stato specificato (descrittivi, previsivi, ecc.)
45
IPOTESI DI BASE DEL MODELLO DI REGRESSIONE
Ipotesi deboli:
1.
2.
3.
4.
5.
Necessarie perché le stime godano di proprietà ottimali, ossia siano
non distorte e a varianza minima (BLUE, Teorema di Gauss-Markow)
yi = + xi + i
E(i) = 0
var(i) = var(yi) = 2
cov(i, j) = 0 (i j)
X nota e senza errore
Ipotesi forte:
Varianza costante, omoschedasticità
Assenza di autocorrelazione
X non stocastica
Necessaria per verificare la significatività delle stime
6. N(0, 2)
La varianza di (o di y) 2 rientra tra i parametri da stimare
Se ci fosse correlazione tra gli errori significherebbe che esistono altri fattori oltre a X ad
influenzare Y, esclusi dal modello. Inoltre implicherebbe un legame anche tra le yi
L’ipotesi distribuzionale (6) è fondamentale nella fase inferenziale
46
RAPPRESENTAZIONE GRAFICA DEL MODELLO
Y
f()
E(Y|X) = a + bx
x1
x2
x3
x4
X
Distribuzioni degli errori (intorno alla stima di Y):
media 0,
varianza costante,
indipendenti,
distribuiti Normalmente
yi i.i.d. con media e varianza costanti
47
VERIFICA DEL MODELLO
Significatività dell’R2
H0: R2 0
H1: R2 > 0
xtest
a
dev reg
dev e n 2
R 2 n 2
1 R2
F1;n 2
Fa,1,n-2
Significatività di a e di b
H0 : 0
H1 : b 0
xtest
b
sb
tn2
a/2
H0 : 0
H1 : a 0
xtest
a
sa
tn 2
a/2
-ta/2,n-2
ta/2,n-2
48
Varianze della regressione
1 n 2
s
ei
n 2 i 1
2
Varianza dei residui:
cod X, Y
2
R2
dev X dev Y
1
Varianza di b:
standard della
regressione
dev e
dev y
Devianza dei residui:
Varianza di a:
s errore
dev e 1
2
s
1
s2a
n
sb2 s2
cod X, Y
dev X
x2
n
2
x
x
i
i 1
1
n
x
i 1
2
i
x
2
sa errore
standard
della stima
di
sb errore
standard
della stima
di
49
Da un campione di 7 aziende risultano i seguenti valori del numero totale di dipendenti (X) e del numero di dipendenti laureati (Y):
Dip. totali (X)
5
8
10
11
7
9
6
Dip. Laureati (Y)
3
5
7
6
4
3
2
a)Disegnare la retta di regressione di Y su X;
b)misurare la bontà dell’adattamento;
c)sapendo che
s2
1 n 2
ei 3,89
n 2 i 1
verificare la significatività del modello al livello dell’1%
xi
yi
5
x x y y x x
2
y y
2
i
x x y y
i
i
3
-3
-1,29
9
1,65
3,86
8
5
0
0,71
0
0,51
0
10
7
2
2,71
4
7,37
5,43
11
6
3
1,71
9
2,94
5,14
7
4
-1
-0,29
1
0,08
0,29
9
3
1
-1,29
1
1,65
-1,29
6
2
-2
-2,29
4
5,22
4,57
56
30
0
0
28
19,43
18
i
i
i
b
cov x, y
2
x
cod x, y
dev x
18
0, 64
28
a y bx 4,29 0,64 8 -0, 86
Equazione della retta:
x
y
y 0,86 0,64x
0
-0,86
8
4,29
cov x, y cod x, y 2
devREG
devRES
R
1
dev y
dev y
dev x dev y
2x 2y
2
2
R2
182
0, 6
28 19, 43
2
Test su R2, unilaterale
Ipotesi
Statistica test
Valore critico
H0: R2 = 0
H1: R2 > 0
X test
R 2 n 2
devREG
devRES n 2
1 R2
F0,01;1;5 = 16,258
Regola di decisione vtest ≤ 16,258
vtest ≥ 16,258
Valore test
Decisione
F1;n 2
vtest
si accetta H0
si rifiuta H0
0,6 5
7,36
1 0,6
7,36 ≤ 16,258
si accetta H0
La relazione lineare tra y ed x non è significativa
Si rifiuta il modello lineare
F0,05;1;5 = 6,608
ANOVA
Source
DF
Sum of
squares
Mean
squares
Model
1
11.571
11.571
Error
5
7.857
1.571
Corrected Total
6
19.429
F
Pr > F
7.364
0.042
Significatività dei coefficienti
Source
Intercept
x
Value
Standar
d error
t
Pr > |t|
Lower
bound
(95%)
Upper
bound
(95%)
-0.857
1.954
-0.439
0.679
-5.879
4.165
0.643
0.237
2.714
0.042
0.034
1.252
Test su b, bilaterale
Ipotesi
Statistica test
H0 : b = 0
H1 : b ≠ 0
Xtest
b
s
tn2
in cui:
s s2
1
n
i 1
xi x
2
Valori critici
t0,005;5 = 4,032
Regola di
decisione
- 4,032 ≤ vtest ≤ 4,032
si accetta H0
vtest ≤ - 4,032 oppure vtest ≥ 4,032 si rifiuta H0
Valore test
vtest
Decisione
0,64
1,72
0,37
- 4,032 ≤ 1,72 ≤ 4,032
s 1,57
1
0,37
28
si accetta H0
La relazione lineare tra y ed x non è significativa
Si rifiuta il modello lineare
Test su a, bilaterale
Ipotesi
Statistica test
Valori critici
H0 : a = 0
H1 : a ≠ 0
Xtest
a
s
tn2
s
s
1
n
x
2
xi x
2
2
n
i 1
t0,005;5 = 4,032
si accetta H0
Regola di decisione - 4,032 ≤ vtest ≤ 4,032
vtest ≤ - 4,032 oppure vtest ≥ 4,032 si rifiuta H0
Valore test
Decisione
s
3,89
82
1
1,35
7
28
- 4,032 ≤ -0,63 ≤ 4,032
vtest
0, 86
0, 63
1,35
si accetta H0
Verifica di ipotesi sul confronto tra due varianze