D e f i n i z i o n e
d i
S t a t i s t i c a
C o mp l e s s o d i c r i t e r i e me t o d i q u a n t i t a t i v i p e r
l ’ o s s e r v a z i o n e e l ’ a n a l i s i d e i f e n o me n i
F e n o me n i c o l l e t t i v i
Defi n izio ne d i po po lazi one st at ist ica
o
c o ll e t t iv o st a t i st ic o
I n s i e me d i p i ù u n i t à o mo g e n e e r i s p e t t o a d u n o o p i ù
aspetti.
Esempio di popolazione st atistica: l’insieme delle imprese
indust riali esist enti ad una certa data in Italia.
1
Collettivo statistico
F e n o me n o c o l l e t t i v o
L’i ns ie me c he s i s tudia
L’aspetto che interessa
studiare del collettivo
Le unità c he c os tituisc ono un c olle ttivo s ono de nominate
unità statistiche
Le unità statistiche sono classificate, in base ad un criterio
qualitativo o ai valori di un carattere quantitativo, in
categorie genericamente denominate modalità:
Modalità
qualitative
quantitative
Es. modalit à qualitative
Le imprese indust riali sono classificat e secondo il carattere stat o
giu ri dico in:i mp rese indiv idua li, soci età in no me co ll….
Il carattere “Stato giuridico” assume modalità qualitative
Es. modalit à quantit ative
Le imprese indust riali sono classificat e secondo il carattere numero
di addetti in imprese con: <2,2-10,…. addetti
Il carattere “ numero di addetti” assume modalità quantitative
2
Frequenza assoluta
numero delle unità di una popolazione statistica che
rie ntrano ne lla s tessa cate gor ia
Frequenze relative
rapporto delle frequenze assolute
al loro totale
l’insieme delle coppie
modalità – frequenza
è denominato:
serie statistica
o
mutabile statistica
seriazione statistica
o
variabile statistica
se le modalità sono
qualitative
quantitative
3
Mutabile statistica
Tav.1
Dist ribuzione degli occupati per settore di attività economica
Italia 1978
Settore di attività economica Occupati (migliaia) Occupati %
Agricoltura
3.090
15,33
Industria
7.633
37,86
Alt re attività
9.436
46,81
Totale
20.159
100,00
Fonte: ISTAT- Bollettino mensile di statistica,1979
Rappresentazioni grafiche di una m utabile statistica
Fig.1
fig.2
Distribuzione degli occupati per settore di
attività
distribuzione degli occupati per settore di
attività
10.000
9.000
8.000
Agricoltura
7.000
Agricoltura
Altre attività
Industria
Industria
Altre attività
6.000
5.000
4.000
3.000
2.000
1.000
0
Agricoltura
Industria
Altre attività
4
Va r i a b i l e s t a t i s t i c a d i s c r e t a
Tav.2
Dist ribuzione delle famiglie it aliane secondo il numero di
componenti-censimento 1971
Famiglie
Componenti
(migliaia)
Frequenze %
1
2.062
12,90
2
3.509
21,96
3
3.582
22,41
4
3.390
21,21
5
1.893
11,85
6
843
5,28
7
366
2,29
8
169
1,06
>8
167
1,04
Totale
15.981
100
Fonte:ISTAT,Censimento della popolazi one 1971
Rappresentazione grafica di una variabile discreta
Fig.3
distribuzione delle famiglie secondo il numero dei
componenti
famiglie
4.000
3.000
2.000
1.000
0
0
2
4
6
8
10
componenti
5
Va r i a b i l e s t a t i s t i c a c o n t i n u a
Tav.3a
Distribuzione delle aziende agricole italiane secondo classi di
superficie totale,1975.
Superficie
Classi di superficie
A zi ende
complessiva
(migliaia)
(mi g liai a di ett a ri)
Senza terreno
12
Fino ad 1
469
309
1-2
598
913
2-3
365
931
3-5
428
1.703
5-10
418
2.989
10-20
217
3.047
20-30
64
1.577
30-50
45
1.742
50-100
29
2.015
Olt re 100
19
7.175
Totale
2.664
22.401
Fonte:Annuario stati stico italiano,1978.
Tav.3b
modalit à della variabile X
x i ⏐⎯ x i + 1
x1 ⏐ ⎯ x2
x2 ⏐ ⎯ x3
…
xi ⏐ ⎯ xi + 1
...
xs ⏐ ⎯ xs + 1
Tota le
Frequenze assolute
n1
n2
…
ni
…
ns
N
6
Tav.3c
Distribuzione di un campione di operai per classi di reddito, Italia,
1996
Classi di reddito(migliaia di euro)
Operai
0-1
9.000
1-2
8.500
2-3
7.000
3-5
10.000
5-10
10.000
10-15
7.500
15-25
10.000
Totale
62.000
Rappresentazione grafica di una variabile continua
Fig.4
Distribuzione dei redditieri per classi di reddito
y
10.000
9.000
8.000
7.000
6.000
5.000
4.000
3.000
2.000
1.000
1
2
3
4
5
6
7
8
9 10 11 12
13
14
15
16
17
18
19
20 21
22 23
24
25
x
reddito (migliaia di euro)
7
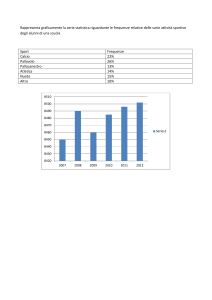
Serie storica
Anni
1951
1961
1971
1981
Tav.5
Popolazione residente in Italia alla data dei censimenti
Popolazione
Numeri
Numeri
Rapporti
Saggio
(migliaia)
indici
indici incrementali d’incremento
Base
Base
(migliaia)
relativo
1951=100 mobile
annuo
47.516
100
50.624
106,54
106,54
310,8
0,006334
54.137
113,93
106,94
351,3
0,006707
56.557
119,03
104,47
242,0
0,004372
Fonte: ISTAT, Censimenti della popolazione
Rappresentazione grafica di una serie storica
Fig.5
Distribuzione della popolazione italiana per anni di
calendario (migliaia)
popolazione
60.000
55.000
50.000
45.000
40.000
1951
1961
1971
1981
8
Serie territoriale
Tav.6
Distribuzione del numero dei nati vivi per provincia
Sicilia, 1998
Province
Nati vivi
Trapani
4.679
Palermo
13.986
Messina
6.083
Agrigento
5.322
Caltanissetta
3.376
Enna
1.961
Catania
12.543
Ragusa
3.233
Siracusa
4.130
Totale Sicilia
55.313
Fonte: ISTAT Annuario di st atistiche de mografiche,1999
Rappresentazione grafica di una serie territoriale
Fig.6
ra
cu
sa
Si
a
ag
us
a
R
Ca
ta
ni
En
na
16.000
14.000
12.000
10.000
8.000
6.000
4.000
2.000
0
Tr
ap
an
i
Pa
le
rm
o
M
es
si
na
Ag
rig
en
Ca
to
lta
ni
ss
et
ta
nati vivi
Distribuzione dei nati vivi per province siciliane
9
S c a l e d i mi s u r a
F a s i n e l l a f o r ma z i o n e d e l c o n c e t t o d i m i s u r a z i o n e :
1. classificazione
s c a l a n o mi n a l e
co ns ist e ne l fissa re p er gli e le me nt i d i un dat o
p iù criteri, ta li c he c ias c un e le me nto ne so dd is fi
ne l riu nire ne lla s tessa c lasse gli e le me nti c he
stesso criterio. Le de no minaz io ni de lle c lass i
co me i gra d i d i una sca la il cui o rd ine d i
arbitrario
Ese mp io : c lass ifica z io ne de i so gget t i sec o nd o
attività economica.
2 . o r d i n a me n t o n o n m e t r i c o
ins ie me d ue o
uno soltanto e
s od d is fa no lo
s’interpretano
successione è
il settore di
scala ordinale
cons iste ne llo s pec ifica re de i c rite ri c he c o nse nta no d i d isp o rre
gli e le me nt i d i un ins ie me in u n o rd ine q uas i se ria le c io è ta le
c he, in ra ppo rto a d una d ata cara tteristica, p iù e le me nti
possano occupare un dato posto nella serie.
Crite ri: re laz ione di coinc ide nz a(A= B)
re laz io ne d i p rece de nza (A< B)
L’ordine in cui si succedono i gradi di questa scala è definito
Ese mp io : c lass ifica z io ne de lle imp rese sec o nd o lo s ta to
giuridico
3 . o r d i n a me n t o m e t r i c o
s c a l a me t r i c a
co ns iste, q ua ndo p oss ib ile, ne ll’asse gna re ad o gn i e le me nto x
de ll’ ins ie me da to un so lo nu mero rea le m(x), ta le c he se tra
d ue e le me nti x ed y va le la re laz io ne d i c o inc ide nza a llo ra
m( x)= m(y)e se va le la re laz io ne d i p rece de nza a llo ra
m( x)< m(y)
s c a l a me t r i c a
scala di intervalli
unità di misura arbitraria
origine arbitraria
scala di rapporti
unità di misura arbitraria
origine non arbitraria
10
Tav.7
Dist ribuzione delle famiglie it aliane secondo il numero di
componenti-censimento 1971
Famiglie
Famiglie con
% di
Componenti
(migliaia)
Componenti
un numero
famiglie con
di
un numero
x
componenti
di
≤ ( fi no a) x
componenti
≤ ( fi no a) x
1
2
3
4
5
6
7
8
>8
Totale
2.062
3.509
3.582
3.390
1.893
843
366
169
167
≤
≤
≤
≤
≤
≤
≤
≤
(f i n o a ) 1
(f i n o a ) 2
(f i n o a ) 3
(f i n o a ) 4
(f i n o a ) 5
(f i n o a ) 6
(f i n o a ) 7
(f i n o a ) 8
≤ (f i n o a )
numer o
massi mo
2.062
5.571
9.153
12.543
14.436
15.279
15.645
15.814
15.981
12,90
34,86
57,27
78,49
90,43
95,61
97,90
98,96
100
15.981
Fonte:ISTAT,Censimento della popolazi one 1971
Tav.8
Dist ribuzione delle famiglie it aliane secondo il numero di
componenti-censimento 1971
Famiglie
Famiglie con
% di
famiglie con
Componenti
(migliaia)
Componenti
un numero
un numero
di
x
componenti
di
≥( fi no a) x
componenti
≥ ( fi no a) x
1
2
3
4
5
6
7
≥8
Totale
2.062
3.509
3.582
3.390
1.893
843
366
336
≥
≥
≥
≥
≥
≥
≥
≥
(a l m e n o )
(a l m e n o )
(a l m e n o )
(a l m e n o )
(a l m e n o )
(a l m e n o )
(a l m e n o )
(a l m e n o )
1
2
3
4
5
6
7
8
15.981
13.919
10.410
6.828
3.438
1.545
702
336
100
87,10
65.14
42,73
21,51
9,67
4,39
3,14
15.981
Fonte:ISTAT,Censimento della popolazi one 1971
11
y
y
100
100
90
90
80
80
70
70
60
60
50
50
40
40
30
30
20
20
10
10
1
2
3
4
5
6
7 8
9 10
x
2
3
4
5
6 7
8 9 10
12
Tav.9
Distribuzione cumulativa delle aziende per classi di superficie agraria
Classi di superficie
Aziende (migliaia)
Fino ad 1
1-2
2-3
3-5
5-10
10-15
20-30
30-50
50-100
Oltre 100
481
598
365
428
418
217
64
45
29
19
Totale
2.664
Valori cumulati
481
%
18,1
1079
40,5
1444
54,2
1872
70,3
2290
86,0
2507
94,1
2571
96,5
2616
98,2
2645
99,3
2664
100,0
Distribuzione cumulativa delle aziende secondo
classi di superfici agrarie
120
100
80
60
Serie1
40
20
0
0
>100
13
Rapporti di composizione
Rapporti fra term ini omogenei
Numeri indici
Rapporti incrementali
Rapporti di densità
Rapporti fra term ini eterogenei
Rapporti di derivazione
Rapporti di durata
14
Rapporti di composizione
Sono rapporti di una parte al tutto.
Es. i rapporti della 3°colonna della tav.2
famiglie con x componenti / famiglie totali
sono rapporti di composizione
Numeri indici semplici
Pongono a confronto le intensità o le frequenze di uno stesso
fenomeno in tempi o in luoghi diversi
Sono istituiti fra termini di una stessa serie storica o
territoriale. Il termine con il quale vengono confrontati tutti
gli altri si chiama base.
La base può essere fissa o variabile
Es.
gli indici della 3°colonna della tav.5
sono indici a base fissa
gli indici della 4°colonna della tav.5
sono indici a base mobile
Rapporti incrementali
Si ottengono dividendo la differenza fra le intensità del
fenomeno alla fine e all’inizio di un dato intervallo per la
lunghezza dello stesso intervallo
Es.
gli indici della 5° colonna della tav.5
Dal rapporto incrementale si ricava
il saggio d’incremento relativo
dividendo il rapporto incrementale per l’intensità media del
fenomeno
Es.
gli indici della 6° colonna della tav.5
15
Rapporti di derivazione
Sono istituiti fra due fenomeni fra i quali vi è un legame di
causalità
Si ottengono eseguendo il rapporto fra l’intensità o la
frequenza di un fenomeno con l’intensità o rispettivamente la
frequenza di un altro fenomeno che ne è il presupposto
necessario.
Es.il fenomeno nascite ha come presupposto l’esistenza di una
popolazione quindi il rapporto
Nascite / popolazione(media)
è
un rapporto di derivazione
Rapporti di densità
Si istituiscono quando si vuole eliminare da un fenomeno
l’influenza di un altro.
Es. il rapporto:
Popolazione / superficie in km q.
dà la densità media di abitanti per Kmq cioè la popolazione
per un kmq di superficie.
Rapporti di durata
Sono ottenuti rapportando la consistenza media del fenomeno
in un dato intervallo temporale per un valore intermedio fra
quelli dei movimenti in entrata ed in uscita.
Es.
Consistenza annuale media dei depositi bancari =
10.000 miliardi.
Prelievi annuali =3.000 miliardi
versamenti annuali =5.000 miliardi
Consistenza media/( prelievi+versamenti)/2=
10.000/4000=2,5anni
il rapporto
[(Prelievi+ versamenti)]/2/consistenza =
= 4.000/10.000=0,4
è
un Rapporto di ripetizione
16
VALORI MEDI
Definizione di m edia del Cauchy:
E’ una quantità compresa fra la più grande e la più piccola
fra le quantità date
Definizione del Chisini
Date n grandezze, x i , per i=1,2,… e, considerata una loro funzione
matematica f=f(x 1 , x 2 ,…,x n ), si chiama media, rispetto alla funzione f
quel numero X che, sostituito a ciascuna delle grandezze date, lascia
invariato il valore della funzione f:
f(x 1 , x 2 ,…,x n )= f(X , X,…,X)
17
Media aritmetica
Dati i valori osservati distinti: x 1 ,x 2 ,…,x i ,…, x n
se la funzione f è la somma delle grandezze, la condizione di
invarianza del Chisini si riscrive:
x1 + x2 + ... + xi + ... + xn = X + X + ... + X + ... + X = nX
x1 + x2 + ... + xi + ... + xn 1 n
X =
= ∑ xi = x
n
n i =1
( media aritmetica semplice)
Data la distribuzione di frequenza:
Vari abile x Frequen za y
x1
y1
x2
y2
…
…
xi
yi
…
…
xn
yn
Totale
N
La media aritmetica è
x y + x2 y 2 + ... + xi yi + ... + xn y n 1
=
x= 1 1
y1 + y 2 + ... + yi + ... + y n
N
n
∑x y
i =1
i
i
( media aritmetica ponderata)
con
N = y 1 + y 2 + ... + y i + ... + y n
18
Proprietà media aritmetica
1° proprietà media aritmetica :
n
∑ (x
i =1
i
− x ) yi = 0
2° proprietà media aritmetica:
∑
n
( xi − x) 2 yi = minimo
i =1
Dalla prima proprietà deriva che :
∑
n
x =
( xi − m) yi
i =1
N
+m
dove m è un’origine arbitraria
N. B. Se la variabile è continua, la media è calcolata
utilizzando il valore centrale delle classi.
19
Media geometrica
se la funzione f è il prodotto delle grandezze distinte
x 1 ,x 2 ,…,x i ,…, x n , la condizione di invarianza del Chisini si
riscrive:
x1 * x2 * ... * xi * ... * xn = X * X * ... * X * ... * X = X n
X = ( x1 * x 2 * ... * xi * ... * xn )
1/ n
=n
n
∏x
i =1
i
(media geometrica semplice)
Su una distribuzione di frequenza la media geometrica si calcola:
X = ( x1 * x2 * ... * xi * ... * xn )
y1
y2
yi
yn 1/ N
n
= N ∏ xi
yi
i =1
(media geometrica ponderata)
con
N = y 1 + y 2 + ... + y i + ... + y n
20
Proprietà media geometrica
1° proprietà media geometrica :
1
log X =
N
n
∑y
1=1
i
log xi
il logaritmo della media geo metrica è eguale alla media aritmetica dei
logarit mi dei valori dati.
2° proprietà media geometrica :
xi =
posto:
ui
;
vi
i=1,2,…,n
1
u1 * u2 * ... * un n n u1 * u2 * ... * un
) =n
X =( 1
v * v2 * ... * vn
v1 * v2 * ... * vn
la media geometrica di più rapporti è uguale al rapporto fra la media
geometrica dei numeratori e la media geo metrica dei denominatori
Se: u1 = u 2 = ... = u n = 1
X =
n
1
la media geometrica dei reciproci di n valori è
v1 * v2 * ... * vn
eguale al reciproco della media geometrica dei valori dati
21
Media armonica
se la funzione f è la somma dei reciproci delle grandezze
distinte x 1 ,x 2 ,…,x i ,…, x n , la condizione di invarianza del Chisini
si riscrive:
1 1
1
1
1 1
1
1
1
+ + ... + + ... +
= + + ... + + ... + = n
x1 x 2
xi
xn X X
X
X
X
X =
n
1
1
1
+
+ ... +
x1 x2
xn
=
n
n
1
∑x
1=1
i
( media armonica semplice )
X =
N
1
1
1
y1 +
y2 + ... +
yn
x1
x2
xn
=
N
1
yi
∑
1=1 xi
n
(media armonica ponderata)
proprietà media armonica:
x −X
) yi = 0
∑( i
x
i
n
i =1
la somma algebrica degli scarti relativi dei valori osservati dalla loro
media armonica, moltiplicati per i rispettivi pesi, è nulla
22
Media potenziata
se la funzione f è la somma delle potenze r-esime delle
grandezze distinte x 1 ,x 2 ,…,x i ,…, x n , la condizione di invarianza
del Chisini si riscrive:
x1 + x2 + ... + xi + ... + xn = X r + X r + ... + X r + ... + X r = nX r
r
r
r
r
1 n r 1r
X =( ∑x )
n i =1
(media potenziata di ordine r semplice)
1
X =(
N
n
∑x y )
r
i =1
1
r
i
(media potenziata di ordine r ponderata)
N:B per r=1 la media potenziata rappresenta una media aritmetica
r =2
“
“
“
una media quadratica
r = -1
“
“
“
una media armonica
r→ 0
“
“
tende ad una media geometrica
23
Medie di posizione
Sono delle costanti che non dipendono strettamente dalle grandezze
date
mediana
moda
quartili
Definizione di mediana: data una successione di valori disposti in
ordine non decrescente di grandezza, è quel valore preceduto e
seguito da uno stesso numero di valori.
Se il numero delle grandezze è dispari, la mediana è quel valore che
occupa il posto centrale della successione ;
se è pari, essendo due i valori centrali, la mediana è qualunque
valore compreso fra di essi ( in genere si considera la semisomma dei
due valori centrali).
Proprietà della mediana:
n
∑| x
i =1
i
− m |= min imo
m= mediana
La somma dei valori assoluti degli scarti dalla mediana è un minimo
24
Quartili
Data una successione di valori non decrescenti si definisce primo quartile quel valore
al di sotto del quale stanno un quarto dei valori osservati e al disopra del quale stanno
i tre quarti dei valori osservati.
si definisce terzo quartile quel valore medio al di sotto del quale stanno i tre quarti dei
valori osservati e al disopra del quale stanno un quarto dei valori osservati.
Il secondo quartile coincide con la mediana
Quantili
Data una successione di valori non decrescenti si definisce k-esimo quantile
(k=1,2,…, q-1) quel valore medio al di sotto del quale sta una frazione k/q dei casi
osservati e al di sopra del quale sta una frazione pari a (1- k/q) dei casi osservati.
Es. se q=10 il quantile prende il nome di decile e se k = 1 si parla del primo decile
che rappresenta quel valor medio al di sotto del quale sta 1/10 dei valori osservati e al
di sopra del quale stanno i 9/10 dei valori osservati.
Moda
Con riferimento ad una distribuzione di frequenza si definisce moda quel valor medio
cui corrisponde la massima frequenza
25
Calcolo della mediana
di una distribuzione per classi di valori
(con frequenze assolute)
⎛N
⎞ x − xi −1
M e = xi −1 + ⎜ − Gi −1 ⎟ i
⎝2
⎠ yi
Gi = y1 + y 2 + .... + yi
G0 = 0
Gn = N
(con frequenze relative)
M e = xi −1
Fi = f1 + f 2 + .... + f i
⎛1
⎞ xi − xi −1
+ ⎜ − Fi −1 ⎟
fi
⎝2
⎠
F0 = 0
Fn = 1
f i = yi / N
Esempio (frequenze assolute):
Dist rib u zi one di a lcune fa mi g lie ita li ane
secondo classi di reddito
Classi di
reddito
(migliaia)
xi-xi+1
50-100
100-200
200-300
Totale
Famiglie
Famiglie
con classi
di
reddito
≥( fi no a) x
Gi
110
400
90
600
Posto valor mediano =
110
510
600
Frequenze Frequenze
relative
relative
fi
cumulat e
Fi
0,1833
0,1833
0,6667
0,8500
0,15
1
1
Posto
classe
mediana
N 600
=
= 300
2
2
Classe mediana = 100-200
⎛ 600
⎞ 200 − 100
100 + ⎜
− 110 ⎟
= 147,50
Valore mediano =
⎝ 2
⎠ 400
26
Calcolo del k.mo quantile
di una distribuzione per classi di valori
(con frequenze assolute)
⎛ k
⎞ x − xi −1
Qk / m = xi −1 + ⎜ N − Gi −1 ⎟ i
yi
⎝ m
⎠
(con frequenze relative)
Qk / m
⎛k
⎞ xi − xi −1
= xi −1 + ⎜ − Fi −1 ⎟
⎝m
⎠ fi
m = numero di parti uguali in cui
è divisa la distribuzione
k= ordine del quantile
Esempio: Calcolo del 1° e 3° quartile (con frequenze relative)
Posto 1° quartile =
1
= 0,25
4
Classe 1° quartile = 100-200
⎛1
⎞ 200 − 100
Q1 / 4 = 100 + ⎜ − 0,1833⎟
= 109,95
⎝4
⎠ 0,67
Posto 3° quartile =
3
= 0,75
4
Classe 3° quartile = 100-200
Q3 / 4
⎛3
⎞ 200 − 100
= 100 + ⎜ − 0,1833⎟
= 184,58
⎝4
⎠ 0,67
27
Variabilità e Mutabilità
fenomeni o caratteri quantitativi
fenomeni o caratteri qualitativi
Definizione: Attitudine dei caratteri ad assumere modalità differenti
Aspetti
dispersione
diseguaglianza
per cause accidentali
per cause accidentali e sistematiche
gli indici misurano di quanto in media
le quantità rilevate differiscono
da una grandezza media
gli indici misurano di quanto in
media le quantità rilevate
differiscono fra di loro
Proprietà:
Gli indici di variabilità devono:
a) assumere valori non negativi;
b) essere nulli quando tutti i termini della distribuzione sono eguali fra loro;
c) crescere all’aumentare della disuguaglianza fra i termini.
28
Indici di variabilità assoluta
Campo di variazione
(valori ordinati in ordine non decrescente)
Su una seriazione
Dati i valori osservati distinti: x 1 ,x 2 ,…,x i ,…, x n
il campo di variazione è:
W = x(n) - x(1)
Su una distribuzione di frequenza
Data la distribuzione di frequenza:
Vari abile x Frequen za y
x1
y1
x2
y2
…
…
xi
yi
…
…
xs
ys
Totale
N
il campo di variazione è:
W = x(s) - x(1)
Differenza interquartilica
D = Q3/4 - Q1/4
29
Indici di dispersione
Indici di disuguaglianza
(Scarto semplice medio)
(Differenza semplice media)
∑
∑
n
n
| xi − x | yi
S =
i =1
n
∆=
n
∑∑| x
i
− x j | yi y j
1=1 i =1
N ( N − 1)
yi
i =1
(Scarto quadratico medio)
( Differenza quadratica media)
(o deviazione standard)
n
σ =2
∑( xi − x)2 yi
i =1
n
∑y
i=1
σ2 =
∑(x
i =1
∆2 =
∑∑ ( x
1=1 i =1
− x ) yi
n
∑y
i =1
i
i
− x j ) 2 yi y j
N ( N − 1)
(Scostamento medio dalla mediana)
n
2
i
n
i
(Varianza )
n
n
S Me =
∑| x
i =1
i
− Me | yi
n
∑y
i =1
i
30
La varianza si può calcolare come differenza fra la media aritmetica dei
quadrati degli scarti da un’origine arbitraria m ed il quadrato della media
aritmetica degli stessi scarti
∑
n
1
σ2 =
N
i =1
∑
n
1
( xi − m) 2 yi − [
N
(xi − m) yi ]2
i =1
se m = 0
∑
n
σ2 =
1
N
i =1
∑
n
xi2 yi − [
1
N
xi yi ]2
i =1
la varianza si calcola come differenza fra il quadrato della media
quadratica ed il quadrato della media aritmetica
31
Dati raggruppati
Gruppi
modalità
1
2
3
…
I
…
nj
1
x11
x21
x31
…
xi1
…
xn j 1
2
x12
x22
x32
…
xi2
…
xn j 2
3
x13
x23
x33
…
xi3
…
xn j 3
…
…
…
…
…
…
…
…
j
x1j
x2j
x3j
…
xij
…
xn j j
…
…
…
…
…
…
…
…
k
x1k
x2k
x3k
…
xik
…
xn j k
n.
modalità
medie
varianze
n1
n2
n3
…
nj
…
nk
m1
σ21
m2
σ22
m3
σ23
…
…
mj
σ2j
…
…
mk
σ2k
Calcolo della media:
nj
1)
2)
k
k
x = ∑∑ xij / ∑ n j
i =1 j =1
j =1
k
k
j =1
j =1
x = ∑ mjnj / ∑ n j
Calcolo della varianza:
nj
k
k
σ = ∑∑ ( xij − x) / ∑ n j
2
1)
2
i =1 j =1
k
σ2 =
2)
∑σ
j =1
j =1
2
j
k
nj
+
k
∑n
j =1
j
∑ (m
j =1
k
− x) n j
2
j
σ2 =
k
∑n
j =1
j
∑σ
j =1
2
j
nj
+σm
k
∑n
j =1
2
j
32
Esempio:
Gruppi
2°
1°
3
2
5
4
Mo
Da
Li
Tà
3°
10
11
12
3,5
1,25
4
medie
varianze
nj
k
k
j =1
j =1
Totali
4
7
11
0,67
3
5,5
2,25
2
17
20
17
4
58
6,44
12,25
x = ∑ mi n j / ∑ n j = 58 / 9 = 6,44
k
σ2 =
∑σ
j =1
2
j
k
nj
+
k
∑n
j =1
varianza
entro i gruppi
j
∑ (m
j =1
j
− x)2 n j
=
k
∑n
j =1
11,5 98,72
+
= 1,28 + 10,97 = 12,25
9
9
j
varianza
tra i gruppi
33
Dati raggruppati
modalità
x1
x2
x3
…
xi
…
xn
1
2
n12
n22
n32
…
ni2
…
n11
n21
n31
…
ni1
…
nn1
frequenze
medie
varianze
nn 2
n.1
m1
σ21
Gruppi
3
n13
n23
n33
…
ni3
…
nn 3
…
…
…
…
…
…
…
…
j
n1j
n2j
n3j
…
nij
…
nn j
n.3
m3
σ23
…
…
…
n.j
mj
σ2j
n.2
m2
σ22
…
…
…
…
…
…
…
…
k
n1k
n2k
n3k
…
nik
…
nnk
Totali
n1.
n2.
n3.
…
ni.
…
n n.
…
…
…
n.k
mk
σ2k
N
Calcolo della media:
nj
1)
2)
k
k
x = ∑∑ xi nij / ∑ nij
i =1 j =1
j =1
k
k
j =1
j =1
x = ∑ m j n. j / ∑ n. j
Calcolo della varianza:
nj
k
k
σ = ∑∑ ( xi − x) nij / ∑ nij
2
1)
2
i =1 j =1
k
σ =
2
2)
∑σ
j =1
j =1
2
j
k
n. j
k
∑n
j =1
.j
+
∑ (m
j =1
j
− x) 2 n. j
k
∑n
j =1
.
j
34
Esempio:
modalità
3
4
5
7
Totali
Medie
Varianze
Gruppi
2°
3°
2
1
3
3
10
5
12
2
27
11
5,63
4,91
1,79
1,36
1°
3
3
2
1
9
4,22
1,51
Totali
6
9
17
15
47
5,19
Calcolo media:
nj
1)
2)
k
k
x = ∑∑ xi nij / ∑ nij = 244 / 47 = 5,19
i =1 j =1
j =1
k
k
j =1
j =1
x = ∑ m j n. j / ∑ n. j = 244 / 47 = 5,19
Calcolo varianza:
nj
k
k
σ = ∑∑ ( xi − x) nij / ∑ nij = 91,28 / 47 = 1,94
2
1)
2
i =1 j =1
k
2)
σ2 =
∑σ
j =1
2
j
k
n. j
k
∑n
j =1
j =1
.j
+
∑ (m
j =1
j
− x) 2 n. j
k
∑n
j =1
.
=
76,76 14,52
+
= 1,63 + 0,31 = 1,94
47
47
j
35
Calcolo della differenza semplice media
Su una seriazione: x1 x 2 x
x1
x2
…
x
n
3
... x
n
Schema per il calcolo della differenza semplice media
x1
x2
…
|x1- x1|
|x1- x2|
…
|x2- x1|
|x2- x2|
…
xn
|x1- xn|
|x2- xn|
…
…
…
…
|xn- x1|
|xn- x2|
…
|xn- xn|
Su una distribuzione di frequenza:
Vari abile x Frequen za y
x1
y1
x2
y2
…
…
xi
yi
…
…
xs
ys
Totale
N
X1
x2
Schema per il calcolo della differenza semplice media
x1
x2
xn
…
|x1- x1|y1y1
|x1- x2| y1y2
|x1- xn| y1yn
…
|x2- x1| y2y1
|x2- x2| y2y2
|x2- xn| y2yn
…
…
…
…
…
…
xn
|xn- x1| yny1
|xn- x2| yny2
…
|xn- xn| ynyn
36
Schema per il calcolo della differenza semplice media
x1
x2
x1
|x1- x1|
|
x2
|x2- x1|
|x2- x2|
x3
|x3- x1|
|x3- x2|
|x3- x3|
…
…
xn
|xn x1|
|xn- x2|
…
…
…
…
…
x
|xn- xn|
n
ai= somma dei minuendi in diagonale = xi +xi+1+…..+xn
si = somma dei sottraendi in verticale = x1 +x2+…..+xi
somma dei minuendi in diagonale
ai +ai+1+…..+an
somma dei sottraendi in verticale
s1 +s2+…..+sn
∑
n
i =1
somma dei minuendi in verticale
=
x1 +2x2+…..+ixi +….+nxn
=
somma dei sottraendi in orizzontale
=
∑
i =1
i = 1,2,…,n
=
nx1 +(n-1)x2+…..(n-i+1) xi+…+xn
∑
n −1
n
(ai − si ) =
i = 1,2,…,n
( 2i − n − 1) xi = 2
(i x − si )
i =1
37
Formule alternative per il calcolo della
differenza semplice media
Data la seriazione: x1 x 2 x
... xi… x n
disponendo le quantità xi in ordine non decrescente: x1 ≤ x2 ≤ ... xi ... ≤ xn
3
n
2
∆=
(2i − n − 1) xi
∑
n(n − 1) i =1
n
2
∆=
∑ (ai − si )
n(n − 1) i =1
(1)
n
ai = ∑ x j
i =i
n −1
4
∆=
∑ (i x − si )
n(n − 1) i =1
i
si = ∑ x j
(2)
i =1
(3)
x1 x 2 x
3
... x
n
y1 y 2 y
3
... y
n
Data la distribuzione:
la (2) si trasforma in:
n
2
∆=
( Ai − S i ) yi
∑
N ( N − 1) i =1
Formula di Czuber-Gini
n
i
n
j =i
j =1
i =1
Ai = ∑ x j y j Si = ∑ x j y j N = ∑ yi
38
Esempio calcolo della differenza semplice media
Schema per il calcolo del numeratore della differenza
semplice media
xi
5
7
8
9
Totali
5
0
2
3
4
9
7
2
0
1
2
5
8
3
1
0
1
5
9
4
2
1
0
7
totali
9
5
5
7
26
n
∆=
n
∑∑| x − x
i
1=1 i =1
xi
5
7
8
9
totali
j
|
n(n − 1)
i
1
2
3
4
=
26
= 2,16
(4 * 3)
criterio (1)
2i
2i-n-1
2
-3
4
-1
6
1
8
3
(2i-n-1) xi
-15
-7
8
27
13
n
2
2
∆=
(2i − n − 1) xi =
*13 = 2,16
∑
n (n − 1) i =1
(4 * 3)
xi
5
7
8
9
totali
Criterio (2)
ai
si
29
5
24 12
17 20
9
29
ai- si
24
12
-3
-20
13
n
2
2
∆=
(
a
−
s
)
=
*13 = 2,16
∑
i
i
n(n − 1) i =1
( 4 * 3)
39
Criterio (3)
I
1
2
3
4
5
7
8
9
totali
i
media =7,25
si
5
12
20
29
x
7,25
14,5
21,75
29
i x − si
2,25
2,5
1,75
0
6,5
4 n −1
4
∆=
(
i
x
−
s
)
=
* 6,5 = 2,16
∑
i
n(n − 1) i =1
(4 * 3)
Data la seguente distribuzione di frequenza
xi yi
5 2
7 4
8 3
9 1
Totali10
si applica la formula di Czuber-Gini
n
2
∆=
( Ai − S i ) yi
∑
N ( N − 1) i =1
xi
5
7
8
9
Totali
∆=
yi
2
4
3
1
10
xiyi
10
28
24
9
71
Ai
71
61
33
9
Si
10
38
62
71
Ai - Si
61
23
-29
-62
(Ai - Si)*yi
122
92
-87
-62
65
2
* 65 = 1,44
10(9)
40
Variabilità relativa
Indici assoluti rapportati al valore medio
Indici assoluti rapportati al massimo
Coefficiente di variazione
σ
x
100
Se la distribuzione massimante è del tipo:
∆ max = 2 x
σ max = x ( N − 1)
xi
yi
0
N-1
n
∑x
σ 2 max = x 2 ( N − 1)
i =1
i
= Nx
1
S max = 2 x( N − 1) / N
Indici di variabilità relativa
rapportati al massimo:
(N-1)
∆ / ∆ max = ∆ / 2 x
σ / σ max = σ / x ( N − 1)
2
σ 2 / σ 2 max = σ 2 / x ( N − 1)
S / S max = S / 2 x( N − 1) / N
1
n
x1 = 0
x n = ∑ xi = N x
i =1
41
Concentrazione
Definizione: La concentrazione è un particolare aspetto della variabilità dei fenomeni
o caratteri trasferibili
Data la seriazione: x1 x 2 x 3 ... xi… x n,
disponendo le quantità xi in ordine non decrescente: x1 ≤ x2 ≤ .... ≤ xn
e considerando gli ultimi r valori (r<n),
si ha concentrazione
se la somma degli ultimi r valori costituisce una frazione della somma degli n valori
maggiore della frazione r/n :
x n−r +1 + x n−r + 2 + ... + x n r
>
x1 + x 2 + ... + xn
n
ovvero, ricordando che s i =
s n − s n− r r
>
sn
n
;
i
∑
i =1
xj ;
i = 1, 2,…,n-1
r = 1, 2,…,n-1
oppure, ponendo (n-r)=i
si i
<
sn n
Posto:
i
= pi
n
si
= qi
sn
qi < pi
qi = pi
concentrazione
equidistribuzione
42
Esempio:
Calcolo delle qi e delle pi e dei rapporti di concentrazione
xi xi/Σxι yi/Σyι qi pi pi - qipi+1-pi qi+1+qi (pi+1-pi)( qi+1+qi
0,016
x1 5 0,08 0,20 0,080,20 0,12 0,20 0,08
0,057
x2 7 0,12 0,20 0,200,40 0,20 0,20 0,28
0,113
x3 10 0,17 0,20 0,370,60 0,23 0,20 0,57
0,207
x4 18 0,30 0,20 0,670,80 0,13 0,20 1,04
0 0,20 1,67
0,333
x5 20 0,33 0,20 1 1
totali60 1
1
0,68
0,726
q
Curva di concentrazione
1
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
0,1
0
0
0,2
0,4
0,6
p
0,8
1
curva di concentrazione ----- retta di equidistribuzione
R=
A
= 2 A Rapporto di concentrazione
1
2
n −1
R = 1 − ∑ ( p i +1 − p i )(q i +1 + q i )
i =0
Rapporto di concentrazione
R= 1- 0,726=0,274
43
1 n −1
( pi − qi )
∑
n i =1
somma delle aree dei rettangoli di base
1/n ed altezza (pi-qi) (area di concentrazione)
1 N −1
1 n −1 i 1 n( n − 1) 1
≅
pi = ∑ =
∑
n i =1
n i =1 n n 2n
2
somma delle aree dei rettangoli di base
1/n ed altezza pi(area del triangolo)
n −1
∑(p
i
i =1
− qi )
n −1
∑p
i =1
R=0,68/2=0,34
i
Rapporto di concentrazione del Gini
( per dati non raggruppati
e sufficientemente numerosi)
Calcolo del rapporto di concentrazione per dati raggruppati
Classi
0-1
1-2
2-3
3-5
5-7
pi+1-pi
xi
0,5
1,5
2,5
4,0
6,0
yi
3
3
10
12
20
48
xi yi
1,5
4,5
25,0
48,0
120,0
199,0
si
1,5
6,0
31,0
79,0
199,0
i
3,0
6,0
16,0
28,0
48,0
qi
0,008
0,030
0,156
0,397
1,000
pi
0,063
0,125
0,333
0,583
1,000
0,063
0,063
0,208
0,250
0,417
qi+1+qi
0,008
0,038
0,186
0,553
1,397
(pi+1-pi)(
qi+1+qi)
0,0005
0,0024
0,0387
0,1382
0,5821
0,7618
R=1-0,7618 = 0,2382
44
Mutabilità
Definizione: E’ l’attitudine dei fenomeni o caratteri qualitativi (misurati su scala
nominale o ordinale) ad assumere differenti modalità.
La mutabilità è nulla se il carattere si presenta sempre con la stessa modalità
La mutabilità è massima se le frequenze con le quali si osservano le diverse modalità
del carattere sono eguali.
Indice di entropia
m
H = −∑ f i log f i
i =1
m
∑f
i
=1
i =1
Scaturisce dalla teoria dell’informazione
Utilizza come misura della quantità d’informazione log(1/fi) dove fi è la frequenza relativa
dell’i-esima modalità (i=1,2,…,m)
Ricordando che:
per fi =1 log (1/fi) = 0
lim - fi log (fi) = lim[ logf / (-1/f)] = lim[( 1/ f ) /(1/ f2 ) ]= lim f= 0
f→0
f→0
f→0
f→0
se m-1 delle m frequenze tendono a zero e di conseguenza una frequenza tende a uno,
H tende a zero
se le frequenze delle m modalità sono eguali ossia fi =1/m , H assume il valore massimo,
Hmax=logm
Indice relativo di entropia
H
1 m
0≤
=−
∑ fi log fi ≤ 1
H max
log m i =1
Indice di mutabilità del Gini
m
m
i =1
i =1
0 ≤ G = ∑ f i (1 − fi ) = 1 − ∑ f i ≤ 1 −
2
1
m
indice assoluto
∑
m
indice relativo
m
∑f
i =1
i
0≤
G
=
Gmax
f i (1 − f i )
i =1
1
1−
m
≤1
=1
45
Momenti
Definizione: si definisce momento di origine m e di grado r di una distribuzione la
media aritmetica ponderata delle potenze r-esime degli scarti da m dei valori xi con
pesi espressi dalle yi
1
=
N
µ m ,r
n
∑ (x
i =1
− m) r y i
i
se l’origine è la media aritmetica il momento si scrive:
1
µr =
N
n
∑ (x
i =1
i
− x ) r yi
Formule di trasformazione
per passare da un’origine m ad un’altra origine m’
r
k ⎛ ⎞ r −k k
⎜
−
=
−
a
b
(
)
(
1
)
∑
Ricordando che:
⎜ k ⎟⎟a b
k =0
⎝ ⎠
r
r
e posto:
∑
r
( xi − m' ) r = [( xi − m) − ( m '− m)]r =
k =0
r
⎛r ⎞
( −1) k ⎜⎜ ⎟⎟( xi − m) r − k ( m'− m) k
⎝k ⎠
⎛r ⎞
⎝k⎠
µ m ',r = ∑ (−1) k ⎜⎜ ⎟⎟µ m ,r −k (m'−m) k
k =0
46
Per m’ = x
∑
n
1
(m'−m) = ( x − m) =
n
r
( xi − m) = µ m,1
i =1
⎛r ⎞
⎝k ⎠
µ r = ∑ ( −1) k ⎜⎜ ⎟⎟µ m,r − k µ k m,1
k =0
Relazioni fra i momenti di origine m e di origine la media aritmetica
µ 2 = µ m , 2 − µ 2 m ,1
µ 3 = µ m ,3 − 3µ m , 2 µ m,1 + 2 µ 3 m ,1
µ 4 = µ m , 4 − 4 µ m ,3 µ m,1 + 6 µ m , 2 µ 2 m ,1 − 3µ 4 m,1
47
Correzioni di Sheppard
Si apportano ai momenti quando:
la distribuzione è per classi
l’ampiezza h delle classi è costante
quando le frequenze delle classi estreme sono piccole
µ ' m,2 = µ m ,2 −
1 2
h
12
1
µ 'm ,3 = µ m ,3 − µ m ,1h 2
4
1
7 4
2
µ 'm , 4 = µ m , 4 − µ m , 2 h +
h
2
240
48
Funzioni di densità di frequenza (o di probabilità)
In una variabile continua i valori della funzione f(x) non esprimono frequenze o
probabilità ma hanno il significato di altezze di rettangoli aventi basi infinitamente
piccole e le cui aree rappresentano frequenze o probabilità. In tal caso la funzione
f(x) è chiamata funzione di densità di frequenza ( o di probabilità )
La frequenza ( probabilità) dei valori all’interno di una classe, di ampiezza
infinitesima dx, è pari al prodotto della densità f(x) per l’ampiezza dx ed è
indicata con il simbolo:
dF(x) = f(x)dx
differenziale della funzione di ripartizione F(x)
x
F ( x) =
∫
f (t )dt
a<x<b
a
F (a) = 0
F (b) = 1
f ( x) =
dF ( x)
= F ' ( x)
dx
derivata della funzione di ripartizione F(x)
49
Adattamento
Definizione: si dice adattamento di una funzione matematica ad una
distribuzione di frequenza la costruzione, in base ai valori osservati, di un
modello matematico capace di rappresentare la distribuzione osservata in
maniera soddisfacente prescindendo dagli aspetti non sistematici
Interpolazione : Fissata la forma della funzione y= f(x) , caratterizzata da n parametri, si pone
la condizione che essa assuma esattamente i valori osservati in corrispondenza di un certo
numero n di valori distinti della variabile x
Nell’adattamento la funzione adattata:
1) non deve necessariamente assumere valori esattamente eguali alle frequenze
osservate;
2) il numero dei parametri è inferiore al numero delle coppie che si ottengono
associando ai valori osservati le corrispondenti frequenze.
Fasi dell’adattamento:
a) scelta della forma della funzione f(x);
b) determinazione dei valori dei parametri della funzione scelta;
c) verifica della bontà dell’adattamento eseguito.
Scelta della forma della funzione
Criteri grafici
Criteri numerici
50
Determinazione dei valori dei parametri
1) Metodo dei minimi quadrati: consiste nel rendere minima la somma dei
quadrati delle differenze fra i valori della funzione adattata e le frequenze
osservate
2) Metodo dei momenti: consiste nel determinare tanti momenti della
distribuzione teorica, di grado progressivamente crescente, quanti sono i
parametri incogniti da stimare e di porre la condizione che i loro valori siano
eguali a quelli dei corrispondenti momenti calcolati sui dati osservati
Stima di r parametri con il metodo dei minimi quadrati
∑ ∑
n
n
ε2 =
i =1
[yi − f ( xi ;θ1 ,θ 2 ...θ r )]2 = minimo
i =1
f ( xi ;θ1 ,θ 2 ...θ r ) = funzione lineare rispetto ai parametri
51
Stima di r parametri con il metodo dei momenti
θ1 ,θ 2 ,θ 3 ...,θ r = parametri
µ’m,1 = momento teorico
µm,1 = momento osservato
µ’m,1 = µm,1
µ’m,2 = µm,2
……
µ’m,r = µm,r
Verifica della bontà dell’adattamento
Le frequenze osservate yi vengono poste a confronto con le frequenze teoriche f(xi)
ottenute. La distribuzione teorica adattata costituisce un’adeguata rappresentazione
dei dati osservati se:
a) gli scarti fra frequenze osservate e teoriche sono piccoli , in valore assoluto,
rispetto alle frequenze;
b) i segni degli scarti si alternano senza un apparente ordine sistematico
Per misurare la bontà dell’adattamento è utilizzato l’indice χ2
∑
n
χ =
2
i =1
[ y i − f ( xi )]2
f ( xi )
52
Calcolo delle probabilità
Probabilità in senso oggettivo
Definizione matematica: la probabilità di un evento è il rapporto fra il numero dei
casi favorevoli ad un evento ed il numero dei casi possibili, considerati tutti
egualmente possibili
Definizione frequentista: la probabilità di un evento è il limite della frequenza
dell’evento al crescere del numero delle prove
Probabilità in senso soggettivo
Definizione: E’ il grado di fiducia che un individuo ripone nel verificarsi di un
evento
Principio delle probabilità totali: Dati n eventi E1, E2,…, En, tra di loro
incompatibili, la probabilità che si verifichi uno qualsiasi di questi eventi ( probabilità
della loro unione) è data dalla somma delle probabilità dei singoli eventi
P(E1
∪
E2
∪
…
∪
En) = P(E1) + P(E2) +…+ P(En)
Principio delle probabilità composte: La probabilità che n eventi compatibili ed
indipendenti E1, E2,…, En, si verifichino tutti insieme ( probabilità della loro
intersezione) è data dal prodotto delle probabilità dei singoli eventi
P(E1 ∩ E2
∩
… ∩ En) = P(E1) *P(E2) *…*P(En)
53
Teorema di Bayes
Dato un evento A e un evento B tra loro compatibili e dipendenti, la probabilità che si
verifichino entrambi gli eventi è data da:
P(A) P(B/A)=P(B) P(A/B)
per cui
P ( A) P( B / A)
P ( B)
P( A / B) =
Si supponga che l’evento B venga posto in relazione con n eventi A1, A2,…Ai,…,
An, tra di loro incompatibili e tali che uno di essi deve necessariamente verificarsi,
cioè:
P(A1) + P(A2) +…+P(Ai)+…+ P(An) = 1
L’evento B,se si verifica, dovrà verificarsi con uno degli eventi Ai
e, poiché
P(Ai ∩ B) = P(Ai) P(B/Ai)
i= 1,2,.., n
e gli eventi (Ai ∩ B) sono incompatibili, la probabilità che B si verifichi è data da:
n
P ( B ) = ∑ P ( Ai ) P( B / Ai )
i =1
da cui si ricava:
P( Ai / B) =
P( Ai ) P( B / Ai )
n
∑ P( A ) P( B / A )
i =1
i
i
54
Esempio: - I sinistri del settore auto di una compagnia di assicurazione sono
classificati, in base alla loro gravità, in (a) lievi, (b) gravi, (c) mortali mentre il tipo
di auto che li ha causati, in (A) utilitarie, (B) medie e (C) superiori. In base
all’esperienza della compagnia, le probabilità di un incidente mortale per
un’utilitaria, media, superiore sono rispettivamente eguali a 0,36, 0,08, 0,40. E’
noto anche che il 50% degli assicurati ha un’utilitaria, il 25% una media, il 25% una
superiore. Avendo osservato un incidente mortale, qual’è la probabilità che esso sia
stato causato da un’utilitaria?
Tipo di incidente
Cilindrata macchina
Incidente mortale = M
Incidente lieve =L
Incidente grave =G
Utilitaria = U
Cilindrata media = Me
Cilindrata superiore =S
P(M/U) = 0,36
P(M/Me) = 0,08
P(M/S) = 0,40
P(U) = 0,50
P(Me) = 0,25
P(S) = 0,25
P(M) = P(U) P(M/U) + P(Me) P(M/Me) + P(S)P(M/S)
P(M)= 0,50*0,36 + 0,25*0,08 + 0,25*0,40 = 0,28
P(U / M ) =
P( Me / M ) =
P( S / M ) =
P(U ) P( M / U ) 0,50 * 0,36
=
= 0,64
0,28
P( M )
P( Me) P( M / Me) 0,25 * 0,08
=
= 0,005
0,28
P(M )
P( S ) P( M / S ) 0,25 * 0,40
=
= 0,355
0,28
P( M )
P(U/M) + P(Me/M) + P(S/M) = 1
55
Distribuzione binomiale
⎛n⎞
Pn , x = ⎜⎜ ⎟⎟ p x q n − x
⎝ x⎠
0≤p ≤1
q=1-p
Probabilità che in n prove indipendenti l’evento E,
avente probabilità costante p, si verifichi x volte
Distribuzione binomiale:
⎛n⎞
( q + p ) = ∑ ⎜⎜ ⎟⎟ p x q n− x = 1
i =0 ⎝ x ⎠
n
n
x
Pn,x
0
⎛n⎞
Pn ,0 = ⎜⎜ ⎟⎟ p 0 q n
⎝0⎠
⎛n⎞
Pn ,1 = ⎜⎜ ⎟⎟ p1q n −1
⎝1 ⎠
1
2
⎛n⎞
Pn, 2 = ⎜⎜ ⎟⎟ p 2 q n − 2
⎝2⎠
…
…
n
⎛n⎞
Pn ,n = ⎜⎜ ⎟⎟ p n q 0
⎝n⎠
Valore medio = np
Varianza =npq
Formula ricorrente
Pn , x+1 =
n− x p
Pn, x
x +1 q
56
Pn,x
Distribuzione binomiale
0,4500
0,4000
0,3500
0,3000
0,2500
0,2000
0,1500
0,1000
0,0500
0,0000
p=0,15
n=7
0
2
4
6
q=0,85
8
Distribuzione binomiale
0,3
0,25
Pn,x
0,2
0,15
p=0,5 q=0,5
n=7
0,1
0,05
0
0
5
10
Distribuzione binomiale
0,25
0,15
p=0,15 q= 9,85
n=30
0,1
0,05
0
0
20
40
Distribuzione binomiale
Pn,x
Pn,x
0,2
0,16
0,14
0,12
0,1
0,08
0,06
0,04
0,02
0
p=q=0,5 n=30
0
10
20
30
40
57
Esempio adattamento binomiale positiva
(me tod o de i mo me nti)
( x
−
x )
2
x
Pn.x (osservato)
x*Pn,x
0
1
2
3
4
5
6
7
Totali
0,3500
0,3700
0,2120
0,0645
0,0031
0,0004
0
0,3700
0,4240
0,1935
0.,0124
0,0020
0,351331
0,000001
0,211195
0,257510
0,027865
0,006394
1,0000
1,0019
0,854296
x = np
P
n , x
Px ( teorico)
χ2
0,3277
0,3963
0,2054
0,0592
0,0102
0,0011
0,0001
0,0000
1,0000
0,001516144
0,001751433
0,000209456
0,00048215
0,004961598
0,000410619
6,10264E-05
1,50629E-06
0,009393934
1,0019 = np
0,8543 = npq
σ = npq
2
σ2
0,8543
q=
=
= 0,8527
x 1,0019
p = 1 − q = 1 − 0,8527 = 0,1473
n=
x 1,0019
=
= 6,80 ≅ 7
p 0,1473
La d is trib uz io ne teo rica ad attata s i o ttie ne sos titue nd o ne lla
∑
⎛ n ⎞ x n− x
⎜⎜ ⎟⎟ p q = 1
⎝ x⎠
∑
⎛7⎞
⎜⎜ ⎟⎟0,1473 x 0,8527 7− x = 1
⎝ x⎠
n
(q + p) n =
i =0
i va lori stima ti p er c u i:
7
(0,8527 + 0,1473) 7 =
i =0
58
Formula di De Moivre
La probabilità che in n prove l’evento si verifichi x volte si può esprimere in funzione
dello scarto ε = x - np
Pn ,np+ε
n! p np+ε q nq−ε
n!(np ) np+ε ( nq ) nq−ε
=
= n
( np + ε )!( nq − ε )! n (np + ε )!( nq − ε )!
che per ε = 0 diventa:
Pn ,np
n! p np q nq
n!( np ) np (nq ) nq
=
=
( np )!( nq )! n n ( np )!( nq )!
Se il numero n delle prove è molto grande, i fattoriali possono essere sviluppati
mediante la formula approssimata di De Moivre Stirling
n!≅ n n e − n 2Πn
Pn , np ≅
1
2Π npq
e se la differenza q-p è piccola
Pn , np + ε ≅
1
− ε 2 /( 2 npq )
e
2Πnpq
funzione continua dello scarto ε
nota come
curva normale delle probabilità
o curva di Gauss
o curva degli errori accidentali
59
Curva normale
0,045
0,04
0,035
0,03
0,025
0,02
0,015
0,01
0,005
61
57
53
49
45
41
37
33
29
25
21
17
13
9
5
1
0
Curve normali
0,09
0,08
0,07
0,06
0,05
0,04
0,03
0,02
0,01
0
varianza =10
61
55
49
43
37
31
25
19
13
7
1
varianza =5
60
Curva normale in funzione dello scarto ridotto z:
z=
Pn , np + ε ≅
f ( z) =
x − np
1
σ
npq
1 −z2 / 2
e
2Π
1 −z2 / 2
e
2Π
curva normale ridotta o stardardizzata
simmetrica rispetto all’asse delle ordinate
f(z) = f(-z)
campanulare con due punti di flesso in
z = -1
z=1
massimo per z = 0
1
f (0) =
1
2Π
2Π
∞
∫e
−z2 / 2
=1
−∞
La variabile continua z, definita nel campo dei numeri reali,
con funzione di densità di probabilità f(z), è una variabile normale
ridotta che si indica con il simbolo N(0,1) perché la sua distribuzione
di probabilità ha valor medio 0 e varianza 1
61
Esempio formula De Moivre:
Un’ urna contiene 10 palline di cui 2 rosse, 3 bianche e 5 nere. Si effettuino 40
estrazioni di una pallina rimettendo a ogni estrazione la pallina nell’urna. Calcolare la
probabilità che esca 2 volte pallina rossa.
La probabilità che esca pallina rossa è p=2/10.
np = 8 ;
npq = 2,53 ; 3 npq = 7,59 ; ε < 3 npq
La probabilità esatta che in 40 lanci esca np volte pallina rossa è
⎛ 40 ⎞ 2 8 8 32
P40,8 = ⎜⎜ ⎟⎟
= 0,156
10
⎝ 8 ⎠ 10
( ) ( )
La probabilità esatta che in 40 lanci esca 2 volte pallina rossa è
⎛ 40 ⎞ 2 2 8 38
P40,2 = ⎜⎜ ⎟⎟
0,0065
10
⎝ 2 ⎠ 10
( ) ( ) =
Applicando la formula de Moivre:
La probabilità approssimata che in 40 lanci esca np volte pallina rossa è
P40,8 ≅
1
= 0,158
2Π 6,4
La probabilità approssimata che in 40 lanci esca 2 volte pallina rossa è
P40, 2 ≅
1
−[( −6 2 ) /( 2*6 , 4 ) ]
e
= 0,0094
2Π 6,4
62
Probabilità integrali
k
P( − k ≤ z ≤ k ) =
∫ f ( z )dz
k>0
−k
Esempi probabilità integrale:
1) Si vuole calcolare la probabilità che in 40 lanci la pallina rossa esca fino a due
volte
Probabilità esatte secondo la distribuzione binomiale e secondo l’approssimazione
della curva normale
X
Pn.x
ε = (x-np)
0
1
2
0,00013
0,00133
0,00650
-8
-7
-6
z = ε / npq
-3,16
-2,77
-2,37
f(z)
0,0027
0,0087
0,0239
Probabilità
integrale
0,00796
Probabilità integrale secondo la binomiale: 0,00796
Probabilità integrale secondo l’approssimazione della normale: 0,0139
f ( z ) / npq
0,0010
0,0034
0,0095
0,0139
2) Si vuole calcolare la probabilità che in 40 lanci la pallina rossa esca più di due
volte
Probabilità integrale secondo la binomiale: 1 - 0,00796 = 0,99204
Probabilità integrale secondo l’approssimazione della normale: 1 - 0,0139 = 0,9861
3) Si vuole calcolare la probabilità che in 40 lanci la pallina rossa esca da due a
cinque volte
Probabilità esatte secondo la distribuzione binomiale e secondo l’approssimazione
della curva normale
X
Pn.x
ε = (x-np)
z = ε / npq
f(z)
f ( z ) / npq
2
3
4
5
0,00650
0,02052
0,00475
0,08541
-6
-5
-4
-3
-2,37
-1,98
-1,58
-1,19
0,0239
0,0566
0,1143
0,1975
0,0095
0,0224
0,0452
0,0781
Probabilità
integrale
0,15987
0,15508
Probabilità integrale secondo la binomiale: 0,15987
Probabilità integrale secondo l’approssimazione della normale: 0,15508
63
Curva normale
Prob(z < k )
z
Curva normale
-z
z
Prob (-k < z < k )
Curva normale
Prob(z > k )
z
64
Asimmetria e kurtosi
Una distribuzione di frequenza è simmetrica quando esiste un valore m tale che, se si
considerano due valori equidistanti da m, questi hanno la stessa frequenza, ossia
f(m+x)=f(m-x)
dove f(x) è la funzione di frequenza o di densità di frequenza della distribuzione
secondo che questa sia discreta o continua
In una distribuzione unimodale simmetrica, media aritmetica, moda e mediana
coincidono e tutti i momenti di origine la media aritmetica e di grado dispari sono
nulli
Indici di asimmetria
Per una distribuzione unimodale:
x− Mo
Indice del Pearson
σ
Nelle distribuzioni per classi:
3( x − M e )
σ
Indice di asimmetria fondato sui momenti:
µ
µ
β 1 = 33 = 33/ 2
σ
µ2
µ32
β1 = 3
µ2
valore 0 nel caso di simmetria
65
Indice di kurtosi
β2 =
µ4
µ22
Nelle distribuzioni normali µ4 =3σ4 e β2=3
β2<3 platikurtiche
β2=3 mesokurtiche
β2>3 leptokurtiche
Adattamento curva normale
Condizioni : distribuzione di frequenza (probabilità) continua
β1 ≅ 0
β2 ≅ 3
determinazione dei parametri con metodo dei momenti
66
Esempi adattamento curva normale
Classi di ore
di assenza
mensili
valori
centrali
Operai
Freq. Rel.
Estr. sup.
Z
P(Z<z)
Frequenze
relative
teoriche
0,0375
1
-1,45386734
0,07
0,07
0-1
0,5
1-2
1,5
4.500
0,05625
2
-1,30330503
0,10
0,02
2-3
2,5
5.000
0,0625
3
-1,15274271
0,13
0,03
3-5
4
12.000
0,15
5
-0,92689924
0,18
0,05
5-10
7,5
20.000
0,25
10
-0,39993115
0,34
0,17
10-15
12,5
15.500
0,19375
15
0,352880423
0,64
0,29
15-25
20
20.000
0,25
25
1,482097776
0,93
0,29
oltre 25
Totale
65
0
0
65
8,257401893
1
0,07
80.000
1
3.000
1,00
Media=10,16 Varianza =44,11 β1=0,35 β2=1,76
Classi di ore
di assenza
mensili
0-5
5-10
10-15
15-20
20-25
25-30
30-35
Totale
valori
centrali
Operai
2,5
1.000
4.500
10.000
12.000
10.000
4.000
1.000
42.500
7,5
12,5
17,5
22,5
27,5
32,5
Freq. Rel.
Estr. sup.
z
P(Z<z)
Frequenze
relative
teoriche
0,0125
5
-2,28718233
0,01
0,01
0,05625
10
-1,51876139
0,07
0,06
0,125
15
-0,75034045
0,23
0,16
0,15
20
0,018080493
0,51
0,28
0,125
25
0,786501433
0,79
0,28
0,05
30
1,554922374
0,94
0,15
0,0125
35
2,323343315
0,99
0,05
0,53125
0,99
Media=17,38 Varianza =42,34 β1=0,011 β2=2,61
67
Quoziente di Lexis
Quando una serie di n prove indipendenti riguardanti un evento E viene ripetuta N
volte, si possono distinguere i tre casi:
1) Schema di Bernoulli- la probabilità p dell’evento E si mantiene costante in ogni
prova di qualunque serie;
Serie
1
2
…
j
…
N
1°
p
p
…
p
…
p
E (U 2 )
Prove
i°
…
p
…
p
…
…
…
p
…
…
…
p
…
2°
p
p
…
p
…
p
2
= σb = npq
…
…
…
…
…
…
…
n°
p
p
…
p
…
p
2) Schema di Poisson- la probabilità dell’evento varia nelle n prove di ciascuna serie
secondo una legge che si ripete immutata nelle serie successive
Serie
1
2
…
j
…
N
Prove
i° …
1°
2°
…
pi
p1
p2
…
…
pi
p1
p2
…
…
…
…
…
…
…
pi
p1
p2
…
…
…
…
…
…
…
pi
p1
p2
…
…
2
2
2
E (U ) = σP = npq -n σp
n°
pn
pn
…
pn
…
pn
3) Schema di Lexis – la probabilità dell’evento si mantiene costante nelle prove di
una stessa serie ma varia da una serie all’altra
Serie
1
2
…
j
…
N
E (U 2 )
N.B.
Prove
i° …
1°
2°
…
p1
p1
p1
p1
p1
p2
p2
p2
p2
p2
…
…
…
…
…
pj
pj
pj
pj
pj
…
…
…
…
…
pn
pn
pn
pn
pn
2
2
= σ L = npq+n(n-1)σ p
n°
p1
p2
…
pj
…
pn
p = probabilità media di successo dell’evento in una prova;
σ p 2 =varian za dell e probabilità nel com plesso delle n*N prove
X j = n. di successi nella j-esim a serie di n prove
N
⎡
⎤
1
2
2⎥
⎢
E (U ) = E
( X j − np)
⎢N
⎥
⎢⎣
⎥⎦
j =1
∑
68
σ (scarto quadratico medio osservato) rappresenta una stima di E(U2)
σ b ( √ npq calcolato sui dati osservati) r a p p r e s e n t a u n a s t i m a d i
E(U2)qualora
i dati fossero conformi allo schema di Bernoulli
Q=
σ
σ
=
σb
npq
Q= 1 se i dat i so no c o nfo r mi a llo sc he ma d i Be r no ull i
Q< 1 s e i dat i s o no c o nfo r mi a llo s c he ma d i P o is s o n
Q> 1 se i dat i so no c o nfo r mi a llo sc he ma d i Le xis
Esempio quoziente di Lexis
x = successi
0
1
2
3
4
5
6
7
8
9
10
Totali
y = serie di prove
20
40
36
54
50
60
22
34
10
20
10
356
356,97
415,95
178,18
81,00
2,52
36,06
69,34
261,87
142,53
456,07
333,54
2334,02
x = 4, 22
n = 10 ( prove in ogni serie)
p =
Dati conformi allo schema di Lexis
( x − x) 2 y
xy
0
40
72
162
200
300
132
238
80
180
100
1504
Q =
x
= 0,42
n
σ
npq
σ 2 = 6,56
npq = 2,44
= 1,64
69
A d a t t a me n t o b i n o m i a l e
x = np
σ 2 = npq
q=
σ2
x
p = 1− q = 1−
σ2
x
=
x −σ 2
x
2
x
x
x
n= =
=
p x −σ 2 x −σ 2
x
se x > σ 2 → distribuzione binomiale
se x < σ 2 → distribuzione binomiale negativa
se x = σ 2 esponenziale di Poisson
70
D i s t r i b u z i o n e b i n o mi a l e n e g a t i v a
1
q'
n = − n'
q=
q' =
x
1
= 2
q σ
n' = − n =
x
2
σ2 −x
σ2 −x
p' = 1 − q ' =
σ2
p = 1− q = 1−
1
p'
=−
q'
q'
(q + p ) n = (
1 p' −n'
− )
q' q'
∞
⎛ − n' ⎞ x
⎟⎟ p'
(1 − p' )− n' = ∑ ( −1) x ⎜⎜
x =0
⎝ x⎠
∞
⎛ n' + x − 1 ⎞ x n'
1
−n'
⎜⎜
⎟⎟ p' q'
−
=
(
1
p
'
)
∑
q'−n'
x
x =0 ⎝
⎠
⎛ n '+ x − 1⎞ x n '
⎟⎟ p ' q '
Px = ⎜⎜
x
⎝
⎠
µ 0,1 =
n' p '
q'
µ2 =
n' p'
q'2
71
Distribuzione binomiale negativa
0,12
0,6
0,1
0,5
0,08
0,4
n=30 p=0,1
0,06
Px
Px
Distribuzione binomiale negativa
0,04
0,2
0,02
0,1
0
0
0
20
40
n=30 p=0,5
0,3
0
20
40
Esempio adattamento binomiale negativa
Distribuzione di alcune aree abitate secondo il numero di
extracomunitari
X
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Totali
parametri
Momenti
Y
97
41
23
23
8
10
8
4
1
5
2
1
0
1
1
0
1
226
f(x)
95,73
43,16
26,32
17,45
12,03
8,49
6,07
4,40
3,21
2,35
1,73
1,28
0,95
0,70
0,53
0,40
1,20
226
n’ =0,65
p’=0,015
χ2
0,02
0,11
0,42
1,77
1,35
0,27
0,61
0,04
1,52
2,99
0,04
0,06
0,95
0,13
0,42
0,40
0,03
11,12
µ =1,95
σ2= 7,75
n’ =µ2 / (σ2 −µ)
p’= (σ2 − µ)/ σ2
72
Esponenziale di Poisson
θ = np finito
p→0
n→∞
Pn, x
n( n − 1)(n − 2)...( n − x + 1) θ x
θ n− x
=
( ) (1 − )
x!
n
n
θ e −θ
x
lim Pn , x = Px =
x!
n→∞
n( n − 1)(n − 2)...(n − x + 1)
=1
n
n→∞
lim
θ
lim(1 − ) − x = 1
n
n→∞
θ
lim((1 − ) n = e −θ
n
n→∞
θ e −θ
x
Px =
x!
73
Di stribuzione di Poisson
0,4
0,35
0,3
Pn
0,25
p=0,1 media =1
0,2
0,15
0,1
0,05
0
0
5
10
15
Distribuzione di Poisson
0,25
0,2
0,15
Pn
p=0,1 media =3
0,1
0,05
0
0
20
40
Distribuzione di Poisson
0,14
0,12
0,1
0,08
Pn
p=0,1 media =10
0,06
0,04
0,02
0
0
50
100
150
74
Formule ricorrenti
Distribuzione binomiale
Pn , x +1 =
n−x p
Pn , x
x +1 q
Distribuzione binomiale negativa
P0 = q'n '
Px +1 =
n'+ x
p' Px
x +1
Esponenziale di Poisson
P0 = e −θ
Px +1 =
θ
x +1
Px
75
Esempio adattamento Esponenziale di Poisson
Distribuzione di alcune aree abitate secondo il numero di
extracomunitari
X
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Totali
parametri
Momenti
Y
1
1
3
6
13
21
28
30
31
29
26
15
10
5
4
2
1
226
f(x)
0,076
0,607
2,426
6,470
12,939
20,702
27,603
31,547
31,547
28,041
22,433
16,315
10,877
6,693
3,825
2,040
1,020
225,160
χ2
11,27
0,26
0,14
0,03
0,00
0,00
0,01
0,08
0,01
0,03
0,57
0,11
0,07
0,43
0,01
0,00
0,00
13,00
µ =θ
µ =7,88
σ2= 7,81
76