Perché il calcolo della
probabilità e la statistica ?
Abbiamo visto al I semestre che , se l’errore
di sensibilità lo consente, misure ripetute
della stessa grandezza fisica nelle stesse
condizioni presentano una dispersione di
valori.
In queste condizioni non è possibile
prevedere quale sarà il risultato di una singola
misura: diremo che esso è una variabile
casuale che ha una certa distribuzione di
frequenza,
visibile ad esempio con un
istogramma.
L’elaborazione dei dati sperimentali richiede
la conoscenza di specifici strumenti forniti
dalla statistica, la quale a sua volta fa uso del
calcolo della probabilità.
Per questo motivo cominciamo ad occuparci
del calcolo della probabilità, senza
dimenticare che questo è un corso di
Laboratorio di Fisica e non di Statistica.
Inizio della storia ( per quanto ne
sappiamo… )
Nel 1654 il nobile Antoine Gombaud ( noto
come Chevalier de Méré e accanito giocatore
) pone a Blaise Pascal e a Pierre de Fermat
questa domanda : è più probabile ottenere
almeno un 6 lanciando quattro volte un dado
o ottenere almeno un 12 lanciando 24 volte
due dadi ? I due rispondono al quesito e da
quel momento possiamo dire che sia nato il
calcolo delle probabilità, almeno nel mondo
occidentale.
Cerchiamo di precisare la nozione di
probabilità, partendo dalla definizione
classica, dovuta a Pierre Simon Laplace nel
1812.
La probabilità di evento in un esperimento è
data dal rapporto fra il numero dei casi
favorevoli e il numero dei casi possibili.
Se il numero di casi favorevoli è zero, la
probabilità è zero; se il numero dei casi
favorevoli è pari al numero dei casi possibili,
la probabilità vale 1.
Lanciando in aria una moneta non truccata
avremo la probabilità ½ di avere testa e ½ di
avere croce.
Se viene lanciata 10 volte una moneta
ottenendo sempre testa, all’11-mo lancio
conviene puntare sul simbolo “in ritardo”,
ossia croce ? No, la probabilità di ottenere
ancora testa resta sempre ½.
Nascono problemi con questa definizione di
probabilità.
Consideriamo il lancio di due monete : qual è
la probabilità dell’uscita di 2 teste ? Ci sono
due ragionamenti possibili. Il primo ci dice
che la probabilità di due teste è ¼ poiché i
casi possibili sono 4 ( TT, CC, TC, CT ). Il
secondo ci dice che la probabilità di due teste
è 1/3 , poiché i casi possibili sono due teste,
due croci, una testa e una croce.
I due risultati sono in disaccordo : quale dei
due ragionamenti è corretto ? Il primo, anche
se anche lo stesso Jean Baptiste Le Rond
d’Alembert era fautore del secondo. Il punto è
che il secondo ragionamento crea uno
squilibrio fra i casi possibili, perché TC e CT
“pesano” il doppio rispetto a TT e CC.
Occorre rivedere la definizione di probabilità.
La probabilità di evento in un esperimento è
data dal rapporto fra il numero dei casi
favorevoli e il numero dei casi possibili,
purché essi siano equiprobabili.
Si cade quindi in un circolo vizioso.
Definizione frequentistica di
probabilità ( John Venn, 1866)
È simile alla definizione classica, ma
sostituisce al rapporto numero dei casi
favorevoli/numero dei casi possibili il
rapporto numero di esperimenti effettuati con
esito favorevole/ numero di esperimenti
effettuati.
Un ragionamento “ a priori” tutto teorico
viene sostituito da una valutazione “ a
posteriori” basata sull’esperienza.
Viene
assunta quindi come probabilità che un
evento si verifichi la frequenza relativa con
cui si presenta in condizioni analoghe.
Un esempio in cui la definizione classica non
è d’aiuto.
Qual è la probabilità che il primo dell’anno
2014 sia una giornata piovosa a Napoli?
Se consultando i bollettini meteorologici degli
ultimi 30 anni si scopre ad esempio che abbia
piovuto 18 volte, diremo che la probabilità di
avere un giorno di pioggia il primo gennaio
2014 sarà pari a 18/30, ossia del 60%.
Ma qual è il numero di prove che bisogna
effettuare per avere una stima affidabile della
probabilità ? L’intuizione ci suggerisce che
più grande è il numero di prove più affidabile
è la stima della probabilità, ma resta una
margine di vaghezza. Per questo motivo, nei
casi in cui possiamo usare la definizione
classica ( come nel lancio di una moneta ) si
ricorre al ragionamento “a priori”, senza ad
esempio lanciare 800 volte una moneta e
ottenere che la probabilità di ottenere testa sia
di 413/800 solo perché è uscita testa 413
volte.
In termini matematici possiamo dire che la
probabilità che si verifichi un evento è pari al
limite della frequenza relativa quando il
numero delle prove tende ad ∞.
Definizione soggettivistica (
Frank Plumpton Ramsey, Bruno
de Finetti, anni 1926-1930)
Ci sono casi in cui nessuna delle due
precedenti definizioni di probabilità sono
d’aiuto, specialmente quando ci occupiamo di
eventi non ripetibili.
In un librettino non facilmente reperibile di
Giuliano Spirito dal titolo “Matematica
dell’incertezza” c’è il seguente esempio che
può aiutare a capire.
Supponiamo che lo studente Alessio
scommetta 3 contro 1 ( se perde pagherà 3, se
vince incassa 1) che sia corretta la soluzione
da lui data ad un certo problema. Per Alessio
ci sono tre possibilità che la soluzione sia
giusta contro una che la soluzione sia
sbagliata, come succede nel caso di un
sorteggio da un’urna, contenente 3 palline
rosse ( soluzione giusta) e 1 nera (soluzione
sbagliata). In conclusione Alessio sta dando
una valutazione ( soggettiva ) di probabilità
e attribuisce una probabilità ¾ ( 75%) al
realizzarsi dell’evento soluzione giusta.
Tutte e tre le definizioni non sono quindi in
generale soddisfacenti. Tuttavia esiste una
teoria assiomatica ( dovuta ad Andrej
Nikolaevič Kolmogorov nel 1933) che cerca
di fornire una base teorica comune.
Sia S l’insieme di tutte le possibili modalità di
un fenomeno e A e B due sottoinsiemi di S. Si
definisce probabilità un numero reale tale che
a) P(A) ≥ 0
b) P(A U B) = P(A) + P(B) se A∩ B = Ø
c) P(S) = 1
dove con A U B si indica il sottoinsieme di
modalità che appartengono o ad A oppure a
B, con A ∩ B il sottoinsieme di modalità che
appartengono sia ad A sia a B ed infine con Ø
l’insieme vuoto.
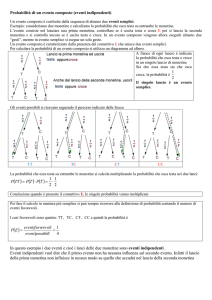
I diagrammi di Venn, illustrati in figura,
aiutano a capire Ā, il complemento di A,
l’unione A U B e l’intersezione A ∩ B.
In particolare si può vedere che
P(A U B) = P(A) + P(B) – P(A ∩ B)
( si evita di contare due volte gli eventi in
comune ad A e B ). Tale regola è nota come
regola di addizione per le probabilità. Se i
sottoinsiemi A e B sono mutuamente
esclusivi ( ossia se i cerchi in figura non
hanno punti in comune ) A∩ B = Ø e P(A ∩
B) = 0.
Se B = Ā, AUĀ= S e A∩Ā = Ø, per cui
P(S) = P(AUĀ) = P(A) +P(Ā) = 1.
Un altro concetto importante è quello di
probabilità condizionale ( chiamata anche
probabilità condizionata). Si scrive P(B│A)
ed esprime la probabilità che si verifichi
l’evento B sotto la condizione che si sia
verificato l’evento A. Si intuisce che la
probabilità condizionale ha qualcosa in
comune con A ∩ B ed infatti per definizione
P (A ∩ B ) = P(B│A) P(A)= P(A│B) P(B)
Quindi:
P(B│A)= P (A ∩ B ) /P(A)
P(A│B)= P (A ∩ B ) /P(B)
Che succede se il verificarsi dell’evento B
non dipende dal precedente verificarsi
dell’evento A ?
Si dice che A e B sono indipendenti fra di
loro e
P (A ∩ B ) = P(B) P(A)= P(A) P(B)
che è la regola di moltiplicazione degli eventi
indipendenti.
Possiamo adesso sapere qual è la probabilità
di ottenere un 12 nel lancio di due dadi.
Per avere un 12 è necessario che nel lancio
del primo dado esca un 6 ( evento A con
probabilità 1/6 ) e che nel lancio del secondo
dado esca ancora un 6 ( evento B con
probabilità 1/6). Ottenere un 12 è
l’intersezione degli eventi A e B, che sono
indipendenti fra di loro, sicché la probabilità
di ottenere un 12 nel lancio di due dadi è
1/6x1/6, ossia 1/36.
E la risposta ad Antoine Gombaud ?
Eccola finalmente.
Qual è la probabilità di ottenere almeno un 6
lanciando 4 volte un dado ? Conviene
introdurre l’evento complementare, ossia
quello di non ottenere nessun 6 in 4 lanci.
Calcoliamo la probabilità di questo ultimo
evento: occorre che non esca nessun 6 nel
primo lancio ( probabilità 5/6), nessun 6 nel
secondo lancio ( probabilità 5/6) e così via.
La probabilità di non ottenere nessun 6 in
quattro lanci è quindi uguale a
5/6x5/6x5/6x5/6 = 625/1296 = ~ 48%
per cui la probabilità che non esca almeno un
6 e circa il 52%.
Qual è la probabilità che lanciando 24 volte
due dadi si ottenga almeno un 12 ? L’evento
complementare a questo è che non esca
nessun 12 in 24 lanci.
Abbiamo visto che la probabilità che esca 12
in un lancio è 1/36. La probabilità che non
esca nessun 12 in un lancio è allora 35/36 e la
probabilità di non ottenere nessun 12 in 24
lanci è 35/36 elevato alla 24, che vale circa
49%. Quindi la probabilità che lanciando 24
volte due dadi si ottenga almeno un 12 è circa
il 51% .
Conclusione : è più facile ( sia pure di poco )
ottenere un 6 in 4 lanci di un dado che 12 in
24 lanci di due dadi.
Il calcolo della probabilità e le
“coincidenze”
C’è un largo convincimento che le
coincidenze di eventi siano altamente
improbabili e che il loro verificarsi richiedano
giustificazioni esterne al fatto in sé. Sentiamo
dire spesso “non può trattarsi di una semplice
coincidenza” ma è vero ?
Facciamo un esempio.
In una stanza ci sono 5 persone e si scopre
che di 2 di loro sono nati nello stesso mese :
è una coincidenza imprevedibile e
significativa ? Vediamo.
Cominciamo a calcolare la probabilità
dell’evento complesso mesi tutti diversi, che
consiste nel fatto che il mese della seconda
persona sia diverso dal mese della prima e
che il mese della terza persona sia diversa dai
mesi delle prime due e che il mese della
quarta sia diverso da quello delle prime tre e
il mese della quinta sia diverso da quello delle
prime quattro. Questa probabilità vale
11/12x10/12x9/12x8/12
ossia 7920/20736=55/144.
Ma l’evento mesi tutti diversi è l’evento
complementare dell’evento atteso ( almeno
due mesi uguali) , che ha quindi una
probabilità di verificarsi pari a 89/144, ossia
circa il 62% , probabilità per nulla piccola.
Distribuzioni di probabilità
Una variabile casuale X è una grandezza di
cui non si può prevedere con certezza il
valore osservato. Si ha solo una legge di
probabilità.
Tale variabile può essere discreta, se può
assumere solo un numero finito di valori xi(
ad esempio gli esiti del lancio di un dado,
l’altezza degli studenti presenti in aula, etc..).
Avremo allora che P( X = xi ) = Pi .
Possiamo definire una funzione di
distribuzione cumulativa F(xi ) come la
somma di tutte le Pj , con l’indice j che varia
fra 1 e i.
Possiamo definire un valore aspettato di x, il
cui simbolo può essere E(x) dall’inglese
expectation value oppure da <x>:
E(x) = ∑j Pj xj
con l’indice j che assume tutti i possibili
valori.
La variabile può essere continua. Avremo
allora che
P ( x ≤ X ≤ x + dx ) = f(x) dx
dove f(x) è la p.d.f. di x, ossia la funzione
densità di probabilità( p.d.f. in inglese sta per
probability density function). L’integrale di
f(x) dx, esteso a Ω, l’insieme di definizione
delle x, deve valere 1, poiché la probabilità
totale che la variabile x assuma un certo
valore in Ω deve valere 1.
Se Ω è l’intervallo [a,b], l’integrale di f(x’)
dx’fra a e x viene chiamato funzione di
distribuzione cumulativa:
( )
∫
( )
F(x) vale 0 se x=a e vale 1 se x=b.
Possiamo definire ancora un valore aspettato
di x, come
( )
∫
( )
Da notare che la mediana della funzione
densità di probabilità viene definita come
quel valore di x per cui F(x) =1/2.
Il valore atteso è un caso particolare dei
momenti di ordine k ( con k intero positivo)
intorno a x0 .
μk (x0 ) = E [(x- x0 )k ]
che vale ∑j Pj (xj - x0 ) k nel caso discreto e
vale ∫ (
) ( )
nel caso continuo.
Se x0 = 0, i momenti si intendono definiti
intorno all’origine.
Quindi μ1 (0 ) = E(x) = μ. Questa grandezza
viene chiamata anche valore medio o media
della distribuzione.
Il secondo momento intorno a μ, ossia
μ2 (μ ) = E [(x- μ )2 ]
viene chiamato varianza della distribuzione,
che solitamente viene indicata col simbolo σ².
La quantità σ è detta deviazione standard.
La varianza dà informazioni sulla larghezza
della distribuzione intorno al suo valore
medio, cosa che non può fare E (x- μ ) perché
è uguale a zero.
Si può vedere che
σ² = E(x² ) - μ², per cui
E(x² ) = σ² + μ².
Si può vedere anche che
E [(x- μ )2 ] = E(x² ) – [E(x)]²
La quantità β, definita come il rapporto fra
E [(x- μ )3 ] e σ², è il coefficiente di
asimmetria ( skewness ) perché è
caratteristica delle funzioni di distribuzione di
probabilità non simmetriche rispetto al valore
medio. Se β è positiva o negativa, la
distribuzione è più estesa a destra o a sinistra
di μ.
Possono essere definiti altri coefficienti,
legati ai momenti di ordine superiore ma noi
non ne parleremo in questo corso di
laboratorio.
Diseguaglianza di BienayméČebičev
Sia g(x) una funzione non negativa della
variabile casuale x con p.d.f. f(x) e varianza
σ² . Si può dimostrare che, se esiste E(g(x)),
allora P(g(x) ≥ c) ≤ 1/c E(g(x)) dove c è una
costante qualunque.
Se in particolare g(x) è uguale a ( x-E(x))² si
ricava che
P[ (│x-E(x) │≥ λσ ] ≤ 1/λ²
che è chiamata diseguaglianza di BienayméČebičev.
Se λ=1, si ha un risultato banale ma al
crescere di λ diventa sempre più piccola la
probabilità di trovare grossi scarti dalla media
μ.
Densità di probabilità congiunta
di N variabili.
Finora abbiamo considerato il caso in cui la
p.d.f. dipenda da una sola variabile casuale.
L’estensione a diverse variabili x1, x2, … x n
consiste nel considerare la funzione di densità
di probabilità congiunta f(x1, x2, … x n), che
supporremo positiva, che assuma un singolo
valore in ogni punto (x1, x2, … x n ) di uno
spazio Ω a n dimensioni e che sia
normalizzata opportunamente.
∫ f(x1, x2, … x n) dx1 dx2 …. dxn = 1.
Possiamo ancora sfruttare quanto abbiamo
introdotto nel caso che n=1.
In particolare
μi =E( xi ) = ∫ xi f(x1, x2,.. x n) dx1 dx2 ..dxn .
Possiamo anche introdurre la matrice delle
covarianze Vij = E[ (xi - μi )(xj - μj ).
Questa matrice è molto importante per i fisici.
Essa è simmetrica : Vij = Vji .
Gli elementi della diagonale principale sono
le varianze.
Un elemento fuori diagonale principale Vij
con i ≠ j è chiamato covarianza di xi e xj ed è
denotato col simbolo cov(xi , xj ).
Viene introdotto anche il coefficiente di
correlazione ρ(xi , xj ), definito da
ρ(xi , xj )= cov(xi , xj ) / σi σj
e che è compreso fra +1 e -1.
Se ρ(xi , xj ) = +1 (-1), xi e xj sono
completamente correlate positivamente (
negativamente). Se ρ(xi , xj ) = 0, xi e xj sono
scorrelate.
Propagazione delle varianze,
conosciuta come propagazione
degli errori.
Siano x1, x2, … x n n variabili casuali e
poniamo
( , ,… )=y( )
Supponiamo inoltre nota la matrice delle
covarianze delle x e vogliamo determinare la
varianza di y.
Se facciamo uno sviluppo in serie di Taylor,
bloccata al primo ordine, intorno al valore
=( , ,…
di (x1, x2, … x n ), abbiamo
y ( ) = y( ) + ∑ (
)
-
)
più termini di ordine superiore e dove la
derivata è calcolata in = .
Il valore atteso di questa espressione vale
{ ( )}
( )
più termini di ordine superiore, poiché ogni
termine del primo ordine vale zero.
Solo nel caso in cui le quantità ( xi – μi )
siano piccole, i termini di ordine superiore
possono essere trascurati.
A questo punto si può ottenere la varianza di
y.
V{ (
)}=E{ ( )
[ ( )]}2
{ ( )
( )}
Per quanto detto prima, sempre trascurando i
termini di ordine superiore, si ha che
V{ (
∑
)}
∑
( )
dove le derivate sono calcolate in
=
.
Per n variabili indipendenti tutti i termini di
covarianza sono zero e la varianza di y vale
V{ (
)}
∑
(
)²
(
)
Un esempio.
Consideriamo la media aritmetica di n
variabili indipendenti x1, x2, … x n aventi tutti
la stessa varianza σ²:
̅= ∑
Le derivate parziali di y rispetto ad ogni xi
valgono 1/n e le derivate di ordine più alto
sono nulle.
Ne consegue, senza nessuna approssimazione
che la varianza della media aritmetica vale
( ̅)=∑
(
)² σ²
²
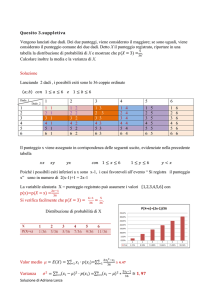
Campione e popolazione
Una funzione di densità di probabilità f(x) per
una variabile continua o, equivalentemente,
un insieme di probabilità nel caso discreto
descrivono le proprietà di una popolazione. In
fisica si associa una variabile casuale all’esito
di una osservazione e la p.d.f. f(x)
descriverebbe l’esito di tutte le possibili
misure su un sistema se le misure fossero
ripetute infinite volte nelle stesse condizioni
sperimentali. Poiché ciò è impossibile, il
concetto di popolazione per un fisico
rappresenta un'idealizzazione che non può
essere ottenuta nella pratica.
Un reale esperimento consiste di un numero
finito di osservazioni e una successione x1, x2,
… xn di una certa quantità costituisce un
campione di dimensione n. Per questo
campione possiamo definire la media
aritmetica o media del campione
̅= ∑
e la varianza del campione
∑ (
=
- ̅ )²
la cui distribuzione dipenderà dalla
distribuzione parente e dalla dimensione del
campione Le due quantità sono funzioni di
variabili casuali e sono anche esse variabili
casuali. Infatti se prendiamo un nuovo
campione di dimensione n otterremo in
generale una nuova media aritmetica e una
nuova varianza : ossia queste grandezze
avranno una loro distribuzione, che dipenderà
dalle proprietà della distribuzione “parente” e
dalla dimensione n del campione.
Il nostro obiettivo è adesso come ricavare, a
partire dalle informazioni che ricaviamo da
un campione, informazioni che riguardano
l’intera
popolazione.
Naturalmente
il
campione deve essere rappresentativo della
popolazione, altrimenti, come accade spesso
nei sondaggi, si ottengono risultati sbagliati.
Per la legge dei grandi numeri la media del
campione tende alla media della popolazione
al tendere di n all’infinito.
Infatti questa legge ( nella forma debole )
prevede che, dato un intero positivo ε, la
probabilità che la media del campione
differisca da μ di una quantità maggiore di ε
tende a zero nel limite di n infinito :
(
̅
Si può anche dimostrare che il valore atteso
della media del campione coincide con la
media della popolazione e che il valore atteso
di s2 coincide con σ2 .
Se il nostro campione è costituito da n coppie
( xi, yi) di valori di due grandezze casuali x e
y, si può definire la covarianza del campione
come
∑ (
Cov (x,y ) =
̅ )(
̅)
In questa espressione ̅ e ̅ sono le medie
aritmetiche del campione delle x e delle y
rispettivamente. Si può allora dimostrare che
il valore atteso della covarianza del campione
coincide con la covarianza della popolazione
delle x e y.