Alessandro Reina
Laura Sorgiacomo
Paolo Rotta
1
“Anyone who has never made a mistake has never tried anything new.”
[Albert Einstein]
2
Indice
04-10-2004
08-10-2004
11-10-2004
15-10-2004
18-10-2004
22-10-2004
25-10-2004
29-10-2004
05-11-2004
08-11-2004
12-11-2004
15-11-2004
19-11-2004
22-11-2004
26-11-2004
29-11-2004
03-12-2004
10-12-2004
13-12-2004
17-12-2004
20-12-2004
10-01-2005
14-01-2005
17-01-2005
21-01-2005
24-01-2005
4
6
8
11
15
18
22
26
29
34
34
38
41
46
51
55
58
63
68
74
77
80
83
87
91
95
3
4-10-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Gnedenko 1931
Il Calcolo della probabilità è quel ramo della matematica che si occupa di modelli
matematici, di fenomeni casuali aventi la proprietà della stabilità della frequenza.
I fenomeni casuali sono quei fenomeni con i quali si possono ottenere risultati differenti a
parità di condizioni iniziali.
I fenomeni deterministici sono quei fenomeni che grazie alla conoscienza delle condizioni
iniziali determinano l’evoluzione futura del sistema.
Ripasso sugli insiemi
Differenza simmetria, A B , corrisponde agli elementi che
appartengono sia ad A che a B ma non a tutti e due.
A B = (A
A
B)
B )C
(A
B
La cardinalità di un insieme è il numero degli elementi dell’insieme stesso.
Dato un insieme A indicheremo la sua cardinalità con la notazione A .
A = {a, b, c}
A =3
L’insieme delle parti di un insieme è costituito da tutti i sottoinsiemi dello stesso
insieme.Per ogni insieme B , l’insieme delle sue parti sarà ( B ) = 2 B
Nell’esempio si prima:
( A) ={{a, b, c} , {a, b} , {a, c} , {b, c} , {a} , {b} , {c} , {
La cardinalità dell’insieme delle parti di A è:
P( A) = 23 = 8
Il prodotto cartesiano è:
C = A× B
A × B = {( , )
A,
B}
4
}}
Ad esempio dati gli insiemi seguenti:
A = {c, d }
B = {7, 42}
Il prodotto cartesiano è:
A × B = {(c,7), (c, 42), (d , 7), (d , 42)}
Cardinalità del prodotto cartesiano:
Se A = n
e B =m
allora
A × B = nm
A × B = 2* 2 = 4
definizione di coppia ordinata:
(a, b) ={{a} , {a, b}}
(b, a) = {{b} , {a, b}}
Tips: Notare bene l’ordine lessicografico!!!
Ovvero data la coppia ordinata
(a, b)
Il suo insieme è esso stesso un insieme i cui elementi sono gli insiemi di {a, b} ed {a} .
{a, b} ovviamente è diversa da {b, a}
che è l’insieme degli elementi su {b, a} e {b} .
5
8-10-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Secondo il nostro “linguaggio naturale” il concetto di funzione può essere espresso nel
modo seguente:
Una funzione f è una regola che associa ad ogni elemento di un insieme di partenza A uno
e uno solo punto di un insieme di arrivo B. L’insieme di partenza A viene chiamata dominio
mentre l’insieme di arrivo B è chiamato codominio.
In termini matematici si può rappresentare come di seguito:
f
A B
( x
A) !( y
B ) : ( x, y )
f
Una funzione f con dominio A e codominio B, è una collezione di coppie ordinate (x,y),
con x appartenente ad A e y appartenente a B, dove ogni elemento dell’insieme A appare
come primo elemento di una coppia ordinata. Non esistono due coppie ordinate che
abbiano lo stesso primo elemento.
Esempio 1.
Determinare la funzione che descrive l’area di un rettangolo.
y
1
A (insieme ambiente)
b2
R
a2
a1
b1
1
x
R= (a1 , b1 ) × (a2 , b)
f :R
A
(b1 a1 )(b2 a2 )
Base
Altezza
Area
6
Modello Kolmogoroviano
Uno spazio di probabilità è una terna ordinata formata da:
( , , P)
= spazio campionario oppure insieme degli esiti
= insieme degli eventi (un evento è una proprietà di interesse)
P = funzione di probabilità
Consideriamo:
Spazio campionario:
Insieme degli eventi:
( )
A
Ac
A
,B
(A
Esempio:
= { A, Ac , , }
B)
Funzione di probabilità:
P:
( × )
P
P( ) = 1 evento certo
A
P ( A) 0
7
11-10-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Articolo I.
Articolo II.
Ripresa del modello Kolmogoroviano
Definizione: è una tripletta ( , , p ) ,dove
è uno spazio campionario, è una collezione
di eventi e p è una funzione di probabilità con dominio (vedere lezione del 8\10)
Esempio 1:
M = {nomi di tutti i cittadini di Milano}
Dati due insiemi
A = numero di cittadini favorevoli a un partito
B = numero di cittadini non favorevoli.
Indichiamo con :
P(A) la probabilità che per la prima estrazione abbia un cittadino favorevole ad un partito;
P(B) la probabilità che per la prima estrazione abbia un cittadino non favorevole.
Poniamo:
A
Ac
P ( A)
0
= { A, Ac , ,
}
rappresenta i milanesi che non sono milanesi
nuove proprietà:
A
,B
A B
P(A
( )
c
A e B sono proprietà di interesse perché appartengono a
B ) = P ( A ) + P ( B ) se A
B=
cioè se sono mutuamente esclusivi
Quindi per calcolare la probabilità che si verificano entrambi gli eventi si deve sommare la
probabilità che si verifichi A con la probabilità che si verifichi B.
Per cercare di capire meglio l’ ultima proprietà scritta facciamo un ulteriore esempio:
Esempio 2:
Prendiamo un dado e lo lanciamo solo una volta.
Alessandro scommette sui pari (P(A)) e Laura scommette sui dispari(P(B))
A = {2, 4, 6}
B = {1,3,5}
= {Tutte le facce del dado con rispettivi numeri}
ovvero: = {1, 2,3, 4,5, 6, 7}
= { A, AC = B, ,
P(
) =1
P( ) = 0
C
=
}
scommetto che con un lancio possa uscire 1 o 2 …6
scommetto che esca 7
scommettere che esca pari ( P( A) ), significa che ho 3 possibilità sul totale (=6) ;
scommettere che esca dispari ( P ( B ) ) , significa che ho ancora 3 possibilità sul totale;
8
scommettere che mi esca pari o dispari ( P ( A
Ipotesi:
A
B
A B=
B ) ) , significa sommare le due probabilità.
i due insiemi devono essere disgiunti ovvero mutuamente esclusivi
Tesi:
P ( A B ) = P ( A) + P ( B )
IMPORTANTE: visto che la probabilità dell’evento certo( P (
dell’evento nullo( P (
fra 0 e 1 compresi.
) )=1 e visto che la probabilità
) )=0, allora la funzione di probabilità sarà compreso
Sezione 2.01 Altri esempi:
Esempio 3:
P( ) = 1
Dimostriamo che P( ) = 0
Poniamo:
A=
B=
Per l’assioma:
P( A B) = P( A) + P( B)
A B=
A
,B
Quindi:
P( A B) = P( A) + P( B) =
P( ) + P( ) = P( ) = 0
Esempio 4:
= {1, 2,3, 4,5, 6}
A = {2, 4, 6}
B = {4,6}
9
in un intervallo
B
A
P (B)
Ogni esito che soddisfa la probabilità B soddisfa anche la A
P ( A)
(A
A= B
(
Bc )
(A
P ( A) = P B
A
Bc = A
B
A=B
Bc )
)
Ciò che ci manca è dimostrare che:
A B
Ipotesi:
A
B
Tesi:
A B
Dimostrazione:
A
B=
(( A
B)
) =(A
c c
c
Bc ) = A
c
B
Cosa succede se A e B non sono disgiunti?
Cioè se A B
Ipotesi:
A
B
Tesi:
P ( A B ) = P ( A) + P ( B ) P ( A
B)
Dimostrazione:
A
B=A
P(A
B=B
(B
Ac )
B ) = P ( A) + P ( B
=B
P (B) = P ( B
(A
Ac )
Ac ) = ( B
A) + P ( B
A)
(B
Ac )
Ac )
P(B
Ac ) = P ( B ) P ( B
P(A
B ) = P ( A) + P ( B ) P ( B
A)
A)
10
15-10-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Ripasso veloce:
Modello Kolmogoroviano:
{ ,{
{
{
,
} ,{
, , P}}
} = spazio misurabile
, P} = spazio misurato
,
,
Ovvero: ( , , P )
1.
Ac
,A
,A
,B
(A
B)
2.
A
,B
(A
B)
3.
A
,B
A = (A
B)
(A
Bc )
4.
A
P( A) 0
P( ) = 1
A
,B
(A
B) =
P( A
B) = P( A) + P( B)
5.
P( ) = 0
6.
A
B
P( A)
P( B)
7.
A
0
P ( A) 1
11
8.
P( Ac ) = 1 P( A)
9.
P( A) = P( A B) + P( A
Bc )
10.
i j
Bi B j =
n
Bi =
i =1
P( A) = P( A
B1 ) + P( A
B2 ) + ... + P( A
Bn )
11.
A
,B
P ( A B ) = P ( A) + P ( B ) P ( A
Teorema del piastrellista
B)
( , , P)
1) che cosa significa? (“non siamo filosofi
”)
2) quali dati sperimentali devo raccogliere per assegnarla utilimente?
3) supposta assegnata che previsione fà?
Keyword: misurazione (ciò che si misura ad esempio in laboratorio, ...)
Variabile casuale: è una funzione definita su
a valori in
.
Esempio 1:
Definiamo una variabile che associa 1 sse il numero uscito laciando il dado è pari.
= {1, 2,3, 4,5, 6}
1
X ( w) =
0
{w
b
Se w è pari
altrimenti
:X ( w) = 1}
, {w
: X ( w) b}
12
Esempio 2:
Sia dato l’insieme rappresentante tutti i cittadini milanesi:
= {1, 2,3,..., n}
Voglio prendere un certificato a caso (esperimento casuale).
A
cittadini filogovernativi
c
A
cittadini non filogovernativi
c
B=A
L’insieme degli eventi sarà così costituito:
= { A, Ac , , }
Osserviamo l’insieme degli esiti in modo ordinato, evidenziando sulla sinistra i cittadini
filogovernativi mentre sulla destra i non filogovernativi.
= {1, 2,..., na , na +1 ,..., n}
Identifichiamo i cittadini filogovernativi:
1...na = n
Identifichiamo i cittadini non filogovernativi:
na +1...n = nb
Definiamo la variabile casuale che mi permette di sapere se ho avuto successo di trovare
cittadini filogovernativi, ricercando tra cittadini a caso:
I A ( x) =
1; x A
0; x A
1.{ x
: I A ( x) = 1} = A
A
2.{ x
: I A ( x) = 0} = Ac
Ac
3.{ x
: I A ( x) 17} =
Il numero 17 nel punto 3 non è sbagliato ,ma non ci serve perché in realtà sappiamo che i
valori possono essere solamente compresi tra 0 e 1.
13
b<0
{x
: I A ( x) b} =
0 b <1
{x
: I A ( x) b} = Ac
Ac
Poniamoci ora un’altra domanda:
E è funzione età
E:x
Numero di giorni intercorsi tra la sua nascita e una data fissata
{x
: E ( x) (40*365)} = Q
Q
A
Q
Q
Q
Ac
E’ una domanda ben posta ma Q non appartiene a nessun sottoinsieme di
Quindi E non è una variabile casuale ammissibile per il problema dato.
Posso dire anche che:
P( A) = P({ x
: I A ( x) = 1})
P( B) = P({ x
: I A ( x) = 0})
Formalizzando:
X:
si dice essere funzione utile o variabile casuale
b
{x
: X ( x) b}
14
.
18-10-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Si dice funzione di ripartizione di una variabile casuale X, quella funzione che ha per
dominio la retta reale e codominio l’intervallo [0,1]
e che soddisfa
FX ( x ) = P ( X
(
)
x ) = P {w : X ( w )
x} per ogni numero reale x.
( , )
X:
c
{w
: X ( w) c}
P( X
c) = P(" X
che possiamo scrivere come " X
c ") = P({w
: X ( w) c}) = FX (c)
Conoscendo FX possiamo rispondere a:
{w
: X ( w) b} = {w
a
P({w
P(a < X
: X ( w) a}
{w
: a < X ( w) b}
b
: a < X ( w) b}) = P({w
b) = P ( X
c"
b) P ( X
: X ( w) b}) P({w
a)
P(a < X
: X ( w) a})
b) = FX (b) FX (a)
Esercizio: proiezione delle votazioni elettorali
Supponiamo le seguenti condizioni:
- si vota in un solo seggio;
- votano n cittadini;
- si possono votare solo due partiti:
e ;
- non ci sono schede bianche o nulle;
- possiamo identificare il cittadino della scheda estratta.
Il partito
Il partito
ottiene n voti.
ottiene n voti, che coincide con n = n n .
Vogliamo sapere
n
n
n
e
che coincide con 1
.
n
n
n
15
Dopo aver mischiato bene l’urna elettorale, per dare un’equiprobabilità ad ogni scheda,
possiamo scegliere in modo arbitrario una scheda da estrarre nell’insieme degli esiti
possibili: 1 = {1, 2,..., n}
Avviene solo una estrazione
Gli eventi possibili sono dunque:
1
= ({1},{2},...,{n}) .
Il nostro spazio campionario è dunque: (
1
,
1
, P1 ???) .
Sapendo che A = {i1 , i2 ,..., i| A| } vogliamo calcolare P1 ( A) .
Se | A |= 0 allora P ( A) = 0 (evento impossibile).
Se A = n allora P ( A) = 1 (evento certo).
P1 ( A) = P1 ({i1 , i2 ,...i| A| }) = P1 ({i1} {i2 } ... {i| A| }) = P1 ({i1}) + P1 ({i2 }) + ... + P1 ({i| A| })
Essendo in condizioni di equiprobabilità:
P1 ({i1}) = P1 ({i2 }) = ... = P1 ({i| A| }) =| A | *P1 ({id }) con 1 < d <| A | , quindi | A | *
Considerando | A |= n , avremo n *
1
n
1
1
= 1 ; dove: la prima n è | A | e è P1 ({i}) con 1 i
n
n
n.
Ovvero il numero di palline totali moltiplicato la probabilità di un singolo evento (in
condizioni di equiprobabilità sono tutte uguali) .
Da questo ricaviamo che P1 ( A) =
| A|
|B|
e P1 ( B) =
.
n
n
| A|
è uguale alla concentrazione di schede per A contenute nell’urna che
n
A n
indicheremo con C quindi C =
=
.
n
n
|B|
Nello stesso modo
è uguale alla concentrazione di schede per B contenute nell’urna
n
B n
che indicheremo con C quindi C =
=
.
n
n
Notiamo che
Introduciamo la variabile casuale
con i
X 1 (i ) =
1.
Se X 1 =1 allora
1
se i
A
0
se i
B
ha almeno un voto, quindi sappiamo che C > 0 .
16
Consideriamo ora che vengano effettuate due estrazioni
(
2
=
2
= (
1
i
1
2
)
2
2
=
1
(
2
) =2
2
,
2
2
1
, P2 ???)
P2 ( ) = 0
P2 (
2
) =1
P2 ({i1 , i2 } =
1
n2
In questo caso con reimmissione, si hanno n scelte di palline per la prima estrazione e n
scelte per la seconda estrazione. Ci sono così n 2 scelte in totale.
17
22-10-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Consideriamo un’urna con palline bianche e palline nere.
n = numero di palline totali (bianche più nere)
n = numero di palline bianche
n = numero di palline nere
n =n +n
c =
c =
n
n
n
concentrazione di palline bianche
concentrazione di palline nere
n
m =numero di estrazioni
nel caso m=1:
1
= {1, 2,3,..., n}
In generale in m estrazioni con reimmissione:
m
=
1
*....*
1
= {( i1 , i2 ,..., im ) ; ik
1
, k = 1,.., m}
Esempio:
A
1
con A = { palline nere
B
con B = { palline bianche
1
IB (" ) =
1
Se "
B
0
Se "
B
}
}
“La prima pallina estratta è bianca”
( i1 , i2 ,..., im ) =
1
0
( i1 , i2 ,..., im ) = 1 se
( i1 , i2 ,..., im ) = 0
i1
B
se i1
B
18
Mi interessa sapere la i1 pallina
X 1 è una variabile causale
X1 :
X 1 ( ( i1 , i2 ,..., im ) ) = I B ( i1 ) dove i1 è la prima estrazione
X 2 ( ( i1 , i2 ,..., im ) ) = I B ( i2 ) i2 e la seconda estrazione
X m ( ( i1 , i2 ,..., im 1 , im ) ) = I B ( im ) im è la m-esima estrazione
m
= (i1 , i2 ,...im )
Consideriamo ora Sm e la definiamo come il numero di successi in m prove considerate
(è una VARIABILE CASUALE)
Si scrive in questo modo:
Sm =”numero di di successi nelle m prove”
Sm ( ( i1 , i2 ,..., im ) ) = I B ( i1 ) + I B ( i2 ) + ... + I B ( im )
NB: Sm indica la quantità di successi (estrazione palline bianche)
Ma quanto è la frequenza di successi?
S m X 1 + X 2 + ... + X m
=
m
m
Per capire meglio quest’ultimo passaggio facciamo un esempio :
Se escono Sm = 10 palline bianche la frequenza, con m = 15 , è
NB: anche
10
.
15
Sm
è una variabile casuale e m è il numero di prove.
m
Attenzione non stiamo parlando di probabilità,ma stiamo facendo una stima.
Esistono due modalità di estrazione :
•
Con reimissione(ad esempio pesco una scheda dall’urna e poi la rimetto dentro),
che indicheremo Pc.r
•
Senza reimissione indicheremo con Qs.r
19
Consideriamo ora la modalità con reimissione.
(
P
m
(
,
m
), P)
({( i , i ,..., i )}) = n1
1
2
m
m
=
1
|
m
|
S m X 1 + X 2 + ... + X m
=
m
m
X 1 può assumere il valore 0 o il valore 1
P (" X 1 = 1") = P
(
{( i1 , i2 ,..., im )
m
1
: i1
)
B} =
n * nm
n
m
1
=
n * nm * n
n
m
1
=
n *n
1
Abbiamo calcolato P (" X 1 = 1") , ma quanto vale P (" X k = 1") ?
Che probabilità ho che alla k –esima estrazione esca una pallina bianca
Consideriamo k compreso tra 1 e m cioè:
1 k
m
P (" X k = 1") =
n * nm
nm
1
=
n
n
=c
Consideriamo la modalità senza reimissione
(
m
(
,
m
) , Qs.r )
Qs.r (" X k = 1")
Suppongo n = m (voglio svuotare l’urna)
= {( i1 , i2 ,..., im )}
m
|
m
|= n m
X 1 = ( ( i1 , i2 ,..., im ) ) = I B ( i1 )
Q
|
({( i , i ,..., i )}) = ?
1
2
m
|= n ! numero di eventi accettabili
Q
({( i , i ,..., i )}) = 0 se " è un evento negativo
Q
({( i , i ,..., i )}) = n1! se "
1
1
2
2
m
m
Q ( " X 1 = 1") =
n * ( n 1) !
n!
=
è un evento positivo
n * ( n 1) !
n * ( n 1) !
=
n
n
20
1
=
n
n
Questo calcolo probabilistico vale per la prima estrazione ma anche per la k-esima
estrazione:
Q ( " X k = 1") =
n * ( n 1) !
n!
=
n
n
21
25-10-2004
Alessandro Reina, Laura Sorgiacomo. Paolo Rotta
Consideriamo il nostro solito esempio sulle schede favorevoli ad un determinato partito
M = numero di estrazioni che si effettueranno
m = numero di estrazioni che noi osserveremo
.
• • • • • • • • • • • • • • • •M
m
1
= {1, 2,..., n}
B = {" schede favorevoli al parito
B
"}
1
I B ( w) =
1 se w favorevole al partito
0 se w favorevole al partito
Variabile casuale che assegna uno se si ha un successo alla prima estrazione
X 1 ((i1 , i2 ,..., iM )) = I B (i1 )
Variabile casuale che assegna uno se si ha un successo alla k-esima estrazione
X 1 ((i1 , i2 ,..., ik ,..., iM )) = I B (ik )
M
=
1
*
1
*
1
*
1
*
1
*
1
*
1
*...*
1
M
P con reimmissione
((
M
, (
M
),
)
P senza reimmissione
Pc.r . ( X 1 = 1) =
Pc.r . ( X 2 = 1) =
n
n
n
n
...
Pc.r . ( X m = 1) =
n
n
Ovviamente si considera sempre l’inizio dell’esperimento in quanto, se solo fossimo alla
seconda estrazione, e alla prima ci fosse stato un successo, il numero di palline da
considerare sarebbe n 1 nel caso senza reimmissione.
Condizione: M = n (numero di estrazioni totali uguale al numero di palline totali)
n
Qs.r . ( X 1 = 1) =
n
n
Qs.r . ( X 2 = 1) =
n
22
...
n
Qs.r . ( X n = 1) =
n
n
1
Qs.r . ( X k = 1) = * n (n 1)! =
n!
n
1
è la probabilità di ogni singolo evento
n!
n indica che nella prima prova ho estratto una pallina bianca
(n 1)! siccome ho avuto un successo nella prova precedente ora ho una pallina bianca in
meno nell’urna per le restanti n-uple.
C =
n
n
concentrazione iniziale (prima che iniziano le estrazione)
Variabile casuale (non è un numero!!!)
Sm = X 1 + X 2 + ... + X m
Per m sufficientemente grandi abbiamo che:
Sm n
(non è uguale è circa uguale )
m
n
Poniamoci la seguente domanda nel caso reimmissione:
Pc.r . (( X 1 = 1) $ ( X 2 = 1)) =
Pc.r . ({(i1 ,..., iM )
n * n * nM
2
M
: i1
B}) =
B $ i2
2
%n &
=' ( =
n
n n * n )
Pc.r . ( X 1 = 1) * Pc.r . ( X 2 = 1)
M
=
n
*
n
Ora nel caso senza reimmissione:
Qs.r . (( X 1 = 1) $ ( X 2 = 1)) =
Qs.r . ({(i1 ,..., iM )
M
: i1
B}) =
B $ i2
A differenza della modalità di estrazione con reimmissione non tutti gli eventi elementari
hanno la stessa probabilità.
=
1
* n *(n
n!
1) *(n 2)! =
In generale: P ( A
B)
n
n
*
(n
1)
(n 1)
P ( A) * P ( B )
23
Se ogni volta che faccio una estrazione e vedo il colore della pallina ne aggiungo all’urna
una del medesimo colore otterrò:
n
Qs.r . (( X 1 = 1) $ ( X 2 = 1)) =
n
*
n +1
n +1
Nelle condizioni di estrazione con reimmissione, esaminiamo il caso in cui venga estratta
una pallina in posizione h e una pallina in posizione k:
Pc.r . (( X h = 1) $ ( X k = 1)) =
Pc.r . ({(i1 ,..., iM )
n * n * nM
2
M
: ih
B}) =
B $ ik
2
%n &
= * =' ( =
M
n
n n * n )
Pc.r . ( X h = 1) * Pc.r . ( X k = 1)
n
n
Nelle condizione di estrazione senza reimmissione, esaminiamo il caso in cui venga
estratta una pallina in posizione h e una pallina in posizione k:
Qs.r . (( X h = 1) $ ( X k = 1)) =
Qs.r . ({(i1 ,..., iM )
1
* n * (n
n!
M
: ih
B}) =
B $ ik
1) *(n 2) ! =
n
n
*
(n
1)
(n 1)
Pc.r . ( Bh
Bk ) = Pc.r . ( Bh ) * Pc.r . ( Bk )
Qs.r . ( Bh
Bk ) Qs.r . ( Bh ) * Qs.r . ( Bk )
Inziamo ad intrudurre un nuovo concetto: la probabilità condizionata
n 1
Qs.r . ( Bh Bk ) = Qs.r . ( Bh )*
n 1
h = 1, k = 1
n 1
Qs.r . ( B1 B2 ) = Qs.r . ( B1 ) *
n 1
Questa è la probabilità che all’evento B2 attribuisce un giocatore che ha già visto
presentarsi l’evento B1 alla prima prova.
Qs.r . ( B1 B2 ) n 1
=
Qs.r . ( B1 )
n 1
Qs.r . ( B1 B2 )
= Qs.r . ( B2 B1 )
Qs.r . ( B1 )
24
A1 = B1c
Q ( A1
B2 ) = Q ( A1 ) *
Q ( B2 | A1 ) =
Q ( A1
Q ( A1
B2 )
Q ( A1 )
=
n
* Q ( B2 | A1 )
n
n
n 1
B2 ) =
({( i ,..., i ) : i
1
n
1
A, i2
)
B} =
1
* n * n * ( n 2 )! =
n!
1
è la probabilità di ogni singolo evento
n!
n indica che nella prima prova ho estratto una pallina nera
n indica che nella seconda prova ho estratto una pallina bianca
(n 2)! siccome ho estratto una pallina bianca e una nera ora ci sono due palline in meno
nell’urna per le restanti n-uple possibili.
=
n *n
n * ( n 1)
Q ( B1
= Q ( A1 ) *
A2 ) = Q ( B1 ) *
n
n 1
n %n n &
Q ( B1 A2 ) n
= * Q ( A2 | B1 ) = * '
(
Q ( B1 )
n
n * n 1 )
25
29-10-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Inziamo con il sottolineare una frase comune che può provocare equivoci:
Non si parla di “La probabilità di un certo evento” in quanto dipende da come viene
effettuato l’esperimento (condizioni sperimentali).
In condizione di modalità di estrazione con reimmissione gli eventi elementari hanno la
stessa probabilità mentre nella modalità senza reimmissione gli eventi elementari non
hanno la stessa probabilità.
Negli appunti della precedente lezione eravamo arrivati alla conclusione che nel calcolo
della probabilità condizionata nella condizione che l’esperimento avvenisse senza
reimmissione:
n n 1
Q( B1 B2 ) = *
n n 1
Definiamo quinidi in maniera precisa il concetto di probabilità condizionata:
Considerando la tripletta: ( , , P+ )
C
,D
e P+ (C ) > 0
La probabilità condizionata è come di seguito scritta:
P (D C)
P+ ( D C ) = +
P+ (C )
Probabilità di D sotto condizione sperimentali + e sotto condizione dell’evento C
Studiamo ora il secondo membro della moltiplicazione precedente:
n
1
n 1
=
P+ ( B1 B2 )
P+ ( B1 )
dove + indica le condizioni sperimentali con le quali stiamo lavorando
Considerando la tripletta ( , , P+ )
Se + indica l’estrazione con reimmissione allora
P+ ( B1 B2 )
= P+ ( B2 )
P+ ( B1 )
Mentre è diverso se + indica che la modalità di estrazione avviene senza reimmissione
P+ ( B1 B2 )
P+ ( B2 )
P+ ( B1 )
Teniamo presente che è la probabilità condizionata di
n n 1
*
n 1
Ps.r . ( B2 | B1 ) = n n 1 =
n
n 1
n
26
La probabilità condizionata viene utilizzata molto spesso quando si cerca la probabilità di
un intersezione.
P+ (C D) = P+ (C ) * P+ ( D C )
Esercizio:
Data la tripletta ( , , P ) e gli eventi D
, C1
e C2
dove C1 C2 =
(eventi
mutuamente esclusivi), C1 C2 = , sapendo che P(C1 ) > 0 e P(C2 ) > 0 per calcolare
P ( D) potremo fare i seguenti calcoli:
(utilizzo della proprietà distributiva)
D=D
= D (C1 C2 ) = ( D C1 ) ( D C2 )
quindi
P( D) = P(( D C1 ) ( D C2 )) = P( D C1 ) + P( D C2 )) =
P( D C1 )
P ( D C2 )
=
* P (C1 ) +
* P(C2 ) = P( D | C1 )* P(C1 ) + P( D | C2 )* P(C2 )
P(C1 )
P(C2 )
Quindi posso calcolare P( D) sotto condizione sperimentali e sotto condizioni di C1 e C2
Se ora poniamo B1 = C1 e A1 = B1c =C2 (infatti C1
Psr ( B2 ) = Psr ( B2 | B1 )* Psr ( B1 ) + Psr ( B2 | A1 ) * Psr ( A1 )
C2 =
) e B2 = D
Analizziamo nel particolare:
Psr ( B2 | B1 ) =
n
1
n 1
probabilità di avere successo alla seconda prova dopo che si è svolta
una prima prova con successo
Psr ( B1 ) =
n
probabilità successo nella prima prova
n
Psr ( B2 | A1 ) =
n
n 1
probabilità che nella seconda prova ci sia un successo se nella prima
c’è stato un insuccesso
Psr ( A1 ) = 1
n
n
probabilità che nella prima prova ci sia un insucesso
Quindi
Psr ( B2 ) = Psr ( B2 | B1 )* Psr ( B1 ) + Psr ( B2 | A1 ) * Psr ( A1 ) =
1 n
(n n ) * n
n
% n & (n 1) * n
+
+
=
*
* '1
(=
n 1 n n 1 *
n )
n * (n 1)
n * (n 1)
n 2 n + n*n n 2 n*n n
n * (n 1) n
=
=
=
n * (n 1)
n * (n 1)
n * (n 1)
n
n
Quindi, senza reimmissione, Psr ( Bk ) =
n
n
27
Infatti Psr ( Bk ) = Psr ( Bk | B1 ) * Psr ( B1 ) + Psr ( Bk | A1 ) * Psr ( A1 ) =
Dimostriamo ora che Psr ( Bi
Bi +1 ) =
n
*
n
n
1 n
n
n n
n
* +
*
=
n 1 n n 1
n
n
1
n n 1
Pensando di fare l’estrazione k 1 su un’urna con una pallina in meno (bianca o nera), per
induzione, avremo che:
Bk +1 ) = P( Bk Bk +1 | B1 ) * P( B1 ) + P( Bk Bk +1 | A1 ) * P( A1 ) =
n 1 n 2 n
n
n 1 n n
n *(n 1) *(n 2) + n (n 1)(n n )
=
*
* +
*
*
=
=
n 1 n 2 n n 1 n 2
n
n *(n 1)*(n 2)
n *(n 2 n 2n + 2) + (n 2 n ) *(n n ) n 3 3n 2 + 2n + n * n 2 n * n n 3 + n
=
=
n *(n 1) *(n 2)
n *(n 1) *(n 2)
2
2
n + n * n + 2n nn
n ( 2n + n * n + 2 n) n *(n 1)*(n 2) n n 1
=
=
=
= *
n *(n 1)*(n 2)
n *(n 1)*(n 2)
n *(n 1) *(n 2)
n n 1
Psr ( Bk
2
=
Svolgendo gli stessi calcoli troveremo anche che
Psr ( B1 B3 ) = P( B1 B3 | B2 ) * P( B2 ) + P( B1 B3 | A2 ) * P( A2 )
Se invece + indica l’estrazione con reimmissione, abbiamo già dimostrato più volte che
2
n
%n &
P( Bi ) =
e anche P( B1 B2 ) = P( B1 ) * P( B2 ) = ' (
n
* n )
Per completezza dimostriamo comunque che:
Bk +1 ) = P(( Bk
P( Bk
2
%n & %n
' ( *'
* n ) * n
Bk +1 ) B1 ) P( B1 ) + P(( Bk
Bk +1 ) A1 ) P( A1 ) =
2
& %n & % n &
( + ' ( * '1
(
n )
) * n ) *
Inoltre dato i
j si ottiene che:
2
%n &
P( Bi B j ) = P( Bi ) * P( B j ) = ' (
* n )
Dato lo spazio campionario ( , , P+ ) e gli eventi D
indipendente dall’evento C se P ( D | C ) = P ( D )
,C
, diremo che l’evento D è
Se + indica l’estrazione con reimmissione Pcr ( B2 | B1 ) = Pcr ( B2 ) =
n
n
e quindi B2 è indipendente da B1 .
Se, invece, + indica l’estrazione senza reimmissione Pcr ( B2 | B1 ) Pcr ( B2 ) in quanto
n 1
. Quindi nella modalità di estrazione senza reimmissione diremo che
P( B2 ) =
n 1
B2 dipende dall’evento B1 .
28
5-11-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Articolo III. Definiamo ancora una volta :
P probabilità con modalità con estrazione
Q probabilità con modalità senza estrazione
Bi evento che alla i-esima prova abbia una pallina bianca
Ai = Bic
Modalità di estrazione con reimmissione
P ( Bi ) =
n
n
Se invece guardiamo due prove distinte ( i
P ( Bi
j ) con Bi e B j successi
2
%n &
B j ) = ' ( = P ( Bi ) * P ( B j )
* n )
dove P ( Bi ) = P ( B j ) perché le condizioni in cui eseguo le due estrazioni i e j sono le
stesse (infatti dopo avere eseguito un’estrazione reinserisco la pallina nell’urna).
Quindi otterremo che la probabilità che si verifichi una pallina bianca alla
estrazione è proprio P ( B j ) .
j-esima
In formula: P ( B j Bi ) = P ( B j )
B j risulta indipendente da Bi nel caso di estrazione con reimmissione.
Modalità di estrazione senza reimmissione
n
Q ( Bi ) =
n
Se invece guardiamo due prove distinte ( i
Q ( Bi
Bj ) =
n
n
*
n
1
n 1
= Q ( Bi ) *
n
1
n 1
j ) , con Bi e B j successi
= Q ( Bi ) * Q ( B j Bi )
Attenzione: Q ( B j Bi ) Q ( B j )
Quindi la probabilità condizionata di avere un successo B j dopo aver avuto un successo
nella prova Bi non è uguale B j come nella modalità con reimmissione. B j risulta
dipendente da Bi nel caso di estrazione senza reimmissione.
29
Consideriamo ora la tripletta
(
, , R)
R è la funzione di probabilità!
C
D
Proprietà:
I. D si dice indipendente da C se:
R( D C ) = R ( D )
cioè se
R(D
C)
R (C )
= R ( D)
R (C ) > 0
con
R ( D ) 0 (necessaria per ciò che vogliamo raggiungere)
II. R ( C ) *
Quindi
III.
R ( D C ) R ( D)
R(D C)
1
=
= R (C )
*
* R (C ) =
R ( D)
R (C )
R ( D)
R ( D)
R (C
D)
R (D)
R (C D )
= R (C )
R (D)
= R ( C ) = R(C D)
R (C
D ) = R (C ) * R ( D )
R (C D )
= R ( D)
R (C )
I) implica II) che implica III) che implica a sua volta I).
Quindi D e C sono indipendenti se R ( C
D ) = R (C ) * R ( D )
In italiano diremmo che C è indipendente dal presentarsi o non presentarsi di D .
30
Esercizio1:
Data la tripletta
(
, , P ) ,due eventi H
e K
indipendenti dimostrare che lo sono
anche H e K c
Ipotesi:
P(H K ) = P(H )* P(K )
Tesi:
P(H
K c ) = P ( H )* P (K c )
“Se due coniugi sono separati, allora, il marito è separato dalla moglie e la moglie è
separata dal marito”
Dimostrazione:
K Kc =
K
Kc =
P(Kc ) + P(K ) =1
P(H ) = P(H
P(H
Kc) =
) = P ( H ( K K c )) = P (( H K ) ( H K c )) = P ( H K ) + P ( H K c )
P ( H K ) + P ( H ) = P ( H ) * P ( K ) + P ( H ) = P ( H ) * (1 P ( K ) ) = P ( H ) * P ( K c )
Esercizio2:
Da un’urna estraiamo con reimissione tre palline: abbiamo tre eventi indipendenti B1 , B2 e
B3 .
P ( B1
B3 ) = P ( B1 ) * P ( B2 ) * P ( B3 ) =
n * n * n * nM
3
n 3 * nM * n
3
=
nM
nM
NB:Questa formula in generale non vale, me nel nostro esempio sì.
B2
3
%n &
= 3 =' (
n
* n )
n
3
Tre eventi si dicono indipendenti se ciascuna coppia è indipendente e se la probabilità
della intersezione degli eventi è uguale al prodotto delle probabilità di ogni singolo evento.
Una terna di eventi è indipendenti se ogni coppia lo è ( B1
P ( B1
B2
B3 ) = P ( B1 ) * P ( B2 ) * P ( B3 )
31
B2 ) , ( B2
B3 ) , ( B1
B3 ) e se
Esempio3:
Ci sono m estrazioni con modalità con reimissione.
In quali di queste estrazioni comparirà per la prima volta una scheda favorevole al mio
partito?
P ("T = K ") = P ( A1
A2 ...
n
dove P ( Bk ) = c =
n
Ak
1
Bk ) = P ( A1 ) * P ( A2 ) * P ( Ak
1
) * P ( Bk ) = (1
c
)
k 1
*c
.
Cosa è T?
T agisce su un esito dell’esperimento i1 , i2 ..., in palline. Agisce sull’indice in cui si trova per
la prima volta la pallina bianca.
T ( ( i1 , i2 ,..., iM 1 , iM ) )
E’ un ciclo che esce con M, o se una pallina è bianca
1 k M 1
P ( " T = k ") =
k=M
Nel primo caso la probabilità si calcolerà : (1 c
)
k 1
*c
Nel secondo caso la probabilità si calcolerà: (1 c ) M
P ("T = M ") = P ( A1
A2
...
AM
1
1
)
Sm = numeri successi
S m = X 1 + X 2 + X m = I B1 + I B2 + I Bm
Guardo le palline che sono nelle prime m posizioni
m
S m ( ( i1 ,..., im , im +1 , iM ) ) = , ( if ix
x =1
P (" Sm = 0") = P ( A1
P ( A ) = (1 P ( B1 ) )
c =
n
n
m
A2
Am ) = P ( A1 ) * P ( A2 ) *...* P ( Am )
...
% n &
= '1
(
n )
*
B 1, else 0 )
m
=p
P (" S m = 0") = (1 p )
m
P (" S m = 1") = m * p * (1 p )
m 1
m
%n &
m
P(" S m = m ") = P( B1 B2 ... Bm ) = '
( =p
* n )
dove m mi permette di scegliere il modo di estrazione
dove p * (1 p )
m 1
è la probabilità di avere successo in una preassegnata prova
% m&
m
P (" Sm = 2") = ' ( * p 2 (1 p )
*2 )
2
32
IN GENERALE:
Distribuzione Binomiale
%m&
m
P (" S m = k ") = ' ( * p k * (1 p )
*k )
1< k < m
p k prefissate prove
(1
p)
m k
k
insuccesso in m k prefissate prove
% m&
' ( numero di sottoinsiemi di numerosità k su un insieme di numerosità m
*k )
33
(08 e 12)-11-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Riassiumiamo i concetti sulla legge di distribuzione binomiale:
n
p= C =
n
P( S m = 0)=(1 p ) m
P ( S m = m) = p m
%m&
P( Sm = k ) = ' ( p k (1 p ) m
*k )
0 k m
k
La legge è svincolata che la modalità di estrazione avvenga con o senza reimmissione.
%m&
' ( rappresenta un sottoinsieme di numerosità k in un insieme di numerosità m
*k )
Ora supponiamo una scatola in cui ci sono m palline.
Le posso scegliere in m ! modi.
Scelgo poi k palline e le metto nelle prime k posizioni.
Le posso scegliere in k ! modi.
Le rimanenti palline le posso scegliere in (m k )! modi.
In questo modo stiamo scoprendo come viene fuori il binomiale...
%m&
m ! = ' ( k !(m k )!
*k )
%m&
m!
=' (
k !(m k )! * k )
%m&
' ( =1
*m)
%m&
'0 ( =1
* )
Mostriamo ad esempio un grafico che rappresenta sottoinsiemi di k palline da un insieme
di 50 palline (m = 50)
Binomiale @50,kD
1.2 × 10
14
1× 10 1 4
8× 10 1 3
6× 10
13
4× 10 1 3
2× 10 1 3
10
20
30
40
50
k
34
Come nelle elezioni americane, possiamo sapere il vincitore dopo un’estrazione parziale di
S
m schede. Significa che conoscendo m supponiamo il valore di C .
m
Nella lezione di oggi, prendiamo in considerazione estrazioni con reimmissione (sarà più
semplice visto che sono estrazioni indipendenti fra loro).
Estratte m schede, valuteremo Sm , calcoleremo
Sm
e assegneremo questo valore, come
m
congettura, a C .
Prendiamo in considerazione il campione
X 1 , X 2 ,..., X m
1 se è a favore di
Xi =
0 altrimenti
Calcoliamo quindi:
m
Sm
=
m
,X
i =1
m
i
(stimatore di C )
Sarà la quantità di successi, diviso il numero di prove.
Ricordiamo che m è una variabile da assegnare. Dobbiamo sceglierla in modo ottimale in
quanto:
- se troppo piccola, rischio di sbagliare;
- se troppo grande, devo aspettare troppo tempo.
Noi non conosciamo il risultato di X 1 , ma sappiamo che sarà a favore di
Che relazione vogliamo che ci sia tra C e
oppure no.
Sm
?
m
Sm
- dove - > 0
C
m
Se stiamo estraendo con reimmissione, non esiste un valore che posso assegnare ad
m per il quale la disuaglianza sia sicuramente vera. Se invece estraiamo senza
S
reimmissione e m = n , allora m = C .
m
%S
&
Vogliamo sapere quanto vale P ' m C
- ( ? - Funzione di - , di m , ma non di C .
* m
)
A noi interessa che la loro differenza non superi un certo errore:
Dato lo spazio campionario ( , , P ) e la variabile casuale Z possiamo studiare
| Z a | b dove a e b equivalgono a costanti decise a priori; studiare questa
disuguaglianza significa studiare l’insieme degli esiti che la soddisfano.
35
P (| Z a | b) = 1 P (| Z a |> b)
P (| Z a |> b) ?
Ci chiediamo quindi quant’è la probabilità che Z non cada nell’intervallo (a b, a + b) .
Z può assumere k valori, che indicheremo con zi . Supponiamo di conoscere P( Z = zi ) zi .
Allora
,
P(| Z a |> b)
i:| zi a| >b
| zi
a |> b
| zi
a|
b
P ( Z = zi )
>1
a)2
( zi
b
2
> 12
quindi
,
P(| Z a |> b)
i:1<
( zi a )2
k
,
1* P( Z = zi )
( zi
a)2
b2
i =1
* P ( Z = zi )
b2
Infine, diremo che:
1 k
P(| Z a |> b)
, ( zi a ) 2 * P ( Z = zi )
b 2 i =1
Ora ci poniamo la seguente domanda:
considerando b fissato, quale valore dovrà assumere a per far sì che
k
, (z
i =1
i
a ) 2 * P ( Z = zi ) assuma valore minimo?
Per fare ciò dovremo calcolarne la derivata prima e indicheremo il risultato con a .
k
g (a ) = , ( zi
i =1
k
a ) 2 * P( Z = zi )
g '(a ) = , 2( zi
i =1
a ) * P( Z = zi ) =
k
, 2( z
i =1
i
a) * P( Z = zi )
La costante 2 possiamo non considerarla. Dobbiamo cercare il valore da assegnare ad a :
k
k
i =1
i =1
zi * P( Z = zi ) a * P( Z = zi ) = , zi * P( Z = zi ) a * , P( Z = zi )
k
quindi
k
k
i =1
i =1
, zi * P(Z = zi ) = a * , P(Z = zi ) e allora a =
, z * P( Z = z )
i
i =1
i
k
, P( Z = z )
i =1
.
i
Se osserviamo, il denominatore, vale 1, in quanto è la sommatoria della probabilità di tutti
k
gli eventi. Quindi troviamo che a = , zi * P ( Z = zi ) .
i =1
Chiamiamo, ora, il valore P( Z = zi ) con la lettera pi con i = 1, 2,..., k .
36
Il valore
k
, z * p viene definito “valore atteso della variabile casuale Z” e lo indicheremo
i =1
i
i
con µ Z .
P(| Z
µ Z |> b)
Il valore
k
, (z
i =1
i
1 k
* , ( zi µ Z ) 2 * P ( Z = zi )
2
b i =1
1
b2
k
, (z
i =1
i
a ) 2 * P ( Z = zi )
µ Z ) 2 * P( Z = zi ) viene chiamato “varianza di Z” e si indica con var( Z ) .
Anche la varianza è un valore atteso dove però la variabile casuale è differente:
Z = ( zi µ Z ) 2 .
Concediamoci un po’ di calcoli matematici per arrivare ad una conclusione:
1
var( Z )
P(| Z µ Z |> b)
* var( Z ) =
2
b
b2
Ricordiamo che b è una costante che definiamo noi; poniamo allora b = r * var( Z ) , quindi:
var( Z )
1
P | Z µ Z |> r * var( Z )
= 2
2
r * var( Z ) r
% Z µ
& 1
Z
P'
> r(
' var( Z )
( r2
*
)
1
Notiamo come P , Z , µ Z e var( Z ) non li conosciamo. Conosciamo solo i valori r e 2 .
r
(
)
37
15-11-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
%S
Come abbiamo già ripetuto più volte, stiamo provando che P ' m
* m
di p .
&
g(
)
p
f ( g , m) e non
Sia Z un’assegnata variabile casuale su un assegnato spazio campionario ( , , P )
supponendo che
sia finito e che Z assuma k valori.
a
e
b > 0 avremo: P(| Z a | b) 1
1 k
* , ( zi
b 2 i =1
a ) 2 * P ( Z = zi )
k
a è la scelta ottimale per rendere minima la sommatoria e vale a = , zi * P ( Z = zi ) . Questo
i =1
valore viene detto “valore atteso” della variabile casuale Z e lo indicheremo con /( Z ) o
µZ .
Il valore minimo della sommatoria è dunque
k
, ( zi
i =1
k
a ) 2 * P ( Z = zi ) = , ( z i
i =1
µ Z ) 2 * P ( Z = zi )
e viene detto “varianza di Z ” e indicato con var( Z ) ed è il valore atteso di ( zi
µZ )2 .
Introduciamo oggi il concetto di deviazione standard della variabile casuale Z che
indicheremo con 0 Z e indica
var( Z ) o anche
/(( zi
µ Z )2 ) .
Quindi la nostra disequazione iniziale possiamo scriverla come P(| Z
Poniamo ora b = r *0 Z dove r > 0 e Z > 0 .
1
P(| Z µ Z | (r * 0 Z )) 1
* 0 Z 2 e come
2
(r *0 Z )
% Z µZ
arriveremo a P ''
* 0Z
abbiam
visto
la
µ Z | b) 1
lezione
1
*0 Z 2 .
2
b
precedente
&
1
r (( 1 2 .
r
)
Se noi puntiamo su un intervallo [ µ Z 0 Z , µ Z + 0 Z ] e supponiamo di conoscere r = 2 , allora
% Z µZ
P ''
* 0Z
&
1
= 0.75 .
2 (( 1
4
)
Se Z assume solo 0,1 allora P( Z = 1) = p e P( Z = 0) = 1 p .
38
% m&
P( Z = k ) = ' ( p k (1 p )m k * I{0,1,...,m} (k ) dove
*k)
I{0,1,...,m} (k ) è la “funzione indicatrice”, in modo da controllare che non vengano assegnati
Se Z assume valori da 0 a m , allora
valori alla variabile casuale che essa non può assumere.
Sostituendo P( S m = k ) nella funzione della variabile casuale, troveremo
m
/( S m ) = , k *
k =0
m!
* p k (1 p )m
k !* (m k )!
k
Ricordiamo che il binomio di Newton è
m
%m&
,' k (*a
k
* bm
k
= ( a + b) m .
* )
Potremmo utilizzare questa uguaglianza nella nostra funzione /( Sm ) se non ci fosse la
k =0
k moltiplicata al binomiale. Vediamo infatti che verrebbe ( p + 1 p )m = 1m = 1 .
Dobbiamo fare un po’ di passaggi per ricondurci alla forma corretta.
Possiamo far partire la sommatoria da k = 1 perché con k = 0 , l’espressione vale 0 ; inoltre
%m&
m!
1
1
1
ricordiamo che ' ( =
e che k * = k *
=
k!
k *(k 1)! (k 1)!
* k ) k !* (m k )!
La sommatoria, quindi, diventa:
m
, (k
k =1
m!
* p k *(1 p ) m
1)!*(m k )!
k
Sostituiamo k con h + 1 , ossia h = k 1 .
m 1
m * (m 1)!
* p h +1 *(1 p )( m 1) h
,
h)!
h = 0 h !*(( m 1)
Ora per arrivare alla forma che vogliamo, portiam fuori dalla sommatoria le costanti m e p .
m 1
(m 1)!
* p h *(1 p )( m 1) h
m* p*,
h)!
h = 0 h !* (( m 1)
La sommatoria vale 1, quindi /( S m ) = mp .
m
%m&
E ( S m ) = , ' ( * p k *(1 p) m k * k = mp
k =0 * k )
%S
E' m
*m
k
1& 1
1
& m %m& k
%
m k
( = , ' k ( * p *(1 p) * m = / ' Sm i m ( = m / ( S m ) = mp m = p
*
)
) k =0 * )
1
%S &
Se vogliamo cercare E ' m ( basterà portar fuori la costante dalla sommatoria e quindi
m
*m)
n
1
%S &
troveremo / ' m ( = mp * = p = C =
m
n
*m)
39
Possiamo dimostrare questa uguaglianza in altri modi, esaminiamone uno.
Supponiamo che l’uguaglianza sia vera per m 1 prove.
Se m = 1 allora /( X 1 ) = 0* (1 p ) + 1* p = 1* p = p .
Supponiamo che qualunque m 1 prove, risulti vero /( Sm 1 ) = (m 1) * p .
m
/( S m ) = , k * P( X 1 + X 2 + ... + X m = k ) =
k =0
m
m
= , k * P( X 1 + ... + X m = k | X 1 = 1) * P( X 1 = 1) + , k * P( X 1 + ... + X m = k | X 1 = 0)* P( X 1 = 0) =
k =0
k =0
m
m
k =0
k =0
= P( X 1 = 1)* , k * P( X 1 + ... + X m = k | X 1 = 1) + P( X 1 = 0) * , k * P( X 1 + ... + X m = k | X 1 = 0) =
Facciamo alcune considerazioni.
Siccome stiamo lavorando con reimmissione, la dipendenza dalla prima estrazione delle
estrazioni successive non c’è, quindi P( X 1 + ... + X m = k | X 1 = 1) = P( X 1 + ... + X m = k ) .
Nella probabilità della prima sommatoria possiamo notare che, avendo un risultato positivo
alla prima estrazione, k non varrà mai 0, allora la sommatoria può partire da k = 1 .
Nella probabilità della seconda sommatoria possiamo notare che, avendo un risultato non
positivo alla prima estrazione, allora la sommatoria può arrivare fino a m 1 .
Inoltre ricordiamo che P( X 1 = 1) = p e che P( X 1 = 0) = 1 p
Quindi:
m
m 1
k =1
k =0
= p * , k * P( X 2 + ... + X m = k 1) + (1 p ) * , k * P( X 2 + ... + X m = k 1) =
m 1
m 1
= p * , (h + 1) * P( X 2 + ... + X m = h) + (1 p ) * , k * P( X 2 + ... + X m = k )
h =0
k =0
m 1
m 1
m 1
h =0
k =0
= p * , h * P( X 2 + ... + X m = h) + p * , 1* P( X 2 + ... + X m = k ) + (1 p ) * , k * P( X 2 + ... + X m = k )
h =0
Notiamo che
m 1
, k * P( X
k =0
2
+ ... + X m = k ) = /( S m 1 ) = (m 1) * p , quindi:
/( S m ) = (1 p ) * (m 1)* p + p *(m 1) * p + p = mp mp 2
40
p + p 2 + mp 2
p 2 + p = mp
19-11-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Sia Sm = X 1 + X 2 + ... + X m la variabile casuale somma dei successi.
Procederemo ora considerando la modalità con reimmissione.
%m&
P( Sm = k ) = ' ( p k (1 p ) m k * I{0,1,...,m} (k )
*k)
p=C =
n
n
q = 1 p probabilità di insuccesso
h=k 1
/( Sm ) valore atteso
m
m
k =0
k =0
/( S m ) = , k * P ( S m = k ) = , k
m
% m 1& k 1 ( m
= mp , '
(p q
k =1 * k 1 )
1) ( k 1)
m!
pk qm
k !(m k )!
k
m
m(m 1)!
pk qm
(k 1))!
k =1 (k 1)!(( m 1)
=,
m 1
= mp ,1* P( Sm = h) = mp
h =0
1
/( Sm ) = mp
con reimmissione
mp m 1
%S & m k
/ ' m ( = , P(Sm = k ) =
,1* P( Sm 1 = h) = p
m h=0
* m ) k =0 m
1
%S
/' m
*m
&
(= p
)
con reimmissione
Abbiamo così dimostrato anche le seguenti proprietà:
/(1) = 1
/( Z ) = /( Z )
41
k
=
Supponiamo ora: Sm = X 1 + X 2 + ... + X m 1 + X m
Sm = X 1 +
Sm
1
In uno schema di m estrazioni ci chiediamo che la quantità di successi sia pari a k .
P( Sm = k )
P( Sm = k ) = P( X 1 + X 2 + ... + X m = k ) = P( X 1 + Sm 1 = k ) =
=P((( X 1 + S m 1 = k )
= P(( Sm 1 = k )
( X 1 = 0))
(( X 1 + Sm 1 = k )
( X 1 = 0)) + P(( Sm 1 = k 1)
( X 1 = 1)) =
( X 1 = 1)) =
Si annulla se k = m
Si annulla se k = 0
(ex: se faccio 10
estrazioni è impossibile
avere 10 successi
quando il primo è
andato male)
=
P(( S m 1 = k ) ( X 1 = 0)) P( X 1 = 0) P(( S m 1 = k 1) ( X 1 = 1)) P( X 1 = 1)
+
=
P( X 1 = 0)
P( X 1 = 1)
Moltiplicando e dividendo il primo membro per la probabilità di insuccesso nella prima
prova e il secondo membro per la probabilità di successo nella prima estrazioni ci portiamo
nelle condizioni e quindi nella corretta espressione della probabilità condizionata.
P( Sm = k ) = P(( Sm 1 = k ) | ( X 1 = 0)) P( X 1 = 0) + P (( Sm 1 = k 1) | ( X 1 = 1)) P( X 1 = 1)
m
/( Sm ) = , kP( Sm = k )
k =0
m
m 1
k =0
k =0
, kP(Sm = k ) = , kP((Sm 1 = k ) | ( X 1 = 0)) P( X1 = 0) +
m
+ , kP(( Sm 1 = k 1) | ( X 1 = 1)) P( X 1 = 1)
k =1
m 1
/( Sm ) = P( X 1 = 0), kP(( Sm 1 = k ) | ( X 1 = 0)) +
k =0
m
+ P( X 1 = 1), kP(( Sm 1 = k 1) | ( X 1 = 1))
k =1
42
Imponiamo h = k 1
m 1
/( S m ) = P( X 1 = 0), kP(( S m 1 = k ) | ( X 1 = 0)) +
k =0
m 1
+ P( X 1 = 1), (h + 1) P(( S m 1 = h) | ( X 1 = 1))
h =0
Ora eseguiamo questo passaggio sottile ma importante, possiamo dividere in due parti il
m 1
secondo addendo P( X 1 = 1), (h + 1) P(( S m 1 = h) | ( X 1 = 1)) dato che abbiamo h + 1 . Quindi:
h =0
m 1
m 1
h =0
h=0
P( X 1 = 1), hP(( S m 1 = h) | ( X 1 = 1)) + P( X 1 = 1),1P(( S m 1 = h) | ( X 1 = 1))
1
m 1
/( S m ) = P( X 1 = 0), kP(( S m 1 = k ) | ( X 1 = 0)) +
k =0
m 1
+ P( X 1 = 1), hP(( Sm 1 = h) | ( X 1 = 1)) +
h =0
+ P( X 1 = 1)
Sappiamo che /( S1 ) = /( X 1 ) dove X 1 è la nostra variabile bernoulliana.
P( X 1 = 0) = 0* q
Inoltre :
P( X 1 = 1) = 1* p
Quindi:
/( S1 ) = p
/( Sm 1 ) = (m 1) p
m-1 estrazioni con concentrazione p di palline bianche
m 1
/( Sm ) = q , kP( Sm 1 = k ) +
k =0
m 1
+ p, kP( Sm 1 = k ) +
k =0
+p
m 1
/( S m ) = (q + p ), kP( S m 1 = k ) + p =
k =0
= /( S m 1 ) + p = (m 1) p + p = mp
/( Sm ) = mp
43
Ed eccoci finalmente a trattare il caso della modalità senza reimmissione
?
Q( S m = k ) = P( Sm = k )
m
, kQ( S
k =0
m
= k ) = f (m, p)
???
Supponiamo m = 1
/( S1 ) = Q( X 1 = 1) = p
palline bianche presenti nell ' urna al
momento di effettuare la prima di (m 1)
/( S m 1 ) = (m 1) *
estrazioni
totale di palline presenti nell ' urna al
momento di effettuare la prima di (m 1)
estrazioni
*
1
*
*
*
Sm
q =1 p =1
=
=
=
*
1
n
n
1 n
+
=
n 1
n 1 n
n
n
p (m 1)
+ ( p + q )(m 1)
=
n
n 1
n 1
n (n 1) + (m 1)n n n (m 1)
=
n(n 1)
n (n 1 + nm n m + 1)
=
n(n 1)
n (nm m) n m(n 1) n m
=
=
n(n 1)
n(n 1)
n
/( S m ) = q(m 1)
=
*
/( S m ) = m
n
+ p(m 1)
n
n
n
n
%S &
/' m ( =
=p
*m) n
44
Quindi lavorando sia con sia senza reimmissione:
%S
P' m
* m
%S
&
- ( = P' m
)
* m
p
%S &
/' m (
*m)
&
-( 1
)
%S &
var ' m (
*m)
-2
Possiamo notare che
%S &
var ' m (
* m ) = 1 % 1 * var( S m ) & = 1 var( S m )
1
' 2
-2
- 2 ()
m2 * - 2
*m
inoltre
%S
- > 0 lim P ' m
m 1
* m
p
&
- ( =1
)
Introduciamo ora la seguente proprietà:
var( Z ) =
2
* var( Z )
costante
Dimostrazione:
var( Z ) = /(( Z /( Z )) 2 ) = /(( Z
= 2 * var( Z )
* /( Z )) 2 ) = /(
45
2
*( Z /( Z )) 2 ) =
2
* /(( Z /( Z ))2 ) =
22-11-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Proprietà Valore Atteso:
1) / ( k ) = k
k costante
2) / ( X ) = / ( X )
3) / ( X 1 + X 2 ) = / ( X 1 ) + / ( X 2 )
4) / ( Y + Z ) = / (Y ) + / ( Z )
5) / ( Y +
)=
/ (Y ) +
Dimostriamo la proprietà 3:
Y = y1 , y2 ,..., yh
Z = z1 , z2 ,..., zk
h
k
/ ( Y + Z ) = ,, ( yi + z j ) * P(Y = yi $ Z = z j ) =
i =1 j =1
h
k
h
k
= ,, yi * P (Y = yi $ Z = z j ) + ,, z j * P(Y = yi $ Z = z j ) =
i =1 j =1
i =1 j =1
Le sommatorie si possono invertire come preferiamo. Invertiamo la seconda in modo da
poter portar fuori la z j .
h
k
k
h
i =1
j =1
j =1
i =1
= , yi , P(Y = yi $ Z = z j ) + , z j , P(Y = yi $ Z = z j ) =
k
, P(Y = y $ Z = z )
Notiamo come in
j =1
h
, P(Y = y $ Z = z ) dove
i
i =1
j
h
k
i =1
j =1
i
j
la P ( Z = z j ) sia uguale a 1. Lo stesso vale per la
P(Y = y j ) è uguale a 1. Quindi:
= , yi * P(Y = yi ) + , z j * P( Z = z j ) =
Quindi concludiamo con il seguente risultato: / ( Y ) + / ( Z )
46
Proprietà Varianza:
1) var ( Z ) =
2
var ( Z )
2) var (1) = 0 dimostrazione:var (1) = / ( (1 1) 2 ) = 0
3) var ( Z +
) = var ( Z )
4) cov (Y , Z ) = cov( Z , Y ) = / ( (Y / ( Y ))*( Z / ( Z )) )
5) var (Y + Z ) = var (Y ) + var ( Z ) + 2 cov (Y , Z )
6) var ( Y + Z ) =
2
var ( Y ) +
2
var ( Z ) + 2
Dimostriamo la proprietà 3:
Ricordiamo: var( Z ) = /
(
var( Z + ) = / ( Z +
(
= / ( Z /( Z ) )
2
((
Z /( Z ) )
/( Z + ) )
2
) = var ( Z )
2
cov (Y , Z )
)
) = / (( Z +
/( Z )
)
2
)=
Dimostriamo la proprietà 5:
(
var (Y + Z ) = / ( (Y + Z ) / (Y + Z ) )
(
= / ( (Y
2
) = / ( ( (Y
/ (Y ) ) + ( Z / ( Z ) )
)
) )=
2
= / (Y / ( Y ) ) + ( Z / ( Z ) ) + 2 (Y / ( Y ) ) * ( Z / ( Z ) ) =
2
2
) (
)
(
)
/ ( Y ) ) + / ( Z / ( Z ) ) + 2/ ( Y / ( Y ) ) * ( Z / ( Z ) ) =
2
2
var (Y ) + var ( Z ) + 2 cov (Y , Z )
Abbiamo così introdotto un nuovo concetto, quello di covarianza:
cov(Y , Z ) = / (Y / (Y ) ) * ( Z / ( Z ) )
(
)
Andiamo ora all’origine dei nostri problemi:
%S &
var ' m (
%S
&
*m)
P' m p - ( 1
-2
* m
)
Ad esempio, dobbiamo saper prendere un campione “piccolo” di sangue in modo da
stimare la concentrazione dei globuli rossi presenti nel nostro corpo, con un errore molto piccolo.
Andremo a dimostrare che Sm cresce con m meno rapidamente di m 2 ottenendo così che
comunque si assegni - > 0 il:
%S
lim P ' m
m 1
* m
p
&
- ( = 1 (Legge debole dei grandi numeri)
)
47
%S &
Cerchiamo di determinare la var ' m ( con un po’ di calcoli:
*m)
2
%% 1 m
& &
%S &
var ' m ( = / ' ' * , ( X i p ) ( ( = ricordiamo che a 2 = a * a, quindi
' * m i =1
*m)
) ()
*
%1 m
/' *, (Xi
* m i =1
& %1 m
p) ( * / ' , ( X j
) * m j =1
&
% 1 m m
p ) ( = / ' 2 * ,, ( X i
)
* m i =1 j =1
p )( X j
& 1
p) ( = 2
) m
m
m
,, / ( ( X
i =1 j =1
i
p )( X j
Stiamo considerando variabili casuali bernoulliane.
Nel caso in cui i = j , / ( ( X i
p ) 2 ) , sia con, sia senza reimmissione, è uguale a
var ( X i ) = p(1 p) .
Quanti casi avremo in cui i = j ? Esattamente m , quindi continuando i conti
=
1
1 m m
mp
(1
p
)
+
,, / ( ( X i
m2
m 2 i =1 j =1
Studiamo ora / ( ( X i
/ (( Xi
p )( X j
p )( X j
p) ) = / ( X i X j
p)( X j
p ) ) con i
pX i
p) )
j:
pX j + p 2 ) = p 2
p/ ( X j )
p/ ( X i ) + E ( X i X j ) =
Ricordiamo che p = / ( X i ) e che quindi / ( X i ) = p e ricordiamo anche che / ( X ) = P( X = 1)
Sostituendolo nella nostra espressione, troveremo:
= p 2 p 2 / ( X j ) / ( X i ) + E ( X i X j ) = E ( X i X j ) P( X i = 1) * P( X j = 1) =
= P( X i X j = 1) P( X i = 1) * P( X j = 1) = P( X i = 1 $ X j = 1) P( X i = 1) * P( X j = 1)
Attenzione al passaggio in blu ;-)
Ora dobbiamo specificare i casi in cui lavoriamo con reimmissione e quelli in cui lavoriamo
senza.
Con Reimmissione
P ( X i = 1 $ X j = 1) P ( X i = 1) * P ( X j = 1) = P ( X i = 1) * P ( X j = 1) P ( X i = 1) * P ( X j = 1) = 0
% S & p (1 p )
Quindi varcr ' m ( =
m
*m)
Per il teorema dei due carabinieri possiamo affermare che:
%S
1 P' m
* m
p
&
-( 1
)
p(1 p)
m- 2
- >0
48
p) ) =
%S
Quindi lim P ' m
m 1
* m
&
- ( =1
p
)
Senza Reimmissione
P( X i = 1 $ X j = 1) P( X i = 1) * P( X j = 1) =
n
1
n
n n 1
Quindi
n
*
n
*
n
n
=
%n 1
*'
n * n 1
n
n (n
1)(n 2)! n
n!
n
*
n
n
=
n &
(
n )
% n % n 1 n &&
% S & p (1 p ) 1
varsr ' m ( =
+ 2 * m * (m 1) * ' * '
((
m
m
*m)
* n * n 1 n ))
n 1 n
Noi sappiamo che tranne
, tutti gli altri membri sono positivi.
n 1 n
n 1 n
<
quindi n(n 1) < n (n 1) se n > n . Questo risulta falso solo se abbiamo
n 1
n
n 1 n
n = n , quindi, in linea di massima,
è negativo.
n 1 n
Quindi sappiamo che
%S &
%S &
varsr ' m ( = varcr ' m ( * qualcosa di negativo
*m)
*m)
%S &
%S &
Possiamo allora dedurre che varsr ' m ( < varcr ' m ( .
*m)
*m)
Per rispondere finalmente alla nostra domanda ecco la risposta:
%S &
%S &
varsr ' m (
varcr ' m (
%S
&
*m) 1
* m ) = 1 p (1 p )
P' m p - ( 1
2
-2
m *- 2
* m
)
Studiamo f ( p ) = p * (1 p ) che vale p
p2 .
La derivata prima vale f '( p ) = 2 p + 1 e se la uguagliamo a 0 troveremo che p =
equivale al punto sull’asse delle x del massimo della parabola. Se sostituiamo
%1& 1
f ( p ) , troveremo f ' ( = .
*2) 4
49
1
che
2
1
a p in
2
H1 pL p
0.25
0.2
0.15
0.1
0.05
0.2
%S
Quindi P ' m
* m
p
&
-( 1
)
0.4
0.6
1
4m- 2
50
0.8
1
p
26-11-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Articolo IV. Legge (debole) dei grandi numeri
Consideriamo la tripletta
(
, , P ) e una collezione di eventi costituita da
{
, , A, Ac , B, B c }
Dato un evento B ,in modalità con reimissione,cos’è P ( B ) ?
Pc.r ( B ) = c =
n
n
=p
Come stimare questa quantità?
e consideriamo m estrazioni.
Prendiamo uno spazio campionario
Come posso scegliere in modo opportuno il numero di estrazione m da effettuare per
calcolare con una certa precisione la probabilità di un evento?
Consideriamo le variabili casuali X i che seguono la legge bernoulliana con parametro p e
la loro rispettiva funzione indicatrice I Bi
X 1 = I B1
X 2 = I B2
...
X m = I Bm
Gli statistici dicono che le variabili casuali X 1 , X 2 ,..., X m sono un campione estratto della
popolazione bernoulliana.
Indichiamo con Sm il numero di successi in m prove:
Sm = X 1 + X 2 + ... + X m
Sm
a cui associo p .
m
Questo è un lavoro abbastanza semplice se lavoriamo con reimissione.
Consideriamo invece la frequenza di successi
Sappiamo che Pc.r ( B1
B2 ) = Pc.r ( B1 ) Pc.r ( B2 ) .
Ciò accade per qualsiasi coppia di prove: Pc.r ( Bi
B j ) = Pc.r ( Bi ) Pc.r ( B j ) .
Facciamo m esperimenti indipendenti tra loro,con probabilità di successo p e sotto le
stesse condizioni sperimentali.
Il numero di successi Sm segue la legge binomiale con parametri m e p .Ciò è una magra
consolazione perché p non lo conosco e non conosciamo neppure m perché dobbiamo
decidere ancora il numero di prove da effettuare.
51
Ciò che sappiamo è :
%S &
Ec.r ' m ( = p
s .r * m )
% m
&
varc.r ( S m ) = varc.r ' , X i ( = var ( X 1 ) + var ( X 2 ) + ... + var ( X m ) = mp (1 p )
* i =1 )
varc.r ( X 1 ) = varc.r ( X 2 ) = varc.r ( X i ) = varc.r ( X m )
% m
&
ATTENZIONE: varc.r ' , X 1 (
* i =1 )
cov c.r ( X i , X j ) = 0 con i j
m
, var ( X )
i =1
c.r
1
cov s.r ( X i , X j ) < 0
varc.r ( Sm ) = mp (1 p )
p (1 p )
%S & 1
varc.r ' m ( = 2 varc.r ( Sm ) =
m
*m) m
%S &
/' m ( = p
*m)
%% S
/'' m
'* m
*
%S
Pc.r ' m
* m
- >0
&
p(
)
p
2
& p (1 p )
(( =
m
)
Errore Quadratico Medio
%S
varc.r ' m
&
*m
-( 1
-2
)
&
(
) = 1 p (1 p )
m- 2
questa formula nasconde apparentemente un limite perché per conoscere questa quantità
dobbiamo conoscere p e m
Noi non conosciamo p ma possiamo studiare come varia p (1 p ) al variare di
p (compreso tra 0 e 1 ).Se riesco a lavorare sui risultati peggiori di p (1 p ) posso lavorare
anche con risultati migliori.
52
H1 pL p
0.25
0.2
0.15
0.1
0.05
0.2
0.4
0.6
0.8
1
p
p (1 p ) si annulla per p = 0 e p = 1
1
4
p (1 p ) =
per p =
1
2
ho un punto di simmetria
1
1
so che è il punto massimo della curva quindi p (1 p ) <
4
4
Di conseguenza:
p (1 p )
1
1
2
m4
%S
&
1
Pc.r ' m p - ( 1
4- 2
* m
)
1
l’errore assoluto è 1
“Questo non è da matematici,ma
4- 2
da persone serie”
p (1 p ) =
%S &
vars.r ' m (
*m)
%S
Ps.r ' m
* m
p
%S &
varc.r ' m (
*m)
%S &
%S &
vars.r ' m (
varc.r ' m (
&
1
*m) 1
*m) 1
-( 1
2
2
4- 2 m2
)
53
Facciamo un esempio:
Sm è il numero di manichini che subiscono danni
m è il numero di prove
p è la probabilità che una macchina lanciata a 40 km h contro un muro uccida 5 persone
- = 0.1 percentuale d’errore massima che la normativa europea mi chiede di non superare
+ = 0.01 probabilità sufficientemente grande di commettere come errore Cosa mi chiede la normativa europea?
Mi chiede di calcolare con una probabilità dello 0.01 un errore sufficientemente piccolo
( - ).
Se voglio soddisfare - e + è sufficiente porre:
1
>1 +
1
4- 2 m
1
<+
4- 2 m
1
m> 2
4- +
L’errore che non vorrei commettere cade in 1 + .
1
Se m > 2 ciò non accade.
4- +
Sostituendo nella formula i valori forniti otteniamo:
1
1
10 4
m> 2 =
=
= 25000
4- + 4 1 1
4
102 10 2
%S
Pc.r ' m
* m
p
&
-( 1 +
)
più 1 + è prossima a 1 più esperimenti devo fare
1 + è la probabilità tanto grande di commettere un errore tanto piccolo.
Abbiamo capito che :
%S
1
se m > 2 allora Ps.r ' m
4- +
* m
p
&
-( 1 +
)
In Soldoni: la probabilità di un evento è misurabile.
54
29-11-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Facciamo un riassunto dei passi da noi effettuati:
- definiamo
il nostro spazio campionario;
- definiamo B un evento appartenente a ;
- vogliamo individuare P ( B ) ;
- effettuiamo m esperimenti e in ognuno studiamo X i . La funzione X i vale 1 se ho
un esito positivo e 0 altrimenti;
- consideriamo S m ( B) come la somma dei successi in m prove differenti, quindi
m
Xi
S m ( B) ,
i =1
=
;
Sm ( B) = , X i e
m
m
i =1
n
S
consideriamo m circa
che è anche P( Bi ) ;
m
n
abbiamo poi effettuato una misurazione, ma ricordiamo che quando se ne effettua
una, si commette un errore, che chiameremo - , quindi
Sm ( B)
P ( B) m
vorremmo che l’errore da noi commesso sia inferiore di - e che
% S ( B)
&
P' m
P( B) - ( 1 + dove 1 + rappresenta il livello di confidenza del
* m
)
modello;
purché prendiamo m abbastanza grande, riusciamo ad approssimare in modo
migliore il valore che vogliamo ottenere;
1
se abbiamo abbastanza fondi da poter effettuare m prove tali che m- 2+ > e se tra
4
% S ( B)
&
le prove i, j con i j , P ( Bi B j ) P ( Bi ) P ( B j ) allora P ' m
P( B) - ( 1 +
* m
)
sarà soddisfatta;
nel caso in cui P ( Bi B j ) > P ( Bi ) P ( B j ) la disequazione NON risulterà più vera.
m
-
-
-
-
Se A e B sono due eventi e A
Sm ( A
B=
allora possiamo calcolare S m ( A) , S m ( B) e
S ( A B ) S m ( A) S m ( B )
B) = S m ( A) + Sm ( B ) . Quindi sappiamo anche che m
=
+
.
m
m
m
Supponiamo ora che A
P ( B A)
P ( B | A) =
P ( A)
B
, allora:
P ( A) lo calcoliamo con uno schema di
S m ( A)
;
m
P ( B A) lo calcoliamo con uno schema di
S ( B A)
m estrazioni trovando m
;
m
m estrazioni trovando
55
S m ( B A)
S ( B A)
m
S ( B A)
m
infine P( B | A) =
*
= m
= m
Sm ( A)
m
Sm ( A)
S m ( A)
m
Supponiamo di avere uno spazio campionario
(tutti i cittadini milanesi) e che Z sia il
patrimonio del cittadino milanese preso in considerazione.
: Z ( w) t} per t
. Consideriamo t
visto
Il nostro insieme degli eventi è = {w
che nella dichiarazione dei redditi si arrotonda il totale all’intero più vicino.
Possiamo semplificare questa complessa struttura dati con FZ che è una funzione di
ripartizione tale che x0
FZ ( x0 ) = P( Z x0 )
Per esempio, se supponiamo di avere un dado truccato definiamo la variabile casuale
Z che può assumere valori da 1 a 6, rispettivamente al numero che compare sulla faccia
del dado, con le rispettive probabilità (ovviamente non uguali ):
Fz HxL
1
0.8
0.6
0.4
0.2
1
2
3
4
5
6
7
x
Notiamo come il gradino tra un valore e l’altro, equivale alla probabilità che la variabile
casuale sia minore di quel valore.
56
Se Z assume i valori z1 < z2 < z3 < z4 , che hanno le loro rispettive probabilità p1 , p2 , p3 , p4 .
Avremo di conseguenza il seguente grafico:
4
Notiamo che il valore atteso /( Z ) = p1 z1 + p2 z2 + p3 z3 + p4 z4 = , zi • P( Z = zi ) quindi
i =1
+1
/( Z ) = area ( A) area ( B) =
2 (1
FZ ( x) ) dx
0
2 F ( x)dx
Z
1
0
Se poniamo z1 come il cittadino più povero di Milano e zk come il più ricco, possiamo
affermare che:
0
con x < z1 allora P( Z x) la stimiamo a
=0
m
m
con x > zk allora P( Z x) la stimiamo a
=1
m
Se invece ci chiediamo quanto vale p1 o Fz ( z1 ) (è la stessa cosa) avremo che
m
P( Z
z1 ) si può stimare con
,I
i=1
( 1 , z1 ]
( zi )
m
Nella sommatoria al numeratore abbiamo la funzione indicatrice del patrimonio del
cittadino i interrogato. La sommatoria indica, invece, il numero di cittadini con reddito
inferiore a z1 .
Infine diremo che
m
x
Fz ( x) la stimiamo con
,I
( 1,x ]
( zi )
i=1
m
57
3-12-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Si dice funzione di ripartizione di una variabile casuale X , indicata da FX , quella
funzione che ha per dominio la retta reale e codominio l’intervallo [0,1] e che soddisfa, per
ogni numero reale x , FX ( x) = P( X x) = P({w : X ( w) x}) .
Risponde ovviamente alla domanda, fissato x , quanto vale la probabilità che la variabile
casuale X assuma un valore minore o uguale a x ?
Introduciamo il concetto di funzione di densità di una variabile casuale discreta che
viene descritta nel seguente modo
Se Z è una variabile casuale discreta con valori distinti z1 , z2 ,..., zn allora la funzione f z è
definita da:
fZ ( z) =
P ( Z = zi )
se z = zi , i = 1, 2,3,..., n
0
se z
zi
che è appunto la funzione di densità discreta di Z .
Se lo spazio campionario
è finito (
un numero finito di valori distinti.
< +1 ) allora anche la variabile casuale assumerà
Indichiamo con Z la variabile casuale che ci accompagnerà nei ragionamenti seguenti.
In conoscenza dello spazio campionario finito definiamo k
quindi:
z1 < z2 < ... < zk 1 < zk
Ovviamente (proprietà):
lim FZ ( x) = 0
x
1
lim FZ ( x) = 1
x
+1
Se zk è un valore tale che P( Z = zk ) = p > 0 allora FZ è discontinua in zk .
58
Fz HxL
1
0.8
0.6
0.4
0.2
-2
2
4
6
a
x
b
+1
Il valore atteso /( Z ) = area ( A) area ( B) =
2 (1
0
FZ ( x) )dx
0
2 F ( x)dx
Z
1
Non disperiamoci per la visione di un integrale ma analizziamo per ordine.
Siamo a conoscenze che l’integrale rappresenta l’area di sottografico di una funzione. Nel
primo caso, ovvero la determinazione dell’area(A) dobbiamo trovare l’area del soprastante
la funzione di ripartizione. Siccome la nostra funzione di ripartizione potrà prendere valori
+1
tra 0 e 1 escludiamo l’area di sottografico e ricaviamo l’area(A) pari a
2 (1
FZ ( x) )dx . Per
0
0
l’area(B) invece è scontato in quanto si tratta dell’area di sottografico quindi
2 F ( x)dx .
Z
1
Ricordiamo inoltre che il valore atteso o media, indica dove sono centrati i valori della
variabile casuale.
P (a < Z
b ) = FZ (b) FZ (a)
59
FZ ( x) = P ( Z x )
Ma attenzione, la probabilità è incognita e di conseguenza anche la funzione di
ripartizione, ma possiamo pensare di analizzare la funzione di ripartizione in un punto x0 e
vedere se sarà valida anche negli altri punti x .
FZ HxL
1500
1250
1000
750
500
250
-10
-5
Quanto vale il valore di FZ ( x0 ) ?
Vogliamo quindi misurare P ( Z
5
x0
10
x
x0 ) .
Possiamo pensare ad esempio che se il cittadino milanese ha un patrimonio netto minore
o uguale ad x 0 (un fissato patrimonio netto) allora la variabile casuale bernoulliana X i
assumera valore 1, altrimenti 0.
X 1 = I ( z1 ) funzione indicatrice
( 1 , x0 ]
X 2 = I ( z2 )
( 1 , x0 ]
X 3 = I ( z3 )
( 1 , x0 ]
...
X m = I ( zm )
( 1 , x0 ]
Per stimare il valore, nel punto x 0 , di FZ ( x0 ) scelgo m cittadini e domando il loro
patrimonio netto zi .
60
FZ ( x0 ) = P ( Z
x0 ) stimato
m
,
I ( zi )
( 1 , x0 ]
=
m
= Gm ( x0 , z1 , z2 ,..., zm ) funzione di ripartizione empirica o campionaria
i =1
Come possiamo vedere G è costitutità dalle zi ordinate in modo da formare una statistica
d’ordine. Quindi attenzione a non farsi portar fuori strada dal nome funzione di ripartizione
empirica in quanto non è una funzione di ripartizione ma una statistica perchè è una
funzione del campione.
Possiamo comprimere la scrittura in Gm ( x0 , Z ) dove m indica la numerosità del campione.
Livello di confidenza
1 +
P ( Gm ( x0 , Z ) FZ ( x0 )
-) 1 +
%1 m
&
/ ( Gm ( x0 , Z ) ) = / ' , I ( zi ) ( =
* m i =1 ( 1, x0 ]
)
m
m
1
1
m
P ( Z i x0 ) = , FZ ( x0 ) = FZ ( x0 )
,
m i =1
m i =1
m
in conclusione / ( Gm ( x0 , Z ) ) = FZ ( xo )
P ( Gm ( x0 , Z ) FZ ( x0 )
var(Gm ( x0 , Z ))
-) 1
-2
Troviamo la varianza:
%1 m
& 1
% m
&
var(Gm ( x0 , Z )) = var ' , I ( zi ) ( = 2 var ' , I ( zi ) ( =
x
x
(
,
]
(
,
]
1
1
0
0
* m i =1
) m
* i =1
)
=
&
1 % m
& % m m
I
z
(
)
+
/ ZZ
/ ( Zi ) / ( Z j ) ( =
2 ' , ( 1 , x ] i ( ' ,, ( i j )
0
m * i =1
) * i =1 j =1
)
con i
j
Ma siccome le m osservazioni sono indipendenti (il nostro giornalista non chiama a casa
di
una
persona
e
poi
si
fa
passare
tutta
la
famiglia)
allora
P ( Z i = 1 $ Z j = 1) P ( Z i = 1) P ( Z j = 1) è uguale 0.
var(Gm ( x0 , Z )) =
=
1
var
m
(
1 % m
, var
m2 '* i =1
I ( zi )
( 1 , x0 ]
var(Gm ( x0 , Z )) =
)
1
var
m
(
(
(
I ( zi )
( 1 , x0 ]
)
& 1
I ( zi ) ( = 2 m var
1 , x0 ]
) m
)
61
(
)
I ( zi ) =
( 1 , x0 ]
Ora:
- >0
P ( Gm ( x0 , Z ) FZ ( x0 )
-) 1
P ( Gm ( x0 , Z ) FZ ( x0 )
-) 1
P ( Gm ( x0 , Z ) FZ ( x0 )
-)
var(Gm ( x0 , Z ))
-2
FZ ( x0 )(1 FZ ( x0 ))
m- 2
1
1
4m- 2
Quindi comunque fissato x
P ( Gm ( x0 , Z ) FZ ( x0 )
-) 1
1
4m- 2
Fissiamo m , e prendiamo il campione Z1 , Z 2 ,..., Z m (le variabili casuali di m esperimenti) che
seguono tutte la probabilità FZ ( x) . m sarà la numerosità del nostro campione.
Diremo campione casuale se dati a, b, c, d arbitrari e i
P ( a < Z i b $ c < Z j d ) = P ( a < Z i b ) P (c < Z j d )
Variabili casuali a due a due indipendenti.
j:
m
Parte della nostra stima sarà, dopo aver fatto l’esperimento, calcolare
,I
i =1
( 1 , x0 )
( Zi )
m
%
&
' , I ( 1, x0 ) ( Z i ) (
( Stimatore non distorto
Inoltre possiamo affermare che FZ ( x) = / ' i =1
m
'
(
'
(
*
)
m
Se Z è un campione casuale di numerosità m estratto dalla popolazione secondo la legge
FZ allora Gm ( x0 , Z ) è una successione consistente di stimatori non distorti di FZ ( x) .
var(Gm ) =
costante
m m
(
a)
x
- >0 + >0
/ ( Tm
2
)
m
1
1
0
0
P ( Gm ( x0 , Z ) FZ ( x0 )
-) 1
1
4m- 2
62
10-12-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Inizio Ripasso:
Consideriamo la tripletta
(
, , 3)
Dato B
• Nel caso del modello di estrazione con reimissione Sm ( B ) segue la legge
binomiale di parametri m e P ( B ) .
•
Sia nel caso con reimmissione sia nel caso senza reimmissione il valore atteso è:
Ec.r ( Sm ( B ) ) = mi P ( B )
s .r
1
1
Ec.r ( Sm ( B ) ) = imi P ( B )
m s .r
m
% S ( B) &
Ec.r ' m
( = P( B)
m )
s .r *
E’ interessante vedere che sebbene non conosciamo P ( B ) , sappiamo che il valore
atteso è uguale P ( B ) .
Sm ( B )
è uno stimatore non distorto:
m
stimatore in quanto sappiamo che il valore atteso è uguale a P ( B ) ;
IMPORTANTE:
-
non distorto in quanto il suo valore atteso è uguale a P ( B ) . Abbiamo anche
stimatori distorti per eccesso (usiamo il simbolo > ) o stimatori distorti per difetto
(usiamo il simbolo < )
•
varc.r ( S m ( B ) ) = mP ( B ) (1 P ( B ) )
spostiamo la m al primo membro:
1
varc.r ( S m ( B ) ) = P ( B ) (1 P ( B ) )
m
moltiplichiamo entrambi i membri per
1
:
m
1 1
1
varc.r ( S m ( B ) ) = P ( B ) (1 P ( B ) )
mm
m
P ( B ) (1 P ( B ) )
1
S
B
var
=
(
)
(
)
.
c
r
m
m2
m
dato che per estrarre una costante dalla varianza, bisogna elevarla al quadrato, per
inserirla dovremo calcolare la sua radice quadrata.
63
% 1
& P ( B ) (1 P ( B ) )
Sm ( B ) ( =
varc.r '
2
m
* m
)
% S ( B ) & P ( B ) (1 P ( B ) )
1
varc.r ' m
(=
m
4m
* m )
P ( B ) (1 P ( B ) )
m
0 per m
Dato che sappiamo che il massimo
1
di P ( B ) (1 P ( B ) ) è
4
+1
Cosa dice la legge dei grandi numeri?
- >0
+ >0
% S ( B)
&
P' m
P (B) - ( 1 +
' m
(
*
)
Sappiamo che Sm ( B ) = I B1 + I B2 + ... + I Bm
m- 2+ >
1
4
Sm ( B ) I B1 + I B2 + ... + I Bm
=
m
m
La legge dei grandi numeri può essere riassunta in questo modo:
sia nel caso con reimissione sia nel caso senza reimissione, la successione di statistica di
Sm ( B )
è una successione consistente di stimatori non distorti della probabilità di
m
successo P ( B ) .
Fine Ripasso
Consideriamo di nuovo la tripletta
= { , , B, B c , A, Ac , A
B, A
B}
(
, , 3)
Per ogni singolo evento posso calcolarne la probabilità.
Sm ( B )
m
S (B)
P ( Bc ) 4 1 m
m
S ( A)
P ( A) 4 m
m
S ( A)
P ( Ac ) 4 1 m
m
S ( A) Sm ( B )
P ( A B) 4 m
+
m
m
P ( B) 4
Sm ( A
m
B)
=
Sm ( A) + S m ( B ) Sm ( A
m
64
B)
Se voglio calcolare la probabilità condizionata P ( B | A) =
P(B
A)
P ( A)
Guardiamo separatamente il numeratore e il denominatore:
P(A
B) 4
P ( A) 4
Sm ( A
B)
m
Sm ( A)
m
Sm ( A B )
S ( A B)
S ( A B)
m
m
4
= m
•
= m
S m ( A)
P ( A)
m
Sm ( A)
Sm ( A)
m
Sm ( A B ) è il numero di volte in cui accanto alla proprietà B ho trovato la proprietà A
P( A
B)
Sm ( A ) è il numero di in cui si è presentata la proprietà A .
Consideriamo la tripletta ( , , 3 )
Consideriamo la variabile casuale Z
x
(
P {"
)
x} = FZ ( x )
, Z (" )
Funzione di ripartizione empirica
Consideriamo m successioni di variabili casuali che modellano m esperimenti sotto le
stesse condizioni sperimentali, ma senza dipendenza tra un esperimento e gli altri.
In corrispondenza di ciascuna estrazione andiamo a calcolare FZ ( x) = P ( Z
m
FZ ( x ) 4 , I (
1, x]
i =1
Consideriamo
Z:
( Zi ) 6 Gm ( x; Z1 ,..., Z m ) = Gm ( x; Z )
(
, , 3)
FZ ( x ) 4 Gm ( x; Z )
/(Z ) =
+1
2 (1
FZ ( x ) ) dx
0
0
2
1
k
FZ ( x ) dx = , z j P ( Z = z j )
j =1
k
/( Z ) 4 , z jP( Z = z j )
j =1
65
x ) cioè :
Per misurare questa quantità:
supponiamo di conoscere quali valori la variabile casuale può assumere
Z ( ) = {Z1 , Z 2 ,..., Z k } . Ci resta però da decidere come dobbiamo stimarli.
Li stimeremo utilizzando la legge dei grandi numeri.
Consideriamo Z1 , Z 2 ,..., Z m ed estraiamo m campioni da FZ . Dobbiamo misurare
P(Z = zj ) .
I{ z } =
j
1 se Z=z j
0 altrimenti
m
P(Z = z j ) =
, I{ } ( Z )
i
zj
i =1
m
m
k
, I{ } ( Z )
j =1
m
/(Z ) 4 , zj
zj
i =1
k
, z I{ } ( Z ) = z
j =1
j
i
zj
i
1 m k
1 m
= ,, z j I{z } ( Z i ) = , zi
j
m i =1 j =1
m i =1
zi è l’unico addendo diverso da 0
i
m
E (Z ) 4
%
' , zi
P ' i =1
' m
'
*
,z
i =1
i
m
&
(
-( 1 +
(
(
)
m
/(Z )
m
La statistica
,z
i =1
m
i
è detta media campionaria.
% m
&
' , Zi (
La media campionaria è uno stimatore non distorto di / ( Z ) se / ' i =1 ( = / ( Z )
' m (
'
(
*
)
m
%
&
' , Zi ( 1 m
/ ' i =1 ( = , / ( Z i ) =/ ( Z i ) = / ( Z )
' m ( m i =1
'
(
*
)
Ogni /( Z i ) = /( Z ) perché tutte le Z i hanno la stessa distribuzione, la stessa legge di
probabilità e lo stesso valore atteso.
66
% m
' , zi
P ' i =1
' m
'
*
% m &
' , zi (
var ' i =1 (
&
' m (
(
'
(
*
)
-( 1
2
(
(
)
/(Z )
Prossimo passo è quindi studiare:
% m &
' , zi ( 1
% m &
var ' i =1 ( = 2 var ' , zi ( =
' m ( m
* i =1 )
'
(
*
)
% m &
Nasce un problema: studiare var ' , zi (
* i =1 )
Cominceremo a studiare la varianza di una somma di 2 variabili casuali Z per capire
come si risolva una sommatoria.
Articolo V.
Articolo VI. Esercizio:
Date due variabili casuali Z1 e Z 2 calcolare var ( Z1 + Z 2 ) .
(
var ( Z1 + Z 2 ) = E ( Z1 + Z 2
(
= E ( Z1
E ( Z1 ) )
2
E ( Z1 + Z 2 ) )
) + E (( Z
2
= var ( Z1 ) + var ( Z 2 ) + 2 E ( Z1
E ( Z2 ))
2
) = E ((( Z
2
1
) + 2E ( Z
1
E ( Z1 ) ) ( Z 2
E ( Z1 ) ) + ( Z 2
E ( Z1 ) ) ( Z 2
E ( Z2 ))
)
2
)=
E ( Z2 )) =
E ( Z2 ))
________________________________________________________________________
Ricordiamo le definizione di covarianza: cov ( Z1 , Z 2 ) = E ( Z1 E ( Z1 ) ) ( Z 2 E ( Z 2 ) )
(
m m
% m & m
var ' , zi ( = , var ( zi ) + 2,, cov ( Z i , Z j )
i =1 j =1
* i =1 ) i =1
quindi
% m &
' , zi ( 1 % m
m m
&
var ' i =1 ( = 2 ' , var ( zi ) + 2,, cov ( Z i , Z j ) (
' m ( m * i =1
i =1 j =1
)
'
(
*
)
Possiamo ora scrivere la disuguaglianza in questo modo:
% m
' , zi
P ' i =1
' m
'
*
/(Z )
&
(
-( 1
(
(
)
m
m
m
, var ( zi ) + 2,, cov ( Zi , Z j )
i =1
i =1 j =1
2 2
m-
67
)
13-12-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
A conoscenza che il valore atteso di una variabile casuale Z è pari a:
• µZ = / ( Z )
e la varianza:
• 0 Z 2 = var ( Z )
Affermiamo attraverso la legge di Tchebycheff che:
•
- >0
P( Z
µZ
-) 1
0Z2
-2
Ponendo:
- = r0 Z
P( Z
µZ
r0 Z ) 1
1
r2
Facendo m prove, osserverò (notare bene il futuro)
Z1 , Z 2 ,..., Z m variabili casuali
FZ1 = FZ2 = ... = FZm distribuite tutte secondo la stessa funzione di ripartizione
Esprimendo tutto ciò in linguaggio tecnico diremo:
Consideriamo un campione Z1 , Z 2 ,..., Z m estratto dalla popolazione FZ
Proponiamo ora uno stimatore di µ Z (il valore atteso) basandoci sul campione.
m
,Z
i =1
m
i
= Z ( m ) che definiamo media campionaria (stimatore µ Z )
Ora ci domandiamo se la media campionaria Z ( m ) è uno stimatore non distorto del valore
atteso
m
%1 m & 1 m
/ ( Z ( m) ) = / ' , Zi ( = , / ( Zi ) = / ( Z ) = / ( Z )
m
* m i =1 ) m i =1
Abbiamo dimostrato che la media campionaria è uno stimatore non distorto del valore
atteso.
68
7 >0
(
P Z(m)
µZ
7
)
1
var ( Z ( m ) )
72
Bene... Solito problema, dobbiamo determinare la varianza della media campionaria.
Esplicitiamola da definizione:
(
var ( Z ( m ) ) = / ( Z ( m )
µZ )
2
)
Errore quadratico medio
(varianza)
Mezzo con il quale stimiamo
Quantità che vogliamo
stimare
Tips: Se noi confrontiamo gli stimatori non distorti guardando i loro errori quadratici medi,
preferiamo quelli che hanno un errore quadratico medio piccolo.
Procediamo alla nostra ricerca della varianza della media campionaria
% m
' , Zi
var ( Z ( m ) ) = var ' i =1
' m
'
*
&
( 1
% m &
( = 2 var ' , Z i (
( m
* i =1 )
(
)
% m &
Ma cosa vale ora var ' , Z i ( ?
* i =1 )
m m
% m & m
var ' , Z i ( = , var ( Z i ) + ,, cov ( Zi , Z j )
i =1 j =1
* i =1 ) i =1
con i
j
Non spaventiamoci dalla mancaza del due del doppio prodotto, non è stato dimenticato
ma imponendo i j avremmo sia cov ( Zi , Z j ) che cov ( Z j , Z i ) .
Essendo sotto le stesse condizione sperimentali le varianze sono tutte uguali quindi è
lecito scrivere m var ( Z ) .
Riprendiamo:
% m
&
' , Z i ( m var ( Z ) 1
+ 2
var ' i =1 ( =
m
m2
' m (
'
(
*
)
m
m
,, cov ( Z , Z )
i =1 j =1
i
j
cm ( m 1)
negativo. Quindi viene
m2
imposta la condizione che c < 0 . In questo modo possiamo dire:
Ora chiamiamo cov ( Zi , Z j ) = c e otteniamo quindi
69
% m
' , Zi
var ' i =1
' m
'
*
&
(
(
(
(
)
var ( Z )
m
Ma ci siamo mai chiesti quale sia il significato della covarianza di due variabili casuali? No,
quindi cerchiamo di capirlo!
((
cov ( Zi , Z j ) = / Z i
•
µZ
i
)(Z
j
))
Ora se consideriamo i = j otteniamo la varianza della variabile casuale in esame,
infatti:
(
cov (Y , Y ) = / (Y
•
µZ
j
E (Y ) )
2
) = var (Y ) = / (Y )
Ora invece consideriamo il caso i
((
cov ( Zi , Z j ) = / Z i
µZ
i
( / (Y ) )
2
)(Z
j
µZ
j
2
j:
)) = / (( Z Z
i
j
µZ Z j µZ Zi + µZ µZ
i
j
i
j
)) =
Fermiamoci ed evidenziamo alcuni elementi della nostra espressione:
/ µ Zi Z j = µ Zi / ( Z j ) = µ Zi µ Z j
(
)
(
)
/ µ Z j Z i = µ Z j / ( Z i ) = µ Z j µ Zi
Di conseguenza, con le relative sostituizioni e semplificazioni immediate otteniamo:
(
cov ( Zi , Z j ) = / ( Z i Z j )
)
µZ µZ
i
j
Ma ora, siccome siamo “curiosi” (forse un po sadici), ci poniamo la domanda quando
cov ( Zi , Z j ) = 0 ? Ovvero quando c = 0 ?
Ok, iniziamo ad arrampicarci sugli specchi...
cov ( Zi , Z j ) = 0
?
/ ( Zi Z j ) = / ( Zi ) / ( Z j )
?
In generale è falso, ma vogliamo vedere in questo caso se è effettivamente possibile
scriverlo.
Per semplificare la scrittura supponiamo Z i = X e Z j = Y
?
/ ( XY ) = / ( X ) / (Y )
70
Sia ora h il numero di valori distinti che la variabile casuale X può assumere e k i relativi
valori che può assumere la variabile casuale Y.
h
k
,, x y P( X = x
j =1 l =1
j
l
j
$ Y = yl )
primo membro
% h
&% k
& h k
' , x j P( X = x j ) ( ' , yl P(Y = yl ) ( = ,, x j yl P( X = x j ) P(Y = yl )
) j =1 l =1
* j =1
) * l =1
secondo membro
Attenzione, non stiamo dimostrando nessun teorema, ma cercando un ipotesi valida per
cui valga l’uguaglianza.
Quindi:
P ( X = x j $ Y = yl ) = P ( X = x j ) P (Y = yl )
Ma ecco che ritornano in gioco le nostre solite “regolette” dell’inzio del corso:
P ( A j Bl ) = P ( Aj ) P ( Bl )
E ciò risulta vero se e solo se i due eventi sono indipendenti.
Ora se le m prove effettuate sono indipendenti possiamo affermare che:
m prove sono effettuate sotto condizione di campionamento casuale!!!
% m
' , Zi
var ' i =1
' m
'
*
&
( var ( Z )
(=
m m
(
(
)
1
0
% m
&
' , Zi (
/ ' i =1 ( = / ( Z )
' m (
'
(
*
)
Quindi una semplice considerazione che salta subito all’occhio, è che più grande è il
var ( Z )
campione, tanto più piccolo sarà l’errore quadratico medio, in quanto
0.
m m 1
Possiamo così dire che è la successione di stimatori di µ Z gode della consistenza in
media quadratica in quanto il limite della varianza con m all’infinto tende a 0.
71
Riassumiamo per evidenziare il fatto che:
% m
&
' , Zi (
/ ' i =1 ( = / ( Z )
' m (
'
(
*
)
non richiede il campionamento casuale
% m
' , Zi
var ' i =1
' m
'
*
richiede il campionamento casuale
&
( var ( Z )
(=
m
(
(
)
Verifichiamo ora se la successione Z ( m ) è una successione semplicemente consistente:
- >0
P( Y
µY < - ) 1
var (Y )
-2
ma è anche vero che (notare
P( Y
µY
P( - < Y
-)
- ) P ( Y µY < - ) 1
µY
-) 1
var (Y )
var (Y )
-2
-2
Quindi riprendendo il discorso sulla media campionaria
% m
&
' , Zi
(
var ( Z )
P ' i =1
µZ < - ( 1
-2
' m
(
'
(
*
)
dove var ( Z ) è la varianza della popolazione
% m
&
' , Zi
(
var ( Z )
µZ < - ( 1
1 P ' i =1
-2
' m
(
'
(
*
)
Per il Teorema dei due carabinieri
- >0
% m
&
' , Zi
(
i =1
'
lim P
µZ < - ( = 1
m 1
' m
(
'
(
*
)
Siccome il limitie tende a 1 possiamo affermare che la successione è semplicemente
consistente.
72
Però possiamo svelare un trucco e dire che se uno stimatore è consistente in media
quadratica, esso sarà anche uno stimatore semplicemente consistente, ma attenzione non
è necessariamente vero il viceversa.
P ( µZ - < Z ( m )
µZ + - ) = FZ
(m)
( µZ + - )
FZ( m ) ( µZ - )
FZ( m ) ( x )
Questa distanza vale 1
quando m va all’infinito
x
µZ -
µZ
µZ + -
Vogliamo calcolare il limite di una funzione che non conosco... e la nostra arte di
arrampicarci sugli specchi deve tornarci in aiuto.
Ma notiamo dal grafico e dalle considerazioni fatte in precedenza che:
- >0
lim FZ( m ) ( µ Z + - ) = 1
m
1
- >0
lim FZ( m ) ( µ Z - ) = 0
m
1
Non so come sia distribuita FZ( m ) ( x ) ma so che:
lim FZ( m ) ( x ) =
m
1
1
0
µ Z (continua da destra)
se x µ Z
se x
73
17-12-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Poniamoci la seguente domanda:
arrivati alla stazione di Cernobil, quanto ci metterà la prima particella
a raggiungere il
mio corpo?!?
Consideriamo le variabili casuali Z1 , Z 2 ,..., Z m i.i.d. (indipendenti ed identicamente
distribuite). Il valore che assume ogni Z i è pari al tempo passato dal mio arrivo alla
stazione al momento in cui vengo colpito dalla i-esima particella .
Consideriamo ora la funzione di ripartizione empirica Gm ( x, Z ) =
1 m
, I(
m i =1
1, x]
( Zi ) .
Consideriamo con k(i ) il numero di volte che compare Z i .
/(Z ) 4
(
)
1
1 m
i k(1) Z (1) + k( 2) Z ( 2) + ... + k( m ) Z ( m ) = , Z i 6 Z ( m ) che è la media campionaria
m
m i =1
estratta da una popolazione Z.
Facciamo notare che / ( Z ( m ) ) = / ( Z ) di conseguenza
di / ( Z ) e che var ( Z ( m ) ) =
Se m
(
+1 allora P Z ( m )
var ( Z )
m
che è successione consistente.
/(Z ) < -
)
1
Della FZ( m ) sappiamo soltanto che, con m
-
se x > / ( Z ) tende a 1;
-
se x = / ( Z ) tende a 1;
-
se x < / ( Z ) tende a 0.
1 m
, Zi è uno stimatore non distorto,
m i =1
var ( Z )
m- 2
tende a 1.
+1 :
Se consideriamo un’altra variabile casuale Y , FY e FZ saranno differenti, ma FY( m ) e FZ( m ) con
/ ( Z ) = / (Y ) saranno molto simili (tendono agli stessi valori).
Se un fenomeno casuale può essere governato con una variabile casuale uguale alle
sommatorie di X i , allora la legge di probabilità è universale.
Se prendo due diverse successioni le loro funzioni di ripartizione hanno lo stesso limite e
si devono assomigliare. (“Teorema del limite centrale”)
74
Definita T come variabile casuale del tempo passato da un certo avvenimento ci
chiediamo la relazione esistente tra
P (T > t + s | T > s ) e P (T > t )
Nel ragionamento comune si va a pensare che la prima sia maggiore della seconda, ma in
realtà, data l’indipendenza di ogni evento, la probabilità presa in questione è la stessa.
Esempio:
Il 53 non esce sulla ruota di Venezia da molte settimane (è un ritardatario). La probabilità
che esca tra 5 estrazioni, dato che non esce da 53 estrazioni, è uguale alla probabilità che
esca tra 5 estrazioni senza sapere da quanto tempo non esce.
Vediamo quanto vale la probabilità di avere un successo alla prima prova:
P(T = 1) = P( B1 ) = p
mentre la probabilità di avere successo alla seconda
P (T = 2) = P ( B1 B2 ) = (1 p ) p
la probabilità di avere successo alla k-esima prova sarà
P (T = k ) = P ( B1 B2 ... Bk 1 Bk ) = (1 p ) k 1 p
Fissato k > 0 , la probabilità che il primo successo avvenga dopo k estrazioni, è la
probabilità che le prime k estrazioni siano tutte insuccessi:
P (T > k ) = P ( B1 B2 ... Bk ) = (1 p ) k = q k
Dimostriamo ora che P (T > h + k | T > h) = P (T > k ) :
P(T > h + k | T > h) =
P ( (T > h + k )
(T > h ) )
P(T > h)
notiamo come al numeratore, l’intersezione delle due probabilità è uguale a P(T > h + k ) in
quanto, se consideriamo P(T > h + k ) come l’insieme A e P(T > h) come l’insieme B, ci
rendiamo conto che l’insieme A è contenuto nell’insieme B, quindi la loro intersezione è
uguale all’insieme A stesso. Quindi:
P ( (T > h + k )
(T > h ) )
P(T > h)
=
P(T > h + k ) q h + k
= h = q K = P (T > k )
P(T > h)
q
Poniamo P(T > x) = H ( x) per x
allora
H (h + k )
H (k ) =
H (h)
Possiamo notare quindi che gode della seguente proprietà: H (h + k ) = H (h) H (k ) .
Chiediamoci quanto vale la probabilità che T sia pari:
P(T pari) = P(T = 2 8 T = 4 8 T = 6 8 ...)
Poniamo (T = 2) = C2 e(T = 4) = C4 e così via.
75
Dato I = insuccesso e S = successo , sappiamo dunque che vorremmo avere IS o IIIS o IIIIIS .
Quindi:
1
P(C2 8 C4 8 C6 8 ...) = , P(T = 2 j )
j =1
1
1
j =1
j =1
, P(T = 2 j) = , q 2 j 1 p =
p 1 2 j
p% 1
(q ) = serie geometrica = '
,
q j =1
q * 1 q2
&
1(
)
Quanto vale P ( D = t )?
9 P ( ( D > t + s ) | D > s ) = P( D > t )
9D 0
Notiamo che non si parla più di successione ma dell’insieme dei numeri reali
H ( X ) = 1 FD ( x) = P( D > x)
H (t ) =
H (t + s )
H (s)
Non sappiamo la funzione di ripartizione, non sappiamo come è fatta H , ma sappiamo
che gode di quelle proprietà.
H (t + s ) = H (t ) H ( s )
Chi è la funzione che trasforma la somma in prodotto?
L’esponenziale
H =e
: >0
:t
FD (t ) = 1 e
:t
FD (t ) = I (t ) (1 e
(0, +1 )
:t
)
P( D = t ) = 0
Il salto di discontinuità è pari a 0.
FD HtL
1
0.8
0.6
0.4
0.2
2
4
6
8
10
t
76
20-12-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Quando consideriamo un campione casuale di m variabili casuali Z1 , Z 2 ,..., Z m , la media
1 m
, Zi con m
m i =1
proprio valore atteso / ( Z ) .
campionaria
1 , avrà un salto di discontinuità nel punto coincidente con il
Sottolineiamo ora alcuni punti importanti:
- con m 1 studiamo variabili casuali non limitate;
m
-
con
,Z
i =1
i
avremo variabili casuali non discrete;
m
avremo variabili casuali continue quando possono assumere tutti i valori reali.
DISTRIBUZIONE GEOMETRICA
P(T = k ) = I{1,2,...} (k )i pq k
1
(ci chiediamo la probabilità che il primo successo avvenga alla
k-esima estrazione).
FT (k ) = (1 q =; >< ) I{1,2,...} (k )
k
FTHxL
0.6
0.5
0.4
0.3
0.2
0.1
1
2
3
4
5
6
7
x
Dopo le prime k estrazioni, avremo al punto x = k un salto di discontinuità di altezza p . Il
secondo salto sarà di altezza pq , il terzo di altezza pq 2 , il quarto pq3 e così via...
1
/ (T ) = , kpq k 1 =
k =1
1 n
=
p n
%n &
Questo significa che più è probabile un successo elementare ' ( , meno dovremo
* n )
aspettare il primo successo.
77
DISTRIBUZIONE ESPONENZIALE
Consideriamo la variabile casuale D 0 .
Sappiamo che P ( D > s ) = P ( D > t + s | D > t ) .
: > 0 : FD ( x) = I (0,+1 ] ( x)i(1 e : x )
FD HxL
2
4
6
8
10
x
0.9
0.8
0.7
0.6
Fissato x sappiamo che P ( D = x ) = 0 in quanto il grafico è formato da una linea continua
e non ha salti di discontinuità.
0
P( D > x )
P( x - < D
notiamo come con - > 0 :
0 P( D = x ) e : ( x +- ) e : ( x
x + - ) = FD ( x + - ) FD ( x - ) = 1 e
-)
=e
:x
(e
:-
e
:-
) < lim(e
:-
-
0
e
:-
: ( x +- )
1+ e
: (x - )
)=0
Quindi 0 P ( D = x ) 0 . Di conseguenza abbiamo dimostrato che il salto di discontinuità
nel punto x è nullo.
Il / ( D ) lo calcoleremo con l’ area ( A) , in quanto non possiamo calcolarlo con la
, xP( D = x) in quanto non possiamo elencare tutti i valori che D può assumere.
x 0
78
1
/ ( D ) = 2 (1 FD ( x))dx
0
quindi / ( D ) 4
1
:
0
2F
D
1
1
1
0
0
( x)dx = 2 (1 FD ( x))dx = 2 (1 1 + e
:x
1
)dx = 2 e
1
:x
0
?e :x @
1
dx = ;
< = 0+
:
= : >0
ma noi non conosciamo : , come la calcoliamo?!?
Se prendiamo un campione casuale di m elementi D1 , D2 ,..., Dm non possiamo tracciarne
direttamente il grafico. Useremo a questo scopo Gm ( x, D) =
1 m
, I(
m i =1
1, x ]
( Di ) .
F AHxL
1
0.8
0.6
0.4
0.2
1
D(1)
/( D) 4
1
:
4
2
3
4
5
6
D(4)
7
x
D(7) ... D(m)
1
( D(1) + D(2) + ... + D( m) ) quindi
m
1 m
, Di lo stimo con la media campionaria
m i =1
79
10-01-2005
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Facciamo un ripasso veloce.
DISTRIBUZIONE GEOMETRICA
Vengono effettuate m prove. La probabilità di successo a una singola prova è uguale a p.
P(T > k ) = q k
FT (k ) = P (T k ) = 1 P (T > k ) = 1 q k
FT ( x) = I[1, 1 ) ( x) * (1 q =; >< )
x
P(T = x) = I{1,2,...} ( x)i pq x
1
Ricordiamo il teorema di “assenza di memoria”
P (T > k + h | T > h) = P (T > k )
DISTRIBUZIONE ESPONENZIALE
La variabile casuale D assume un valore reale non negativo che rappresenta il tempo
passato dal punto di origine da noi scelto e il primo successo.
Anche qui
P( D > s + t | D > s ) = P( D > t )
FD (t ) = I (0,1 ) (t )i(1 e : t )
: >0
P( D = x) = 0
P( D = x1 8 D = x2 ) = P( D = x1 ) + P( D = x2 ) = 0 + 0 = 0
con b > a
80
P (a < D b) = FD (b) FD (a ) = (1 e
:b
) (1 e
:a
)
se b tende ad a, la probabilità vale 0 in quanto è uguale a e
:b
( e
:a
)
Ma quanto rapidamente accade questo?
P (a D b)
e :b ( e :a )
=
b a
b a
:b
:a
e
( e )
=: e :a
lim
b a
b a
Definiamo densità di probabilità di D
d
d
d
A D ( x) = FD ( x) = (1 e : x ) = ( e
dx
dx
dx
b
2 A ( x ) dx = F ( b )
D
D
FD ( a ) = P ( a
:x
) =: e
:x
D b)
a
Proviamo ora a fare lo stesso discorso per la v.c. geometrica:
d
FT ( x) = 0
dx
b
d
2a dx FT ( x )dx = 0 accade che dove esiste, la derivata di FT ( x ) è nulla.
Confrontiamo ora i casi appena visti:
ESPONENZIALE
GEOMETRICA
f D ( x ) = P ( D = x) = 0
fT ( x) = P (T = x)
A D ( x) =
d
FD ( x)
dx
AT ( x ) =
Def: Una variabile casuale X si dice “continua” se
b
d
2 dx F
X
( x)dx = P (a
X
d
FT ( x) = 0
dx
a, b a < b abbiamo
b)
a
dove
d
FX ( x) = A X ( x)
dx
Quindi comunque si fissa una ragionevole regione A della retta la P( X
A) = 2 A X ( x)dx
A
81
/ ( D) =
+1
=
2 (x
0
+1
+1
0
0
2 (1 FD ( x))dx = 2
dx
(1 FD ( x))dx = = uv
dx
+1
0
1
d
+1
(1 FD ( x))dx) + ( x(1 FD ( x)) 0 = = 2 ( x A D ( x)dx) + ( xe
dx
0
dx
=u
dx
/(D
+1
)= 2 x A
2
D
( x)dx
1
se x < 0
0
AD ( x ) =
:e
:x
se x > 0
var ( D ) = / ( D 2 ) / ( D )
FD ( x ) = (1 e
:x
2
) I ( x)
(0, +1 )
: =?
/( D) =
d
2 u dx (1
FD ( x))dx =
0
(1 FD ( x)) = v
2
+1
1
:
D1 + D2 + ... + Dn
1
stimatore di
n
:
82
:x
1
1
) = 2 ( x A D ( x)dx)
0
0
14-01-2005
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Variabili Casuali “Continue”
Una variabile casuale X viene detta continua se esiste una funzione A X tale che
x
FX ( X ) = P ( X
P(X
x ) = 2 A X (k )dk per ogni numero reale x .
1
B) = 0
length ( B ) = 0
BC
P( X
AX : A
A) = 2 A X ( x ) dx
b
P ( a < X < b ) = 2 A X ( x ) dx
a<b
a
Siccome siamo nel continuo l’uguale nei segni di minore e maggiore può essere omesso
in quanto la probabilità nel punto è pari a 0.
dFX ( x )
dx
= AX ( x)
AX ( x) 0
monotona decrescente
9 +1
9 2 A X ( x ) dx = 1
1
/( X ) =
+1
2 xA ( x ) dx
X
1
/( X 2 ) =
+1
2 x A ( x ) dx
2
X
1
var ( X ) =
+1
2 (x
/ ( X ) ) A X ( x ) dx
2
1
P(x
x + x ) = FX ( x + x ) FX ( x ) = A X x + ...errore trascurabile
X
FX ( x + x ) FX ( x )
0
x
A X ( x ) = lim
x
Variabili Casuali Discrete
T1 numero estrazioni che aspetto affinchè esca il numero 53
T2 numero di tentativi per cui esca di nuovo il numero 53
P (T1 = x1 $ T2 = x2 ) = P (T1 = x1 ) P ( T2 = x2 )
P (T1
( a1 , b1 ) $ T2 ( a2 , b2 ) ) = P (T1 ( a1 , b1 ) ) P (T2 ( a2 , b2 ) )
/ ( T1T2 ) = / (T1 ) / (T2 )
83
Variabili Casuali Continue
D1 tempo nel quale aspetto che passi il primo autobus a Napoli
D2 tempo nel quale aspetto che passi il secondo autobus a Napoli
Non ho informazioni se D1 arriva prima di D2 dato che il traffico a Napoli è disordinato. Si
tratta di variabili casuali indipendenti.
Vediamo quindi di descrivere questo fenomeno di indipendenza.
P ( D1 = x1 $ D2 = x2 ) = P ( D1 = x1 ) P ( D2 = x2 )
=0
segue
legge exp
=0
segue
legge exp
=0
Però notiamo che il risultato non è dato dal fatto che il traffico è disordinato ma da un fatto
puramente matematico dato che la probabilità in un punto è pari a 0. DI conseguenza
questa espressione non descrive il fenomeno di indipendenza come invece accade nel
discreto.
Invece la seguente lo descrive perfettamente:
A1
P ( D1
, A2
A1 $ D2
A2 ) = P ( D1
x1
P ( D1
x1
D2
A1 ) P ( D2
A2 )
x1 ) P ( D2
x2 )
x2
x2 ) = P ( D1
FD1 , D2 ( x1 , x2 ) = FD1 ( x1 ) FD2 ( x2 )
Funzione di ripartizione congiunta.
/ ( D1 D2 ) = / ( D1 ) / ( D2 )
Se X 1 e X 2 sono variabili casuali indipendenti
B
/ ( X1 X 2 ) = / ( X1 ) / ( X 2 )
g , h / ( g ( x ) h ( x )) = / ( g ( x )) / ( h ( x ))
84
Variabili casuali indipendenti e identicamente distribuite
X 1 , X 2 ,..., X n ,...
FX i = FX
Xn =
stimatore
1 n
Xi
µX
,
n i =1
/( Xn )
stimatore non distorto
=
var ( X n )
consistenza in media quadratica
(
lim P X n
h
1
=
µX < - )
lim FX n ( x ) =
n
µX
1
var ( X )
n
consistenza semplice
=
1
se x > µ X
0
se x < µ X
1
Fxn HxL
1
0.8
0.6
0.4
0.2
-3
-2
-1
1
2
µX
3
4
x
Consideriamo una variabile casuale X la funzione generatrice dei momenti di X è
mX ( t ) = / ( etX )
X 1 + X 2 = S 2 variabili casuali indipendenti
(
mS2 ( t ) = / ( etS2 ) = / e (
t X1 + X 2 )
) = / (e
tX1 tX 2
e
) = / ( e ) / ( e ) = m (t ) m (t )
tX1
X 1 , X 2 indipendenti
i .i .d .
(
mX1 + X 2 ( t ) = mX1 ( t ) mX 2 ( t ) = mX1 ( t )
)
2
X 1, X 2 ,..., X n i.i.d .
(
mX1 + X 2 +...+ X n ( t ) = mX1 ( t )
)
n
85
tX 2
X1
X2
i.i.d. bernoulliane
X 1, X 2 ,... X n
( )
mSn ( t ) = / etSn
n
mSn ' ( t ) = , ketk P ( S n = k )
k =0
n
mSn ' ( 0 ) = , kP ( Sn = k ) = / ( Sn )
k =0
n
mSn '' ( 0 ) = , k 2 P ( S n = k ) = / ( S n 2 )
k =0
(
( )
mSn ( t ) = / etSn = / e (
mSn ( t ) = ( q + pet )
t X1 + X 2 +..+ X n )
) = (m
X1
(t ))
n
= ( et 0 q + pet1 ) = ( q + pet )
n
n
n
mSn ' ( t ) = n ( q + pet )
n 1
pet
mSn ' ( 0 ) = np
Ovvero il valore atteso della binomiale
Proviamo a ricavare dalla funzione generatrice dei momenti la funzione di distribuzione:
mA ( t ) = ( q + pet )
n
( q + pe ) = , %' k &( q
* )
n
t n
n
n k
p k etk
k =0
%n&
f K ( k ) = f K ( k ; n, p ) = ' ( q n k p k I ( k )
(0,1,..., n )
*k )
Ottenendo la funzione di densità della distribuzione binomiale.
In questo caso è stato facile ricavare la funzione di denstià dalla funzione generatrice dei
momenti ma negli altri casi è un operazione molto difficile. Inoltre la funzione generatrice
dei momenti definisce univocamente la funzione di densità ad essa associata.
FX
mX
mX ( t ) =
+1
2e
tX
A X ( x ) dx
1
86
17-01-2005
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Consideriamo una variabile casuale X , la sua FX e t , che è un numero appartenente ad
un qualsiasi insieme (naturale, intero, razionale, reale o immaginario...).
Consideriamo
/ ( etX ) =
+1
2e
tX
A x ( x)dx
1
Chiamiamo M l’insieme delle t tali che esiste finito il valore atteso di etX :
M = {t : / ( etX ) esiste finito}
Chiamiamo Funzione generatrice dei momenti, e la indichiamo con mX :
mX (t ) = / ( etX )
La funzione generatrice dei momenti è un ottimo sistema per calcolare valore atteso e
varianza, infatti / ( X ) è uguale alla derivata prima della funzione generatrice dei momenti
calcolata nel punto t = 0 .
/ ( X ) = m ' X (0)
Se vogliamo calcolare la varianza (ricordiamo che var ( X ) = / ( X 2 ) / ( X ) ) ci basta
2
calcolare la derivata seconda della funzione generatrice dei momenti nel punto t = 0
E ( X 2 ) = m '' X (0)
e calcolare poi la varianza come visto prima.
Ricordiamo che se conosciamo FX possiamo calcolare mX e viceversa. (anche se non è
poi così facile determinare dalla funzione generatrice dei momenti la sua funzione di
ripartizione)
Supponiamo di avere una successione di variabili casuali X 1 , X 2 ,..., X n , una successione
delle funzioni di ripartizione FX1 , FX 2 ,..., FX n e quindi le relative funzioni generatrici dei
momenti mX1 , mX 2 ,..., mX n allora
lim mX n (t ) = m(t )
n
1
lim FX n = F
n
1
e risulteranno tali che m(t ) D F
87
Consideriamo una successione di variabili casuali indipendenti ed identicamente
distribuite.
1 n
Z ( n ) = , Z i è la media campionaria.
n i =1
n
n
% %' t &( , Zi &
t
% % nt Z1 & &
Zn &
% nt Z1 nt Z2
tZ ( n )
n ) i =1
*
n
( = / ' e ie i...ie ( = ' / ' e ( (
= /' e
mZ( n ) (t ) = / e
'
(
'
(
*
) * *
))
*
)
t
Z1
%t&
n
quindi sostituendo e con mZ1 ' ( troveremo
*n)
( )
n
2
%
&
t
n
m ''Z1 (0)
'
(
%
t
% t &&
n + ... ( =
mZ( n ) (t ) = ' mZ1 ' ( ( = sviluppo di Mac Laurin = ' mZ1 (0) + m 'Z1 (0) +
n
2!
* n ))
'
(
*
'
(
*
)
n
%
µZ1 t µZ2 t 2 &
µZ t &
%
= '1+
+
( = glia addendi dopo il secondo possiamo trascurarli = ' 1 + 1 (
2
'
n
n )
2n ()
*
*
n
se calcoliamo il limite per n che tende ad infinito...
n
% µZ t &
lim '1 + 1 ( = et µZ
n 1
n )
*
Consideriamo la variabile casuale D come il tempo passato dal successo precedente
oppure come il tempo che intercorre tra il mio arrivo alla pensilina dei pullman e l’arrivo del
primo autobus, o dall’arrivo dell’autobus che ho appena perso all’arrivo del prossimo.
Questa variabile casuale è i.i.d (Indipendente ed Identicamente Distribuita).
La funzione di ripartizione di D è FD ( x) = (1 e : x ) I (0,+1 ) ( x) .
Supponiamo di aspettare il pullman T secondi.
Quanti pullman vedo passare in T secondi? Nell’intervallo (0, T ) ? Questa domanda può
essere posta per un qualsiasi intervallo (a, b) , basta porre a = 0 e b = T . Indichiamo con
N (a, b) il numero di pullman che passano nell’intervallo (a, b) .
Vediamo che P ( N (a, b) = 0) = P ( D > (b a )) , che significa che il primo pullman arrivo dopo
un tempo maggiore che trascorre dal nostro arrivo a , a quando ce ne andiamo b .
Visto che FD ( x) = P( D
k ) , allora
P ( D > (b a )) = 1 FD ( x) = 1 P ( D
Quindi P( N (0, T ) = 0) = +e
: (T 0)
k ) = 1 (1 e
= +e
: (b a )
) = 1 1+ e
: (b a )
= +e
: (b a )
:T
Questo non ci dice poi molto visto che siamo abituati ad attese abbastanza lunghe.
Prendiamo allora l’intervallo da noi considerato, (0, T ) , e suddividiamo in n intervalli distinti,
T
disgiunti e della stessa ampiezza .
n
88
Fissiamo la nostra attenzione su uno di questi singoli intervalli e chiamiamo qn la
probabilità che, nell’intervallo considerato, non passi nemmeno un autobus:
qn = e
:
Non passa nessun autobus
T
n
pn = 1 qn = 1 e
:
Il suo complementare, passa ALMENO un autobus, quindi anche
2,3...
T
n
Consideriamo la variabile casuale Sn con legge binomiale di parametri n e pn . Questa
variabile casuale indica il numero di intervalli nei quali è passato un autobus (abbiamo
avuto un successo). Ma Sn è il numero di autobus che vediamo passare?!
NO, in quanto, come detto, in un intervallo di tempo (non conosciamo quanto tempo vale
un intervallo, può essere di 1 minuto come di un’ora) possono passare più autobus.
Se n 1 , il tempo di un intervallo diventa talmente minimo, che possiamo considerare Sn
come il numero di autobus che vediamo passare (non possono passare due autobus in un
secondo, dovrebbero stare uno sopra l’altro... ).
Quindi FN (0,T ) = lim FSn .
n
mSn ( t ) = ( qn + pn et )
qn = e
:
n
t
n
pn = 1 e
:
ex = 1 + x +
pn = 1 e
pn
1
:
t
n
x2
+ ...
2!
t
n
2
%
&
t
t
2 t
= 1 '1 : +:
+ ... ( 1 1 + :
2
n
n
2!n
*
)
:t
n
npn : t
Con n
+1 abbiamo npn : t da cui pn
:t
n
=
E
n
.
La funzione generatrice dei momenti di Sn vale:
E
E
n
E
%
& %
mSn (t ) = (qn + pn et ) n = (1 pn + pn et ) n = '1
+ et ( = ' 1 + (
n n ) *
n
*
Quindi dato FN (0,T ) = lim FSn sappiamo che
n
1
89
% E ( et 1) &
t &
(
1 + e ) ( = '1 +
(
n
) '*
)
n
n
% E ( et 1) &
E et 1
( =e ( )
= lim '1 +
n 1'
(
n
*
)
n
( )
mN (0,T ) (t ) = lim mSn
1
n
Ora scriviamo N (0, T ) come NT 0 ossia NT .
Ci chiediamo ora quanto vale P( NT = k ) , ponendo k come un numero intero non negativo.
1
Ricordiamo che / ( etNT ) = mNT (t ) = , etk P( NT = k )
k =0
Cominciamo a calcolarci mNT :
mNT (t ) = lim ( (1 pn ) + pn et ) = e
n
(
1
n
) = e E eE e
E et 1
t
1
x 2 x3
xk
ricordiamo, per aiutarci nei conti, che e = 1 + x + + + ... = , .
2! 3!
k =0 k !
t
Se poniamo x = E e , viene facile scrivere che
x
E E et
e e
E
=e
1
,
( Ee )
t k
k!
k =0
se uguagliamo
1
, etk
k =0
1
e E E k etk
e E E k tk
=,
e
k!
k!
k =0
k =0
1
=,
1
e EEk
= , etk P( NT = k ) , vediamo facilmente che
k!
k =0
E
e Ek
I (0,1,2...) (k )
k!
dalla quale, sostituendo E = : t , e tornando quindi indietro, troviamo che
e : t (: t ) k
P ( NT = k ) =
I (0,1,...) (k )
k!
P ( NT = k ) =
Questa legge di probabilità si chiama LEGGE DI POISSON con parametro : t .
Vediamo ora i vari punti di questa legge:
e : t (: t ) k
P( N = k ) =
k!
mN (t ) = e
(
)
E et 1
/ ( N ) = m ' N (0) = e
(
)E et = 1iE i1 = E
E et 1
E ( et 1)
E ( et 1)
/ ( N 2 ) = m '' N (0) = E %' et e
+ et e
E et &( = E (1 + E ) = E + E 2
*
)
var ( N ) = / ( N 2 ) / ( N ) = E + E 2
2
E2 = E
90
21-01-2005
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Supponiamo due variabili casuali X ,Y e le loro rispettive funzioni generatrici dei momenti
mX e mY . Vogliamo studiare la variabile casuale Z così definita: Z = X + Y .
Se X eY sono indipendenti è elementare calcolare la funzione generatrice dei momenti
di Z.
( )
(
)
( ) ( )
mZ (t ) = / etZ = / etX e tY = / etX / e tY = mX (t )mY (t )
Ripassiamo qualche proprietà dell’esponenziale:
1
xk
ex = ,
x
k =0 k !
e x + y = e xe y
g ( x ) = e x g '( x ) = g ( x ) = e x
g (0) = 1
Fissato un numero positivo E > 0 definiamo N variabile casuale di Poisson se
mN (t ) = e E ( e
t
1)
.
Ricordiamoci l’esempio dei pullman di Napoli...la variabile casuale D1 indica il tempo che
un pulmann impiega ad arrivare alla mia fermata. Questa variabile segue l’esponenziale e
la funzione di ripartizione vale: FD1 ( x ) = (1 e : x ) I(0,+1 ) ( x ) . Consideriamo D2 indipendente
da D1 .
Per stimare : ricordiamo che / ( D ) =
1
:
, ma non conoscendo / ( D ) , diremo che uno
stimatore non distorto del nostro valore atteso è la media
stimatore
1 1
1
Di
,
:
n i =1
Siccome non sappiamo il valore di : , non sappiamo quanto tempo ci mettiamo a veder
passare n autobus.
E’ meglio fissare un tempo T di osservazione.
T
Suddividiamo T in n intervalli di lunghezza .
n
0
T
Studiamo, come fatto precedentemente, qn e pn = 1 qn (la probabilità che passa almeno
un autobus).
Studiamo Sn con n
1 per trovare NT , ovvero il numero di autobus che passano alla
mia fermata. L’intervallo nel quale possiamo avere un successo è talmente breve che
possiamo stimare con esso il numero di bus passati dalla pensilina nell’intervallo di tempo
T.
91
(
mNT (t ) = lim mSn (t )
n
1
mNT (t ) = e(: t )( e
t
1)
)
che viene chiamata legge di Poisson di parametro : t .
La probabilità che N assuma un valore intero non negativa vale:
P (N = k ) =
Ek
k!
e E I{0,1,2,...} (k )
Il valore atteso di N vale:
/ ( N ) = m 'N (0) = E
La varianza di N vale:
2
var(N ) = / ( N ) / N 2 = E + E 2
( )
E2 = E
Ricordando che E = : t possiamo affermare che / ( NT ) = : T .
Come possiamo stimare : in maniera non distorta basandoci sul numero di conteggi degli
autobus da effettuare?
1
%N &
/ ( NT ) = : T
/ ( NT ) = :
: = / ' T ( ovvero il valore atteso della frequenza media in
T
*T )
cui passa un autobus
Certo che con questa stima T può essere 2 minuti o 2 anni...questa cosa è sospetta,
quanto può essere accurata questa misurazione?
Possiamo valutarla in base al valore della varianza, più piccola sarà la varianza più
accurata sarà la nostra misurazione.
1
:
%N & 1
var ' T ( = 2 var ( NT ) = 2 : T = .
T
T
*T ) T
Sapendo che : è una costante, vediamo che più T sarà grande, quindi più tempo starò alla
pensilina, più la nostra misurazione sarà accurata.
Dato che il parametro E = : T e che T deve tendere all’infinito per avere una stima
corretta, allora anche E tende all’infinito.
Usiamo Tchebycheff, scrivendo E come / ( NE ) diremo che:
P ( NE
E <-) 1
var(NE )
-2
- >0
92
Possiamo scriverla, come mostra il libro di testo:
(
P NE
E <r E
)
1
1
r2
r >0
% N E
&
1
P' E
< r( 1 2
r
E
*
)
Ma in questo caso ci accorgiamo come Tchebycheff possa sviarci dal nostro vero obiettivo
in quanto noi vorremmo scriverla esplicitamente senza fare intervenire E .
Osservando Tchebycheff possiamo dire che
E
,
0 k
k E
k!
e
E
e facendo lim
E
<r
E
1
,
0 k
k E
E
E
k!
e
E
<r
Ci accorgiamo che se lo facciamo della funzione di ripartizione sarà molto difficile
calcolarlo mentre è estremamente semplice se lo si fa prendendo come argomento la
nostra funzione generatrice dei momenti.
lim m NE
E
1
E
(t )
E
N /(N )
= N*
var ( N )
/( N* ) = 0
var ( N * ) = 1
(
)
%
%
% t (N E ) & &
%
(t ) = / ( e ) = / ( exp(tN ) ) = / ' exp '
( ( = / ' exp '
E ))
*
*
*
*
lim mN F (t ) =
1
n
mN F
E
t
E
E
tNEF
F
t
E
E
E
( NE
&&
E)( (
))
=s
(
/ ( exp ( sNE
sE ) ) = / esNE e
sE
)=e
sE
(
)
/ e sNE = e
sE
mNE (s ) = e
sE
%
%
t
% t & &&
= exp '' E
+ E ' exp '
( 1( ((
E
E
*
) ))
*
*
dato che lim eT = lim (T )
n
1
( )
n
1
%
%
%
%
t
% t & &&
% t & &&
+ E ' exp '
lim '' E
1( (( = lim '' t E + E ' exp '
(
( 1( ((
n 1
n 1
E
E
E
*
)
*
) ))
*
)
*
*
)
*
93
eE (e
s
1)
=
1 t 2 ?; 1 t 3 @<
+
. Il fattore tra parentesi quadre
3
E 2 E ; 3! 2 <
= E >
possiamo trascurarlo in quanto è un infinitesimo di grado maggiore rispetto al precedente.
Quindi:
Sviluppo di Mac Laurin dell’exp: 1 +
t
+
%
% t
%
1 t2 &&
t2 & t2
quindi il limite dell’esponenziale
lim '' t E + E '
lim
+
=
t
E
+
t
E
+
( (( n 1 '
(=
n 1
2
2
2
E
E
*
)
*
)
*
)
vale
e
1 2
t
2
Osservando nell’appendice del nostro libro di testo individuiamo la funzione generatrice
dei momenti in corrispondenza della distribuzione normale.
Quindi riprendendo il nostro discorso da Tchebycheff
% N E
&
1
lim P ' E
< r ( = P( G < r) =
E 1
2G
E
*
)
r
2e
x2
2
dx
r
94
24-01-2005
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Riassumiamo brevemente quello che abbiamo visto nelle ultime due lezioni.
Consideriamo X 1 , X 2 ,..., X n variabili casuali bernoulliane, indipendenti e identicamente
distribuiti con 0 < p < 1 .
n
Sn = , X i
i =1
SnF =
Sn / ( Sn )
var ( Sn )
=
Sn
np
np (1 p )
/ ( SnF ) = 0
var ( SnF ) = 1
lim mS F ( t ) = e
1
n
t2
2
n
Osserviamo che il limite è la funzione generatrice dei momenti della normale.
+1
1
e
2G
2
1
x2
2
t2
2
e dx = e = / ( etG ) Dove con G si intende una variabile casuale Gaussiana
tx
(Normale standarizzata)
1
AG ( x ) =
e
2G
/ (G ) = 0
x2
2
var ( G ) = 1
lim FS F ( x ) = FG ( x )
n
1
n
Consideriamo ora N E variabile casuale di Poisson di parametro E > 0 .
/ ( NE ) = E
var ( N E ) = E
Notiamo un caso particolare, ovvero valore atteso uguale varianza.
Effettuiamo l’operazione di standarizzazione.
N E
N EF = E
E
lim mN F ( t ) = e
n
1
t2
2
E
Ed ecco di nuovo che il riusultato del limite è la funzione generatrice dei momenti della
normale standarizzata. Ricordiamo che la variabile casuale Gaussina è una variabile
casuale continua.
95
1
è!!!!!!!!
2
0.4
x2
2
0.3
0.2
0.1
-4
-2
2
4
x
Notiamo che la normale standarizzata è simmetrica rispetto all’asse delle ordinate.
x0
P (G
x0 ) = P ( 1 < G
x0 ) =
x0
2 A ( y ) dy
G
1
96
Ora non vogliamo più parlare di variabili casuale Bernoulliane e Poissoniane.
Consideriamo semplicemente X 1 , X 2 ,..., X n variabili casuali indipendenti e identicamente
distribuite.
/ ( X i ) = µX
var ( X i ) = 0 X2
i = 1, 2,..., n
n
Sn = , X i
i =1
% n
&
X
/
,
i
', Xi (
* i =1 )
= i =1
n
%
&
var ' , X i (
* i =1 )
n
SnF =
S n / ( Sn )
var ( Sn )
?
Ma ora non sappiamo se lim mS F ( t ) = e
n
1
n
t2
2
però possiamo tentare di verificarlo.
% n
& % n
&
/
X
X
,
i
' , i ( ' , X i ( nµ X
* i =1 ) = * i =1 )
= i =1
=
n
n0 X2
%
&
var ' , X i (
* i =1 )
n
F
n
S =
S n / ( Sn )
var ( S n )
n
1
S =
n
F
n
Yi =
,( X
Xi
i =1
i
µX )
0X
µX
0X
/ ( Yi ) = 0
var (Yi ) = 1
SnF =
1 n
, Yi
n i =1
97
n
, Xi
i =1
n
, µX
i =1
n0 X
n
=
,( X
i =1
i
µX )
n0 X
% t ,Yi &
n
mS F ( t ) = / ' e i=1 (
n
'
(
*
)
n
s=
t
n
% t ,Yi &
% s ,Yi
n i=1 (
'
mS F ( t ) = / e
= / ' e i=1
n
'
(
'
*
)
*
n
(
mS F ( t ) = mY1 ( s )
n
n
)
&
i .i .d .
n
( = / e sY1 e sY2 ...e sYn = / ( e sY1 )
(
)
n sviluppo di Mac Laurin
=
(
)
&
%
s2
s3
'
''
'''
m
0
+
m
0
s
+
m
0
+
m
0
+ ... (
' Y1 ( )
Y1 ( )
Y1 ( )
Y1 ( )
2!
3!
)
*
n
/ ( e0Y1 ) = / (1) = 1
m'Y1 ( 0 ) = / (Y1 ) = 0
m''Y1 ( 0 ) = / (Y12 ) = var (Y1 ) = / (Y12 ) / ( Y1 ) = 1
2
3 &
% % t &2
t
%
&
' '
3 n
(
'
( (
% s2
' * n)
n) (
3 s &
3 *
+ / (Y1 )
mS F ( t ) = '1 + + / (Y1 ) ( = '1 +
n
2
3! )
2
3! (
*
'
(
'
(
*
)
n
Il terzo addendo è un infinitesimo più grande rispetto al secondo addendo di conseguenza
può essere trascurato.
Il momenti terzo è chiamato Curtosi e rappresenta quanto la densità sia simmetrica intorno
al suo valore atteso.
%
t2 &
mS F ( t ) = '1 + (
n
* 2n )
n
n
2
t
%
t2 &
lim mS F ( t ) = lim '1 + ( = e 2
n
n 1
n 1
* 2n )
Ed ecco dimostrata la nostra congettura: lim mS F ( t ) = e
n
1
98
n
t2
2
Dedichiamoci ora a Tchebycheff e ad alcune osservazioni.
a<b
P (a
S
F
n
b
1
e
2G
b) = P ( a G b) = 2
a
x2
2
dx
a<b
µX = / ( X i )
%
'
lim P ' a
n 1
'
'
*
n
,X
i =1
nµ X
i
n0 X
&
(
b(
(
(
)
n
%
X i nµ X
n
,
'
%
&
i
1
=
X i nµ X
'
,
'
(
n
i =1
'
(
P a
b = P'a
'
n0 X
n0 X
'
(
'
(
'
n
*
)
'
*
n
1
%
&
%
X i µX
,
'
(
X n µX
n
n
i =1
= P'a
b ( = P '' a
'
(
'
var X n
var X n
'
(
*
*
)
( )
%
lim P '' a
n 1
'
*
Xn
µX
( )
&
1
b (( =
2G
(
)
n
( )
var X n
a= r
b
2e
y2
2
&
(
%
(
'
b( = P'a
(
'
'
(
*
(
)
1 n
, Xi µX
n i =1
1
0X
n
&
(
b( =
(
(
)
&
b ((
(
)
dy
a
b=r
0
r >0
% X µ
&
n
1
Xn
'
< r (( =
lim P '
n 1
2G
' var X n
(
*
)
( )
r
2e
y2
2
dy
r
Noi vogliamo che la maggiorazione della disuguaglianza di Tchebycheff sia fatta con il
1
risultato del limite e non con 1 2 .
r
99
Se vogliamo calcolare la probabilità all’interno dell’intervallo (–r,r) possiamo più
rapidamente calcolarla come 1 meno tutto ciò che non sta nell’intervallo ovvero:
1
2
e
2G 2r
1
y2
2
dy
Il due al numeratore viene fuori dal discorso di simmetria della densità normale rispetto
all’asse delle ordinate, di conseguenza le aree (“blu”) sottese al grafico sono uguali.
r
r
Ora vogliamo dimostrare che:
1
2
e
2G 2r
1
y2
2
1
r2
dy 1
Studiare però quell’integrale risulta difficile, ma vediamo se riusciamo ad arrampicarci sugli
specchi
1
2 1ie
x2
2
r
? 1
x
dx 2 ie
r
r
x2
2
dx
Possiamo fare il confronto in quanto: x > r quindi
1
1
xe
r 2r
x2
2
1%
dx = ' e
r '*
x2
2
r2
& +1 e 2
(( =
r
)r
Quindi:
1
2
2G
r>0
+1
2e
r
x2
2
dx 1
r2
2
2 e
2G r
100
x
>1
r
In conclusione se n è molto grande (tendente all’infinito nelle nostre considerazioni)
possiamo affermare che:
r >0
% X µ
&
n
11
Xn
'
< r (( 1
P'
1
r
r
' var X n
(
*
)
( )
21
e
G r
r2
2
101
4-10-2004
Alessandro Reina, Laura Sorgiacomo, Paolo Rotta
Gnedenko 1931
Il Calcolo della probabilità è quel ramo della matematica che si occupa di modelli
matematici, di fenomeni casuali aventi la proprietà della stabilità della frequenza.
I fenomeni casuali sono quei fenomeni con i quali si possono ottenere risultati differenti a
parità di condizioni iniziali.
I fenomeni deterministici sono quei fenomeni che grazie alla conoscienza delle condizioni
iniziali determinano l’evoluzione futura del sistema.
Ripasso sugli insiemi
Differenza simmetria, A B , corrisponde agli elementi che
appartengono sia ad A che a B ma non a tutti e due.
A B = (A
A
B)
(A
B )C
B
La cardinalità di un insieme è il numero degli elementi dell’insieme stesso.
Dato un insieme A indicheremo la sua cardinalità con la notazione A .
A = {a, b, c}
A =3
L’insieme delle parti di un insieme è costituito da tutti i sottoinsiemi dello stesso
insieme.Per ogni insieme B , l’insieme delle sue parti sarà ( B ) = 2 B
Nell’esempio si prima:
( A) ={{a, b, c} , {a, b} , {a, c} , {b, c} , {a} , {b} , {c} , {
}}
La cardinalità dell’insieme delle parti di A è:
P( A) = 23 = 8
Il prodotto cartesiano è:
C = A× B
A × B = {( , )
A,
B}
102
Ad esempio dati gli insiemi seguenti:
A = {c, d }
B = {7, 42}
Il prodotto cartesiano è:
A × B = {(c,7), (c, 42), (d , 7), (d , 42)}
Cardinalità del prodotto cartesiano:
Se A = n
e B =m
allora
A × B = nm
A × B = 2* 2 = 4
definizione di coppia ordinata:
(a, b) ={{a} , {a, b}}
(b, a) = {{b} , {a, b}}
Tips: Notare bene l’ordine lessicografico!!!
Ovvero data la coppia ordinata
(a, b)
Il suo insieme è esso stesso un insieme i cui elementi sono gli insiemi di {a, b} ed {a} .
{a, b} ovviamente è diversa da {b, a}
che è l’insieme degli elementi su {b, a} e {b} .
103

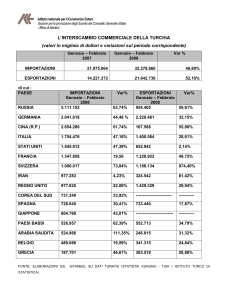

![2 [6] Una compagnia di assicurazione ritiene che gli assicurati](http://s1.studylibit.com/store/data/002416903_1-3377a891909164cbe7bb266e8421813f-300x300.png)