13.02.2015 - 2^ Prova in itinere di STATISTICA per studenti ENE - docente: E. Piazza
obbligatorio - n. iscrizione sulla lista
se non ve lo ricordate
siete fritti; o no?
il presente elaborato si compone di 4 (quattro) pagine
Cognome
Nome
matr.n.
Avvertimento: nello svolgimento degli esercizi se una quantità è indicata con il simbolo x continuare a chiamarla x, e se si chiama W non chiamarla X, e se si chiama ti non chiamarla xi , e se si
chiama T̄n non indicarla con X̄n . Se volete scrivere dipendenti non scrivete indipendenti, se dovete
sottrarre non sommate. Si fanno troppi errori di distrazione. Mi raccomando: concentrazione.
–––––––––––––––––––––––––––––––––––––––
Si consiglia di lavorare con 3 decimali, arrotondando opportunamente.
c I diritti d’autore sono riservati. Ogni sfruttamento commerciale non autorizzato sarà p erseguito.
Problema 1. Il Dottor H. vuole inferire sulla durata X di un automa MM. A tal fine registra le durate in
minuti di 111 automi MM indipendenti. I dati raccolti hanno media campionaria e varianza campionaria
s2111 = 4.9902,
x111 = 1.96,
e, relativamente alle classi di seguito introdotte, risultano così distribuiti
Classi
[0 − 2)
[2 − 4)
[4 − 6)
[6 − 8)
[8 − 10)
[10 − 12)
2
Frequenze assolute
74
24
5
4
3
1
1.1 Fornire una stima puntuale e una stima intervallare di confidenza 0.95 asintotica della durata media
µ = E[X] di un automa MM.
Stima puntuale: µ = x111 = 1.96.
Stima intervallare di confidenza 0.95 (anche se il campione non proviene da una normale, è tuttavia sufficientemente numeroso, essendo n = 111 > 40):
s111
µ± √
t0,025 (110) = 1.96 ±
111
2
4.9902
1.9818 = 1.96 ± 0.42 = (1.54 , 2.38).
111
Il Dottor H. sospetta che la durata X di un automa MM abbia distribuzione esponenziale.
1.2 Impostare un opportuno test di adattamento per verificare se X abbia distribuzione esponenziale.
Esplicitare le ipotesi statistiche e la regione critica di livello α, utilizzabile con i dati a disposizione.
1
H0 : X ∼ E, H1 : X ≁ E.
La regione critica Rα dipende dalla scelta delle classi Aℓ ed è utilizzabile se
n pℓ = 111 · P(X ∈ Aℓ ) > 5 per ogni ℓ.
Le probabilità vanno stimate con la distribuzione esponenziale di media µ = 1.96, ovvero di parametro λ =
1/µ = 0.510204082. Per le classi assegnate si ha
Aℓ
[0 , 2)
[2 , 4)
[4 , 6)
[6 , 8)
[8 , 10)
[10 , 12)
[12 , +∞)
Nℓ
74
24
5
4
3
1
0
pℓ
0.6395522114
0.2305251803
0.0830922915
0.0299504327
0.0107955672
0.0038912383
0.0021930786
n pℓ
70.9902954656
25.5882950125
9.2232443512
3.3244980301
1.1983079631
0.4319274554
0.243431722
per cui conviene accorpare le ultime quattro classi
Aℓ
[0 , 2)
[2 , 4)
[4 , 6)
[6 , ∞)
Nℓ
74
24
5
8
pℓ
0.6395522114
0.2305251803
0.0830922915
0.0468303169
n pℓ
70.9902954656
25.5882950125
9.2232443512
5.1981651706
e utilizzare la corrispondente regione critica
4
Rα : Q =
ℓ=1
2
(Nℓ − npℓ )2
> χ2α (2).
npℓ
1.3 Calcolare il p-value dei dati raccolti e trarre le dovute conclusioni circa la distribuzione di X.
Il p-value dei dati raccolti è la soluzione α di
4
χ2α (2) = Q =
ℓ=1
(Nℓ − npℓ )2
= 3.67
npℓ
Con le tavole
χ20.5 (2) = 1.39 < χ2α (2) = 3.67 < χ20.1 (2) = 4.61
0.1 < α < 0.5
2
mentre il valore esatto è α = 0, 16. Il p-value non è particolarmente alto, ma comunque superiore a 0.1.
Pertanto, agli usuali livelli di significatività, non possiamo rifiutare H0 e concludiamo che la distribuzione di X
è un’esponenziale. La conclusione tuttavia è debole.
1.4 Fornire una stima puntuale della probabilità che un automa MM duri più di 12 minuti.
Coerentemente con la conclusione del test stimiamo la probabilità di X > 12 con
P(X > 12) = e−12/µ = 0.0021930786 = 0.22%.
2
Problema 2. Il Dottor H. vuole confrontare il carico di rottura µM degli elmetti M con il carico di rottura
µS degli elmetti S. In particolare vuole capire se si può affermare, con forte evidenza statistica, che µM > µS .
Usando uno strumento con errore di misura casuale gaussiano standard (fissata opportunamente l’unità di
misura), intende effettuare m misure indipendenti di µM , con risultati
X1 , . . . , Xm
campione casuale N (µM , 1),
e n misure indipendenti di µS , con risultati
Y1 , . . . , Yn
2
2.1 Impostare un opportuno test statistico per poter rispondere alla domanda del Dottor H. Esplicitare
ipotesi nulla, ipotesi alternativa e regione critica di livello α.
1
1
+ zα .
m n
2.2 Calcolare la probabilità β dell’errore di seconda specie per il test impostato in funzione di d = µM − µS .
H0 : µM µS ≤ 0,
2
β = P Xm − Y n <
2
campione casuale N (µS , 1).
1
1
+ zα
m n
H1 : µM − µS > 0,
=P
Rα : X m − Y n > +
X m − Y n − (µM − µS )
1
m
+
1
n
< zα −
µM − µS
1
m
+
1
n
= Φ zα −
µM − µS
1
m
+
1
n
2.3 Supponendo m = n e α = 0.05, calcolare la minima ampiezza campionaria n capace di rivelare una
differenza µM − µS = 0.5 con una probabilità di errore del II tipo del 40% al massimo.
µ
−
µ
S
β = Φ z0.05 − M
≤ 0.4
2
n
z0.05 −
µM − µS
2
n
≤ z0.6
2
2
z0.05 − z0.6
1.645 + 0.253
=2
= 28.8
µM − µS
0.5
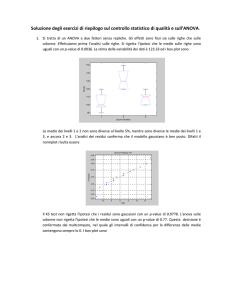
Alla fine il Dottor H. esegue 49 misure sugli elmetti M e 45 misure sugli elmetti S, ottenendo
n≥2
x49 = 13.24
y 45 = 13.05,
e i seguenti boxplot
3
2
2.4 Calcolare il p-value dei dati raccolti.
Il p-value dei dati raccolti è la soluzione α di
1
1
+ zα
m n
xm = yn +
per cui
zα =
2
2
x49 − y 45
1
49
+
1
45
√
0.19 2205
√
=
= 0.92
94
α = 1 − Φ(0.92) = 1 − 0.821214 = 0.178786.
2.5 Trarre le dovute conclusioni agli usuali livelli di significatività.
Nonostante x49 > y45 , abbiamo un p-value > 0.1 e quindi non possiamo rifiutare l’ipotesi nulla agli usuali livelli
di significatività: µM ≤ µS
2.6 Se la conclusione fosse sbagliata, avreste commesso un errore del primo o del secondo tipo?
Secondo tipo.
4
Problema 3. Il dottor H. vuole trovare un buon modello lineare empirico gaussiano che spieghi l’energia
Y consumata al minuto da un automa MM con la sua altezza x1 e la sua larghezza x2 . Raccoglie pertanto i
dati relativi a 21 differenti automi MM, e li elabora con due regressioni lineari multiple: Y su x1 e x2 (modello
1) e Y su x1 , x2 e x1 x2 (modello 2). Per ciascun modello trovate in allegato lo specchietto riassuntivo della
regressione, alcuni grafici dei residui standardizzati, il p-value dei residui standardizzati per il test di normalità
di Shapiro-Wilk.
Modello ridotto
Modello completo
2
2
3.1 Scrivere il legame fra le variabili Y , x1 e x2 ipotizzato dai due modelli lineari empirici gaussiani.
Modello 1: Y = β 0 + β 1 x1 + β 2 x2 + ǫ dove ǫ ∼ N (0, σ2 ).
Modello 2: Y = β 0 + β 1 x1 + β 2 x2 + β 3 x1 x2 + ǫ dove ǫ ∼ N (0, σ2 ).
3.2 Spiegare quale dei due modelli è il migliore spiegando tutti i pro e contro.
È migliore il modello 2 in quanto:
( ) è decisamente meglio confermata l’ipotesi gaussiana:
( ) entrambi gli scatterplot dei residui standardizzati sono a nuvola senza struttura, ma il modello 1 avrebbe
ben 9 outlier su 21 dati, mentre il modello 2 non ha outlier
( ) il normal Q-Q plot dei residui standardizzati è migliore per il modello 2
5
2
( ) il p-value di Shapiro-Wilk è molto più alto per il modello 2
( ) è maggiore R2corretto (0.9978 per il modello 1, 0.9993 per il modello 2), ovvero è minore la stima di σ2
Non danno invece indicazioni la significatività globale della regressione (che è la medesima per entrambi i
modelli) e le significatività dei singoli regressori (che sono tutte ottime per tutti i regressori per entrambi i
modelli).
3.3 Dare una stima puntuale del consumo medio di energia al minuto degli automi MM alti 13 e larghi 8.
E[Y |x1 = 13, x2 = 8] = β 0 + β 1 x1 + β 2 x2 + β 3 x1 x2
= 108.34230 + 8.75735 · 13 + 9.41282 · 8 + 0.54069 · 13 · 8 = 353.722.
2
3.4 Dare una stima puntuale della variazione media di energia consumata al minuto passando da automi
MM alti 13 e larghi 8 ad automi alti 15 e larghi 8.
E[Y |x1 = 15, x2 = 8] − E[Y |x1 = 13, x2 = 8] = β 1 · (15 − 13) + β 3 · (15 − 13) · 8
= 8.75735 · 2 + 0.54069 · 2 · 8 = 25.80.
2
3.5 Il dottor H. ritiene tuttavia che l’intercetta del modello debba valere 50. Stabilire con un opportuno
test di livello 1% se i dati possono confutare tale convinzione. Esplicitare ipotesi statistiche, regione critica e
conclusione.
H0 : β 0 = 50,
Per i dati raccolti
H1 : β 0 = 50,
Rα : |β 0 − 50| > se(β 0 ) tα/2 (n − 1).
|β 0 − 50| = 58.3423 > se(β 0 ) t0.005 (20) = 10.25250 · 2.845 = 29.1684
quindi ad un livello dell’1% i dati consentono di rifiutare l’ipotesi nulla. Pertanto β 0 = 50.
6