LEGGI DEI GRANDI NUMERI
Esiste un insieme di teoremi che riguardano la convergenza di una successione di v.a. ad
una costante.
Queste leggi si definiscono deboli se la successione converge in probabilità ad una
costante, forti se la successione converge quasi certamente alla costante.
VERSIONE INTUITIVA DELLE LEGGI DEI GRANDI NUMERI
La legge dei grandi numeri, detta anche legge empirica del caso oppure teorema di
Bernoulli (in quanto la sua prima formulazione è dovuta a Jakob Bernoulli), descrive il
comportamento della media di una sequenza di n v.a. indipendenti e caratterizzate dalla
stessa distribuzione di probabilità (n misure della stessa grandezza, n lanci della stessa
moneta ecc.) al tendere ad infinito della numerosità della sequenza stessa (n). In altre
parole, grazie alla legge dei grandi numeri, possiamo fidarci che la media che calcoliamo a
partire da un numero sufficiente di campioni sia sufficientemente vicina alla media vera.
In termini generici, per la legge dei grandi numeri si può dire:
che la media della sequenza è una approssimazione, che migliora al crescere di n,
della media della distribuzione;
e che, viceversa, si può prevedere che sequenze siffatte mostreranno una media
tanto più spesso e tanto più precisamente prossima alla media della distribuzione
quanto più grande sarà n.
Un caso particolare di applicazione della legge dei grandi numeri è la previsione
probabilistica della proporzione di successi in una sequenza di n realizzazioni indipendenti
di un evento E: per n che tende a infinito, la proporzione di successi converge alla
probabilità di E (vedi l’esempio riportato più sotto).
LEGGE FORTE DEI GRANDI NUMERI
Se, data una successione di variabili casuali X1,X2,...,Xn,... indipendenti e identicamente
distribuite con media μ, si considera la media calcolata
la legge (forte) dei grandi numeri afferma che
ossia la media campionaria converge quasi certamente alla media comune delle Xi.
LEGGE DEBOLE DEI GRANDI NUMERI
Se, data una successione di variabili casuali X1,X2,...,Xn,... aventi la stessa media μ, la
stessa varianza finita e indipendenti, si considera la media campionaria
la legge (debole) dei grandi numeri afferma che per ogni
:
ossia la media campionaria converge in probabilità alla media comune delle Xi.
Esempio.
Supponiamo di avere un evento (come il fatto che lanciando un dado esca il sei) con
probabilità sconosciuta p (sconosciuta perché il dado potrebbe essere truccato, o
semplicemente difettoso: non possiamo saperlo in anticipo).
Eseguendo n lanci consecutivi otteniamo una stima della probabilità di fare sei con quel
dado, data da
dove le X della somma rappresentano l'esito dei lanci e valgono uno se in quel lancio è
uscito il sei, o zero se è uscito un altro numero. La legge dei grandi numeri afferma
semplicemente che, tante più prove usiamo per calcolare la stima, tanto più questa sarà
vicina, probabilmente, alla probabilità reale dell'evento p.
Se la stima X(n) che calcoleremo sarà molto vicina a un sesto, che è la probabilità teorica
che esca il sei per un dado perfetto, potremo essere ragionevolmente certi che il dado in
questione non è polarizzato per il sei (per essere sicuri che il dado non sia truccato in
nessun modo dovremmo ripetere il test anche per gli altri cinque numeri). Che cosa
significhi ragionevolmente sicuri dipende da quanto vogliamo essere precisi nel nostro
test: con dieci prove avremmo una stima grossolana, con cento ne otterremmo una molto
più precisa, con mille ancora di più e così via: il valore di n che siamo disposti ad accettare
come sufficiente dipende dal grado di casualità che riteniamo necessario per il dado in
questione.
VERSIONE FORMALE DELLE LEGGI DEI GRANDI NUMERI
Data la successione Xn di v.a. indipendenti generate da prove bernoulliane, distribuite in
modo identico, facciamo l’assunzione che per ciascuna v.a. la probabilità che si verifichi il
successo sia costante e pari a p.
Quindi
-
ciascuna v.a. Xn assume valore 1 con probabilità p e valore 0 con probabilità 1-p
la successione Xn distribuita in modo bernoulliano con parametro p rappresenta un
processo bernoulliano con un parametro p che si può vedere sia come la
probabilità dell’ evento E che il valor medio di Xn .
Le somme parziali costituiscono una v.a. che rappresenta la frequenza assoluta dei
successi in n prove bernoulliane:
S1 X 1
S2 X1 X 2
S 3 X 1 X 2 X 3 ....
Sn X1 X 2 X 3 X n
Chiamiamo questa v.a. SnBin(n,p) con valor medio e varianza
E (S n ) np
Var( S n ) np(1 p)
n
S
X X 2 ... X n
La successione Fn n 1
n
n
X
i 1
i
n
si può vedere come la frequenza relativa dei successi. Ha valor medio e varianza
E ( Fn )
np
p
n
Var ( Fn ) Var (
Sn
Var ( S n ) np(1 p) p(1 p)
)
n
n
n2
n2
Si osserva che il valor medio è costante al variare di n, mentre la varianza tende a 0 al
crescere di n.
LEGGI DEBOLI DEI GRANDI NUMERI
LEGGE DEBOLE DEI GRANDI NUMERI (versione Khintchine)
Se X n è una successione di v.a. indipendenti ed identicamente distribuite con valor medio
comune E(X)=p, per qualsiasi >0 si ha che la successione Fn converge in probabilità a p,
ossia
p
Fn
p
LEGGE DEBOLE DEI GRANDI NUMERI PER PROVE BERNOULLIANE (Bernoulli)
Se XnBer(p), la frequenza relativa con cui l’evento si realizza in n prove indipendenti Fn
converge in probabilità al valore di probabilità associato all’evento:
p
Fn
p
Possiamo riscrivere questa espressione come
lim
S
P( n p ) 0
n
n
Questo significa che l’evento (
l’evento (
Sn
p ) è molto improbabile al crescere di n, mentre
n
Sn
p ) diviene certo.
n
Questo è il motivo per la cui la legge dei grandi numeri si accosta alla legge empirica del
caso.
LEGGE DEBOLE DEI GRANDI NUMERI PER PROVE BERNOULLIANE DIFFERENTI
(Poisson)
Se XnBer(p) è una successione di v.a. indipendenti, allora per ogni >0 si ha
n
lim
P( Fn
n
p
i 1
n
i
) 1
LEGGI FORTI DEI GRANDI NUMERI
LEGGE FORTE DEI GRANDI NUMERI PER PROVE BERNOULLIANE (Borel)
Viene sostituita nella formula di Bernoulli la convergenza in probabilità con la convergenza
quasi certa.
Se XnBer(p) , allora la successione Fn converge quasi certamente alla convergenza in
probabilità p,
qc
Fn
p
LEGGE FORTE DEI GRANDI NUMERI (Kolmogorov)
Se Xn è una successione di v.a. indipendenti aventi ciascuna valor medio E(Xi)=pi e
varianze i2 uniformemente limitate, allora la successione sotto riportata tende a zero:
n
Fn
p
i 1
n
i
qc
0
TEOREMA LIMITE CENTRALE
Un gruppo di risultati teorici ha portato a dimostrare che, sotto certe condizioni, somma (e
quindi media ) di v.a. di qualsiasi tipo convergono alla v.a. normale.
Si consideri una successione X n di v.a. indipendenti ed identicamente distribuite con
valor medio comune E(Xn)= e varianza
Var(Xn)=2<+,
la v.a. somma Sn ha valor medio e varianza
E ( S n ) n
Var ( S n )n 2
Queste grandezze però assumono valori infiniti per n tendente ad infinito.
Si utilizza allora la v.a. somma standardizzata
Zn
S n E (S n )
Var ( S n )
S n n
n
che ha valor medio e varianza pari a
E(Z n ) 0
Var (Z n ) 1
Una formulazione rigorosa del teorema limite centrale è stata data da De Moivre e
Laplace:
TEOREMA LIMITE CENTRALE (DE MOIVRE – LAPLACE)
La v.a. Sn somma di v.a. Xn statisticamente indipendenti ed identicamente distribuite, con
E(Xn)=p e Var(Xn)=p(1-p), converge in distribuzione ad una v.a. normale standardizzata:
Zn
S n np
np(1 p)
d
Z N(0,1)
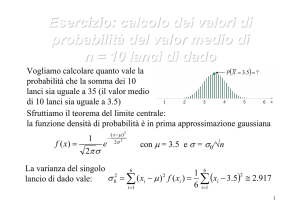
Il teorema è applicabile nel caso di n .Nella pratica si vede però che, anche se le
v.a. Xn non sono del tutto simmetriche, la v.a. Sn assume una distribuzione che
approssima bene la gaussiana già per n superiore a poche decine (a volte a poche unità).
Questo perché la sommia o la media di v.a. gaussiane ha sempre distribuzione normale, e
in virtù di questo teorema la gaussiana si può vedere come distribuzione limite di altre
distribuzioni (Bernoulli, Poisson, gamma, chi quadrato, Student, lognormale).
Possiamo dire che Zn può essere approssimato da Z purchè:
- le n v.a. abbiano la stessa distribuzione e n>30
- le n v.a. siano indipendenti e np>5 .
Questo teorema consente quindi di approssimare la distribuzione di una v.a. attraverso la
distribuzione della v.a. normale standardizzata.
-La media di n v.a. uniformi per n2 presenta distribuzioni unimodali e simmetriche che
tendono velocemente alla v.a. normale standardizzata.
La distribuzione della somma di n=12 v.a. uniformi è un’ottima approssimazione della
funzione densità della v.a. normale standardizzata ed era un tempo utilizzata per la
generazione dei numeri pseudocasuali normali, ottenuti con l’estrazione (con ripetizione)
da un’urna contenente le 10 cifre.
-Data una v.a. binomiale XBin(n,p) , se vista come somma di n v.a. bernouliiane di
parametro p, se n è grande e p non è prossimo allo zero, la v.a. X può essere
approssimata da una distribuzione normale standardizzata:
Z
X np
np (1 p)
in cui l’approssimazione da v.a. a continua si può effettuare considerando che ad un
singolo valore della prima corrisponda un intervallo di valori della seconda.
-Data una v.a. di Poisson XPo() , X converge in distribuzione ad una v.a. normale, e se
è grande (si indica spesso 18) X può essere approssimata da una v.a. normale avente
valor medio e varianza .
-La v.a. chi-quadrato è data dalla somma di v.a. normali standardizzate e indipendenti al
quadrato.
Le considerazioni riportate sopra motivano l’importanza della distribuzione normale in tutti
gli studi statistici e probabilistici di distribuzione, e giustificano teoricamente l’osservazione
secondo la quale molti fenomeni composti da diverse componenti hanno distribuzione
empirica normale.