Introduzione
alla
teoria della misura
LABORATORIO DI MISURE
(LAUREA TRIENNALE IN SCIENZE BIOLOGICHE)
a.a 2006-2007
Lino Miramonti
Dipartimento di Fisica – Università degli Studi di Milano
Via Celoria 16 - Milano
1
Analisi degli errori
Quando effettuiamo una misura, dobbiamo essere in grado di associare un
livello confidenza al risultato che abbiamo trovato:
Il risultato viene spesso espresso sotto forma di un intervallo, indicato con
x x
x
Indica
possiamo anche indicarlo come errore relativo:
o, come errore percentuale:
100
x
[ x x, x x ]
x
x
• Il grado di incertezza (errore sperimentale)
e viene preso, in generale, come l'intervallo
entro il quale la probabilità di trovare il
valore "vero" (che non conosciamo)
della misura è pari al 68%
• L‘errore associato alla misura
x
2
Possiamo dividere gli errori in 2 categorie (a seconda della loro origine):
• errori statistici
(o errori casuali)
precisione
• errori sistematici accuratezza
Non sono descrivibili per mezzo di una teoria
statistica (devono essere individuati ed eliminati!)
La teoria degli errori si occupa degli errori casuali,
chiamati così proprio perché
dipendendo da variabili casuali (in primis, la corretta interpolazione ed interpretazione della misura fornita
dallo strumento) determinano una dispersione del valore misurato attorno al valore vero, ma senza alcuna
direzione preferenziale
3
Abbiamo fatto riferimento ad un presunto valore vero (che indichiamo con )
della quantità che vogliamo misurare. In realtà, se dobbiamo effettuare una misura
vuol dire che noi il valore di quella quantità non lo conosciamo
Se dobbiamo misurare una quantità non nota sapendo che il valore misurato è affetto
da un errore casuale, può risultare utile ripetere la misura più di una volta,
aspettandosi che i diversi valori misurati si distribuiranno intorno a quello che è il
valore vero ma incognito
ATTENZIONE:
Questo tipo di procedimento risulta inutile se la misura della grandezza incognita
viene eseguita con uno strumento poco sensibile.
Data la grossolanità della gradazione dello strumento, sarà inutile effettuare più di
una misura, in quanto otterremo sempre lo stesso risultato.
(Questo tipo di errore è detto errore di sensibilità, Corrisponde all’errore
massimo che si commette nella misura, ed assorbe tutti gli errori casuali)
4
Supponiamo di fare un numero N di misure, avremo alla fine una serie di valori:
Rappresenta una informazione più precisa
rispetto alla singola misura, però è evidente che
non è possibile esprimere il risultato di una
misura come un insieme di tanti numeri diversi.
x1, x2 ,..... xN
Un caso analogo si manifesta quando la grandezza da misurare è riferita ad una data popolazione.
Generalmente le misure in questo caso vengono compiute su un sottoinsieme (campione) della popolazione completa
Campione Popolazion e
Ci si pone quindi il problema di come esprimere il risultato di tutte le misure.
Il modo più semplice è quello di considerare la media aritmetica delle singole misure:
N
valor medio
x
x
i
i 1
N
x1 x2 ...... xN
N
Il valor medio x così calcolato risulta la miglior stima del valore vero .
5
Per ognuno dei singoli valori misurati xi possiamo considerare che la differenza tra questo valore
ed il valore vero dia un’indicazione dell’errore.
Non conoscendo il valore vero, possiamo calcolare questa differenza, chiamata scarto,
utilizzando il valore medio come miglior stima del valore vero .
Come nel caso precedente, possiamo pensare a fare una media degli scarti:
x x x
N
i
i 1
1
N
x x2 x ...... xN x
x x ..... xN N x x1 x2 ...... xN N x
1 2
xx0
N
N
N
N
La media degli scarti si
rivela essere nulla,
il che ci suggerisce che la
definizione sia mal posta.
6
Più utile ai fini della stima dell'errore è la media
dei quadrati degli scarti (chiamata varianza)
N
Definiamo la varianza della popolazione come:
2x
x i 2
i 1
N
Campione Popolazion e
x
N
In mancanza della conoscenza di , si definisce la varianza del campione come:
S x2
i 1
i
x
2
N 1
7
Dal punto di vista dimensionale, per ricavare l’errore bisogna però fare la radice quadrata della varianza.
N
Definiamo la deviazione
standard della popolazione [SD] come: x
x2
x
i 1
2
i
N
Campione Popolazion e
x x
N
e la deviazione
standard del campione come:
Sx S
2
x
i 1
2
i
N 1
(queste grandezze prendono anche il nome di scarto quadratico medio).
8
Nella definizione delle grandezze relative al campione, notiamo che, oltre alla sostituzione, nel termine tra
parentesi, del termine con la sua stima , a denominatore è comparso un termine N-1 al posto di N.
Gradi di libertà definito come la differenza tra il numero di misure indipendenti ed il numero di
parametri calcolati da queste misure.
Per comprende meglio il significato del termine (N-1) considerando il caso estremo di N=1. In questo
caso, abbiamo una sola misura, e quindi il valor medio coincide con il valore misurato, mentre per la
deviazione standard, usando N a denominatore, otterremmo:
xi x
N
Sx
2
i 1
N
x
1
x
1
2
x1 x1 2
1
Da questo risulterebbe che
l’errore sulla misura è 0
assurdo!
0
Se invece usiamo la definizione con (N-1) a denominatore, troviamo che:
xi x
N
Sx
2
i 1
N 1
x
1
x
0
2
x1 x1 2
0
0
0
Che corrisponde ad un
caso di indeterminazione
e rappresenta in effetti la
situazione in cui ci si trova
(con una sola misura l’errore
risulta indeterminato).
9
Esempio
Una grandezza viene misurata 12 volte trovando i seguenti valori:
3.0 3.2 2.9 3.1 3.3 2.9 3.0 3.0 3.1 3.1 3.0 3.0
Possiamo ordinare i valori come nella Tabella,
Il valor medio è:
N
x
x
i
i 1
N
36.6
3.05
12
questo valore viene utilizzato per calcolare i termini
presenti nelle altre 2 colonne.
La somma dei quadrati è uguale a 0.15, per cui la
deviazione standard (scarto quadratico medio) è:
x x
N
Sx
i 1
2
i
N 1
0.15
0.0136 0.117
11
10
L’errore che abbiamo calcolato (la deviazione standard) è per definizione il valore medio dell’errore stimato
su ognuna delle misure; rappresenta l’errore “tipico” che possiamo associare ad ognuna delle misure.
Però ci possiamo attendere che l’errore sulla media sia minore
In effetti il motivo per cui si fanno misure ripetute è proprio per cercare di diminuire l’incertezza dovuta agli
errori causali; è quindi da aspettarsi che, mentre l’errore sulla singola misura sia approssimativamente
sempre lo stesso, l’errore sul valor medio diminuisca all’aumentare del numero delle misure effettuate.
Si introduce pertanto una grandezza detta deviazione
anche errore standard), il cui valore si dimostra essere:
x
N
Sx
i 1
i
x
2
N N 1
standard della media
[SDOM] (detta
Relazione tra
deviazione standard della media
e
deviazione standard del campione
x
N
Sx
i 1
i
x
N N 1
x
N
2
1
N
i 1
i
x
N 1
2
Sx
N
La deviazione standard della media diminuisce all’aumentare del numero di misure
(con la radice quadrata - se si vuol ridurre il valore della deviazione standard della media di un
fattore 10, si dovrà aumentare di un fattore 100 il numero delle misure effettuate)
11
Esempio bis
Nel caso dell’esempio precedente, la deviazione standard della media
risulta pari a:
xi x
N
Sx
i 1
2
N N 1
0.15
0.00114 0.034
12 11
Tenendo conto delle opportune cifre significative potremo scrivere il risultato nella seguente forma:
3.05 0.03
Abbiamo quindi ottenuto un risultato in cui è presente sia la misura che la sua incertezza!
12
Il problema delle cifre
significative
Definiamo cifre significative quelle cifre che esprimono realmente il risultato di una misura, o del suo
errore (cioè che non sono completamente incluse nell'intervallo di incertezza dovuto all'errore).
Le cifre significative vengono definite sulla base dell'errore, considerando la prima cifra (a partire da
sinistra) diversa da zero.
(regola pratica)
L'errore viene indicato con
una sola cifra significativa se la prima cifra diversa da zero è maggiore o uguale a 5 x 5
due cifre significative se la prima cifra è minore o uguale a 2
x2
Nelle altre situazioni, si possono indicare una o due cifre significative (Valutando caso per
caso l'effetto dell'approssimazione).
2 x5
Per il risultato l’approssimazione viene fatta allo stesso ordine di grandezza dell’errore.
Senza aver calcolato l'errore, non è possibile sapere quante sono le cifre
significative della misura e quindi a che livello bisogna approssimare!
13
ESEMPI:
11.415 ± 0.237
11.42 ± 0.24
(la prima cifra diversa da zero dell’errore è un 2, quindi tengo due cifre significative per l’errore:
approssimo sia l’errore che il valore al centesimo)
112459 ± 6740
112000 ± 7000
(la prima cifra diversa da zero dell’errore è il 6 nella posizione delle migliaia, e quindi devo
approssimare a questo ordine di grandezza; le cifre corrispondenti a centinaia, decine e unità non sono
significative, e non vengono quindi più esplicitate)
0.795 ± 0.048
1.146 ± 0.034
0.80 ± 0.05
1.146 ± 0.034
In questi 2 casi la prima cifre dell’errore diversa da zero è compresa tra 2 e 5, caso in cui la regola
suggerita lascia libertà di scelta su come agire. Nel primo caso la differenza tra il valore 0.048 e
l’approssimazione tra 0.05 è minima, per cui si può tenere una sola cifra significativa; nel secondo
caso, l’approssimazione da 0.034 a 0.03 comporterebbe una variazione di oltre il 10% del valore
dell’errore, per cui può ritenersi preferibile mantenere 2 cifre significative.
14
Distribuzioni
Riprendiamo l’esempio considerato precedentemente,
Avevamo 12 misure:
3.0 3.2 2.9 3.1 3.3 2.9 3.0 3.0 3.1 3.1 3.0 3.0
I valori misurati si possono catalogare anche in un modo diverso; vediamo infatti che, sulle 12
misure, ci sono 5 differenti valori e precisamente:
Il valore 2.9 è misurato 2 volte;
il valore 3.0 è misurato 5 volte;
il valore 3.1 è misurato 3 volte;
il valore 3.2 è misurato 1 volta;
il valore 3.3 è misurato 1 volta.
6
5
nk
4
Possiamo rappresentare questo risultato
con un grafico a barre dove ad ognuno
dei valori misurati mk corrisponde una barra
la cui altezza è uguale al numero di volte
che quel valore compare nk:
3
2
1
0
2.8
2.9
3.0
3.1
3.2
3.3
3.4
mk
15
Per ognuno dei valori misurati, possiamo definire la frequenza come il rapporto tra il numero di volte che
quel valore è stato misurato ed il numero totale di misure:
Fk
nk
N
Costruiamo la seguente tabella:
Fk
M
Vale la seguente condizione detta di normalizzazione
M
n
1
Fk k
N
k 1
k 1 N
M
n
k 1
k
3
0.25
12
N
1
N
16
Consideriamo nuovamente il valor medio
N
x
xi
i 1
N
12
xi
i 1
12
3.0 3.2 2.9 3.1 3.3 2.9 3.0 3.0 3.1 3.1 3.0 3.0
12
2.9 2.9 3.0 3.0 3.0 3.0 3.0 3.1 3.1 3.1 3.2 3.3
12
2 2.9 5 3.0 3 3.1 1 3.2 1 3.3
12
Vediamo che la sommatoria può essere riscritta come
somma di ogni singolo valore misurato (mk) per il numero di volte che tale misura è stata fatta (nk)
Ricordando la definizione di frequenza, otteniamo quindi il seguente risultato:
5
nk mk
k 1
12
M
n
k 1
k
mk
N
M
M
nk
mk Fk mk
k 1 N
k 1
Abbiamo quindi trovato:
M
x Fk mk
k 1
17
Distribuzione in intervalli (istogrammi)
valori continui
Quando passiamo da una variabile che può assumere solo valori discreti ad una che assume valori continui,
possiamo estendere questo tipo di trattazione dividendo l'intervallo dei possibili valori assunti dalla variabile in
una serie di sotto-intervalli di larghezza definita (bin).
Supponiamo ad esempio di avere 30 risultati di misure, compresi tra 21 e 25.
Definiamo ora 8 intervalli di larghezza 0.5, e contiamo il numero di misure che cadono in ognuno di essi:
0 ,3 0
0 ,2 5
F
k
0 ,2 0
Costruiamo l'istogramma corrispondente
L’aspetto del grafico dipende dalla scelta della larghezza dell’intervallo (bin) scelto.
•Troppi intervalli → numero troppo basso di misure per ogni intervallo (al lim distribuzione piatta)
•Pochi intervalli → si perde ogni informazione sulla distribuzione dei dati
0 ,1 5
0 ,1 0
0 ,0 5
0 ,0 0
2 1 ,0
2 1 ,5
2 2 ,0
2 2 ,5
2 3 ,0
m
2 3 ,5
2 4 ,0
2 4 ,5
2 5 ,0
k
18
Esempio
Dati i seguenti valori:
105
107
108
109
110
110
111
111
111
112
112
112
112
113
113
114
114
115
117
118
119
costruiamo due diversi istogrammi nelle seguenti 2 ipotesi:
A) tra 104.5 e 119.5, con intervallo 1
B) tra 104.5 e 119.5, con intervallo 3
A)
B)
0,50
0,45
0,40
0,35
Come si vede, quando la larghezza dell’intervallo è
piccola la distribuzione è poco diversa da una
distribuzione piatta; aumentando la larghezza
dell’intervallo abbiamo una concentrazione di dati
nell’intervallo centrale, a scapito dell’informazione sulla
distribuzione dei dati. Come si può notare l’altezza delle
barre nella figura aumenta all’aumentare della
larghezza dell’intervallo considerato
Fk
0,30
0,25
0,20
0,15
0,10
0,05
0,00
102
104
106
108
110
112
114
116
118
120
122
mk
19
Esempio (tra 110.5-113.5)
0.15x3 = 0.45
0.15x1 + 0.20x1 + 0.10x1 = 0.45
La modo più corretto per rappres. questo tipo di informazione
0.25
consiste nel
0.20
definita come
rapporto tra la frequenza e la larghezza dell’intervallo.
Frequenza (Fk )
Larghezza intervallo ( k)
Fk
x
Fk/k
riportare sull’asse delle ordinate la densità di frequenza
110.5-113.5
0.15
0.10
0.05
0.00
102
104
106
108
110
112
114
116
118
120
122
mk
In questo caso le aree dei 2 istogrammi risultano uguali, perché in un istogramma il numero di occupazione (e la
frequenza) non sono rappresentati dall’ordinata (altezza) ma dall’area (altezza·larghezza dell’intervallo).
20
Propagazione degli errori
Spesso capita che il valore della grandezza che si vuole determinare non è misurabile, ma deve essere
ricavato a partire da misure di altre grandezze ad essa correlate.
Ad esempio misurare la velocità di un oggetto (che per semplicità supponiamo si muova di moto rettilineo uniforme)
significa misurare il tempo che tale oggetto impiega per percorrere una determinata distanza. Quindi per misurare la
velocità dovremo misurare contemporaneamente lo spazio ed il tempo e calcolare il loro rapporto.
v
s
t
Un altro esempio è dato dal seguente; supponiamo di dover preparare una serie di soluzioni di diversa concentrazione,
sulla cui determinazione si dovrebbe essere in grado di fornire una stima della precisione. Per preparare la soluzione si
deve pesare una certa massa di soluto (usando una bilancia analitica di precisione), e sciogliere tale soluto in acqua in
appositi matracci tarati, che forniscono quindi la misura del volume totale della soluzione. Abbiamo pertanto:
m δm errore determinat o sulla base della sensibilit à delle bilancia
V δV errore determinat o sulla base della sensibilit à del matraccio
c
m
V
La relazione che lega le tre variabili c, m e V, come pure quella che lega spazio, tempo e velocità, è una relazione
funzionale (la grandezza è espressa in funzione delle altre due).
c f m,V
21
Generalizziamo i casi precedenti considerando una relazione funzionale del tipo:
y = f(x1, x2, …...xN)
che esprime una funzione f nelle variabili x1, x2,…...xN.
Si dimostra che l’errore sulla grandezza derivata è dato da:
2
2
2
f
f
f
f f
f
f
f x1
x2 ...
xN 2
x1x2 ..... 2
xN 1xN
x
x
x
x
x
x
x
1
2
N 1
N
1 2
N
I termini
x1x2 ,..., xN 1xN
sono detti termini di covarianza, e permettono di ricavare un indice della indipendenza o meno di due
variabili fra loro. Il coefficiente di correlazione
Nel caso in cui i termini di covarianza sono identicamente nulli (cioè le variabili sono tra loro indipendenti)
x1x2 ...... xN 1xN 0
La precedente assumerà la più semplice forma:
2
2
f
f
f
f
x1
x2 ...
xN
x1
x 2
x N
f
f
xi
i 1 xi
N
2
2
22
f x, y a x b y
Per semplicità consideriamo il caso di solo due variabili.
f x, y
a x b y a x b y a 0 a
x
x
x
x
f x, y
a x b y a x b y 0 b b
y
y
x
x
Sostituendo nell’ equazione generale della propagazione degli errori, troviamo:
2
2
f
f
f
f
x1
x2 ...
xN
x1
x 2
x N
2
Analogamente nel caso della differenza si trova:
f
a x 2 b y 2
f
a x 2 b y 2
L'errore su una grandezza che si esprime come somma o differenza di altre variabili si trova sommando in quadratura gli
errori delle singole variabili, moltiplicati per gli eventuali coefficienti moltiplicativi.
23
Sx
Sx
N
N
Consideriamo il caso di una serie di N misure.
Il valor medio di queste misure è stato definito come:
x
x
i
i 1
N
x1 x2 ...... xN
N
e l’errore su ognuna di queste misure si può stimare uguale alla deviazione standard del campione Sx.
Calcoliamo l’errore sulla media (deviazione standard della media) usando la formula della propagazione:
2
x
S x
S x
x
i 1
i
N
e cioè
Sx
2
1
Sx
i 1 N
N
N S x2
Sx
N2
N
Sx
N
che è esattamente ciò che avevamo trovato!
24
f x, y x a y b
Per semplicità consideriamo il caso di solo due variabili.
2
2
2
xa yb
xa yb
f
f
xk
x
y
x
y
k x k
2
2
a yb
b xa
x
y
y
x
x
y
y
f
b
y
a x a 1 x
a x a 1 x
b
x
2
a
x
2
a
b y b 1 y
b y b1 y
2
2
Questo risultato può essere meglio espresso se consideriamo l’errore relativo:
f
f
1
x y
a
b
y
b
a x a 1 x
y b a x a 1 x
xa yb
x
2
a
b y b 1 y
x a b y b 1 y
xa yb
2
f
2
2
2
a x b y
x
y
y
a x b
f
x
y
2
2
2
L’errore relativo su una grandezza che è funzione di potenze di altre variabili è uguale alla radice della somma in quadratura
degli errori relativi delle singole variabili, moltiplicati per il rispettivo valore dell’esponente.
25
Esempio
Riprendiamo l’esempio della concentrazione, introdotta precedentemente.
c
m
V
c m1 V 1
quindi:
2
c
1 m 1 V
c
V
m
2
cioè l'errore relativo sulla concentrazione si ottiene calcolando gli errori relativi su massa e volume,
moltiplicandoli per il fattore che si trova all'esponente, elevandoli al quadrato, facendone la somma e
infine la radice della somma.
26
Esempio
E’ dato un cilindro omogeneo, con sezione a corona circolare di raggi R1=
10 cm ed R2= 12 cm, la cui massa è M = 1000 g.
Supposto che
l’errore percentuale nella misura del raggio sia dello 0.5%, e che
l’errore percentuale nella misura della massa sia dell’1%,
stimare l’errore percentuale più probabile che si commette nella
determinazione del momento d’inerzia I del cilindro rispetto ad una
generatrice del cilindro esterno:
I
M
3 R22 R12
2
Soluzione:
Il momento d’inerzia è:
I
1000
3 144 100 2.66 105 g cm 2
2
L’errore nella determinazione del momento d’inerzia I si trova utilizzando la formula generale della
propagazione degli errori:
2
I
I
I
I
M
R1
R2
M
R1
R2
2
2
27
I
M
3 R22 R12
2
R1= 10 cm
R2= 12 cm,
M = 1000 g.
dove le derivate parziali rispetto alle tre variabili M, R1 e R2 sono:
I
3 2 1 2
M 2 R2 2 R1
I
M R1
R
1
I
3 M R2
R2
Gli errori sui valori misurati si calcolano a partire dagli errori percentuali:
Quindi
2
M 0.01 M 10 g
R1 0.005 R1 0.05 cm
R2 0.005 R2 0.06 cm
2
I
I
I
I
M
R1
R2
M
R1
R2
2
2
3 2 1 2
2
2
R2 R1 M M R1 R1 3 M R2 R2
2
2
2
100
3
2
2
144
10 1000 10 0.05 3 1000 12 0.06
2
2
3463 g cm 2
Pertanto l’errore relativo risulta pari a
3463
0.013 1.3%
2.66 105
28
Probabilità, pdf, Gaussiana
Introduciamo il concetto in
maniera
empirica ed intuitiva.
Consideriamo un dato sistema, in cui il verificarsi di un evento
un numero N di casi possibili ed equiprobabili:
E presenta n casi favorevoli su
n casi favorevoli
N casi possibili
Possiamo definire la probabilità P(E) che l’evento si verifichi, come il rapporto fra il numero
dei casi favorevoli n, ed il numero dei casi possibili ed equiprobabili N:
P( E )
n
N
29
Così ad esempio
•La probabilità che lanciando un dado si ottenga il valore 4 sarà pari ad 1/6; infatti il
dado è composto dai numeri: 1, 2, 3, 4, 5 e 6, quindi abbiamo N = 6 casi possibili e n=1
casi favorevoli (il numero 4).
•La probabilità di ottenere un numero pari sarà invece di 1/2, infatti si hanno n = 3 casi
favorevoli (potrebbe uscire indifferentemente il 2, il 4 od il numero 6) e N = 6 casi possibili,
quindi in definitiva avremo P(E) = 3/6 = 1/2.
30
Per come è stata definita, la probabilità comporta la conoscenza a priori del sistema “probabilità a priori” e
ciò non sempre è possibile. Inoltre nella definizione si introduce il concetto di eventi equiprobabili utilizzando di
conseguenza il concetto di probabilità che si vorrebbe definire.
In generale, però, la probabilità non è nota a priori.
Supponiamo quindi di eseguire un numero N di prove di un certo sistema, e verifichiamo che un dato evento E
si verifica n volte. Si definisce frequenza il rapporto tra il numero di prove in cui l’evento si è verificato ed il
numero totale di prove eseguite. La frequenza n/N è anche detta probabilità empirica o “probabilità a
posteriori”.
La legge empirica del caso stabilisce che se si conosce a priori la probabilità che un dato evento si verifichi, la
N
frequenza tenderà alla probabilità al crescere delle prove eseguite. Frequenza
Probabilit à
Il valore fluttuerà di conseguenza intorno ad un valore ben determinato che è la probabilità a priori e tenderà a
stabilizzarsi col crescere delle prove.
Simulazione al calcolatore di un lancio di dadi: Si vede come
tutte le traiettorie rivelano la tendenza a convergere verso il
valore 1/2
Quindi quanto più grande è il numero N di prove, più la
frequenza (o probabilità a posteriori) tende alla probabilità
a priori.
P( E )
n
N
per
N
31
Definiamo adesso la probabilità
in termini assiomatici.
Definiamo probabilità di un evento E un numero reale P(E)
che soddisfa i 3 assiomi seguenti:
1) La probabilità di un dato evento è sempre positivo o nullo: P(E) ≥ 0
2) La somma delle probabilità di tutti gli eventi possibili è uguale ad 1.
3) Se indichiamo con E1 ed E2 due eventi mutuamente esclusivi, la probabilità che si verifichi o l’evento E1 o
l’evento E2 è pari alla somma delle loro probabilità.
P(E1E2)=P(E1)+P(E2) con E1E2 = .
La definizione assiomatica di probabilità non fornisce alcuna indicazione di come la probabilità
P(E) associata ad un dato evento E debba essere valutata. Tale valutazione deve essere
ricercata in altri ambiti; come ad esempio la ricerca della frequenza relativa facendo un numero
di prove sufficientemente elevato o ove possibile attraverso la probabilità a priori.
32
Generalizziamo ora il 3^ assioma, consideriamo cioè il caso che gli eventi E1 ed E2 non siano
mutuamente esclusivi, cioè E1E2 .
In questo caso la probabilità che si verifichi o l’evento E1 o l’evento E2 è pari:
P(E1E2)=P(E1)+P(E2)-P(E1E2)
con
E1E2
Consideriamo ad esempio un mazzo di 40 carte, e chiediamoci quale è la probabilità di ottenere una figura od una carta di
colore rossa estraendo una carta dal mazzo.
Indichiamo con
P(E1) la probabilità di ottenere una figura
e con
P(E2) la probabilità di ottenere una carta di colore rosso.
In un mazzo di carte abbiamo:
12 figure
20 carte rosse
P(E1) = 12/40,
P(E2) = 20/40
Ma gli eventi E1 ed E2 non sono mutuamente esclusivi, cioè le figure di colore rosso soddisfano ad entrambe le condizioni; di
conseguenza, se considerassimo la semplice somma della probabilità terremmo conto due volte della probabilità di estrarre
una carta che è contemporaneamente figura e rossa.
La probabilità che si verifichi o l’evento E1 o l’evento E2: P(E1E2) non sarà quindi la semplice somma delle probabilità, ma
dovremmo tener conto (sottrarre) della probabilità P(E1E2)
Nel nostro esempio P(E1E2) = 6/40 (sono infatti 6 le figure di colore rosso).
Quindi la probabilità che pescando da un mazzo di carte otteniamo una figura od una carta di colore rosso è:
PE1 E 2 P( E1 ) P( E 2 ) P( E1 E 2 )
12 20 6 26 13
40 40 40 40 20
33
Per contro se avessimo chiesto quale è la probabilità di estrarre o un
asso o un re, questa sarebbe stata banalmente la somma delle
probabilità, essendo l’intersezione dell’insieme “assi” e dell’insieme
“re” vuoto (non esistono carte che siano al tempo stesso asso e re).
Quindi la probabilità che pescando da un mazzo di carte otteniamo un
asso o un re è pari a
PE1 E 2 P( E1 ) P( E 2 )
4
4
8 1
40 40 40 5
34
Probabilità composta
Quale è la probabilità di ottenere contemporaneamente il verificarsi di due (o più) eventi ciascuno con
probabilità P(E)?
Si può dimostrare che la probabilità composta che indicheremo con P(E1+E2) [o più in generale
P(E1+E2+...En) ], nel caso di eventi indipendenti è pari al prodotto delle singole probabilità:
PE1 E2 P( E1 ) P( E2 )
Così nel caso del lancio di un dado la probabilità di ottenere due volte il numero 6 pari a:
P E1 E 2 P( E1 ) P( E 2 )
1 1 1
6 6 36
La condizione di indipendenza è necessaria!
35
Consideriamo infatti il seguente esempio:
Si estraggano due carte da un mazzo di 40 carte, e chiediamoci quale è la probabilità di ottenere due assi.
Potremmo erroneamente pensare la probabilità di ottenere 2 assi sia di:
1 1
1
10 10 100
in realtà l’uscita del secondo asso è condizionata dall’estrazione della prima carta; infatti se la prima carta
estratta non è un asso, allora la probabilità di ottenere un asso dalla seconda carta sarà 4/39 (essendo il
numero delle carte totali diminuito di una unità) se poi la prima estrazione fosse stata un asso, la
probabilità di ottenere un secondo asso dalla successiva estrazione sarebbe pari a 3/39 (ora il numero di
eventi favorevoli è pari a 3, essendoci un asso in meno nelle 39 restanti carte).
Una situazione di questo tipo viene descritta introducendo la probabilità condizionata, cioè la
probabilità che avvenga un evento E2 una volta avvenuto l'evento E1, e che indichiamo con il simbolo
PE1 E2 P( E1 ) P( E2 E1 )
Nell’esempio precedente, la condizione di indipendenza potrebbe essere ristabilita, se ad esempio una
volta estratta la prima carta, la si riponesse nel mazzo.
36
Ritorniamo ora all’esempio delle variabili distribuite con continuità, e consideriamo l'ipotesi in cui gli errori
siano esclusivamente di tipo casuale.
0.25
0.25
0.20
0.20
0.15
0.15
Fk/x
Fk/x
Se si aumentano le misure, si verifica che la distribuzione delle stesse attorno al valor medio assume
una forma maggiormente simmetrica
.
Aumentare il numero delle misure, permette anche di ridurre la dimensione del singolo intervallo scelto
per la costruzione dell'istogramma, quindi di ottenere una informazione maggiormente puntuale sulla
forma di questa curva.
0.10
0.10
0.05
0.05
0.00
0.00
mk
mk
37
Nell’ipotesi limite di un numero infinito di misure, potremmo idealmente far tendere a zero la
larghezza dell'intervallo, ottenendo una informazione puntuale sulla forma della curva, e sostituire la
serie di valori con una funzione vera e propria, chiamata
funzione di densità di probabilità che indichiamo con f(x), ove x rappresenta la variabile misurata.
Se questa funzione deve descrivere una distribuzione di probabilità, allora deve valere
la condizione di normalizzazione, che in questo caso si scrive come:
M
F
k
k 1
1 M
f ( x ) dx 1
Abbiamo in pratica sostituito la frequenza con la probabilità (area di altezza f(x) e larghezza dx).
Nel caso di misure con errori casuali, si può dimostrare che la distribuzione di probabilità assume
la caratteristica forma a “campana” detta distribuzione
espressa mediante la seguente espressione:
G x f , x
1
2
e
x 2
22
gaussiana o distribuzione normale
1,0
Curva centrata attorno al valore µ di larghezza σ
0,5
1
3
0,8
0,6
0,4
Fattore di normalizzazione, che garantisce
l’integrale della curva sia uguale a 1
0,2
0,0
5
10
15
20
25
38
Qual è il significato di questa curva nel caso della conduzione di misure con errore casuale?
La curva f(x)dx dà la probabilità di ottenere un certo valore x effettuando una misura
Il valore , attorno al quale la curva è centrata, è identificabile col
valore vero della grandezza che
vogliamo misurare, mentre la larghezza σ è in qualche modo legata alla precisione sulla misura.
Ricordando la definizione di valor medio calcolato con la frequenza, e generalizzando al caso delle
funzioni di distribuzione di probabilità, possiamo scrivere:
M
x mk Fk
M
k 1
x
x f ( x ) dx
e inoltre:
2
x x f ( x) dx
2
Andando a risolvere l’integrale presente nell’espressione precedente, si trova che:
• (nel caso ipotetico di un numero infinito di misure).
il valor medio
N
x
risulta essere uguale ad il valore vero µ
• (nel caso reale di un numero finito di misure), risulta che
il valor medio x calcolato con la formula nota risulta essere la miglior stima di µ
la deviazione standard Sx risulta la miglior stima di σ
39
Esempio
Quindi, riprendendo l’Esempio introdotto all’inizio in cui avevamo
Valor medio pari a 3.05
e deviazione standard pari a 0.12
3.05
4
possiamo costruire la corrispondente funzione normale:
G x f , x
1
0.12 2
x 3.052
2
e 20.12
G(x)dx per ogni valore x, esprime la probabilità che
il risultato della misura cada in intervallo dx intorno a
G(x)
Ovviamente G(x) è massima in corrispondenza di :
G( )
1
2
-
+
3
2
1
0
2.5
3.0
3.05-0.12=2.93
3.5
3.05+0.12=3.17
3.3 G (3.05)
40
La probabilità di trovare un valore che “dista”
dal valore medio non più di σ è pari a 0.6827.
Cioè nel 68.27% dei casi, ci aspettiamo di
trovare come risultato della misura un valore
che dista meno di una deviazione standard
dal valore vero
4
-
+
3
2
68.27%
(quindi nel 31.73% dei casi la differenza tra
valore misurato e valore vero può essere
maggiore di una deviazione standard!!)
1
0
La curva G(x) però scende rapidamente e la
probabilità di trovare il risultato della misura
nell’intervallo di n scende molto con n
2.5
3.0
3.5
31.73%
Prob in (±1σ) = 0.6827 (68.27%)
complementare (~30%)
Prob in (±2σ) = 0.9545 (95.45%)
complementare (~5%)
Prob in (±3σ) = 0.9973 (99.73%)
complementare (~0.3%)
Prob in (±tσ) =
41
E' possibile ricavare il valore della
probabilità per qualsiasi intervallo,
simmetrico o meno.
t( x)
x
In appendice (delle dispense) è
riportata una tabella che fornisce
le probabilità di trovare un valore
in un generico intervallo sim-
±t·σ
metrico
centrato intorno
al valore vero , per valori di t
compresi tra 0.0 e 5.0.
42
Esempio di utilizzo tabella
Consideriamo ad esempio il caso in cui µ=15 e σ=0.5.
In questo caso,
+ = 15+0.5 = 15.5,
- = 15-0.5 = 14.5,
e quindi l’intervallo ±σ (68.27% di probabilità), corrisponde all’intervallo [14.5-15.5]
analogamente l’intervallo ±2σ (95.45% di probabilità) corrisponde all’intervallo [14-16].
0,8
Gaussiana con X = 15 e = 0.5
0,6
0,4
Gaussiana con X = 15 e = 3
0,2
0,0
12,0 12,5 13,0 13,5 14,0 14,5 15,0 15,5 16,0 16,5 17,0 17,5 18,0
43
Se σ = 3, l’intervallo [14.5-15.5] corrisponderebbe a ± 0.17σ.
Infatti la differenza tra ogni singolo estremo dell'intervallo e il valor medio è pari a 0.5, che è una
0.5 0.5
frazione di .
t
0.17
3
Quindi
14.5 = - 0.17
15.5 = + 0.17
e dalla tabella in appendice possiamo vedere che il valore di probabilità associato a t=0.17 è pari al
13.50%.
l’intervallo corrispondente al 68.27% di probabilità (±σ) è [12,18 ].
0,8
Gaussiana con X = 15 e = 0.5
0,6
0,4
Gaussiana con X = 15 e = 3
0,2
0,0
12,0 12,5 13,0 13,5 14,0 14,5 15,0 15,5 16,0 16,5 17,0 17,5 18,0
44
Due misure, supposte affette da errori casuali, si dicono tra loro compatibili quando la loro differenza può
essere ricondotta ad una pura fluttuazione statistica attorno al valore nullo
(ovvero, se possono essere considerate uguali, nei limiti dei rispettivi errori sperimentali).
Il concetto di compatibilità può essere quantificato per mezzo del "livello di confidenza" (CL,) che
esplicita il valore di probabilità con cui si vuole essere sicuri ("confidenti") che le due misure siano
compatibili, ed indica la probabilità che la loro differenza sia una fluttuazione statistica intorno al valore nullo.
Si parte dall'ipotesi che, se due misure
x1 S1
x2 S 2
Se si riferiscono allo stesso valore vero, la loro differenza deve essere distribuita normalm. attorno al valore 0.
Si calcola:
a) la differenza
b) l'errore su questa differenza
e si calcola il rapporto
t
x2 x1
S diff S12 S 22
x 2 x1
S diff
e si ricava dalla tabella della gaussiana la probabilità di ottenere una differenza grande come quella osservata
o più grande di quella osservata , per una distribuzione delle differenze con valore centrale 0 e σ = Sdiff.
In genere due misure si dicono compatibili se CL > 5% (≈ 2 σ) e incompatibili se CL < 0.3% (≈ 3 σ)
45
Esempio
Due gruppi di studenti fanno due misure della stessa grandezza, trovando i seguenti valori:
35 3
29.1 0.2
Discutere la compatibilità dei due risultati.
Abbiamo:
x2 x1 35 29.1 5.9
S diff
S x 2 2 S x1 2
32 0.2 3.01
2
t
x 2 x1
S diff
5.9
1.96
3.01
Questo vuol dire che la differenza (5.9) “dista” dal valore atteso 0 di un fattore che è pari a 1.96
volte la deviazione standard sulla differenza:
Ora, dalla tabella della gaussiana ricaviamo che la probabilità di avere un valore che “dista” dal
valore atteso di un fattore inferiore a 1.96 deviazioni standard è 0.05 (5%). Quindi possiamo dire
che i due valori sono tra loro compatibili con un livello di confidenza del 5%.
46
Medie Pesate
Consideriamo N studenti (1,2,…N) che misurano la stessa grandezza ottenendo i seguenti risultati:
Studente 1 :
Studente 2 :
Studente N :
x1 1
x2 2
Miglior media di tutte le misure dello studente 2
xN N
Deviazione standard della della media
Supponiamo che le misure
effettuate dagli N studenti siano
consistenti:
cioè la differenza tra
x1.x2…..xN non sia
significativamente più grandi di
δ1, δ2…..δN
Ci poniamo il problema di trovare il modo migliore di combinare x1.x2…..xN
per ottenere una singola miglior stima di µ
Se uno dei due studenti ha eseguito una misura con una precisione maggiore degli altri (cioè il suo
δ è minore),
sarà lecito aspettarsi che alla sua misura debba essere dato un maggior peso (maggiore considerazione).
In qualche modo bisognerebbe "privilegiare" le informazioni fornite dalle misure più precise.
Fare semplicemente la media dei singoli valori tratterebbe tutti i dati come equivalenti
47
Ognuna delle singole misure è riferita allo stesso valor vero µ; ci aspettiamo quindi che ad ognuna di
esse sia associata una distribuzione normale centrata attorno a tale valor vero.
Quindi, possiamo scrivere che la probabilità di effettuare la
misura xi con associato l’errore i è proporzionale alla relativa
funzione gaussiana centrata su μ:
P ( xi )
1
i
( xi )2
e
2 i2
Quindi, alla serie di misure x1±1, x2±2 , …… xN±N sono associate le probabilità P(x1) , P(x2) , ..., P(xN)
La probabilità congiunta di avere la serie di misure x1±1, x2±2 , …… xN±N è data dal seguente
prodotto:
Se indipendenti!
P( x1 , x2 ,....., xN ) P( x1 ) P ( x2 ) ...... P( xN )
1
1
e
( x1 ) 2
2 12
1
2
e
( x2 ) 2
2 22
......
1
N
e
( xN )2
2 N2
1 ( x1 2 )
e 2 1
i 1 i
N
2
48
la precedente espressione può essere riscritta come:
P( x1 , x2 ,......, xN )
1
Dove abbiamo indicato
N
i 1
e
N
i 1
2
( xi )2
2 i2
i 1
N
i
( xi )2
i2
1
i 1
( CHI
e
N
2
2
i
QUADRATO)
Il principio della MASSIMA VEROSIMIGLIANZA asserisce che la miglior stima per il valor vero μ è quella
che massimizza la probabilità congiunta di aver effettuato la serie di misure x 1±1, x2±2 , … xN±N.
La miglior stima del valore vero µ si trova andando a minimizzare il valore del CHI QUADRATO.
Ricordiamo che per trovare i punti di minimo, si deve porre uguale a zero la derivata del CHI QUADRATO rispetto
alla variabile considerata (in questo caso, μ):
2
d
0
d
49
Si può dimostrare che tale condizione viene soddisfatta in corrispondenza del seguente valore:
N
xbest
i 1
N
2
i
1
i 1
N
xi
2
i
x
i 1
i
Dove abbiamo indicato con
xbest
la miglior stima del valore vero µ
wi
N
w
i 1
i
wi
Si può poi dimostrare che l’incertezza vale:
x
best
1
1
N
1
i 1
" peso"
2
i
2
i
1
N
w
i 1
i
50
Dimostrazione della formula delle Medie Pesate:
Consideriamo per semplicità due misure, che indicheremo con misura 1 e misura 2:
Ipotizziamo che entrambe le misure sono governate dalla distribuzione normale, e denotiamo con il valore
vero incognito di x.
Px1
La probabilità che la misura 1 fornisca il valore x1 è:
1
e
1
e analogamente la probabilità che la misura 2 fornisca il valore x2 è:
x1 2
212
P x 2
1
e
2
x2 2
2 22
La probabilità che la misura 1 fornisca il valore x1 e la misura 2 fornisca il valore x2 è il prodotto delle due
probabilità:
1
Px1 , x 2 Px1 P x 2
e
1 2
dove, come in precedenza, abbiamo indicato con:
x 2 x 2
1 2 2 2
2 2
21
2
x
1
1
2
2
1
e 2
1 2
x 2
2
2
51
Il principio di massima verosimiglianza afferma che la migliore stima del valore vero incognito è quel
valore che rende massima la probabilità delle effettive osservazioni x1 ed x2.
Quindi la migliore stima del valore vero
è il valore per il quale la probabilità
Px1, x2 è massima,
o se si preferisce, il valore di è 2 minimo.
2
x
1
1
2
x 2
2
2
2
Per trovare tale miglior stima differenziamo quindi rispetto a e uguagliamo la derivata a zero:
d 2
0
d
x
x
d 2
2 1 2 2 2 2 0
d
1
2
e risolvendo rispetto a si ottiene:
x best
x1 x 2
2 2
2
1
1
1
2 2
2
1
N
che nel caso generale di N misure diviene:
x best
x
2i
i 1
N
i
1
2
i 1
i
52
Si può dimostrare inoltre con pure semplificazioni algebriche che, come è lecito attendersi, le formule
precedenti si riducono alla formula generale della media aritmetica se tutte le incertezze sono uguali tra
loro:
N
xbest
2
i 1
N
i
1
2
i 1
N
xi
1 2 ... N
xbest
i
xi
2
i 1
N
1
2
i 1
1
2
N
xi
i 1
N
2
N
1
2
N
xi xi
i 1
1
2
N
i 1
N
che è appunto la definizione di media aritmetica.
53
Esempio
Quattro gruppi di studenti misurano con quattro differenti metodi la massa di rame depositata sul catodo
in seguito ad una elettrolisi con solfato di rame, e trovano i seguenti valori, espressi in mg:
10.3
9 .8
10.5
9.9
0 .3
0 .1
0. 5
0 .4
Calcolare la miglior stima della massa, e la sua incertezza.
Abbiamo quattro diverse misure, condotte in maniera indipendente l’una dall’altra, ognuna corredata dal
proprio errore sperimentale.
4
xi
i 1
4
1
i 1
2
i
2
i
10.3
9.8
10.5
9.9
1198.3
2
2
2
0.3 0.1 0.5 0.42
1
1
1
1
121.36
0.32 0.12 0.52 0.42
4
xbest
xi
i 1
4
1
i 1
2
i
2
i
1198.3
9.87
121.36
x
best
1
4
1
i 1
1
0.09
121.36
2
i
54
Se avessimo calcolato la miglior stima della massa con la formula della semplice media aritmetica
(trascurando cioè le informazioni sulla precisione dei singoli metodi), avremmo trovato il seguente
risultato:
N
x
x
i 1
i
N
10.3 9.8 10.5 9.9
10.125
4
x
4
x
i
x
2
i 1
N N 1
0.165
che, tenendo conto delle cifre significative, si dovrebbe scrivere 10.13 0.17. Si vede quindi come la
bassa incertezza associata al valore 9.8 fa in modo che questo termine, nella formula delle medie
pesate, abbia un peso maggiore, e quindi porti a stimare il valore della massa più basso rispetto a
quanto trovato usando la formula classica della media aritmetica.
Media Pesata
11
10
9
8,6
8,8
9,0
9,2
9,4
9,6
9,8
10,0
10,2
10,4
10,6
10,8
11,0
11,2
11,4
11,6
11,8
12,0
valori della massa misurata
55
Dimostrazione di come il Valor
Medio sia la miglior stima del Valore Vero
Sia dato un numero N di misure x1, x2, …., xN, ci proponiamo di trovare la miglior stima di μ e σ basandoci
su gli N valori misurati. Supponiamo che le nostre misure siano distribuite normalmente, seguano cioè la
funzione:
G x f , x
1
2
e
x 2
2 2
Se conoscessimo i parametri µ e σ, potremmo calcolare la probabilità di ottenere i valori x1, x2, …., xN che
si sono presentati come risultato delle nostre misure.
Di conseguenza la probabilità di ottenere una lettura vicino a x1 è proporzionale a:
Px1
1
e
x1 2
2 2
la probabilità di ottenere una lettura vicino a x2 è proporzionale a:
Px2
1
e
x2 2
2 2
e conseguentemente la probabilità di ottenere una lettura vicino a xN è proporzionale a:
Px N
1
e
xN 2
2 2
56
La probabilità di ottenere contemporaneamente l’insieme delle N misure è il prodotto delle singole probabilità:
Px1 , x2 , ..... x N
1
N
e
N
xi 2
i 1
2 2
Ricordiamo che il valori di µ e σ nell’equazione precedente non sono noti, quello che stiamo cercando è la
loro miglior stima basandoci sulle osservazioni delle N misure x1, x2, …., xN.
Applichiamo il principio di massima verosimiglianza: cerchiamo cioè i valori di e che rendono massima
la probabilitàP , x1 , x2 , ..... x N
La probabilità è massima quando la somma ad esponente è minima
N
Dovremo pertanto differenziare
xi 2
i 1
Derivando rispetto a μ otteniamo:
2 2
rispetto alle due variabili e porre le derivate uguali a zero:
xi 0
N
i 1
x1 x2 ........... x N 0
Quindi
x1 x 2 ........... x N N 0
N
N x1 x 2 ........... x N xi
i 1
N
Il che comporta che la miglior stima per µ è
x
i 1
N
i
x
57
Derivando rispetto a σ e procedendo come fatto per μ si ottiene:
N
x
i 1
2
i
N
che con la sostituzione di µ con x porta alla già nota:
x
N
Sx
i 1
i
x
2
N
La sostituzione di μ con x comporta una sottostima di Sx. Pertanto il suo valore deve essere
“riaggiustato” sostituendo al denominatore N con (N-1); in questo si ritrova la più corretta formula
per la deviazione standard:
x
N
Sx
i 1
i
x
2
N 1
58
Relazione funzionale
Consideriamo il caso in cui vogliamo verificare una relazione funzionale tra due grandezze x e y:
y f (x )
Possiamo misurare i valori di y in corrispondenza di diversi valori di x:
y1
y
2
y3
yn
f ( x1 )
f ( x2 )
f ( x3 )
.
.
f ( xn )
In genere, gli xi sono supposti noti con errore trascurabile, mentre agli yi viene associato un errore
sperimentale i.
59
Consideriamo ad esempio un grave che cade
dalla cima di un palazzo. Supponiamo di rilevare la
posizione del grave ad intervalli (ad esempio regolari) di
tempo; registriamo cioè la coppia di valori (tempo,spazio)
più volte.
y f (x )
Se riportiamo su un grafico lo spazio percorso dal
grave in funzione del tempo otterremo che i punti si
disporranno su una parabola secondo la ben nota
relazione:
s
1 2
gt v0 t s0
2
s f (t )
Se invece registriamo la coppia di valori
(tempo,velocità) cioè rileviamo la velocità del grave in
funzione del tempo, troveremo che i punti si disporranno
su di una retta secondo la relazione lineare:
v gt v0
s h(t )
60
La funzione f che lega y a x dipende da una serie di parametri (nel caso delle leggi del moto, posizione
iniziale x0, velocità iniziale v0, accelerazione g).
Nel caso in cui questi parametri siano incogniti, li possiamo ricavare dalle misure effettuate ricordando che
la funzione di distribuzione di probabilità per una misura yi è data dalla funzione gaussiana centrata sul
valore vero y0 e con larghezza σ. Il valore vero attorno a cui la distribuzione è centrata corrisponde a quello
previsto dalla relazione funzionale f(xi), mentre la larghezza della distribuzione corrisponde all’errore
sperimentale δi. Quindi, avendo misurato il valore yi con errore σi, la probabilità di quella misura è
esprimibile come:
f yi
1
i 2
yi f ( xi ) 2
2 i2
e
Questo discorso vale per ognuno dei valori misurati yi. La probabilità di tutta la serie di misure y1, y2, …..yN,
è data dal prodotto delle singole probabilità:
f y
i
i
1
i
2 n
e
i
yi f xi 2
2 i2
i
Applicando di nuovo il principio della massima verosimiglianza, discende che i valori incogniti dei parametri
che caratterizzano la relazione funzionale studiata si trovano massimizzando tale probabilità.
61
Limitiamo l'analisi al caso di una relazione di tipo lineare:
y A Bx
B coefficiente angolare
A Ordinata all’origine
Lo scopo è trovare la retta
y A Bx
che meglio si adatta alle misure.
Ciò significa trovare la miglior stima delle costanti A e B basandoci sui dati
x1 , y1 x2 , y2 ..... x N , y N
Possiamo riscrivere la probabilità introdotta precedentemente esplicitando la relazione lineare: f xi A B xi
i
f yi
1
i
2 n
e
i
yi A B xi 2
2 i2
i
62
Si dimostra che i valori di A e B che massimizzano la probabilità sono dati da:
xi2
A
yi
i
2
i
i
2
i
i
xi y i
i2
i
xi
i i 2 i 2
i
i
2
i
2
i
x
1
xi
xi y i
i2
B
2
1
2
i
i
i
2
i
i
xi
i2
i
xi
i 2 i 2 i 2
i
i
i
xi2
1
yi
i2
2
Gli errori su A e B, che nel caso più comune in cui gli errori sperimentali sono casuali corrispondono
ad una deviazione standard e per questo li indichiamo con , sono dati da:
xi2
2
A
i
2
i
xi
i i 2 i 2
i
i
2
i
2
i
x
1
1
2
2
B
i
2
i
xi
i 2 i 2 i 2
i
i
i
xi2
1
2
63
Siccome i due parametri A e B sono stati trovati in maniera non indipendente, ma entrambi ricavati
dallo stesso set di dati, si verifica che il termine di covarianza risulta essere diverso da 0:
xi
AB
i
2
i
x
i 2 i 2 i i2
i
i
i
xi2
Si definisce inoltre il termine di correlazione
1
AB
2
AB
A B
che è un indice della correlazione tra i parametri A e B.
64
Nel caso in cui i valori y1 , y2 , ...... y N
siano dati senza errore, oppure nel caso in cui gli errori siano tra loro tutti uguali, le formule precedenti
si semplificano nel modo seguente:
A
x y x y x
2
i
i
i
i
i
i
i
i
B
i
N xi2 xi
i
i
2
N xi yi xi yi
i
i
i
N xi2 xi
i
i
2
Gli errori su A e B e il termine di covarianza si calcolano come:
2
A
y2 xi2
N xi2 xi
i
i
AB
y2
2
B
i
2
N y2
N x xi
i
i
2
2
i
y2 xi
i
N xi2 xi
i
i
2
corrisponde all’errore tipico sulla misura, se tale dato è disponibile.
65
Quando
y2 non viene specificato, deve essere ricavato a posteriori mediante la formula:
y
1
yi A B xi 2
N 2 i
A denominatore c'è un termine N-2 invece che N. Ricordando la definizione di
gradi di libertà, vediamo che in questo caso i gradi di libertà sono N-2 (sono
infatti 2 i parametri ricavati dai dati, A e B).
Se avessimo considerato due sole coppie di valori (come sappiamo dalla
geometria elementare per due punti passa una ed una sola retta), la formula di
σy, con N al denominatore darebbe come risultato il valore 0 il che è assurdo;
invece con N-2 otterremmo sotto la radice il termine
0
y
0
che essendo una forma di indecisione indica che per solo due misure il valore
σy è giustamente indeterminato.
66
Una volta determinati quindi i coefficienti A e B della relazione lineare, possiamo usare questa relazione per
calcolare il valore y' assunto per un qualsivoglia valore della variabile indipendente x'. Per calcolare l'errore
su y', applichiamo la formula della propagazione degli errori, ricordandoci che in questo caso A e B non
sono indipendenti, in quanto il loro termine di covarianza è diverso da zero:
2
y ' A B x'
Quando
2
y '
y '
y ' y '
y ' A B 2
AB
A B
A B
1 A 2 x' B 2 2 x' AB
y2 non viene specificato, deve essere ricavato a posteriori mediante la formula:
y
1
yi A B xi 2
N 2 i
A denominatore c'è un termine N-2 invece che N. Ricordando la definizione di
gradi di libertà, vediamo che in questo caso i gradi di libertà sono N-2 (sono
infatti 2 i parametri ricavati dai dati, A e B).
Se avessimo considerato due sole coppie di valori (come sappiamo dalla
geometria elementare per due punti passa una ed una sola retta), la formula di
σy, con N al denominatore darebbe come risultato il valore 0 il che è assurdo;
invece con N-2 otterremmo sotto la radice il termine
0
y
0
che essendo una forma di indecisione indica che per solo due misure il valore
σy è giustamente indeterminato.
67
Calcoliamo le costanti A e B
Facciamo due assunzioni per semplificare il problema:
- Gli errori su x siano trascurabili
- Gli errori su y siano tutti uguali e governati da una distribuzione di Gauss
(vedremo poi il caso più generale)
Se conoscessimo le costanti A e B allora per ogni dato valore xi potremmo calcolare il valore vero del
corrispondente yi
Valore vero per
yi A Bx i
La misura di yi è governata da una distribuzione gaussiana centrata su questo valore vero con
larghezza y.
Allora la probabilità di ottenere il valore osservato yi è:
1
PA, B ( yi )
e
y
( yi A Bxi ) 2
2 y2
La probabilità di ottenere l’insieme completo di misure y1…………yN è il prodotto:
2
1 2
PA,B ( y1 y N ) PA,B ( y1 ) PA,B ( y N ) N e
y
68
N
2
Dove abbiamo indicato
yi A Bxi 2
y2
i 1
Le miglior stime per A e B le otterremo differenziando 2 rispetto ad A e B e ponendo le derivate uguali
a zero:
2 N
2
2 yi A Bx i 0
i 1
A
y
2 2 N
xi yi A Bx i 0
2
B
y i 1
Queste 2 equazioni possono essere riscritte:
AN B xi yi
A x B x2 x y
i i i
i
Che risolte danno:
x y x y x
A
N x x
2
i
i
i
2
i
i
2
i
i
B
N xi y i xi y i
N xi2 xi
2
69
Lo spazio percorso da un corpo che si muove di moto rettilineo uniforme viene
misurato in corrispondenza di 8 diversi istanti:
Esempio
70
60
1
3
6
9
10
12
16
19
50
si (m)
1.27
8.3
19.0
28.8
33.1
40.0
52.1
61.0
40
σi (m)
0.12
0.3
0.8
1.1
1.0
1.0
1.0
1.2
si(m)
ti (s)
30
s ( t ) s0 v t
20
Trovare la posizione iniziale del corpo e la sua velocità
10
0
0
2
4
6
8
10
12
14
16
18
20
ti(s)
Si costruisce la seguente tabella:
70
da cui si ricava, applicando le formule introdotte in precedenza:
A
1043.3 401.5 3206.7 170.8
2.10
2
1043.3 86.6 170.8
A
3206.7 86.6 170.8 401.5
B
2
1043.3 86.6 170.8
A
B
1043.3
2
1043.3 86.6 170.8
86.64
2
1043.3 86.6 170.8
3.42
xi2
yi
2
i
2
i
i
i
xi2
i
2
i
i
xi yi
i
2
i
i
x
i2
2
i i i
1
xi
xi yi
2
i
B
2
1
2
i
i
i
i
xi2
i
2
i
1
2
i
2
i
i
i
i
i
xi
2
i
i
x
i2
i i
yi
i2
2
1
2
i
x
i2
2
i i i
1
2
i
xi2
xi2
0.13
A2
B2
2
i
xi2
i
2
i
i
2
i
x
i2
2
i i i
1
2
0.037
xi
AB
170.8
2
1043.3 86.6 170.8
0.0028
AB
i
xi2
i
quindi
2
i
i
2
i
x
i
i2 i i2
1
2
s0 A 2.1 0.13 m
v B 3.42 0.04 m
s
71
Nel caso in cui le misure fossero state date senza errore, si sarebbero applicate le formule semplificate:
In questo caso i valori di A e B sono dati da:
A
988 243.6 3203 76
1.31
2
8 988 76
B
8 3203 76 243.6
3.34
2
8 988 76
72
Per trovare gli errori, bisogna prima ricavare:
y2
1
yi A B xi 2 1 yi 1.31 3.34 xi 0.78
n2 i
6 i
e quindi:
A
0.78 988
2
8 988 76
0.60
B
8 0.78
2
8 988 76
0.054
AB
0.78 76
2
8 988 76
0.0028
Ne discende che
s0
v
A 1.3
0.6
m
m
B 3.34 0.05
s
I risultati sono ovviamente diversi perché in questo secondo caso
tutti i dati vengono trattati allo stesso modo, mentre con la formula
precedente ogni dato veniva pesato in base al proprio errore.
73
Avendo determinato quindi i coefficienti A e B della relazione lineare
teniamo per buoni quelli trovati nell’ultimo calcolo:
A 1.3 0.6 m
B 3.34 0.05 m s
possiamo usare questa relazione per calcolare la posizione del corpo ad un qualsiasi istante, senza
necessariamente fare la misura.
Ad esempio, in corrispondenza dell’istante
la posizione del corpo sarà data da:
t' 50 s
y' s( t' ) A B t' 1.3 3.34 50 165.69 m
L'errore sul valore così calcolato si ricava tramite la formula introdotta in precedenza:
y' 2A t' B 2 t' AB
2
0.602 502 0.052 2 50 0.028 1.95
Tenendo conto delle cifre significative, il risultato si può scrivere come:
s( t' 50 ) 165.7 2.0 m
74
Il test di chi quadrato
Abbiamo visto il procedimento da seguire per trovare i valori incogniti dei parametri che caratterizzazione
una relazione funzionale, quando sono a disposizione una serie di misure sperimentali.
Il fatto di avere delle formule o degli algoritmi che permettono di ricavare i valori incogniti dei parametri
non significa automaticamente che le misure sperimentali sono in accordo con la relazione funzionale
ipotizzata
Un metodo quantitativo e statisticamente corretto per verificare l’accordo dei dati con una
determinata relazione funzionale è il test di chi quadrato
Per trovare i valori incogniti dei parametri abbiamo infatti utilizzato il principio della massima
verosimiglianza, andando a massimizzare la probabilità congiunta di trovare i valori misurati
f y
i
i
1
i
2 n
e
i
y1 , y2 , ...... y N
yi f xi
2
2 i2
i
Trovare il massimo della probabilità equivale a minimizzare il termine all'esponente:
2
i
yi f xi 2
i2
75
che non è altro che, per ogni valore misurato, il rapporto tra
2
i
yi f xi
2
i2
la differenza tra misura e valore previsto dalla funzione
l'errore di misura
entrambi elevati al quadrato
Idealmente, il termine a numeratore dovrebbe essere 0. In realtà, ci si aspetta che la differenza tra la
misura e la previsione sia dello stesso ordine di grandezza dell'errore sperimentale, pertanto ci si aspetta
che ogni termine nella somma che definisce il 2 sia uguale a 1. Di conseguenza è ragionevole aspettarsi
che il termine all'esponente sia uguale al numero di misure effettuate.
Per generalizzare il discorso, risulta utile considerare il chi quadrato ridotto , cioè il rapporto tra 2 e il
numero di gradi di libertà:
2
2
~
ng
Ci aspettiamo quindi che il valore di chi quadrato ridotto, pari al rapporto tra il numero di misure fatte e
numero di gradi di libertà, sia poco superiore a 1.
Esistono delle tabelle che danno, la probabilità, in funzione del numero di gradi di libertà, di trovare un
valore di chi quadrato ridotto maggiore o uguale a valori prefissati. E' quindi possibile, usando questa
tabella, trovare la probabilità che in effetti le misure fatte siano regolate dalla relazione che era stata
ipotizzata.
76
Nel caso particolare della relazione
lineare, la grandezza da considerare è data da:
2
yi A B xi 2
i2
i
12
10
yi
A+Bxi
(x4,y4)
Dati
Fit Lineare (y=A+Bx)
(x3,y3)
} [yi-(A+Bxi)]
8
y
6
(x2,y2)
4
(x1,y1)
2
0
0,0
0,5
1,0
1,5
2,0
2,5
x
3,0
3,5
4,0
xi
77
12
Esempio
10
yi
A+Bxi
(x4,y4)
Dati
Fit Lineare (y=A+Bx)
(x3,y3)
} [yi-(A+Bxi)]
8
Applichiamo il test del chiquadrato al caso riportato nella figura.
y
6
I valori di A e B risultano pari a –0.5 e 2.9 rispettivamente.
(x2,y2)
4
Calcolando le differenze tra valore misurato e valore atteso
secondo la relazione lineare troviamo:
(x1,y1)
2
0
0,0
0,5
1,0
1,5
2,0
2,5
x
3,0
3,5
4,0
xi
y1 A B x1 3 0.5 2.9 1 0.6
y A B x 4 0 .5 2 . 9 2 1 . 3
2
2
y3 A B x3 9 0.5 2.9 3 0.8
y 4 A B x4 11 0.5 2.9 4 0.1
Nell'ipotesi che l'errore su ognuno dei valori misurati sia pari a 0.7:
2
2
2
2
2
2
yi A B xi
0.6 1.3 0.8 0.1
i2
0.7 2 0.7 2 0.7 2 0.7 2
i
5.52
78
Siccome i gradi di libertà sono 2 (4 misure – 2, perché i parametri A e B sono stati calcolati a partire
dalle misure stesse), il chi quadrato ridotto vale:
2
5.52
~
2
2.76
ng
2
Dalla tabella si ricava che la probabilità di avere un tale valore di chi quadrato ridotto con 2 gradi di
libertà è circa il 6.5%. Quindi questo test mi indica che i dati così misurati possono essere descritti
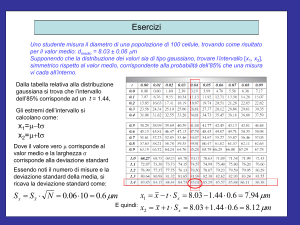
da una relazione di tipo lineare.
79
Nel caso che la relazione che vogliamo verificare sia lineare, possiamo usare un metodo
alternativo al chiquadrato per verificarne l’esistenza.
Lo stabilire se tra le variabili x e y esista una correlazione lineare è reso difficile quando i valori sono
molto dispersi e non si ha alcuna informazione sulla loro incertezza.
(Ad esempio ci si può chiedere se esiste o meno una relazione lineare tra il numero di fumatori e i casi di tumore alle vie respiratorie.
Riportando in grafico ad esempio in ascissa il numero di fumatori per un dato campione di persone, ed in ordinata il numero di decessi
imputabili ad un tumore alle vie respiratorie potremo evincere se esiste o meno una relazione di causa effetto.)
L’ipotesi secondo la quale i punti sostengono una relazione di tipo lineare tra le variabili x e y è
quantificata dal coefficiente di correlazione lineare r:
r
S xy
SxSy
x x
N
Sx
i 1
N
y
N
Sostituendo questi nella precedente otteniamo:
r
x
i
i
x
x yi y
x yi y
2
i
i
Questo indice non va confuso con il termine di correlazione
i
AB
2
i
Sy
2
S xy
i 1
i
y
2
N
1
N
x x y
N
i 1
i
i
y
che è invece un indice della correlazione tra i parametri A e B!.
80
Come si nota, questo test può essere applicato anche quando non si hanno informazioni a priori sugli
errori sperimentali.
1 r 1
Il termine r è un numero compreso tra
ed indica quanto bene i punti xi , yi si adattano ad una retta.
Più precisamente, se r 1 o un numero ad esso vicino i punti giacciono su una qualche retta
intercettante i punti dati, altrimenti se il valore di r è vicino a 0 i punti sono distribuiti più o meno
casualmente nel piano e non sono tra loro correlati.
30
30
25
25
20
20
y
15
15
y
10
10
5
5
0
0
0
0
5
10
15
20
25
5
10
15
20
25
x
x
i dati si dispongono abbastanza bene intorno alla
retta mostrando quindi un buon grado di
correlazione lineare
i dati sono maggiormente dispersi nel piano e di
conseguenza sono incorrelati o la loro correlazione
è estremamente piccola
81
Supponiamo infatti che tutti i punti (xi,yi) giacciano perfettamente sulla retta
y A Bx ,
significa affermare che
per ogni i e quindi ne consegue che
y A Bx
yi A B xi
ciò
Se sottraiamo questa ultima equazione dalla precedente:
yi y A B xi A B x B xi x
per ogni i
e la sostituiamo nella relazione che definisce il termine r otteniamo:
r
x
i
x
i
i
x yi y
x yi y
2
i
i
2
x
i
x
i
i
x B xi x
x B 2 xi x
2
i
2
B
1
B
i
Esistono delle tabelle che permettono di assegnare una probabilità al valore del coefficiente di
correlazione r, e di conseguenza stimare quanto dei valori sono più o meno correlati tra loro.
82