“Teoria e metodi della ricerca sociale e organizzativa”
Corso di Laurea in Scienze dell’Organizzazione
Facoltà di Sociologia
Università Milano-Bicocca
2009
Simone Sarti
1
Lezione
L’inchiesta campionaria e l’analisi secondaria
Corbetta, capitolo 5.
1. Cos’è l’inchiesta campionaria
2. La matrice dei dati
3. L’analisi secondaria
2
L’Inchiesta campionaria (o Survey)
La survey è un particolare metodo di raccolta dati
basato su:
- sull’interrogazione di un gruppo di individui
“rappresentativi” di una certa popolazione,
- secondo procedure standardizzate (questionario),
- con l’obiettivo di studiare le relazioni tra le variabili
rilevate sulle proprietà degli individui osservati.
3
La survey ideale
Si raccolgono informazioni su tutta la
popolazione oggetto di studio.
Lo strumento di rilevazione è realmente
oggettivo, tutti gli intervistati interpretano
esattamente cosa viene chiesto loro e
rispondono correttamente.
4
La “rappresentatività”
La “rappresentatività” è determinata dal
campionamento, ossia dalla procedura
attraverso la quale si selezionano le unità
di analisi nella popolazione su cui rilevare il
fenomeno oggetto di studio.
La selezione delle unità è detta CAMPIONE.
5
La “rappresentatività”
In fase di campionamento (o selezione dei casi)
possono commettersi tre errori:
- di copertura
- di campionamento
- di non-risposta
6
La “rappresentatività”
L’errore di copertura
Non è conosciuta la lista della popolazione su cui
effettuare la selezione!
Ad esempio, non è possibile effettuare un campione di
persone senza fissa dimora.
7
La “rappresentatività”
L’errore di non risposta
Parte consistente degli intervistati non viene raggiunta o
si rifiuta di rispondere!
Il rischio è che le non risposte potrebbero essere dovute a
errori sistematici. Ad esempio è noto che nelle indagini in
cui viene chiesto il reddito i lavoratori autonomi hanno
tassi di non risposta molto maggiori dei lavoratori
dipendenti.
I campioni telefonici sono particolarmente esposti a
questo problema.
8
La “rappresentatività”
L’errore di campionamento
E’ la misura di quanto il campione sia simile alla
popolazione.
NB: solo i campionamenti probabilistici (o casuali)
assicurano la possibilità di conoscere la misura
dell’imprecisione che commettiamo nel selezionare
le unità di analisi.
9
La “rappresentatività”
Un campionamento è casuale quando di
ogni unità di analisi è nota la
probabilità di essere estratta.
La statistica ci offre allora gli strumenti
matematici per misurare l’errore di
campionamento.
10
La “rappresentatività”
Campione casuale semplice: quando, per esempio, tutte le unità
hanno la stessa probabilità di essere intervistate l’errore di
campionamento per la media di un campione è:
s
e z
1 f
n
Dove:
- z è il coefficiente che determina l’intervallo di fiducia,
- s è la deviazione standard,
- n è l’ampiezza del campione ed N della popolazione ,
- f la frazione di campionamento, data da n/N
La stima della media della popolazione è “approssimativamente”
compresa al 95 % tra la media del campione più e meno e.
NB: L’errore dipende più dall’ampiezza del campione
che non da quella della popolazione.
11
Lo strumento di rilevazione: il questionario
Nelle survey le procedure di raccolta delle
informazioni consistono nell’utilizzare uno
strumento di rilevazione standardizzato (il
questionario):
Lo scopo è assicurare, quanto il più possibile,
l’invarianza dello stimolo, ossia lo strumento
deve essere lo stesso per tutti i soggetti
intervistati.
12
Lo strumento di rilevazione: il questionario
Un
questionario
è
caratterizzato
dalla
standardizzazione delle domande e delle
risposte, ossia da un insieme di regole che
assicurino il principio dell’invarianza dello
stimolo.
13
Il Questionario: invarianza dello stimolo
Con invarianza dello stimolo si intende che le
domande debbono essere poste nello stesso
modo ed avere lo stesso significato per tutti i
soggetti intervistati.
Le discrezionalità interpretative delle domande,
dell’intervisto come dell’intervistatore, devono
essere ridotte al minimo.
Idealmente il questionario dovrebbe misurare
l’oggettività della realtà e per questo dovrebbe
possedere
requisiti
di
neutralità
ed
universalità
rispetto
alle
interpretazioni
dell’intervistato e dell’intervistatore.
14
Il Questionario: le domande chiuse
Uno dei principali criteri di standardizzazione è
costituito dall’uso di domande chiuse, ossia
domande la cui gamma di risposte è decisa a
priori dal ricercatore.
15
Il Questionario: le domande chiuse, vantaggi
I vantaggi delle domande chiuse sono:
1) presentano a tutti gli intervistati lo stesso
quadro di riferimento,
2) costituiscono una sorta di promemoria che
aiuta l’intervistato a ricordare,
3) eliminano l’indecisione nella risposta
costringendo l’intervistato ad una scelta precisa.
16
Il Questionario: le domande chiuse, svantaggi
Gli svantaggi delle domande chiuse sono:
1) impossibilità di registrare risposte alternative
a quelle previste,
2) influenza delle opzioni sulle scelte che
possono forzare l’intervistato,
3)
maggiore
rischio
di
discrezionalità
dell’intervistato
nell’interpretazione
della
domanda e della risposta.
17
Il Questionario: formulazione delle domande - 1
LINGUAGGIO:
1.Usare un linguaggio semplice (es: evitare concetti difficili o tecnicismi)
4.Evitare espressioni in gergo
5.Evitare definizioni ambigue (es: “locali nell’abitazione?”)
6.Evitare parole connotate negativamente (es: “Lei è xenofobo?”)
7.Evitare domande sintatticamente complesse (es: doppia negazione)
8.Evitare domande con risposta non univoca (non unire due domande in una)
STRUTTURA:
2.Lunghezza delle domande
3.Numero delle alternative di risposta
21.Sequenza delle domande (seguire un criterio logico)
SENSO:
9.Evitare domande non discriminanti (es: non fare domande scontate)
10.Evitare domande tendenziose (es: aggettivazioni come “i coraggiosi soldati”)
18
Il Questionario: formulazione delle domande - 2
COMPORTAMENTI E ATTEGGIAMENTI:
11.Comportamenti presunti (usare filtri, non dare scontati certi comportamenti)
12.Focalizzazione nel tempo (es:circoscrivere i tempi di un consumo culturale)
13.Concretezza Vs. astrazione (evitare concetti troppo astratti)
14.Comportamenti e atteggiamenti (distinguere i fatti dalle opinioni)
18.Intensità degli atteggiamenti (misurare intensità diverse)
SENSIBILITA’ DELL’INTERVISTATO:
15.Desiderabilità sociale delle risposte (evitare stereotipi)
16.Domande imbarazzanti (spersonalizzare la domanda)
17.Mancanza di opinioni, non so (non forzare le risposte)
19.Acquiescenza o (uniformità nelle risposte – response set)
20.Effetto memoria (nelle interviste telefoniche)
19
20
Questionari on-line
Archivio dati per le Scienze Sociali
www.sociologiadip.unimib.it/sociodata
21
Modalità di raccolta dei dati
Le tecniche di raccolta dei dati tramite questionario si
distinguono secondo le modalità di interfaccia tra
intervistatore e intervistato e secondo il mezzo impiegato:
Assenza dell’intervistatore:
- Questionario postale
- Questionari auto-somministrati, con cartaceo
- Questionari auto-compilati, on-line
Presenza dell’intervistatore:
- Interviste faccia a faccia, con cartaceo (PAPI)*
- Interviste faccia a faccia, con computer (CAPI)**
- Interviste telefoniche (CATI)***
* Paper Assisted Personal Interviewing
** Computer Assisted Personal Interviewing
*** Computer Assisted Telephone Interviewing
La raccolta delle informazioni
L’obiettivo della survey è lo studio delle relazioni tra
le variabili:
il questionario registra gli STATI delle proprietà che
caratterizzano le unità di analisi (gli individui),
con il fine di mettere in relazione le proprietà tra
loro, secondo quelle che sono le ipotesi di ricerca.
23
La raccolta delle informazioni
Alcune proprietà possono essere ad esempio:
-
l’anno di nascita
il genere
il grado del titolo di studio
la condizione occupazionale
24
La raccolta delle informazioni
Gli stati su cui sono registrate le proprietà
rappresentano i possibili modi con cui le proprietà si
manifestano:
- l’anno di nascita (1980, …, 1990)
- il genere (maschio/femmina)
- il titolo di studio (lic.elementare, …, laurea)
- la condizione occupazionale (disoccupato, occupato,
ritirato, …, altro)
25
La raccolta delle informazioni
Gli stati delle proprietà sono registrati in VARIABILI e
prendono il nome di VALORI, MODALITA’ o CATEGORIE
della variabile.
L’anno di nascita avrà un range di valori (var. metrica)
Il genere avrà due modalità (variabile dicotomica)
Il titolo di studio avrà k modalità ordinate (var.ordinale)
La condizione occupazionale avrà k modalità non ordinabili
(variabile categoriale)
NB: anche alle modalità possono essere assegnati dei valori!
26
La matrice dei dati
La survey raccoglie informazioni in una MATRICE DATI
organizzata nella forma CASI X VARIABILI,
dove a ogni riga corrisponde un caso (o UNITA’ di ANALISI),
e ad ogni colonna una variabile.
Le informazioni così organizzate permettono l’analisi dei dati
attraverso l’uso di software statistici.
27
La matrice dei dati – Il data set
La matrice dati in forma software è chiamata
BASE DATI (DATA SET), ed è registrata come
un qualsiasi file dati.
Ad ogni individuo corrisponde un RECORD
(l’insieme delle celle di una riga) che raccoglie
tutte le informazioni che lo riguardano.
28
UN DATA SET (17 individui X 6 variabili)
Età, Sesso, Stato civile, Stato civile precedente, Anno matrimonio, Titolo di studio
29
UN DATA SET (17 individui X 6 variabili)
Sul data set vengono realizzate analisi che:
-sintetizzano le informazioni
ES: Nel campione considerato sono presenti 10 donne e 7 uomini; 3
laureati e 14 non laureati.
- e che permettono di testare delle ipotesi sulle
relazioni tra le variabili
ES: Nel campione considerato gli uomini sono più laureati delle
donne (3/10 rispetto a 0/14).
30
Tipi di Survey
Esistono diversi tipi di survey:
- Cross-sectional o trasversali: ripetute nel tempo su
campioni diversi (es: Eurobarometer)
- Survey trasversale retrospettiva (es:ILFI 1a wave)
- Panel o longitudinali: ripetute nel tempo sugli stessi
individui (ISTAT – Forze Lavoro)
- Panel dinamico (ILFI), il campione può integrare nuovi
casi secondo alcune regole di inclusione
31
L’analisi secondaria
32
Caratteristiche dell’analisi secondaria
L’analisi secondaria utilizza dati già raccolti al
di fuori degli scopi per cui questi dati erano
stati prodotti inizialmente.
I dati “archiviati” acquisiscono per questo un valore
potenziale a prescindere dagli esiti dello studio in cui
furono originati.
L’analisi secondaria RICICLA dunque in modo creativo ed
economico informazioni raccolte nel passato recente o
lontano.
33
L’analisi secondaria
L’analisi secondaria di dati survey
Vantaggi e svantaggi dell’analisi secondaria
Le fonti dati
34
L’Analisi Secondaria di dati survey
“Una ricerca che viene condotta su
dati di inchiesta campionaria già
precedentemente raccolti e disponibili
nella forma della matrice-dati originale”
Corbetta, pag.225
35
Caratteristiche dell’analisi secondaria
Nell’analisi secondaria la raccolta dei dati non è
responsabilità diretta del ricercatore.
Nell’analisi primaria, infatti, il ricercatore è responsabile
del disegno della ricerca, della raccolta dati, delle analisi
e della presentazione dei risultati.
Nell’analisi secondaria egli si occupa solo delle ultime
due fasi.
36
Caratteristiche dell’analisi secondaria
L’analisi secondaria e l’analisi primaria possono
essere utilizzate in modo complementare.
L’analisi secondaria può essere utile nello studio
diacronico di un certo fenomeno sociale. Per il passato
vengono utilizzati dati già esistenti, sulla loro base, per il
presente, vengono raccolti nuovi dati ad hoc.
37
Vantaggi dell’analisi secondaria
1- Superamento dei problemi posti dai costi
economici e di tempo.
38
Vantaggi dell’analisi secondaria
2- Sedimentazione storica dei dati che mette a
disposizione un insieme di risorse informative
sempre più ricco.*
Inoltre una parte di queste risorse ha due qualità
particolari: la rappresentatività dei campioni a livello
nazionale e la standardizzazione dei metodi di
rilevazione. Queste qualità permettono studi comparativi
tra diverse nazioni.
39
Vantaggi dell’analisi secondaria
* A favore della sedimentazione dei dati ha giocato un
ruolo fondamentale lo sviluppo tecnologico, soprattutto
nel campo informatico.
Esso ha infatti agevolato sia la manipolabilità delle
matrici dati sottoforma di files, sia la diffusione e
l’accessibilità a software applicativi dedicati all’analisi
statistica.
40
Vantaggi dell’analisi secondaria
3- Opportunità di comparare dati prodotti nel
passato con dati prodotti in tempi successivi.
Possibilità di effettuare analisi di trend su determinati
fenomeni.
41
Svantaggi dell’analisi secondaria
1- I dati già raccolti sono semplicemente
“vecchi”.
Il loro utilizzo va contestualizzato al momento della
rilevazione. Talvolta, in mancanza di dati aggiornati, si
impiegano per studiare fenomeni che si vorrebbero
attuali, ma la cui osservazione appartiene al passato.
42
Svantaggi dell’analisi secondaria
2- Quasi sempre i dati archiviati sono stati
raccolti con finalità diverse da quelle per cui
vengono riutilizzati nell’analisi secondaria.
I ricercatori originari, perseguendo obiettivi diversi,
potrebbero aver impiegato termini, definizioni,
classificazioni e misurazioni delle variabili adeguati ai
loro scopi, ma non adeguati al contesto in cui vengono
riutilizzati.
43
Svantaggi dell’analisi secondaria
3- Quando si utilizzano dei dati archiviati
occorre verificare e valutare la loro QUALITÀ.
I dati non sono sempre “pronti all’uso” ed in certi casi
possono non essere utilizzabili.
44
La qualità dei dati
Reperebilità e Leggibilità dei files
I files dei dati per l’analisi secondaria:
- devono essere recuperati dalla fonte;
- devono essere in un formato “leggibile”;
- se non sono leggibili devono essere forniti della
documentazione tecnica necessaria (es: tracciato record).
45
La qualità dei dati
Documentazione metodologica
Devono essere sempre noti fonte e disegno della ricerca, ed
in particolare le note metodologiche su:
- date e tempi della rilevazione,
- campionamento,
- tecniche di intervista (CATI, CAPI, ecc.),
- questionario (domande e risposte),
- codebook (codifica della matrice dati),
- missing (distinzione tra NA, DK e mancanti).
46
La qualità dei dati
Integrità dei dati
Occorre verificare l’integrità dei dati in termini di
corrispondenza della matrice-dati originale. A causa di
possibili errori durante il trattamento dei dati le informazioni
potrebbero infatti non corrispondere.
47
Le fonti dati
L’analisi secondaria richiede dunque
disponibilità di dati con un elevato livello di
qualità.
Il ricercatore che vuole fare analisi secondaria si
rivolge così alle fonti di dati.
48
Le fonti dati: una classificazione
Fonti statistiche
pubbliche (ufficiali)
nazionali
Fonti autonome
Fonti internazionali
Archivi dati per le
scienze sociali
Servizi statistici statali nazionali (Istat, IRER,
ecc.) ed enti pubblici preposti alla raccolta di
dati (anagrafi comunali, uffici ministeriali,
ecc.)
Società private (istituti di ricerca, banche,
associazioni, ecc.) ed istituzioni accademiche
o enti pubblici non preposti alla raccolta dei
dati
Servizi statistici sovranazionali (Eurostat, ecc.)
e organizzazioni internazionali (ONU,OCSE,
Fmi, ecc.)
Archivi dati nazionali per le scienze sociali e
network internazionali (ICPSR, UK Data
Archive, ADPSS-Sociodata, ecc.)
49
Le fonti statistiche pubbliche (ufficiali) nazionali
Queste fonti iniziano a svilupparsi tra il ‘700 e l’800, quando
gli stati nazionali necessitano, per motivi di amministrazione
pubblica, di informazioni sulla popolazione raccolte in modo
sistematico.
Un esempio di dati prodotti da queste fonte sono i
Censimenti della Popolazione. Il primo in Italia è quello del
1861.
50
Le fonti autonome
Le fonti autonome costituiscono un insieme eterogeneo di
istituzioni private e pubbliche che non sono preposte in via
naturale all’archiviazione dei dati, ma per esigenze diverse
vengono a costituirsi come vere e proprie fonti di dati.
Un esempio importante è costituito dagli Istituti di Ricerca, i
quali, tra l’altro sono i primi storicamente ad iniziare la
raccolta dei dati attraverso lo strumento dell’indagine
campionaria (negli USA negli anni ’40 per studiare le
preferenze di voto).
51
Le fonti internazionali
Le fonti internazionali producono dati per conto di organismi
sovra-nazionali, e rivestono un ruolo particolarmente
importante nella costruzione di dati comparabili tra diversi
paesi.
Ad esempio una delle funzioni principali dell’Eurostat è lo
sviluppo di un linguaggio statistico condiviso e
standardizzato.
Un esempio di dati di fonte internazionale è la PISA
(Programme for International Student Assessment)
dell’OCSE (Organizzazione per la Cooperazione e lo Sviluppo
Economico).
52
Gli archivi dati (SSDA, Social Science Data Archives)
Gli archivi dati non producono direttamente dati come le
precedenti fonti, tuttavia possono essere paragonati ad esse
per due motivi:
- Spesso divengono distributori esclusivi di importanti survey,
divenendo, pur indirettamente, gli unici depositari e quindi la
fonte a cui richiederne i dati.
- Gli SSDA svolgono in modo continuativo un’attività di
integrazione dei nuovi data sets acquisiti e di aggiornamento
delle vecchie indagini allo scopo di migliorarne la qualità e
quindi l’utilizzabilità per l’analisi secondaria.
53
Gli archivi dati (SSDA, Social Science Data Archives)
La finalità degli archivi dati è quella di rintracciare
ed ordinare l’esistente, svolgendo in pratica una
funzione di data collector, cioè di “collezionisti di
dati”.
Tra i principali archivi dati per le scienze sociali a livello
internazionale vi sono l’ICPSR del Michigan, lo ZA di Colonia,
lo UK data-Archive di Essex.
A livello italiano l’archivio dati più longevo è ADPSSSociodata presso il Dipartimento di Sociologia di MilanoBicocca.
54
Gli Eurobarometer
ESEMPIO DI SURVEY
55
Gli Eurobarometer
Gli Eurobarometer costituiscono uno degli strumenti più
utilizzati per l’analisi secondaria di tipo comparativo tra i
paesi dell’Unione Europea.
Condotti a partire dal 1973 considerano campioni
“rappresentativi” delle popolazioni dei paesi appartenenti
all’UE.
Gli EB sono condotti su incarico della Commissione
Europea, Direzione Generale X, Unità di Ricerche
sull’Opinione Pubblica.
56
Finalità e temi degli Eurobarometer
La finalità generale degli EB è quella di conoscere gli
atteggiamenti e le valutazioni dei cittadini europei su
alcuni temi di ampio interesse generale.
Il tema più affrontato è quello del processo di unificazione
europea, ma vengono affrontati temi (anche più d uno alla
volta) anche molto differenti tra loro come:
- le elezioni europee,
- la condizione e i valori dei giovani,
- gli atteggiamenti verso gli immigrati,
- la diffusione delle nuove tecnologie,
- eccetera.
57
Campionamento e pesi di riporto
Gli EB, iniziati a partire dal 1973, si rivolgono ad
un campione “rappresentativo” della popolazione
con almeno 15 anni di tutti i paesi europei.
A parte lievi differenze tecniche i soggetti
intervistati vengono selezionati in base ad un
campionamento casuale multi-stage (multistadio) simile in tutti i paesi considerati.
58
Campionamento multi-stadio
Al primo stadio vengono selezionate casualmente le PSU
(primary sampling units), punti di campionamento primari,
costituiti dalle unità amministrative locali, proporzionali a
livello nazionale rispetto a: popolazione nazionale, regione
d’appartenenza, dimensione demografica, densità di
popolazione e tipo d’area (metropolitana, urbana o rurale).
Al secondo stadio da ogni PSU vengono estratti una serie
di indirizzi. Infine all’interno delle famiglie viene
selezionato casualmente un solo individuo, secondo la
tecnica dell’“ultimo compleanno” che sarà intervistato
personalmente (intervista “faccia a faccia”).
59
Campionamento: numerosità
La procedura di campionamento è ripetuta exnovo per ogni indagine realizzata.
I campioni nazionali vengono monitorati
simultaneamente due volte l’anno (primavera ed
autunno) intervistando direttamente nel proprio
domicilio circa 1000 persone per paese (i paesi
più piccoli sono sottocampionati).
60
61
Campionamento: pesi campionari
Gli EB vengono distribuiti provvisti di pesi
campionari necessari a correggere le distorsioni
del campione ed a garantire la distribuzione
proporzionale della numerosità del campione
rispetto alle popolazioni europee.
I pesi campionari rappresentano una correzione
a posteriori del campione.
62
Campionamento: pesi campionari
WSAMPLE: è il peso base compreso in tutti gli altri pesi
fattoriali utilizzati. Aggiusta la distribuzione sociodemografica del
campione a quella dell’universo. Le variabili considerate sono:
età, sesso, grandezza del nucleo familiare, regione di
appartenenza, ampiezza demografica del comune (o della
relativa area amministrativa).
WNATION: è identico al peso base, a meno della ponderazione
di alcuni paesi: Germania e Regno Unito. Il campione viene
aggiustato proporzionalmente alle popolazioni di ex-Repubblica
Federale Tedesca ed ex-Repubblica Democratica Tedesca, e di
Gran Bretagna e Nord Irlanda.
WEURO: riporta tutti i campioni nazionali alle proporzioni reali
della popolazione dell’Unione Europea. Ogni gruppo nazionale
pesa proporzionalmente alla numerosità della sua popolazione.
Es: i casi del Lussemburgo vengono quasi completamente
annullati.
63
Frequenza casi osservati
COUNTRY COUNTRIES / PAYS
Validi
Frequenza
1 BELGIQUE
1063
2 DANMARK
1000
3 DEUTSCHLAND WEST
1015
4 ELLAS
1004
5 ITALIA
1000
6 ESPANA
1000
7 FRANCE
1002
8 IRELAND
1000
9 NORTHERN IRELAND
300
10 LUXEMBOURG
600
11 NEDERLAND
975
12 PORTUGAL
1000
13 GREAT BRITAIN
1070
14 DEUTSCHLAND OST
1034
16 SUOMEN
1010
17 SVERIGE
1000
18 OESTERREICH
1005
Totale
16078
Percentuale
6,6
6,2
6,3
6,2
6,2
6,2
6,2
6,2
1,9
3,7
6,1
6,2
6,7
6,4
6,3
6,2
6,3
100,0
Percentuale
valida
6,6
6,2
6,3
6,2
6,2
6,2
6,2
6,2
1,9
3,7
6,1
6,2
6,7
6,4
6,3
6,2
6,3
100,0
Percentuale
cumulata
6,6
12,8
19,1
25,4
31,6
37,8
44,1
50,3
52,1
55,9
61,9
68,2
74,8
81,2
87,5
93,7
100,0
D10 D.10. - Sex D.10. - Sexe du r0pondant
Validi
1 Male
2 Female
Totale
Frequenza
7654
8424
16078
Percentuale
47,6
52,4
100,0
Percentuale
valida
47,6
52,4
100,0
Percentuale
cumulata
47,6
100,0
64
Frequenza casi pesati con WSAMPLE
COUNTRY COUNTRIES / PAYS
Validi
Frequenza
1 BELGIQUE
1063
2 DANMARK
1000
3 DEUTSCHLAND WEST
1015
4 ELLAS
1004
5 ITALIA
1000
6 ESPANA
1000
7 FRANCE
1002
8 IRELAND
1000
9 NORTHERN IRELAND
300
10 LUXEMBOURG
600
11 NEDERLAND
975
12 PORTUGAL
1000
13 GREAT BRITAIN
1070
14 DEUTSCHLAND OST
1034
16 SUOMEN
1010
17 SVERIGE
1000
18 OESTERREICH
1005
Totale
16078
Percentuale
6,6
6,2
6,3
6,2
6,2
6,2
6,2
6,2
1,9
3,7
6,1
6,2
6,7
6,4
6,3
6,2
6,3
100,0
Percentuale
valida
6,6
6,2
6,3
6,2
6,2
6,2
6,2
6,2
1,9
3,7
6,1
6,2
6,7
6,4
6,3
6,2
6,3
100,0
Percentuale
cumulata
6,6
12,8
19,1
25,4
31,6
37,8
44,1
50,3
52,1
55,9
61,9
68,2
74,8
81,2
87,5
93,7
100,0
D10 D.10. - Sex D.10. - Sexe du r0pondant
Validi
1 Male
2 Female
Totale
Frequenza
7772
8306
16078
Percentuale
48,3
51,7
100,0
Percentuale
valida
48,3
51,7
100,0
Percentuale
cumulata
48,3
100,0
65
Frequenza casi pesati con WNATION
COUNTRY COUNTRIES / PAYS
Validi
Frequenza
1 BELGIQUE
1000
2 DANMARK
1000
3 DEUTSCHLAND WEST
1583
4 ELLAS
1000
5 ITALIA
1000
6 ESPANA
1000
7 FRANCE
1000
8 IRELAND
1000
9 NORTHERN IRELAND
32
10 LUXEMBOURG
600
11 NEDERLAND
1000
12 PORTUGAL
1000
13 GREAT BRITAIN
1268
14 DEUTSCHLAND OST
417
16 SUOMEN
1000
17 SVERIGE
1000
18 OESTERREICH
1000
Totale
15900
Percentuale
6,3
6,3
10,0
6,3
6,3
6,3
6,3
6,3
,2
3,8
6,3
6,3
8,0
2,6
6,3
6,3
6,3
100,0
Percentuale
valida
6,3
6,3
10,0
6,3
6,3
6,3
6,3
6,3
,2
3,8
6,3
6,3
8,0
2,6
6,3
6,3
6,3
100,0
Percentuale
cumulata
6,3
12,6
22,5
28,8
35,1
41,4
47,7
54,0
54,2
58,0
64,3
70,5
78,5
81,1
87,4
93,7
100,0
66
Frequenza casi pesati con WEURO
COUNTRY COUNTRIES / PAYS
Validi
Frequenza
1 BELGIQUE
429
2 DANMARK
223
3 DEUTSCHLAND WEST
2871
4 ELLAS
453
5 ITALIA
2523
6 ESPANA
1700
7 FRANCE
2416
8 IRELAND
153
9 NORTHERN IRELAND
66
10 LUXEMBOURG
19
11 NEDERLAND
654
12 PORTUGAL
423
13 GREAT BRITAIN
2372
14 DEUTSCHLAND OST
671
16 SUOMEN
214
17 SVERIGE
370
18 OESTERREICH
343
Totale
15900
Percentuale
2,7
1,4
18,1
2,8
15,9
10,7
15,2
1,0
,4
,1
4,1
2,7
14,9
4,2
1,3
2,3
2,2
100,0
Percentuale
valida
2,7
1,4
18,1
2,8
15,9
10,7
15,2
1,0
,4
,1
4,1
2,7
14,9
4,2
1,3
2,3
2,2
100,0
Percentuale
cumulata
2,7
4,1
22,2
25,0
40,9
51,6
66,8
67,7
68,1
68,3
72,4
75,0
89,9
94,2
95,5
97,8
100,0
67
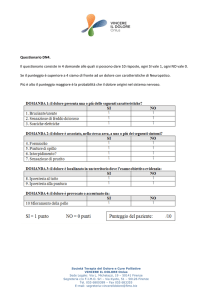
Il Questionario
Gli EB utilizzano come strumento di rilevazione
un questionario, quasi sempre di tipo strutturato.
Un questionario strutturato è caratterizzato dalla
standardizzazione delle domande e delle
risposte, ossia da un insieme di regole che
assicurino il principio dell’invarianza dello
stimolo.
68
Il Questionario negli EB
I questionari negli Eurobarometer sono di tipo
strutturato e vengono tradotti nelle lingue dei
paesi dell’UE.
In ogni paese esistono Istituti di Ricerca,
coordinati dall’INRA, incaricati di tradurli e di
portare a compimento la raccolta dei dati.
Per l’Italia se ne occupa InraDemoskopea.
69
Il Questionario negli EB: struttura
I questionari degli EB hanno mantenuto nel corso degli
anni una struttura simile.
Generalmente vengono prima le domande relative alla
partecipazione politica ed al processo di unificazione
europea, successivamente le domande che riguardano gli
argomenti topici di ogni EB. Infine le domande che
rilevano le caratteristiche socio-demografiche degli
intervistati (sesso, età , occupazione, ecc.).
70
71
Il Questionario negli EB: struttura
Dopo la lettura della domanda l’intervistatore
registra la risposta, e secondo le indicazioni
previste procede nell’intervista. A volte sono
presenti dei filtri nel questionario.
Le risposte date dall’intervistato vengono
registrate successivamente nella matrice-dati
che raccoglie le interviste provenienti da tutti i
paesi UE.
72
La matrice dati
Gli EB sono distribuiti in formati manipolabili con SPSS,
completi di etichette e codici.
Ogni riga corrisponde ad un soggetto intervistato, ogni
colonna una variabile che registra la proprietà di un
concetto.
73
74
75
La matrice dati: frequenza di una variabile
76
Trend
Negli EB, fin dalla loro nascita, è stata presente
l’intenzione di creare uno strumento di rilevazione
diacronico, ossia raffrontabile nel tempo. Uno strumento
capace di “monitorare” nel tempo i cambiamenti
nell’opinione pubblica europea.
In questo senso gli EB non sono solo fotografie istantanee
della realtà sociale, ma una sorta di filmato delle
dinamiche di cambiamento.
A questo scopo negli EB sono previste alcune domande
particolari che vengono ripetute nel tempo (anche se
spesso in modo saltuario).
L’insieme di queste domande è stato utilizzato per formare
l ‘EUROBAROMETRO CUMULATIVO
77
Trend: un esempio
78
Trend: embargo provisions
Negli EB, fin dalla loro nascita, un problema esistente nella
costruzione di trend aggiornati è la presenza di embargo
provisions.
In pratica alcuni temi di particolare interesse (come le
intenzioni di voto) vengono temporaneamente omessi al
momento dell’uscita dell’EB.
Il data set completo viene rilasciato solo dopo alcuni mesi
di ritardo, successivamente alla pubblicazione da parte
della Commissione Europea di un rapporto esclusivo su
quei temi.
79
Problemi tecnici nella preparazione di un data set per
un’analisi di trend
Variazione nella formulazione delle domande
Variazione delle modalità di risposta
Problemi di collocazione dei missing
Variazioni dei campioni (Germania Ovest-Est)
80
Variazioni nella formulazione delle domande
Domanda sulle aspettative per il futuro:
EB 53.0 e seguenti:
“Nel corso dei prossimi cinque anni, si aspetta
che la sua situazione personale migliorerà,
rimarrà la stessa o peggiorerà?”
Fino all’EB 52.1:
“Per quanto la riguarda, lei pensa che il 1985
sarà migliore, peggiore o simile al 1984?”
81
Variazioni nei codici delle modalità di risposta
Domanda sulla condizione occupazionale, opzioni di risposta:
82
Variazioni nei codici delle risposte
Codici della variabile Nazione in EB 35.0 ed in EB 54.0
83
Collocazione dei missing
A volte può succedere che la codifica dei valori
missing
DK-Don’t Know
NA-Not applicable
crei dei problemi di armonizzazione, infatti per alcuni EB i
valori DK e NA possono essere codificati insieme, mentre
in EB successivi non lo sono.
84
Variazioni dei campioni
Rispetto alle medie europee come considerare il caso della Norvegia?
Rispetto alla Germania come considerare l’unificazione tedesca ?
La regola generale è di tenere le classi delle variabili utilizzate
il più omogenee possibili.
85
86