Riferimento bibliografici:
• Levine, Krehbiel, Berenson (2006): Statistica, II ed., Apogeo.
• Piccolo D., (2000): Statistica, il Mulino, Bologna.
Lezione 4
Modelli di variabili
casuali
Insegnamento: Statistica
Corso di Laurea Magistrale in Matematica
Facoltà di Scienze, Università di Ferrara
E-mail: [email protected]
Argomenti
Modelli Continui:
La variabile casuale uniforme continua, la variabile
casuale Normale, la variabile casuale Chi – quadrato,
la variabile casuale di Student
Modelli discreti:
La variabile Binomiale, la variabile di Poisson
Introduzione
Anche se gli schemi probabilistici sono in numero illimitato è
opportuna una loro classificazione ricercando elementi di
omogeneità tra le diverse prove mediante la formalizzazione di
modelli standard.
In pratica una famiglia parametrica di v.c. è una collezione di
v.c. caratterizzate dalla stessa forma funzionale della funzione
di ripartizione; e quindi della stessa distribuzione di probabilità
(se discrete) o della stessa densità (se continue).
I membri della famiglia parametrica di v.c. si distinguono
esclusivamente per lo specifico valore numerico del
parametro.
Alcuni tipici fenomeni continui sono l’altezza, il peso, le
variazioni giornaliere nei prezzi di chiusura di un’azione, il
tempo che intercorre fra gli arrivi di aerei presso un aeroporto,
il tempo necessario per servire un cliente in un negozio
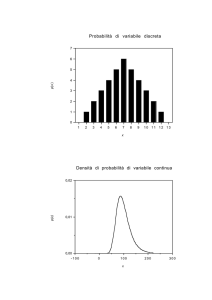
La figura rappresenta graficamente tre funzioni di densità di
probabilità: normale, uniforme ed esponenziale
Modelli continui: La variabile casuale uniforme continua
Il modello probabilistico che genera la v.c. uniforme continua
è utilizzato per la semplicità della sua forma funzionale ma in
pratica esso si riscontra quasi esclusivamente in situazioni
artificiali come ad es. giochi, esperimenti geometrici etc.
Definizione:
Modelli continui: La variabile casuale uniforme continua
Modelli continui: La variabile casuale uniforme continua
La formulazione standard per tale v.c. è la v.c. Uniforme
standardizzata, cioè la v.c. Uniforme continua definita sul supporto
(0,1).
Si osserva che:
• La trasformazione lineare di una v.c. genera un’altra v.c. uniforme.
• La combinazione lineare di v.c. uniformi indipendenti generano una
v.c. la cui funzione di densità è molto diversa.
Modelli continui: La variabile casuale uniforme continua
La variabile casuale normale
La distribuzione normale (o distribuzione Gaussiana in onore
del matematico Carl Friedrich Gauss (1777-1855)) è la
distribuzione continua più utilizzata in statistica.
La distribuzione normale è importante in statistica per tre
motivi fondamentali:
1. Diversi fenomeni continui sembrano seguire, almeno
approssimativamente, una distribuzione normale.
2. La distribuzione normale può essere utilizzata per
approssimare numerose distribuzioni di probabilità discrete.
3. La distribuzione normale è alla base dell’inferenza statistica
classica in virtù del teorema del limite centrale.
Tale distribuzione è anche nota come legge degli errori in quanto
descrive la distribuzione degli errori casuali relativi a successive
misurazioni di una quantità fisica.
La variabile casuale normale
La distribuzione
caratteristiche:
normale
ha
alcune
importanti
La distribuzione normale ha una forma campanulare e
simmetrica
Le sue misure di posizione centrale (valore atteso, mediana)
coincidono
Il suo range interquartile è pari a 1.33 volte lo scarto
quadratico medio, cioè copre un intervallo compreso tra –
2/3σ e + 2/3σ
La variabile aleatoria con distribuzione normale assume valori
compresi tra - e +
La variabile casuale normale
Molte variabili statistiche che osserviamo nella realtà hanno una
distribuzione con caratteristiche simili a quelle della distribuzione
normale.
Consideriamo ad esempio lo spessore misurato in centimetri di 10
000 rondelle di ottone prodotte da una grande società metallurgica.
Il fenomeno aleatorio continuo di interesse, lo spessore delle
rondelle, si distribuisce approssimativamente come una normale.
La variabile casuale normale
Definizione
Dallo studio analitico della densità normale si osserva che:
• La funzione è sempre non negativa ed il suo integrale sull’asse
reale vale 1.
• E’ simmetrica rispetto al punto di ascissa x=µ, in corrispondenza
del quale si ha un massimo.
•
La variabile casuale normale
Notiamo che, essendo e e delle costanti, le probabilità di una
distribuzione normale dipendono soltanto dai valori assunti dai
due parametri µ e σ.
Specificando particolari combinazioni di µ e σ, otteniamo
differenti distribuzioni di probabilità normali.
La variabile casuale normale
Poiché esiste un numero infinito di combinazioni dei parametri µ
e σ, per poter rispondere a quesiti relativi a una qualsiasi
distribuzione normale avremmo bisogno di in numero infinito di
tavole.
Introduciamo ora una formula di trasformazione delle
osservazioni, chiamata standardizzazione, che consente appunto
di trasformare una generica variabile aleatoria normale in una
variabile aleatoria normale standardizzata.
La standardizzazione
Z
X
Z è la variabile ottenuta sottraendo ad X il suo valore atteso µ e
rapportando il risultato allo scarto quadratico medio, σ.
La variabile casuale normale standardizzata
La variabile casuale normale standardizzata
Quindi è sempre possibile trasformare qualsiasi insieme di valori
distribuiti normalmente nel corrispondente insieme di valori
standardizzati e ricavare le probabilità desiderate dalle tavole
della distribuzione normale standardizzata. Infatti:
Supponiamo che il tempo necessario per caricare la home page del
sitoOnCampus! sia distribuito normalmente con µ=7 secondi e scarto
quadratico medio pari σ=2 secondi.
La variabile casuale normale standardizzata
Nella figura si osserva come a ciascun valore della variabile X
(tempo di caricamento) è associato il corrispondente valore della
variabile
standardizzata
Z,
ottenuto
applicando
la
standardizzazione.
Supponiamo di voler determinare la probabilità che il tempo di
caricamento della home page in una generica sessione sia
inferiore ai 9 secondi.
La variabile casuale normale standardizzata
X
Applicando l’equazione Z
si ottiene che a X=9 corrisponde
il valore della variabile standardizzata Z=(9-7)/2=+1.
Dopodiché si utilizza la Tavola della funzione di ripartizione della
v.c. normale standardizzata per determinare l’area cumulata fino
al valore 1.
Esempio 1 Tempo di caricamento della home page del sito
OnCampus!: calcolo di P(X<7 o X>9)
Esempio 2 Tempo di caricamento della home page del sito
OnCampus!: calcolo di P(5<X<9)
La distribuzione normale
Esempio 3 Tempo di caricamento della home page del sito
OnCampus!: calcolo di P(X>9)
Esempio 4 Tempo di caricamento della home page del sito
OnCampus!: calcolo di P(5<X<9)
La variabile casuale normale
Il risultato dell’esempio 4 può essere generalizzato, infatti per un
insieme di dati con distribuzione normale:
approssimativamente il 68.26% apparterrà all’intervallo (µ
– σ, µ + σ)
approssimativamente il 95.44% apparterrà all’intervallo (µ
– 2 σ, µ + 2 σ)
approssimativamente il 99.73% apparterrà all’intervallo (µ
– 3 σ, µ + 3 σ)
È quindi evidente il motivo per cui un intervallo di ampiezza 6 σ
centrato su µ, vale a dire l’intervallo (µ – 3 σ, µ + 3 σ), può
essere considerato come un’approssimazione pratica del range
per dati distribuiti normalmente.
Negli esempi 1 - 4 la tavola della distribuzione normale
standardizzata viene utilizzata per calcolare l’area fino ad un
certo valore X. In molte applicazioni si è però interessati al
procedimento opposto, cioè determinare il valore di X cui
corrisponde una certa area cumulata.
Esempio 6. Tempo di caricamento della home page del sito
OnCampus!: calcolo del tempo massimo di caricamento per
almeno il 10% delle sessioni
Esempio 6 Tempo di caricamento della home page del sito
OnCampus!: calcolo del tempo massimo di caricamento di
almeno il 10% delle sessioni
Determinare il valore X associato a una probabilità (cumulata)
X Z
(6.4)
il valore X è dato dalla media µ, cui va sommato il prodotto tra Z
e lo scarto quadratico medio, σ.
X = 7 + (-1.28)(2) = 4.44 secondi
Esempio 7 Tempo di caricamento della home page del sito
OnCampus!: determinazione dell’intervallo centrato sulla media
in cui appartiene il 95% dei tempi di caricamento
Esempio 7 Tempo di caricamento della home page del sito
OnCampus!: determinazione dell’intervallo centrato sulla media
in cui appartiene il 95% dei tempi di caricamento
X = 7 + (-1.96)(2) = 3.08 secondi
X = 7 + (+1.96)(2) = 10.92 secondi
Valutazione dell’ipotesi di normalità
Non tutti i fenomeni continui sono distribuiti normalmente e non
tutti seguono una distribuzione che può essere approssimata
adeguatamente con una normale. È quindi importante verificare la
plausibilità dell’ipotesi di normalità, cioè di accertare se in effetti
un insieme di dati può provenire da una distribuzione normale.
Dal punto di vista pratico il problema è di valutare la bontà di
adattamento del modello normale a un insieme di dati, problema
che deve essere affrontato ancora prima di applicare le
metodologie descritte nel precedente paragrafo.
Due sono gli approcci esplorativi di carattere descrittivo che
possono essere adottati:
1. Il confronto fra le caratteristiche dei dati e le proprietà di
un’eventuale distribuzione normale sottostante
2. La costruzione di un normal probability plot
Valutazione dell’ipotesi di normalità
La distribuzione normale ha alcune importanti proprietà teoriche:
è simmetrica: la media e la mediana coincidono
ha forma campanulate, di modo che può essere applicata la
regola empirica
il suo range interquartile è pari a 1.33 volte lo scarto
quadratico medio
il range è infinito
Per un dato insieme di dati, per valutare l’adeguatezza dell’ipotesi
di normalità si può procedere con
la costruzione di grafici per analizzare la forma della
distribuzione
il calcolo delle misure di sintesi e il confronto con le
proprietà teoriche
il confronto fra le caratteristiche dei dati e le proprietà di
un’eventuale distribuzione normale sottostante
Valutazione dell’ipotesi di normalità
Un normal probability plot è un grafico a due dimensioni in cui
le osservazioni sono riportate sull’asse verticale e a ciascuna di
esse viene fatto corrispondere sull’asse orizzontale il relativo
quantile di una distribuzione normale standardizzata.
Se i punti del grafico si trovano approssimativamente su una linea
retta immaginaria inclinata positivamente, allora possiamo
affermare
che
i
dati
osservati
si
distribuiscono
approssimativamente secondo la legge normale.
Valutazione dell’ipotesi di normalità
Esempio: Normal Probability Plot per il rendimento 2003 dei fondi
comuni di investimento ottenuto con Microsoft Excel
Proprietà riproduttiva della v.c. normale
La variabile casuale Chi - Quadrato
La funzione di densità di una v .c.
chi – quadrato per alcuni gradi di
libertà k = g
La funzione di ripartizione di una v
.c. chi – quadrato per alcuni gradi di
libertà k = g
La variabile casuale t di Student
• La forma della distribuzione t di Student è simile alla normale, entrambe sono a
campana e simmetriche attorno alla media.
•Come la normale ha media in µ=0 e la sua varianza dipende dal grado di libertà
(g.d.l.) g; la varianza è maggiore di 1 e tende a 1 al crescere di g.
•Si può dimostrare che la distribuzione t con g.d.l. g tende alla distribuzione normale
standardizzata al crescere di g.
• Sono disponibili delle tavole, in cui sono tabulati alcuni valori scelti di tα per vari
valori di g dove tα è tale che l’area alla destra di tα è uguale ad α .
La funzione di densità di una v .c. t
di Student per alcuni gradi di libertà
(df)
La funzione di ripartizione di una v
.c. t di Student per alcuni gradi di
libertà (df)
Modelli discreti: la distribuzione binomiale
Uno dei modelli probabilistici più utilizzati è la distribuzione
binomiale che caratterizzata da quattro essenziali proprietà:
• Si considera un numero prefissato di n osservazioni
• Ciascuna osservazione può essere classificata in due categorie
incompatibili ed esaustive, chiamate per convenzione successo e
insuccesso
• La probabilità di ottenere un successo, p, è costante per ogni
osservazione, così come la probabilità che si verifichi un
insuccesso, (1 – p).
• Il risultato di un’osservazione, successo o insuccesso, è
indipendente dal risultato di qualsiasi altra. …
La distribuzione binomiale
Per assicurare l’indipendenza, le osservazioni possono
essere ottenute con due diversi metodi di campionamento:
un campionamento da una popolazione infinita senza
reimmissione oppure un campionamento da una
popolazione finita con reimmissione
La variabile casuale X che conta il numero di successi in
una sequenza di n sottoprove indipendenti nelle quali è
costante la probabilità p di un successo si dice variabile
binomiale di parametri n e p.
X può assumere come valori gli interi compresi tra 0 e n.
La distribuzione binomiale
Distribuzione binomiale
n x
P( X x) p (1 p) n x
x
dove
x = 0,1,2,...,n è il numero di successi nel campione
n = ampiezza campionaria
p = probabilità di successo
1−p = probabilità di insuccesso
La ripartizione della binomiale
x
n r
nr
F ( x)
p
(
1
p
)
dove [x] è il massimo
r 0 r
intero non superiore al reale x.
La distribuzione binomiale
Caratteristiche della distribuzione binomiale
Forma: una distribuzione binomiale può essere simmetrica o
asimmetrica in base ai valori assunti dai parametri. Per qualsiasi
valore di n la distribuzione binomiale è simmetrica se p = 0.5 e
asimmetrica per valori di p diversi da 0.5. L’asimmetria
diminuisce all’avvicinarsi di p a 0.5 e all’aumentare del numero
di osservazioni n.
Il valore atteso: si ottiene moltiplicando fra loro i due
parametri n e p.
La distribuzione binomiale
Lo scarto quadratico medio:
Si osserva che anche la v.c. binomiale possiede la proprietà
riproduttiva:
La distribuzione binomiale
Distribuzione binomiale per n=4 e p=0.1 realizzata
utilizzando Microsoft Excel
La distribuzione di Poisson
In molte applicazioni si è interessati a contare il numero di volte
in cui si osserva la realizzazione di un evento in una certa area di
opportunità.
Un’area di opportunità è un intervallo continuo quale un tempo,
una lunghezza, una superficie, o in generale un’area nella quale
un certo evento può verificarsi più volte.
Esempi possono essere il numero di difetti su uno sportello di un
frigorifero, il numero di telefonate che arrivano in un centralino
in un certo periodo di tempo o ancora il numero di persone che
entrano in un grande magazzino in un pomeriggio.
La distribuzione di Poisson
Quando si considerano aree di opportunità si può ricorrere alla
distribuzione di Poisson se sono soddisfatte quattro condizioni:
si è interessati a contare il numero di volte in cui un certo
evento si realizza in una certa area di opportunità
la probabilità che in una certa area di opportunità si osservi un
certo evento è la stessa in tutte le aree di opportunità
il numero di volte in cui un evento si realizza in una certa area
di opportunità è indipendente dal numero di volte in cui un
l’evento si è verificato in un’altra area
la probabilità che in una certa area di opportunità l’evento di
interesse si verifichi più di una volta diminuisce al diminuire
dell’area di opportunità
La distribuzione di Poisson
Sia E un evento da studiare nell’intervallo [0,T]. Allora un
processo di Poisson è caratterizzato dalle seguenti condizioni:
Il verificarsi di E in (t1,t2) è indipendente dal verificarsi di E in
qualsiasi altro (t3,t4) se gli intervalli non si sovrappongono.
La probabilità che si verifichi E nell’intervallo infinitesimo
(t0,t0+dt) è proporzionale al parametro λ che caratterizza la
prova.
La probabilità che due eventi si verifichino nello stesso
intervallo di tempo è un infinitesimo di ordine superiore
rispetto la probabilità che se ne verifichi uno solo.
Esempio
Supponiamo di esaminare il numero di clienti che raggiungono
una banca in un minuto. L’arrivo di un cliente è l’evento di
interesse e l’area di opportunità è l’intervallo temporale di un
minuto. Dato che le quattro condizioni sono soddisfatte possiamo
ricorrere alla distribuzione di Poisson per determinare la
probabilità con cui in un certo intervallo di tempo si presenti in
banca un certo numero di clienti.
La distribuzione di Poisson è caratterizza dal parametro λ, che
rappresenta il numero atteso di volte (che varia da zero ad
infinito) in cui l’evento si verifica nell’area di opportunità
considerata. Il numero di volte in cui si verifica un evento X in un
certo intervallo temporale varia da zero a infinito (per numeri
interi).
La distribuzione di Poisson
L’espressione matematica della distribuzione di Poisson per il
numero di eventi X, dato che il numero atteso di eventi è pari a λ è
dato da
Distribuzione di Poisson
P( X x) e
dove
x
x!
λ = numero atteso di successi nell’area di
opportunità
x = numero di successi per area di opportunità
(x=0,1,2,…)
Il valore atteso di tale v.c. coincide con la varianza ed è pari al
parametro λ. Tale v.c. gode della proprietà riproduttiva:
La distribuzione di Poisson
Riprendiamo l’esempio dell’arrivo di clienti presso una banca e
supponiamo che in un minuto arrivano in media tre clienti.
Qual è la probabilità che in un certo minuto arrivino esattamente
due clienti? Qual è la probabilità che arrivino più di due clienti?
La distribuzione di Poisson
Per evitare molti conti, le probabilità relative alla distribuzione di
Poisson possono essere ottenute a partire dalle Tavole.
Probabilità per una variabile aleatoria di Poisson
Calcolo di P(X=2) con λ=3