TRATTAMENTO STATISTICO DEI DATI ANALITICI
Nell’analisi chimica un analista effettua un numero limitato di prove e considera la media
dei risultati ottenuti per poter arrivare a determinare non il valore VERO di una determinata
grandezza ma una stima che sia il più possibile vicino ad esso e nel modo più riproducibile
possibile.
Il risultato finale dell’analisi dovrà essere rappresentativo ed affidabile, con associata una
incertezza che sia la più bassa possibile.
Perché questo si possa realizzare è assolutamente indispensabile adottare una strategia
di controllo statistico sulle fonti di errore e sulla qualità del dato analitico.
In generale qualsiasi misura di grandezza fisica o chimica comprende un certo margine di
incertezza (o errore) dovuto a diversi fattori, che possono essere distinti in due classi
fondamentali:
1. ERRORI SISTEMATICI (bias) legati alla capacità dell’operatore, agli strumenti, al
metodo analitico, e possono essere:
Additivi o sottrattivi: falsano il risultato sempre di una stessa quantità
Proporzionali: dipendono dall’entità della grandezza misurata
2. ERRORI CASUALI (indeterminati o Random) sono inevitabili e non possono mai
essere eliminati completamente
L’influenza di questi errori sul dato analitico può essere stimata, da un punto di vista
teorico, mediante l’analisi statistica dei dati raccolti attraverso una serie ripetuta di misure.
Prima di poter eseguire una tale analisi statistica è necessario introdurre alcuni termini che
verranno utilizzati:
VALORE VERO (µ)
È il risultato ottenuto da un analista esperto, in perfette condizioni fisiche che effettua un
numero ipoteticamente infinito di prove analitiche usando metodi appropriati e strumenti
efficienti. Questo insieme di dati rappresenta la popolazione dei dati ottenibili e la media
aritmetica coincide con il valore vero
ACCURATEZZA (xi) – ESATTEZZA ( x )
Indicano quanto un singolo dato o la media aritmetica di una serie di dati si avvicina al
valore vero (µ).
Esse vengono espresse in termini di:
ERRORE ASSOLUTO O SCARTO
Eass x i
riferito ad una media (esattezza)
Eass x i riferito ad una singola misura (accuratezza)
ERRORE RELATIVO
x
riferito ad una singola misura e detto ACCURATEZZA
Erel i
xi
Erel
riferito ad una media e detto ESATTEZZA
ERRORE RELATIVO PERCENTUALE
x
Erel% i
*100 riferito ad una singola misura e detto ACCURATEZZA
Erel%
xi
* 100 riferito ad una media e detto ESATTEZZA
Conseguentemente l’errore associato ad una singola misura estratta da una serie di dati
analitici sarà dato da :
Ei xi Ei xi x x
dove
x x
x
i
è l’errore assoluto casuale
è l’errore assoluto sistematico
PRECISIONE
Indica il grado di accordo di una serie di dati tra di loro, in genere viene espressa come
deviazione dei dati dalla media aritmetica e quindi è una misura della dispersione dei
risultati, per cui viene chiamata anche DEVIAZIONE STANDARD
INTERVALLO o RANGE
Corrisponde alla differenza tra il valore massimo e il valore minimo di una serie di misure
Es. 2,77 …… 4,03 R = 4,03 – 2,77 R = 1,26
VARIANZA ( s 2 )
È uguale alla somma dei quadrati delle differenze tra ogni dato (xi) e il valore medio ( x ),
x x
2
divisa per i gradi di libertà
s
DEVIAZIONE STANDARD
È la radice quadrata della varianza:
sx s
2
x
2
x
i
n 1
x
i
x
2
n 1
Nel caso di piccole serie di dati, la deviazione standard viene calcolata con la relazione :
sx = KRx
dove
K è il fattore di deviazione che è funzione del numero (n) di dati della serie;
K è ricavato dalla tabella allegata:
n
2
3
4
5
6
K
0,89
0,59
0,49
0,43
0,40
n
7
8
9
10
K
0,37
0,35
0,34
0,33
COEFFICIENTE DI VARIAZIONE (CV)
È la deviazione standard espressa come percentuale sulla media
CV
sx
*100
x
GRADI DI LIBERTA’
Se si effettuano n misure si ottengono n risultati i quali sono tutti indipendenti tra di loro.
Difatti non è possibile prevedere alcun nuovo dato conoscendo quello precedente o
successivo; in questi casi si dice che la serie di dati ha n gradi di libertà.
Se invece si considerano gli scarti della media si può prevedere uno scarto in base alla
somma di tutti gli altri, poiché la somma totale deve essere uguale a zero. Di
conseguenza, quando si prendono in considerazione gli scarti, i valori fra loro indipendenti
sono uno in meno rispetto al numero dei dati ( n – 1 ).
In generale, ogni volta che si può stabilire una relazione che lega tra loro una serie di dati,
si perde un grado di libertà e al limite, maggiore è il numero di relazioni, minore è il
numero di gradi di libertà.
MEDIANA
La mediana di una serie di dati è quel valore intorno al quale gli altri sono egualmente
distribuiti:
a) Se la serie è costituita da un numero dispari di misure, il valore della mediana
coincide con il valore centrale
b) Se la serie è costituita da un numero pari di misure, il valore della mediana coincide
con il valore medio della coppia centrale
ATTENDIBILITA’ (o affidabilità)
Caratterizza complessivamente un risultato analitico e dipende da diversi fattori:
sensibilità, precisione, accuratezza,..
RIPETIBILITA’
La ripetibilità indica la possibilità che un operatore alle prese con aliquote diverse di uno
stesso campione, ottenga risultati più o meno dispersi con la stessa procedura, con gli
stessi strumenti, in momenti diversi
RIPRODUCIBILITA’
La riproducibilità si riferisce ai risultati ottenuti da operatori diversi con strumenti diversi,
ma usando la stessa procedura.
RACCOLTA E SINTESI DEI DATI
Il dato analitico è un numero che deriva da una misura strumentale, mentre il risultato di
una prova è un numero che si ottiene del precedente dopo aver effettuato dei calcoli. Il
data analitico deve essere riportato in modo tale da contenere solo CIFRE
SIGNIFICATIVE, cioè le cifre che sono giustificate dalle prestazioni dello strumento e dal
metodo usato per l’analisi. In particolare si devono riportare le cifre significative note con
certezza più la prima cifra incerta, indicando l’intervallo di incertezza.
Es.
4,00 ± 0,02 g
0,897 ± 0,001 A
Un numero ottenuto attraverso un calcolo deve conservare esclusivamente le cifre
significative, eliminando le non significative attraverso l’operazione di arrotondamento
Es.
2,38 2,4
2,51 A 2,5
ADDIZIONI E SOTTRAZIONI
Nel caso di addizioni e sottrazioni il risultato deve avere tante cifre decimali quante ne
possiede il termine che ne ha di meno e la sua incertezza è uguale alla radice quadrata
della somma dei quadrati delle singole incertezze:
Es.
10,1 ± 0,2
+
223,23 ± 0,01 +
1456,72 ± 0,05 =
1690,05
± (0,2) 2 (0,01) 2 0(0,05) 2 0,2
Il risultato pertanto verrà espresso come : 1690,1 ± 0,2
MOLTIPLICAZIONE E DIVISIONE
Il risultato deve avere tante cifre significative quante ne ha il termine che ne ha meno;
l’incertezza è uguale alla radice quadrata della somma dei quadrati delle incertezze dei
moltiplicandi e dei dividendi, espresse in percentuale rispetto al valore cui si riferiscono
(56 1) * (0,033 0,002 ) * (15,0 0,05)
Es.
l’incertezza sarà:
0,115852
(239 ,27 0,15
2
2
2
2
0,5
0,15
1
0,002
*100
* / 100
*100 7,14384 %
*100
56
0,033
15,0
239 ,27
7,14384 : 100 = x : 0,115852
x = 0,0082763
Il risultato sarà quindi espresso come : 0,12 ± 0,01
SINTESI DEI DATI
Quando si applica un metodo analitico raccogliendo una serie numerosa di dati, per
stabilire quanto essi siano dispersi e con quale frequenza si presenti ciascuno di essi, si
può costruire un istogramma in cui l’altezza rappresenta la densità di frequenza.
Aumentando il numero di analisi, aumenta il numero di dati e l’istogramma tende a
diventare più simmetrico.
Al limite con un numero infinito di misure, l’istogramma tenderà ad assumere la forma di
una curva a campana, centrata sul valore medio e con l’area totale sottesa alla curva
uguale ad 1. Questa curva rappresenta dunque la distribuzione delle frequenze di tutti i
valori o anche la distribuzione di probabilità di ottenere un certo risultato e perciò viene
detta CURVA DI DENSITA’ DI PROBABILITA’.
L’area compresa tra due valori qualsiasi x1 e x2 corrisponde alla probabilità di trovare un
qualsiasi valore in quell’intervallo. L’equazione che descrive la curva è detta funzione di
probabilità p(x) che obbedisce a due regole fondamentali:
1. la probabilità che un evento accada è compresa tra 0 e 1
2. alla probabilità è associato il rischio (α) che l’evento non accada
Probabilità e rischio sono legati dalla relazione
P=1-α
Le distribuzioni di probabilità più comuni e che meglio interpretano le misure sperimentali
di cui si occupa l’analisi chimica sono:
la distribuzione normale o gaussiana
la distribuzione del t di Student
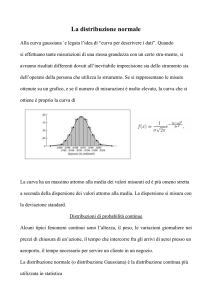
1. DISTRIBUZIONE NORMALE O GAUSSIANA
La curva normale o gaussiana è
caratterizzata di un andamento
simmetrico a campana e la funzione di
probabilità che la descrive, detta
distribuzione normale è data da:
f ( x)
1
( x )2
2 2
dove
e
* 2
σ = deviazione standard
µ = Valore medio
l’area sottesa alla curva ha valore 1
La probabilità che un valore sia compreso in un determinato intervallo corrisponde all’area
sottesa alla curva delimitata dalle ordinate che corrispondono agli estremi di tale intervallo.
Il calcolo di quest’area e, quindi, matematicamente dell’integrale, non è facile, in ogni caso
si assume che:
95,45% dell’intera superficie è compreso nell’intervallo (µ ± 2σ), ovverosia il
95% dell’intera superficie è compreso nell’intervallo (µ ± 1,96σ) e quindi la
probabilità di trovare valori all’esterno di tale intervallo è del 5%
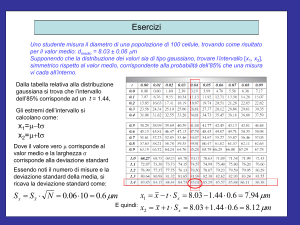
2. DISTRIBUZIONE DEL t DI STUDENT
La distribuzione normale o gaussiana è tipica dell’analisi chimica, anche se non sempre
valida, e comunque applicabile ad un numero elevato di prove. Nella comune pratica di
laboratorio il numero di prove è molto limitato per cui tale distribuzione è applicabile con
estrema difficoltà. Di questo problema si occupò GOSSET (che si firmava student) il quale
studiò la distribuzione del rapporto t, detto di Student giungendo ad una funzione di
probabilità, detta distribuzione di Student, i cui valori sono riportati in tabella in funzione di
t*s
p e ν. Questo valore ci permette di calcolare l’intervallo di fiducia: CL x
dove:
n
t = costante di student calcolata per
α = (1-p)/2 e
v = (n – 1)
s = deviazione standard
n = numero di misure
TEST DI SIGNIFICATIVITA’
Sono dei semplici test che permettono di verificare la presenza di dati anomali in una
serie; noi esamineremo il TEST DI DIXON supponendo che uno o più valori agli estremi
siano anomali.
In particolare l’ipotesi è verificare due dati sospetti. Uno all’inizio e uno alla fine della serie.
Si dispongono i dati sistemandoli x1, x2, …, xn in ordine crescente
Si calcola il parametro r:
x x
per il primo valore rA 2 1
xn1 x1
x x
per l’ultimo valore rB n n1
xn x2
Si confrontano i valori rA e rB con il valore rt (tabulato in funzione di n e α 0 0,05
(probabilità del 95%)
Se rA ≤ rt
Se rB ≤ rt
l’ipotesi è nulla e il dato non va eliminato
l’ipotesi è nulla e il dato non va eliminato
Se rA > rt
Se rB > rt
l’ipotesi è valido e il dato va eliminato
l’ipotesi è valida e il dato va eliminato
RELAZIONI TRA DUE VARIABILI
In generale tra due variabili vi è un legame quando le variazioni di una causano variazioni
dell’altra. Esamineremo il caso in cui le variabili possono essere correlate in modo
generico, tracciando una curva di regressione che permette di evidenziare un legame più
o meno forte tra di loro.
CORRELAZIONE
Quando due variabili non sono legate da una legge nota, ma riportate su un diagramma
cartesiano, mostrano un certo grado di associazione, è possibile quantificare tale legame
mediante un parametro detto COEFFICIENTE DI CORRELAZIONE che nel caso di una
2
s xy
correlazione lineare diventa:
dove
r
s x2 * s y2
sx = varianza di x
sy = varianza di y
s2xy = covarianza di x ed y
x x * y
i
y
n
x x * y y
x x * y y
r
più semplicemente
i
i
i
2
i
2
i
il valore di r varia tra (-1) e (+1).
Valori di r uguali o vicini a zero indicano che non vi è alcuna correlazione lineare tra
le due variabili;
valori di r uguali o molto vicini a (+1) indicano una forte correlazione positiva.
Per verificare ora se due variabili possono essere considerate correlate o indipendenti tra
di loro:
1. si calcola il valore di r in base alla formula vista
2. si confronta il valore di r calcolato (rc) con quello riportato in tabella in
corrispondenza dell’α prescelto e per ν = n – 2
3. l’ipotesi è nulla, i dati sono correlati se rc < rt
n2
si può verificare il grado di correlazione (r) usando la funzione: t r *
1 r2
si confronta poi il valore tc calcolato con il valore tt ricavato dalla tabella in corrispondenza
dell’α prescelto e per ν = n – 2
se tc ≥ tt l’ipotesi è nulla; le variabili sono correlate
REGRESSIONE
La relazione di regressione si stabilisce quando tra le due variabili esiste, per esempio,
una legge di dipendenza lineare, come nel caso della relazione che lega l’assorbanza (A)
alla concentrazione (C), data dalla Legge di BEER A = K * C
La retta di regressione è data dall’equazione
y = b0 + b1x
con
1. Coefficiente angolare
b1
x y
i
i
x
2
i
2. Termine noto
b0 y b1 x
x y
i
n
xi 2
n
i
dove x e y sono, rispettivamente, il valore medio di (x) ed (y).
Una volta definita l’equazione che meglio interpreta la relazione tra la variabile dipendente
e la variabile indipendente, dobbiamo verificare se questo modello è quello valido.
Il modello matematico che viene comunemente utilizzato è il metodo detto dei “minimi
quadrati” secondo il quale la retta che meglio si adatta ai punti sperimentali è quella che
consente di minimizzare i quadrati delle distanze (misurate lungo l’asse delle ordinate) tra i
punti osservati e la retta stessa.
In pratica la validità del modello di regressione è fornita dal coefficiente di correlazione o
meglio dal coefficiente di determinazione (R2) che altro non è che il quadrato del
coefficiente di correlazione lineare (r2)
x y x * y
x * y y
x
2
R
i
2
i
i
2
2
i
i
n
i
2
2
i
i
n
RETTA DI TARATURA
Il modello della regressione lineare si presta bene per l’interpolazione delle rette di
taratura. (Conc. Segnale) permettendoci di ricavare informazioni su tre importanti
parametri relativi ad un metodo analitico.
1) SENSIBILITA’ DI UN METODO
Se si riporta su un grafico la conc. di un analita (asse x) e la corrispondente risposta
strumentale (asse y), il coefficiente angolare della retta (b1), che si può interpolare con il
metodo dei minimi quadrati, rappresentala la sensibilità del metodo. In definitiva la
dy
sensibilità è data da : S
ovvero dal rapporto tra la variazione del segnale (dy) e la
dx
corrispondente variazione di concentrazione (dx) che esprime la variazione di
concentrazione unitaria al variare del segnale.
2) LIMITE DI RIVELABILITA’
Il limite di rivelabilità che può essere raggiunto con una determinata procedura analitica,
corrisponde alla concentrazione (o alla quantità) che può essere determinata effettuando
una misura che sia al tempo stesso significativa e la più bassa possibile. Tale valore può
essre determinato con approcci diversi a seconda della tecnica analitica, per la precisione:
Metodi basati sulla sottrazione del bianco con i quali si procede alla misura di una
serie di bianchi, poi si determina il valore medio e la deviazione standard. Questi
valori vengono poi trasformati in termini di concentrazione, usando il grafico di
taratura o il fattore di conversione stechiometrico
Metodi basati sulla misura dell’area e dell’altezza, nei quali l’unico punto di
riferimento è il disturbo della linea di base. Pertanto si può monitorare la variazione
del segnale per un certo periodo di tempo o lungo un determinato intervallo di
misura. Il segnale di disturbo viene considerato significativo se aumenta di 2 o 3
volte rispetto alla media delle variazioni registrate.
3) INTERVALLO DI LINEARITA’
I grafici di taratura hanno un andamento lineare solo entro limiti ben precisi di
concentrazione. Il limite superiore dell’intervallo di linearità, detto limite di linearità,
corrisponde a quella concentrazione (o quantità) che produce un segnale inferiore del 5%
rispetto a quello previsto dall’equazione di regressione.