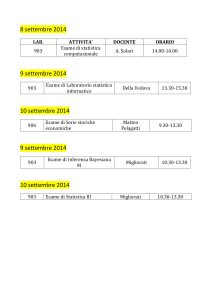
Metodi Statistici e Probabilistici per l’Ingegneria
FONDAMENTI DI INFERENZA
Corso di Laurea in Ingegneria Civile
Facoltà di Ingegneria, Università di Padova
Docente: Dott. L. Corain
E-mail: [email protected]
Home page: www.gest.unipd.it/~livio/Corso_Civile.html
FONDAMENTI DI INFERENZA
1
SOMMARIO
Distribuzioni campionarie
Teorema del limite centrale
Stima e intervalli di confidenza
Verifica di ipotesi
Errore di primo e di secondo tipo
Verifica di ipotesi ad un campione
Verifica di ipotesi a due campioni
Verifica di ipotesi a più campioni (ANOVA)
Test Chi-quadrato
FONDAMENTI DI INFERENZA
2
1
DISTRIBUZIONI CAMPIONARIE
L’interesse dell’inferenza statistica è di trarre conclusioni
sulla popolazione e su alcuni suoi parametri e non sul
solo campione.
A questo scopo si utilizzano delle statistiche, ovvero
delle funzioni calcolate sulla base di un campione allo
scopo o di stimare (stima) o prendere delle decisioni
(verifica di ipotesi) sui valori dei corrispondenti
parametri dell’intera popolazione.
La media campionaria è l’esempio di una statistica
utilizzata per stimare la media di una variabile di
interesse (ad es. la prevalenza di un patogeno) riferita
all’intera popolazione (un dato processo alimentare).
La proporzione campionaria è una statistica utilizzata
per stimare la proporzione di unità (ad es. confezioni di
prodotto) in una popolazione (processo alimentare) che
hanno una certa caratteristica (sono contaminate).
FONDAMENTI DI INFERENZA
3
DISTRIBUZIONI CAMPIONARIE
Supponendo ipoteticamente di procedere all’estrazione
di tutti i possibili campioni, la distribuzione di tutti i
risultati ottenuti si dice distribuzione campionaria.
La distribuzione della media campionaria è perciò la
distribuzione di tutte le possibili medie che
osserveremmo se procedessimo all’estrazione di tutti i
possibile campioni di una certa ampiezza.
Nella pratica invece, da una popolazione viene estratto a
caso un solo campione, di ampiezza prestabilita a partire
dal quale si può calcolare il valore osservato della
statistica campionaria.
La media campionaria è non distorta per la media della
popolazione, cioè la media di tutte le possibili medie
campionarie (calcolate a partire campioni di uguale
ampiezza n) fornisce la vera media della popolazione.
FONDAMENTI DI INFERENZA
4
2
DISTRIBUZIONI CAMPIONARIE
Mentre le osservazioni nella popolazione assumono anche
valori estremamente piccoli o estremamente grandi, la
media campionaria è caratterizzata da una minore
variabilità rispetto ai dati originali. Le medie campionarie
saranno quindi caratterizzate, in generale, da valori meno
dispersi rispetto a quelli che si osservano nella
popolazione. Lo scarto quadratico medio della media
campionaria, detto errore standard della media,
quantifica la variazione della media campionaria da
campione a campione:
L’errore standard della media
σX =σ / n
L’errore standard della media campionaria è uguale allo
scarto quadratico medio della popolazione diviso √n.
FONDAMENTI DI INFERENZA
5
DISTRIBUZIONI CAMPIONARIE
Introdotta l’idea di distribuzione
campionaria e definito l’errore
standard della media, bisogna
stabilire quale sia la distribuzione
della media campionaria. Se un
campione è estratto da una
popolazione normale con media
µ e scarto quadratico medio σ, la
media campionaria ha distribuzione normale indipendentemente dall’ampiezza campionaria n,
ed è caratterizzata da valore atteso µ X = µ e scarto quadratico
medio pari all’errore standard σX . In figura sono riportate le
distribuzioni delle medie campionarie di 500 campioni di
ampiezza 1,2,4,8,16 e 32 estratti da una popolazione normale.
FONDAMENTI DI INFERENZA
6
3
TEOREMA DEL LIMITE CENTRALE
Sinora abbiamo analizzato la distribuzione della media
campionaria nel caso di una popolazione normale. Tuttavia,
si presenteranno spesso casi in cui la distribuzione della
popolazione può non essere normale. In questi casi è utile
riferirsi ad un importante teorema della statistica, il teorema
del limite centrale, che consente di dire qualcosa sulla
distribuzione della media campionaria, anche nel caso in cui
una popolazione non abbia distribuzione normale.
Teorema del limite centrale
Quando l’ampiezza del campione casuale diventa
sufficientemente grande, la distribuzione della media
campionaria può essere approssimata dalla distribuzione
normale. E questo indipendentemente dalla forma della
distribuzione dei singoli valori della popolazione.
FONDAMENTI DI INFERENZA
7
TEOREMA DEL LIMITE CENTRALE
Si tratta, allora, di stabilire cosa si intende per
“sufficientemente grande”, problema ampiamente affrontato
dagli statistici. Come regola di carattere generale, molti
sono concordi nell’affermare che quando il campione
raggiunge un’ampiezza pari almeno a 30, la distribuzione
della media campionaria può ritenersi approssimativamente
normale. Tuttavia, il teorema del limite centrale può essere
applicato anche con campioni di ampiezza inferiore se si sa
che la distribuzione della popolazione ha alcune
caratteristiche che la avvicinano di per se stessa alla
normale (ad esempio, quando è simmetrica).
Il teorema del limite centrale svolge un ruolo cruciale in
ambito inferenziale, in quanto consente di fare inferenza
sulla media della popolazione senza dover conoscere la
forma specifica della distribuzione della popolazione.
FONDAMENTI DI INFERENZA
8
4
TEOREMA DEL LIMITE CENTRALE
Ciascuna
delle
distribuzioni
campionarie riportate è ottenuta
estraendo 500 campioni diversi
dalle
rispettive
popolazioni.
Sono state considerate diverse
ampiezze campionarie (n = 2, 5,
30). Nella seconda colonna è
riportata la distribuzione della
media campionaria nel caso di
una
popolazione
la
cui
distribuzione
(uniforme
o
rettangolare) è simmetrica e
nella terza si considera una
popolazione con distribuzione
obliqua a destra (esponenziale).
FONDAMENTI DI INFERENZA
9
TEOREMA DEL LIMITE CENTRALE
Sulla base dei risultati ottenuti per le distribuzioni note (la
normale, l’uniforme l’esponenziale) possiamo trarre alcune
conclusioni in merito al teorema del limite centrale:
Per
la
maggior
parte
delle
popolazioni,
indipendentemente dalla forma della loro distribuzione, la
distribuzione
della
media
campionaria
è
approssimativamente normale, purché si considerino
campioni di almeno 30 osservazioni.
Se la distribuzione della popolazione è abbastanza
simmetrica, la distribuzione della media campionaria è
approssimativamente una normale, purché si considerino
campioni di almeno 5 osservazioni.
Se la popolazione ha una distribuzione normale, la media
campionaria è distribuita secondo la legge normale,
indipendentemente dall’ampiezza del campione.
FONDAMENTI DI INFERENZA
10
5
STIMA E INTERVALLI DI CONFIDENZA
L’inferenza statistica è il processo attraverso il quale i
risultati campionari vengono utilizzati per trarre
conclusioni sulle caratteristiche (parametri e forma della
distribuzione) di una popolazione.
Tale processo consente di stimare caratteristiche non
note della popolazione come i parametri (ad es. la media
per le var. numeriche o la proporzione per le var.
categoriali) che caratterizzano la distribuzione della
variabile di interesse.
Ci sono due approcci fondamentali di stima: le stime
puntuali e le stime per intervalli (intervalli di
confidenza).
Uno stimatore puntuale è una statistica (cioè una
funzione dei dati campionari) che viene definita allo
scopo di fornire una sintesi su un parametro di interesse.
FONDAMENTI DI INFERENZA
11
STIMA E INTERVALLI DI CONFIDENZA
La stima puntuale è lo specifico valore assunto da una
statistica, calcolata in corrispondenza dei dati campionari
e che viene utilizzata per stimare il vero valore non noto
di un parametro di una popolazione.
Uno stimatore per intervallo è un intervallo costruito
attorno allo stimatore puntuale, in modo tale che sia nota
e fissata la probabilità che il parametro appartenga
all’intervallo stesso.
Tale probabilità è detta livello di confidenza ed è in
generale indicato con (1−α)% dove α è la probabilità che
il parametro si trovi al di fuori dell’intervallo di confidenza.
Quindi la confidenza è il grado di fiducia che l’intervallo
possa contenere effettivamente il parametro di interesse.
FONDAMENTI DI INFERENZA
12
6
STIMA E INTERVALLI DI CONFIDENZA
Esempio: si consideri un processo industriale di
riempimento di scatole di cereali e sia assuma che il peso
X delle scatole sia X~N(µ;152). Dato un campione casuale
di n=25 scatole con peso medio 362.3 grammi si vuole
costruire un intervallo di confidenza al 95% per µ.
Per la proprietà della distribuzione normale e della media
campionaria risulta che
X −µ
P − Zα / 2 ≤
≤ Zα / 2 = 1 − α
σ/ n
quindi un intervallo di confidenza all’(1−α)% per µ è dato da
X − Zα / 2 ⋅ σ / n ≤ µ ≤ X + Zα / 2 ⋅ σ / n
Nel caso specifico si ottiene 356.42 ≤ µ ≤ 368.18.
FONDAMENTI DI INFERENZA
13
STIMA E INTERVALLI DI CONFIDENZA
Ipotizziamo che µ sia uguale a 368. Per comprendere a
fondo il significato della stima per intervallo e le sue
proprietà è utile fare riferimento all’ipotetico insieme di tutti i
possibili campioni di ampiezza n che è possibile ottenere.
Osserviamo che per alcuni campioni la stima per intervalli di
µ è corretta, mentre per altri non lo è.
FONDAMENTI DI INFERENZA
14
7
STIMA E INTERVALLI DI CONFIDENZA
Nella pratica estraiamo un solo campione e siccome non
conosciamo la media della popolazione non possiamo
stabilire se le conclusioni a cui perveniamo sono corrette o
meno.
Tuttavia possiamo affermare di avere una fiducia all’(1−α)%
che la media appartenga all’intervallo stimato.
Quindi, l’intervallo di confidenza all’(1−α)% della media con
σ noto si ottiene utilizzando l’equazione:
Intervallo di confidenza per la media con σ noto
X − Zα / 2 ⋅ σ / n ≤ µ ≤ X + Zα / 2 ⋅ σ / n
dove Zα/2 è il valore a cui corrisponde un’area cumulata pari
a (1−α/2) della distribuzione normale standard.
FONDAMENTI DI INFERENZA
15
STIMA E INTERVALLI DI CONFIDENZA
In alcuni casi risulta desiderabile un grado di certezza
maggiore, ad es. del 99%, ed in altri casi possiamo
accettare un grado minore di sicurezza, ad es. del 90%.
Il valore Zα/2 di Z che viene scelto per costruire un intervallo
di confidenza è chiamato valore critico. A ciascun livello di
confidenza (1−α) corrisponde un diverso valore critico.
Livelli di confidenza maggiori si ottengono perciò a prezzo di
un ampliamento dell’intervallo di confidenza: esiste un tradeoff tra utilità pratica dell’intervallo e livello di confidenza.
FONDAMENTI DI INFERENZA
16
8
STIMA E INTERVALLI DI CONFIDENZA
In genere lo scarto quadratico medio della popolazione σ,
al pari della media µ, non è noto. Pertanto, per ottenere un
intervallo di confidenza per la media della popolazione
possiamo basarci sulle sole statistiche campionarie X e S.
Se la variabile casuale X ha una distribuzione normale
allora la statistica
t=
X −µ
S n
ha una distribuzione t di Student con (n−1) gradi di libertà.
Se variabile casuale X non ha una distribuzione normale la
statistica t ha comunque approssimativamente una
distribuzione t di Student in virtù del Teorema del Limite
Centrale.
FONDAMENTI DI INFERENZA
17
STIMA E INTERVALLI DI CONFIDENZA
La distribuzione t di Student ha una forma molto simile a
quella della normale standardizzata. Tuttavia il grafico
risulta più appiattito e l’area sottesa sulle code è maggiore
di quella della normale a causa del fatto che s non è noto e
viene stimato da S. L’incertezza su s causa la maggior
variabilità di t.
All’aumentare dei gradi di libertà, la distribuzione t si
avvicina progressivamente alla distribuzione normale fino a
che le due distribuzioni risultano virtualmente identiche.
FONDAMENTI DI INFERENZA
18
9
STIMA E INTERVALLI DI CONFIDENZA
Il significato dei gradi di libertà è legato al fatto che per
calcolare S2 è necessario calcolare preventivamente X .
Quindi, dato il valore di X , solo n−1 osservazioni
campionarie sono libere di variare: ci sono quindi n−1 gradi
di libertà.
L’intervallo di confidenza all’(1−α)% della media quando σ
non è noto è definito nell’equazione:
Intervallo di confidenza per la media (σ non noto)
X − tn −1;α / 2 ⋅ S / n ≤ µ ≤ X + tn −1;α / 2 ⋅ S / n
dove tn−1;α/2 è il valore critico a cui corrisponde un’area
cumulata pari a (1−α/2) della distribuzione t di Student con
(n−1) gradi di libertà.
19
FONDAMENTI DI INFERENZA
STIMA E INTERVALLI DI CONFIDENZA
Data un campione casuale X1,...,Xn estratto da una
popolazione normale di media µ e varianza σ2, è possibile
costruire un intervallo di confidenza per la varianza σ2
facendo riferimento alla distribuzione Chi-quadrato, infatti
∑( X
n
S =
2
i =1
i
−X)
n −1
2
≈
σ2
n −1
χ n2−1
L’equazione seguente definisce l’intervallo di confidenza
all’(1−α)% per la varianza della popolazione.
Intervallo di confidenza per la varianza
(n − 1) S 2 χα2 /2;n −1 ≤ σ 2 ≤ (n − 1) S 2 χ12−α /2;n−1
dove χ2α/2;n-1 e χ21-α/2;n-1 sono i valori critici della
distribuzione Chi-quadrato con n-1 gdl a livello α/2 e 1-α/2.
FONDAMENTI DI INFERENZA
20
10
STIMA E INTERVALLI DI CONFIDENZA
Data una popolazione i cui elementi possiedono una certa
caratteristica secondo una data proporzione, indicata dal
parametro incognito π, è possibile costruire un intervallo di
confidenza per π a partire dal corrispondente stimatore
puntuale, dato dalla frequenza campionaria πˆ =X/n, dove n
è l’ampiezza campionaria e X è il numero di elementi del
campione che hanno la caratteristica di interesse.
L’equazione seguente definisce l’intervallo di confidenza
all’(1−α)% per la proporzione nella popolazione.
Intervallo di confidenza per la proporzione
πˆ − Zα / 2 ⋅ πˆ (1 − πˆ ) n ≤ π ≤ πˆ + Zα /2 ⋅ πˆ (1 − πˆ ) n
dove Zα/2 è il valore critico della distribuzione normale
standard e si assume che X e (n−X) siano entrambi >5.
FONDAMENTI DI INFERENZA
21
VERIFICA DI IPOTESI
La verifica di ipotesi è una procedura inferenziale che
ha come scopo quello di considerare l’informazione
empirica (ottenuta da una statistica campionaria) e di
stabilire se questa è favorevole ad una asserzione di
interesse sui parametri della popolazione.
Ad esempio, potremmo asserire che il processo
produttivo di riempimento delle scatole di cerali può
essere considerato appropriato (sotto controllo) se il
peso medio µ delle scatole è di 368 grammi.
La verifica di ipotesi ha inizio proprio con una
considerazione di una teoria o proposizione riguardante
un particolare parametro della popolazione e l’ipotesi
che il valore del parametro della popolazione sia uguale
ad un dato valore prende il nome di ipotesi nulla.
FONDAMENTI DI INFERENZA
22
11
VERIFICA DI IPOTESI
L’ipotesi nulla in genere coincide con lo stato delle cose
e viene indicata con il simbolo H0, quindi nell’esempio
del processo produttivo
H0: µ = 368
Sebbene le informazioni siamo tratte a partire dal
campione, l’ipotesi è espressa con riferimento a un
parametro della popolazione, perché si è interessati
all’intero processo produttivo, vale a dire alla
popolazione di tutte le scatole di cereali prodotte.
Se i risultati campionari non fossero favorevoli all’ipotesi
nulla si dovrebbe concludere che l’ipotesi nulla sia falsa
e chiaramente ci deve essere un’altra ipotesi che risulti
vera. L’ipotesi alternativa H1 è l’asserzione opposta
all’ipotesi nulla, e nell’esempio in questione
H1: µ ≠ 368
FONDAMENTI DI INFERENZA
23
VERIFICA DI IPOTESI
L’ipotesi alternativa rappresenta la conclusione a cui si
giunge quando si rifiuta l’ipotesi nulla (decisione forte),
cioè quando il campione osservato fornisce sufficiente
evidenza del fatto che l’ipotesi nulla sia falsa.
D’altro canto il mancato rifiuto dell’ipotesi nulla non prova
che essa è vera. Quello che si può concludere è che non
vi è sufficiente evidenza empirica contraria ad essa
(decisione debole).
Di seguito sono riassunti i punti principali che sintetizzano
il concetto di ipotesi nulla e di ipotesi alternativa:
l’ipotesi nulla H0 rappresenta lo stato attuale delle cose
o l’attuale convinzione riguardo a una situazione;
l’ipotesi alternativa H1 è specificata come ipotesi
opposta all’ipotesi nulla e rappresenta una certa …
FONDAMENTI DI INFERENZA
24
12
VERIFICA DI IPOTESI
… conclusione inferenziale che si è interessati a
dimostrare.
se si rifiuta l’ipotesi nulla si accetta l’ipotesi alternativa.
se si accetta l’ipotesi nulla ciò non significa che si è
dimostrato che l’ipotesi nulla sia vera.
l’ipotesi nulla H0 si riferisce sempre a un valore
specifico del parametro della popolazione (ad esempio
µ), e non a una statistica campionaria (ad esempio X ).
l’ipotesi nulla contiene sempre un segno di eguale
relativo al valore specificato del parametro della
popolazione (ad esempio H0: µ = 368 grammi).
l’ipotesi alternativa non contiene mai un segno di
eguale relativo al valore specificato del parametro della
popolazione (ad esempio H1: µ ≠ 368 grammi).
FONDAMENTI DI INFERENZA
25
VERIFICA DI IPOTESI
La logica sottostante alla verifica di ipotesi è quella di
stabilire la plausibilità dell’ipotesi nulla alla luce delle
informazioni campionarie.
Se ipotesi nulla asserisce che il peso medio dei cereali
contenuti in tutte le scatole prodotte è 368 grammi (il
valore del parametro specificato dall’azienda) si procede
all’estrazione di un campione di scatole e si pesa
ciascuna scatola per calcolare la media campionaria
(statistica che stima il vero valore del parametro µ).
Anche se l’ipotesi nulla è vera, è probabile che la
statistica differisca dal vero valore del parametro per
effetto del caso (della variabilità campionaria).
Ciononostante ci aspettiamo che in questo caso la
statistica campionaria sia vicina al parametro della
popolazione.
FONDAMENTI DI INFERENZA
26
13
VERIFICA DI IPOTESI
La teoria della verifica di ipotesi fornisce definizioni
chiare sulla base delle quali valutare le differenze
osservate tra la statistica e il parametro.
Il processo decisionale è sostenuto dal punto di vista
quantitativo, valutando la probabilità di ottenere un dato
risultato campionario, se l’ipotesi nulla fosse vera.
Tale probabilità si ottiene determinando prima la
distribuzione campionaria della statistica di interesse (ad
es. la media campionaria) e poi calcolando la probabilità
che la statistica test assuma il valore osservato in
corrispondenza del campione estratto.
La distribuzione campionaria della statistica test spesso
è una distribuzione statistica nota, come la normale o la
t, e quindi possiamo ricorrere a queste distribuzioni per
decidere se rifiutare o meno a un’ipotesi nulla.
FONDAMENTI DI INFERENZA
27
VERIFICA DI IPOTESI
La distribuzione campionaria della statistica test è divisa
in due regioni: una regione di rifiuto (chiamata anche
regione critica) e una regione di accettazione.
Se la statistica test cade nella regione di accettazione,
l’ipotesi nulla non può essere rifiutata e se la statistica
test cade nella regione di rifiuto, l’ipotesi nulla deve
essere rifiutata.
La regione di rifiuto può essere vista come l’insieme di ...
FONDAMENTI DI INFERENZA
28
14
ERRORE DI PRIMO E DI SECONDO TIPO
… tutti i valori della statistica test che non è probabile
che si verifichino quando l’ipotesi nulla è vera, mentre è
probabile che questi valori si verifichino quando l’ipotesi
nulla è falsa.
Per prendere una decisione sull’ipotesi nulla, dobbiamo
in primo luogo definire le regioni di rifiuto e di
accettazione e questo viene fatto determinando il
cosiddetto valore critico della statistica test.
La determinazione di questo valore dipende
dall’ampiezza della regione di rifiuto, che è legata al
rischio comportato dal prendere una decisione sul
parametro alla luce delle sole informazioni campionarie.
Quando si applica un procedimento di verifica di ipotesi,
si possono commettere due tipi di errori, l’errore di
prima specie e l’errore di seconda specie.
FONDAMENTI DI INFERENZA
29
ERRORE DI PRIMO E DI SECONDO TIPO
L’errore di prima specie (detto anche livello di
significatività) si verifica se si rifiuta l’ipotesi nulla quando
questa è vera e quindi non dovrebbe essere rifiutata. La
probabilità che si verifichi un errore di prima specie è
indicata con α.
L’errore di seconda specie si verifica se si accetta
l’ipotesi nulla quando questa è falsa e quindi dovrebbe
essere rifiutata. La probabilità che si verifichi un errore di
seconda specie è indicata con β.
FONDAMENTI DI INFERENZA
30
15
ERRORE DI PRIMO E DI SECONDO TIPO
In genere, si controlla l’errore di prima specie fissando il
livello del rischio α che si è disposti a tollerare.
Dal momento che il livello di significatività è specificato
prima di condurre la verifica di ipotesi, il rischio di
commettere un errore di prima specie α è sotto il
controllo di chi compie l’analisi (in genere i valori
assegnati ad α sono 0.01, 0.05 o 0.1).
La scelta di α dipende fondamentalmente dai costi che
derivano dal commettere un errore di prima specie.
Una volta specificato il valore di α, si ottiene anche la
regione di rifiuto perché è la probabilità che la statistica
test cada nella regione di rifiuto quando l’ipotesi nulla è
vera. Il valore critico che separa la regione di
accettazione da quella di rifiuto viene determinato di
conseguenza.
FONDAMENTI DI INFERENZA
31
ERRORE DI PRIMO E DI SECONDO TIPO
Il coefficiente di confidenza, indicato con (1−α),
rappresenta la probabilità che l’ipotesi nulla non sia rifiutata
quando è vera (quindi non dovrebbe essere rifiutata). Il
livello di confidenza di un test di ipotesi è dato da
(1−α)×100%.
A differenza dell’errore di prima specie, che controlliamo
fissando α, la probabilità di commettere un errore di seconda
specie dipende dalla differenza tra il valore ipotizzato e il
vero valore del parametro della popolazione: se la differenza
è grande, è probabile che β sia piccolo.
La potenza del test, indicata con (1–β), rappresenta la
probabilità di rifiutare l’ipotesi nulla quando è falsa (e quindi
dovrebbe essere rifiutata).
FONDAMENTI DI INFERENZA
32
16
VERIFICA DI IPOTESI AD UN CAMPIONE
Un modo per controllare e ridurre l’errore di seconda
specie consiste nell’aumentare la dimensione del
campione perché un’elevata dimensione del campione
consente di individuare anche piccole differenze tra la
statistica campionaria e il parametro della popolazione.
Per un dato valore di α, l’aumento della dimensione
campionaria determina una riduzione di β e quindi un
aumento della potenza del test per verificare se l’ipotesi
nulla H0 è falsa.
Tuttavia per una data ampiezza campionaria dobbiamo
tenere conto del trade-off tra i due possibili tipi di errori:
possiamo fissare un valore piccolo per α, tuttavia al
diminuire di α, β aumenta e pertanto una riduzione del
rischio connesso all’errore di prima specie si
accompagna a un aumento di quello connesso a un
errore di seconda specie.
FONDAMENTI DI INFERENZA
33
VERIFICA DI IPOTESI AD UN CAMPIONE
Tornando al problema di stabilire se il processo produttivo
funziona in maniera adeguata, viene estrae un campione di
25 scatole, esse sono pesate e si confronta il peso medio
delle scatole del campione (la statistica campionaria) con la
media di 368 grammi (il valore ipotizzato del parametro).
L’ipotesi nulla e l’ipotesi alternativa in questo esempio sono
rispettivamente:
H0: µ = 368
H1: µ ≠ 368
Se si assume che la popolazione abbia distribuzione
normale e che scarto quadratico medio della popolazione σ
sia noto, la verifica di ipotesi viene condotta utilizzando il
cosiddetto test di ipotesi Z. Tale test può essere applicato
anche se la distribuzione non è normale purché l’ampiezza
sia sufficientemente elevata (Teorema del Limite Centrale).
FONDAMENTI DI INFERENZA
34
17
VERIFICA DI IPOTESI AD UN CAMPIONE
L’equazione illustra come si ottiene la statistica test Z. Il
numeratore dell’equazione misura di quanto la media
osservata X differisce dalla media µ ipotizzata, mentre al
denominatore troviamo l’errore standard della media.
Pertanto Z ci dice per quanti errori standard X differisce da µ.
Statistica Z per la verifica d’ipotesi sulla media (σ noto)
Z=
X −µ
σ/ n
Per definire le regioni di accettazione e di rifiuto è necessario
determinare i valori critici della statistica test, facendo
riferimento alla distribuzione normale standardizzata una
volta fissato l’errore di prima specie α.
FONDAMENTI DI INFERENZA
35
VERIFICA DI IPOTESI AD UN CAMPIONE
Ad esempio, se si fissa α=0.05, l’area sottesa in
corrispondenza della regione di rifiuto deve essere pari a
0.05. Poiché la regione di rifiuto coincide con le due code
della distribuzione (si parla di un test a due code), l’area
0.05 viene divisa in due aree di 0.025. Una regione di rifiuto
di 0.025 nelle due code della distribuzione normale dà luogo
a un’area cumulata di 0.025 alla sinistra del valore critico
più piccolo e a un’area pari a 0.975 alla sinistra del valore
critico più grande.
Cercando queste aree nella tavola della distribuzione
normale [Tavola E.2b], troviamo che i valori critici che
dividono la regione di rifiuto da quella di accettazione sono
–1.96 e +1.96.
FONDAMENTI DI INFERENZA
36
18
VERIFICA DI IPOTESI AD UN CAMPIONE
La Figura mostra che se la media µ ha valore 368, come
ipotizza H0, allora la statistica test Z ha una distribuzione
normale standardizzata. Valori di Z maggiori di +1.96 o
minori di –1.96 indicano che X è così distante dal valore
ipotizzato per µ (368) che non è probabile che questo valore
si verifichi quando H0 è vera.
37
FONDAMENTI DI INFERENZA
VERIFICA DI IPOTESI AD UN CAMPIONE
Pertanto la regola decisionale è la seguente:
Rifiutare H0
se Zα/2<–1.96 oppure se Zα/2>+1.96
Non rifiutare H0
altrimenti
Supponiamo che la media campionaria calcolata a partire
dal campione di 25 scatole sia 372.5 grammi e che σ sia 15
grammi, allora
X − µ 372.5 − 368
Z=
σ/ n
=
15 / 25
= +1.50
e quindi non è possibile rifiutare l’ipotesi nulla.
FONDAMENTI DI INFERENZA
38
19
VERIFICA DI IPOTESI AD UN CAMPIONE
Le 6 fasi della verifica di ipotesi utilizzando l’approccio
del valore critico:
1.
Specificare l’ipotesi nulla e l’ipotesi alternativa.
2.
Scegliere il livello di significatività α e l’ampiezza
campionaria n. Il livello di significatività viene fissato in
base all’importanza relativa che si accorda ai rischi
derivanti dal commettere un errore di prima specie e
dal commettere un errore di seconda specie.
3.
Individuare la tecnica statistica a cui fare riferimento e
la corrispondente distribuzione campionaria.
4.
…
FONDAMENTI DI INFERENZA
39
VERIFICA DI IPOTESI AD UN CAMPIONE
3.
…
4.
Calcolare i valori critici che separano la regione di
rifiuto da quella di accettazione.
5.
Raccogliere i dati e calcolare il valore campionario
della statistica test.
6.
Prendere la decisione statistica. Se la statistica test
cade nella regione di accettazione, l’ipotesi nulla H0
non può essere rifiutata. Se la statistica test cade nella
regione di rifiuto, l’ipotesi nulla H0 viene rifiutata.
Esprimere la decisione statistica con riferimento al
problema che si sta affrontando.
FONDAMENTI DI INFERENZA
40
20
APPROCCIO DEL P-VALUE ALLA VERIFICA DI IPOTESI
Esiste un altro approccio alla verifica di ipotesi: l’approccio
del p-value.
Il p-value rappresenta la probabilità di osservare un valore
della statistica test uguale o più estremo del valore che si
calcola a partire dal campione, quando l’ipotesi H0 è vera.
Un p-value basso porta a rifiutare l’ipotesi nulla H0.
Il p-value è anche chiamato livello di significatività
osservato, in quanto coincide con il più piccolo livello di
significatività in corrispondenza del quale H0 è rifiutata.
In base all’approccio del p-value, la regola decisionale per
rifiutare H0 è la seguente:
Se il p-value è ≥ α, l’ipotesi nulla non è rifiutata.
Se il p-value è < α, l’ipotesi nulla è rifiutata.
FONDAMENTI DI INFERENZA
41
APPROCCIO DEL P-VALUE ALLA VERIFICA DI IPOTESI
Torniamo ancora una volta all’esempio relativo alla
produzione delle scatole di cereali. Nel verificare se il peso
medio dei cereali contenuti nelle scatole è uguale a 368
grammi, abbiamo ottenuto un valore di Z uguale a 1.50 e
non abbiamo rifiutato l’ipotesi, perché 1.50 è maggiore del
valore critico più piccolo –1.96 e minore di quello più grande
+1.96.
Risolviamo, ora, questo problema di verifica di ipotesi
facendo ricorso all’approccio del p-value. Per questo test a
due code, dobbiamo, in base alla definizione del p-value,
calcolare la probabilità di osservare un valore della statistica
test uguale o più estremo di 1.50.
FONDAMENTI DI INFERENZA
42
21
APPROCCIO DEL P-VALUE ALLA VERIFICA DI IPOTESI
Si tratta, più precisamente, di calcolare la probabilità che Z
assuma un valore maggiore di 1.50 oppure minore di –1.50.
In base alla Tavola E.2, la probabilità che Z assuma un
valore minore di –1.50 è 0.0668, mentre la probabilità che Z
assuma un valore minore di +1.50 è 0.9332, quindi la
probabilità che Z assuma un valore maggiore di +1.50 è 1 –
0.9332 = 0.0668. Pertanto il p-value per questo test a due
code è 0.0668 + 0.0668 = 0.1336.
FONDAMENTI DI INFERENZA
43
Legame tra intervalli di confid. e verifica di ipotesi
Finora abbiamo preso in considerazione i due elementi
principali dell’inferenza statistica – gli intervalli di
confidenza e la verifica di ipotesi. Sebbene abbiano una
stessa base concettuale, essi sono utilizzati per scopi
diversi: gli intervalli di confidenza sono stati usati per
stimare i parametri della popolazione, mentre la verifica di
ipotesi viene impiegata per poter prendere delle decisioni
che dipendono dai valori dei parametri.
Tuttavia è importante sottolineare che anche gli intervalli di
confidenza possono consentire di valutare se un parametro
è minore, maggiore o diverso da un certo valore: anziché
sottoporre a verifica l’ipotesi µ=368 possiamo risolvere il
problema costruendo un intervallo di confidenza per la
media µ. In questo caso accettiamo l’ipotesi nulla se il
valore ipotizzato è compreso nell’intervallo costruito, …
FONDAMENTI DI INFERENZA
44
22
Legame tra intervalli di confid. e verifica di ipotesi
… perché tale valore non può essere considerato insolito
alla luce dei dati osservati. D’altronde, l’ipotesi nulla va
rifiutata se il valore ipotizzato non cade nell’intervallo
costruito, perché tale valore risulta insolito alla luce dei dati.
Con riferimento al problema considerato, l’intervallo di
confidenza è costruito ponendo: n=25, X =372.5 grammi, σ
= 15 grammi.
Per un livello di confidenza del 95% (corrispondente al
livello di significatività del test α=0.05), avremo:
X ± Zα / 2 ⋅ σ / n ⇒ 372.5 ± (1.96) ⋅15 / 25 ⇒ 366.6 ≤ µ ≤ 378.4
Poiché l’intervallo comprende il valore ipotizzato di 368
grammi, non rifiutiamo l’ipotesi nulla e concludiamo che
non c’è motivo per ritenere che il peso medio dei cereali
contenuti nelle scatole sia diverso da 368 grammi.
FONDAMENTI DI INFERENZA
45
I test ad una coda
Fin qui abbiamo considerato i cosiddetti test a due code, ad
esempio abbiamo contrapposto all’ipotesi nulla µ=368
grammi l’ipotesi alternativa µ≠368. Tale ipotesi si riferisce a
due eventualità: o il peso medio è minore di 368 oppure è
maggiore di 368. Per questo motivo, la regione critica si
divide nelle due code della distribuzione della media
campionaria.
In alcune situazioni, tuttavia, l’ipotesi alternativa
presuppone che il parametro sia maggiore o minore di un
valore specificato (ci si focalizza in una direzione
particolare). Per esempio, si potrebbe essere interessati
all’eventualità che il peso dei cereali contenuti ecceda i 368
grammi, perché in tal caso, essendo il prezzo delle scatole
basato su un peso di 368 grammi, la società subirebbe
delle perdite. In questo caso si intende stabilire se il peso
medio è superiore a 368 grammi.
FONDAMENTI DI INFERENZA
46
23
I test ad una coda
L’ipotesi nulla e l’ipotesi alternativa in questo caso sono
specificate rispettivamente:
H0: µ = 368 H1: µ >368
La regione di rifiuto in questo caso è interamente racchiusa
nella coda destra della distribuzione della media
campionaria, perché rifiutiamo l’ipotesi nulla H0 solo se la
media è significativamente superiore a 368 grammi.
Quando la regione di rifiuto è contenuta per intero in una
coda della distribuzione della statistica test, si parla di test
a una coda.
Fissato il livello di significatività α, possiamo individuare,
anche in questo caso, il valore critico di Zα.
Nel caso H0: µ=368 contro H1: µ<368 possiamo individuare
il valore critico di Zα come segue.
FONDAMENTI DI INFERENZA
47
I test ad una coda
Come si può osservare dalla tabella e dalla figura, poiché
la regione critica è contenuta nella coda di sinistra della
distribuzione normale standardizzata e corrisponde a
un’area di 0.05, il valore critico lascia alla sua sinistra una
massa pari a 0.05; pertanto tale valore è −1.645 (media di
−1.64 e −1.65).
FONDAMENTI DI INFERENZA
48
24
I test ad una coda
Nell’approccio del p-value al test a una coda, si calcola la
probabilità di ottenere o un valore della statistica test più
grande di quello osservato o un valore più piccolo a
seconda della direzione dell’ipotesi alternativa.
Se la regione di rifiuto risulta contenuta per intero nella
coda di sinistra della distribuzione della statistica test Z,
dobbiamo calcolare la probabilità che Z assuma un valore
minore di Z osservato, ad esempio −3.125. Tale probabilità,
in base alle tavole risulta 0.009.
FONDAMENTI DI INFERENZA
49
Il test di ipotesi t per la media (σ
σ non noto)
In molte applicazioni lo scarto quadratico medio della
popolazione σ non è noto ed è quindi necessario stimarlo
con lo campionarie scarto quadratico medio S.
Se si assume che la popolazione abbia distribuzione
normale allora la media campionaria si distribuisce
secondo una t di Student con (n−1) gradi di libertà.
Statistica t per la verifica d’ipotesi sulla media (σ non noto)
t=
X −µ
S n
Se variabile casuale X non ha una distribuzione normale la
statistica t ha comunque approssimativamente una
distribuzione t di Student in virtù del Teorema del Limite
Centrale.
FONDAMENTI DI INFERENZA
50
25
Il test di ipotesi t per la media (σ
σ non noto)
Per illustrare l’uso del test t si consideri un campione di
fatture per valutare se l’ammontare medio delle fatture è
stato uguale a $120.
1.
H0: µ = 120
H1: µ ≠ 120
2.
α=0.05 e n=12
3.
poiché σ non è noto la statistica test è t con n−1 gradi
di libertà
4.
il test è a due
code e i valori
critici si
determinano
dalla Tav. E3.
FONDAMENTI DI INFERENZA
51
Il test di ipotesi t per la media (σ
σ non noto)
5.
dati i valori delle 12 fatture campionate
108.98 152.22 111.45 110.59 127.46 107.26
93.32 91.97 111.56 75.71 128.58 135.11
si ottiene X = 112.85 e S= 20.80 e quindi
t=
6.
X − µ 112.85 − 120
=
= −1.19
S / n 20.80 / 12
poiché −2.201 < t = −1.19 < +2.201 l’ipotesi nulla non
va rifiutata
FONDAMENTI DI INFERENZA
52
26
Il test di ipotesi Z per la proporzione
In alcuni casi si è interessati a verificare ipotesi su π, la
proporzione di unità nella popolazione che possiedono una
certa caratteristica. A tale scopo, per un campione casuale
estratto dalla popolazione, si deve calcolare la proporzione
campionaria p=X/n. Se il numero di successi X e di
insuccessi (n−X) sono entrambi >5, la distribuzione della
proporzione di successi può essere approssimata dalla
distribuzione normale e, quindi, si può ricorrere alla
statistica Z per la proporzione.
Statistica test Z per la verifica d’ipotesi sulla proporzione
Z=
p −π
π (1 − π ) n
La statistica test Z ha approssimativamente
distribuzione normale standard
FONDAMENTI DI INFERENZA
una
53
Il test di ipotesi Z per la proporzione
Esempio: dato un campione casuale di 899 persone che
lavorano a casa, 369 delle quali sono donne, si è
interessati a stabilire se la proporzione di donne è il 50%,
cioè H0: π=0.5. Si ha quindi p=X/n=369/899=0.41. Fissato
un livello di significatività α=0.05, le regioni di accettazione
e rifiuto sono illustrate in figura (dalle tavole il valore critico
è Z0.025=1.96).
FONDAMENTI DI INFERENZA
54
27
Il test di ipotesi Z per la proporzione
Z=
p −π
0.41 − 0.50
−0.09
=
=
= −5.37
π (1 − π ) n
0.50(1 − 0.50) 899 0.0167
Poiché −5.37 < −1.96 l’ipotesi nulla va rifiutata. Possiamo
quindi concludere che a livello di significatività α=0.05 la
proporzione di donne che lavorano da casa non è pari a
0.50.
FONDAMENTI DI INFERENZA
55
Confronto tra medie di due pop. indipendenti
Consideriamo
due
popolazioni
indipendenti
e
supponiamo di estrarre un campione di ampiezza n1
dalla prima popolazione di ampiezza n2 dalla seconda
popolazione.
Siano µ1 e µ2 le medie che caratterizzano rispettivamente la prima e la seconda popolazione e si assumano
i due scarti quadratici medi σ1 e σ2 come noti.
Si vuole verificare l’ipotesi nulla che le medie delle due
popolazioni (indipendenti) sono uguali tra loro:
H0: µ1 = µ2 (µ1 − µ2 = 0)
contro l’ipotesi alternativa
H1: µ1 ≠ µ2 (µ1 − µ2 ≠ 0)
A questo scopo viene definita la statistica test Z per la
differenza tra le due medie.
FONDAMENTI DI INFERENZA
56
28
Confronto tra medie di due pop. indipendenti
FONDAMENTI DI INFERENZA
57
Confronto tra medie di due pop. indipendenti
Se si assume che i due campioni siano estratti
casualmente ed indipendentemente da due popolazioni
normali la statistica Z ha distribuzione normale.
Se le due popolazioni non hanno distribuzione normale il
test Z può essere utilizzato con ampiezza campionarie
sufficientemente elevate (in virtù del teorema del limite
centrale).
In molti casi le varianze delle due popolazioni non sono
note. Se si assume l’ipotesi di omogeneità della varianze
(σ21=σ22), per verificare se c’è una differenza significativa
tra le medie delle due popolazioni è possibile utilizzare il
test t basato sulle varianze campionarie combinate.
Il test t è appropriato se le popolazioni hanno
distribuzione normale oppure, in caso contrario, se le
ampiezze campionarie sono sufficientemente elevate.
FONDAMENTI DI INFERENZA
58
29
Confronto tra medie di due pop. indipendenti
FONDAMENTI DI INFERENZA
59
Confronto tra medie di due pop. indipendenti
Regione di rifiuto e di accettazione per la differenza tra due
medie utilizzando la statistica test t basata sulle varianze
combinate (test a due code).
Quando l’assunzione dell’omogeneità delle varianze non è
plausibile occorre fare riferimento al test t con varianze
diverse (ricorrendo all’Excel o ad altri software statistici).
FONDAMENTI DI INFERENZA
60
30
Confronto tra medie di due pop. indipendenti
Esempio: confronto tra le vendite settimanali (numero di
pezzi venduti) della BLK cola in due gruppi di supermercati,
dove il primo adotta la collocazione a scaffale mentre il
secondo utilizza uno spazio dedicato
FONDAMENTI DI INFERENZA
61
Confronto tra medie di due pop. indipendenti
FONDAMENTI DI INFERENZA
62
31
Confronto tra medie di due pop. indipendenti
In base al fatto che l’ipotesi alternativa sia nella forma A:
H1:µ1≠µ2 oppure B: H1:µ1<µ2 o C: H1:µ1>µ2 si parla di test ad
una coda e test a due code.
FONDAMENTI DI INFERENZA
63
Intervallo di confidenza per la differenza tra le
medie di due pop. indipendenti
Anziché (o oltre a) sottoporre a verifica l’ipotesi nulla
secondo la quale due medie sono uguali, possiamo
utilizzare l’equazione (10.3) per ottenere un intervallo di
confidenza per la differenza tra le medie µ1 e µ2 delle due
popolazioni:
Intervallo di confidenza per la differenza (µ1−µ2)
( X 1 − X 2 ) − tn1 − n2 −1;α / 2 ⋅ S p2 (1 n1 + 1 n2 ) ≤ µ1 − µ 2 ≤
≤ ( X 1 − X 2 ) + tn1 −n2 −1;α / 2 ⋅ S p2 (1 n1 + 1 n2 )
dove tn1−n2−2;α/2 è il valore critico a cui corrisponde un’area
cumulata pari a (1−α/2) della distribuzione t di Student con
(n1−n2−2) gradi di libertà.
FONDAMENTI DI INFERENZA
64
32
Confronto tra le proporzioni di due popolazioni
Spesso si è interessati a effettuare confronti e ad
analizzare differenze tra due popolazioni con riferimento
alla proporzione di casi con una certa caratteristica
Per confrontare due proporzioni sulla base dei risultati di
due campioni si può ricorrere al test Z per la differenza
tra due proporzioni, la cui statistica test ha distribuzione
approssimativamente normale quando le ampiezza
campionarie sono sufficientemente elevate
Statistica Z per la differenza tra due proporzioni
Z=
( p1 − p2 ) − (π 1 − π 2 )
1 1
p (1 − p ) +
n1 n2
con p =
X1 + X 2
X
X
, p1 = 1 , p2 = 2
n1 + n2
n1
n2
FONDAMENTI DI INFERENZA
65
Confronto tra le proporzioni di due popolazioni
A seconda di come è formulata l’ipotesi alternativa
avremo un test a due code (H1: π1 ≠ π2 (π1−π2 ≠ 0)) o un
test a una coda (ipotesi direzionali: H1: π1 > π2 (π1−π2 >
0) oppure H1: π1 < π2 (π1−π2 < 0)).
Esempio
La catena di alberghi TC Resort è interessata a valutare
se esiste differenza tra la proporzione di clienti che
intendono visitare nuovamente due dei suoi alberghi.
Vengono campionati 227 clienti nel primo albergo e 262
dal secondo di cui 163 si dicono disposti a ritornare nel
primo campione, 154 nel secondo.
Adottando un livello di significatività pari a 0.05 si può
affermare che nei due alberghi esiste una differenza tra
la proporzione di coloro che sono disposti a ritornare?
FONDAMENTI DI INFERENZA
66
33
Confronto tra le proporzioni di due popolazioni
Z= + 3,01 > +1,96 perciò si rifiuta H0 concludendo che le
percentuali sono diverse.
FONDAMENTI DI INFERENZA
67
Intervallo di conf. per la differ. tra due proporzioni
Anziché (o oltre a) sottoporre a verifica l’ipotesi nulla
secondo la quale due proporzioni sono uguali, possiamo
utilizzare la seguente equazione per ottenere un intervallo di
confidenza per la differenza tra le due proporzioni.
Intervallo di confidenza per la differenza tra due proporzioni
( p1 − p2 ) − Zα / 2
≤ ( p1 − p2 ) + Zα / 2
p1 (1 − p1 ) p2 (1 − p2 )
+
≤ (π 1 − π 2 ) ≤
n1
n2
p1 (1 − p1 ) p2 (1 − p2 )
+
n1
n2
FONDAMENTI DI INFERENZA
68
34
Test F per il rapporto tra due varianze
Talvolta si pone il problema di valutare l’ipotesi di
omogeneità delle varianze e a questo scopo è possibile
considerare un test statistico per verificare H0: σ21 = σ22
contro l’ipotesi alternativa H1: σ21 ≠ σ22. Questo test è
basato sul rapporto delle due varianze campionarie:
F = S21 / S22
La statistica test F segue una distribuzione F con (n1−1)
e (n2−1) gradi di libertà rispettivamente a numeratore e a
denominatore.
FONDAMENTI DI INFERENZA
69
Test F per il rapporto tra due varianze
Esempio: determinazione del valore critico superiore FU di
una distribuzione F con 9 e 9 gradi di libertà corrispondente
a un’area nella coda destra pari a 0.025.
Esiste un modo molto semplice per determinare il valore
critico inferiore FL: FL=1/FU*, dove FU* è il valore critico
superiore delle distribuzione F con gradi di libertà invertiti,
cioè (n2−1) a numeratore e (n1−1) a denominatore.
FONDAMENTI DI INFERENZA
70
35
Test F per il rapporto tra due varianze
Regioni di rifiuto e di accettazione per un test F a due code
sull’uguaglianza tra due varianze a un livello di
significatività pari a 0.05, con 9 e 9 gradi di libertà.
Nella verifica di ipotesi sulla omogeneità delle varianze si
ipotizza che le due popolazioni siano normali. La statistica
F non è robusta rispetto a violazioni di questa assunzione.
FONDAMENTI DI INFERENZA
71
Analisi della varianza (ANOVA) ad una via
Finora abbiamo descritto test di ipotesi finalizzati alla
verifica di ipotesi sulla differenza tra parametri di due
popolazioni
Spesso si presenta la necessità di prendere in
considerazione esperimenti od osservazioni relative a
più di due gruppi individuati sulla base di un fattore di
interesse.
I gruppi sono quindi formati secondo i livelli assunti da
un fattore, ad esempio
la temperatura di cottura di un oggetto in ceramica
che assume diversi livelli numerici come 300°,
350°,400°,450° oppure
il fornitore che serve una azienda può assumere
diversi livelli qualitativi come Fornitore 1, Fornitore 2,
Fornitore 3, Fornitore 4.
FONDAMENTI DI INFERENZA
72
36
Analisi della varianza (ANOVA) ad una via
L’analisi della varianza (o ANOVA, ANalysis Of
VAriance) è una tecnica che consente di confrontare da
un punto di vista inferenziale le medie di più di due
gruppi (popolazioni).
Quando i gruppi sono definiti sulla base di un singolo
fattore si parla di analisi della varianza a un fattore o a
una via.
Questa procedura, basata su un test F, è una estensione
a più gruppi del test t per verificare l’ipotesi sulla
differenza tra le medie di due popolazioni indipendenti.
Anche se si parla di analisi della varianza in realtà
l’oggetto di interesse sono le differenze tra medie nei
diversi gruppi e proprio tramite l’analisi della variabilità
all’interno dei gruppi e tra gruppi che siamo in grado di
trarre delle conclusioni sulla differenza delle medie.
FONDAMENTI DI INFERENZA
73
Analisi della varianza (ANOVA) ad una via
La variabilità all’interno dei gruppi è considerata un
errore casuale, mentre la variabilità tra i gruppi è
attribuibile alle differenza tra i gruppi, ed è anche
chiamata effetto del trattamento.
Ipotizziamo che c gruppi rappresentino popolazioni con
distribuzione normale, caratterizzate tutte dalla stessa
varianza e che le osservazioni campionarie siano
estratte casualmente ed indipendentemente dai c gruppi.
In questo contesto l’ipotesi nulla che si è interessati a
verificare è che le medie di tutti gruppi siano uguali tra
loro
H0: µ1 = µ2 = … = µc
contro l’ipotesi alternativa
H1: non tutte le µj sono uguali tra loro (con j=1,…,c)
FONDAMENTI DI INFERENZA
74
37
Analisi della varianza (ANOVA) ad una via
Per verificare le due ipotesi considerate, la variabilità
totale (misurata dalla somma dei quadrati totale – SST)
viene scomposta in due componenti: una componente
attribuibile alla differenza tra i gruppi (misurata dalla
somma dei quadrati tra i gruppi – SSA) e una seconda
componente che si riferisce alle differenze riscontrare
all’interno del gruppi (misurata dalla somma dei quadrati
all’interno dei gruppi – SSW) .
75
FONDAMENTI DI INFERENZA
Analisi della varianza (ANOVA) ad una via
Poiché sotto l’ipotesi nulla si assume che le medie dei
gruppi siano tutti uguali, la variabilità totale SST si
ottiene sommando le differenze al quadrato di ciascuna
osservazione e la media complessiva, indicata con X .
Variabilità totale nell’ANOVA a una via
c
nj
(
SST = ∑∑ X ij − X
c
nj
∑∑ X
dove X =
j =1 i =1
j =1 i =1
n
ij
)
2
c
= media complessiva, n = ∑ n j
j =1
SST è caratterizzata da (n−1) gradi di libertà poiché
ciascuna osservazione Xij viene confrontata con la media
campionaria complessiva X .
FONDAMENTI DI INFERENZA
76
38
Analisi della varianza (ANOVA) ad una via
La variabilità tra gruppi SSA si ottiene sommando le
differenze al quadrato tra le medie campionarie di
ciascun gruppo, X j , e la media complessiva, X , dove
ogni differenza è ponderata con l’ampiezza campionaria
nj del gruppo a cui è riferita.
Variabilità tra gruppi nell’ANOVA a una via
c
nj
dove X j =
(
SSA = ∑ n j X j − X
∑X
i =1
j =1
)
2
ij
media campionaria nel j-esimo campione
nj
Poiché si tratta di confrontare c gruppi, SSA sarà
caratterizzata da (c−1) gradi di libertà.
77
FONDAMENTI DI INFERENZA
Analisi della varianza (ANOVA) ad una via
Infine, la variabilità nei gruppi SSW si ottiene sommando
le differenze al quadrato tra ciascuna osservazione e la
media campionaria del gruppo a cui appartiene.
Variabilità all’interno dei gruppi nell’ANOVA a una via
nj
SSW = ∑∑ ( X ij − X j )
c
2
j =1 i =1
Poiché ciascuno dei c gruppi contribuisce con (nj−1)
gradi di libertà, SSW avrà complessivamente (n−c)=
=∑(nj−1) gradi di libertà.
Dividendo ciascuna somma dei quadrati per i rispettivi
gradi di libertà, si ottengono tre varianze, o medie dei
quadrati – MSA (la media dei quadrati tra gruppi), MSW
(la media dei quadrati all’interno dei gruppi) e MST (la
media dei quadrati totale).
FONDAMENTI DI INFERENZA
78
39
Analisi della varianza (ANOVA) ad una via
Se l’ipotesi nulla è vera e non ci sono differenze
significative tra le medie dei gruppi, le tre medie dei
quadrati – MSA, MSW e MST, che sono esse stesse
delle stime di varianze e rappresentano tutte stime della
varianza globale della popolazione sottostante.
Quindi per verificare l’ipotesi nulla contro l’alternativa si
fa riferimento alla statistica test F per l’ANOVA a una via,
ottenuta come rapporto tra MSA e MSW.
Statistica test F per l’ANOVA a una via
F=
SSA /( n − c) MSA
=
SSW /(c − 1) MSW
Se l’ipotesi nulla è vera, la realizzazione della statistica F
dovrebbe essere approssimativamente 1, mentre se H0
è falsa ci aspettiamo valori significativ. superiori all’unità.
FONDAMENTI DI INFERENZA
79
Analisi della varianza (ANOVA) ad una via
La statistica F ha distribuzione F con (c−1) gradi di
libertà al numeratore e (n−c) gradi di libertà al
denominatore.
Quindi, fissato il livello di significatività α, l’ipotesi nulla
dovrà essere rifiutata se il valore osservato della
statistica test è maggiore del valore critico FU di una
distribuzione F con (c−1) e (n−c) gradi di libertà.
FONDAMENTI DI INFERENZA
80
40
Analisi della varianza (ANOVA) ad una via
I risultati del test F per l’ANOVA vengono solitamente
riportati nella cosiddetta tabella dell’ANOVA.
Nella tabella dell’ANOVA viene solitamente riportato
anche il p-value, cioè la probabilità di osservare un
valore di F maggiore o uguale a quello osservato, nel
caso l’ipotesi nulla sia vera. Come usuale, l’ipotesi nulla
di uguaglianza tra le medie dei gruppi deve essere
rifiutata quando il p-value è inferiore al livello di
significatività scelto.
FONDAMENTI DI INFERENZA
81
Analisi della varianza (ANOVA) ad una via
Esempio: una azienda produttrice di paracadute, vuole
confrontare la resistenza dei paracadute prodotti con
fibre sintetiche acquistate da quattro diversi fornitori.
FONDAMENTI DI INFERENZA
82
41
Analisi della varianza (ANOVA) ad una via
Fissiamo α=0.05 e identifichiamo nelle tavole il valore
critico di interesse.
FONDAMENTI DI INFERENZA
83
Analisi della varianza (ANOVA) ad una via
Poiché il valore osservato della statistica test è F=3.46<
3.24=FU l’ipotesi nulla deve essere rifiutata e si conclude
che la resistenza media dei paracadute varia in modo
significativo a seconda del fornitore.
FONDAMENTI DI INFERENZA
84
42
Analisi della varianza (ANOVA) ad una via
Procedura di Tukey-Cramer
Quando si rifiuta l’ipotesi nulla del F per l’ANOVA, viene
stabilito che ci sono almeno due medie significativamente diverse tra loro.
Per identificare quali sono i gruppi che effettivamente
differiscono tra loro si deve utilizzare una ulteriore
procedura che rientra nei cosiddetti metodi dei confronti
multipli.
Tra questi metodi, la procedura di Tukey-Cramer
consente di effettuare simultaneamente confronti a due a
due tra tutti i gruppi. A questo scopo si deve innanzi tutto
calcolare c×(c−1)/2 differenze tra le medie campionarie
di tutti i gruppi X j − X j(con
j ≠ j′), quindi calcolare il range
'
critico (ampiezza critica) della procedura di TukeyCramer.
FONDAMENTI DI INFERENZA
85
Analisi della varianza (ANOVA) ad una via
Procedura di Tukey-Cramer
Se la differenza tra due medie campionarie è superiore
al range critico, le corrispondenti medie dei gruppi
(popolazioni) sono dichiarate significativamente diverse
a livello di significatività α.
Calcolo del range critico per la procedura di Tukey-Cramer
Range critico = QU
MSW
2
1
1
+
nj nj'
dove QU è il valore critico superiore della distribuzione del
range studentizzato con c gradi di libertà al numeratore e
n−c gradi di libertà al denominatore.
FONDAMENTI DI INFERENZA
86
43
Analisi della varianza (ANOVA) ad una via
Esempio della procedura di Tukey-Cramer per il caso dei
paracadute.
FONDAMENTI DI INFERENZA
87
Analisi della varianza (ANOVA) ad una via
Procedura di Tukey-Cramer
FONDAMENTI DI INFERENZA
88
44
Analisi della varianza (ANOVA) ad una via
Assunzioni alla base del test F per l’ANOVA a una via
Prima di applicare un test di ipotesi è sempre necessario
valutare se le assunzioni di base del test possono o mene
essere ragionevolmente soddisfatte. Le ipotesi alla base
del test F per l’ANOVA a una via sono essenzialmente tre:
casualità e indipendenza;
normalità;
omogeneità delle varianze.
L’ultima ipotesi stabilisce che le varianze nei gruppi sono
tra loro uguali (σ21 = σ22 = … = σ2c). Nel caso di campioni
con ampiezza simile le inferenze basate sulla
distribuzione F non sono molto influenzate da eventuali
differenze tra varianze, al contrario se le ampiezze sono
diverse tra loro il problema potrebbe essere serio.
FONDAMENTI DI INFERENZA
89
Analisi della varianza (ANOVA) ad una via
Test di Levene per l’omogeneità delle varianze
Questa procedura inferenziale è stata sviluppata per
verificare l’ipotesi nulla H0: σ21 = σ22 = … = σ2c contro
l’ipotesi alternativa H1: non tutte le varianze sono uguali.
Per verificare tale ipotesi si calcola la differenza in valore
assoluto tra ogni osservazione e la mediana campionaria
del gruppo di appartenenza e su questi dati si conduce
l’ANOVA a una via.
Per l’esempio dei paracadute si considera:
FONDAMENTI DI INFERENZA
90
45
Analisi della varianza (ANOVA) ad una via
Test di Levene per l’esempio dei paracadute
FONDAMENTI DI INFERENZA
91
Test Chi-quadrato per la differenza tra 2 proporzioni
Il problema della verifica di ipotesi sulla differenza tra
due proporzioni (test Z) può essere affrontato anche con
una procedura alternativa basata su una statistica test la
cui distribuzione tende ad approssimarsi con una
distribuzione chi-quadrato (χ
χ2). I risultati ottenuti
saranno del tutto equivalenti a quelli dalla statistica Z
Se siamo interessati a confrontare le proporzioni di casi
che presentano una certa caratteristica in due gruppi
indipendenti possiamo costruire una tabella a doppia
entrata (o di contingenza) di dimensioni 2×2 nella
quale sono riportati il numero (o le percentuali) di
successi e insuccessi nei due gruppi
FONDAMENTI DI INFERENZA
92
46
Test Chi-quadrato per la differenza tra 2 proporzioni
Ad esempio
93
FONDAMENTI DI INFERENZA
Test Chi-quadrato per la differenza tra 2 proporzioni
Per verifica l’ipotesi nulla secondo cui non c’è differenza
tra le due proporzioni
H0: π1 = π2
contro l’alternativa
H1: π1 ≠ π2
si può considerare la statistica χ2
Statistica test χ2 per la differenza tra due proporzioni
χ =
2
∑
tutte le celle
( f0 − fe )
2
(11.1)
fe
La statistica χ2 si ottiene calcolando per ogni cella della
tabella di contingenza la differenza al quadrato fra la
frequenza osservata (f0) e quella attesa (fe), divisa per fe,
e sommando quindi il risultato ottenuto per ogni cella
FONDAMENTI DI INFERENZA
94
47
Test Chi-quadrato per la differenza tra 2 proporzioni
Per calcolare la frequenza attesa si deve tener conto del
fatto che se l’ipotesi nulla è vera la proporzione di
successi e insuccessi è la stessa nei due gruppi e le
proporzioni campionarie dovrebbero differire solo per
effetto del caso. In questo caso per stimare il parametro
π conviene utilizzare una combinazione delle due
frequenze campionarie, indicata con p
Calcolo della proporzione globale di successi
p=
X1 + X 2 X
=
n1 + n2
n
(11.2)
Per calcolare la frequenza attesa fe per le celle relative al
successo (prima riga) si dovrà moltiplicare l’ampiezza
campionaria n1 e n2 (totali di colonna) per p
FONDAMENTI DI INFERENZA
95
Test Chi-quadrato per la differenza tra 2 proporzioni
Analogamente, per calcolare la frequenza attesa fe per le
celle relative all’insuccesso (seconda riga) si dovrà
moltiplicare l’ampiezza campionaria n1 e n2 di ciascuno
dei due gruppi per (1− p )
La statistica test introdotta nell’equazione (11.1) si
distribuisce
approssimativamente
secondo
una
distribuzione chi-quadrato con 1 grado di libertà
Fissato α, l’ipotesi nulla dovrà essere rifiutata se il valore
osservato della statistica χ2 è maggiore del valore critico
χ2U di una distribuzione χ2 con 1 grado di libertà
FONDAMENTI DI INFERENZA
96
48
Test Chi-quadrato per la differenza tra 2 proporzioni
FONDAMENTI DI INFERENZA
97
Test Chi-quadrato per la differenza tra 2 proporzioni
FONDAMENTI DI INFERENZA
98
49
Test Chi-quadrato per la differenza tra 2 proporzioni
FONDAMENTI DI INFERENZA
99
Test Chi-quadrato per la differenza tra C proporzioni
Il test χ2 opportunamente generalizzato può essere
utilizzato per confrontare le proporzioni di più popolazioni
indipendenti. Supponiamo di voler verificare l’ipotesi
nulla secondo cui le proporzioni di c popolazioni sono
uguali
H0: π1 = π2 = … = πc contro l’alternativa
H1: non tutte le πj sono uguali tra loro (con j=1,…,c)
Per risolvere questo problema dovremo costruire una
tabella di contingenza di due righe (successo e
insuccesso) che avrà un numero di colonne pari a c
La statistica test sarà la stessa dell’equazione (11.1),
dove la frequenza attesa viene calcolata dalla stima p di
π = π1 = π2 = … = πc che in questo caso si ottiene come
combinazione delle c frequenze campionarie
FONDAMENTI DI INFERENZA
100
50
Test Chi-quadrato per la differenza tra C proporzioni
Calcolo della proporzione globale di successi
p=
X 1 + X 2 + ... + X c X
=
n1 + n2 + ... + nc
n
(11.3)
La statistica test dell’equazione (11.1) si distribuisce
approssimativamente secondo una distribuzione chiquadrato con (2−1)×(c−1)=(c−1) gradi di libertà
Fissato α, l’ipotesi nulla dovrà essere rifiutata se il valore
osservato della statistica χ2 è maggiore del valore critico
χ2U di una distribuzione χ2 con (c−1) gradi di libertà
101
FONDAMENTI DI INFERENZA
Test Chi-quadrato per la differenza tra C proporzioni
Esempio: tabella di contingenza
soddisfazione dei clienti di 3 alberghi
2x3
relativa
alla
Frequenze attese
FONDAMENTI DI INFERENZA
102
51
Test Chi-quadrato per la differenza tra C proporzioni
Calcolo della statistica test χ2 per l’esempio relativo alla
soddisfazione dei clienti di 3 alberghi
Regione di rifiuto e di accettazione del test χ2 (2 gradi di
libertà) per la differenza tra tre proporzioni al livello di
significatività α=0.05
FONDAMENTI DI INFERENZA
103
Test Chi-quadrato per la differenza tra C proporzioni
Foglio di Microsoft Excel con i calcoli necessari per
calcolare valore critico e p-value (test chi-quadro, 3 gruppi)
FONDAMENTI DI INFERENZA
104
52
Test Chi-quadrato per l’indipendenza
Se si considera una tabella di contingenza con r righe c
colonne il procedimento del test χ2 può essere
generalizzato per verificare l’indipendenza tra due
variabili categoriali X e Y
In questo contesto le ipotesi nulla e alternativa sono
H0: le due variabili categoriali sono indipendenti ( X ⊥ Y )
(non sussistono relazioni tra le due variabili)
H1: le due variabili categoriali sono dipendenti ( X ⊥ Y )
(sussiste una relazione tra le due variabili)
Il test si basa ancora una volta sull’equazione (11.1)
2
f0 − f e )
(
2
χ = ∑
fe
tutte le celle
La regola decisionale consiste nel rifiutare H0 se il valore
osservato della statistica χ2 è maggiore del valore critico
χ2U della distribuzione χ2 con (r−1)×(c−1) gdl
FONDAMENTI DI INFERENZA
105
Test Chi-quadrato per l’indipendenza
Pure se presentano delle analogie, la differenza
fondamentale tra il test chi-quadrato per le proporzioni e
per
l’indipendenza
riguarda
lo
schema
di
campionamento:
Nel confronto tra proporzioni siamo di fronte a
campioni estratti da popolazioni indipendenti
Nel test di indipendenza abbiamo un solo campione
su cui rileviamo due variabili qualitative che possono
assumere r e c modalità distinte
Nel caso di test chi-quadrato per l’indipendenza è
possibile semplificare il calcolo delle frequenze attesa
applicando la seguente regola:
fe =
totale di riga × totale di colonna
n
FONDAMENTI DI INFERENZA
106
53
Test Chi-quadrato per l’indipendenza
Esempio: tabella della frequenze osservate con
riferimento al principale motivo di insoddisfazione e
all’albergo
Frequenze attese
FONDAMENTI DI INFERENZA
107
Test Chi-quadrato per l’indipendenza
Calcolo della statistica χ2 per il test di indipendenza
FONDAMENTI DI INFERENZA
108
54
Test Chi-quadrato per l’indipendenza
Regione di rifiuto e di accettazione del test χ2 per
l’indipendenza nell’esempio sulla soddisfazione dei clienti
(al livello di significatività 0.05 con 6 gradi di libertà)
FONDAMENTI DI INFERENZA
109
Test Chi-quadrato per l’indipendenza
Foglio di Microsoft Excel con i calcoli necessari per la
verifica dell’ipotesi di indipendenza tra motivo di
insoddisfazione e albergo
FONDAMENTI DI INFERENZA
110
55