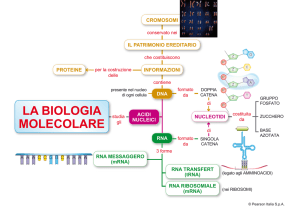
CODICE GENETICO
E
TRADUZIONE
Dogma centrale della Biologia molecolare
(Francis Crick):
Flusso dell’informazione genetica:
schematizzato in figura.
Gli esperimenti su Neurospora crassa (muffa del pane) hanno rivelato che i geni
possono codificare per gli enzimi (esperimenti di Beadle eTatum).
N.c. può riprodursi in terreno minimo di coltura: contiene zucchero, sali
inorganici e la vit. Biotina.
Beadle eTatum con raggi X hanno indotto mutazioni geniche
ceppi mutanti che avevano perso la capacità di sopravvivere in terreno minimo,
benchè in grado di crescere su un terreno completo addizionato con diversi
amminoacidi, nucleosidi e vitamine!
Quindi i mutanti avevano perso la capacità di sintetizzare alcuni Aa o vitamine e
potevano sopravvivere solo in terreni addizionati di ciò!
Beadle eTatum trasferirono i mutanti in una serie di ≠ mezzi di coltura, ciascuno
contenente in aggiunta un singolo Aa o 1 vitamina
individuati una serie di
mutanti ciascuno impossibilitato a sintetizzare un particolare Aa o 1 vit.
Poiché gli Aa e le vit. sono sintetizzati con ≠ vie metaboliche Beadle eTatum
cercarono di identificare il passaggio difettivo di ciascuna via!
Aggiunsero quindi al terreno minimo i precursori metabolici di un Aa o vitamina:
trovarono che ciascuna mutazione corrispondeva alla inattivazione di un unico
enzima che catalizzava un passaggio responsabile della sintesi di uno specifico
Aa
formularono l’ipotesi della corrispondenza diretta fra un gene – un
enzima
Pauling scoprì mediante l’elettroforesi, che l’emoglobina delle cellule falciformi
migrava con una velocità diversa rispetto all’emoglobina normale, suggerendo
che le due proteine differiscono nella carica elettrica.
Esperimento di Ingram
Ingram: Una mutazione genica è in grado di
modificare un singolo Aa!
UN GENE CODIFICA PER UNA SEQUENZA
AMMINOACIDICA (per la struttura quaternaria delle
proteine).
IN EUCARIOTI SEQUENZE CODIFICANTI E NON
C. all’interno di un gene
Alcuni geni codificano per RNA e non per polipeptidi
Proflavina: mutageno (colorante all’acridina) causa delezioni o addizioni di basi:
MUTAZIONI FRAMESHIFT.
Crick e Brenner: stesso tipo di risposte su fagi T4.
Nirenberg e Matthei utilizzarono sistemi acellulari per lo studio della sintesi
proteica.
•Mescolarono ribosomi isolati, amminoacidi, una fonte di energia ed un estratto
cellulare contenente i componenti solubili del citoplasma.
•L’aggiunta di RNA aumentava la velocità della sintesi proteica
•Ma come le molecole di RNA aggiunte funzionavano come messaggi
determinando la sequenza Aa?
•Usarono la polinucleotide fosforilasi che produce molecole sintetiche di RNA
con composizione in basi predeterminata
•Costruirono poliU e ottennero polifenilalanina e così via…
•Khorana costruì un mRNA sintetico con sequenza alternata: UAUAUA… e
ottenne un poliAa: contenente solo tirosina e leucina alternati.
•Ulteriori studi portarono a decifrare il codice genetico:
RNA
PROTEINE
•Enzimi
•fattori trascrizione
•proteine strutturali
•proteine contrattili
•trasporto; pompe; canali ionici
•ormoni - fattori di crescita
•recettori
•deposito
•anticorpi
•tossine
PROTEINE
Struttura chimica
•Proteine semplici
•Proteine coniugate (con gruppi prostetici)
Modificazione
post-traduzionale
apoproteine
PROTEINE
Concatenamento di 20 div. Aa
R
H2N
C
H
COOH
Negli mRNA che codificano per
poche proteine rare, la molecola
di mRNA si ripiega in modo da
legare specifici tRNA:
•UGA è utilizzato per specificare
incorporazione di selenocisteina.
•UAG: pirrolisina.
TOTALE 22 Aa
Corrispondente eucariotico: 80S: 60S + 40S.
•Le cellule contengono 20 ≠ Aa-tRNA-sintetasi
•Quando per un determinato Aa esistono più tRNA,
la stessa Aa-tRNA- sintetasi li riconosce tutti
•Le Aa-tRNA-sintetasi riconoscono i nucleotidi
localizzati in almeno 2 ≠ regioni della molecola di
tRNA
•Alcune Aa-tRNA-sintetasi riconoscono gli Aa non
corretti eventualmente legati ai tRNA.
Segmento 5’ non tradotto
(da ~10 a più di 200 nucleotidi)
Segmento 3’ non tradotto
(da ~50 a più di 200 nucleotidi)
Regola la stabilità dei messaggeri.
Sequenza codificante tradotta
5’
3’
5’ cap
…….
AUG
Codon di inizio
T
...
AAUAAA
...
Coda di poli(A)
OH
Codon di terminazione
(UGA, UAA o UAG
(da ~30 a più di 200 nucleotidi)
Complessata con una proteina
che è vitale per la cellula.
Il CAP 5’:
1.
Facilità la fase di inizio
2.
E’ un segnale riconosciuto
dai complessi del poro
3.
Protegge gli mRNA dalle
ribonucleasi
Caratteristiche strutturali di un mRNA eucariotico. La coda di poli(A) non è presente in alcuni
mRNA eucariotici; la struttura cap 5’ non è presente in alcuni mRNA di virus che infettano cellule
eucariotiche.
La fase d’inizio negli eucarioti coinvolge
•un gruppo diverso di fattori di inizio (eIF)
•Una modalità di assemblaggio del complesso d’inizio leggermente ≠
•Un particolare tRNA iniziatore che trasporta la metionina
- eIF2 + GTP si unisce al tRNA iniziatore carico prima che il tRNA si leghi allla
subunità ribosomiale minore insieme ad altri fattori d’inizio
- Il complesso risultante si lega all’estremità 5’ dell’mRNA, riconoscendo il
CAP al 5’
- In seguito al legame di un mRNA, la subunità ribosomiale minore con il tRNA
iniziatore a rimorchio, scivola lungo l’mRNA e normalmente inizia la traduzione a
livello del primo AUG che incontra.
- ACCAUGG
- Quando il tRNA iniziatore si appaia con il codone d’inizio, la subunità ribosomiale
maggiore si unisce al complesso.
Meccanismi
che
promuovono
distruzione degli mRNA difettivi:
la
•la degradazione mediata da mutazioni non
senso [distinzione tra i codoni di stop normali
e quelli prematuri è effettutata sulla base della
loro relazione spaziale con il complesso di
giunzione degli esoni (EJC)] e
•la degradazione per assenza di stop (un
complesso enzimatico di degradazione si lega
al sito A vuoto del ribosoma e degrada mRNA
difettivo)
Nei batteri:
Quando la traduzione si arresta alla fine di un
mRNA privo di codone di stop: tmRNA si lega
al sito A e dirige l’aggiunta di una dozzina di
Aa: sequenza segnale per la degradazione
della proteina!
insulina
Polipeptide lungo circa 30 Aa
La sequenza segnale (15-30 Aa)
contiene:
• regione N-terminale carica
positivamente → promuove
l’interazione con l’esterno idrofilico
della membrana del RE
•Una regione centrale idrofobica →
può favorire l’interazione con
l’interno lipidico della membrana
• una regione polare vicino al sito di
taglio proteolitico.
SRP: particella di riconoscimento
del
segnale
all’estremità
Nterminale
Dopo che i polipeptidi sono stati rilasciati nel lume del RE, si ripiegano per
assumere la loro struttura terziaria definitiva e, in alcuni casi, si associano con altri
polipeptidi (struttura quaternaria).
Il ripiegamento è facilitato dagli chaperoni molecolari.
Chaperone BiP (binding protein) della famiglia chaperoni Hsp70, si lega alle
regioni idrofobiche delle catene polipeptidiche (particolarmente a quelle ricche di
triptofano, fenilalanina e leucina).
Negli eucarioti, la formazione di ponti disolfuro è limitata alle proteine
sintetizzate nel RE.
Il lume del RE contiene l’enzima disolfuro isomerasi.
Le glicoproteine sintetizzate nel RE, possono essere ulteriormente glicosilate
nel complesso di Golgi quindi smistate e distribuite verso altre
localizzazioni (sequenze segnale, es: mannosio-6-fostato per enzimi
lisosomiali; sequenza KDEL (Lys-Asp-Glu-Leu) all’estremità C-terminale per le
proteine con destinazione finale RE).
L’inserzione delle proteine integrali di membrana utilizza
sequenze di stop del trasferimento:
•La sequenza serina-lisina-leucina
(SKL)
vicino
al
C-terminale,
indirizza le proteine ai perossisomi
(dopo la traduzione);
•Il
segnale
di
localizzazione
nucleare verso i pori nucleari:
nucleo.
•Per mitocondri e cloroplasti:
sequenza di transito all’estremità Nterminale (Aa idrofobici e idrofilici).
TOM, TIM, TOC, TIC: traslocasi