LA SINTESI PROTEICA
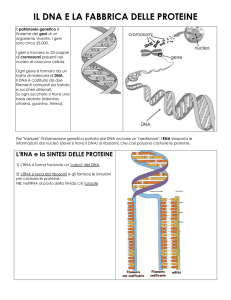
La sintesi proteica è il processo che porta alla formazione delle proteine utilizzando le informazioni
contenute nel DNA.
Nelle sue linee fondamentali questo processo è identico in tutte le forme di vita, sia eucarioti che
procarioti.
Come vedremo, il processo comincia nel nucleo (negli eucarioti) e termina nel citoplasma o nel
reticolo endoplasmatico ruvido.
LE MOLECOLE CHE INTERVENGONO IN TALE PROCESSO SONO:
1) DNA in cui sono contenute le “istruzioni” per sintetizzare le diverse proteine.
Ogni “porzione” di DNA che codifica per una specifica proteina è detta gene.
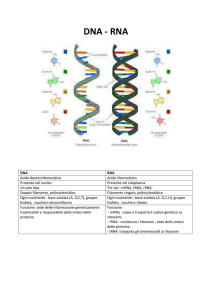
2) Nella sintesi proteica interviene un altro acido nucleico, l’RNA, presente in 3 forme diverse
(ma a filamento singolo):
-
l’RNA messaggero (mRNA ) è una singola catena lineare di RNA che fa da tramite tra il
nucleo e il citoplasma. Contiene una copia “in negativo” del gene.
-
l’RNA ribosomale (rRNA) costituente principale (insieme ad alcune proteine) dei ribosomi.
-
l’RNA transfer (tRNA ) è una particolare catena di RNA che viene rappresentato
bidimensionalmente come un trifoglio (vedi figura). Agisce come un adattore. Vi è un tRNA
per ogni amminoacido.
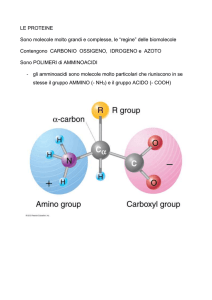
3) Gli amminoacidi cioè i “mattoncini” che, assemblati in sequenza, costituiranno le proteine.
Tutte le nostre proteine sono costituite da solo 20 tipi di amminoacidi, un po’ come tutte le
parole del nostro vocabolario sono formate utilizzando 21 lettere dell’alfabeto.
Una sequenza di amminoacidi, come quella riporta qui in basso, è un POLIPEPTIDE.
Le proteine sono polipeptidi generalmente molto lunghi e con un organizzazione anche
molto complessa.
4) Le “fabbriche” cellulari di proteine sono i ribosomi, piccoli organuli costituiti da due sub
unità fatte di rRNA e proteine .
Le fasi della sintesi proteica sono 2:
-
La Trascrizione (che, negli eucarioti, avviene nel nucleo), nella quale la doppia elica di
una porzione di DNA viene svolta e aperta da un enzima, la RNA-polimerasi, e che inizia,
utilizzando uno dei due filamenti come stampo, a costruire una molecola complementare
di mRNA.
Esempio di mRNA completare al DNA
La catena di RNA così formata è una sorta di impronta “in negativo” del gene da cui si è
generato e migrerà verso i ribosomi liberi nel citoplasma o verso quelli attaccati al reticolo
endoplasmatico rugoso, portando le istruzioni per la sintesi della proteina.
-
La Traduzione (che avviene sui ribosomi) dove l’informazione nel mRNA è tradotta nella
struttura primaria delle proteine, che vedremo, nel dettaglio, più avanti.
IL CODICE GENETICO
Ma come si fa a passare dal “linguaggio” degli acidi nucleici che utilizza 4 “lettere”, cioè i 4 acidi
nucleici (adenina, timina, guanina e citosina) al “linguaggio” delle proteine che utilizza 20 “lettere”,
cioè i 20 amminoacidi?
Certo non può esserci una corrispondenza 1:1, cioè non può corrispondere ad ogni acido
nucleico un amminoacido
Ma non è neanche possibile associare un amminoacido ad una coppia di basi azotate, in
quanto, in tal caso, le possibili coppie di basi sono 42 = 16 (AA, UU, CC, GG, AU, AC, AG, UA,
UC, UG, CA, CG, CU, GA, GU, GC) troppo poche per poter codificare i 20 amminoacidi
Appare evidente, quindi, che il codice utilizzato si basa su triplette di basi azotate, infatti
43 = 64 combinazioni sono più che sufficienti per codificare i 20 amminoacidi
ED ECCO IL CODICE GENETICO:
Ovviamente è ridondante: ci sono
cioè più triplette che codificano per
lo stesso amminoacido
Ci sono anche le triplette di inizio
(AUG) e di stop (UAA, UAG e UGA)
che determinano l’inizio e la fine di
una sequenza polipeptidica
Ogni tripletta di basi sull’RNA
è anche detta codone
LA TRADUZIONE
La traduzione è lo stadio della sintesi proteica in cui le istruzioni portate dall'm-RNA vengono
tradotte nella sequenza corretta di amminoacidi per formare una proteina.
La traduzione ha luogo nel ribosoma (formato da r-RNA e proteine), composto da due subunità:
quella piccola contiene un sito di legame per l'm-RNA; quella grande ha due siti di legame per due
molecole di t-RNA e un sito che catalizza la formazione del legame peptidico tra due amminoacidi
adiacenti.
Ogni molecola di t-RNA è specifica per un unico amminoacido ed è in grado di riconoscere sia
l'amminoacido che deve trasportare, sia il codone complementare di m-RNA associato al
ribosoma.
La traduzione ha inizio quando due codoni del filamento di m-RNA si legano alla subunità piccola
di un ribosoma. Il primo codone è la tripletta di "inizio lettura" AUG, alla quale corrisponde
l'amminoacido metionina; il secondo codifica il primo vero amminoacido della proteina.
I due t-RNA corrispondenti a quei codoni, si legano alla subunità grande (sul sito P, cioè il primo, e
sul sito A, cioè il secondo) e si forma un legame peptidico tra i due amminoacidi trasportati.
Quando il primo tRNA si stacca dal ribosoma, il secondo tRNA si sposta sul sito P, trascinando la
piccola catena di amminoacidi, facendo scorrere il ribosoma sull’mRNA. Un terzo tRNA occuperà il
sito A e il processo si ripete fino ai codoni di stop.