Alcune informazioni pratiche
Testi di riferimento
Norman
GR, Streiner DL, Biostatistica: quello che
avreste voluto sapere, Casa Editrice Ambrosiana,
Milano, 2000
Edizione originale: Biostatistics, The bare
essentials, BC Decker, Hamilton
Pagano M, Gavreau K, Fondamenti di Biostatistica,
Gnocchi Ed. 1994
Edizione originale: Principles of Biostatistics,
Duxbury
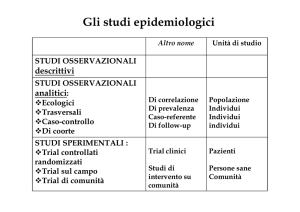
La natura dei dati e della statistica
Statistica descrittiva ed inferenziale
Prof. Giovanni Capelli
Cattedra di Igiene
Dipartimento di Scienze Umane,
Sociali e della Salute
Università di Cassino e L.M.
Recapiti
[email protected]
Blackboard
Natura della Statistica
What is
Statistics?
Statistica descrittiva
ha
a che fare con la presentazione, organizzazione
e sintesi dei dati
Tabelle, grafici, indici di sintesi
Statistica Inferenziale
ci
L. Gonick, W. Smith,
“The cartoon guide to statistics”,
Harper Perennial, 1993
permette di generalizzare i risultati ottenuti
dai dati raccolti in un piccolo campione ad una
popolazione più ampia
Stima di parametri
Test di ipotesi
1
Obiettivi della analisi statistica (1)
Descrivere i dati
Obiettivi della analisi statistica (2)
stabilire
quanto è verosimile che esista una
relazione tra le variabili
cioè, fare inferenze sulla popolazione da cui
i dati sono tratti
condensare
anche un gran numero di dati
rilevati in pochi valori riassuntivi, capaci di
indicare importanti proprietà della popolazione
oggetto di indagine
Classificare
descrivere
ed analizzare gruppi definiti sulla
base di caratteristiche comuni misurate dalle
variabili rilevate
Esplorare le relazioni
definire
rilevate
i dati raccolti per prevedere i valori
che ci si aspetta di trovare nella popolazione
oggetto di indagine in particolari condizioni
e descrivere le relazioni tra le variabili
Tutti gli obiettivi elencati sono sistemi
differenti per affrontare lo stesso problema:
LA
VARIABILITA
Infatti:
le caratteristiche d interesse variano della
popolazione studiata
le relazioni tra variabili variano nella popolazione
studiata
Il tutto varia da popolazione a popolazione, e nella
stessa popolazione, nel tempo
es. età, presenza di malattie croniche, durata della degenza, ecc.
Fare previsioni
utilizzare
Generare ipotesi
grazie
alle 5 fasi precedentemente descritte le
variabili divengono meglio comprensibili, ed è
possibile che questo porti a proporre nuove
idee a proposito della popolazione indagata
Obiettivi della analisi statistica (3)
Valutare ipotesi
Obiettivi della analisi statistica (4)
L obiettivo primario di pressochè
tutti i metodi statistici è:
i d e n t i f i c a r e
e comprendere la
presenza e il ruolo di comportamenti
sistematici tenendo conto degli effetti
di questa variabilità
es. età ->presenza di malattie croniche
e tutta questa variabilità porta un certo grado
di incertezza in ogni analisi
2
Dati Elementari
Dati sintetici
il DATO è una descrizione originaria e non
interpretata di un evento
è
la materia prima del processo di costruzione
delle informazioni
è costituito da gruppi di simboli (lettere, numeri,
caratteri speciali) che rappresentano quantità,
azioni, cose, ecc.
il DATO INIZIALE o ELEMENTARE è la
rappresentazione oggettiva di fenomeni o eventi
reali
i dati sintetici si possono considerare
equivalenti ad un “prodotto semilavorato
intermedio” di un processo produttivo
il
processo di sintesi che permette di generare un
dato sintetico a partire da più dati elementari
modifica il potenziale informativo iniziale
Informazioni
E’ INFORMAZIONE tutto ciò che produce
variazione nel patrimonio conoscitivo di un
soggetto
Il
concetto di informazione fa riferimento al suo
percettore, al suo utilizzatore
L’ INFORMAZIONE è un dato che è stato
sottoposto ad un processo che lo ha reso
significativo per il destinatario e realmente
importante per il suo processo decisionale presente
o futuro
L’ INFORMAZIONE è relativa: sussiste solo se
destinata a qualcuno per qualche scopo
Decisioni
Definizione: una particolare classe di
INFORMAZIONI che ha lo scopo di provocare
AZIONI determinate;
Perchè ciò avvenga, si richiede:
la definizione di una SITUAZIONE FINALE da
raggiungere
la definizione di una SITUAZIONE PRESENTE, che è
quella riferita dal sistema informativo
L’identificazione delle AZIONI DA COMPIERSI in
conformità ad una “politica” prestabilita
L’uso delle informazioni appare finalizzato all’attività
decisionale;
3
Statistica:
nomenclatura
Statistica Descrittiva:
Inquadramento delle tipologie di dati e analisi
esplorativa
Modalità
o valore o dato
(es. azzurro)
Unità statistica
(es. 1 persona)
CAMPIONE (es. alcuni impiegati)
Carattere statistico
o variabile
(es. colore del vestito)
Proprietà di un campione casuale
Ogni unità della popolazione ha la
stessa probabilità di essere scelta
La scelta di una unità non influenza
la selezione delle altre
POPOLAZIONE (es. tutti gli impiegati)
Statistica:
nomenclatura
La rappresentazione
interna dei dati
Modalità
o valore o dato
Unità statistica
(es. 1 regione)
CAMPIONE (es. 1 anno)
Carattere statistico,
Variabile
Modalità,
Dato
(es. 3,5 milioni)
3 500 000
Unità statistica,
Record
Carattere statistico
o variabile
(es. numero abitanti)
POPOLAZIONE (es. Italia in diversi anni)
Dati aggregati
4
Un esempio: tipo di intervento in
cardiochirugia infantile e danno cerebrale
Una grandezza fisica
può essere definita come
l insieme delle operazioni che
servono a realizzare una misura
. describe
Contains data from circarrest2.dta
obs:
171
vars:
8
17 May 2002 15:35
size:
6,156 (99.2% of memory free)
------------------------------------------------------------------------------storage display
value
variable name
type
format
label
variable label
------------------------------------------------------------------------------vsd
float %9.0g
Ventricular Septal Defect
(1=yes; 0=no)
dhca
float %9.0g
Deep Hypothermic Circulatory
Arrest (1=yes; 0=low-flow
bypass)
minutes
float %9.0g
Duration of circulatory arrest
(minutes)
birthwt
float %9.0g
Birth weight (grams)
age
float %9.0g
Age at surgery (days)
clinseiz
float %9.0g
Clinical Seizures within 7
postoperative days
eegseiz
float %9.0g
EEG seizure activity within 48
postoperative hours
pdi
float %9.0g
Psychomotor Development Index
at age 1
-------------------------------------------------------------------------------
Da:
Stevens, 1951
Una
importante causa di instabilità dei dati
epidemiologici è la incapacità degli operatori sul
campo a seguire protocolli standardizzati di misura.
Un metodo di misura può essere considerato
protocollo standardizzato soltanto se sono
soddisfatte due condizioni:
devono esistere istruzioni per l uso del metodo
comprensibili anche ad altri ricercatori che
intendano seguirlo
deve esistere una dimostrazione (quanto meno
uno studio pilota) che le misure che risultano dal
metodo sono riproducibili
Definiamo misura il processo di collegare CONCETTI
ASTRATTI ad INDICATORI EMPIRICI
questa definizione pone enfasi sulla componente teorica
del processo di misura e pone l accento sul fatto che ciò
che si misura
non è la variabile di reale interesse
ma un suo qualche indiretto indicatore
La variabile di reale interesse non può essere misurata
direttamente o è impossibile da definire
• Amstrong, White, Saracci, 1992
Concetti astratti ed indicatori empirici:
LE REGOLE
Anderson e Mantel, 1983
La misura è l assegnazione di NUMERI ad oggetti ed eventi
in conformità a REGOLE definite
Zeller e Carmines, 1980
1) “A comparison of the perioperative neurologic effects of hypothermic circulatory arrest versus low-flow cardiopulmonary bypass in
infant heart surgery” J.W.Newburger and coll. NEJM 329:1057-1064 (October 7),1993
2) “Developmental and neurologic status of children after heart surgery with Hypothermic Circulatory Arrest or Low-Flow
Cardiopulmonary By-pass” D.C. Bellinger and coll. NEJM 332: 549-555 (March 2), 1995
MISURA
segni/sintomi, diagnosi, codifica
Segni, sintomi e reperti di laboratorio sono
indicatori empirici dell’ esistenza di uno
stato di malattia
il
medico li sintetizza in una “diagnosi” astratta
ma il suo fine è in genere clinico
definire una possibile terapia nel singolo paziente: a questo
scopo l’eccessiva categorizzazione può essere
controproducente
ai
fini epidemiologici la “diagnosi” astratta deve
diventare “codice”
il fine è contare eventi “operativamente
equivalenti”
la definizione di categorie e criteri di codifica è obbligatoria:
senza codifica non c’è equivalenza, e senza equivalenza non c’è
conta
5
Il ruolo delle variabili indagate
Esposizione
Un momento chiave nella analisi dei dati
è la formulazione di una IPOTESI
ESPLICATIVA
Situazione in cui sono
presenti insieme agente
(o fattore di rischio) e
ospite: sono possibili
l’incontro e l’interazione
tra essi.
un
modello concettuale dei possibili legami tra le
entità o i fenomeni misurati
Questo richiede la definizione di:
Una
(o più) variabili di risultato
Effetto (outcome), variabili dipendenti
Le possibili variabili “causali”
Esposizioni, variabili indipendenti (esplicative)
Le possibili variabili “di confondimento”
Effetto
Un esempio: tipo di intervento in
cardiochirugia infantile e danno cerebrale
. describe
Un esempio: tipo di intervento in
cardiochirugia infantile e danno cerebrale
. describe
Esposizione
Contains data from circarrest2.dta
obs:
171
vars:
8
17 May 2002 15:35
size:
6,156 (99.2% of memory free)
------------------------------------------------------------------------------storage display
value
variable name
type
format
label
variable label
------------------------------------------------------------------------------vsd
float %9.0g
Ventricular Septal Defect
(1=yes; 0=no)
dhca
float %9.0g
Deep Hypothermic Circulatory
Arrest (1=yes; 0=low-flow
bypass)
minutes
float %9.0g
Duration of circulatory arrest
(minutes)
birthwt
float %9.0g
Birth weight (grams)
age
float %9.0g
Age at surgery (days)
clinseiz
float %9.0g
Clinical Seizures within 7
postoperative days
eegseiz
float %9.0g
EEG seizure activity within 48
postoperative hours
pdi
float %9.0g
Psychomotor Development Index
at age 1
-------------------------------------------------------------------------------
Risultato della interazione
tra agente (o fattore di
rischio) e ospite
Effetto
A priori
A posteriori
Contains data from circarrest2.dta
obs:
171
vars:
8
17 May 2002 15:35
size:
6,156 (99.2% of memory free)
------------------------------------------------------------------------------storage display
value
variable name
type
format
label
variable label
------------------------------------------------------------------------------vsd
float %9.0g
Ventricular Septal Defect
(1=yes; 0=no)
dhca
float %9.0g
Deep Hypothermic Circulatory
Arrest (1=yes; 0=low-flow
bypass)
minutes
float %9.0g
Duration of circulatory arrest
(minutes)
birthwt
float %9.0g
Birth weight (grams)
age
float %9.0g
Age at surgery (days)
clinseiz
float %9.0g
Clinical Seizures within 7
postoperative days
eegseiz
float %9.0g
EEG seizure activity within 48
postoperative hours
pdi
float %9.0g
Psychomotor Development Index
at age 1
-------------------------------------------------------------------------------
Precoce
Tardivo
6
Il confondimento
Proprietà formali dei dati
In ambito epidemiologico e di sanità
pubblica siamo interessati alla
associazione tra esposizione ed effetto
Relazione di equivalenza (=, ≠)
i
membri di una stessa sottoclasse devono essere
equivalenti rispetto alla proprietà misurata
Capita
spesso di dover verificare che la nostra
analisi di associazione non sia distorta da una
terza variabile
correlata sia alla esposizione che all’ effetto
Definiremo questa variabile di confondimento se
si tratta di una variabile estranea che soddisfa
entrambe le seguenti condizioni:
E’ fattore di rischio per l’ effetto
E’ associata all’esposizione, ma non ne è una
conseguenza
Relazione di posizione (<, >)
è
possibile ordinare logicamente le modalità
Relazioni aritmetiche (+, -, *, /)
sono
ed
definite le distanze relative (+, -)
i rapporti tra le osservazioni (*, /)
Tipologie dei dati : esempi
Tipologie dei dati
Categorici
dicotomici
DATI
Categorici
nominali
Categorici
ordinali
Numerici
discreti
Numerici
continui
Relazione di equivalenza (=, ≠)
Qualità
Categorici
Le modalità
esprimono
Quantità
Relazione di posizione (<, >)
Numerici
Relazioni aritmetiche
Sesso
2
Quante modalità
sono possibili?
No
>2
Sì
Le modalità
sono solo
numeri interi?
Lavoro
Medico,
M/F
Malattia
No
Si/No
Evento
Avvocato, ...
Gruppo
sanguigno
0,A,B,AB
Le modalità
sono ordinabili?
Vero/Falso
Sì
Scommessa
Nazionalità
Italiana,...
Categorici
dicotomici
Categorici
nominali
Categorici
ordinali
Classi
Numerici
discreti
Numerici
continui
Vinta/Persa
Stato Civile
Libero,
Coniugato,...
Titolo di
studio
Elementari,
Medie,...
Gravità
stadi
tumorali
Classi di
esposizione
MISURE
TECNICHE
n°
temperatura
n°
altezza
decessi
figli
abitanti
n° esami
svolti
n° piastrine
n°
(lunghezza)
peso
durata
tempo
nel
Non
fuma,
lieve fum.,
medio fum.,
forte fum.
Patologia
Approssimazione
codici
standard
Valore soglia (cutoff)
CONTE DI
EVENTI
(+, -, *, /)
Trasformazione
E’ necessario definire dei CODICI
L ’unità di
misura NON E’
frazionabile
L ’unità
di misura E’
frazionabile
7
Tipologie dei dati : proprietà e
caratteristiche
Variabili e Valori
Significato
Dipendenti
(Misure di: Effetto, Outcome, Risultato)
Variabili
Indipendenti
(Caratteri statistici)
(Esposizione, Esplicative, di Raggruppamento)
Caratteristiche formali
assumono
Discreti
Categorie
Numeri discreti
Continui
Numeri continui
Di Intervallo
Le misure sono attendibili?
Numerici
discreti
Numerici
continui
Relazioni aritmetiche (+, -, *, /)
2
Di Rapporto
(infinite alternative)
Categorici
ordinali
Relazione di posizione (<, >)
Multinomiali
(Modalità, Dati)
Categorici
nominali
Relazione di equivalenza (=, ≠)
Dicotomici
Ordinali
(alternative definite)
Valori
Nominali
Categorici
dicotomici
Prima di tutto, l effetto è stato
concettualizzato, portando a diverse
possibili misure:
cerebrale a breve termine
aumento attività elettrica (poligrafia EEG)
enzimi necrosi
convulsioni cliniche
alterazioni macroscopiche (ECO cerebrale)
Numero di modalità assumibili dal carattere
∞
Potenziale informativo aggregativo del carattere
Potenziale informativo discriminativo del carattere
Visibilità di un indicatore da
misurare
Alterazioni Anatomiche (Eco)
Convulsioni cliniche
Sofferenza
scartato poi perché 0 positivi
• sensibilità nulla
Aumento Enzimi segno di
necrosi dei tessuti (CK)
Convulsioni EEG
Sofferenza
cerebrale a lungo termine
deficit intellettivo
PDI (Psychomotor Developmental Index), il QI ad 1 anno
8
Attendibilità di una misura
Tipi di dati: variabili categoriche
vsd=
Convulsioni EEG
Diagnosi:
1= Difetto del Setto Ventricolare; 0= Setto Ventricolare intatto
dhca=
Arresto circolatorio:
1=Arresto Circolatorio Profondo Ipotermico; 0=By-pass a basso flusso
minutes=
Durata dell'arresto circolatorio:
Minuti, variabile continua (di rapporto)
birthwt=
Convulsioni Cliniche
Peso alla nascita:
Grammi, variabile continua (di rapporto)
agesurg=
Età all'intervento:
Giorni, variabile continua (di rapporto)
clinseiz=
Deficit psicomotorio a
1 anno
1=Sì; 0=No
eegseiz=
Specificità
pdi=
Arresto circolatorio:
1=Arresto Circolatorio Profondo Ipotermico; 0=By-pass a basso flusso
minutes=
Il calcolo dei ranghi
Per trasformare, ad es., dati
continui in ranghi
Durata dell'arresto circolatorio:
Minuti, variabile continua (di rapporto)
birthwt=
Peso alla nascita:
Grammi, variabile continua (di rapporto)
agesurg=
Età all'intervento:
Giorni, variabile continua (di rapporto)
clinseiz=
Convulsioni clinicamente manifeste entro 7 giorni dall’intervento:
1=Sì; 0=No
eegseiz=
Attività convulsiva EEG entro 48 ore dall'intervento:
1= Sì; 0= No
pdi=
Indice di Sviluppo Psicomotorio a 1 anno:
Punteggio standard (media normale=100), variabile continua (di intervallo)
Indice di Sviluppo Psicomotorio a 1 anno:
Punteggio standard (media normale=100), variabile continua (di intervallo)
Diagnosi:
1= Difetto del Setto Ventricolare; 0= Setto Ventricolare intatto
dhca=
Attività convulsiva EEG entro 48 ore dall'intervento:
1= Sì; 0= No
Sensibilità
Tipi di dati: variabili numeriche
vsd=
Convulsioni clinicamente manifeste entro 7 giorni dall’intervento:
le unità statistiche vanno
ordinate in ordine crescente
secondo le modalità assunte
dal carattere che si intende
trasformare (es X)
si definisce un nuovo carattere
statistico (rango di x)
ogni unità statistica assume
per il carattere “rango di
x” (Rx) un valore che
incrementa di 1 unità
se due unità hanno lo stesso
valore nella variabile originaria
mantengono lo stesso rango
è conservata la posizione
relativa delle osservazioni
X:
20, 15,9,3,4,1,6, 15
X:
1,3,4,6,9, 15, 15,20
X:
1,3,4,6,9, 15, 15,20
Rx:
X:
1,3,4,6,9, 15, 15,20
Rx: 1,2,3,4,5,
X:
?,
?, 8
1,3,4,6,9, 15, 15,20
Rx: 1,2,3,4,5,6.5,6.5, 8
9
Il calcolo dei ranghi
Mostra
Ordina
. list minutes
+---------+
| minutes |
|---------|
1. |
2. |
8 |
6 |
3. |
4. |
61 |
51 |
Calcola (attento ai pari!)
. sort minutes
. list id minutes
1.
2.
3.
4.
5.
5. |
12 |
|---------|
6. |
7. |
31 |
51 |
6.
7.
8. |
9. |
5 |
68 |
8. | 23
9. | 22
10. |
22 |
|---------|
. egen rank=rank( minutes)
. list rank id minutes
+--------------+
| id
minutes |
|--------------|
| 8
5 |
| 2
6 |
| 20
8 |
| 1
8 |
| 13
8 |
|--------------|
| 15
9 |
| 5
12 |
+---------------------+
| rank
id
minutes |
|---------------------|
|
1
8
5 |
|
2
2
6 |
|
4
20
8 |
|
4
1
8 |
|
4
13
8 |
|---------------------|
6. |
6
15
9 |
7. |
7
5
12 |
1.
2.
3.
4.
5.
18 |
20 |
8. |
9. |
8
9
23
22
11. |
44 |
10. | 10
22 |
|--------------|
11. | 19
25 |
10. |
10
10
22 |
|---------------------|
11. |
11
19
25 |
12. |
13. |
62 |
8 |
12. | 6
13. | 17
31 |
31 |
12. | 12.5
13. | 12.5
6
17
31 |
31 |
14. |
15. |
51 |
9 |
14. | 21
15. | 25
35 |
43 |
14. |
15. |
21
25
35 |
43 |
14
15
|---------|
16. |
61 |
|--------------|
16. | 11
44 |
|---------------------|
16. |
16
11
44 |
17. |
18. |
31 |
45 |
17. | 18
18. | 7
45 |
51 |
17. |
18. |
17
19
18
7
45 |
51 |
19. |
20. |
25 |
8 |
19. | 14
20. | 4
51 |
51 |
19. |
20. |
19
19
14
4
51 |
51 |
|---------|
21. |
35 |
|--------------|
21. | 16
61 |
|---------------------|
21. | 21.5
16
61 |
22. |
23. |
20 |
18 |
22. | 3
23. | 12
61 |
62 |
22. | 21.5
23. |
23
3
12
61 |
62 |
24. |
25. |
63 |
43 |
24. | 24
25. | 9
63 |
68 |
24. |
25. |
24
9
63 |
68 |
+---------+
+--------------+
24
25
Statistica Descrittiva:
Analisi esplorativa univariata
18 |
20 |
+---------------------+
Tabelle e Grafici
TABELLE
Organizzazione spazio
righe e colonne
GRAFICI
discreto
Organizzazione spazio
piano “cartesiano”
(piani angolari)
continui
Elementi
testo, numeri
Elementi
grafici 2 dimensioni
punto, linea, area
testo, numeri
Quantità
posizione
area
Vantaggi
immediatezza
Quantità
numeri
Vantaggi
comparazioni simultanee
Graphical excellence
Una buona rappresentazione dei dati dovrà:
mostrare i dati
indurre chi guarda a riflettere sulla sostanza
piuttosto che sui metodi, il disegno grafico, la tecnologia di
produzione grafica
evitare di distorcere ciò che i dati hanno da dire
presentare molti numeri in poco spazio
rendere coerenti grandi set di dati
incoraggiare l’occhio a comparare diversi aspetti dei dati
presentare i dati a diversi livelli di dettaglio
da una visione d’insieme fino alla struttura fine
servire un obiettivo ragionevole:
descrivere, esplorare, tabulare, decorare
essere fortemente integrata con le descrizioni verbali e
statistiche dei dati
Edward E. Tufte, The visual display of quantitative information, Graphics Press, 1983
10
Elting LS, Martin CG, Cantor SB, et al., Influence of data display
formats on physician investigator’s decisions to stop clinical trials:
prospective trial with repeated measures - BMJ 1999, 318:1527-1531
Graphical elegance is often found in
simplicity of design and complexity of data
Rappresentazioni di dati statistici attraenti:
sono realizzate con schema e formato appropriati
utilizzano parole, numeri e disegni insieme
sono il risultato di un bilanciamento, una valutazione delle
proporzioni, una riflessione sulla scala dei fenomeni
mostrano un dettaglio di complessità accessibile
hanno spesso qualità narrativa
hanno una storia da raccontare sui dati
sono realizzati in maniera professionale
con attenzione e cura ai dettagli tecnici
evitano la decorazione fine a sè stessa
inclusa la “spazzatura grafica” di retinati, colori
sgargianti, ecc.
Edward E. Tufte, The visual display of quantitative information, Graphics Press, 1983
Le Tabelle di sintesi dei dati
Tabelle a singola entrata
Generalità
presentano i dati in forma analitica o sintetica,
organizzati secondo righe e colonne
presentata la distribuzione di frequenza di
UN SOLO carattere statistico
possibili
Tassi
Soggetti classificati in una categoria nel tempo t (eventi)/Media soggetti
studiati nel tempo t
conta PDI<100 / ((conta Reclutati + conta PDI misurati a 1 anno)/2)
Soggetti classificati in una categoria nel tempo t (eventi)/Totale tempopersona osservato in periodo t
conta EEG seizures / (48h*conta poligrafie)
di tutte le modalità
Dato numerici discreti e continui
Dati
Proporzioni (Percentuali)
Soggetti classificati in una categoria/Totale soggetti studiati
conta Clinical Seizures / numero Soggetti in studio
Dati nominali ed ordinali
Rappresentazione
Conte
di soggetti classificati nella stessa categoria
Relative
A seconda dei tipi di dati
Frequenze
Assolute
Numero di Clinical Seizures osservate
è
aggregati per classi
Rapporti
Soggetti classificati in una categoria non binomiale/soggetti classificati in
un altra categoria non binomiale
conta PDI>116 / conta PDI<84
Odds
Soggetti classificati in una categoria binomiale/soggetti classificati
nell altra categoria
conta Clinical Seizures SI / conta Clinical Seizures NO
11
Conte
di soggetti classificati nella stessa categoria
Numero di Clinical Seizures osservate = 11
Relative
Proporzioni (Percentuali)
Soggetti classificati in una categoria/Totale soggetti studiati
conta Clinical Seizures / numero Soggetti studiati = 11 / 170 = 0.0647 = 6.47%
Partendo da questi dati grezzi:
Id
Sesso Età
35
lieve fumatore
italiana
F
40
non fumatore
francese
M
60
forte fumatore
italiana
0004
M
29
lieve fumatore
italiana
0005
M
27
medio fumatore
belga
0006
F
26
non fumatore
francese
0007
F
35
non fumatore
tedesca
0008
F
32
forte fumatore
belga
Rapporti
Soggetti classificati in una categoria non binomiale/soggetti classificati in
un altra categoria non binomiale
0009
M
45
non fumatore
tedesca
0010
M
19
lieve fumatore
tedesca
F
24
non fumatore
francese
0012
F
28
forte fumatore
italiana
Odds
Soggetti classificati in una categoria binomiale/soggetti classificati
nell altra categoria
0013
M
36
non fumatore
italiana
conta EEG seizures / (48h*conta poligrafie) = 27/(48*136) = 27/6528 = 0.00413 eventi/
ora-persona
conta PDI>116 / conta PDI<84 = 13/30 = 0.433
conta Clinical Seizures SI / conta Clinical Seizures NO = 11/(170-11) = 11/159 = 0.0692
0011
STATA:
Raggruppare in classi
Come sono costituite le classi?
Valori
predefiniti (logica, letteratura)
Liberi
es. classi età (0-14, 15-29, 30-65, >65)
classi tempo (<7gg, 7-14, 15-30, 31-60, >60)
A larghezza costante
es classi quinquennali di età
Suddivisioni
statistiche (quantili)
quartili, quintili, decili (a numerosità costante)
si usa quando non ci sono valori di cut-off noti
aumenta la potenza statistica
Classi
dicotomiche o classi ordinali?
Le classi dicotomiche (0-1) ottenute con 1 solo
cut-off hanno alcune proprietà notevoli
la media è la proporzione
si possono utilizzare nei modelli statistici
Modalità
Freq.
assoluta
Freq.
relativa
M
7
7/13
F
6
6/13
Carattere
Tot.
13
Conta dei soggetti
che nel campione presentano
quella specifica modalità
tabulate sesso
Tabelle:
Indice rappresentato
Nazionalità
M
Soggetti classificati in una categoria nel tempo t (eventi)/Totale tempopersona osservato in periodo t
0001
Classe di
esposizione
0003
Singola entrata, Variabile Dicotomica
0002
Tassi
Soggetti classificati in una categoria nel tempo t (eventi)/Media soggetti
studiati nel tempo t
conta PDI<100 / ((conta Reclutati + conta PDI misurati a 1 anno)/2) = 97/((171+142)/2) =
97/156.5 = 0.619 = 61.9%
Tabelle:
Sesso
Frequenze
Assolute
Singola entrata, Variabile Numerica
Partendo da questi dati grezzi:
Id
0001
Sesso Età
Classe di
esposizione
M
35
lieve fumatore
italiana
0002
F
40
non fumatore
francese
0003
M
60
forte fumatore
italiana
0004
M
29
lieve fumatore
italiana
0005
M
27
medio fumatore
belga
0006
F
26
non fumatore
francese
0007
F
35
non fumatore
tedesca
0008
F
32
forte fumatore
belga
0009
M
45
non fumatore
tedesca
0010
M
19
lieve fumatore
tedesca
0011
F
24
non fumatore
francese
0012
F
28
forte fumatore
italiana
0013
M
36
non fumatore
italiana
STATA:
In questo caso, ha senso
la frequenza cumulativa !
Indice rappresentato
Nazionalità
Classi di
Modalità
Carattere
Età
Freq.
assoluta
Freq.
Freq.
relativa cumulativa
10-29
6
6/13
6/13
30-39
4
4/13
10/13
>39
3
3/13
13/13
generate eta2=eta
recode eta2 10/29=1 30/39=2 40/max=3
tab eta2
Tot.
13
Conta dei soggetti
che nel campione presentano
quella specifica modalità
12
1 sola variabile, dato dicotomico
DIAGRAMMI A TORTA
. tabulate eegseiz
graph pie, over(eegseiz) angle(90) pie( 1,
color(ltblue))pie( 2, color(blue)) title(EEG
seizure activity) subtitle(within 48 hours
since surgery) legend(rows(2)) legend
(position(3) region(lcolor(none)))
graphregion(fcolor(white))
EEG seizure |
activity |
within 48 |
postoperati |
ve hours |
Freq.
Percent
Cum.
------------+----------------------------------0 |
109
80.15
80.15
1 |
27
19.85
100.00
------------+----------------------------------Total |
136
100.00
STATA 7:
graph <5 5_17 18_64 >65, pie
STATA 8: graph pie <5 5_17 18_64 >65
Può essere rappresentato
un solo carattere
Le modalità sono
rappresentate da spicchi
della torta
L area della torta è
proporzionale alla
frequenza relativa della
modalità
DIAGRAMMI A BARRE
Torte 2D e torte 3D
n
Frequenza delle osservazioni
Le modalità qualitative sono
riportate in ascissa
asse X qualitativo
Per ogni gruppo si costruisce un
rettangolo:
il nome della modalità è
centrato sulla base del
rettangolo, di larghezza
costante e arbitraria (0->∞)
l area del rettangolo è
proporzionale alla frequenza
rilevata per il gruppo
0
ma siccome le basi sono
A
B
C
D
uguali per definizione,
Modalità qualitatitive
sarà l altezza a fare la
STATA:
graph bar (count) idvar, over(variable)
differenza
La scala utilizzata per gli assi
deve consentire la visualizzazione
dei rettangoli interi
STATA:
graph hbar
I rettangoli non devono essere
(count) idvar,
adiacenti (tranne nel caso di
over(variable)
variabili ordinali…)
13
1 variabile continua: istogramma
7
5.5
4
1
0
0
n
Frequenza delle osservazioni
0
0 1
4 5.5
7
13
I dati vengono divisi in classi
16
Modalità numeriche
in questo caso 6 classi con un
intervallo non costante
Per ogni gruppo si costruisce
un rettangolo:
la posizione della base
del rettangolo
corrisponde ai margini
dell intervallo (è
quantitativa)
l area del rettangolo è
proporzionale alla
frequenza rilevata per il
gruppo
La scala utilizzata per gli
assi deve consentire la
visualizzazione dei rettangoli
interi
.3
.2
Fraction
13
Modalità numeriche
16
.1
0
45
55
STATA:graph twoway (histogram eta)
25
1 variabile continua: istogramma
con Stata 8
65
75
85
95
105
115
125
Psychomotor Development Index at
135
145
155
Distribuzioni di frequenza
Se la numerosità del campione che
stiamo studiando aumenta
costruire un istogramma con classi di
ampiezza via via più piccola
fino a poter pensare ad una curva continua
che descrive la distribuzione della
frequenza delle osservazioni
5
10
Percent
15
20
possiamo
0
Frequenza delle osservazioni
ISTOGRAMMI
n
0
10
20
30
40
50
60
70
80
Duration of circulatory arrest (minutes)
90
100
110
histogram minutes, width(10) start(0) percent bfcolor(yellow) blcolor(gold) normal
normopts( clcolor(red) clpat(dot) ) kdensity kdenopts( clcolor(blue) ) xlabel( 0 (10)
110) plotregion(margin(zero))
14
Valutare una distribuzione di frequenza
Distribuzioni
Simmetrica Unimodale
Asimmetrica
a destra
dhca==0
.6
Simmetrica Bimodale
Simmetrica
dhca==1
.4
Asimmetrica
a
destra
a
sinistra
Fraction
.2
0
0
20
40
60
80
100
120
0
20
40
60
80
100
120
Durata dell intervento chirurgico (minuti)
Duration of circulatory arrest (
Fare un istogramma in 6 passi
1) Ordinare i dati
2) Calcolare l ampiezza del l intervallo dei valori (minmax)
3) Scegliere un ampiezza di classi di valori tale da
sintetizzare i dati in un numero di classi compreso
tra 10 e 20
4) Realizzare una tabella di sintesi che presenti
-> le classi, i valori al centro di ciascuna classe, la
frequenza assoluta di osservazioni rilevate per classe e
la frequenza cumulativa
5) Trasformare la tabella in un istogramma
6) Accettare la perdita di dettaglio informativo dovuta
al raggruppamento
Histograms by Deep Hypothermic Circulatory Arrest (1=yes; 2=low-
Lo Stem & leaf plot
Tukey (1977) ha proposto una tecnica
che permette di saltare le fasi 1 e 6 e
combinare le fasi 4 e 5 in una sola
Il
diagramma che ne deriva, chiamato Stem
(ramo) & leaf (foglia) plot, si costruisce in soli 3
passi:
1) Calcola ampiezza intervallo valori (max-min)
2) Scegliere un ampiezza di classi di valori
tale da sintetizzare i dati in un numero di
classi compreso tra 10 e 20
3) Realizzare una tabella che ha l aspetto di
un istogramma, e mantiene il dettaglio dei
dati originali
15
Stem and leaf plot
stem
Poligoni di frequenza
pdi
Stem-and-leaf plot for pdi (Psychomotor Development Index at age 1)
Invece di una barra a coprire ogni
intervallo
mettiamo
un punto in corrispondenza del centro
di ogni classe
e connettiamo i punti con linee rette
ma attenzione:
5*
5.
6*
6.
7*
7.
8*
8.
9*
|
|
|
|
|
|
|
|
|
2
9.
10*
10.
11*
11.
12*
12.
13*
|
|
|
|
|
|
|
|
8888888888888888888888899999
4444
555555555559
000111111114
555577788
022224
00333
67
0001
55678
0000000000022
6666666666777777
02222222222222222223333
negli istogrammi si esprime una distribuzione uniforme
all interno della classe definita
nei poligoni di frequenza, invece, assumiamo e
rappresentiamo tutte le osservazioni nel punto centrale
della classe
• tranne per i poligoni di frequenza cumulativa, che
presentano la somma di tutte le osservazioni fino
alla fine di ciascuna delle classi presentate
04
Poligoni di Frequenza
Poligoni di frequenza
Deep Hypothermic Circulatory Ar
50
Low Flow Bypass
30
(count) pdi
40
20
30
20
10
10
0
0
50
60
70
80
90
PDI a 1 anno
100
110
120
130
50
60
70
80
90
PDI a 1 anno
100
110
120
130
16
Poligoni di frequenza cumulativa
Deep Hypothermic Circulatory Ar
Low Flow Bypass
70
Statistica Descrittiva:
60
Analisi esplorativa bi- e multivariata
50
40
30
20
10
0
50
60
70
80
90
100
PDI a 1 anno
110
120
130
140
Il ruolo delle variabili indagate
Un momento chiave nella analisi dei dati
è la formulazione di una IPOTESI
ESPLICATIVA
un
modello concettuale dei possibili legami tra le
entità o i fenomeni misurati
Questo richiede la definizione di:
Una
(o più) variabili di risultato
Effetto (outcome), variabili dipendenti
Le possibili variabili “causali”
Esposizioni, variabili indipendenti (esplicative)
Le possibili variabili “di confondimento”
Un esempio: tipo di intervento in
cardiochirugia infantile e danno cerebrale
. describe
Esposizione
Contains data from circarrest2.dta
obs:
171
vars:
8
17 May 2002 15:35
size:
6,156 (99.2% of memory free)
------------------------------------------------------------------------------storage display
value
variable name
type
format
label
variable label
------------------------------------------------------------------------------vsd
float %9.0g
Ventricular Septal Defect
(1=yes; 0=no)
dhca
float %9.0g
Deep Hypothermic Circulatory
Arrest (1=yes; 0=low-flow
bypass)
minutes
float %9.0g
Duration of circulatory arrest
(minutes)
birthwt
float %9.0g
Birth weight (grams)
age
float %9.0g
Age at surgery (days)
clinseiz
float %9.0g
Clinical Seizures within 7
postoperative days
eegseiz
float %9.0g
EEG seizure activity within 48
postoperative hours
pdi
float %9.0g
Psychomotor Development Index
at age 1
-------------------------------------------------------------------------------
A priori
A posteriori
17
Un esempio: tipo di intervento in
cardiochirugia infantile e danno cerebrale
Tabelle:
. describe
6
10
seizure
|
activity |
within 48 |Deep Hypothermic Circulatory Arrest (1=yes; 2=low-flow bypass) and
postopera |
Ventricular Septal Defect (1=yes; 0=no)
tive
| -------- 0 --------------- 1 ------------- Total -----hours
|
0
1 Total
0
1 Total
0
1 Total
----------+-----------------------------------------------------------------0 |
43
11
54
49
6
55
92
17
109
2
8
italiana
0004
M
29
lieve fumatore
0005
M
27
medio fumatore
italiana
Carattere
1
0006
F
26
non fumatore
francese
0007
F
35
non fumatore
tedesca
0008
F
32
forte fumatore
belga
0009
M
45
non fumatore
tedesca
0010
M
19
lieve fumatore
tedesca
0011
F
24
non fumatore
francese
0012
F
28
forte fumatore
0013
M
36
non fumatore
belga
9
M
Sesso
F
Tot.
non
2
4
6
lieve
3
0
3
medio
1
0
1
italiana
forte
1
2
3
italiana
Tot.
7
6
13
Tardivo
Conta dei soggetti nel campione
che presentano la combinazione di
entrambe le modalità
tab classe sesso
Barre affiancate
10
19
15
12
27
Total |
49
13
62
58
16
74
107
29
136
-----------------------------------------------------------------------------
|
|
|
11.4
63
12.6
66
22.5
129
1 |
|
33.0
16.4
54.8
8.2
43.9
16.9
|
|
Total |
21
21
42
18.7
52.6
36.0
|
|
15.2
84
11.7
87
21.7
171
-------------------------------
40
| Deep Hypothermic
| Circulatory Arrest
| (1=yes; 0=low-flow
|
bypass)
|
0
1 Total
----------+-------------------0 | 13.9
52.0
33.4
----------------------------------------------------------------------------EEG
|
6
francese
forte fumatore
20
49
9
eegseiz vsd dhca, row col scol
1 |
|
italiana
non fumatore
60
table
vsd dhca, c(mean
minutes sd minutes count
minutes) row col f(%4.1f)
Ventricul
ar Septal
Defect
(1=yes;
0=no)
-----------------------------------. table
lieve fumatore
40
M
0
11
2
35
F
0003
-------------------------------
Septal Defect (1=yes;
0=no)
tive
| ---- 0 ------ 1 --hours
|
0
1
0
1
----------+------------------------43
6
Modalità del
carattere 1
M
0002
STATA:
Modalità del
carattere 2
Carattere 2
Nazionalità
60
.
|
Circulatory Arrest
|
(1=yes; 0=low-flow
| bypass) and Ventricular
0 |
1 |
Precoce
Classe di
esposizione
EEG seizure activity within 48 h since surgery
-----------------------------------|
Deep Hypothermic
within 48 |
postopera |
0001
Sesso Età
Tabelle a n entrate
eegseiz vsd dhca
EEG
seizure
activity
Id
Number of children
. table
Partendo da questi dati grezzi:
Esposizione
Effetto
Contains data from circarrest2.dta
obs:
171
vars:
8
17 May 2002 15:35
size:
6,156 (99.2% of memory free)
------------------------------------------------------------------------------storage display
value
variable name
type
format
label
variable label
------------------------------------------------------------------------------vsd
float %9.0g
Ventricular Septal Defect
(1=yes; 0=no)
dhca
float %9.0g
Deep Hypothermic Circulatory
Arrest (1=yes; 0=low-flow
bypass)
minutes
float %9.0g
Duration of circulatory arrest
(minutes)
birthwt
float %9.0g
Birth weight (grams)
age
float %9.0g
Age at surgery (days)
clinseiz
float %9.0g
Clinical Seizures within 7
postoperative days
eegseiz
float %9.0g
EEG seizure activity within 48
postoperative hours
pdi
float %9.0g
Psychomotor Development Index
at age 1
-------------------------------------------------------------------------------
Doppia entrata, Variabile Ordinale
Low Flow By-Pass
EEG seizures
Deep Hypothermic Circulatory Arrest
No EEG seizures
graph bar (sum) eegseiz noeegseiz, over(dhca, relabel(1 "Low Flow ByPass" 2 "Deep Hypothermic Circulatory Arrest")) bar(2, bfcolor
(ltblue) blcolor(ltblue)) ytitle(Number of children) title(EEG
seizure activity within 48 h since surgery) legend(order(1 "EEG
seizures" 2 "No EEG seizures"))
18
Barre sovrapposte
Torte affiancate
EEG seizure activity within 48 h since surgery
Deep Hypothermic Circulatory Arrest
0
20
40
Number of children
60
80
Low Flow By-pass
Low Flow By-Pass
Deep Hypothermic Circulatory Arrest
EEG seizures
No EEG seizures
EEG seizure activity within 48 postoperative hours
noeegseiz
Graphs by Deep Hypothermic Circulatory Arrest (1=yes; 2=low-flow bypass)
graph bar (sum) eegseiz noeegseiz, over(dhca, relabel(1 "Low Flow ByPass" 2 "Deep Hypothermic Circulatory Arrest")) bar(2, bfcolor
(ltblue) blcolor(ltblue)) ytitle(Number of children) title(EEG
seizure activity within 48 h since surgery) legend(order(1 "EEG
seizures" 2 "No EEG seizures")) stack
graph pie eegseiz noeegseiz, angle(90) by(dhca) pie( 2, color
(ltblue))
DIAGRAMMI DI DISPERSIONE
DIAGRAMMI DI DISPERSIONE
A DUE DIMENSIONI
STATA: !twoway (scatter marriage pop,
, xlabel(, angle(forty_five)) caption(1980 U.S. census data, size(small))!
200,000
150,000
100,000
00
0
00
,0
25
0,
,0
0
20
,0
00
0
,00
15
,0
00
,0
00
,0
10
0,
00
00
0
50,000
Georgia
Virginia
Tennessee
Indiana New Jersey
Missouri
S. Carolina
Alabama
Washington
Oklahoma
Maryland
Massachusetts
N. Carolina
Louisiana
Wisconsin
Minnesota
Colorado
Kentucky
Arizona
Mississippi
Iowa
Arkansas
Connecticut
Kansas
Oregon
W.Mex
Virginia
New
Utah
ico
Idaho
Nebraska
Hawaii
Maine
New
S.
Montana
DakHampshire
ota
Rhode
Island
Wyoming
N.
Dakota
Alaska
Vermont
Delaware
00
,0
00
,0
25
Se i due caratteri non
sono correlati, i punti
si distribuiscono
casualmente su tutto il
piano cartesiano
msize(medium))!
Florida Il linois
Ohio
Pennsylvania
Michigan
5,
00
00
,0
00
,0
20
00
,0
15
10
,0
00
,0
,00
0
00
00
5,
00
0 ,0
0
Population
1980 U.S. census data
la scala per un
carattere è riportata
nell asse x e la scala
per l altro nell asse
y
New York
Nevada
0
California
Tex as
0
50,000
Sono utili per
illustrare la relazione
tra due diversi
caratteri che
assumono modalità
numeriche
Ogni punto del grafico
rappresenta una unità
statistica
Number of marriages
100,000
150,000
0
Number of marriages
200,000
A DUE DIMENSIONI
Population
1980 U.S. census data
STATA:
!twoway (scatter marriage pop, msize(small) mlabel(state) mlabsize(small)
mlabcolor(red)), xlabel(, angle(forty_five)) caption(1980 U.S. census data, size(small))!
19
DIAGRAMMI DI DISPERSIONE
DIAGRAMMI DI DISPERSIONE
A DUE DIMENSIONI
50,000100,000150,000200,000
A DUE DIMENSIONI
200000
Trend
Outliers
Clustering
West
0
50,000
South
50,000100,000150,000200,000
100000
N C ntrl
0
Number of marriages
Number of marriages
150000
NE
0
0
0
!gr7
1.0e+07
Population
1.5e+07
2.0e+07
Ginec.Ostet.2
3
Nido
Ginec.Ostet.2
Rianimaz.
Oculistica
ICP --->
Oculistica
Cardio Em
Urologia
Litotrissia
Em atologi a Cardiochirurgia
Ginec.Ostet.1
Ch.G enerale2 Neurochir.
Neonatol.
Ch.GCh.Urgenza
enerale1
Psic hiatr ia
Endocrino
Mal
.Infett.
Ortopedia
odinam.
Nefr ologia
Cardio Medica
UTICMed.Generale
Pneumologia
Geriatria
ORL
Ch.G enerale1
Em atologi a Cardiochirurgia
Ginec.Ostet.1
Ch.G
enerale2
Endocrino
Cardio Medica Neurologia
UTIC
Mal .Infett.
1
Oncologia Med.
Pediatria Nido
ORL
Cardio Em odinam.
Geriatria
20,000,000
30,000,000
Psic hiatr ia
Med.Generale
1
∞
Tranquilla
Complessità
Quadrante
PROBLEMATICO
Neurologia
Pediatria
1
ICP --->
2
10,000,000
Complessità della casistica (ICM)
0
Rianimaz.
Neonatol.
Neurochir.
Ch.Urgenza
Pneumologia
Nefr ologia
Urologia
Ortopedia
3
30,000,0000
!twoway (scatter marriage pop), by( region)
STATA:
1997
2
20,000, 000
Graphs by Census region
marriage pop, oneway twoway xlab(0 (0.5e+07) 2.5e+07) ylab(0 (50000) 200000)!
1996
10,000,000
Population
2.5e+07
∞
STATA:
5.0e+06
Litotrissia
.5
.33
.33
.5
1
ICM --->
3
.33
1998
3
2
Rianimaz.
Urologia
Cardiochirurgia
3
Ginec.Ostet.2
Ch.G
enerale2
Neurochir.
Ch.Urgenza
ICP --->
Ginec.Ostet.1
Mal .Infett.
Pneumologia
Med.Generale
Ginec.Ostet.2
Neurologia
Ortopedia
Nefr ologia
Geriatria
UTIC
Oculistica
Cardio Medica
Cardio Em odinam.
Oncologia Med.
Nido
2
Rianimaz.
Ch.Urgenza
Endocrino
Ch.G
enerale2
Ch.G
enerale1
Em atologi
a
Pediatria
ORL
1
1
ICM --->
Neonatol.
Neurochir.
Neonatol.
Urologia
.5
1999
3
2
Mal .Infett.
Ch.G enerale1
Oculistica
Nefr ologia
Med.Generale
Endocrino
Geriatria
1
Pediatria
Cardio Em odinam.
Litotrissia
.5
.33
.5
1
ICM --->
2
3
Efficiente
Semplicità
Standard di
riferimento
Complessità:
Efficienza:
ELEVATA
SCARSA
Quadrante
VIRTUOSO
Cardiochirurgia
NidoOncologia Med.
Litotrissia
.33
.33
SCARSA
SCARSA
UTIC
Ortopedia
Neurologia
Em atologi a
Ginec.Ostet.1
ORL
Psic hiatr ia
Cardio Medica
Pneumologia
Psic hiatr ia
.5
Complessità:
Efficienza:
.33
.5
1
ICM --->
2
3
0
ICP --->
2
1
.33
Efficienza (ICP)
.5
Complessità:
Efficienza:
SCARSA
ELEVATA
Complessità:
Efficienza:
ELEVATA
ELEVATA
20
Cardio Emodinam.
Neurochir.
Cardio Medica
Neurologia
19 98
2
2
19 96
19 97
1.5
1.5
1 9 96
19 99
1 9 96
19 97
1919
9896
1 9 97
1
1
.66
1 9 99
.66
.5
Cardiochirurgia
2
.66
1
1.5
2
ICP
.5
.5
ICP
19 99
11999989
1 9 19 7
9 98
ORL
1.5
Oculistica
2
1 9 96
19 96
1.5
1 9 97
1 9 98
1
.66
.66
19 99
19 97 19 99
19 98
.5
.5
.5
.66
1
1.5
.5
2
graph twoway (connect anno eventi), sort
è così possibile seguire il
comportamento del
carattere riportato in y in
un determinato periodo
.5
Pert osse " - ROMA"
.66
1
1.5
2
Pert osse " - Di strett o A"
Tasso per 100.000 ab.
Tasso per 100.000 ab.
15
10
5
0
10
5
0
Jan 91 Jul 91 Jan 92 Jul 92 Jan 93 Jul 93 De c93 Jun 94De c94 Jun 95 De c95 Jun 96De c96 Jun 97De c97
Jan 91 Jul 91 Jan 92 Jul 92 Jan 93 Jul 93 De c93 Jun 94 De c94 Jun 95De c95 Jun 96De c96 Jun 97De c97
Pert osse " - ASL RME"
Pert osse " - Di strett o B"
15
15
Tasso per 100.000 ab.
2
15
Tasso per 100.000 ab.
1.5
Pertosse - RM/E (1991-1997)
DIAGRAMMI LINEARI
Ciascun punto sul grafico
rappresenta una coppia
di modalità
A Ciascun valore sull
asse x ha un solo valore
sull asse y
I punti adiacenti sono
collegati da linee rette
In genere, la scala sull
asse x rappresenta il
tempo
1
Graphs by Reparto
Graphs by Reparto
.66
ICM
ICM
STATA:
19 97
19 96
19 98
1 9 99
1
10
5
0
10
5
0
Jan 91 Jul 91 Jan 92 Jul 92 Jan 93 Jul 93 De c93 Jun 94De c94 Jun 95 De c95 Jun 96De c96 Jun 97De c97
Jan 91 Jul 91 Jan 92 Jul 92 Jan 93 Jul 93 De c93 Jun 94 De c94 Jun 95De c95 Jun 96De c96 Jun 97De c97
21
Mortalita' grezza
Trend lineare (p=0.07)
Mortalita' grezza
Media mobile a 5 mesi
Media mobile a 5 mesi
.15
.15
.1
.1
.05
.05
0
0
2/96
1/96
7/96
1/97
7/97
1/98
7/98
Mese
1/99
7/99
1/00
7/00
1/01
2/97
Infettiv e
Tumori
Leucemie
Circ XVII
Circ XVIII
Circ XIX
Circ XX
Diabete
M. Circolator
Ipertensione
IMA
Cirrosi
Traumatismi
Infarto
Rapporti standardizzati di mortalita' - per causa - 1996
gr7 c17 c18 c19 c20, star label(causa)
Il diverso sviluppo delle braccia
per raggruppamenti diversi fa
risaltare le caratteristiche
distintive
2/00
2/01
Primario 1 (valori indice=100)
da usare per piu variabili
o per rappresentare andamenti
temporali ciclici
A ciascun braccio della
stella corrisponde un
diverso carattere
numerico
Le braccia adiacenti sono
collegate da linee rette
La forma generale delle
stelle vuole evidenziare a
prima vista deviazioni
dalla regolarità
STATA:
2/99
Sono grafici multivariati
Tutte
Mese
Starplot multivariato
DIAGRAMMI POLARI o A STELLA
2/98
Cardiochirurgia Ospedale San Carlo - Potenza
N. medio dimessi/die
140
% altre provincie (>1 gg)
120
100
Primario 2
Primario 3
% DRG Chirurgici
80
60
40
% da prov. confine (>1gg)
20
% DRG Specialistici
0
% da regione, altra prov. (>1gg)
% da provincia (>1gg)
ICM (solo ricoveri >1 gg)
ICP (solo ricoveri >1 gg)
22
Starplot multivariato
MAPPE
Primario 1 (valori indice=100)
Primario 2
Primario 3
% DRG Chirurgici
% altre provincie (>1 gg)
% da altre provincie (tutti)
160
% DRG Specialistici
140
120
La distribuzione spaziale
di una variabile può
essere rappresentata
ICM (anche ricoveri 0-1 gg)
100
80
60
% da prov. confine (>1gg)
ICM (solo ricoveri >1 gg)
40
20
0
% da prov. confine (tutti)
ICP (anche ricoveri 0-1 gg)
% da regione, altra prov. (>1gg)
ICP (solo ricoveri >1 gg)
% da regione, altra prov. (tutti)
N. medio dimessi/die
% da provincia (>1gg)
% da provincia (tutti)
Grafici famosi del passato
1137 d.C., Cina
1686 d.C., Inghilterra
1801 d.C. Inghilterra
William Playfair, economista, pubblica il
Commercial e Political Atlas, che
contiene 44 grafici, per lo più grafici
lineari (serie temporali), o grafici a barre
William Playfair pubblica il primo grafico
a torta
Snow, medico, costruisce la
famosa mappa per punti dei morti
per colera a Londra
A.M. Guerry in Essai sur la Statistique
morale de la France pubblica un
istogramma
STATA (add-on!): tmap
Proprietà formali dei dati e
strumenti utilizzabili per descriverli
equivalenza
(=, ≠)
1857 d.C., Inghilterra
Florence
Nightingale, infermiera,
usa i “coxcombs”, oggi chiamati
grafici polari, nella sua campagna di
miglioramento delle condizioni
sanitarie dell’esercito
Pearson conia il termine
Istogramma
1952 d.C.
Mary
Eleanor Spear propone la
“range bar”, prina versione
orizzontale del box plot
1977 d.C.
John
Tukey propone il box plot
posizione
(<, >)
aritmetiche
(+, -, *, /)
Frequenza
(conte)
• Freq. assoluta
• Freq. relativa
• Freq. percentuale
• Freq. cumulativa
Tendenza
centrale
(sintesi)
• Moda
• Mediana
• Media aritmetica
• Media geometrica
• Massimo e minimo
• Percentili
• Varianza
• Deviaz. standard
• Errore standard
• Coeff. di variazione
1895 d.C.
Karl
1833 d.C., Francia
1854 d.C., Inghilterra
John
1785 d.C., Inghilterra
coordinate cartesiane nella mappa delle
strade di Yu il grande
Edmund Halley, astronomo, misura
l’altezza del mercurio in un barometro a
diverse altezze s.l.m. e deriva una
relazione tra pressione e altezza
attraverso un grafico a dispersione
assegnando lo stesso colore
alle aree delimitate dai loro
confini geografici che
presentano la stessa modalità
o appartengano alla stessa
classe di modalità
rispetto ad una tabella, è
mantenuto il potere
informativo della
contiguità
utilizzando come delimitatore
delle curve isolivello del
carattere numerico in uso
curve isolivello
Variabilità
(precisione)
23
Indici (Statistiche)
Gran parte della analisi statistica consiste nel condensare
complessi pattern di osservazioni in un indicatore che sia
capace di riassumere una specifica caratteristica di tutte
le rilevazioni in un singolo numero
In statistica descrittiva distinguiamo:
Indici
di tendenza centrale
che esprimono il valore tipico
Indici di dispersione
che esprimono quanto i dati si raggruppano
strettamente intorno al valore tipico
Indici di forma
che esprimono le caratteristiche di
simmetria
e
curvatura
della
distribuzione dei dati
Indici di sintesi numerica
. summ pesonasc, detail
Peso alla nascita (grammi)
------------------------------------------------------------Percentiles
Smallest
1%
2268
1497
5%
2631
1769
10%
2767
1996
Obs
680
25%
3084
1996
Sum of Wgt.
680
50%
75%
90%
95%
99%
Il Valore atteso: indici di
tendenza centrale
Media aritmetica
La
somma di tutti i valori rilevati in un campione
divisa per la numerosità
Utilizza le proprietà delle relazioni
aritmetiche (quantità, operazioni)
Esiste solo per i dati numerici continui e discreti
3447
3719
4037
4173
4627
Mean
Std. Dev.
3409.396
495.4868
Variance
Skewness
Kurtosis
245507.1
-.025685
3.402766
Il Valore atteso: indici di
tendenza centrale
Media aritmetica
La
somma di tutti i valori rilevati in un campione
divisa per la numerosità
Esempio: Il volume espiratorio forzato in 13
adolescenti asmatici (in litri)
2.3, 2.1, 3.5, 2.6, 2.8, 2.8, 4.0, 2.2, 2.6, 3.0, 4.0, 2.8, 3.3
Sintetizza tutti i dati: è il valore più vicino a
tutte le singole osservazioni
E invariante per trasformazioni affini
Somma dei 13 valori xi
Divisione per n=13
2.3+2.1+3.5+2.6+2.8+2.8+4.0+2.2+2.6+3.0+4.0+2.8+3.3= 38
+k, - k, *k, /k sui dati
• spostano nello stesso senso la media
E valida soprattutto per i dati che seguono
una distribuzione di frequenza normale
E sensibile ai valori estremi
Largest
4763
4808
4989
5171
38 / 13 = 2.9
n
∑x
i
STATA:
summarize fev
x=
i =1
n
24
Il Valore atteso: indici di tendenza centrale
Significato:
La Media aritmetica
Moda, media
e mediana
Quanto
sarebbero alti i soggetti che abbiamo
studiato, se fossero tutti uguali?
n
∑x
i
x=
xi
n
i =1
n
∑x
i
i =1
x1
x2
Mediana
x3
x
x
x
Il Valore atteso: indici di
tendenza centrale
Il
valore, che, dopo aver posto le osservazioni in ordine
crescente, divide il campione in due gruppi di eguale
numerosità
Come si determina?
Nelle serie dispari è il valore al centro della distribuzione ordinata
(valore nella (n+1)/2 esima posizione)
Nelle serie pari è la media dei due valori al centro della
distribuzione ordinata (media tra il valore nella n/2 esima e il valore
nella (n/2)+1 esima posizione)
Mediana
Il
valore, che, dopo aver posto le osservazioni in ordine
crescente, divide il campione in due gruppi di eguale
numerosità
Esempio: Il volume espiratorio forzato in 13
adolescenti asmatici (in litri)
2.3, 2.1, 3.5, 2.6, 2.8, 2.8, 4.0, 2.2, 2.6, 3.0, 4.0, 2.8, 3.3
Non è sensibile ai valori estremi
E il migliore indice di sintesi nelle distribuzioni
asimmetriche
Ordina i 13 valori xi
Calcolo:
Nelle serie dispari (N=13 è dispari) è il valore al centro della
distribuzione ordinata
• valore nella (n+1)/2 esima posizione = 7a posizione
2.1, 2.2, 2.3, 2.6, 2.6, 2.8, 2.8, 2.8, 3.0, 3.3, 3.5, 4.0, 4.0
Esiste per i dati numerici continui e discreti e per i dati categorici
ordinali
2.1, 2.2, 2.3, 2.6, 2.6, 2.8, 2.8, 2.8, 3.0, 3.3, 3.5, 4.0, 4.0
E detta anche 50° percentile
Utilizza le relazioni di posizione dei dati (>,<)
Il Valore atteso: indici di
tendenza centrale
6 osservazioni < o =
STATA:
6 osservazioni > o =
centile fev, centile(50) oppure summarize fev, detail
25
Moda
Il Valore atteso: indici di
tendenza centrale
Valutare una distribuzione di frequenza
Il
valore, che si presenta più frequentemente nella
popolazione o nel campione
Si determina contando la frequenza delle
modalità
Utilizza soltanto la relazione di identità dei dati
(=, ≠)
Esiste per i dati categorici binomiali, nominali e ordinali e per i
dati numerici discreti (quando le modalità osservate siano
poche)
Per i dati numerici continui, è necessario prima raggruppare in
classi le osservazioni
Non tiene conto di tutte le altre modalità
E utile per sospettare la copresenza di più
popolazioni
Simmetrica Unimodale
Media
Simmetrica Bimodale
Moda1
< Media = Mediana < Moda2
Asimmetrica a destra
Moda
= Mediana = Moda
< Mediana < Media
Asimmetrica a sinistra
Media
< Mediana < Moda
La variabilità (precisione): indici
di dispersione
Varianza
E
un valore sintetico che vuole esprimere la distanza media
di ogni singola osservazione dalla media aritmetica del
campione
Idealmente, la distanza media delle osservazioni dalla
media artimetica del campione si potrebbe studiare
calcolando la media aritmetica dei semplici scarti.
Tuttavia, per la stessa definizione della media artimetica, la somma degli
scarti è pari a zero
Allora, per evitare l azzeramento della somma degli
scarti, si calcola la media dei quadratin degli scarti
per la varianza di una popolazione:
∑ ( xi − µ )2
σ 2 = i =1
n
per la varianza in un campione
• si tende ad essere più conservativi:
n
s2 =
∑ ( x − x)
2
i
i =1
n −1
26
La variabilità (precisione): indici
di dispersione
Varianza
La variabilità (precisione): indici
di dispersione
E
un valore sintetico che vuole esprimere la distanza media
di ogni singola osservazione dalla media aritmetica del
campione
si calcolano gli scarti
E
un valore sintetico che vuole esprimere la
distanza media di ogni singola osservazione dalla
media aritmetica del campione
Utilizza le proprietà delle relazioni aritmetiche
(quantità, operazioni)
2.3, 2.1, 3.5, 2.6, 2.8, 2.8, 4.0, 2.2, 2.6, 3.0, 4.0, 2.8, 3.3
2.3-2.9, 2.1-2.9, 3.5-2.9, …
-0.6, -0.8, +0.6, -0.3, -0.1, -0.1, +1.1, -0.7, -0.3, +0.1, +1.1, -0.1, +0.4
si calcolano i quadrati degli scarti
Si calcola la media dei quadrati degli scarti (con i gradi di
libertà)
Varianza
Esiste solo per i dati numerici continui e discreti
Trasformazioni
E invariante per +k, - k,
Si modifica per *k, /k
0.36, 0.64, 0.36, 0.09, 0.01, 0.01, 1.21, 0.49, 0.09, 0.01, 1.21, 0.01, 0.16
E valida soprattutto per i dati che seguono una
distribuzione di frequenza normale
E sensibile ai valori estremi
La sua unità di misura non è quella della media
0.36+0.64+0.36+0.09+0.01+0.01+1.21+0.49+0.09+0.01+1.21+0.01+0.16
n
4.65/(13-1) = 0.3875
2
• attenzione: è in una scala al quadrato !
STATA:
summarize fev, detail
s2 =
∑ ( x − x)
i
i =1
n −1
è al quadrato!
La variabilità (precisione): indici
di dispersione
Deviazione standard
E
un valore sintetico che vuole esprimere la
distanza media di ogni singola osservazione dalla
media aritmetica del campione
E la radice quadrata della varianza, e ne ha le
stesse proprietà
Riporta l
indice di precisione alla stessa scala
della media aritmetica
Coefficiente di variazione
E
un indice che rapporta il valore della deviazione
standard alla media del corrispondente campione
E detto anche Deviazione Standard Relativa
E utile per confrontare tra loro la precisione di
metodi diversi
La variabilità (precisione): indici
di dispersione
Quantili, Percentili
Per
QUANTILI si intende la suddivisione di una
distribuzione in gruppi ordinati e di eguale
numerosità
Decili: dieci gruppi
Quintili: cinque gruppi
Quartili: quattro gruppi
Centili (o percentili): cento gruppi
Per PERCENTILE si intende la suddivisione in 100
parti uguali di una serie di valori continui
ad esempio pesi o altezze di bambini
Un bambino che superi il 90% percentile avrà dunque un valore
(es. di altezza) superiore al 90% di tutti i bambini considerati
27
La variabilità (precisione): indici
di dispersione
Calcolo del p-esimo Percentile
La variabilità (precisione): indici
di dispersione
Calcolo del p-esimo Percentile
75°
Considerando
n osservazioni ordinate
ed intendendo calcolare il valore del pesimo percentile
valutiamo l espressione (n*p)/100
se NON è un intero
• il p-esimo percentile sarà l osservazione che si
trova alla posizione data da np/100 approssimato
per eccesso
se è un intero
• il p-esimo percentile sarà la media tra l
osservazione che si trova nella posizione np/100 e l
osservazione che si trova nella posizione successiva
DIAGRAMMI A SCATOLA
percentile nel nostro esempio di 13 osservazioni
valutiamo l espressione (n*p)/100
75*13/100 = 9.75 è NON è un intero
• il p-esimo percentile sarà l osservazione che si
trova alla posizione data da np/100 approssimato
per eccesso
• e cioè la 10a osservazione dopo aver ordinato i dati
2.1, 2.2, 2.3, 2.6, 2.6, 2.8, 2.8, 2.8, 3.0, 3.3, 3.5, 4.0, 4.0
STATA:
centile fev, centile(75) oppure summarize fev, detail
1 variabile continua
& 1 variabile di raggruppamento
Peso alla nascita (grammi)
STATA:
graph eta, box by(reparto)
Sono utili per verificare la
asimmetria delle
distribuzioni di frequenza
La scatola centrale si
estende dal 25° percentile al
75° percentile (i quartili
dei dati)
La linea dentro la scatola
rappresenta la mediana
Le linee al di fuori della
scatola si estendono ai valori
adiacenti, osservazioni più
estreme che non superano
più di 1,5 volte l altezza
della scatola esternamente
ad ognuno dei quartili
5000
42
41
43
41
4000
3000
2000
33
29
1000
0
1
28
1 variabile continua
& 1 variabile di raggruppamento
mosmoke==0
Valutare la distribuzione
mosmoke==1
100
Frequency
50
0
1000
2000
3000
4000
5000
1000
2000
3000
4000
5000
. by mosmoke: summarize pesonasc
-> mosmoke=
0 -> (figli di non fumatrice)
Variable |
Obs
Mean
Std. Dev.
Min
Max
---------+----------------------------------------------------pesonasc |
381
3507.535
477.3541
1497
5171
-> mosmoke=
1 -> (figli di fumatrice)
Variable |
Obs
Mean
Std. Dev.
Min
Max
---------+----------------------------------------------------pesonasc |
299
3284.341
490.7343
1996
4536
Molte analisi statistiche applicabili ai
dati continui sono basate
sull assunzione che i dati disponibili
siano un campione estratto
casualmente da una popolazione a
distribuzione normale
prima
di svolgere questi test, è dunque
necessario verificare se tale assunzione è lecita
sui dati grezzi
su una loro trasformazione (es. Logaritmica)
Peso alla nascita (grammi)
STATA:
Histograms by Madri fumatrici
ladder variabile e/o gladder variabile
La normalità si valuta con
la posizione relativa di media e mediana
la forma dell istogramma
il 10%, 50%, 90% percentile o il box plot
il normal plot
l indice di skewness (simmetria)
100
50
1000
0
l indice di kurtosi
3
= ok, > 3= dati concentrati intorno alla media, < 3=
dati molto dispersi alle code
test statistici (Shapiro-Wilk, Shapiro-Francia,
Kolmogorov-Smirnov)
0.75
0.50
0.25
0.00
0
Normal F[(etapadre-m)/s]
= curva simmetrica, +1 = asimmetria a destra, -1 =
asimmetria a sinistra
Normal F[(pesonasc-m)/s]
sovrapponibili la distribuzione sarà simmetrica
2000
3000
4000
Peso alla nascita (grammi)
0.00
5000
1.00
200
0.75
150
Frequency
se
1.00
150
Frequency
Valutare la normalità
0.50
0.25
0.50
Empirical P[i] = i/(N+1)
0.75
1.00
100
50
0.25
0
0.00
0.00
0.25
0.50
Empirical P[i] = i/(N+1)
0.75
1.00
20
30
40
Eta' del padre (anni)
50
29
Statistica Inferenziale
I metodi della statistica inferenziale
hanno l obiettivo di quantificare la
probabilità che una deduzione basata
sui dati raccolti per un campione e
riferita alla popolazione sia vera
Il campione
Statistica inferenziale:
Elementi generali, test di ipotesi e intervalli di
confidenza
descrive
gli individui sotto osservazione
La popolazione
descrive
gli ipotetici (e, di solito) infiniti
soggetti a cui volete generalizzare ciò che
avete dedotto dal campione
Segnale e rumore
EVENTO “ALEATORIO”
Definizione
Praticamente tutti i test statistici sono basati sul
calcolo di un rapporto SEGNALE/RUMORE
dove
il segnale è il fenomeno di interesse ed il rumore la
variabilità individuale
L’ evento è l’ elemento di base al quale
può essere applicata la probabilità
è
il risultato di una osservazione o di un
esperimento
è la descrizione di un potenziale risultato
è lo “stato” preso da un “sistema”
L’ evento è una proposizione logica
suscettibile di essere verificata o no
a
seconda del risultato dell’ “esperimento”
30
Probabilità
Se un “esperimento”
Definizione Frequentista
viene ripetuto n volte in condizioni sostanzialmente
identiche
e se l’ evento A si verifica m volte
all’ aumentare di n la proporzione m/n si avvicina ad un
limite fisso che è la probabilità di A
P (A) = m / n
lim n⇒∞ (m / n) = P (A)
La probabilità di un evento è dunque definita come la
frequenza relativa con cui l’ evento si verifica in una
lunga serie di esperimenti condotti in condizioni
virtualmente identiche
Il valore di una probabilità è un numero compreso tra 0
e1
Se un particolare evento si verifica con certezza, allora
n/n =1
Come aiutare a percepire le
misure di probabilità e rischio ?
Calman e Royston (BMJ, 1997), hanno
portato un contributo interessante al
problema della comunicazione e
comprensibilità delle misure di rischio
spesso
è difficile proporre, stime di probabilità
o di aumento relativo di probabilità non solo ai
pazienti, ma anche agli operatori sanitari
ed hanno proposto di fare riferimento
a scale legaritmiche (come quella Richter per i
terremoti)
a riferimenti in termini di distanza chilometrica
a riferimenti qualitativi verbali
a riferimenti delle dimensioni di comunità crescenti
. tabulate mosmoke
Madri
|
fumatrici
|
(si'=1,no=0)|
Freq.
Percent
------------+-------------------------0 |
381
56.03
1 |
299
43.97
------------+-------------------------Total |
680
100.00
2 eventi
mutuamente esclusivi
. tab scolapad
Anni di |
scolarita' |
del padre |
Freq.
Percent
Cum.
------------+----------------------------------6 |
5
0.74
0.74
10 |
92
13.53
14.26
12 |
224
32.94
47.21
14 |
142
20.88
68.09
16 |
217
31.91
100.00
------------+----------------------------------Total |
680
100.00
Pr(fumatrice)=0.4397
Pr(non fum)=1-0.4397
5 eventi
mutuamente esclusivi
Pr(16 anni)=0.3191
Pr(14 anni)=0.2088
Pr(12 anni)=0.3294
Pr(10 anni)=0.1353
Pr(6anni)=0.0074
Community cluster classification
da Calman KC, Royston G, Personal paper: Risk
language and dialects, BMJ, 1997, 315: 939,-942
Grouping
Approximate size
Individual
Family
Street
Village
Small town
Large town
City
Province or country
Large country
Continent
World
1
10
100
1000
10000
100000
1000000
10000000
100000000
1000000000
10000000000
Logarithm of size
0
1
2
3
4
5
6
7
8
9
10
31
Proprietà additiva - eventi esclusivi
. tab scolapad
Anni di |
scolarita' |
del padre |
Freq.
Percent
Cum.
------------+----------------------------------6 |
5
0.74
0.74
10 |
92
13.53
14.26
12 |
224
32.94
47.21
14 |
142
20.88
68.09
16 |
217
31.91
100.00
------------+----------------------------------Total |
680
100.00
5 eventi
mutuamente esclusivi
Pr(16 anni)=0.3191
Pr(14 anni)=0.2088
Pr(12 anni)=0.3294
Pr(10 anni)=0.1353
Pr(6anni)=0.0074
Pr(12 anni OR 14 anni)=
Pr(14 anni) + Pr(12 anni) = 0.2088 + 0.3294 = 0.5382
Proprietà additiva - eventi non esclusivi
. tabulate mosmoke
Madri fumatrici
(si'=1,no=0)|
Freq.
Percent
------------+-------------------------0 |
381
56.03
1 |
299
43.97
------------+-------------------------Total |
680
100.00
. tab fatsmoke
Padri fumatori
(si'=1,no=0)|
Freq.
Percent
------------+------------------------0 |
214
31.47
1 |
466
68.53
------------+------------------------Total |
680
100.00
. tab fatsmoke mosmoke, cell
Padri |
fumatori |
Madri fumatrici
(si'=1,no=0)|
0
1 |
Total
------------+----------------------+---------0 |
159
55 |
214
|
23.38
8.09 |
31.47
------------+----------------------+---------1 |
222
244 |
466
|
32.65
35.88 |
68.53
------------+----------------------+---------Total |
381
299 |
680
|
56.03
43.97 |
100.00
Proprietà additiva - eventi non esclusivi
. tab fatsmoke mosmoke, cell
Padri |
fumatori |
Madri fumatrici
(si'=1,no=0)|
0
1 |
Total
------------+----------------------+---------0 |
159
55 |
214
|
23.38
8.09 |
31.47
------------+----------------------+---------1 |
222
244 |
466
|
32.65
35.88 |
68.53
------------+----------------------+---------Total |
381
299 |
680
|
56.03
43.97 |
100.00
2 eventi NON
mutuamente esclusivi
-> 4 eventi!
Pr(P0 AND M0)=0.2338
Pr(P0 AND M1)=0.0809
Pr(P1 AND M0)=0.3265
Pr(P1 AND M1)=0.3588
2 eventi
mutuamente esclusivi
Pr(fumatrice)=0.4397
Pr(non fum)=1-0.4397
2 eventi
mutuamente esclusivi
Pr(fumatore)=0.6853
Pr(non fum)=1-0.6853
2 eventi NON
mutuamente esclusivi
-> 4 eventi !
Pr(P0 AND M0)=0.2338
Pr(P0 AND M1)=0.0809
Pr(P1 AND M0)=0.3265
Pr(P1 AND M1)=0.3588
La proprietà moltiplicativa
Prendiamo in esame 1 evento aleatorio esposizione
ed 1 effetto: ad esempio esposizione al fumo ed la
presenza di Basso peso alla nascita
Se i due eventi non fossero associati, si
combinerebbero casualmente, seguendo la
proprietà moltiplicativa della probabilità
1.6%
3.68%
Pr(Padre fuma OR Madre fuma)=
43.6%
x
=
Pr(P1)+Pr(M1)-Pr(P1 AND M1) = 0.6853+0.4397-0.3588 = 0.7662
P(A AND B ) = P(A) x P(B)
P(A AND B ) < P(A); P(A AND B ) < P(B)
32
La probabilità condizionata
Eventi indipedenti e dipendenti
• L’ Epidemiologia costruttiva utilizza le misure di frequenza allo
scopo di stimare se i due eventi si associano solo casualmente, o
se l’esposizione aumenta il RISCHIO di malattia:
se l’ esposizione e la
malattia sono tra loro
indipendenti
(non esiste dunque alcuna
associazione)
se l’ esposizione e la
malattia sono tra loro
dipendenti
L’ esposizione e la malattia potrebbero essere
distribuite nella popolazione come nel seguente
schema:
Malati
(l’esposizione modifica la
probabilità di malattia)
0,2
0,5
Non
malati
0,8
La probabilità di essere
Fumatore AND Malato
è il prodotto delle
probabilità elementari
La probabilità di essere
Fumatore AND Malato
è MAGGIORE del prodotto
delle probabilità elementari
Eventi indipendenti
se l’ esposizione e la malattia sono tra loro
indipendenti la conoscenza dello stato di
malattia non influenza la probabilità che un
soggetto sia esposto
0,5
0,2
0,8
Malati
0,5
Non
malati
0,5
Esposti
Non esp.
Esposti
0,1
0,5*0,2= 0,1
se l’ esposizione e la malattia sono tra loro
dipendenti la conoscenza dello stato di malattia
modifica la stima della probabilità che un
soggetto sia esposto
0,95
0,2
Non esp.
0,5*0,8=
Malati
0,05
0,39
0,4
0,8
0,5
0,4
Non
esposti
Eventi dipendenti
0,5*0,2=
0,5*0,8=
0,5
Esposti
0,05*0,2=
0,19
0,01
Esposti
0,39*0,8=
0,31
Non esp.
0,61*0,8=
0,49
Esposti
Non esp.
0,95*0,2=
Non
malati
0,61
33
La probabilità condizionata
se l’ esposizione e la malattia sono tra loro
dipendenti la conoscenza dello stato di malattia
modifica la stima della probabilità che un
soggetto sia esposto
Esposti
Malati
Non esp.
Esposti
Non
malati
Il teorema di Bayes (1)
La conoscenza dello stato
assunto da uno dei due eventi
condiziona la stima della
probabilità che si verifichi
l’ALTRO evento:
a partire dai prodotti marginali e dalle
probabilità nelle singole diramazioni, è possibile
“rovesciare” l’ albero delle probabilità
B
P(B∩A) ∪ P(B∩Ac) = P(BANDA) OR P(BANDAc) = P(B)
P(A)* P(B|A) + P(Ac)* P(B|Ac) = P(B)
B
PROBABILITA’
CONDIZIONATA
(0,95*0,2) + (0,39*0,8 ) = 0,19
Bc
P(Bc∩A) ∪ P(Bc∩Ac) = P(BcANDA) OR P(BcANDAc) = P(Bc)
Non esp.
Bc
P(A)* P(Bc|A) + P(Ac)* P(Bc |Ac) = P(Bc)
(0,05*0,2) + (0,61*0,8) = 0,01
In questo modo è possibile modificare la stima
della probabilità che un soggetto sia malato
sulla base della conoscenza dello stato di
esposizione
0,19/0,5=
0,38
0,19+0,31=
0,5
Esposti
0,31/0,5=
0,62
0,01/0,5=
0,01+0,49=
0,5
Non
esposti
0,02
0,49/0,5=
0,98
Malati
0,5*0,38=
0,19
Non
malati
0,5*0,61=
0,31
Malati
0,5*0,02=
0,01
Non
malati
0,49
Il teorema di Bayes viene utilizzato
spesso nella valutazione di test
diagnostici o screening
Test
Diagnostici: hanno come obiettivo di
consentire una diagnosi di malattia
Test di Screening: utilizzati su soggetti che non
presentano alcuna sintomatologia clinica,
permettono di classificare tali individui sulla base
della probabilità di essere affetti da una
particolare patologia
0,5*0,98=
+ 0,49 = 0,50
Il teorema di Bayes ed i test
Il teorema di Bayes (2)
+ 0,31 = 0,50
Il teorema di Bayes consente di
utilizzare la probabilità per valutare le
incertezze associate ai risultati
34
Misure di qualità di un test
Qualità del test ed alberi di probabilità
SENSIBILITA’:
la
percentuale di soggetti malati che il test
classifica come positivi
= Veri positivi / (Veri positivi + Falsi
negativi)
Sensibilità
Prevalenza
P(B|A)
Test +
Malati
P(A)
Test-
esprime la probabilità che il test sia positivo nei
soggetti malati
SPECIFICITA’:
la
percentuale di soggetti sani che il test
identifica come negativi
= Veri negativi / (Veri negativi + Falsi
positivi)
1- P(A)
Test-
esprime la probabilità che il test sia negativo nei
soggetti sani
Misure di qualità di un test
VALORE PREDITTIVO DEL TEST
POSITIVO (VPP):
probabilità di essere malati dei soggetti risultati
positivi al test
= Veri positivi / (Veri positivi + Falsi positivi)
Specificità
probabilità di essere sani dei soggetti risultati
negativi al test
= Veri negativi / (Veri negativi + Falsi negativi)
Falsi positivi
Veri negativi
P(Bc|Ac)
Valore predittivo
test +
P(B)
P(A|B)
Test +
Malati
Non
malati
VALORE PREDITTIVO DEL TEST
NEGATIVO (VPN):
la
Falsi negativi
Qualità del test ed alberi di probabilità
la
Test +
Non
malati
Veri positivi
Malati
Test-
Valore predittivo
test -
Non
malati
Veri positivi
Falsi positivi
Falsi negativi
Veri negativi
P(Ac|Bc)
35
Qualità del test ed alberi di probabilità
P(A|B) =
P(A)* P(B|A)
P(A)* P(B|A) + P(Ac)* P(B|Ac)
Prevalenza
Veri positivi
=
(Preval. * Sensib.) + (1-Preval.)*(1-Specif.)
Veri positivi
Malati
Non
malati
Malati
Test-
Falsi negativi
Falsi positivi
Non
malati
Test
+
Falsi positivi
Falsi negativi
Malati
Test-
Veri negativi
Non
malati
Specificità
P(Ac|Bc)=
P(Ac)* P(Bc|Ac)
P(A)*
P(Bc|A)
+
Valore
predittivo
del test +
P(Ac)*
P(Bc|Ac)
=
Valore
predittivo
del test -
(1-Preval. )* Specif.
Prevalenza
Malati
P(B|A)
=0.75
P(A)=0.01
Test +
1-0.75=0.25
1-0.01
=0.99
1-0.93=0.07
Specificità
Falsi negativi
=0.01*0.25
=0.0025
Test + Falsi positivi
=0.99*0.07
=0.0693
TestP(Bc|Ac)
=0.93
Reagan (OMS)
Normale
Atipia
Displasia lieve
Papanicolau
I
II
Displasia Carcinoma Carcinoma
grave
III
in situ
invasivo
IV
V
da: Nanda K, et al., Ann Intern Med 2000; 132:810-819
Il Pap-test
Stime di frequenza
10:1000 (p=0.01)
3:1000 (p=0.003)
da: CNR - Basi scientifiche per la definizione di linee guida
da: Loiudice et al, Eur J Cancer Prev, 1998; 7:295-304
80:1000
10:1000 (p=0.01)
(p=0.08)
0.40
0.96
0.75
0.93
Sensibilità
Specificità
10:100000
(p=0.0001)
Qualità del test ed alberi di probabilità
P(A)* P(B|A)
P(A)* P(B|A) + P(Ac)* P(B|Ac)
Preval. * Sensib.
=
(Preval. * Sensib.) + (1-Preval.)*(1-Specif.)
Valore predittivo
del test +
Sensibilità
0.75
Prevalenza
0.0075
0.01
0.25
0.07
0,999917
Non
malati
0.93
0.0075
Veri positivi
Test
+
Veri positivi
0.0025
0.0693
Test-
Falsi negativi
Falsi positivi
Test
+
Falsi positivi
Falsi negativi
0.0025
Malati
Veri negativi
=0.99*0.93
=0.9207
Displasia
Moderata
Veri positivi
=0.01*0.75
=0.0075
Neoplasia Intraepitaeliale della Cervice
CIN I
CIN II
CIN III
Condiloma
P(A|B) =
Test-
Non
malati
Richart
Preval. * (1-Sensib.) + (1-Preval.)*Specif.
Un esempio: il pap-test
Sensibilità
Lesione Intraepiteliale Squamosa (SIL)
ASCUS Basso Grado (LSIL)
Alto Grado (HSIL)
riparative
Test
+
TestVeri negativi
Classificazione citologica
Infezione
Reazioni
Preval. * Sensib.
Sensibilità
Test
+
Sistema di
Classificazione
Bethesda
Test-
0.0693
P(Ac|Bc)=
Non
malati
0.0976
Test
+
0.0768
0.9023
0.0027
Veri negativi
Veri negativi
0.9207
0.9207
Specificità
P(Ac)*
Malati
P(Bc|Ac)
P(A)* P(Bc|A) + P(Ac)* P(Bc|Ac)
=
Malati
TestNon
malati
0.9232
0.9973
Valore predittivo
del test -
(1-Preval. )* Specif.
Preval. * (1-Sensib.) + (1-Preval.)*Specif.
36
Qualità del test ed alberi di probabilità
0.0075/0.0768
0.0075
+0.0693
=0.0768
Malati
Veri positivi
1.2
=0.0075
=0.0976
Test +
Prevalenza della malattia e valori predittivi
Non
malati
0.0693/0.0768
Probabilità di malattia post-test
Valore predittivo test +
Falsi positivi
=0.0693
=0.9023
0.0025/0.9232
=0.0027
0.0025
+0.9207
Malati
=0.0025
Test-
=0.9232
0.9207/0.9232
=0.9973
Falsi negativi
Non
malati
Veri negativi
Probabilità di malattia post-test
Sensibilità = 0.99
Specificità = 0.99
0.6
Sensibilità = 0.50
Specificità = 0.50
0.4
0.2
Risultato negativo
(normale)
0
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
1
1.1
Probabilità di malattia pre-test (prevalenza)
Teorema di Bayes ed assistenza al singolo paziente
Prevalenza della malattia e valori predittivi
Il valore predittivo del
test negativo risente
in modo critico della
SENSIBILITA’
1
0.8
Supponiamo che un medico di base osservi in un suo studio
un paziente maschio che lamenta facile stancabilità ed una
storia di calcoli renali, ma senza segni di patologia alle
paratiroidi
Test positivo (0.80,0.99)
Test positivo (0.70,0.99)
Test positivo (0.70,0.95)
0.6
Test negativo (0.70,0.95)
0.4
Test negativo (0.70,0.99)
0.2
Test negativo (0.80,0.99)
0
0
Risultato positivo
(alterato)
0.8
0
=0.9207
Valore predittivo test -
Il valore predittivo del
test positivo risente
in modo critico della
SPECIFICITA’
Sensibilità = 0.99
Specificità = 0.99
1
0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
1
Probabilità di malattia pre-test (prevalenza)
Nel processo diagnostico, il medico considera la probabilità che
il paziente sia affetto da iperparatiroidismo, e decide di
stimarla nello 0,02 (su 100 simili pazienti, si aspetta che solo 2
ne siano affetti)
Ha definito una probabilità a priori in termini soggettivi e
bayesiani
Per meglio valutare la situazione, decide comunque di
prescrivere un test del calcio sierico per “escludere” la
diagnosi
Con sua sorpresa, il risultato del test è positivo
Qual è adesso la probabilità che il paziente sia affetto da
iperparatiroidismo?
Si può calcolare sulla base del teorema di Bayes, conoscendo la sensibilità e
specificità del test (in questo caso rispettivamente stimabili a 0,90 e 0,95) e
dando alla prevalenza il valore di probabilità a priori precedentemente
definito
37
Assistenza al singolo paziente: valutazione del I test
Teorema di Bayes ed assistenza al singolo paziente
Valutazione del risultato di un test su un singolo paziente
soglia
"diagnostica"
Probabilità post-test (val. predittivo)
1,000
0,900
0,800
0,700
0,600
Test +
0,500
Test -
0,400
0,300
0,200
0,100
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1
Probabilità Pre-test (prevalenza)
Come abbiamo osservato nel grafico precedente, la stima della
probabilità che il paziente sia affetto da iperparatiroidismo
dopo l’ esecuzione del test è salita a 0,27 (su 100 simili pazienti,
ci si aspetta che 27 ne siano affetti)
Possiamo considerare questa la probabilità a priori per
valutare i risultati di un test di conferma
Il medico decide di ordinare un test che prevede il
dosaggio radioiimunologico dell’ ormone paratiroideo con la
misura simultanea del calcio sierico, test molto più costoso
del precedente
0,000
Considerando per questo test una sensibilità di 0,95 ed una
specificità di 0,98, se il risultato del test è positivo
L a p r o b a b i l i t à c h e i l p a z i e n t e s i a a f f e t t o d a
iperparatiroidismo sale a 0,94, cioè al 94%
Ed il medico è giunto ad una diagnosi
Il nostro paziente
La tabella di contingenza
Assistenza al singolo paziente: valutazione del II test
Valutazione del risultato di un test su un singolo paziente
soglia
"diagnostica"
1,000
Probabilità post-test (val. predittivo)
Il teorema di Bayes permette di calcolare una probabilità
che il soggetto sia malato dato il risultato del test (valore
predittivo del test postivo)
0,900
Se esposizione e malattia sono indipendenti (cioè
non c’è una relazione tra loro) ci attendiamo che la
probabilità degli eventi intersezione sia:
Esposti
0,800
Non
esposti
0,700
0,600
Test +
0,500
Test -
0,400
Malati
P(B ∩ A)
= 0,10
P(Bc ∩ A)
= 0,10
0,2
Non
malati
P(B ∩ Ac)
= 0,40
P(Bc ∩ Ac)
= 0,40
0,8
0,5
0,5
0,300
0,200
0,100
0,000
0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
Probabilità Pre-test (prevalenza)
Il nostro paziente
0,8
0,9
1
38
La tabella di contingenza
Questa prende il nome di
Se
stiamo studiando
“Tabella delle frequenze attese”
ad“Expected”
esempio, ci
( o soggetti,
E, dall’inglese
una popolazione di 100
aspetteremmo che:
La tabella di contingenza
Questa prende il nome di
Ed invece nel campione di 100 soggetti da noi
“Tabella delle frequenze osservate”
raccolto
( o O,
dall’ingleseabbiamo
“Observed” osservato queste frequenze
assolute:
Esposti
Non
esposti
Malati
10
10
20
Malati
16
4
20
Non
malati
40
40
80
Non
malati
34
46
80
50
100
50
100
50
Eventi dipendenti ed indipendenti
. tabulate sottopes
Sottopeso |
(<2500 g) |
Freq.
Percent
------------+--------------------------0 |
655
96.32
1 |
25
3.68
------------+--------------------------Total |
680
100.00
SE Eventi indipendenti:
. tabulate mosmoke sottopes, cell
Madri | Sottopeso (<2500 g)
fumatrici |
0
1 |
Total
-----------+----------------------+---------0 |
372
9 |
381
|
54.71
1.32 |
56.03
-----------+----------------------+---------1 |
283
16 |
299
|
41.62
2.35 |
43.97
-----------+----------------------+---------Total |
655
25 |
680
|
96.32
3.68 |
100.00
Pr(M1 AND sottopeso)= Pr(M1)* Pr(sottopeso) = 0.4397 * 0.0368 = 0.0162 <- valore
ATTESO
MA Valore osservato: 0.0235
Probabilità condizionate
Pr(sottopeso) != Pr(sottopeso|M1) != Pr(sottopeso|M0)
Pr(sottopeso | fumatrice) = 16/299 = 0.0535<- probabilità SE madre fumatrice
(Rischio assoluto per gli esposti…)
Pr(sottopeso | non fumatrice) = 9/381 = 0.0236 <- probabilità SE non fumatrice
(Rischio assoluto per i non esposti…)
La densità di probabilità
Nel caso delle variabili aleatorie continue, i valori che possono
essere assunti come modalità sono infiniti
quindi, la probabilità di assumere un singolo specifico valore P(X=x) è
uguale a 0
ma è evidente che valori appartenenti ad alcuni range sono più probabili di
altri
se si procede a raggruppare i dati in classi
E allora, la funzione cui la probabilità è sottesa prende il nome di
densità di probabilità
P( 1 8 0 < X < 1 8 5 )
0,07
• e la probabilità che X
assuma un valore nell’
intervallo compreso tra i
risultati x1 e x2 è uguale
all’ area che giace tra
questi due valori
0,06
P(180< X< 185)
P(X= dx)
0,05
P(X= dx)
. tabulate mosmoke
Madri fumatrici
(si'=1,no=0)|
Freq.
Percent
------------+-------------------------0 |
381
56.03
1 |
299
43.97
------------+-------------------------Total |
680
100.00
Non
esposti
0,04
0,03
0,02
0,01
0
15
150
151
152
153
154
155
156
157
158
169
160
161
162
163
164
165
166
167
168
179
170
171
172
173
174
175
176
177
178
189
180
181
182
183
184
185
186
187
188
199
190
191
192
193
194
195
196
197
198
9
50
Esposti
A ltezza (cm)
39
La distribuzione normale
E’ la distribuzione continua più comune, ed è nota anche
come
introducendo il carattere statistico Z
evento aleatorio con E(X)=µ=0 e σ=1
che è calcolato come:
La sua densità di probabilità è data dall’equazione:
1 ⎛ x − µ ⎞
⎟
σ ⎠
− ⎜
1
e 2⎝
2πσ
Z=
Traslazione:
-µ
σ
Schiacciamento:
/σ
µ la media della popolazione (il valore atteso)
σ la deviazione standard della popolazione
sono costanti π=3,14159 ed e =2.71828
-2 -1 0 1 2
-2 -1 0 1 2
-2 -1 0 1 2
La distribuzione normale standard
La distribuzione normale standard
X −µ
2
dove i parametri µ e σ, che definiscono completamente la
densità di probabilità, rappresentano:
Qualsiasi distribuzione normale può essere
riportata alla distribuzione standardizzata
operando una semplice trasformazione sui
dati
distribuzione Gaussiana
da Karl Frederich Gauss, professore di astronomia nell’
Università di Gottingen dal 1807 al 1855
curva “a campana”
per la sua forma unimodale e simmetrica intorno alla media µ
f (x) =
La distribuzione normale standardizzata
Valori più estremi di un certo z presentano una
densità probabilità pari all’ area sottesa alla
curva da quel valore fino all’ infinito
Per differenza, è possibile calcolare anche la probabilità
che un valore cada tra multipli della deviazione standard
σ
e cioè tra valori interi di z
0-1
p=0.341
0.5
1-2
p=0.136
0.4
0.3
2-3
p=0.022
0.2
3-4
p=0.0009
>4
p<0.0001
0.1
0
z>1 è p=0.159
z>2 è p=0.023
-5
-4
-3
-2
-1
0
1
2
3
4
5
40
mosmoke==0
Probabilità di una classe di eventi numerici
mosmoke==1
100
Mosmoke=0
Media:
mosmoke==0
3507
standard: 477
Deviazione
50
0
2000
3000
4000
5000
1000
2000
3000
4000
0
1000
2000
3000
4000
5000
1000
2000
3000
4000
5000
2500 − 3507
=
= −2.11
477
smosmoke0
Peso alla nascita (grammi)
Pr(peso<2500 | mosmoke0) = Pr(Z<-2.11) = 0.0174
5000
. by mosmoke: summarize pesonasc
-> mosmoke=
0 -> (figli di non fumatrice)
Variable |
Obs
Mean
Std. Dev.
Min
Max
---------+----------------------------------------------------pesonasc |
381
3507.535
477.3541
1497
5171
-> mosmoke=
1 -> (figli di fumatrice)
Variable |
Obs
Mean
Std. Dev.
Min
Max
---------+----------------------------------------------------pesonasc |
299
3284.341
490.7343
1996
4536
Z sottopes =
Distribuzioni di popolazione
si
riferiscono alla distribuzione di
caratteristiche in popolazioni definite
Distribuzioni campionarie
d e r i v a t e
dalle distribuzioni di
popolazione attraverso l’ osservazione
di più campioni tratti da una
popolazione
mosmoke==0
mosmoke==1
100
3284
standard: 491
50
Deviazione
0
1000
2000
xsottopes − xmosmoke0
smosmoke0
3000
4000
5000
1000
2000
3000
4000
5000
2500 − 3284
=
= −1.59
491
Peso alla nascita (grammi)
Histograms by Madri fumatrici
Pr(peso<2500 | mosmoke1) = Pr(Z<-1.59) = 0.0559
Histograms by Madri fumatrici
Distribuzioni in statistica
Mosmoke=1
Media:
Peso alla nascita (grammi)
50
Histograms by Madri fumatrici
1000
xsottopes − xmosmoke0
Frequency
Frequency
Z sottopes =
mosmoke==1
100
Frequency
Probabilità di una classe di
eventi numerici
Distribuzione campionaria della media
Si
prende in considerazione un campione di n
soggetti estratti a caso dalla popolazione di
riferimento e se ne calcola la media
Si prende in considerazione un secondo campione di
n soggetti estratti a caso dalla popolazione di
riferimento e se ne calcola la media
si ripete l’ operazione un numero m di volte
il risultato è una serie di m medie ottenute da
campioni di n soggetti
a questo punto, si considera ogni media come una
osservazione individuale e si studia la distribuzione
di frequenza di queste medie
41
200
Frequency
Distribuzione campionaria della media
Una distribuzione
campionaria
150
100
50
0
0
0
7
1
2
3
4
5
6
7
14
8
21
28
35
42
49
56
63
70
9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56
18.89
la
conoscenza delle proprietà delle distribuzioni
campionarie permette di trarre delle conclusioni
(inferenza statistica) a partire da un solo
campione
Media vera
Campioni casuali di 4 osservazioni
18 Medie del campione
11
13
15
33
16.75
11
15
21
25
24.25
5
21
29
42
22.75
11
21
25
34
22
14
21
25
28
19.25
21
19
16
14 15
in termini di evento aleatorio la media
delle n osservazioni raccolte per una serie di m
campionamenti sulla popolazione di riferimento
ha un proprio valore atteso (una media)
ed una propria varianza
46
16.5
17
9
19
21
22.5
12
16
28
34
28.75
18
E’ detta anche soltanto “distribuzione
campionaria”
Esprime
20.75
8
Ovviamente, non è necessario realizzare
ogni volta campioni multipli da una
popolazione
22
21.15
31
44
Media campionaria (media delle medie)
La deviata normale e le
distribuzioni campionarie
La distribuzione delle medie campionarie
Ha tre importanti proprietà:
La
sua media è uguale alla media µ della
popolazione generale
σ
La sua deviazione standard è uguale a
n
nota come errore standard della media
all’ aumentare di n si riduce la variabilità
La
forma della distribuzione campionaria è
approssimativamente normale, posto che n sia
sufficientemente grande
anche quando la distribuzione originaria
non era normale
teorema del limite centrale
la trasformazione in deviata normale era stata
definita come:
X −µ
Z =
σ
poiché
in questo caso ci troviamo di fronte ad una
distribuzione campionaria di medie, avremo che:
la media è la media della popolazione (µ’ = µ)
la deviazione standard è l’ errore standard (σ’ = σ/ √ n)
µ’=µ
X − µ'
Z =
σ'
Z =
X −µ
σ/ n
σ/ n
42
Cosa cambia tra distribuzione del
campione e distribuzione campionaria?
Gli intervalli di confidenza
Supponiamo di considerare una variabile per la quale la media
della popolazione è 140
Se non è noto il valore vero di µ, come
si può stimare a partire da un singolo
campione?
Stima “puntuale”
a sinistra vediamo la distribuzione del campione
e l’area rossa corrisponde alla probabilità di trovare per caso un
VALORE pari a 138 o minore (più estremo verso sinistra)
a destra vediamo la distribuzione campionaria
e l’area corrisponde alla probabilità di trovare per caso una
MEDIA pari a 138 o minore (più estremo verso sinistra) in un
campione casuale di 25 soggetti
la
media x.bar per un singolo campione è
utilizzata per stimare µ
ma non ci sono informazioni sulla variabilità
di questa stima
CAMPIONARIA
(medie di campioni)
CAMPIONE
(valori)
Stima “intervallare”
Intervallo di confidenza
Un
intervallo tale da essere sicuro (confidente) al 95% (o
al 90%, o al 99%) che esso includa il valore del parametro.
Gli intervalli di confidenza
Definizione frequentista
Ovvero:
Sulla
base delle osservazioni campionarie definisco un
intervallo (CLInf, CLSup) tale che, se:
il valore del parametro fosse minore di CLInf
io estraessi dalla popolazione un grande numero di campioni della
stessa numerosità
• non più del 2.5% delle stime campionarie sarebbe uguale o
maggiore del valore effettivamente osservato
Analogamente,
se il valore del parametro fosse maggiore di
CLSup, non più del 2.5% delle stime campionarie sarebbe
uguale o minore del valore effettivamente osservato
Intervallo di confidenza al 95% (o al 90%, o al 99%)
Stima “intervallare”
Un
intervallo di valori entro i quali si
ritiene sia compreso il parametro in esame
(µ) con un certo grado di “confidenza”
L’ intervallo di confidenza al 95% NON
esprime una probabilità del 95% che µ
sia compresa nel range
perché µ ha un suo valore, che già esiste
piuttosto
possiamo affermare che,
ripetendo gli esperimenti, degli n
intervalli calcolati, il 95% comprenderà
effettivamente µ
43
Come interpretare gli
Intervalli di Confidenza
Gli intervalli di confidenza
N=20
Va tenuto presente che lo stimatore X.bar è una variabile
aleatoria, mentre il parametro µ è una COSTANTE. Perciò,
l intervallo:
( X − 1.96 ⋅
N=100
N=5
Intervalli di confidenza al 95%, 90% 99%
n
σ
, X + 1.96 ⋅
n
)
è casuale ed ha un 95% di probabilità di comprendere µ
PRIMA che il campione venga scelto.
Visto che µ è una costante, una volta che il campione è
scelto e sono stati calcolati gli intervalli di confidenza
(utilizzando x.bar, la media calcolata, e non lo stimatore
teorico):
( x − 1.96 ⋅
σ
σ
n
, x + 1.96 ⋅
σ
n
)
µ fa parte dell intervallo oppure no. Non ci sono più
probabilità: l evento è certo o impossibile.
CI 95% - Media, N=20
-1.96
2.5%
2.5%
-4 SE
-3 SE
-2 SE
-1 SE
-1.645
-1.645 SE
mean
90%
mean
1 SE
2 SE
3 SE
+1.645
1.645 SE
4 SE
-1.96
-1.96 SE
-2.32
-2.32 SE
95%
mean
99%
mean
+1.96
-1.96 SE
95%
mean
+1.96
1.96 SE
1.96 SE
+2.32
2.32 SE
44
CI 95% - Media, N=100
-1.96
-1.96 SE
95%
mean
+1.96
1.96 SE
CI 99% - Media, N=100
-2.32
99%
+2.32
CI 90% - Media, N=100
-1.645
-1.645 SE
mean
mean
+1.645
1.645 SE
CI 90% - Media, N=20
-1.645
-1.645 SE
-2.32 SE
90%
90%
mean
+1.645
1.645 SE
2.32 SE
45
CI 99% - Media, N=20
-2.32
-2.32 SE
99%
mean
La distribuzione t di Student
+2.32
2.32 SE
Se la deviazione standard σ della
popolazione non è nota, non sempre è
corretto utilizzare la distribuzione
normale standard per il calcolo degli
intervalli di confidenza
si
utilizza allora la deviazione standard del
campione, s, e un’ altra distribuzione di probabilità
continua, la distribuzione t di Student
Introdotta dal matematico inglese William
Sealy Gosset (1876-1937), che pubblicava
articoli di statistica con lo pseudonimo di
“Student”
La distribuzione t di Student
Impossibile visualizzare l'immagine. La memoria del computer potrebbe essere insufficiente per aprire l'immagine oppure
l'immagine potrebbe essere danneggiata. Riavviare il computer e aprire di nuovo il file. Se viene visualizzata di nuovo la x
rossa, potrebbe essere necessario eliminare l'immagine e inserirla di nuovo.
La distribuzione t di Student
Partendo dall assunto che la popolazione
originaria da cui vengono i dati presenti
una distribuzione normale o quasi normale,
e sulla base di una serie di simulazioni e
calcoli, Gosset osserva:
Che l utilizzo di s (deviazione standard del
campione) per stimare
sigma (deviazione
standard della popolazione) introduce una
quantità aggiuntiva di incertezza
Impossibile
visualizzare
l'immagine. La
memoria del computer
potrebbe essere
insufficiente per aprire
l'immagine oppure
l'immagine potrebbe
essere danneggiata.
Riavviare il computer e
aprire di nuovo il file.
Se viene visualizzata di
nuovo la x rossa,
Motivo per cui t è più schiacciata di Z
e ha code più alte
L imprecisione dipende dalle dimensioni del
campione
All aumentare di N, t si avvicinerà a Z,
visto che la stima di sigma diventa via via
più precisa se il campione è più grande
46
Intervallo di confidenza con la
distribuzione t di Student
La distribuzione t di Student
in questo caso la trasformazione si modifica come segue:
Z=
X −µ
σ/ n
t
Z
-3 SE
-2 SE
-1 SE
0
1 SE
2 SE
3 SE
4 SE
-4 SE
-3 SE
-2 SE
-1 SE
0
1 SE
2 SE
3 SE
4 SE
-4 SE
-3 SE
-2 SE
-1 SE
0
1 SE
2 SE
3 SE
σ
n
)
( x − Z (1−α / 2) ⋅
σ
n
, x + Z (1−α / 2) ⋅
σ
n
)
s
s
, x + t( n−1,1−α / 2) ⋅
)
n
n
4 SE
Applichiamo la distribuzione t
di una media (7)
L intervallo calcolato da STATA in ci è calcolato
utilizzando la opportuna distribuzione t invece di Z
n
, x + 1.96 ⋅
( x − t( n−1,1−α / 2) ⋅
Intervallo di confidenza
σ
generalizzando
t
Z
t
Z
L intervallo del 95% di probabilità dovrà essere calcolato per
la specifica distribuzione t di riferimento, che sarà quella con
N-1 gradi di libertà
( x − 1.96 ⋅
N=100 è gl=99
N=10 è gl=9
Come si calcola allora un intervallo di
confidenza utilizzando la distribuzione t?
Per un campione casuale di dimensione n selezionato dalla
popolazione normale originaria, la distribuzione della
variabile aleatoria t è nota come distribuzione t di Student
con n-1 gradi di libertà
N=3 è gl=2
-4 SE
X −µ
t=
s/ n
E quindi per i dati visti in precedenza avremo:
N: 100, Media campione: 123.4, Deviazione standard campione: 14
Gradi di Libertà: 100-1= 99
Un campione davvero piccolo…
Immaginiamo di voler stimare la durata media (in minuti) di un intervento
chirurgico piuttosto inconsueto in un determinato ospedale.
sono state: 200, 240, 300, 410, 450, e 600 minuti. Cerchiamo l intervallo di
confidenza al 95%
La stima puntuale della media è:
La stima campionaria della deviazione standard è:
X = 366.6667
s = 149.3542
Distribuzione t
N=100, g.l.=99, C.I.=95%
. display invttail(99,.025)
1.984217
. display 123.4-1.984*(14/sqrt(100))
120.6224
. display 123.4+1.984*(14/sqrt(100))
126.1776
-1.984
95%
+1.984
-1.984 SE
0
1.984 SE
La stima dell errore standard è: ES = s/√n = 149.3542/√6 = 60.9736
I gradi di libertà sono:
gl = 6-1 = 5
Il valore della t è:
t(5,97.5%) = 2.571
Quindi, il limite inferiore è: X - (t) (ES) = 209.904
e il limite superiore è: X + (t) (ES) = 523.430
L intervallo di confidenza al 95% è: 209.904 ≤ m ≤ 523.430
Saremo pertanto confidenti al 95% che la durata media dell intervento
è tra i 210 e i 523 minuti
non che il 95% degli interventi dura tra i 210 e i 523 minuti!
47
Il test statistico di ipotesi
Applichiamo la distribuzione t
Un campione davvero piccolo…
Durata interventi chirurgici 200, 240, 300, 410, 450, e 600 minuti.
La stima puntuale della media è:
X = 366.6667
La stima campionaria della deviazione standard è:
s = 149.3542
Il valore della t è:
t(5,97.5%) = 2.571
L intervallo di confidenza al 95% è: 209.904 ≤ m ≤ 523.430
Se avessi usato Z, il C.I. 95% avrebbe usato 1.96
Il
principio del “rasoio di Occam”,
secondo cui:
E l intervallo sarebbe stato: 247.1606 ≤ m ≤ 486.1728
Distribuzione Z
Distribuzione t
-2.57
-2.57 SE
95%
0
è necessario adottare sempre la
spiegazione più semplice tra quelle
coerenti con i fatti noti
e solo quando sono presenti incoerenze
è giustificata l’ introduzione di una
spiegazione più elaborata e complessa
N=6, C.I.=95%
N=6, g.l.=5, C.I.=95%
+2.57
2.57 SE
-1.96
-1.96 SE
95%
0
+1.96
1.96 SE
Ipotesi nulla ed ipotesi alternativa
Il test statistico di ipotesi
L’ immaginazione umana non ha limiti nella
capacità di creare teorie e modelli per
descrivere la realtà
ma quale principio si segue nel decidere il
modello che meglio si attiene ai dati?
E’ esattamente questo principio che
viene applicato nel test di ipotesi in
statistica:
definisce la spiegazione più semplice
“Ipotesi nulla”
si verifica se i dati raccolti nel campione
disponibile sono compatibili con essa
si calcola, cioè, quanto sarebbe stato
probabile ottenere quei dati nel caso che
l'ipotesi nulla fosse vera
Si segue dunque, in statistica, il principio della
“dimostrazione inversa”:
se si intende proporre che due popolazioni siano diverse
non
potendosi dimostrare in via diretta la
diversità
si
si propone come ipotesi la loro uguaglianza
e si dimostra che tale ipotesi cade in contraddizione, è
incompatibile con i dati, rende i dati estremamente improbabili
definita
come “Ipotesi nulla” o H0
è
allora necessario accettare l’ “ipotesi
alternativa” HA
che altro non è che il reciproco di H0
• e cioè l’ ipotesi che le due popolazioni NON siano
uguali, cioè siano diverse
48
Un suggerimento per interpretare i
valori di p presentati in letteratura
Il livello di significatività
In quali casi riteniamo che le incongruenze tra l’ ipotesi nulla
ed i dati siano sufficienti a rifiutare l’ ipotesi nulla?
Per significatività statistica si intende una soglia arbitraria,
stabilita a priori, di probabilità che i dati derivino da una
realizzazione casuale dell’ Ipotesi nulla
dobbiamo introdurre il concetto di significatività statistica
che non necessariamente è sinonimo di significatività ad
esempio, clinica
se la probabilità che i dati derivino dall’ ipotesi nulla è inferiore
alla soglia
possiamo rifiutare l’ ipotesi nulla e accettare l’ ipotesi
alternativa
La soglia di significatività definisce dunque il limite sotto al
quale riteniamo accettabile la probabilità di commettere un
errore rifiutando l’ ipotesi nulla
1.0
Valore di p
Prove contrarie all ipotesi nulla deboli
0.1
Il valore di p si riduce: le prove
contro l ipotesi nulla si rafforzano
0.01
0.001
Prove schiaccianti contrarie all ipotesi nulla
0.0001
Da: Sterne JAC, Smith GD, Sifting the evidence-what s wrong
with significance tests? , BMJ, 322:226-231,2001
Logica del test di ipotesi
Il test di ipotesi può esser paragonato ad un
processo penale
la
giuria ha a disposizione delle “prove” sulla base delle
quali valutare
che l’ innocenza dell’ imputato non è compatibile con i
dati a disposizione
perché in assenza di sufficienti prove l’ imputato è da considerarsi
innocente
La
stessa situazione si verifica per l’ ipotesi che µ = µ0
Non colpevole
Giusto
Colpevole
Errato
Colpevole
Errato
Giusto
µ = µ0
µ ≠ µ0
H0 non rifiutata
Giusto
Errato
H0 rifiutata
Errato
Giusto
µ ≠ µ0
H0 non rifiutata
Giusto
Errato
H0 rifiutata
Errato
Giusto
L’ errore α esprime la probabilità di rifiutare l’ ipotesi nulla
quando questa è vera
α = P(rifiutare H0 |H0 è vera)
è un errore di sovrastima delle differenze tra il campione e la popolazione di
riferimento
Popolazione
Test
Innocente
Popolazione
µ = µ0
che vengono comunemente distinti come Errore α
(Errore di I tipo) ed errore β (Errore di II tipo)
Ed il campione costituisce gli elementi di prova
Imputato
Giuria
w Abbiamo visto che si
possono verificare due
situazioni di errore nei
test di ipotesi:
Test
Tipi di errore
ed è il livello di significatività
L’ errore β esprime la probabilità di non rifiutare l’ ipotesi
nulla quando questa è falsa
β = P(non rifiutare H0 | H0 è falsa)
è un errore di sottostima delle differenze esistenti
49
La Regione critica o Zona di rifiuto
Per ogni test statistico è possibile costruire
una distribuzione campionaria della probabilità
(o densità di probabilità) di osservare valori in
un certo range nel caso che l’ ipotesi nulla H0
sia vera
Zone di rifiuto Bilaterali e Unilaterali
H0 e HA
Definito il limite sotto al quale riteniamo
accettabile la probabilità di commettere un errore
rifiutando l’ ipotesi nulla
H0 : µ1 = µ0
HA : µ1 ≠ µ0
Il range di valori estremi che presentano una
densità di probabilità definita come accettabile (es.
p<0.05)
definito regione critica o zona di
rifiuto
p=0.05
P(z<Zs1)+P(z>Zs2) = α
P(z>Zs) = α
Quanti gruppi
distinguiamo?
La potenza è definita come 1-β
es µ0
variazione
nei parametri attesi nel campione
es. Diff.= µ1-µ0
Siamo interessati al
comportamento di quanti
caratteri statistici ?
1
H0 | H0 è falsa)
è dunque la probabilità complemento dell’ errore di
tipo II
e come β dipende da:
numerosità del campione
errore α
parametri della popolazione di riferimento
Scegliere un test
statistico
Partenza
La potenza è la probabilità di rifiutare l’
ipotesi nulla H0 quando essa è falsa
ed
Zs=+1.645
Zs2=+1.96
Zs1=-1.96
1 coda
p=0.025
p=0.025
La “potenza” di un test
potenza=P(rifiutare
H0 : µ1 ≤ µ0
HA : µ1 > µ0
p=0.05
2 code
è
es. esposizione al fumo
aumenta gli addotti
es. durata di degenza in due
ospedali è diversa
la soglia di significatività
Indicano una direzione:
Non indicano una direzione:
>2
2
1 binomiale
1 numerico
o ordinale
1 nominale
1 numerico
o ordinale
1
2
Il carattere che vogliamo
prevedere assume
modalità...
Che modalità
assumono ?
2 categorici
nominali
o binomiali
• Z- test
• T-test
2 numerici
numeriche
1 numerico
o ordinale
1 ordinale
• T-test 2 camp.
• Wilcoxon
• ANOVA
• Kruskal-Wallis
>2
NO
Correlazione
di Spearman
Test del
Chi quadro
Sono
distribuiti
normalmente?
SI
Correlazione
di Pearson
Regressione
multipla
binomiali
Regressione
logistica
50
Test di ipotesi: 1 solo campione e standard
SI
2 code
H0 : µ1 = µ0
HA : µ1 ≠ µ0
Confronto tra 1 campione ed uno
standard
NO
Qual è
l ipotesi nulla ?
H0 : µ1 ≤ µ0
HA : µ1 > µ0
σ/ n
X − µ0
t =
s/ n
X − µ0
Conosco
σ?
Test per 1 campione
Z =
SI
Z =
σ/ n
X − µ0
t =
s/ n
X − µ0
Conosco
σ?
1 coda
NO
Test z 2 code
p= P(z < -Zs)+P(z > Zs)
Test t 2 code
p= P(tn-1 < -ts)+P(tn-1 > ts)
Test z 1 coda
p = P(z > Zs)
Test t 1 coda
P = P(tn-1 > ts)
NB: X barrato è stimatore di µ1
Esempio n.1
La distribuzione delle pressioni diastoliche della popolazione
di donne diabetiche di età compresa tra 30 e 34 anni ha una
media µd non nota ed una deviazione standard σd = 9.1 mmHg.
Può essere utile ai medici sapere se la media di questa
popolazione è uguale alla pressione diastolica media di 74.4
mmHg della popolazione generale di donne di questa fascia di
età (µ0).
Qual è l’ipotesi nulla del test ?
Qual è l’ ipotesi alternativa ?
Si seleziona un campione casuale di 10 donne diabetiche; la loro
pressione diastolica media è x.barratod=84 mmHg. Utilizzando
questo dato, eseguite un test bilaterale ad un livello di
significatività α = 0.05. Qual è il valore p del test ?
Quale conclusione si può trarre dai risultati del test ?
La conclusione sarebbe stata diversa con α = 0.01 invece di α =
0.05 ?
Esempio n.1
La distribuzione delle pressioni diastoliche della popolazione di donne diabetiche di età compresa tra 30 e 34
anni ha una media µd non nota ed una deviazione standard σd = 9.1 mmHg. Può essere utile ai medici sapere se la
media di questa popolazione è uguale alla pressione diastolica media di 74.4 mmHg della popolazione generale di
donne di questa fascia di età (µ0).
uguale
Qual è l’ipotesi nulla del test ?
Qual è l’ ipotesi alternativa ?
Si seleziona un campione casuale di 10 donne diabetiche; la loro pressione diastolica media è x.barratod=84 mmHg. Utilizzando
questo dato, eseguite un test bilaterale ad un livello di significatività α = 0.05. Qual è il valore p del test ?
Quale conclusione si può trarre dai risultati del test ?
La conclusione sarebbe stata diversa con α = 0.01 invece di α = 0.05 ?
bilaterale
Test di ipotesi: 1 solo campione e standard
DATI
σdσd== 9.1
9.1mmHg
mmHg
n = 10
µ0 = 74.4 mmHg
x.barratod=84 mmHg
α(1) = 0.05
α(2) = 0.01
H0 : µ1 = µ0
HA : µ1 ≠ µ0
Qual è
l’ipotesi nulla ?
Ho ; Ha
p(1), p(2)
H0 : µ1 ≤ µ0
HA : µ1 > µ0
1 coda
SI
X − µ0
σ/ n
p= P(z < -Zs )+P(z > Zs )
t =
X − µ0
s/ n
p= P(t n-1 < -t s)+P(t n- 1 > t s )
Test t
2 code
Test z 1 coda
Z =
X − µ0
σ/ n
p = P(z > Zs )
t =
X − µ0
s/ n
P = P(t n-1 > ts )
Conosco
σ?
NO
2 code
Z =
Conosco
σ?
NO
QUESITI
Test z
SI
2 code
Test t
1 coda
NB: X barrato è stimatore di µ1
51
σd = 9.1 mmHg
σ
= 9.1 mmHg
dn = 10
µ0 = 74.4 mmHg
x.barratod=84 mmHg
α(1) = 0.05
α(2) = 0.01
uguale
bilaterale
Esempio n. 2
Esempio n.1
DATI
Dunque, dobbiamo eseguire:
un test Z
a due code
Qual è la zona di rifiuto?
QUESITI
Ho ; Ha
p(1), p(2)
Z =
α(2)=0.01
α(1)=0.05
σ/ n
X −µ
<-1.96
Z =
9.1 / 10
=
84 − 74.4
+3.33
> +1.96
<-2.57
> +2.57
Ho rifiutata
L’ infezione da Echinococcus canis è una malattia
parassitaria dei cani che talvolta viene contratta dagli
uomini. Tra gli uomini infetti, la distribuzione dei valori dei
globuli bianchi ha una media µ ed una deviazione standard σ
non note. Nella popolazione generale, i globuli bianchi sono in
media 7’250/mm3. Si ritiene che i soggetti infetti abbiano,
in media, un numero minore di globuli bianchi.
Quali sono le ipotesi nulla ed alternativa per un test
unilaterale ?
Per un campione casuale di 15 soggetti infetti, il numero
medio di globuli bianchi è x.barrato=4’767/ mm3 e la
deviazione standard è s=3’204/ mm3. Eseguire il test ad
α=0.05.
Che cosa si può concludere?
Ho rifiutata
Esempio n. 2
L’ infezione da Echinococcus canis è una malattia parassitaria dei cani che talvolta viene
contratta dagli uomini. Tra gli uomini infetti, la distribuzione dei valori dei globuli bianchi ha
una media µ ed una deviazione standard σ non note. Nella popolazione generale, i globuli
bianchi sono in media 7’250/mm3. Si ritiene che i soggetti infetti abbiano, in media, un
numero minore
minore di globuli bianchi.
Test di ipotesi: 1 solo campione e standard
DATI
Quali sono le ipotesi nulla ed alternativa per un testunilaterale
unilaterale ?
Per un campione casuale di 15 soggetti infetti, il numero medio di globuli bianchi è
x.barrato=4’767/ mm3 e la deviazione standard è s=3’204/ mm3. Eseguire il test ad α=0.05.
Che cosa si può concludere?
µ0 = 7250/mmc
n = 15
σσdd ==? ?
x.barratod=4767
s=3204
α = 0.05
H0 : µ1 = µ0
HA : µ1 ≠ µ0
Qual è
l’ipotesi nulla ?
Ho ; Ha
p
H0 : µ1 ≤ µ0
HA : µ1 > µ0
1 coda
X − µ0
σ/ n
Z =
Conosco
σ?
NO
QUESITI
Test z
SI
2 code
SI
X − µ0
s/ n
Z =
X − µ0
σ/ n
Conosco
σ?
NO
t =
X − µ0
s/ n
minore
unilaterale
2 code
p= P(t n-1 < -t s)+P(t n- 1 > t s )
Test z 1 coda
p = P(z > Zs )
Test t
1 coda
P = P(t n-1 > ts )
µ0 = 7250/mmc
n = 15
σσdd ==? ?
Dunque, dobbiamo eseguire:
x.barratod=4767
s=3204
α = 0.05
QUESITI
Esempio n. 2
DATI
un test t
ad una coda
Qual è la zona di rifiuto?
H0 : µ1 ≥ µ0
HA : µ1 < µ0
Ho ; Ha
p
p= P(z < -Zs )+P(z > Zs )
Test t
t =
2 code
t =
s/ n
X −µ
t =
α=0.05
3240 / 15
=
4767 − 7250
Gradi di libertà = n-1 =14
-2.95
<-1.761
Ho rifiutata
NB: X barrato è stimatore di µ1
52
Vantaggi
dei test non parametrici
Test parametrici e non parametrici
In statistica inferenziale, il confronto tra i dati di un
campione con una popolazione di riferimento o tra i dati
di due o più campioni possono essere realizzati per
mezzo di tecniche diverse, a seconda della tipologia dei
dati e di alcune assunzioni generali:
Se è ragionevole assumere che la distribuzione originaria dei
dati sia normale o possa comunque essere approssimata alla
normale (teorema del limite centrale)
Si realizza il confronto sui parametri che riassumono le
caratteristiche delle popolazioni o dei campioni (medie,
varianze)
TEST PARAMETRICI
• test basati sulle distribuzioni z e t
Se tale assunzione non è ragionevole, o non è corroborata dai
risultati di test preliminari di valutazione della distribuzione
Il confronto tra i gruppi si realizza indipendentemente
dai parametri della distribuzione
TEST NON PARAMETRICI
• test basati sulle intere distribuzioni, sul segno delle differenze o sulle
proprietà ordinali dei dati (ranghi)
Non implicano tutte le assunzioni restrittive
dei test parametrici
non richiedono che le popolazioni originarie
siano normalmente distribuite
L utilizzo dei ranghi rende queste tecniche
meno sensibili ad errori di misurazione rispetto
ai test tradizionali
e permette anche l utilizzo di misurazioni
ordinali piuttosto che continue
poiché non ha senso, su tali dati, calcolare una
media ed una deviazione standard, i test
parametrici non sono di solito appropriati
Svantaggi
dei test non parametrici
Se le assunzioni per il corrispondente test
parametrico sono soddisfatte
il test non parametrico è meno potente di
quello parametrico
se H0 è falsa, il test non parametrico richiede
un campione più ampio per rifiutarla
Le ipotesi testate con un test non parametrico
tendono ad essere meno specifiche di quelle
testate con i metodi tradizionali
poichè si basano sui ranghi invece che sui valori
reali
Esposizioni quali-quantitative ed
effetti quantitativi:
Correlazione e Regressione lineare singola e multipla
e
quindi non utilizzano tutte le informazioni note
di una distribuzione
53
Esposizioni ed Effetti
Esposizioni ed Effetti
esempi
Esposizione categorica ed effetto categorico
metodi
Esposizione categorica ed effetto categorico
Fumatore
vs Non fumatore & BPCO vs Non BPCO
Uso contraccettivo & Infarto
2x2: RA, RR, OR, RD, AR, Combined OR (tabelle
stratificate)
Regressione logistica: Adjusted OR (esposti/non esposti)
Esposizione numerica ed effetto categorico
Numero
di sigarette fumate & BPCO vs Non BPCO
Durata arresto cardiocircolatorio & Convulsioni vs Non
convulsioni
Tabelle
Esposizione categorica ed effetto numerico
Fumatrice
Esposizione numerica ed effetto categorico
Regressione
logistica: Adjusted OR (per incrementi di 1
unità nella “dose” di esposizione)
Esposizione categorica ed effetto numerico
vs Non fumatrice & peso feto alla nascita
a GnRH analogo & durata intervento
Esposizione
Esposizione numerica ed effetto numerico
Numero
di sigarette fumate & peso feto alla nascita
Numero di esami effettuati & durata degenza
Durata arresto cardiocircolatorio & punteggio indice PDI
Regressione lineare: Coefficienti angolari
“adjusted” (Incremento della media esposti/non esposti)
equivalente a ttest o ANOVA
Esposizione numerica ed effetto numerico
Regressione lineare: Coefficienti angolari
“adjusted” (Incremento della media per incrementi di 1
unità nella “dose” di esposizione)
Il coefficiente di correlazione
di Pearson
Il coefficiente di correlazione di
Pearson
Lo stimatore utilizzato per ρ è noto come:
coefficiente
ed
di correlazione di Pearson (r)
è calcolato come:
r=
La correlazione tra due variabili continue X e
Y rappresentate negli assi è indicata con ρ
r
r
che
può essere intesa come la media del prodotto delle
deviate normali standardizzate di X e Y
STATA:
y ⎞
⎟
⎠
non ha una unità di misura
può assumere valori da -1 a +1
⎡( X − µ x ) (Y − µ y )⎤
ρ = media ⎢
⎥
σ y ⎦
⎣ σ x
1 n ⎛ x i − x ⎞ ⎛ y i −
⎟ ⎜
∑ ⎜
n − 1 i =1 ⎝ sx ⎠ ⎝ s y
|1|
0
+
-
= correlazione massima
= correlazione minima
= correlazione positiva (proporzionali)
= correlazione negativa (inv. proporz.)
correlate var_1 var_2 … var_n oppure pwcorr var_1 var_2 … var_n
54
Il coefficente di correlazione
ha alcune limitazioni
Matrice
correlazione
Lunghezza (cm)
5171
Peso alla nascita
(grammi)
1497
Eta' gestazionale
(settimane)
Quantifica solo la forza della relazione
lineare tra due variabili
se
la relazione non è lineare, non fornisce una
valida misura dell’ associazione
42
Eta' della
madre (anni)
15
Altezza della
madre (cm)
43.2
58.4
29
48
145
prodotto
180
| lunghezz pesonasc settiman etamadre altmadre
----------+--------------------------------------------lunghezz |
1.0000
pesonasc |
0.7114* 1.0000
settiman |
0.3310* 0.4258* 1.0000
etamadre |
0.0049
0.0013
0.0034
1.0000
altmadre |
0.1779* 0.2051* 0.0485
0.0187
1.0000
Coefficiente di correlazione dei
ranghi di Spearman
Coefficiente di correlazione dei
ranghi di Spearman
Il coefficiente di correlazione di
Pearson, come altre tecniche
parametriche
è
molto sensibile alle osservazioni atipiche
Per ottenere una misura di
correlazione meno sensibile ad esse
è
possibile utilizzare un suo analogo non
parametrico , che invece dei valori assoluti
delle osservazioni considera
i
STATA:
ranghi delle osservazioni
spearman var_1 var_2 … var_n
delle deviate normali standard!
Non può essere estrapolato oltre i
valori osservati per le variabili
Una forte correlazione non implica una
relazione di causa-effetto
. pwcorr lunghezz pesonasc settiman etamadre altmadre, star(0.01)
E’ molto sensibile ai valori estremi
Si procede come segue:
i
dati vengono ordinati per ciascuna
variabile X,Y e viene definito un rango di
ogni osservazione secondo l una o l altra
delle variabili considerate (xr, yr)
si
calcola una r di Pearson per i ranghi di xr
e yr che si indica con rs
rs
si valuta secondo gli stessi riferimenti
dell r di Pearson
55
La regressione lineare semplice
Un modello di relazione lineare semplice
implica 4 assunzioni fondamentali:
La regressione lineare semplice si usa
per valutare la relazione tra due
variabili continue
L’
analisi di regressione e’ migliore
perchè:
La media di Y è una funzione ignota, ma
lineare, di x
La
variabilità di Y intorno alla sua
media è la stessa per tutti i valori di x
(omoscedasticità della varianza)
La distribuzione di Y intorno alla sua
media segue la distribuzione normale
Tutte le risposte sono indipendenti
ci
permette di studiare il valore previsto di una
variabile (variabile di outcome o di risultato)
per ogni livello dell’ altra variabile (variabile
esplicativa o predittiva o ”covariata”)
ci permette di stimare la variazione prevista
nella variabile di risultato
c o r r i s p o n d e n t e a d u n a d e t e r m i n a t a
variazione nella variabile esplicativa
Il modello regressione lineare
Un modello di regressione lineare semplice
µ
viene indicato come segue:
100
y|x
µy|x=
β0 + β1x
y
β1
δx=1
Laddove siano:
x
µy|x il valore medio di Y per un soggetto in studio
con una covariata pari a x
β0 e β1 i coefficienti dell’ equazione della retta:
β0 l’ intercetta (o costante), è il valore medio
della risposta Y per x=0
β1 la pendenza della retta, è la variazione in Y
che corrisponde ad una variazione di 1 unità in x
β0
systolic blood pressure
80
60
40
20
20
25
gestational age
30
35
56
Regressione lineare multipla
Invece di considerare
1
variabile di risultato, 1 variabile esplicativa
Consideriamo
1
Se mi interessa considerare nel modello variabili
categoriche, come mi comporto?
Non posso certo assegnare dei codici numerici alle
categorie ed inserirle nel modello
sola variabile di risultato, più variabili esplicative
µy|x= β0 + β1x1+ β2x2 + β3x3 …+ βqxq
Covariate categoriche (“Dummy variables”)
L’ intercetta β0 sarà in questo caso il valore medio di Y
quando tutte le variabili esplicative sono a 0
Ogni pendenza βj sarà la variazione in Y per un aumento
di 1 unità della corrispondente variabile xj, posto che
tutte le altre variabili siano costanti
Devo
costruire delle “Dummy variables” o
“Variabili indicatrici”
variabili binomiali possono esser inserite in un
modello di regressione lineare
=
=
=
=
=
680
92.53
0.0000
0.2147
0.2124
439.74
se x=0, il coeffiente è annullato
se x=1, il coefficente va a modificare l’ intercetta
Rappresentazione grafica di un
modello di regressione lineare
Un esempio di regressione lineare
Number of obs =
F( 2,
677)
Prob > F
R-squared
Adj R-squared
Root MSE
cioè devo trasformare, ad es., una variabile nominale
che assuma 3 diverse modalità in 2 variabili indicatrici
che assumono solo modalità binomiali
Le
“Aggiustamento” per le covariate
. regress pesonasc settiman mosmoke
Source |
SS
df
MS
---------+-----------------------------Model | 35786558.0
2 17893279.0
Residual |
130912791
677 193371.921
---------+-----------------------------Total |
166699349
679 245507.141
neppure nel caso di categorie ordinali, perchè non c’è
costanza nell’ intervallo di rapporti
pesnasns
pesnassm
5000
4000
-----------------------------------------------------------------------------pesonasc |
Coef.
Std. Err.
t
P>|t|
[95% Conf. Interval]
---------+-------------------------------------------------------------------settiman |
107.7179
9.042413
11.913
0.000
89.96336
125.4725
mosmoke | -183.0683
34.14107
-5.362
0.000
-250.1034
-116.0332
_cons | -794.1128
361.8053
-2.195
0.029
-1504.508
-83.71746
------------------------------------------------------------------------------
3000
2000
In questo semplice modello, noi stimiamo che:
Pesonasc= -794.1128 + 107.7179*settiman -183.0683*mosmoke
E cioè stimiamo che il valore del peso alla nascita aumenti di circa 108 grammi per ogni settimana in più
(a parità di stato di fumatore), e che l essere fumatrice della madre riduca il peso del nascituro di
circa 183 grammi (a parità di settimana di gestazione).
1000
30
35
40
45
Eta' gestazionale (settimane)
50
57
Interazioni
Può capitare che due variabili x1 e x2
si influenzino reciprocamente
è
necessario valutare nel modello un nuovo
componente
il prodotto di x1*x2 potrà essere testato
nel modello ed assumere un suo coefficiente
µy|x= β0 + β1x1+ β2x2 + β3(x1*x2) …+ βqxq
Un altro esempio di regressione lineare
. gen interact =age*sex
. regress fev age sex interact
Source |
SS
df
MS
---------+-----------------------------Model | 315.410417
3 105.136806
Number of obs =
F( 3,
650) =
Prob > F
=
654
389.37
0.0000
Residual | 175.509416
650 .270014487
---------+-----------------------------Total | 490.919833
653 .751791475
R-squared
=
Adj R-squared =
Root MSE
=
0.6425
0.6408
.51963
-----------------------------------------------------------------------------fev |
Coef.
Std. Err.
t
P>|t|
[95% Conf. Interval]
---------+-------------------------------------------------------------------age |
.1627289
.0099522
16.351
0.000
.1431865
.1822713
sex | -.7758666
.1427455
-5.435
0.000
-1.056164
-.4955686
interact |
.1107487
.013786
8.033
0.000
.0836782
.1378193
_cons |
.8494671
.1021995
8.312
0.000
.6487862
1.050148
------------------------------------------------------------------------------
FEV, età e sesso
model for males, model for f emales
6
Esposizioni quali-quantitative ed
effetti qualitativo:
4
Analisi dei dati categorici - Chi-quadro, Mantel-Haenszel,
Regressione logistica
2
0
0
5
10
age
15
20
58
La tabella di contingenza
Se esposizione e malattia sono indipendenti (cioè
non c’è una relazione tra loro) ci attendiamo che la
probabilità degli eventi intersezione sia:
Esposti
La tabella di contingenza
Questa prende il nome di
Se
stiamo studiando
“Tabella delle frequenze attese”
ad“Expected”
esempio, ci
( o soggetti,
E, dall’inglese
Non
esposti
una popolazione di 100
aspetteremmo che:
Esposti
Non
esposti
Malati
P(B ∩ A)
= 0,10
P(Bc ∩ A)
= 0,10
0,2
Malati
10
10
20
Non
malati
P(B ∩ Ac)
= 0,40
P(Bc ∩ Ac)
= 0,40
0,8
Non
malati
40
40
80
0,5
0,5
50
100
50
La tabella di contingenza
Questa prende il nome di
Ed invece nel campione di 100 soggetti da noi
“Tabella delle frequenze osservate”
raccolto
( o O,
dall’ingleseabbiamo
“Observed” osservato queste frequenze
assolute:
Esposti
Malati
16
Test del Chi quadrato (χ2)
Non
esposti
4
20
Potremmo formulare una ipotesi nulla ed
una ipotesi alternativa come segue:
H0:
p(B ∩ A) = p(B)*p(A) e cioè P(A|B) = p(A)
Ha:
p(B ∩ A) ≠ p(B)*p(A) e cioè P(A|B) ≠ p(A)
Come decidere se l’ipotesi nulla sia da
rifiutare?
Si
Non
malati
34
50
46
80
50
100
utilizza il test del Chi-quadrato
che ha l’obiettivo di stabilire se le differenze tra
le frequenze osservate e quelle attese sono troppo
grandi per essere attribuite al caso
le differenze nelle diverse celle vanno combinate
ed il valore ottenuto va confrontato con una distribuzione di
probabilità apposita, la distribuzione del χ2
59
Test del Chi quadrato (χ2)
Caselle nella tabella = r*c
(Oi − Ei ) 2
χ =∑
Ei
i =1
2
Test del Chi quadrato (χ2)
rc
Differenze tra
Osservati ed Attesi
in ogni casella
rc
χ2 = ∑
i =1
Attesi
in ogni casella
χ2 =
La distribuzione di probabilità di questa
sommatoria è approssimata da una
distribuzione detta del Chi-quadrato (χ2)
con (r-1)*(c-1) gradi di libertà
Test del Chi quadrato (χ2)
E se abbiamo solo la tabella a doppia entrata delle frequenze
osservate Oi ?
come ricalcolare rapidamente la tabella delle frequenze attese Ei?
E’ sufficiente moltiplicare il totale di riga corrispondente per il
totale di colonna corrispondente e dividere per il totale generale
come nell’ esempio:
Osservato
Osservato
Ecco un altro
esempio, relativo
a traumi cranici
Trauma
e protezione
dovuta al casco: Cranico
Si
No
Atteso
Carattere 1
Carattere 2
Si
No
Si
(C1*R1)/T
(C2*R1)/T
No
(C1*R2)/T (C2*R2)/T
Totale di colonna
a+c
b+d
C1
C2
a+b
R1
c+d
R2
Si
No
a
b
a+b
R1
R2
c
d
c+d
a+c
b+d
a+b+c+d
C1
C2
No
No
17
218
235
130
428
558
147
646
793
Si
Trauma
Cranico
T
Totale di riga
chi-quadrato
p
Totale generale
Si
Si
Casco protettivo
a+b+c+d
T
Casco protettivo
Atteso
Carattere 1
Carattere 2
= 8.1 + 8.1 + 2.025 + 2.025 = 20.25
p < 0.0001
Test del Chi quadrato (χ2)
(19 − 10) 2 (1 − 10) 2 (31 − 40) 2 (49 − 40) 2
+
+
+
10
10
40
40
χ2
esempio in questo caso
r*c = 2*2 = 4
Gradi di libertà della χ2 = (2-1) * (2-1) = 1
(O1 − E1 ) 2 (O2 − E2 ) 2 (O3 − E3 ) 2 (O4 − E4 ) 2
+
+
+
E1
E2
E3
E4
χ2 =
ad
(Oi − Ei ) 2
Ei
STATA:
No
Si
43,56
191,44
235
No
103,44
454,56
558
147
646
793
28,2555
1,1E-07
tabulate trauma casco, chi2
60
Test del Chi quadrato (χ2)
La tabella 2 x 2
Osservato
Il test può
essere
svolto
anche se i
caratteri
assumono
più di due
modalità:
Risposta
Scarso
Gruppo
Suffic.
A
35
78
140
253
B
23
95
120
238
58
173
260
491
Atteso
Malati
Risposta
Scarso
Gruppo
Suffic.
89,14
133,97
253
B
28,11
83,86
126,03
238
58
173
260
491
Non
malati
5,238
Fattore protettivo
20
46
80
50
100
La tabella 2 x 2
Ma possiamo anche considerare gli ODDs, rapporti
tra eventi tra loro esclusivi:
Esposti
Non
esposti
16
4
0
0
=0-
campo esistenza: 0-1
16/50 = 0.32
Rischio
Relativo
4/50 = 0.08
Proporzioni
Rischio assoluto per gli esposti
0.32/0.08
=
4
Malati
Rapporto
20
Malati esposti / Malati non esposti =
Odds per i malati
campo esistenza: 0-∞
Non
malati
0
0
1
0
34
50
Rischio Assoluto
per gli esposti
Rischio Assoluto
per i non esposti
4
Esposti malati / Esposti =
0,073
Il Rischio relativo (RR)
0-1
16
Rischio assoluto per i non esposti
Gradi di libertà = (2-1)*(3-1) = 2
0-1
Non
esposti
Buono
29,89
p=
Esposti
Non esposti malati / non esposti =
A
chi-quadrato
Se consideriamo un campione di 100 soggetti :
Buono
34
50
46
80
50
100
Non malati esposti / Non malati non esposti =
Fattore di rischio
Odds per i non malati
34/46 = 0.74
16/4 = 4
Rapporti
campo esistenza: 0-∞
61
L’ Odds Ratio (OR)
Qualcos’altro su OR
Odds
Ratio
0-∞
0-∞
Odds per i non malati
=04/0.74
=
5.4
Fattore protettivo
Gli esposti hanno 5.4 volte (4/0.74) il rischio dei non esposti
I non esposti hanno 0.18 volte (0.74/4) il rischio degli esposti
Qulache volta, conviene utilizzare il log odds ratio invece dell’odds
ratio.
Rapporto
campo esistenza: 0-∞
-4
-2
0
2
4
0
5
1
1
0
2
5
0
Lo
g
O dd
O dds
R
a tio
0
0
1
0
0
0
Odds per i malati
Gli OR tendono ad essere asimmetrici
Il log OR che confronta esposti e non esposti è log(1.44) = 1.68
Il log OR che confronta non esposti ed esposti è log(0.69) = -1.68
log OR > 0: Rischio aumentato (fattore di rischio)
log OR = 0: Nessuna differenza di rischio
log OR < 0: Rischio ridotto (fattore protettivo)
Fattore di rischio
Il confondimento
In ambito epidemiologico e di sanità
pubblica siamo interessati alla
associazione tra esposizone ed effetto
spesso di dover verificare che la nostra
analisi di associazione non sia distorta da una
terza variabile
correlata sia alla esposizione che all’ effetto
Definiremo questa variabile di confondimento
se si tratta di una variabile estranea che
soddisfa entrambe le seguenti condizioni:
E’ fattore di rischio per l’ effetto
E’ associata alla’esposizione, ma non ne è una
conseguenza
La stratificazione
Per controllare per i fattori di
confondimento possiamo utilizzare la
stratificazione. L’idea di base è:
Suddividiamo
il campione in strati
confronti all’interno degli strati
confrontando similia cum similibus
Ricombiniamo per una stima complessiva (overall)
Capita
Facciamo
Spesso la decisione se trattare o no una
variabile come confondente
è
legata a considerazione non statistiche, quali
la conoscenza della storia naturale di malattia
il giudizio soggettivo
una revisione della letteratura
62
Confondimento:
Confondimento: esempio
una definizione operativa
Se una analisi “cruda” ( “unadjusted”)
Shapiro et al. (Lancet, 1979) hanno
realizzato uno studio caso-controllo su
utilizzo
fornisce una risposta sostanzialmente diversa
da una analisi stratificata che controlli per la
variabile X,
X è un fattore di confondimento
e
Il confondimento non è tutto o nulla
è
un bias (distorsione) e le distorsioni possono
essere grandi o piccole
di contraccettivi orali (OC)
infarto del miocardio
stratificando per età
Età 30-39
Età 40-49
Infarto Controlli
Infarto Controlli
Uso recente di
SI
13
59
72
Uso recente di
SI
12
14
26
contraccettivi
NO
45
720
765
contraccettivi
NO
158
663
821
58
779
837
orali
170
677
847
orali
^OR1= 3.53
C’è associazione tra uso di OC e
Infarto, controllando per classi di età?
Confondimento: esempio
Età 30-39
Età 40-49
Infarto Controlli
Infarto Controlli
Confondimento: esempio
Uso recente di
SI
13
59
72
Uso recente di
SI
12
14
contraccettivi
NO
45
720
765
contraccettivi
NO
158
663
821
58
779
837
orali
170
677
847
orali
^OR1= 3.53
26
valore
(13 + 12) * (720 + 663)
= 2.33
(59 + 14) * (45 + 158)
ben inferiore agli ^OR strato-specifici
il che suggerisce, secondo la nostra defizione
operativa, che l’età sia un confondente
Infatti, l’età è associata sia con
l’effetto che con l’esposizione
nel
gruppo più anziano ci sono PIU’ infarti
170/847=0.201 contro 58/837=0.069
nel gruppo più anziano c’è MENO uso di OC
26/847=0.031 contro 72/837=0.086
ma l’età più avanzata non è una conseguenza
dell’ uso di OC
^OR2= 3.60
La stima dell’ OR “cruda” (unadjusted) è:
ORˆ =
^OR2= 3.60
Perciò, concluderemo che l’età è
fattore di confondimento della
associazione tra uso di OC e infarto
del miocardio
63
Stratificazione
Immaginiamo di suddividere la
popolazione in studio in strati
ogni strato considereremo una associazione
esposizione-effetto
avremo dunque numerose tabelle 2x2, una per
strato
Stratificazione
Se gli OR negli strati sono più o meno gli stessi
OR1~OR2~OR3~ORk~ OR*
stima di OR*m sarà una utiule misura della associazione
tra esposizione ed effetto nella intera popolazione
Una
per
Se invece i valori di OR differiscono
sostanzialmente tra gli strati
parleremo
di modificazione di effetto (in epidemiologia) o di
interazione (in statistica)
non sarà possibile stimare un valore riassuntivo per tutta la
popolazione
perchè l’effetto cambia nei doversi strati!
Se non c’è relazione tra esposizione ed
effetto
gli
OR calcolati per ogni strato saranno tutti =1
L’ipotesi nulla di non associazione è dunque
H0: OR1=OR2=OR3=Ork=1
La stratificazione può essere usata per:
controllare
Se c’è associazione positiva (fattore di
rischio) costante in ogni strato
descrivere
OR1>1, OR2>1, OR3>1, ORk>1
Una strategia per l’analisi di
tabelle 2x2 stratificate (1)
Confondimento ed interazione
Confondimento
E’
una distorsione sistematica della associazione esposizioneeffetto dovuta ad una terza variabile X, il fattore di
confondimento
Può talvolta essere controllato
con una analisi appropriata (analisi stratificata)
con un disegno apposito (matching)
E’ un bias e quindi va EVITATO!
Determinare i potenziali fattori di
confondimento o le variabili categoriche per
le quali il campione è stato stratificato
s u l l a
base delle conoscenze mediche ed
epidemiologiche
Dare un’occhiata agli ^ORi per avere una
idea della situazione
se
si ha un piccolo numero di strati con numerosi
soggetti ciascuno,
Modificazione di effetto (interazione)
la variazione della associazione esposizione-effetto per
livelli di una terza variabile, X, il modificatore di effetto
E’ una proprietà intrinseca del fenomeno esposizione-effetto
e non c’è disegno che la possa evitare se c’è
E’ un fenomeno interessante, e quindi va DESCRITTO!
per i fattori di confondimento
l’interazione (modificatori di effetto)
E’
Svolgere il test di non associazione di
Mantel-Haenszel
se
non sono evidenti interazioni qualitative (alcuni
^ORi >1 ed altri < 1)
64
Una strategia per l’analisi di
tabelle 2x2 stratificate (2)
Svolgere un test di omogeneità
per
valutare se si può ritenere comune l’OR tra gli
strati
esempio il test di Woolf per l’omogeneità di un
piccolo numero di strati numerosi
Stima dell’OR combinato secondo M-H
Se non ci sono elementi per rifiutare
l’assunzione di un OR comune
può
essere in pratica considerato una media
ponderata degli OR strato-specifici
stimarlo
con lo stimatore di Mantel-Haenszel, e
stimare i relativi intervalli di confidenza
Lo stimatore di Mantel-Haenszel
Lo stimatore di Mantel-Haenszel dell’
OR combinato lavora bene
sia
per un piccolo numero (K) di strati numerosi
per un grande numero di strati piccoli
che
Se invece si rifiuta l’assunzione di
omogeneità degli OR
è
necessario riportare OR e intervalli di confidenza
separati per ogni strato
La regressione logistica
La regressione logistica
Se la variabile che misura l’effetto, è
binomiale, possiamo estendere i metodi
della regressione per “prevederla”?
Se
applichiamo la regressione lineare
abbiamo un problema
il
valore previsto può essere inferiore a 0 o
maggiore di 1
Ci serve allora un’altra funzione, che sia vincolata
a non oltrepassare 0 e 1
Ma cosa possiamo prevedere?
Non
tanto il valore della variabile di effetto, quanto
la probabilità che essa assuma uno dei due valori
possibili (1-> l’effetto verificato)
Potremmo prendere in considerazione
una quantità L che sia una funzione
lineare del valori assunto dal fattore di
rischio considerato:
L=β0+
β1 x1
Ed operare su di essa una
trasformazione che produca una
quantità obbligata a non assumere
valori esterni all’intervallo 0-1
un
trasformazione logistica:
y = Pr(effetto | L) =
1
1 + e−L
65
La regressione logistica
Infatti, se L=0, avremo:
y = Pr(effetto | L) =
y = Pr(effetto | L) =
1
1
=
= 0.5
1 + e0 1 + 1
Se L va ad ∞, avremo:
E con alcuni passaggi, arriviamo
facilamente a:
y = Pr(effetto | L) =
1
1 + e−L
1
1 + e−L
1
1
= =1
1 + e −∞ 1
y = Pr(effetto | L) =
(1 − y )
= e −( β0 + β1x1 )
y
1
1 + e −( β0 + β1x1 )
p/(1-p)=odds!
E se L va a - ∞, avremo:
y = Pr(effetto | L) =
1
1
=
=0
1 + e∞ 1 + ∞
La regressione logistica
La regressione logistica si utilizza per
costruire un modello della probabilità che si
verifichi una certo risultato binario in
funzione di una serie di variabili che si ritiene
siano collegate al fenomeno (covariate)
Regressione logistica semplice:
exp(β0 + β1 x)
px =
1 + exp(β0 + β1 x)
La regressione logistica
Regressione logistica multipla:
px =
exp(β0 + β1 x1 + β 2 x2 + ... + β q xq )
1 + exp(β0 + β1 x1 + β 2 x2 + ... + β q xq )
⎡ y ⎤
log⎢
⎥ = β 0 + β1 x1
⎣ (1 − y ) ⎦
⎡ Pr(eff | L) ⎤
log⎢
⎥ = β 0 + β1 x1
⎣ (1 − Pr(eff | L)) ⎦
I parametri nella regressione logistica
Calcolo
La
stima avviene attraverso un
procedimento matematico ricorsivo
(maximum likelihood), non può essere
fatto a mano
Significato
I
coefficenti β corrispondono al
logaritmo degli Odds Ratio che
confrontano i soggetti esposti con i non
esposti (o l’esposizione “baseline”)
e dunque: OR = exp(β)
66
Odds Ratio: problemi
Gli OR sono difficili da comprendere direttamente
e sono solitamente interpretati come equivalenti
del Rischio Relativo
Vantaggi della regressione logistica
Deeks J, Letters to the Editor, BMJ, 317: 1155, 1998
Si può operare un aggiustamento per più fattori di
confondimento contemporaneamente
Si possono considerare sia covariate qualitative che
quantitative
Si possono testare direttamente le interazioni
(modificatori di effetto)
Si possono valutare i possibili fattori di
confondimento
Si ottengono stime puntuali ed intervalli di
confidenza degli OR
Matematicamente conveniente se si ha un software
adatto
Svantaggi della regressione logistica
Un esempio di regressione logistica
Tuttavia,
va ricordato che gli OR non approssimano
bene il RR quando il rischio iniziale (la prevalenza o
l’incidenza del fenomeno di interesse) è alto
sovrastimano la dimensione del rischio, sia in senso
negativo che protettivo
Davies HTO, Crombie IK, Tavakoli M, When can odds ratios
mislead?, BMJ, 316: 989-991, 1998
Le uniche situazione sicure in cui utilizzare gli OR
sono gli studi caso-controllo e le regressioni
logistiche, situazioni in cui essi consentono le
migliori stime possibili del Rischio Relativo
E’ astratta e matematica
Può creare una barriera tra il ricercatore ed i dati
ci
si potrebbe trovare a migliore agio valutando i risultati di
un metodo classico (es. Mantel-Haenszel)
Fa assunzioni implicite, delle quali può esser
difficile verificare l’applicabilità
Molti modelli potrebbero “fittare” bene, e non è
facile scegliere
Possibilità di troppa fiducia nei risultati
“Ho
fatto una analisi estensiva sul computer: allora le mie
conclusioni sono corrette”
. logistic
lowbwt
gestwks
Logit Estimates
Log Likelihood = -123.84356
mothsmok
Number of obs
chi2(2)
Prob > chi2
Pseudo R2
=
680
= 62.09
= 0.0000
= 0.2004
-----------------------------------------------------------------------------lowbwt | Odds Ratio
Std. Err.
z
P>|z|
[95% Conf. Interval]
---------+-------------------------------------------------------------------gestwks |
.5432452
.0508903
-6.514
0.000
.4521233
.6527322
mothsmok |
2.697852
1.005295
2.663
0.008
1.29968
5.600151
-----------------------------------------------------------------------------. logit
Logit Estimates
Log Likelihood = -123.84356
Number of obs
chi2(2)
Prob > chi2
Pseudo R2
=
680
= 62.09
= 0.0000
= 0.2004
-----------------------------------------------------------------------------lowbwt |
Coef.
Std. Err.
z
P>|z|
[95% Conf. Interval]
---------+-------------------------------------------------------------------gestwks | -.6101944
.0936783
-6.514
0.000
-.7938004
-.4265884
mothsmok |
.9924558
.3726281
2.663
0.008
.262118
1.722794
_cons |
20.41724
3.588344
5.690
0.000
13.38421
27.45026
------------------------------------------------------------------------------
67
Regressione lineare e logistica:
Rappresentazione grafica del modello
probsmo2
alcuni suggerimenti
probnsm2
1
Non sempre conviene utilizzare una
variabile numerica come tale
se
il suo comportamento non è lineare,
spezzarla in classi (ed analizzarla come più
variabili “dummy”) aiuta ad avere risultati più
attendibili
Come decidere le classi?
.5
Valori rilevanti di letteratura
Classi di eguale ampiezza
Gruppi di eguale numerosità
• quartili, quintili
0
30
35
40
Gestational age (weeks)
45
50
Regressione lineare e logistica:
Regressione lineare e logistica:
scelta del modello
Valutare modelli di regressione è una operazione
complicata
Può essere necessario considerare molte covariate
e le interazioni tra loro
per avere risultati attendibili bisogna avere
almeno 10 osservazioni per ogni variabile considerata nel
modello (ogni interazione è una nuova variabile…)
scelta del modello
modelli
ricordate,
E’ talvolta necessario considerare trasformazioni
dei dati, relazioni non lineari
Bisogna partire da strutture semplici e poi
complicare via via
facendosi
guidare dalle conoscenze sull’argomento, dal buon
senso e dai risultati dei test formali
Il primo passo utile è fare uno “screening”
attraverso una analisi “univariata”
che considerano 1 sola covariata
Hosmer e Lemeshow consigliano di prendere in
considerazione le variabili che in questa fase hanno un
coefficiente con un p<0.25
E poi costruire un modello multivariato che
includono tutte le variabili considerate rilevanto
nella IPOTESI formulata e le variabili che hanno
superato lo “screening” univariato
Quando ci sembra di essere vicini ad un modello
finale
cominciamo
a testare le interazioni, le trasformate, i
termini “quadratici”, ecc.
68
Regressione lineare e logistica:
scelta del modello
NON esiste UN SOLO modello finale!
Si
può arrivare a più soluzioni logiche, plausibili e
supportate dai dati
Bisgna usare attenzione, logica, buon senso e
plausibilità biologica nel costruire un modello
ma
bisogna anche saper essere “creativi”
la scelta dei modelli è altrettanto “arte” quanto
“scienza”
La significatività statistica non è l’unica ragione
per la quale vale la pena di mantenere una variabile
nei modelli definitivi
le
variabili “essenziali” (l’esposizione “principale”, i
confondenti noti, ecc.) vanno mantunuti nel modello
comunque!
N. Agabiti, C.
Ancona, S.
Ferro, G.
Cesaroni, V. De
Pascali, C.
Saitto, M.
Arcà, F.
Forastiere, C.A.
Perucci
DIFFERENCES
OF INHOSPITAL
MORTALITY
ASSOCIATED
WITH
CORONARY
ARTERY
BYPASS
GRAFT
SURGERY,
ROME 1996
Epidemiologia e
Prevenzione,
23: 17-26, 1999
N. Agabiti, C.
Ancona, S. Ferro,
G. Cesaroni, V. De
Pascali, C. Saitto,
M. Arcà, F.
Forastiere, C.A.
Perucci
DIFFERENCES OF
IN-HOSPITAL
MORTALITY
ASSOCIATED
WITH CORONARY
ARTERY BYPASS
GRAFT SURGERY,
ROME 1996
Epidemiologia e
Prevenzione, 23:
17-26, 1999
N. Agabiti, C.
Ancona, S. Ferro, G.
Cesaroni, V. De
Pascali, C. Saitto, M.
Arcà, F. Forastiere,
C.A. Perucci
DIFFERENCES OF
IN-HOSPITAL
MORTALITY
ASSOCIATED
WITH CORONARY
ARTERY BYPASS
GRAFT SURGERY,
ROME 1996
Epidemiologia e
Prevenzione, 23:
17-26, 1999
69
N. Agabiti, C. Ancona, S. Ferro, G. Cesaroni, V. De Pascali, C. Saitto, M. Arcà, F. Forastiere, C.A. Perucci
DIFFERENCES OF IN-HOSPITAL MORTALITY ASSOCIATED WITH CORONARY ARTERY BYPASS GRAFT SURGERY, ROME 1996
N. Agabiti, C. Ancona,
S. Ferro, G. Cesaroni,
V. De Pascali, C.
Saitto, M. Arcà, F.
Forastiere, C.A.
Perucci
Epidemiologia e Prevenzione, 23: 17-26, 1999
DIFFERENCES OF
IN-HOSPITAL
MORTALITY
ASSOCIATED WITH
CORONARY ARTERY
BYPASS GRAFT
SURGERY, ROME
1996
Epidemiologia e
Prevenzione, 23:
17-26, 1999
70