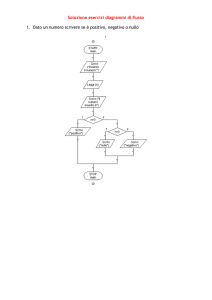
Matematica Discreta II
Lezione del giorno 22 novembre 2007
Algoritmo di fattorizzazione di Pollard.
Premettiamo alcune considerazioni su un argomento di Calcolo delle Probabilità: il cosiddetto
paradosso dei compleanni.
Siano n,m numeri naturali , S un insieme finito di cardinalità m e sia data una successione finita di n
termini scelti in S (anche non distinti):
a1, a2, ……, an
in modo che gli ai siano scelti random in modo “uniforme” (dal punto di vista della probabilità) fra
gli elementi di S, nel senso che per ogni indice i, ogni elemento dell’insieme S abbia la stessa
probabilità 1/m di essere scelto come elemento ai : un esempio concreto si ha inserendo in un’urna
m palline numerate da 1 ad m, fisicamente identiche, ed estraendo casualmente in successione n
palline reinserendo ad ogni estrazione la pallina estratta nell’urna.
Calcoliamo la probabilità che almeno 2 degli elementi della successione coincidano.
Se n>m ovviamente è certo che ciò avverrà, quindi supponiamo nm.
Calcoliamo dapprima la probabilità che tutti gli elementi della successione siano distinti.
Fissato a1, la probabilità che a2 sia diverso da a1 è (m-1)/m; fissati a1,a2 distinti, la probabilità che a3
sia diverso da a1 e da a2 è (m-2)/m , quindi la probabilità che a1, a2, a3 siano tutti distinti è il
prodotto [(m-1)/m][(m-2)/m]=(m-1)(m-2)/m2.
Iterando il ragionamento si ottiene che la probabilità che a1, a2, ….., an siano tutti distinti è:
[(m-1)(m-2)…..(m-n+1)]/mn-1
dunque la probabilità che almeno 2 degli elementi a1, a2, ….., an coincidano è una funzione delle
variabili n,m, data da:
p=p(n,m)=1-[(m-1)(m-2)…..(m-n+1)]/mn-1 (sempre nell’ipotesi nm)
Con ragionamenti analitici, sfruttando lo sviluppo in serie di Taylor della funzione ex, si ottiene che
una buona approssimazione per p(n,m) è:
p(n,m) 1 e
n2
2m
da cui si ricava che, fissato m e fissato un valore di probabilità p con 0<p<1, il numero n degli
elementi di una successione per i quali la probabilità che fra essi almeno 2 coincidano è
approssimativamente:
1
)]
n 2m[log e (
1 p
In particolare per esempio se fissiamo una probabilità del 50% (p=0.5), si ottiene n 1,77 m ,
mentre se se fissiamo una probabilità del 90% (p=0.9), si ottiene n 2,14 m .
Dunque scegliendo in modo “random” una successione di elementi dell’insieme S di cardinalità m:
a1, a2, a3, ………………..
il minimo indice n per cui l’elemento an coincide con almeno uno degli elementi che lo precedono è,
dal punto di vista probabilistico, di ordine di grandezza uguale a quello di m .
Un’applicazione di tale teoria é appunto il cosiddetto “paradosso dei compleanni”: se sono scelte
random un numero n di persone con n<365, la probabilità che almeno 2 fra esse compiano gli anni
nello stesso giorno e mese dell’anno è 1 e
n2
730
; inoltre, fissato un valore di probabilità p con
0<p<1, il numero n di persone (scelte random) per le quali la probabilità che fra esse almeno 2
1
)]
compiano gli anni nello stesso giorno e mese dell’anno è 730[log e (
1 p
(tutto questo supponendo che giorno e mese di nascita degli esseri umani siano distribuiti in modo
uniforme fra i 365 giorni dell’anno, il che non è vero in pratica).
Per esempio se la probabilità fissata è del 50% (p=0,5), n 730[log e 2 ] 23: scegliendo 23
persone in modo random, la probabilità che fra esse almeno 2 compiano gli anni nello stesso giorno
e mese dell’anno è 50% (abbastanza paradossale…..).
Scegliendo invece 50 persone in modo random, la probabilità che almeno 2 fra esse compiano gli
anni nello stesso giorno e mese dell’anno è addirittura 97%.
Introduciamo ora l’ Algoritmo di fattorizzazione di Pollard.
Fa parte di una famiglia di algoritmi di fattorizzazione che generano, a partire da un “seme”,
particolari successioni numeriche che vengono trattate come successioni di numeri casuali, anche se
a rigor di termini solo il “seme” può essere definito casuale.
Il metodo di Pollard si basa sulle seguenti considerazioni.
Siano dati un numero naturale m, un insieme finito S di cardinalità m, una funzione f : S S e la
successione ottenuta per iterazione dell’azione di f, a partire da un seme casuale sS:
s=f(0)(s), f(s)=f(1)(s), f(f(s))=f(2)(s),……, f(i)(s)=f(f(i-1)(s)),…..
Supponiamo anche che gli elementi di S siano uniformemente distribuiti (dal punto di vista
probabilistico) nella successione.
Poiché S é finito, gli elementi della successione f(i)(s) non possono essere tutti distinti, quindi
esisterà una coppia di indici j,k con 0j<k tali che f(j)(s)=f(k)(s), e se supponiamo k minimale
sappiamo, dalla teoria del “paradosso dei compleanni”, che k ha lo stesso ordine di grandezza di
m.
Allora la successione diventa ciclica con “periodo” k-j, nel senso che dal termine di indice j in poi i
termini coincidono ogni k-j posizioni.
Per esempio se j=3, k=9, la successione diventa ciclica con periodo 6 dal termine di indice 3 in poi:
f(3)(s)=f(9)(s), f(4)(s)=f(f(3)(s))= f(f(9)(s))=f(10)(s), e così via f(5)(s)=f(11)(s), f(6)(s)=f(12)(s), f(7)(s)=f(13)(s),
f(8)(s)=f(14)(s), f(9)(s)=f(15)(s)=f(3)(s), f(10)(s)=f(16)(s)=f(4)(s) etc.
Dall’indice j in poi, due qualunque termini della successione, i cui indici differiscano per un
multiplo di k-j (cioè i cui indici siano congrui modulo k-j), coincidono fra loro.
Rappresentando graficamente la situazione, si ottiene un disegno di struttura simile a quella della
lettera greca .
Nell’esempio precedente con j=3, k=9, periodo=k-j=6, la struttura grafica è la seguente:
f(5)(s)= f(11)(s)
f(4)(s)= f(10)(s)
f(3)(s)= f(9)(s)
f(2)(s)
f(6)(s)= f(12)(s)
f(7)(s)= f(13)(s)
f(8)(s)= f(14)(s)
f(1)(s)
f(0)(s)
Supponiamo dunque di volere fattorizzare un numero intero n>1 (non primo), cercando un divisore
non banale di n.
Sia p un fattore primo minimale di n (ovviamente a priori il valore di p non è noto), e poniamo
S={0,1,2,…,p-1}.
Fissiamo un polinomio a coefficienti interi non negativi g(x) (nei casi concreti spesso g(x) è della
forma g(x)=x2+a).
Consideriamo la funzione f : S S definita per ogni bS da f(b)=g(b)modp (dunque si calcola il
valore del polinomio g(x) nell’elemento bS e si riduce il risultato modulo p). Dato un seme
casuale sS, possiamo come sopra costruire la corrispondente successione f(i)(s).
Supponiamo che gli elementi di S siano distribuiti uniformemente (dal punto di vista probabilistico)
nella successione (sperimentalmente si è visto che la scelta di polinomi della forma (x 2+a)
garantisce spesso una distribuzione “abbastanza” uniforme).
Per il ragionamento precedente esisteranno indici j,k con 0j<k (con k avente lo stesso ordine di
grandezza di p ) tali che f(j)(s)=f(k)(s), ed inoltre comunque dati gli indici s,rj con sr (mod k-j) si
avrà f(s)(s)=f(r)(s).
Ovviamente, non essendo il fattore primo p a priori conosciuto, non possiamo calcolare
esplicitamente la successione f(i)(s), né gli indici j,k.
Definiamo allora, dato T={0,1,2,……,n-1}S, la funzione F : T T definita per ogni bT da
f(b)=g(b)modp (dunque si calcola il valore del polinomio g(x) nell’elemento bT e si riduce il
risultato modulo n), e costruiamo la successione relativa:
s=F(0)(s), F(s)=F(1)(s), F(F(s))=F(2)(s),……, F(i)(s)=F(F(i-1)(s)),…..
(questa effettivamente calcolabile).
Poiché p è divisore di n, per ogni bST da F(b)g(b) (mod n) segue F(b)g(b) (mod p), e dunque
F(b)f(b) (mod p).
Si deduce in particolare che F(i)(s)f(i)(s) (mod p), per ogni indice i0.
Relativamente agli indici j, k indicati sopra, si ha allora F(j)(s)F(k)(s) (mod p), e comunque dati gli
indici s,rj con sr (mod k-j) si ha F(s)(s) F(r)(s) (mod p).
In particolare allora p è divisore comune di n e della differenza F(j)(s)-F(k)(s) (che supponiamo non
negativa: in caso contrario utilizziamo la differenza opposta F(k)(s)-F(j)(s) ) .
Tale differenza è in ogni caso <n (perché F(j)(s),F(k)(s) sono <n essendo elementi di T).
Se tale differenza è 0 (cioè se F(j)(s)=F(k)(s)) non abbiamo alcuna informazione.
Ma se F(j)(s)-F(k)(s) >0, si ha che p è divisore comune di F(j)(s)-F(k)(s) e di n, dunque p è divisore del
mcd(F(j)(s)-F(k)(s) ,n)=d, ossia lo stesso d è un divisore di n con d>1 (perché p divide d) e con d<n
(perché d divide F(j)(s)-F(k)(s)<n): abbiamo in tale caso risolto il problema di fattorizzare n, trovando
un suo divisore non banale d.
Se conoscessimo i valori degli indici j,k, potremmo dunque implementare un algoritmo in cui:
- scegliamo il seme casuale s con 0sn-1 per la successione F(i) (supponendo che il seme della
corrispondente successione f(i) sia la riduzione di s modulo p)
- calcoliamo i numeri F(j)(s),F(k)(s)
- se F(j)(s)=F(k)(s) allora l’algoritmo fallisce, e si può tornare alla scelta casuale del seme s,
modificando tale scelta, e reiterando l’algoritmo, per cercare di trovare un divisore non banale di n.
Però, come già detto, non conosciamo j,k.
Possiamo però implementare l’algoritmo facendo variare in tutti i modi possibili le coppie di indici
a,b con 0a<b, e per ogni coppia studiare i valori F(a)(s),F(b)(s) nel modo sopra indicato, con
l’aspettativa di arrivare alla coppia corretta a=j, b=k in un numero di passi dello stesso ordine di
grandezza di p 2=p (perché si tratta di coppie di numeri k, e l’ordine di grandezza di k è quello di
p ).
Ma essendo p fattore primo minimale di n, si ha p n , quindi l’algoritmo avrebbe un’efficienza
non migliore dell’algoritmo “ingenuo” di ricerca di un divisore non banale di n (ricerca effettuata
testando tutti i naturali da 2 a n ).
Ma possiamo migliorare molto l’efficienza dell’algoritmo con il seguente ragionamento.
Sia m il minimo naturale multiplo di k-j che sia j; allora F(m)(s)F(2m)(s) (mod p) (perché m,2mj, e
perché 2mm (mod k-j)) dunque, come detto sopra, si ha che d=mcd(F(m)(s)-F(2m)(s),n) è un divisore
non banale di n, a patto che sia F(m)(s)F(2m)(s).
Possiamo notare che certamente mk (perché se fosse per assurdo m>k, allora t=m-(k-j)=(m-k)+j
sarebbe un multiplo di k-j, con tj , e con t<m, contro la minimalità di m).
Dunque possiamo implementare una versione molto più efficiente dell’algoritmo facendo variare
semplicemente l’indice i=1,2,….. e per ogni valore di i studiare i valori F(i)(s),F(2i)(s) nel modo
sopra indicato (verificando se essi coincidono), con l’aspettativa di arrivare al valore corretto i=m in
un numero di passi dello stesso ordine di grandezza di p (perché mk, e k ha come detto lo stesso
ordine di grandezza di p ), dunque dello stesso ordine di grandezza di 4 n , il che rappresenta un
significativo miglioramento nell’efficienza (anche se la complessità resta esponenziale nella taglia
dell’input n).