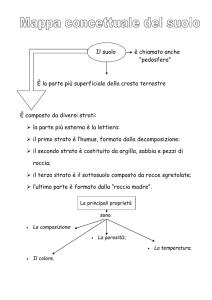
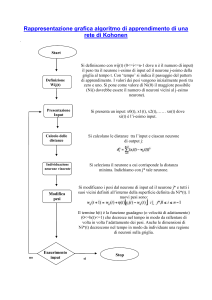
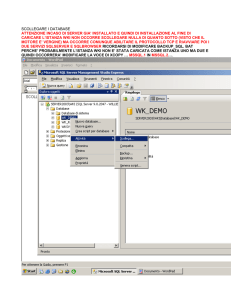
RETI NEURALI
ARTIFICIALI
RN-1
• Le reti neurali sono “learning machine” generali, adattative, non
lineari, distribuite, costituite da molti processori elementari (PE)
• I segnali che fluiscono attraverso le connessioni sono scalati con
opportuni parametri modificabili detti pesi (wij)
• Il singolo PE somma tutti questi contributi e produce un’uscita
che è una funzione non lineare di tale somma
PROCESSORE ELEMENTARE
x1
w1
x2
w2
y
f(.)
...
xD
S
wD
D
y f wi xi
i 1
Esempio di RNA:
x1
PE
w1
x2
w4
w3
w2
w5
PE
w6
RN-2
•
•
•
•
•
•
La forma della funzione discriminante cambia con la topologia
Funzioni discriminanti arbitrarie
Classificatori ottimi
La posizione delle funzioni discriminanti è regolata dai valori dei pesi
I pesi vengono adattati automaticamente durante il training
Sui dati disponibili per il training non deve essere fatta alcuna
ipotesi sulla pdf
P2
x21
x22
.
.
.
x2M
P1
x11
x12
.
.
.
x1M
Rete
Neurale
(wij)
Y2
Y1
y21
y22
.
.
.
y2M
y11
y12
.
.
.
y1M
-
+
S
E2
e21
e22
.
.
.
e2M
E1
E11
E12
.
.
.
E1M
D2
d21
d22
.
.
.
d2M
Il progettista deve stabilire la “topologia” per ottenere il
numero e la forma voluti delle funzioni discriminanti
D1
d11
d12
.
.
.
d1M
Pocessore Elementare di McCULLOCH - PITTS RN-3
( PE di MP o MP-PE )
+1
b
xD
...
x1
S
w1
wD
net
y = f(net)
wi : pesi
b: bias
1 se net 0
f net
1 se net 0
D
y f net f wi xi b
i 1
funzione segno
NOTA:
il MP-PE è costituito da un ADALINE seguito da una non-linearità
Proprietà per il pattern recognition:
– può separare due sole classi
– la funzione discriminante è un iperpiano nello spazio a D
dimensioni di equazione: w1x1 + w2x2 + … + wDxD + b = 0
– la funzione soglia divide lo spazio in due semi-spazi a cui
attribuisce i valori +1 e -1 rispettivamente
Es: Spazio degli ingressi a 2 dimensioni (caso 2D)
g
g = g(x , x )
1
2
funzione discriminante
Superficie di decisione
x1
x2
tg a
x2
b
w2
g>0
g<0
a
RN-4
g w1 x1 w2 x2 b
g x1 , x2 0 w1 x1 w2 x2 b 0 x2
w1
w2
w1
b
x1
w2
w2
La distanza dell’iperpiano dall’origine è:
b
w
con
w wi2
i
x1
g=0
• Nel 2-D la funzione discriminante è un piano e la sua intercetta
con il piano (x1,x2) è una linea (superficie di decisione)
• Nel caso a D dimensioni la superficie di decisione è un iperpiano a
D-1 dimensioni
RN-5
FUNZIONI DI ATTIVAZIONE
• Nel MP-PE la funzione di attivazione è la funzione a soglia detta “segno”
• Possono essere utilizzate altre funzioni non lineari
FUNZIONI SIGMOIDALI
1.) Tangente iperbolica:
f net tanh a net
+1
2.) Funzione logistica:
f net
tanh
+1
net
-1
1
1 ea net
logistica
net
• RNA con funzioni a soglia creano superfici di decisione lineari a tratti
• RNA con funzioni sigmoidali creano superfici di decisione molto
complesse e non-lineari
• Le funzioni sigmoidali sono smooth ed esiste la derivata della mappa
da loro creata (V.I. per il training)
LEARNING
• In un problema di classificazione la funzione discriminante
deve essere spostata in modo da minimizzare gli errori
• Si deve dotare il sistema di una retroazione governata
dall’errore tra l’uscita desiderata e quella di rete
• Usualmente per RNA si adotta l’MSE
• Funzione costo:
1
J
2N
1
p 2 N
2
p
d
RN-6
p yp
p
2
p indice di pattern
ALGORITMO DI LEARNING PER UN MP-PE
STEP 1.
STEP 2.
STEP 3.
STEP4.
In sintesi:
(Rosemblatt 1958)
PERCEPTRON ALGORITHM
Presentare il campione x C1
Se l’uscita è corretta non fare niente
Se l’uscita non è corretta modificare i pesi e il bias finché
l’uscita diventa corretta
Ripetere l’operazione finché tutti i pattern non siano
correttamente classificati
wn 1 wn d n yn xn :tasso di learning
Infatti:
RN-7
Caso a) d = 1 (classe 1) e y = -1 w(n+1) = w(n) + 2 x
Caso b) d = -1 (classe 2) e y = 1 w(n+1) = w(n) - 2 x
caso a)
caso b)
classe 2
y = -1
wa(n)
classificazione
corretta
Hp: caso monodimensionale (un unico peso)
classe 1
y=1
w
Dwa(n)
Dwb(n)
wb(n)
w
• In entrambi i casi il peso si aggiusta nella giusta direzione
• Se i pattern sono linearmente separabili si può dimostrare che
l’algoritmo converge in un numero finito di passi
RN-8
CONFRONTO CON LMS PER ADALINE
• Nel LMS: w(n+1) = w(n) + (n) x(n) stessa formulazione
• Vi sono, però, delle sostanziali differenze di significato
– non si ha la corrispondenza con la discesa del gradiente il
sistema ha una discontinuità
– il perceptron algorithm minimizza la differenza tra la risposta del
MP-PE e l’uscita desiderata anziché tra l’uscita dell’ADALINE e
l’uscita desiderata
implicazioni
• Il MP-PE impara solo quando la sua uscita è errata
• I risultati finali dei pesi coincidono con quelli trovati per una
regressione lineare. Infatti le non linearità sono portate dentro
la regola di aggiustamento dei pesi
Hp:
RN-9
- pattern linearmente separabili
- bias nullo (per semplicità)
Esiste una funzione discriminante lineare che produce zero errori
di classificazione
w* vettore dei pesi ottimi prodotto dal perceptron algorithm
wi* xi n 0 per d (n) 1
i w* x n 0 per d (n) 1
i i
i
n indice del
training-set
*
La soluzione è un iperpiano di equazione : wi xi 0 o
xw 0
*
i
• Vantaggi: l’algoritmo converge in un numero finito di passi
• Svantaggi:
– la funzione discriminante trovata all’ultimo campione può
non andare bene in fase di test
– l’algoritmo converge solo per classi linearmente separabili,
altrimenti la soluzione oscillerà
CHAIN RULE (REGOLA CATENA)
RN-10
• Consente di calcolare la derivata parziale di una variabile rispetto
ad un’altra quando esiste un legame funzionale tra le due
Sia y = f(x) con f differenziabile
y y f
x f x
• Si può dimostrare che l’LMS è equivalente alla chain rule nel calcolo
della “sensitivity” della funzione costo rispetto alle incognite:
2
J 1 d p y p J p
2 p
p
Jp : funzione costo del p-esimo campione
yp : wxp
con:
J p J p y p
Utilizzando la chain-rule: w y w d p y p x p p x p
p
Dalla regola per l’aggiornamento dei pesi:
w(k+1) = w(k) - J(k) (steepest descent)
si ha: w(k+1) = w(k) + p xp
che è lo stesso risultato ottenuto nel LMS
Il gradiente dà una misura della “sensitivity”
RN-11
ESTENSIONE DEL LMS AL MP-PE
x1
xi
xD
net
wi
.
.
.
.
.
.
wi
S
y
wi
f(net)
y
net
y
y f net f xi wi
i
wD
y
y
net f ' net xi
wi net wi
Infatti:
y
f ' net
net
net w x 0 0 ... wi xi ... 0 x
i
wi wi k k k
wi
RN-12
REGOLA DELTA
J
wi
N
2
J 1 d p y p
2 N p 1
y p f wi xip
i
p: indice di pattern
i: indice di peso
y p
J
net p
y p net p wi
d p y p f ' net xip p f ' net xip
Regola Delta
da cui
wi n 1 wi n p n f ' net p n xip n
con n: indice di iterazione
• Estende l’LMS a sistemi non-lineari con non-linearità smooth
• E’ locale rispetto al pattern ed al peso
f’(net)
tanh=f(net)
• Fa uso della f ’(.):
+1
f 'log neti xi 1 xi
f 'tanh neti 0,5 1 x
2
i
net
-1
net
• Quando net è nella regione di linearità di f(.), la f ’(.) è vicina
all’unità e la sensitività:
RN-13
y
f ' net xi xi
w
cioè uguale alla sensitività di un PE lineare
• Quando il punto di funzionamento è vicino alla saturazione, la
sensitività del PE non lineare è attenuata rispetto al PE lineare
questo implica effetti benefici sulla stabilità del processo di learning
• Con PE non lineari la funzione costo non è più quadratica
presenza di minimi locali
• I metodi basati sul gradiente possono intrappolarsi nei
minimi locali o convergere in punti di stazionarietà
• Con PE non lineari:
– miglior filtraggio dei dati rispetto alla regressione lineare
– più efficienti in problemi di classificazione non
linearmente separabili
IL PERCEPTRONE
(Rosemblatt 1950)
+1
b1
b
w11 M
x1
b2
y1
1
y2
w12
x2
w1M
xD
.
.
.
2
.
.
.
wDM
RN-14
yi f neti f wij x j bi
j
MP-PE
M
yM
• Lo strato di uscita è costituito da MP-PE
• Il numero di PE in uscita ( M ) è legato alla codifica adottata per le classi
• Ciascun neurone risolve il problema di decidere se un pattern appartiene
alla classe i-esima oppure no
• Il perceptrone può essere allenato utilizzando la ben nota regola di
aggiustamento dei pesi:
w(n+1) = w(n) + (n) x(n)
per
riconoscere pattern linearmente separabili in un numero finito di passi
RN-15
• Le regioni di decisione di un perceptron sono sempre regioni convesse
REGOLA DELTA APPLICATA AL PERCEPTRON
N
J 1 d p y p
2N p 1
2
Se M = 1
p : indice del pattern
Se abbiamo un numero M di PE nello strato di uscita:
2
N M
2
1
1
con
y
f
w
x
J
d
y
pi
ij jp f netip
ip
p
ip
2N
2
N
p 1 i 1
p i
j
J J yip net d y f ' net x f ' net x
ip
ip
ip
ip
jp
ip
ip
jp
wij yip netip wij
da cui
definendo:
wij n 1 wij n ip f ' netip n x jp
ip J f ' netip
yip
errore locale per il PE i-esimo
wij n 1 wij n ip x jp
RN-16
REGOLA DELTA PER IL PERCEPTRON
wij n 1 wij n ip x jp
• Usa solo quantità locali disponibili ai pesi:
– il valore xjp che raggiunge wij dall’ingresso
– l’errore locale ip propagato dalla funzione costo
• La località fa sì che l’algoritmo prescinda dalla complessità della rete
• SVANTAGGI: la superficie di decisione è molto vicina all’ultimo
pattern classificato correttamente risultati scadenti in fase di
generalizzazione
• La superficie di decisione dovrebbe essere posta fra le due classi a
distanza uguale dai “bordi” delle due classi
• Si può modificare l’algoritmo introducendo il “margine” tra
l’iperpiano < x , w > = b e il set degli esempi
S = { ( x 1 , d 1) , . . . , ( x N , d N) }, come:
min
x, w b 0
xS
margine
RN-17
Vapnik ha mostrato che :
2
w
2
• Si definisce IPERPIANO OTTIMO l’iperpiano che massimizza il
margine tra le due classi
• Per trovare l’iperpiano ottimo occorre trovare i VETTORI DI
SUPPORTO
vettori di supporto
Iperpiano ottimo
RN-18
LIMITI DEL PERCEPTRON
• Risolve solo problemi linearmente separabili
Es: Problema X-OR
(non è linearmente separabile)
x1
x2
y
0
0
0
1
0
1
1
1
0
1
1
0
x2
g(x)
x1
• A prescindere da dove si piazzi la superficie di decisione si commette
un errore di classificazione
Soluzione
MULTI LAYER PERCEPTRON (MLP)
bias
bias
y1
x1
+1
+1
1
1
• L’ MLP estende il
y2
x2
perceptron aggiungendo
2
2
.
.
.
. y
.
.
strati nascosti (hidden
xD .
.
.
M
M
K
layer) - Es: 1 hidden layer
input layer hidden layer
output layer
+1
+1
b3
b1
x1
Es: Problema X-OR
x3
w1
1
w2
x2
RN-19
w5
3
b2
w3
w4
x4
2
w6
+1
Hp: i PE hanno funzione di attivazione a soglia
x2
x4
g2 w3 x1 w4 x2 b2 0
x1
x2
x3
x4
y
0
0
0
1
0
0
1
0
1
1
1
1
1
1
0
1
1
0
1
1
g3 w5 x3 w6 x4 b3 0
x1
g1 w1x1 w2 x2 b1 0
x3
Mappatura totale
input/output
y f ( w5 x3 w6 x4 b3 )
f ( w5 ( f ( w1 x1 w2 x2 b1 )) w6 ( f ( w3 x1 w4 x2 b2 )) b3 )
f ( g1 g 2 b3 )
RN-20
• Il primo strato di neuroni ha trasformato un problema non linearmente
separabile in uno linearmente separabile nello spazio x3,x4
• Lo strato d’uscita esegue la desiderata separazione di due insiemi
linearmente separabili
• L’aggiunta dello strato nascosto ha reso possibile la realizzazione di
regioni di decisione non più necessariamente convesse
• In max numero di regioni distinte nello spazio degli ingressi è
controllato dal numero di neuroni nascosti (2k per k>>D)
• Ciascun neurone nascosto crea una funzione discriminante lineare
• I neuroni d’uscita combinano alcune delle regioni create dai neuroni
nascosti creando regioni non necessariamente convesse
• Esistono differenti combinazioni di pesi che realizzano un particolare
adattamento delle regioni di decisione
RN-21
CAPACITÀ DI MAPPING DELLE MLP CON SINGOLO HIDDEN LAYER
• BUMP: regione singola, di estensione limitata, di valori “alti” (1), circondata da
valori bassi (0)
- la funzione discriminante dei valori bassi non può essere convessa e
quindi un semplice perceptron non può realizzare un bump
- il bump più semplice è triangolare ed è ottenuto con 3 neuroni nascosti
• Una MLP con 1 strato nascosto può costruire un bump nello spazio degli ingressi
• Una MLP con 1 strato nascosto può costruire regioni di decisione complesse,
non convesse, eventualmente disgiunte (es. X-OR)
TEOREMA DI CYBENKO
Una MLP con 1 strato nascosto di neuroni con funzioni di attivazione sigmoidale è
un mappatore universale, cioè può approssimare arbitrariamente bene qualunque
regione di decisione continua, purché il numero di neuroni nascosti sia
sufficientemente grande
ALGORITMO ERROR BACK PROPAGATION (EBP)
RN-22
• Si basa sull’uso della CHAIN RULE che consente di propagare
sistematicamente la sensitivity attraverso un numero indeterminato di nodi
interni (hidden) di una topologia
ith
wki
PE
kth PE
yk
yi
xi
• NOTA: non conosciamo la risposta desiderata dell’i-esimo neurone nascosto
Per adattare i pesi wij del neurone nascosto:
1. Si utilizza un errore derivato propagando l’errore nello strato d’uscita (noto)
2. Si calcola la sensitivity usando la chain-rule
wij (n 1) wij (n) f ' (neti (n)) i (n) x j (n)
con
i (n) ek (n) f ' (netk (n)) wki (n)
k
Errore locale del nodo i-esimo
ALGORITMO EBP
RN-23
Hp: uno strato nascosto, un neurone d’uscita
x1
wij
xj
neti
i-th
yi
xd
J
J yi neti
wij yi neti wij
1
J
poiché
2N
wki
Chain rule
N
( d k yk ) 2
p 1
yk f wki yi f ( netk )
i
yi f wij x j f (neti )
j
netk
k
yk
neti
yi
xj ;
f ' (neti )
wij
neti
J
J yk J yk net k
yi yk yi yk net k yi
ma
netk
yk
wki ;
f ' (netk )
yi
netk
J
ek
yk
J
e k f ' (net k ) wki
yi
RN-24
J
J yk yi neti
ek f ' (netk ) wki f ' (neti ) x j
wij yk yi neti wij
Da cui, utilizzando la regola del gradiente discendente:
w(n 1) w(n) grad J (n)
J
Regola di aggiornamento dei pesi
wij (n 1) wij (n)
wij
wij (n 1) wij( n) ek (n) f ' (netk (n))wki (n) f ' (neti (n)) x j (n)
ESTENSIONE DELL’EBP AL CASO DI M NEURONI DI USCITA
1
y1
k
yk
M
yM
x1
wij
xj
neti
i-th y
i
wki
RN-25
xd
J M J yk netk
ek f ' (netk ) wki
yi k 1yk netk yi
k
Ciascun neurone K di uscita contribuisce in modo additivo al gradiente del costo
rispetto all’uscita dell’iesimo neurone nascosto
quindi:
J
ek f ' (netk ) wki f ' (neti ) x j
wij
k
ESTENSIONE DELL’EBP A RETI CON PIÙ DI UNO STRATO NASCOSTO
l-1
l
1
y1
k
yk
M
yM
RN-26
w1i
j-th
wij
yi
i-th y
i
wki
wMi
J
ek f ' (netk ) wki f ' (neti ) yi
wij
k
La regola di aggiornamento è:
wij (n 1) wij (n) f ' (neti (n)) ek (n) f ' (netk (n)) wki (n)
k
Tornando indietro di strato in strato si può propagare all’indietro l’errore sino all’ingresso
IMPLEMENTAZIONE
RN-27
STEP 1: Presentare alla rete il pattern {x1 , d1}
STEP 2: FORWARD STEP:
Calcolare l’uscita di ciascun neurone dall’input (l = 1) all’output (l = L):
yil (n) wijl ylj1 (n)
j
Con
y (j0) x j
ei (n) di (n) yi (n)
STEP 3: Calcolare l’errore nello strato d’uscita
STEP 4: BACKWARD STEP:
Calcolare l’errore locale partendo dallo strato di uscita sino all’ingresso
L
L
- strato d’uscita: i (n) ei (n) f ' (neti (n))
l
l
l 1
l 1
- negli altri strati i (n) f ' (neti (n)) k (n)wki (n)
k
STEP 5: Ripetere questa procedura per tutti i pattern del training e per il numero di epoche
richiesto per la convergenza (randomizzare i pattern tra un’epoca e l’altra)
NOTA: n indice di iterazione e anche x(n), d (n) n 1, ,N training set
l: indice di strato l=1,…,L ; l=1 input layer ; l=L output layer
RN-28
EBP
wij (n 1) wij (n) f ' (neti (n)) ek (n) f ' (netk (n)) wki (n) y j
k
L’errore locale di un neurone di uscita è:
k
allora
J
f ' (netk ) ek f ' (netk )
yk
i
i
ek (n) f ' (netk (n)) wki (n) k wki (n)
k
k
wij
j
yi
è l’errore totale propagato all’i-esimo neurone dall’uscita o anche è il contributo che
il neurone i-esimo dà all’errore in uscita
• Se questo passa attraverso la non-linearità dello stesso i-esimo nodo si
ottiene:
l’errore locale del neurone i-esimo dello strato nascosto i (n) f ' (neti (n)) k wki (n)
k
Da cui: wij (n 1) wij (n) i (n) y j (n)
REGOLA
CIASCUN PESO PUÒ ESSERE AGGIORNATO MOLTIPLICANDO L’ERRORE
LOCALE i (n) PER L’ATTIVAZIONE LOCALE y j (n) CIOÈ
Dwij i (n) y j (n)
Dwij i (n) y j (n)
Errore
locale
RN-29
Attivazione locale
VALE PER TUTTI I NEURONI DEI VARI STRATI
Da strato a strato quello che si modifica è il modo di calcolare l’errore locale a seconda
che il neurone appartenga ad uno strato nascosto o di uscita o se ha una funzione di
attivazione lineare o non lineare:
CASO 1: NEURONE D’USCITA E LINEARE. i (n) ei (n)
Infatti f’(neti(n)) ha un valore costante uguale
ad 1 (ritroviamo la regola LMS)
CASO 2: NEURONE D’USCITA E NON LINEARE. i (n) ei (n) f ' (neti (n))
L’aggiornamento dei pesi viene fatto con la regola delta
Dw i (n) yi (n)
perché conosciamo l’uscita desiderata
CASO 3: NEURONE NASCOSTO E NON LINEARE i (n) ei (n) f ' (neti (n)) k wki (n)
k
Dw i (n) y j (n)
La formula per l’aggiornamento dei pesi non cambia strutturalmente perché il learning
è condotto usando ancora il gradiente discendente
RN-30
PROBLEMI APERTI
• Scelta del numero di neuroni nello strato nascosto
• Non si è ancora affermata alcuna tecnica per la scelta del numero
ottimo di neuroni nascosti
• In letteratura sono stati proposti algoritmi che trovano soluzioni
sub-ottime
• Spesso la scelta del numero di neuroni nascosti è condotta con
tecniche del tipo trial and error
MLP CON DUE STRATI NASCOSTI
• Funzione discriminante:
RN-31
y f ( f ( f ( ())))
deriva da tre livelli di composizione
• Uno strato nascosto crea bump locali nello spazio degli ingressi. Un ulteriore
strato può essere pensato come un combinatore di bump in regioni disgiunte
dello spazio
• Teorema: una combinazione lineare di bump localizzati può approssimare
qualunque funzione UNA MLP CON DUE STRATI NASCOSTI È UN
APPROSSIMATORE UNIVERSALE (Anche una MLP con 1 strato nascosto lo è)
• Non esistono teoremi costruttivi
• Di norma si dovrebbe iniziare a sperimentare con reti con 1 solo strato
nascosto perché le MLP con 2 strati hanno una convergenza più lenta a causa
dell’attenuazione che subiscono gli errori attraverso le non-linearità
RN-32
EPB PER MLP CON DUE o PIÙ STRATI
L’algoritmo non subisce alcuna modifica
Output
Input
1
Risposta
Desiderata
Activation forward
Criterio
di Costo
ANN
3
1. FOWARD STEP:
2.
2
Calcolo
dell’errore
Error Backward
yil (n) f wijl y lj1 (n)
j
ei (n) di (n) yi (n)
3. BACKWARD STEP iL (n) ei (n) f ' (netiL (n))
il (n) f ' (netil (n)) kl 1(n) wkil 1(n)
Regola d’aggiornamento
l 1
wij (n 1) wij (n) f ' (netil (n)) kl 1 (n) wki
(n) f ' (netk (n)) y j (n)
k
k
Dwij i (n) y j (n)
RN-33
ANCORA SULL’EPB
Rete neurale originale
wi2
wij
yi f ( wij y j )
i f ' (neti ) k wki
k
Se k è di uscita
S
k
wi1
wi2
wij
i
Metodo del gradiente discendente
i-esimo PE
w1i
ei
w2i
x
S
f ‘(net)
input
w2i
wki
FORWARD STEP
wki
BACKWARD STEP
Se k è nascosto
Dwij i (n) y j (n)
yi
f (net)
yj
Rete duale
i f ' (neti ) ek wki
w1i
wi1 i-esimo PE
yj
wij
i
FORWARD
BACKWARD
i-esimo
PE
yi
wki
k
ek
output
errore
CLASSIFICATORI OTTIMI
RN-34
• Un classificatore ottimo è quello che crea funzioni discriminanti arbitrarie che separano
cluster di dati secondo le probabilità a posteriori
• Un classificatore ottimo bayesiano produce uscite che sono le probabilità a posteriori di
classi di dati
• Se il training di una MLP è condotto sotto certe condizioni le uscite possono essere
interpretate come stima delle probabilità a posteriori (Bishop)
CONDIZIONI
• MLP allenata per minimizzare l’MSE
• Numero di neuroni nascosti sufficiente a realizzare il mappaggio richiesto (mappatore
universale
• Funzione di attivazione SOFTMAX che assicura la somma delle uscite pari a 1 e ciascuna
uscita compresa tra 0 e 1
exp(netk )
y
La sommatoria è estesa a
k
SOFTMAX
exp(
net
)
j
tutti i nodi di output
j
• La softmax è simile a tanh e logistic eccetto che le uscite sono scalate secondo la totale
attivazione dello strato d’uscita così d’assicurare la somma delle uscite pari a 1
• Nel caso di due sole classi l’unico neurone d’uscita può avere funzioni logistic
RN-35
probabilità classe 1 = y
probabilità classe 2 =1-y
•In generale yk può fornire una stima della probabilità condizionale media:
yk ( x, w* ) tik p(tik | x)
i
w*: pesi ottimi
t: uscite desiderate
•Per un classificatore dove le uscite desiderate sono 0 e 1 e con tanti nodi
d’uscita quante sono le classi:
cioè
yk ( x) P(ck | x)
l’uscita k-esima della MLP fornisce la probabilità a posteriori che il pattern x
appartenga alla classe Ck
• Si ha un metodo per la stima della probabilità a posteriori direttamente dai
dati senza dover usare la regola di Bayes