Metodi Quantitativi per Economia,
Finanza e Management
Lezione n°4
Analisi Univariata
Quantitative Market Research
Set-up Protocol
Business Aim
Targeted population
Characters to be
assesed
Choice of
sample
Sampling error
Fieldwork
Techniques of data
collection
Data Audit
Set-up
questionnarie
Data Analysis
Pre-test
questionnarie
Presentation
The 5 Clusters
4 Factors
Our choice was consistent with the
following criteria:
-The
proportion
between
the
maximum number of variables and the
chosen factors is in the acceptable
range (4/13 < 30%)
-The Eingenvalues are all bigger than 1
-The Cumulative Variance Explained is
over 60%
-Communalities homogeneous values
•
•
•
•
•
As the Scree Plot confirms, only after 4
components the slope of the curve
sensibly decreases.
40
Cool Hunters (28%): More than all, they are users absolutely interested on
Broadening.
PR’s (7%): Interested above all in Public Relations and express some
attachment to Spying, but not related at all with Keeping Up.
Detached (20%): Apart from some light interest on Broadening, they do not
express any involvement with the Facebook use (in particular with Public
Relations).
Functional (18%): Above all, interested in Keeping up with their network of
friends and use Public Relations inside this network. Besides, they do not care
at all about Spying and Broadening.
Gossipers (27%): They are also interested in Keeping up, but above all in Spying
their network. Furthermore, they are not interested in Public Relations and
Broadening.
Each single Cluster was then crossed with socio-demographic and usage
variables, through the contingency table tool, in order to better
understand their main characteristics. The following slides sum-up the
most relevant results of these crossings for each single cluster.
68
Type of data
• Qualitative
– Nominal it’s used for qualitative data which are classified
in defined categories with no a specific order.
– Ordinal the categories have got a specific order; it does
not enable to define any numeric assessment.
• Quantitative
– Ratio scale through this type of data it is possible to
determine the different ratio between one category and an
other; the value “0” of the scale is set.
– Interval scale has the same characteristics as the
previous scale, even though it has not got a fixed value “0”.
Type of data guides the analyses
Most of the quantitative methods deal with quantitative data
Tipologie di dati
• Qualitativi dati espressi in forma verbale, solitamente
classificati in categorie
• Quantitativi dati espressi in forma numerica. si
distinguono in:
– discreti dati caratterizzati da una quantità finita o
infinita numerabile di classi di misura
– continui risposta numerica derivamte da
un
processo di misurazione che fornisce indicazioni
puntuali all’interno di un continuum
• Territoriali
• Date
Tipologie di dati
qualitativi
• Nominale usato per dati qualitativi, che vengono così
classificati in categorie distinte senza alcun ordine
implicito (es. professione del cliente)
Where do you come from?
a. North Italy
b. Center Italy
c.
South Italy
d. Outside Italy
• Ordinale le categorie presentano un ordine implicito;
consente di stabilire una relazione d’ordine tra le
diverse categorie, ma nessuna asserzione numerica,
ovvero si può dire che un determinato valore è più
grande di un altro, ma non di quanto
Education level (Currently Attending)
a.
High School
b.
Undergraduate
c.
Graduate
Tipologie di dati
quantitativi
• Scala di rapporti con questa tipologia si può dire di quanto
una categoria è maggiore di un’altra; è fissato un valore “0”
della scala.
es. Le variabili spesa media e tempo impiegato sono misurate
a livello di rapporto,ovvero rientrano in una scala di
valutazione comparativa
How long have you been a Facebook user for (Months):
Approximately, how many friends do you have on Facebook:
How many of these friends do you contact regularly:
On average, how many times a week do you check Facebook:
How much time do you spend on each visit (in minutes):
Tipologie di dati
quantitativi
• Scala di intervalli presenta le stesse caratteristiche della
precedente, ma non possiede un valore “0” fissato.
es. In una indagine sui clienti di un supermercato, il loro livello
di soddisfazione può essere adeguatamente rappresentato
mediante una scala di valutazione compresa tra 1 e 9, ciò
che posso asserire è che la differenza tra 2 e 3 è la
medesima di quella tra 8 e 9, ma non che 8 sia il doppio di 4.
Where do you connect on Facebook more frequently?
1
Low
2
3
Medium
4
5
6
a. Home,
b. Work/ University
c. Other places (internet point, friends' houses ..)
La tipologia di dati guida l’analisis
7
High
8
9
L’analisi statistica dei dati
Statistica descrittiva insieme dei metodi che riguardano la
rappresentazione e sintesi di un insieme di dati al fine di
evidenziarne le caratteristiche principali
Statistica inferenziale insieme dei metodi che permettono la
stima di una caratteristica di una popolazione basandosi
sull’analisi di un campione
Misura riassuntiva,
La parte di popolazione
calcolata sui dati campionari,
utile per descrivere una selezionata per l’analisi
caratteristica non nota della
popolazione
Totalità degli elementi
presi in esame dalla
indagine
Univariate descriptive statistics
In the univariate descriptive statistics we analyze one
variable at a time.
N_ID
H1
H2
H3
H4
H5
H6
H7
H8
H9
H10
H11
H12
H13
H14
H15
H16
H17
H18
H19
H20
H21
H22
H234
H235
H236
D_8_2
0.1
0
0
0.2
0.05
0.2
0.1
0.1
0.2
0.05
0
0
0
0.15
0
0.1
0
0.2
0
0.05
0.2
0.2
…
…
0.2
0.1
0.1
• Frequency distribution
• Synthesis measures
– Measures of location
– Measures of spread
– Measures of shape
• Data Audit
– Input errors
– Missing values
– Outliers
• Basic insights
Le distribuzioni di frequenza
• Frequenza assoluta: è un primo livello di sintesi dei
dati- consiste nell’associare a ciascuna categoria, o
modalità, il numero di volte in cui compare nei dati
• Distribuzione di frequenza: insieme delle modalità e
delle loro frequenze
• Frequenza relativa: rapporto tra la frequenza assoluta
ed il numero complessivo delle osservazioni effettuate.
pi= ni/ N
I due tipi di frequenze vengono usati con dati quantitativi,
qualitativi ordinali, quantitativi discreti.
Le distribuzioni di frequenza
product
program
home
p_info
catalog
freeze
login
logpost
addcart
pay_req
shelf
cart
pay_res
download
regpost
register
• Rappresentazione grafica var.qualitative:
Diagramma a barre-professione intervistato
Diagramma a torta
250
200
150
100
50
0
casalinga
dirigente
studente
Diagr. a barre: nell’asse delle ascisse ci sono le
categorie, senza un ordine preciso; in quello delle
ordinate le frequenze assolute/relative corrispondenti
alle diverse modalità
Diagr.
a
torta:
la
circonferenza
è
divisa
proporzionalmente alle frequenze
Le distribuzioni di frequenza
• Rappresentazione grafica var.quantitative discrete:
istogram m a
Diagramma delle frequenze
300
200
0,06
220
170
0,04
100
100
0
30
57
0,02
30
0
Diagr. delle frequenze: nell’asse delle ascisse ci sono i
valori assunti dalla var. discreta (quindi ha un
significato quantitativo); l’altezza delle barre è
proporzionale alle frequenze relative o assolute del
valore stesso
Istogramma:nell’asse delle ascisse ci sono le classi degli
intervalli considerati; l’asse delle ordinate rappresenta
la densità di frequenza; l’area del rettangolo
corrisponde alla frequenza della classe stessa.
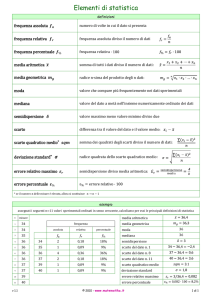
Misure di sintesi
Misure di tendenza centrale:
• Media aritmetica
• Mediana
• Moda
Misure di tendenza non centrale:
• Quantili
• Percentili
Misure di dispersione:
• Campo di variazione
• Differenza interquantile
• Varianza
• Scarto quadratico medio
• Coefficiente di variazione
Misure di forma della distribuzione:
• Skewness
• Kurtosis
Misure di Tendenza Centrale
Tendenza Centrale
Media
Mediana
Moda
n
x
x
i 1
i
n
Media
Aritmetica
Valore centrale delle
osservazioni ordinate
Valore più
frequente
Media Aritmetica
• La misura di tendenza centrale più comune
• Media = somma dei valori diviso il numero di valori
• Influenzata da valori estremi (outlier)
0 1 2 3 4 5 6 7 8 9 10
Media = 3
1 2 3 4 5 15
3
5
5
0 1 2 3 4 5 6 7 8 9 10
Media = 4
1 2 3 4 10 20
4
5
5
Mediana
• In una lista ordinata, la mediana è il valore “centrale” (50%
sopra, 50% sotto)
0 1 2 3 4 5 6 7 8 9 10
0 1 2 3 4 5 6 7 8 9 10
Mediana = 3
• Non influenzata da valori estremi
Mediana = 3
Moda
•
•
•
•
•
Valore che occorre più frequentemente
Non influenzata da valori estremi
Usata sia per dati numerici che categorici
Può non esserci una moda
Ci può essere più di una moda
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
Moda = 9
0 1 2 3 4 5 6
No Moda
Misure di Tendenza Non Centrale
• I Quartili dividono la sequenza ordinata dei dati in 4
segmenti contenenti lo stesso numero di valori
25%
Q1
25%
25%
Q2
25%
Q3
• Il primo quartile, Q1, è il valore per il quale 25% delle
osservazioni sono minori e 75% sono maggiori di esso
• Q2 coincide con la mediana (50% sono minori, 50% sono
maggiori)
• Solo 25% delle osservazioni sono maggiori del terzo quartile
Box Plot
X
minimo
Q1
25%
12
Mediana
Q3
(Q2)
25%
30
25%
45
X
25%
57
Differenza Interquartile
57 – 30 = 27
OUTLIERS:
massimo
Q1 - 1,5 * Differenza interquartile
Q3 + 1,5 * Differenza interquartile
70
Misure di Variabilità
Variabilità
Campo di
Variazione
Differenza
Interquartile
Varianza
Scarto
Quadratico
Medio
Coefficiente
di Variazione
• Le misure di variabilità
forniscono informazioni sulla
dispersione o variabilità
dei valori.
Stesso centro,
diversa variabilità
Campo di Variazione
• La più semplice misura di variabilità
• Differenza tra il massimo e il minimo dei valori osservati:
Campo di variazione = Xmassimo – Xminimo
Esempio:
0 1 2 3 4 5 6 7 8 9 10 11 12
13 14
Campo di Variazione = 14 - 1 = 13
Campo di Variazione
• Ignora il modo in cui i dati sono distribuiti
7
8
9
10
11
12
Campo di Var. = 12 - 7 = 5
7
8
9
10
11
12
Campo di Var. = 12 - 7 = 5
• Sensibile agli outlier
1,1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,3,3,3,3,4,5
Campo di Var. = 5 - 1 = 4
1,1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,2,2,2,3,3,3,3,4,120
Campo di Var = 120 - 1 = 119
Differenza Interquartile
• Possiamo eliminare il problema degli outlier usando la
differenza interquartile
• Elimina i valori osservati più alti e più bassi e calcola il campo
di variazione del 50% centrale dei dati
• Differenza Interquartile = 3o quartile – 1o quartile
IQR = Q3 – Q1
Varianza
• Media dei quadrati delle differenze fra ciascuna osservazione
e la media
N
– Varianza della Popolazione:
dove
σ
2
μ = media della popolazione
N = dimensione della popolazione
xi = iimo valore della variabile X
(x
i 1
i
μ)
N
2
Scarto Quadratico Medio
• Misura di variabilità comunemente usata
• Mostra la variabilità rispetto alla media
• Ha la stessa unità di misura dei dati originali
– Scarto Quadratico Medio della Popolazione:
N
σ
2
(x
μ)
i
i 1
N
Scarto Quadratico Medio
Scarto quadratico medio piccolo
Scarto quadratico medio grande
Scarto Quadratico Medio
Dati A
11
12
13
14
15
16
17
18
19
20 21
Media = 15.5
s = 3.338
20 21
Media = 15.5
s = 0.926
20 21
Media = 15.5
s = 4.570
Dati B
11
12
13
14
15
16
17
18
19
Dati C
11
12
13
14
15
16
17
18
19
Scarto Quadratico Medio
• Viene calcolato usando tutti i valori nel set di dati
• Valori lontani dalla media hanno più peso
(poichè si usa il quadrato delle deviazioni dalla media)
• Le stesse considerazioni valgono anche per il calcolo
della Varianza
Coefficiente di Variazione
• Misura la variabilità relativa
• Sempre in percentuale (%)
• Mostra la variabilità relativa rispetto alla media
• Può essere usato per confrontare due o più set di dati
misurati con unità di misura diversa
s
CV
|x |
100%
Coefficiente di Variazione
• Azione A:
– Prezzo medio scorso anno = $50
– Scarto Quadratico Medio = $5
•
s
$5
CVA 100%
100% 10%
|x |
$50
Azione B:
– Prezzo medio scorso anno = $100
– Scarto Quadratico Medio = $5
s
$5
CVB 100%
100% 5%
$100
| x|
Entrambe le
azioni hanno lo
stesso scarto
quadratico
medio, ma
l’azione B è
meno variabile
rispetto al suo
prezzo
Forma della Distribuzione
• La forma della distribuzione si dice simmetrica se le osservazioni
sono bilanciate, o distribuite in modo approssimativamente regolare
attorno al centro.
Distribuzione Simmetrica
120
100
60
40
20
0
Frequenza
80
10
9
8
7
6
5
4
3
2
1
0
1
2
3
4
5
6
7
8
9
Forma della Distribuzione
• La forma della distribuzione è detta asimmetrica se le
osservazioni non sono distribuite in modo simmetrico
rispetto al centro.
Distribuzione con Asimmetria Positiva
12
10
Frequenza
Una distribuzione con asimmetria
positiva (obliqua a destra) ha una
coda che si estende a destra, nella
direzione dei valori positivi.
8
6
4
2
0
1
3
4
5
6
7
8
9
8
9
Distribuzione con Asimmetria Negativa
12
10
Frequenza
Una distribuzione con asimmetria
negativa (obliqua a sinistra) ha una
coda che si estende a sinistra, nella
direzione dei valori negativi.
2
8
6
4
2
0
1
2
3
4
5
6
7
Misure di Forma della Distribuzione
• Descrive come i dati sono distribuiti
• Misure della forma
– Simmetrica o asimmetrica
Obliqua a sinistra
Media < Mediana
Simmetrica
Media = Mediana
Obliqua a destra
Mediana < Media
Misure di Forma della Distribuzione
Skewness: indice che informa circa il grado di simmetria o
asimmetria di una distribuzione.
– γ=0 ditribuzione simmetrica;
– γ<0 asimmetria negativa (mediana>media);
– γ>0 asimmetria positiva (mediana<media).
Kurtosis: indice che permette di verificare se i dati seguono una
distribuzione di tipo Normale (simmetrica).
– β=3 se la distribuzione è “Normale”;
– β<3 se la distribuzione è iponormale (rispetto alla
distribuzione di una Normale ha densità di frequenza minore
per valori molto distanti dalla media);
– β>3 se la distribuzione è ipernormale (rispetto alla
distribuzione di una Normale ha densità di frequenza
maggiore per i valori molto distanti dalla media).
IMPORTO NETTO UNITARIO
Basic Statistical Measures
Location
Variability
Mean
106.1410
Std Deviation
81.01306
Median
103.2900
Variance
6563
Mode
0.0000
Range
523.69000
Interquartile Range
118.62500
IMPORTO NETTO UNITARIO
IMPORTO NETTO UNITARIO
IMPORTO NETTO UNITARIO
Basic Statistical Measures
Location
Variability
Mean
138.0247
Std Deviation
64.29397
Median
129.1100
Variance
4134
Mode
149.0000
Range
521.77000
Interquartile Range
82.62000