VARIABILI ALEATORIE MULTIPLE
E TEOREMI ASSOCIATI
Fonti: Cicchitelli, Dall’Aglio, Mood-Graybill.
Moduli 6, 9, 10 del programma.
VARIABILI ALEATORIE DOPPIE
Dopo aver trattato delle distribuzioni di probabilità di una variabile aleatoria, che
associa ad ogni evento elementare dello spazio campionario uno ed un solo numero
reale, è del tutto naturale estendere questo concetto al caso di due o più dimensioni.
ESEMPIO 1:
Si consideri lo spazio campionario ottenuto lanciando tre monete ben equilibrate e si
pensi di associare ad ogni evento elementare il “numero di realizzazioni con il risultato
Testa” (v.a. X) e il “numero di variazioni nella sequenza” (v.a. Y), intendendo con questo
il numero di volte in cui si passa dal simbolo “Testa” al simbolo “Croce”. Indicando con
T = “Testa” e C = “Croce”, si ottiene:
ω
X
Y
P(ω)
ω1 = TTT
3
0
1/8
ω2 = TTC
2
1
1/8
ω3 = TCT
2
2
1/8
ω4 = CTT
2
1
1/8
ω5 = CCT
1
1
1/8
ω6 = CTC
1
2
1/8
ω7 = TCC
1
1
1/8
ω8 = CCC
0
0
1/8
1
Ad ogni coppia distinta di valori (x, y) è possibile associare un livello di probabilità che
è pari alla probabilità dell’evento o alla somma delle probabilità degli eventi elementari
che danno luogo a tale coppia. Si ottengono pertanto i seguenti livelli di probabilità:
P(X = 0, Y = 0) = P(ω8 = CCC) = 1/8;
P(X = 1, Y = 1) = P(ω5 = CCT) + P(ω7 = TCC) = 2/8;
P(X = 1, Y = 2) = P(ω6 = CTC) = 1/8;
P(X = 2, Y = 1) = P(ω2 = TTC) + P(ω4 = CTT) = 2/8;
P(X = 2, Y = 2) = P(ω3 = TCT) = 1/8;
P(X = 3, Y = 0) = P(ω1 = TTT) = 1/8.
Dette probabilità possono essere riportate nella seguente tabella a doppia entrata:
X
Y
0
1
2
p(x)
0
1/8
0
0
1/8
1
0
2/8
1/8
3/8
2
0
2/8
1/8
3/8
3
1/8
0
0
1/8
p(y)
2/8
4/8
2/8
1
Variabile aleatoria doppia discreta
Dato uno spazio campionario discreto Ω, si chiama variabile aleatoria doppia discreta la
funzione (X, Y), definita in ℜ 2 , che associa ad ogni evento elementare ωi dello spazio
campionario Ω la coppia di numeri reali (x, y), essendo x = X(ω) e y = Y(ω).
Come visto nell’esempio, è possibile assegnare ad ogni coppia (x, y) un livello di
probabilità, che prende il nome di funzione di probabilità congiunta:
p(x, y) = P(X = x, Y = y).
2
La parola “congiunta” deriva dal fatto che questa probabilità è legata al verificarsi di
una coppia di valori, il primo associato alla v.a. X ed il secondo alla v.a. Y.
La funzione di probabilità gode delle seguenti proprietà:
i) p(x, y) ≥ 0
ii)
∑ ∑ p (x , y ) = 1 ; il segno di doppia sommatoria indica che la somma è estesa,
x y
rispettivamente, a tutti i valori di X e a tutti i valori di Y.
Per determinare la probabilità che la v.a. (X, Y) assuma valori in un qualsiasi
sottoinsieme A:
P [(x , y ) ∈ A ] =
∑ ∑ p (x , y ) ,
dove la somma è estesa a tutte le coppie (x, y)
( x , y )∈A
appartenenti ad A.
Funzioni di probabilità marginali
Data la funzione di probabilità congiunta p(x, y) è possibile pervenire alla costruzione
della funzione di probabilità della singola v.a., X o Y:
pX (x ) = P (X = x ) = ∑ p (x , y )
y
pY (y ) = P (Y = y ) = ∑ p (x , y )
x
che prendono, rispettivamente, il nome di funzione di probabilità marginale di X e
funzione di probabilità marginale di Y.
Facendo riferimento all’esempio 1, si possono costruire le funzioni di probabilità di X e
di Y:
3
X
pX(x)
0
1/8
1
3/8
2
3/8
3
1/8
Funzione di probabilità marginale di X
1
Y
pY(y)
0
2/8
1
4/8
2
2/8
Funzione di probabilità marginale di Y
1
Funzioni di probabilità condizionate
Data una v.a. doppia, può avere senso introdurre il concetto di relazione che lega Y ad
X. Si può quindi studiare la distribuzione di probabilità di Y per livelli assegnati di X: si
vuole quindi capire se e in che modo il livello di X va ad influenzare la distribuzione di
probabilità di Y.
Data la v.a. doppia discreta (X, Y), descritta dalla funzione di probabilità congiunta
p(x, y), si vuole definire la funzione di probabilità di Y condizionata ad un prefissato
valore di X. Posto X = x si definisce funzione di probabilità condizionata di Y dato X:
p (y x ) = P (Y = y X = x ) =
P (Y = y ∩ X = x ) p (x , y )
=
pX (x )
P (X = x )
con
pX (x ) > 0 ; (si ricordi la
definizione di probabilità condizionata vista nelle probabilità elementari).
Analogamente, fissato un particolare valore di Y, è possibile definire la funzione di
probabilità condizionata di X dato Y:
4
p (x y ) = P (X = x Y = y ) =
P (X = x ∩ Y = y ) p ( x , y )
=
pY ( y )
P (Y = y )
con
pY ( y ) > 0 .
E’ immediato verificare che:
P (X = x Y = y ) ≥ 0 e
P (X
∑
x
= x Y = y ) = 1;
P (Y = y X = x ) ≥ 0 e
∑y P (Y
= y X = x ) = 1.
Facendo ancora riferimento all’esempio 1, si ottiene:
X
p(xly2)
0
0
1
1/2
2
1/2
3
0
Funzione di probabilità condizionata di X dato Y = y2
1
Y
p(y lx2)
0
0
1
2/3
2
1/3
Funzione di probabilità condizionata di Y dato X = x2
1
Indipendenza stocastica
Dalla definizione di distribuzione di probabilità condizionata è possibile derivare la
nozione di indipendenza stocastica (o semplicemente indipendenza); infatti, se:
P (X = x Y = y ) = P (X = x )
∀y
5
cioè se X non dipende da Y, allora si può dire che X è indipendente da Y; e se:
P (Y = y X = x ) = P (Y = y )
∀x
cioè se Y non dipende da X, allora si può dire che Y è indipendente da X.
Se X è indipendente da Y, allora si ottiene che:
P (X = x ,Y = y ) = P (X = x ) ⋅ P (Y = y ) ,
e se Y è indipendente da X, si ottiene che:
P (X = x ,Y = y ) = P (X = x ) ⋅ P (Y = y )
da cui si può dedurre che la relazione di indipendenza è simmetrica, e si dice che X e Y
sono indipendenti (X ⊥ Y ) .
Valore atteso congiunto, Covarianza e Correlazione
Il valore atteso e la varianza, così come definiti per una v.a. unidimensionale, non
possono essere applicati al caso bidimensionale.
In questo contesto si possono definire il valore atteso congiunto E(XY), la covarianza
Cov(X,Y) e il coefficiente di correlazione lineare ρ (X ,Y ) , dati da:
E (XY ) = ∑ ∑ x ⋅ y ⋅ p (x , y ) ;
x
y
Cov (X ,Y ) = ∑ ∑ (x − E (X ) ) ⋅ (y − E (Y ) ) ⋅ p (x , y ) ;
x
y
6
ρ (X ,Y ) =
Cov (X ,Y )
.
σ (X ) ⋅ σ (Y )
Nota: La covarianza può anche essere calcolata nel seguente modo:
Cov (X ,Y ) = ∑ ∑ (x − E (X ) ) ⋅ (y − E (Y ) ) ⋅ p (x , y ) =
x
y
= ∑ ∑ x ⋅ y ⋅ p (x , y ) −∑ ∑ x ⋅ E (Y ) ⋅ p (x , y ) −∑ ∑ E (X ) ⋅ y ⋅ p (x , y ) +
x
y
x
y
x
y
+ ∑ ∑ E (X ) ⋅ E (Y ) ⋅ p (x , y ) =
x
y
= E (XY ) − E (Y ) ⋅ ∑ x ∑ p (x , y ) −E (X ) ⋅ ∑ y ∑ p (x , y ) +
x
y
y
x
+ E (X ) ⋅ E (Y ) ⋅ ∑ ∑ p (x , y ) =
x
y
= E (XY ) − E (Y ) ⋅ ∑ x ⋅ pX (x ) −E (X ) ⋅ ∑ y ⋅ pY (y ) +E (X ) ⋅ E (Y ) =
x
y
= E (XY ) − E (Y ) ⋅ E (X ) − E (X ) ⋅ E (Y ) + E (X ) ⋅ E (Y ) =
= E (XY ) − E (Y ) ⋅ E (X )
cioè come differenza tra il valore atteso congiunto e il prodotto tra il
valore atteso della distribuzione marginale di X e il valore atteso della
distribuzione marginale di Y.
Esempio 2:
Data la seguente distribuzione congiunta:
X
Y
0
1
2
p(xi)
1
0
2/8
1/8
3/8
2
0
3/8
1/8
4/8
3
1/8
0
0
1/8
p(yJ)
1/8
5/8
2/8
1
7
calcolare il valore atteso congiunto, la covarianza e il coefficiente di correlazione
lineare.
E (XY ) = 1 ⋅ 1 ⋅
E (X ) = 1 ⋅
2
3
1
1 14 7
+ 2 ⋅1 ⋅ + 1 ⋅2 ⋅ + 2 ⋅2 ⋅ =
= ;
8
8
8
8 8 4
3
4
1 7
+ 2⋅ + 3⋅ =
8
8
8 4
Cov (XY ) =
E (Y ) = 0 ⋅
e
7 7 9
7
− ⋅ =−
;
4 4 8
32
2
2
3
4
1 7
7
Var (X ) = 1 ⋅ + 22 ⋅ + 32 ⋅ − =
8
8
8 4
16
2
−7
ρ (X ,Y ) =
1
5
2 9
+1⋅ +2⋅ = ;
8
8
8 8
7
16
32
⋅ 23
=−
64
e
5
2 9
23
Var (Y ) = 1 ⋅ + 22 ⋅ − =
;
8
8 8
64
2
7
= 0,552 .
161
Per comprendere il significato della covarianza e del coefficiente di correlazione
lineare, si consideri l’esempio:
Esempio 3:
Rappresentare mediante un diagramma di dispersione la seguente v.a. doppia:
x
y
P(x, y)
2
1
0,1
2
4
0,1
3
2
0,2
5
2
0,1
5
3
0,2
5
4
0,1
6
4
0,2
8
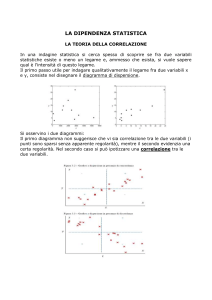
Il diagramma di dispersione non è altro che la rappresentazione delle coppie di punti,
individuati dalle v.a. X,Y e si ottiene ponendo i valori di X sull’asse delle ascisse e quelli
di Y sull’asse delle ordinate. Riportando nel medesimo grafico anche le rette
individuate dai due valori attesi, rispettivamente, di X e di Y, si ha:
E(X) = 4,2
e
E(Y) = 2,9
Diagramma di dispersione
6
5
y
4
X, Y
3
E(X)
2
E(Y)
1
0
0
2
4
6
8
x
La nuvola di punti viene così suddivisa in 4 quadrati, numerati in senso antiorario e
partendo da quello in alto a destra.
Per i punti che si trovano nel I quadrante vale che:
x > E (X ) e y > E (Y )
⇒
(x
− E (X ) ) ⋅ (y − E (Y ) ) > 0
Per i punti che si trovano nel II quadrante vale che:
x < E (X ) e y > E (Y )
⇒
(x
− E (X ) ) ⋅ (y − E (Y ) ) < 0
Per i punti che si trovano nel III quadrante vale che:
9
x < E (X ) e y < E (Y )
⇒
(x
− E (X ) ) ⋅ (y − E (Y ) ) > 0
Per i punti che si trovano nel IV quadrante vale che:
x > E (X ) e y < E (Y )
⇒
(x
− E (X ) ) ⋅ (y − E (Y ) ) < 0
Si può calcolare il valore atteso dei prodotti degli scarti, che non è altro che la
covarianza:
Cov (X ,Y ) = ∑ ∑ (x − E (X ) ) ⋅ (y − E (Y ) ) ⋅ p (x , y ) ,
x
y
che in questo caso vale Cov(X, Y) = 0,82.
Se prevalgono punti nel I e III quadrante la nuvola di punti avrà un andamento
crescente e la covarianza segno positivo; mentre se prevalgono punti nel II e IV
quadrante la nuvola di punti avrà un andamento decrescente e la covarianza segno
negativo.
Se la covarianza è nulla si dice che le due v.a. sono tra loro incorrelate o linearmente
indipendenti (si introduce così un secondo tipo di indipendenza, più debole, dopo quello
di indipendenza stocastica).
Se Cov(X, Y) > 0 la relazione tra X e Y è diretta, per cui a valori bassi di X tendono ad
associarsi valori bassi di Y e a valori elevati di X tendono ad associarsi valori elevati di
Y.
Se Cov(X, Y) < 0 la relazione tra X e Y è inversa, per cui a valori bassi di X tendono ad
associarsi valori elevati di Y e a valori elevati di X tendono ad associarsi valori bassi di
Y.
10
La covarianza non è un valore di facile interpretazione perché non è noto il suo range di
variazione (valore minimo e valore massimo che può assumere), quindi di essa è possibile
dare un’interpretazione del segno (positivo, negativo o nullo), ma non del valore.
Al fine di normalizzare la covarianza è possibile dimostrare che:
[Cov (X ,Y )]2 ≤ Var (X ) ⋅Var (Y )
⇒ − σ X ⋅ σ Y ≤ Cov (X ,Y ) ≤ σ X ⋅ σ Y
da cui si ottiene il coefficiente di correlazione lineare:
ρ (X ,Y ) =
Cov (X ,Y )
σ X ⋅ σY
⇒ − 1 ≤ ρ (X ,Y ) ≤ +1
che risulta pertanto un indice normalizzato tra -1 e +1, in modo tale da tenere conto sia
dei valori positivi che di quelli negativi della covarianza.
Il coefficiente di correlazione lineare misura l’intensità del legame lineare tra due v.a.
X e Y ed ha lo stesso segno della covarianza (infatti il numeratore è positivo o
negativo, mentre il denominatore è sempre positivo).
Tanto più
ρ (X ,Y ) → 1 tanto più la relazione lineare è stretta e i punti si dispongono
più o meno attorno ad una retta.
Se
ρ (X ,Y ) = +1
la relazione tra X e Y è del tipo Y = a + b X (con b > 0) e nel
diagramma di dispersione i punti sono allineati, come nel grafico che segue:
Relazione lineare diretta
30
25
y
20
15
10
5
0
0
2
4
6
8
10
x
11
Se
ρ (X ,Y ) = −1
la relazione tra X e Y è del tipo Y = a + b X (con b < 0) e nel
diagramma di dispersione i punti sono allineati come nel grafico che segue:
y
Relazione lineare inversa
16
14
12
10
8
6
4
2
0
0
2
4
6
8
10
x
Nell’esempio si ha:
ρ (X ,Y ) =
0,82
= 0,534
2,16 ⋅ 1,09
che indica un grado di correlazione lineare diretta di media intensità.
Nota: Confrontando l’indipendenza stocastica con l’indipendenza lineare si può
dire che l’indipendenza stocastica implica quella lineare, ma non vale il viceversa:
Indipenden za stocastica
⇒ Indipenden za
lineare
Esempi di correlazione
I sei grafici che seguono (indicati con le lettere A, B, C, D, E, F) mostrano alcune
situazioni del coefficiente di correlazione lineare ρ(X,Y) che meritano di essere
commentate.
12
A. Un valore del coefficiente di correlazione lineare pari ad 1 indica che tra le due v.a.
X ed Y esiste una perfetta relazione lineare per cui punti del diagramma di dispersione
giacciono tutti su una retta (nel grafico non è così evidente perché i punti sono
migliaia), caratterizzata da un coefficiente angolare positivo. Quindi i valori di Y
possono essere determinati dall’equazione della retta che lega Y ad X.
B. Un valore del coefficiente di correlazione lineare pari a 0,69 indica una relazione
diretta (trend crescente) di media intensità. I punti mostrano in modo evidente il
trend crescente, anche se non si dispongono in modo evidente attorno ad una retta.
C. Il valore del coefficiente di correlazione lineare è ancora pari a 0,69 anche se la
relazione tra X ed Y pur essendo di forma evidente (è di tipo parabolico), non è
assolutamente di tipo lineare. Per valori bassi di X il trend è decrescente, mentre per
valori elevati diventa crescente.
D. Un valore del coefficiente di correlazione lineare pari a –0,96 indica che la relazione
tra X e Y è di tipo lineare e molto stretta (i punti sono “quasi” allineati), ma mostra un
trend decrescente.
E. ed F. Questi ultimi due grafici mostrano due situazioni molto diverse in cui il
coefficiente di correlazione lineare è pari a 0, che indica un caso incorrelazione, cioè di
mancanza di relazione lineare tra X e Y.
Nel grafico E la relazione è molto forte (i punti tendono a disporsi lungo una
circonferenza), ma non è assolutamente lineare, mentre nel grafico F non c’è nessun
tipo di relazione.
13
A
B
D
C
E
F
14
Nota: Per commentare correttamente il valore del coefficiente di correlazione lineare
è importante guardare il grafico; il “numero” potrebbe trarre in inganno (situazione C)!
L’intensità della relazione lineare indicata dal valore potrebbe essere smentita dal
grafico.
Distribuzione ipergeometrica estesa
Questa v.a. doppia discreta non è altro che una generalizzazione della ipergeometrica
in cui, anziché avere solo due risultati possibili (del tipo A e A ), ce ne sono k.
Si consideri un insieme di N unità di cui M1 di tipo A1, M2 di tipo A2, …, Mk di tipo Ak,
con
k
N = ∑ Mi ;
si
estraggano
n
unità
senza
reimmissione.
Per
estensione
i =1
dell’ipergeometrica la probabilità che fra le n unità estratte x1 siano di tipo A1, x2 di
k
tipo A2, …, xk di tipo Ak, con n = ∑ x i , è pari a:
i =1
M1 M2
M
⋅ ⋅ ... ⋅ k
x x
2
xk
p (x 1 , x 2 ,..., x k ) = 1
N
n
, con
x 1 = 0,1,2...; x 2 = 0,1,2...; ...; x k = 0,1,2... e
k
xi
∑
i
=n .
=1
Esempio 4:
Da un’urna contenente 20 palline bianche, 20 rosse e 10 verdi, ne vengono estratte 5
senza reimmissione. Siano X e Y, rispettivamente, il numero di palline bianche e il
numero di palline rosse estratte.
15
Scrivere la funzione di probabilità congiunta di (X, Y) e determinare la probabilità che
siano estratte 2 palline bianche e 2 rosse.
La funzione di probabilità è data da:
10
20 20
⋅ ⋅
x y 5 − x − y
p (x , y ) =
50
5
x ≥0
x + y ≤ 5,
y ≥0
mentre la probabilità di estrarre 2 palline bianche e 2 rosse è pari a:
20 20 10
⋅ ⋅
2
2
1
p ( x , y ) = = 0,1704 .
50
5
Distribuzione multinomiale
Questa v.a. doppia discreta non è altro che una generalizzazione della binomiale in cui,
anziché avere solo due risultati possibili (del tipo A e A ), ce ne sono k.
Si consideri un insieme di N unità di cui M1 di tipo A1, M2 di tipo A2, …, Mk di tipo Ak,
k
con N = ∑ Mi ; per cui
i =1
p1 =
M
M1
M
, p2 = 2 ,..., pk = k . Si estraggano n unità con
N
N
N
reimmissione. Per estensione della binomiale la probabilità che fra le n unità estratte
k
x1 siano di tipo A1, x2 di tipo A2, …, xk di tipo Ak, con n = ∑ x i , è pari a:
i =1
p (x 1 , x 2 ,..., x k ) =
n!
x 1 !⋅x 2 !⋅... ⋅ x k !
⋅ p1 x ⋅ p2 x ⋅ ... ⋅ pk xk , con
1
2
x 1 = 0,1,2...; x 2 = 0,1,2...; ...; x k = 0,1,2... e
16
k
xi
∑
i
=1
=n .
Esempio 5:
In una città il 10% delle famiglie possiede più di una casa, il 70% solo la prima casa, il
20% non possiede case. L’ufficio tributario del comune, al fine di effettuare un
controllo, estrae un campione con reinserimento di 10 famiglie.
Si determini la probabilità che nel campione entrino 6 famiglie che possiedono una sola
casa e 2 famiglie che non possiedono casa.
Si ricerca quindi la probabilità che fra le 10 famiglie estratte 2 possiedano più di una
casa, 6 possiedano una casa e 2 non possiedano case:
P (X 1 = 1, X 2 = 7, X 3 = 2) =
10!
⋅ 0,10 2 ⋅ 0,70 6 ⋅ 0,20 2 = 0,0593 .
2! ⋅ 6! ⋅ 2!
DISUGUAGLIANZA DI CHEBYSHEV
Sotto determinate condizioni la distribuzione di una qualsiasi v.a., discreta o continua,
soddisfa sempre questa disuguaglianza, che fornisce un limite superiore per la
probabilità che un valore x cada all’esterno dell’intervallo (E(X) - t; E(X) + t).
Sia X una v.a. qualsiasi con valore atteso E(X) e varianza σ2 e sia t > 0 una quantità
prefissata; allora vale la seguente disuguaglianza:
(1): P {X − E (X ) ≥ t } ≤
σ2
t2
∀t > 0 ,
che può anche essere riscritta fornendo un limite inferiore per la probabilità che un
valore x cada all’interno dell’intervallo (E(X) - t; E(X) + t) :
(2): P {X − E (X ) < t } > 1 −
σ2
t2
∀t > 0 .
17
La disuguaglianza di Chebyshev viene utilizzata per avere delle informazioni sulla
probabilità di una v.a. quando di questa si conoscono solo il valore atteso e la varianza,
ma non la distribuzione di probabilità.
µ-t
µ
µ+t
Quindi la disuguaglianza di Chebyshev permette di affermare che la probabilità di
ottenere un valore all’interno dell’intervallo [E(X) - t; E(X) + t] è sempre > 1 −
σ2
,
t2
mentre la probabilità di ottenere un valore all’esterno del medesimo intervallo è
sempre ≤
σ2
.
t2
Esempio 6:
Un supermercato ha acquistato una partita di patate confezionata in sacchi del peso
medio di 10,2 kg con varianza pari 0,36 kg.
Se non si conosce la distribuzione del peso di un sacco di patate, calcolare la
probabilità che un sacco abbia un peso tra i 9,5 i 10,9 kg.
Se la distribuzione del peso di un sacco di patate è di tipo normale, calcolare la
probabilità che un sacco abbia un peso tra i 9,5 i 10,9 kg.
Dato che non si conosce la distribuzione di X per determinare la probabilità si può
utilizzare la disuguaglianza di Chebyshev.
In questo caso t = 0,7
P {X − 10,2 < 0,7} > 1 −
0,36
= 1 − 0,735 = 0,265 .
0,7 2
18
Se si ipotizza, invece, la distribuzione normale:
9,5 − 10,2
P (9,5 < X < 10,9) = P
0,36
<Z <
10,9 − 10,2
=
0,36
= P ( −1,17 < Z < 1,17 ) = 0,758.
COMBINAZIONE LINEARE DI V.A.
Si definisce combinazione lineare di n variabili aleatorie indipendenti X1, X2, …,Xn con
pesi a1, a2, …, an:
Y = a1X1 + a2X2 + ... + an Xn .
Il valore atteso e la varianza della combinazione lineare possono essere calcolati come:
E (Y ) = a1E (X 1 ) + a2E (X 2 ) + ... + an E (X n )
Var (Y ) = a12Var (X 1 ) + a22Var (X 2 ) + ... + an2Var (X n ) =
Se le n variabili aleatorie sono tutte distribuite secondo una normale, allora anche Y si
distribuisce in modo normale.
Se le n variabili aleatorie, oltre ad essere indipendenti, sono anche identiche (cioè
hanno la stessa distribuzione) e i pesi sono tutti pari ad 1/n, si ottiene la media
campionaria:
X =
X1 + X2 + ... + Xn
, per la quale si hanno valore atteso e varianza pari a:
n
19
E (X ) = E (X )
e
Var (X ) =
Var (X )
.
n
Esempio 7:
Una variabile aleatoria normale X ha valore atteso µ e varianza σ2 finite.
Siano X1, X2, …, X40 40 variabili aleatorie indipendenti e identiche a X.
Determinare il valore atteso della variabile aleatoria S = X1 + X2 + … + X40.
Determinare la varianza della variabile aleatoria S = X1 + X2 + … + X40.
Dire, giustificando il risultato, se il coefficiente di variazione della variabile aleatoria
somma S è maggiore, minore o uguale di quello della variabile X.
Per il valore atteso si ha:
E (S ) = E (X 1 + ... + X 40 ) = E (X 1 ) + ... + E (X 40 ) = µ + ... + µ = 40 µ .
Per la varianza si ha:
Var (S ) = Var (X 1 + ... + X 40 ) = Var (X 1 ) + ... +Var (X 40 ) = σ 2 + ... + σ 2 = 40σ 2 .
Per quanto riguarda il coefficiente di variazione, definito come il rapporto tra lo
scarto quadratico medio e il valore atteso, si ottiene:
CV (X ) =
σ
µ
CV (S ) =
40σ 2 σ
40
1
.
= ⋅
= CV (X ) ⋅
40 µ
µ 40
40
La variabile S risulta pertanto avere un coefficiente di variazione minore rispetto alla
variabile X.
20
Esempio 8:
Un supermercato ha acquistato una partita di patate confezionata in 100 sacchi del
peso medio di 10,2 kg con varianza pari 0,36 kg.
Si determini il valore atteso del peso medio dei sacchi presenti in magazzino e la sua
variabilità.
Si determini la probabilità che il peso medio dei sacchi di patate sia superiore ai 10 kg.
Considerando il peso medio dei 100 sacchi si ha
E (X ) = E (X ) = 10,2
Var (X ) =
Var (X ) 0,36
=
= 0,0036.
n
100
P (X > 10) = P Z >
10 − 10,2
= P (Z > −3,33) = 1 − 0,9996 = 0,0004.
0,0036
TEOREMA DEL LIMITE CENTRALE
Siano X1, X2, ..., Xn n variabili aleatorie indipendenti ed identicamente distribuite con
media E(Xi) = E(X) e varianza Var(Xi) = σ2.
Sia Sn = X1 + X2 + ... + Xn la variabile aleatoria ottenuta come somma delle variabili
aleatorie Xi con media E(Sn) = nE(X) e varianza Var(Sn) = nσ2. Allora si ha che:
Sn − nE (X )
P
lim
n
→∞
nσ
2
≤ z = Φ(z )
quindi per n → ∞ la standardizzazione della v.a. Sn tende a distribuirsi come una
normale standardizzata.
21
Fra le numerevoli applicazioni del teorema del limite centrale il nostro interesse è
soprattutto rivolto al limite della distribuzione binomiale.
Infatti se X segue una distribuzione binomiale (n, p), allora se n → ∞ è possibile
dimostrare che la distribuzione tende ad una normale standardizzata,
Sn − np
≤ z = Φ(z ) .
np (1 − p )
lim P
n →∞
Esempio 9:
Un’indagine ha mostrato che la probabilità di laurearsi in corso per uno studente
iscritto alla facoltà di economia di Milano è pari a 0,15.
Se vengono estratti con reinserimento 8 studenti immatricolati lo stesso anno,
determinare la probabilità che non più di due si laureino in corso.
Se vengono estratti con reinserimento 400 studenti immatricolati lo stesso anno,
calcolare la probabilità che almeno 80 si laureino in corso.
La probabilità che non più di due studenti si laureino in corso è determinata utilizzando
la binomiale:
P (X ≤ 2) = P (X = 0) + P (X = 1) + P (X = 2) =
8
8
8
= ⋅ 0,15 0 ⋅ (1 − 0,15) 8 + ⋅ 0,151 ⋅ (1 − 0,15) 7 + ⋅ 0,152 ⋅ (1 − 0,15) 6 =
0
1
2
= 0,2725 + 0,3847 + 0,2376 = 0,8948.
Considerando, invece, un campione di 400 studenti (n è quindi grande) si può applicare
l’approssimazione della binomiale alla normale. Il valore atteso e la varianza sono pari a:
22
E (X ) = n ⋅ p = 400 ⋅ 0,15 = 60
Var (X ) = n ⋅ p ⋅ (1 − p ) = 400 ⋅ 0,15 ⋅ (1 − 0,15) = 51
per cui:
X −n ⋅ p
80 − 60
≥
= P (Z ≥ 2,8) = 1 − Φ(2,8) = 0,0026.
n ⋅ p ⋅ (1 − p )
51
P (X ≥ 80) = P
Φ(2,8) è determinato sulle tavole della normale standardizzata ed è pari a 0,9974.
23