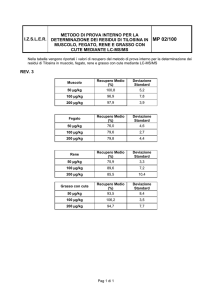
Distribuzione Gaussiana
- Facciamo un riassunto Nell’ipotesi che i dati si distribuiscano seguendo una curva Gaussiana è possibile dare un
carattere predittivo alla deviazione standard
• La prossima misura ha il 68 % di probabilità di cadere all’interno dell’intervallo
x ; x
• La prossima misura ha il 95 % di probabilità di cadere all’interno dell’intervallo
x 2 ; x 2
• La prossima misura ha il 99.7 % di probabilità di cadere all’interno dell’intervallo
x 3 ; x 3
La deviazione standard quindi:
• E’ una quantità associata alla singola misura
• E’ una stima quantitativa della incertezza su una singola misura
• E’ una stima quantitativa della dispersione delle singole misure
• E’ una stima della larghezza della distribuzione di probabilità delle misure
• NON è una stima dell’errore del valor medio ottenuto
• NON è una stima dell’incertezza statistica presente nel nostro valor medio
• NON dipende dal numero di misure effettuate
• Che variabile statistica quantifica l’errore/incertezza presente nel valor medio ?
Deviazione Standard della Media
Abbiamo visto precedentemente (e si può dimostrare con il teorema del limite centrale) che
l’incertezza a cui è soggetto il valore medio è data dal rapporto della deviazione standard con
la radice quadrata del numero di misure effettuate.
Deviazione standard della media m x
N
Altri nomi della Deviazione Standard della media (SDOM) sono:
• Errore Standard
• Errore Standard della Media
• La Deviazione Standard della media decresce con l’aumentare del numero di misure
Nell’ipotesi di:
• Aver effettuato N misure della medesima quantità (misure ripetute ed indipendenti).
• NON siano presenti errori sistematici.
C’e’ il 68% di probabilità che il valore xvero sia all’interno dell’intervallo (xbest – m; xbest + m).
Il valore xbest è estratto attraverso il processo di media.
Analogamente per il 95% ed il 99.7% di probabilità con 1.96m e 3m
DEFINIZIONI
Deviazione Standard
La deviazione standard è una stima dell’incertezza sulla singola misura, in altre parole è una
valutazione quantitativa delle fluttuazioni casuali e quindi di come si disperdono le singole
misure attorno al valore medio. In particolare, nella gaussiana, esiste il 68% di probabilità
che una singola misura sia all’interno dell’intervallo (xbest – ; xbest + )
Deviazione Standard della Media m
La deviazione standard della media è una stima dell’incertezza sul valor medio, in altre
parole è una valutazione quantitativa di quanto (in assenza di errore sistematico) xbest è
lontano da xvero . In particolare, esiste il 68% di probabilità che xvero sia all’interno
dell’intervallo (xbest – m; xbest + m)
Nota Importante
Voglio conoscere il valore di una osservabile m attraverso una operazione di misura.
Ipotizzo che i dati si distribuiscano secondo una gaussiana attorno al valore medio
Effettuo N misure (indipendenti e ripetibili) dell’osservabile.
• Estraggo il valore medio xbest (la migliore stima del valore vero)
• Estraggo la deviazione standard del campione s (la migliore stima di )
• Estraggo la deviazione dalla media sm (la migliore stima del mio errore)
• Estraggo il valore dell’osservabile ‘z’
z
xbest x0
• Posso quindi affermare che ho il 68% (z=1) di probabilità che il valore vero sia nell’intervallo
(xmedio ± m) o il 99.7% (z=3) che il valore vero sia nell’intervallo (xmedio ± 3m)
Tuttavia:
• per estrarre la deviazione dalla media devo usare la deviazione standard, che tuttavia non
conosco ma di cui ho una stima (la deviazione standard del campione) non
necessariamente corretta.
• Come posso stimare l’errore della misura o la variabile ‘z’ se non conosco il valore vero della
deviazione standard ?
• Se il numero di misure N è ‘piccolo’ posso aspettarmi che il valore della deviazione standard
del campione possa essere molto differente dal valore vero della deviazione
standard
Il grafico riporta l’andamento della deviazione standard al variare del numero di misure nel
caso di un dado equiprobabile. Il valore ‘vero’ è indicato dalla linea gialla.
Osservate che dopo 3-5 tiri la deviazione standard del campione può essere molto
differente dal valore vero della deviazione standard
Per risolvere questo problema bisogna studiare la distribuzione dell’osservabile ‘z’ quando
è estratta usando la deviazione standard del campione di N misure. Questa osservabile è
in linea di principio differente dalla ‘z’ e molti libri la definiscono come ‘t’
La distribuzione dell’osservabile ‘t’ è stata calcolata da William Sealy Gosset, nel 1905 con lo
pseudonimo di Student e quindi nella storia passata come “Student’s t distribution” ed è
data dalla relazione:
2 n 1 / 2
1 Gn 1 / 2 t
1
p(t ,n )
n Gn / 2 n
Dove G indica una funzione matematica speciale (vedi pg. 196 del Bevington).
Nella formula l’osservabile ‘n’ indica il numero di gradi di libertà (n = N-1 se dal medesimo
set di dati si estrae anche il valor medio) e l’osservabile ‘t’ è data dalla relazione
t
x x0
x
x valor medio estratto dai dati
x deviazione standard estratta dai dati
P(t,n) indica quindi la probabilità di ottenere in una misura un valore che corrisponde ad
un determinato valore di t avendo fatto un numero di misure pari a N che corrispondono a
n gradi di liberta.
P(z) è l’equivalente di P(t,n) per una gaussiana -> Esempio P(Z=1)=68%
-Nel caso di una gaussiana, la probabilità di ottenere un valore superiore a |xo+x| in una
misura (che corrisponde a z=1) è del 68%
Notate che non c’e’ dipendenza dal numero di misure
Nota:
• La distribuzione ha code più lunghe rispetto alla Gaussiana standard
• All’aumentare di N la distribuzione "t" di Student tende alla Gaussiana standard.
f(t)
0.4
Notate che, nel caso di tre misure
(n=2) la probabilità di ottenere
|t| 2 con una distribuzione
gaussiana è più bassa (4.6%) che
con la distribuzione ‘t Student’
18.3%.
gaussiana
0.3
0.2
p=0.1
0.1
Questo andamento è intuitivo
poiché non conoscendo il valore
vero di devo ridurre la
predittività della misura
p=0.1
t di Studentn (n=2)
0
-8
-6
-4
-2
0
2
4
6
t8
Esempio 2, una probabilità inferiore al 5% (su un dataset di tre misure) la ottengo
con dato che dista circa 4.1 dal valore medio (non 2)
La pagina 266 del Bevington (e la tabella che segue) indicano il valore dell’integrale della
distribuzione della ‘t’ di Student nell’intervallo da x1 = <x> - tx a x2 = <x> + tx fissato il
valore dell’osservabile ‘t’ e del numero di gradi di libertà.
Facciamo un esempio:
• Vengono fatte n (numero piccolo) misure e si ottiene un valor medio di 5,88 ed una
deviazione della media di 0,31 (Il valore atteso è pari a 6.50)
• Nel caso di una distribuzione gaussiana il parametro z assume un valore pari a
z = (6.50-5,88)/0.31 = 2, in altre parole il valor medio misurato dista due deviazioni
standard della media misurate dal valore atteso.
• Se la deviazione standard misurate fosse esattamente quella vera (e quindi anche la
deviazione dalla media) potremmo dire che esiste il 4.6 % di probabilità che la
distanza tra il valore misurato ed il valore atteso sia dovuto alle fluttuazioni
statistiche
• la misura, tuttavia, ha dato solo una stima, non necessariamente precisa, della
deviazione standard. Lo sperimentatore NON conosce il vero valore di
• Questo è il tipico caso in cui è utile la distribuzione della ‘t’ Student
Quindi:
L’osservabile ‘z’ è una variabile statistica definita come
z
x x0
tot
Dove la deviazione standard tot indica la deviazione standard ‘vera’ , quindi non nota a
meno di fare infinite misure, della differenza (<x> - x0)
Come per tutte le variabili statistiche quindi ‘z’ sarà nota con una certa precisione, questa
dipende soprattutto dalla precisione con cui si conosce tot
Ogni affermazione statistica che fa uso della variabile ‘z’ deve tenere conto del fatto che
‘z’ può avere una sua incertezza, quindi nel caso della stima della probabilità di una
gaussiana:
Se ho un elevato numero di misure
- Posso considerare misurata praticamente uguale alla vera e quindi usare la
probabilità integrale della gaussiana (osservabile z)
-Se ho poche misure
- E’ possibile che la misurata sia differente dalla vera, quindi per tenere conto di
questa incertezza non devo usare la probabilità integrale gaussiana ma la
tabella della ‘t’ di Student
La tabella degli integrali della distribuzione ‘t Student’ (distribuzione a due code) per t = 2
La tabella ERF mi dice che P(z=2) = 4.6% (ma non è necessariamente vero che t=z)
Probabilità che la differenza di due dal valor medio
sia dovuta ad una fluttuazione statistica (t=2)
Gradi di Liberta
Numero Misure
2
3
18.3 %
3
4
13.9 %
4
5
11.6 %
5
6
10.2 %
8
9
8 .0%
10
11
7.3 %
20
21
5.9 %
50
51
5.1 %
infinite
Infinite
4.6 %
Notate che si usa z per la gaussiana e t per ‘Student’
Notate che per un numero infinito di misure t=z (le due distribuzioni sono uguali)
Notate che il risultato dipende dal numero di misure
Notate che la tabella fornisce la compatibilità o meno tra valori medi o tra una media e un
valore atteso. In altre parole indica la probabilità entro il quale ci aspettiamo che il
valore atteso sia entro due sigma o sigma-m
La tabella C.8 pg 266
del Bevington
Notate che se (con
tre misure) ottengo
t = 2 allora ho una
Probabilità di 1-0.817
= 18.3% che le
misure appartengano
alla distribuzione
statistica attesa
La tabella da
l’integrale interno
Cosa bisogna fare quando ho poche misure:
Esempio:
ho 4 Misure che mi hanno dato un valore medio di 5.32 ed una deviazione standard della media 0.17.
Voglio verificare la compatibilità di questo risultato con un valore atteso di 4.92.
•
•
La funzione ERF della gaussiana (‘z’), poiché costruita con la deviazione standard del campione non
produce le corrette probabilità
Estraggo l’osservabile ‘t’ usando la deviazione standard misurata
• tstud = (5.32 – 4.92)/0.17 = 2.35
•
Utilizzando la tabella della ‘t di Student’ trovo la probabilità associata alla ‘t’ ottenuta
• P(esterna,tstud=2.35) = 1 – 0.90 = 0.1
•
Ricavo la probabilità equivalente a 0.1 = 10% con la funzione ERF gaussiana
• P(gaussiana-esterna)= 10% -> zgauss = 1.64
•
Eseguo tutti i ragionamenti di compatibilità come se la ‘t’ ricavata dai miei dati sperimentali fosse 1.64
• Poiché zgauss < 2 allora il dato sperimentale è compatibile con il valore atteso
• Ho il 10% di probabilità che la differenza tra la mia misura e il valore atteso sia di origine
statistica e quindi lo accetto
•
Se non avessi usato la distribuzione di ‘Student’ avrei concluso la NON compatibilità tra il dato
sperimentale e quello atteso . La bassa statistica invece rende la misure compatibili
T di student
N Misure-1
P(t,n)=P(2.35,3) ≈ 90 %
1- P(2.35,3) = 10%
Gaussiana
P(z)=90 % z = 1.65
L’esempio di prima ci dice che
Se avete 4 Misure (cioè 3 GDL) e volete trovare l’intervallo in cui cadono il 90% delle misure (cioè un
C.L. del 90%) allora l’intervallo sarà dato da ± tstud con tstud =2.35.
Se fosse stata usata la statistica gaussiana ‘pura’ avrei dovuto avere un intervallo pari a z z1.65
Altro esempio
Se avete 4 misure (i.e. 4 -> 3 GDL) e volete un risultato ad un C.L. 99.7% cioè volete trovare l’intervallo
entro il quale cadono il 99.7 % delle misure allora tstud deve essere pari a circa 9.2. e quindi l’intervallo
sarebbe ± tstud
Se fosse stata usata la statistica gaussiana ‘pura’ avrei dovuto avere un intervallo pari a z z3
In questo caso quindi l’intervallo diventa enorme e poco utile/predittivo. Poche misure sono poco
predittive.
http://www.tutor-homework.com/statistics_tables/statistics_tables.html
Livello di confidenza
Abbiamo visto che nel caso di un numero infinito di misure ripetibili ed indipendenti
che si distribuiscano secondo una gaussiana il 68 % dei dati sperimentali deve cadere
all’interno di una deviazione standard.
In altre parole abbiamo un “livello di confidenza” che, eseguendo una misura più volte,
nel 68% dei casi il risultato cadrà entro una deviazione standard.
Spesso, ma non sempre, si sceglie la deviazione standard, un livello di confidenza del
68%, come riferimento.
Ovviamente questo non vale per una distribuzione poissionana o piatta.
Per distribuzioni non gaussiane si fa il viceversa, si dice [x1, x2] al 95% C.L.
Questo significa che il 95% delle misure cadono nell’intervallo [x1, x2]
In generale quando la misura è molto più piccola dell’errore (esempio 0.2 ± 12) anche se
la distribuzione è gaussiana si usa il livello di confidenza
- ad esempio [-11.8, 12.2] 68% C.L.