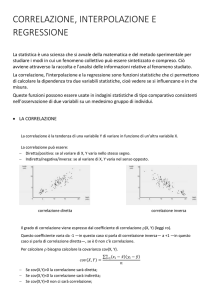
INTERPOLAZIONE STATISTICA
Nell’esame di fenomeni collettivi spesso ci troviamo a confrontare le coppie di valori tra
due variabili ipotizzando vi sia una relazione tra loro; è noto, ad esempio, vi sia relazione
tra prezzo e domanda di un bene, reddito e consumo, altezza e peso.
Per stabilire l’esistenza di un legame tra due variabili è opportuno:
a) raccogliere i dati e organizzarli ordinatamente in una tabella;
b) disporre le coppie dei dati in un grafico cartesiano;
c)
studiare l’andamento tabellare e grafico alla ricerca di relazioni funzionali;
d) ipotizzare un legame mediante una funzione del tipo y = f (x ) che possa sintetizzare
e rappresentare al meglio la relazione tra le variabili.
La tabella 1 riporta la rilevazione tra l’altezza e il numero di scarpe e il relativo grafico
cartesiano di un gruppo di persone:
tabella 1
numero scarpe reale
160
162
162
163
165
165
165
165
166
166
167
170
170
172
175
175
187
38
39
41
37
40
43
43
39
40
39
41
40
42
41
42
44
46
49
numero scarpe
altezza in cm
44
39
34
155
160
165
170
175
180
185
190
altezza in cm
Dall’analisi tabellare notiamo che all’aumentare dell’altezza tende ad aumentare anche il
numero delle scarpe; osservando il grafico notiamo una nuvola di punti estesi secondo un
andamento che potremmo ipotizzare di tipo lineare. La scelta successiva sarà quella di
supporre una funzione che possa sinteticamente descrivere il legame.
Per determinare la funzione si può procedere in due modi :
interpolazione per punti ( o interpolazione matematica ), determinazione di una funzione
che passi esattamente per tutti i punti noti ;
interpolazione fra punti ( o interpolazione statistica ), determinazione di una funzione che
passi tra i punti osservati .
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 1 di 13
METODO DEI MINIMI QUADRATI
Il metodo dei minimi quadrati si basa sull’interpolazione fra punti. Indicate con X e Y
rispettivamente la variabile supposta indipendente e quella supposta dipendente , con N il
numero delle osservazioni, con (x1; y1 ) ,
( x2 ; y 2 ) ,
… (xi ; yi ) , …
(x N ; y N )
le coppie dei
singoli valori osservati , si ordinano le coppie in una tabella e le si rappresentano altresì
graficamente in un piano cartesiano . Il grafico è costituito da una nuvola di punti, le
singole coppie, e viene chiamato DIAGRAMMA A DISPERSIONE O SCATTER .
asse Y
DIAGRAMMA A DISPERSIONE O SCATTER
asse X
Dall’esame del grafico bisogna ipotizzare e scegliere la funzione interpolante che meglio
rappresenti la nuvola di punti, l’andamento del fenomeno ; una volta scelta la funzione che
può essere lineare, iperbolica, esponenziale, è necessario determinare i parametri della
funzione ; nel caso della retta , ad esempio , bisogna determinare i parametri a e b ,
rispettivamente intercetta sull’asse y e coefficiente angolare .
Scelti i parametri della funzione andremo a sostituire le vecchie coppie (xi ; yi ) di valori
reali con le nuove coppie (xi ; yi∗ ) dove yi∗ o f * ( xi ) sono le frequenze teoriche calcolate
sulla base dei parametri della funzione interpolante.
La differenza tra valori reali e valori teorici
d i = yi − yi∗ rappresenta l’errore che si
commette nell’interpolazione per cui l’obiettivo è quello di scegliere una funzione
interpolante che minimizzi gli errori.
Il metodo dei minimi quadrati si basa sulla condizione di accostamento tra i valori reali e
i valori teorici in modo che sia minima la somma dei quadrati delle differenze tra valori reali
e valori teorici :
N
∑( y
i
− yi∗ ) 2 = MINIMO
i =1
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 2 di 13
errori della retta interpolante
14
12
10
8
6
4
2
0
0
5
10
15
20
25
30
35
I punti del grafico rappresentano
le osservazioni reali, le coppie
( xi ; yi ) , la retta interpolante i valori
teorici, i segmenti che uniscono i
punti con la retta sono gli errori
d i , al di sopra della retta quelli per
difetto ( valori reali maggiori di
quelli teorici) e al di sotto della
retta quelli per eccesso.
Scelto il tipo di funzione ( retta, parabola, esponenziale, iperbole ) il metodo dei minimi
quadrati assicura il migliore accostamento relativo a quella tipologia ; se l’interpolante è
una retta il metodo offre la migliore retta tra le infinite rette interpolanti, cioè quella con il
migliore accostamento ; se l’interpolante è una parabola il metodo offre la migliore delle
parabole; il metodo non fornisce la migliore interpolante, la scelta del tipo di funzione
appartiene al ricercatore in base al grafico, alla relazione logica tra le due variabili e anche
allo scopo della ricerca.
Una scelta sbagliata della funzione interpolante , non rispondente all’andamento del
fenomeno, porta esclusivamente alla migliore interpolante tra tutte quelle dello stesso tipo
ma non garantisce assolutamente il migliore degli accostamenti possibili.
Una volta scelta la funzione si può calcolare un indice di scostamento per verificare la
bontà di adattamento della funzione ai valori reali :
N
∑( y
i =1
I=
con I ≤ 0,1 per avere un buon accostamento, in alcuni casi è
− yi∗ )2
i
richiesto un valore ancora più piccolo I ≤ 0,01 .
N
N
∑y
∗
i
i =1
N
FUNZIONE INTERPOLANTE LINEARE
Data l’equazione della retta y = a + bx , dove il coefficiente a è l’intercetta sull’asse delle
ordinate e il coefficiente b il coefficiente angolare , la migliore retta interpolante con il
metodo dei minimi quadrati si rappresenta mediante la seguente funzione da minimizzare:
N
N
ϕ ( a, b) = ∑ ( yi − y ) = ∑ ( yi − a − bxi )2 con a e b i parametri da calcolare.
∗ 2
i
i =1
i =1
Si tratta di calcolare il minimo di una funzione a due variabili a, b ; calcoliamo le derivate
prime parziali rispetto alle due variabili ponendole uguali a zero:
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 3 di 13
N
'
−
D
=
2
⋅
( yi − a − bxi ) ⋅ ( −1) = 0
∑
a
i =1
=
N
D ' = 2 ⋅ ( y − a − bx ) ⋅ ( − x ) = 0 −
∑
i
i
i
b
i =1
N
N
Na
+
b
x
=
yi
∑
∑
i
i =1
i =1
i =1
i =1
= N
(1)
N
N
N
N
N
2
2
xi yi + a ∑ xi + b∑ xi = 0 a ∑ xi + b∑ xi = ∑ xi yi
∑
i =1
i =1
i =1
i =1
i =1
i =1
N
∑y
N
i
+ Na + b∑ xi = 0
Si dimostra che sia il relativo Hessiano sia la derivata seconda Da' ',a sono maggiori di zero
e pertanto la risoluzione del sistema ( 1 ) fornirà i parametri incogniti a e b .
Oltre allo schema precedente , si dimostra che i parametri della retta interpolante a e b
possono essere calcolati mediante le seguenti formule:
−
N
b=
∑(x
i =1
i
− x ) ⋅ ( yi − y )
N
−
∑(x
i =1
−
−
i
− x)
;
2
a = y − bx ,
−
con xi − x e yi − y gli scarti di ogni valore rispetto alla media aritmetica.
Ricordiamo che il coefficiente a esprime il valore della variabile y quando la variabile x
assume il valore zero , graficamente è il punto dove la retta taglia l’asse y , il valore del
carattere y quando il carattere x è nullo; il coefficiente angolare b esprime la pendenza
della retta, positiva se b > 0 , negativa se b < 0 , nulla (retta parallela all’asse x ) se b = 0 ;
dal punto di vista algebrico il coefficiente b esprime la variazione delle ordinate
all’aumentare unitariamente delle ascisse , si ottiene anche come rapporto incrementale
della variazione delle ordinate e la variazione delle ascisse b =
y j − yi
x j − xi
.
Dalla retta interpolante y = a + bx , sostituendo al parametro a l’espressione ottenuta con
−
−
il metodo dei minimi quadrati si ottiene y = y − b x + bx e quindi
−
−
y − y = b ⋅ ( x − x)
− −
La coppia delle medie aritmetiche x; y è chiamato baricentro della distribuzione .
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 4 di 13
Esempio.
La tabella sottostante riporta il prezzo di un bene di largo consumo e la relativa quantità domandata in
cinque distinti periodi; calcolare la retta dei minimi quadrati e l’indice di scostamento
risoluzione
mediante il
sistema
coppie rilevate
rilevazione 1
rilevazione 2
rilevazione 3
rilevazione 4
rilevazione 5
totale
media
.
risoluzione mediante la formula degli scarti
−
−
−
−
−
xi
yi
xi2
xi ⋅ yi
xi − x
yi − y
( xi − x ) ⋅ ( y i − y )
( xi − x ) 2
12
13
15
16
19
75
15
100
95
90
86
74
445
89
144
169
225
256
361
1155
1200
1235
1350
1376
1406
6567
-3
-2
0
1
4
0
11
6
1
-3
-15
0
-33
-12
0
-3
-60
-108
9
4
0
1
16
30
N
N
Na
+
b
x
=
yi
∑
∑
i
5a + 75b = 445
i =1
i =1
A) risoluzione mediante il sistema :
=
e applicando
N
N
N
75
a
+
1
.
155
b
=
6567
2
a x + b x = x y
∑
∑
i
i
i i
∑
i =1
i =1
i =1
a = 143 ; la retta avrà equazione y = −3,60 x + 143 .
b = −3,60
uno dei vari metodi di risoluzione si ottiene
b=
B) Applicando la formula degli scarti si ottiene
∑ ( x − x ) ⋅ ( y − y ) = − 108 = −3,60 ,
30
∑ ( x − x)
i
i
2
i
a = y − b x = 89 − ( −3,60) ⋅ 15 = 89 + 54 = 143
N
∑( y
C) per calcolare l’indice di scostamento
i =1
I=
i
− yi∗ ) 2
N
N
∑y
bisogna calcolare i valori teorici y i∗ = a + bxi ;
∗
i
i =1
N
ad
esempio,
il
primo
valore
y1∗ = a + bx1 = 143 − 3,60 ⋅ 12 = 99,80 .
Il
secondo
valore
y2∗ = a + bx2 = 143 − 3,60 ⋅ 13 = 96,20 .La tabella sarà la seguente:
coppie rilevate
Valori
teorici
∗
xi
yi
yi
Valore 5
12
13
15
16
19
100
95
90
86
74
Totale
75
445
99,8
96,2
89
85,4
74,6
445
Valore 1
Valore 2
Valore 3
Valore 4
Errori
di
∗
yi - y i
0,20
-1,20
1,00
0,60
-0,60
0,00
quadrato
degli errori
(y
i
−y
)
∗ 2
i
0,04
1,44
1
0,36
0,36
3,20
N
∑(y
i =1
I=
i
− yi∗ ) 2
N
N
∑y
i =1
∗
i
3,20
5 = 0,009
=
445
5
N
L’indice denota un buon accostamento.
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 5 di 13
REGRESSIONE
La regressione e la correlazione studiano la relazione tra variabili e permettono di
individuare il legame , se esiste, tra le variabili oggetto di studio.
Nello studio della regressione si suppone che il legame tra una variabile e l’altra sia di
dipendenza dell’una rispetto all’altra. Pertanto si suppone che una variabile assuma valori
predeterminati e l’altra variabile si considera dipendente dalla prima.
( esempi: statura e peso; quantità di fertilizzante e quantità del prodotto raccolto; età e
pressione sanguigna; funzione della domanda che esprime il legame tra il prezzo e la
quantità domandata; consumo e reddito).
Nello studio della correlazione nessuna delle due variabili assume un ruolo preponderante
nel determinare il valore dell’altra.
•
Scopo della regressione è quello di misurare la dipendenza di una variabile rispetto
all’altra.
•
Scopo della correlazione è quello di misurare il grado di interdipendenza tra le variabili.
La funzione di regressione più utilizzata è quella lineare e abbiamo così la regressione
lineare e la correlazione lineare dove si suppone che la dipendenza tra le variabili possa
essere studiata mediante l’equazione della retta .
Date N coppie di valori (xi;yi) le stesse si possono rappresentare mediante il DIAGRAMMA
A DISPERSIONE .
altezza in cm
numero calzatura
160
38
162
39
162
41
163
37
165
40
165
43
165
44
166
40
166
39
167
41
170
40
170
42
172
41
175
42
175
44
187
46
La tabella riporta la distribuzione di 16 individui
secondo l’altezza e il rispettivo numero delle scarpe.
Rappresentando graficamente le coppie dei punti si
ottiene il seguente diagramma a dispersione:
50
48
46
44
42
40
38
36
34
155
160
165
170
175
180
185
altezza in cm
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 6 di 13
190
Lo studio della regressione consiste nel trovare una funzione y = f (x ) che esprime al
meglio il legame esistente tra le variabili.
Nella regressione lineare bisogna pertanto determinare una funzione lineare , la retta, che
esprime nel modo più rappresentativo possibile la relazione esistente tra le due variabili X
( variabile indipendente ) e Y ( variabile dipendente) .
L’equazione della retta teorica sarà :
y = a1 + b1 x
dove
-
a1 esprime il valore che assume y quando il carattere x è nullo e
-
b1
, coefficiente angolare della retta, chiamato primo coefficiente di regressione ,
esprime di quanto varia in media il carattere y al variare di una unità del carattere x .
Se si vuole studiare la interdipendenza tra le variabili , si scambiano le variabili x e y in
modo che la variabile y diventi variabile indipendente ; si introduce la seconda retta
x = a2 + b2 y
dove
-
a2 esprime il valore che assume x quando il carattere y è nullo e
-
b2 , chiamato secondo coefficiente di regressione , esprime di quanto varia in media il
carattere x al variare di una unità del carattere y .
I parametri a1 ; b1 ; a2 ; b2 si determinano mediante il metodo dei minimi quadrati che
garantisce il migliore accostamento tra valori osservati e valori teorici.
I valori dei coefficienti si ricavano dalle seguenti formule :
−
N
b1 =
i =1
−
N
∑(x
i =1
∑(x
i
i
−
− x ) ⋅ ( yi − y )
i =1
i =1
a2 = x − b2 y
−
N
∑( y
a1 = y − b1 x
− x)2
−
N
b2 =
−
∑ ( xi − x ) ⋅ ( y i − y )
i
− y)2
I coefficienti a2 e b2 si ottengono scambiando la variabile x con la variabile y dalle
rispettive formule di a1 e b1 .
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 7 di 13
I coefficienti di regressione b1 e b2
assumono sempre lo stesso segno in quanto il
numeratore è uguale e il denominatore è un quadrato; b1 è il coefficiente angolare della
prima retta di regressione, mentre b2 è il reciproco del coefficiente angolare della seconda
retta di regressione..
Nello studio della regressione si individuano i seguenti altri indici :
N
1)
COD( x, y ) = ∑ ( xi − x )( yi − y )
CODEVIANZA
i =1
N
2)
DEV ( X ) = ∑ ( xi − x ) 2
DEVIANZA DI X
i =1
N
3)
DEV (Y ) = ∑ ( yi − y ) 2
DEVIANZA di Y
i =1
N
4)
COV ( x, y ) =
COVARIANZA
∑(x
i =1
i
− x )( yi − y )
N
e pertanto i coefficienti di regressione si possono ottenere mediante le formule:
b1 =
COD( X , Y )
DEV ( X )
e
b2 =
COD( X , Y )
DEV (Y )
Dai dati della tabella precedente si ottiene il seguente grafico della retta di regressione :
retta di regressione
y = 0,2543x - 1,6953
49
44
39
34
155
160
165
170
175
180
185
190
altezza in cm
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 8 di 13
CORRELAZIONE
Nello studio della correlazione nessuna delle due variabili assume un ruolo fondamentale
nel determinare il valore dell’altro.
Scopo della correlazione è quello di misurare il grado di interdipendenza delle due variabili
.
La correlazione si calcola mediante un indice indicato con r , compreso tra –1 e +1, ed
esprime come le due variabili variano congiuntamente.
Così come nello studio della variabilità di una variabile si utilizza la varianza σ2 o VAR(X) ,
oppure lo scarto quadratico medio σx , per misurare la variabilità congiunta di due variabili
si utilizza la covarianza COV(X,Y) o σxy.
L’indice per misurare la correlazione è il coefficiente di correlazione di Pearson :
N
r=
COV ( X , Y )
σ xσ y
=
∑(x
i =1
i
− x )( yi − y )
N
N
i =1
i =1
∑ ( xi − x)2 ∑ ( yi − y )2
l’indice si può ottenere anche con i coefficienti di regressione b1 e b2
r = ± b1 × b2
dove il segno + si utilizza se il coefficiente di regressione è positivo , segno – se il
coefficiente è negativo .
OSSERVAZIONI Si è già riferito che i due coefficienti di regressione hanno lo stesso
segno e quindi le rette di regressione sono o entrambe crescenti o entrambe decrescenti.
-
se b1 e b2 sono positivi le rette sono crescenti e r è positivo ;
-
se b1 e b2 sono negativi le rette sono decrescenti e r è negativo;
-
se b1 è uguale a 0 le rette sono parallele agli assi e r è uguale a 0;
-
r è un indice adimensionale , cioè non dipende dalle unità di misura dei caratteri ed è
sempre compreso tra –1e +1;
-
quando r si avvicina a –1 vi è forte correlazione negativa, quando si avvicina a +1 vi è
forte correlazione positiva; quando si avvicina a 0 non vi è correlazione lineare tra le
variabili.
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 9 di 13
Nella tabella 1 è evidenziato l’organizzazione dei dati per calcolare gli indici di regressione e correlazione.
TABELLA 1
indici
totale
statura in
cm
peso in
kg
xi
yi
154
155
166
170
174
175
175
176
186
189
1720
62
65
65
70
81
76
77
76
88
90
750
n
media di X
media di Y
COD(X,Y)
DEV(X)
DEV(Y)
COV(X,Y)
VAR(X)
VAR(Y)
10
172
75
936
1176
830
93,6
117,6
83
b1
0,796
a1
-61,898
b2
1,128
a2
87,422
scarti x
scarti y
( x i − x) ( y i − y )
-18
-17
-6
-2
2
3
3
4
14
17
0
prodotto degli scarti
scarti
scarti
quadratici quadratici
( x i − x) ⋅ ( y i − y )
( x i − x) 2 ( y i − y ) 2
-13
-10
-10
-5
6
1
2
1
13
15
0
234
170
60
10
12
3
6
4
182
255
936
324
289
36
4
4
9
9
16
196
289
1176
169
100
100
25
36
1
4
1
169
225
830
r
0,947
Il coefficiente di correlazione è significativamente vicino a 1 e pertanto vi è una forte correlazione,
una decisa interdipendenza tra le variabili statura e peso; al crescere della statura si verifica un
corrispondente aumento di peso.
In particolare il primo coefficiente di regressione indica che se la statura aumenta di 1 cm il peso
aumenta mediamente di 0,79 kg.
Il secondo coefficiente di regressione indica che al crescere del peso di 1 kg si può ragionevolmente
supporre l'aumento dell'altezza pari a 1,12 cm.
Le due rette di regressione sono y = -61,898+0,7959x e x = 87,42+1,1277y.
Se si volesse stimare il peso di una persona della quale conosciamo l'altezza di 180 cm si
va a sostituire questo valore alla x della prima retta e si ottiene il peso teorico atteso di 81 kg circa.
Viceversa se si conosce il peso di una persona pari a kg 67 si va a sostituire questo valore alla y
della seconda retta di regressione e si ottiene la statura teorica attesa di 163 cm circa.
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 10 di 13
DISTRIBUZIONE SECONDO DUE CARATTERI IN UNA TABELLA A DOPPIA ENTRATA
Quando le unità del collettivo sono numerose e le coppie (xi ; yi ) assumono gli stessi
valori , cioè si ripetono, è preferibile rappresentare i dati mediante una distribuzione doppia
di frequenze e contando poi le unità di ciascuna delle classi ottenute:
Date ad esempio le seguenti 20 coppie rappresentanti le unità rilevate del reddito e del
consumo (R;C)
(100;70) (100;70) (100;70) (100;90) (100;80) (100;80) (100;80) (100;80) (100;80) (100;90) (100;90)
(100;90) (100;90) (100;90) (100;90) (110;70) (110;80) (110;80) (120;80) (120;100)
esse si possono rappresentare nella seguente tabella a doppia entrata :
VALORI Y CONSUMO
VALORI X
REDDITO
100
110
120
totale colonna
70
80
90
100
totale riga
3
1
0
4
5
2
1
8
6
1
0
7
0
0
1
1
14
4
2
20
In generale una tabella a doppia entrata con frequenze sarà così rappresentata:
carattere y
carattere x
y1
y2
y3
yj
yt
totale
righe
x1
n11
n12
n13
n1j
n1t
n10
x2
n21
n22
n23
n2j
n2t
n20
x3
n31
n32
n33
n3j
n3t
n30
ni1
ni2
ni3
nij
nit
ni0
xs
ns1
ns2
ns3
nsj
nst
ns0
totale colonne
n01
n02
n03
n0j
n0t
n
xi
Dove il simbolo
ni 0
nij
indica la frequenza della coppia della
indica il totale delle frequenze della riga
colonna
i − esima riga e la j − esima colonna,
i − esima e
n0 j
indica il totale delle frequenze della
j − esima .
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 11 di 13
DISTRIBUZIONI MARGINALI
La colonna e la riga del totale ( ultima colonna e ultima riga della tabella ) sono chiamate
distribuzioni marginali . Esse corrispondono alle distribuzioni di frequenze dei due
caratteri esaminati, reddito e consumo; la colonna del totale è la distribuzione del carattere
X , nell’esempio la distribuzione del carattere reddito; la riga del totale è la distribuzione
del carattere Y, nell’esempio la distribuzione del carattere consumo.
distribuzione marginale consumo
valori Y consumo totale colonna
70
4
80
8
90
7
100
1
totale
20
distribuzione marginale reddito
valori X reddito
totale riga
100
14
110
4
120
2
totale
20
Ad ognuna delle due distribuzioni marginali corrisponde una media marginale M x e M y .
t
∑y
s
Mx =
∑x ⋅n
i =1
i
n
i0
100 ⋅ 14 + 110 ⋅ 4 + 120 ⋅ 2
=
= 104
20
My =
j
⋅ n0 j
j =1
n
=
70 ⋅ 4 + 80 ⋅ 8 + 90 ⋅ 7 + 100 ⋅ 1
= 82,50
20
I coefficienti delle due rette di regressione y = a1 + b1 x e
y = a2 + b2 x
si ottengono
dalle seguenti formule:
s
COD( X , Y )
b1 =
=
DEV ( X )
t
∑∑ ( x
− M x ) ⋅ ( yi − M y ) ⋅ nij
i
i =1 j =1
s
∑(x
i =1
s
COD ( X ,Y )
b2 =
=
DEV (Y )
t
∑∑ ( x
i
− M x ) ⋅ ni 0
i
− M x ) ⋅ ( yi − M y ) ⋅ nij
i =1 j =1
t
∑( y
j =1
a1 = M y − b1 ⋅ M x
2
− M y ) ⋅ n0 j
a2 = M x − b2 ⋅ M y
2
i
Il coefficiente di correlazione è dato dalla radice quadrata del prodotto dei due coefficienti
di regressione:
r = ± b1 ⋅ b2
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 12 di 13
Esempio:
Calcolare le rette di regressione di Y su X e X su Y e il coefficiente di correlazione.
Y
10
20
30
40
totale
15
4
8
12
1
25
25
1
2
3
19
25
totale
5
10
15
20
50
medie
marginali
X
a) si
calcolano
le
2
Mx =
∑ x ⋅n
i
delle
due
variabili
Mx
e
My
:
4
i0
i =1
n00
∑ y j ⋅ n0 j 10 ⋅ 5 + 20 ⋅ 10 + 30 ⋅ 15 + 40 ⋅ 20 1500
15 ⋅ 25 + 25 ⋅ 25 1000
=
=
= 20 M y = j =1
=
=
= 30
50
50
n00
50
50
b) si costruisce la tabella a doppia entrata degli scarti:
y’
y1-My
y2-My
Y3-My
Y4-My
y’
totale
x’
-20
-10
0
10
totale
x’
x1-Mx
4
8
12
1
n10
-5
4
8
12
1
25
x2-Mx
1
2
3
19
n20
5
1
2
3
19
25
totale
n01
n02
n03
n04
n
totale
5
10
15
20
50
c) si calcolano la codevianza e le devianze:
COD( X , Y ) = ( −5)( −20)4 + ( −5)( −10)8 + ( −5)(0)12 + ( −5)(10)1 + (5)( −20)1 + (5)( −10)2 + (5)(0)3 + (5)(10)19 = 1500
DEV ( X ) = (−5) 2 ⋅ 25 + (5) 2 ⋅ 25 = 1250
DEV (Y ) = (−20) 2 ⋅ 5 + (−10) 2 ⋅ 10 + (0) 2 ⋅ 15 + (10) 2 ⋅ 10 = 5000
d) si calcolano i coefficienti :
b1 =
1500
1500
= 1,20; ⇒ a1 = 30 − 1,2 ⋅ 20 = 6; b2 =
= 0,30; ⇒ a2 = 20 − 0,30 ⋅ 30 = 11
1250
5000
le rette di regressione :
y = 1,20 x + 6 e x = 0,30 y + 11
coefficiente di correlazione
r = 1,20 ⋅ 0,30 = 0,60
Bibliografia : Leti, Statistica descrittiva; Girone-Salvemini , Matematica con applicazioni informatiche 3, Gambotto Manzone - Consolini,
Tramontana; Probabilità e statistica descrittiva Bergamini,Trifone,Barozzi, Zanichelli.
FACOLTÀ DI ECONOMIA PESCARA Corso di Laurea Triennale in ECONOMIA E COMMERCIO Classe L-33
STATISTICA Anno Accademico 2010-2011 Prof . Annibale ROCCO
INTERPOLAZIONE, REGRESSIONE E CORRELAZIONE
Pagina 13 di 13