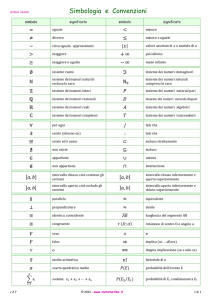
DISPENSE DI “SICUREZZA E ANALISI DI RISCHIO”
Indice
Cap. I Introduzione
1. Concetto di rischio
2. Corretta valutazione della “sicurezza”
3. Qualità e guasto
Cap. II Elementi generali di statistica
1. Utilità e funzioni dell’Analisi Statistica
2. Definizioni di base
3. Probabilità e Frequenza
4. Modelli probabilistici
4.1 Modelli discreti
4.2 Modelli Continui
Cap III Prove di affidabilità
1. Introduzione
2. Correlazioni tra variabili e Metodo dei Minimi Quadrati
3. Analisi campionaria (Inferenza statistica)
3.1 Metodo di Bayes
3.2 Metodo χ2
3.3 Tabelle di Contingenza
Cap IV Qualità, Manutenzione e Ridondanza
1. Qualità e guasto
2. Collaudi
2.1 P-value
2.2 Campionamento
3. Affidabilità
4. Prove di affidabilità
5. Disponibilità e Manutenzione
6. Parametri di affidabilità
7. Ridondanza
Cap V Affidabilità di sistemi
1. Concetti generali
2. Principali strategie
3. Collegamento logico-sequenziale della successione degli eventi
Cap VI Valutazione dell’errore umano
1
CAPITOLO I
INTRODUZIONE
1. Concetto di rischio
In molti casi di interesse pratico risulta che la nozione di “rischio” non è univocamente condivisa da
tutti i ricercatori, e questo a causa di una annosa confusione sull’uso corretto dei termini di volta in
volta utilizzati. Si verifica, infatti, che molti utilizzino o lo stesso termine con significati diversi,
oppure termini diversi associandovi lo stesso significato. Per prima cosa risulta così indispensabile
fornire le corrette definizioni dei principali termini utilizzati.
Pericolo (“Hazard”) : qualunque entità (fisica, chimica, procedurale …)
potenzialmente origine di danno; le caratteristiche del pericolo
sono:
l’oggettività : anche se non siamo in grado di avvedercene (per
inesperienza o mancanza di idonei strumenti di valutazione) i pericoli
esistono e sono, in linea di principio, misurabili (es. livelli di difficoltà per
le ascese in montgna);
il collegamento con eventi indesiderati (danno);
la natura probabilistica di tale collegamento : se, ad esempio, un evento
indesiderato si verificherà con certezza non parleremo di pericolo (non
corriamo il pericolo di morire, evento certo, ma semmai di morire prima
del tempo).
Danno (“Demage”) : rappresenta l’evento indesiderato che non inevitabilmente può
risultare come conseguenza di un pericolo; la valutazione del danno è
abbastanza oggettiva e sempre quantificabile in qualche unità di misura (ad
es. in denaro quando si tratta di un risarcimento ecc); a causa di queste sue
caratteristiche la valutazione del danno, e del collegato rischio, rimane un
problema aperto a temi quali la responsabilità, la decisione e l’accettabilità.
Probabilità :
data una certa situazione la probabilità fornisce una valutazione di
quanto spesso dobbiamo attenderci l’accadere di un evento; molto
2
raramente risulta valutabile rigorosamente, più spesso viene espressa in
termini di frequenza (ad es. eventi/uomo-anno) o semplicemente in termini di
giudizio (ad es. quasi mai, spesso, possibile, improbabile …);
Rischio (“Risk”) :
viene valutato combinando la probabilità (che a seguito di un
pericolo si abbia un evento dannoso) con l’entità dell’eventuale
danno, il rischio viene così ad essere una funzione della
probabilità e del danno;
Salvaguardia :
qualunque azione che può essere intrapresa per contenere il danno;
può consistere in azioni di prevenzione cioè nel cercare di limitare il valore
da associare alla probabilità di avere un danno (come ad es. l’introduzione dei
limiti di velocità nelle strade), o di protezione cioè nel limitare il valore da
associare al danno (come ad es. l’adozione delle cinture di sicurezza sugli
automezzi).
Il concetto di rischio, sulla base di quanto già visto, dipende dai concetti di “incertezza”;
incertezza che può essere ad esempio legata alla più corretta azione da intraprendere (es. la velocità
minima per le autovetture, controllata e sanzionata negli Usa e poco o nulla in molti Paesi Europei)
e di “danno” (in termini di possibili conseguenze negative a causa della scelta prima effettuata). In
termini formali si può scrivere:
rischio (R) = incertezza + danno
(1.1)
Un altro importante passo consiste nel legare il concetto di “rischio” a quello di “pericolo”.
Quest’ultimo esiste di per sé stesso mentre il rischio è essenzialmente legato a come viene
affrontata una situazione pericolosa. Ad esempio scalare una alta montagna comporta
sicuramente un pericolo, che può essere convertito in un rischio più o meno elevato a seconda di
come si affronti la scalata stessa. In ogni caso, poiché il pericolo non può mai essere eliminato del
tutto: il rischio potrà unicamente essere ridotto il più possibile, non annullato. Anche questo
concetto può essere espresso in termini formali:
R = Pericolo/ Salvaguardie
(1.2)
Connesso a questo concetto è quello di “rischio percepito” (es rischio volontario ed involontario);
che tiene conto del fatto che la quantificazione del rischio viene ad essere direttamente legata
all’osservatore. La quantificazione del rischio dipende, cioè, direttamente dalle informazioni in
possesso dell’osservatore: non è possibile effettuare una valutazione assoluta dell’entità del
rischio. Se, ad esempio, un signore sta guidando la sua automobile, senza sapere che i freni sono
fuori servizio, dirà che il rischio connesso alla guida è basso ed in qualche modo da lui
3
controllabile; ma, appena proverà ad effettuare una frenata, la sua valutazione sulla sicurezza del
mezzo cambierà drasticamente.
Se si presuppone di avere una corretta conoscenza della situazione in esame si può dire che il
rischio (R) è funzione della probabilità (p) e del danno (d):
R= f(p,d)
(1.3)
Il rischio viene perciò ad avere una quantificazione non direttamente deterministica, nel senso che
dipende da valutazioni (della probabilità e del danno) che possono essere in qualche modo
soggettive. Possiamo raffigurare il legame intercorrente tra le diverse grandezze nel modo seguente:
Fig.1.1 Rappresentazione del legame tra pericolo, danno, probabilità e
rischio
È importante notare che, a parità di pericolo, si possono avere valori molto diversi del rischio (ad es,
a seconda del numero di persone esposte, valore che incide sulla quantificazione sia del danno sia
della probabilità ecc).
Si può ora introdurre il concetto di Analisi di rischio (o di Valutazione dei Rischi) che costituisce
un processo sistematico atto a :
identificare i pericoli
valutare i danni
valutare in rischi associati mediante una “stima” od un “giudizio” per le probabilità; stima
che può essere di tipo:
-qualitativo
-quantitativo
Per quanto riguarda quest’ultimo punto si tenga presente che gli orientamenti comunitari
individuano nell’approccio qualitativo la modalità adeguata per quanto riguarda l’analisi dei rischi
4
non rilevanti; quello quantitativo alle situazioni che prevedono lo svilupparsi di incidenti a “rischio
rilevante”.
La valutazione del rischio consiste in sostanza nel trovare le corrette risposte ai seguenti tre
quesiti fondamentali:
i)
quale sequenza di eventi indesiderati può trasformare il pericolo in un danno?
ii)
quale è la probabilità che si verifichi ognuna di queste sequenze?
iii)
quali sono le conseguenze per ognuna di queste sequenze?
Su questa base per prendere delle decisioni si confronteranno i rischi associati alle diverse possibili
sequenze di eventi (scenari) effettuando un loro ordinamento secondo una scala di importanza (o di
gravità). Per i casi più critici risulta, così, di fondamentale importanza fornire un corretto legame tra
la quantificazione dell’entità del rischio e la conoscenza dei valori di volta in volta assunti da terne
di variabili tra loro legate e costituite dai seguenti dati:
1. sj: scenario di riferimento (che può essere individuato dai seguenti quesiti: cosa può
accadere? Cosa può andare storto?);
2. pj: probabilità che si venga a verificare effettivamente lo scenario (sj);
3. xj: entità del danno conseguente al verificarsi, con una probabilità (pj), dello scenario (sj).
Si può, così, definire il rischio (R) in funzione di gruppi di terne di valori:
R= (sj, pj, xj)
per j=1,N
(1.4)
dove (N) rappresenta il numero di possibili diversi scenari presi in considerazione (scenari che
dovranno essere scelti in modo tale da essere auto escludenti, assicurando che uno stesso identico
evento non possa essere preso in esame più di una sola volta). Come vedremo in seguito l’Analisi di
Rischio consiste appunto nell’individuazione di queste terne di valori e nella costruzione delle
relative tabelle.
Può in ogni caso essere utile puntualizzare alcuni importanti concetti. Per prima cosa (N) non
rappresenterà tutti i possibili scenari, ma solo quelli che si ritiene utile prendere in considerazione e
che verranno chiamati “scenari di riferimento o credibili”; in oltre l’entità del possibile danno può
essere, a sua volta, nota come un unico valore oppure come un vettore. Se, ad esempio, è possibile
ridurre gli (xj) ad una sequenza di valori si può, allora, pensare di ordinare i diversi (N) scenari in
ordine crescente di danno:
Tenendo inoltre conto che le pj non saranno più ordinate secondo la stessa logica, si sostituisce ai
(pj) la loro somma (da j a N) sostituendo,cioè, al valore della probabilità di un generico scenario
quella cumulata di avere tutti gli scenari possibili da quello in poi; si può così graficare l’andamento
di (p) in funzione di (x) ottenendo la curva a gradini di Fig. 2.1. La giustificazione di tale scelta può
essere trovata nelle seguenti considerazioni:
5
si vuole agire sulla probabilità con una logica analoga a quella utilizzabile per la valutazione
delle conseguenze (una conseguenza più grave in qualche modo “comprende in sé” anche la
meno grave);
applicare quanto sopra al fine di massimizzare la probabilità di evento, a causa delle incertezze
nella sua corretta valutazione.
Fig.2.1 Curva del rischio (andamento della probabilità cumulata in funzione del
possibile crescente danno)
Questo andamento può essere visto come una discretizzazione della realtà che è, al contrario,
continua (la curva a gradini verrà sostituita da quella continua); si viene così a dire che il rischio e
le conseguenze sono legate dalla probabilità associata al verificarsi dell’evento considerato, nel
senso che si avrà un alto valore della probabilità con moderate conseguenze associate, oppure un
suo basso valore con conseguenze assai più gravose.
Nella maggior parte dei casi questo approccio, formalmente rigoroso, non risulta applicabile; si
ricorre allora ad una sua versione semplificata, la quale, considerando di volta in volta un singolo
scenario credibile, esplicita il legame funzionale tra rischio, danno e probabilità in forma di
semplice prodotto:
R= p x d
(1.5)
In questo modo si viene ad avere che un danno grave ed improbabile ed uno piccolo e molto
probabili presentano lo stesso valore di R; si ha così lo stesso valore del rischio a fronte di molte
(infinite) diverse combinazioni di (p) e (d).
Se la percezione del rischio è tale da portare ad associare una maggiore rilevanza alle conseguenze,
piuttosto che alla probabilità di accadimento; la (1.5) si modifica allora come segue:
R = p x dk
per k1
(1.6)
6
Nel caso. poi, si vogliano prendere in considerazione più eventi indesiderati contemporaneamente
(ad esempio n eventi), si estende la (1.6) effettuando la valutazione del rischio composito:
R = i pi x di
per i= 1,n
(1.7)
← Inaccettabilità
(a)
Fig. 3.1 Curve di Farmer
(b)
Il più semplice modo per rappresentare l’andamento della probabilità e del danno è rappresentato
dalle curve di Farmer basate sula 1.6, Fig. 3.1 (a,b); nella prima è riportato il caso di
proporzionalità inversa (inclinazione della retta pari a –1) e nell’altra il caso in cui si dia maggiore
importanza alle conseguenze (con un aumento conseguente della pendenza della retta). In entrambe
le figure la retta suddivide il piano in una zona relativa a situazioni inaccettabili, ed in una che
rappresenta situazioni che, anche se caratterizzate da coppie di valori (p,d) molto diverse tra di loro,
risultano accettabili.
Più correttamente di quanto ora visto si possono utilizzare le curve (iperboli) a rischio costante
(dette “curve isorischio”). Nella seguente Fig.4.1 sono riportate due curve corrispondenti a due
diversi valori del rischio (R1R2); dato un certo pericolo si potrà, ad esempio, individuare il punto
A sulla curva R = R2
Fig.4.1 Curve isorischio.
L’ “Analisi di rischio” (e/o “di sicurezza”) si prefigge il compito di effettuare il passaggio, mediante
un processo tecnico-decisionale, dalla curva R2 a quella R1; in questa fase particolarmente
interessanti risultano le situazioni corrispondenti ai punti B1 e B3. Il primo può, infatti, essere
raggiunto adottando criteri di prevenzione: si diminuisce la probabilità di accadimento (mediante
l’adozione di interventi tesi ad aumentare la sicurezza impiantistica come l’adozione di barrire di
7
contenimento, formazione ed informazione del personale addetto ecc); il secondo utilizzando criteri
di protezione (salvaguardie): si diminuisce l’entità del danno a parità di probabilità di evento
(mediante ad esempio l’adozione di sistemi di protezione individuale quali tute ignifuge, guanti,
occhiali ecc). In generale si adotteranno nella pratica delle misure che si rifanno ad entrambe queste
metodologie, venendo ad individuare il punto B2.
In molti casi di interesse pratico non si dispone di valori affidabili di (p) e (d), o per oggettive
difficoltà di valutazione o per l’eccessivo onere finanziario che una corretta valutazione
comporterebbe; si può allora ricorrere all’utilizzo di un appropriato insieme di regole che
permettano ad esperti di esprimere dei giudizi di appartenenza delle variabili ad opportuni intervalli
di variazione. Gli assi cartesiani vengono così suddivisi in intervalli ed i corrispondenti valori di R
sono sostituiti dalle caselle della griglia risultante secondo il processo rappresentato in Fig.5.1.
Fig.5.1 Passaggio logico dalle curve isorischio alla Matrice di rischio
Come risultato di questo processo di semplificazione si ottiene la “Matrice di rischio”; nei suoi due
lati, che prendono il posto delle ascisse e delle ordinate, si trova un certo numero di livelli
(generalmente compresi tra tre e sei) rispettivamente di probabilità e di danno; in ogni casella è
riportato l’indice di rischio corrispondente (indice di “criticità”). Si è così passati da una
valutazione quantitativa del rischio ad una qualitativa/quantitativa. In generale ad un indice uno
8
corrisponde una situazione perfettamente accettabile, mentre agli indici più elevati situazioni che
richiedono interventi di mitigazione immediati. Utilizzando questo strumento è importante tenere
presente come non sia tanto importante quale matrice utilizzare, se con pochi o molti livelli, ma
piuttosto una corretta definizione delle classi corrispondenti, articolandole ed esemplificandole il
più possibile rispetto alla situazione in esame.
Nei casi più semplici non solo non risulta possibile una analisi qualitativa/quantitativa, ma può
risultare utile adottare delle espressioni più sfumate rispetto a quelle ora viste, quali ad esempio
“situazioni pericolose”, “elementi di rischio”, “fattori di rischio”, condizioni di rischio”. Queste,
se non usate ambiguamente, possono rendere più agevole commentare gli aspetti descrittivi ed
illustrativi dell’analisi.
Ritornando alla Matrice di Rischio in generale si adotterà un numero dispari di livelli di probabilità
al fine di avere un “valore centrale” (intermedio) di più facile determinazione; più semplice risulterà
in genere la determinazione dei livelli di danno. La Matrice di Rischio nasce infatti per l’analisi
di incidenti (infortuni) che sono caratterizzati dall’essere:
-
originati da un errore, malfunzionamento o deficienza non evitati;
-
di durata modesta;
-
da elevata “dose” (energia, materia ..) rilasciata esposizione acuta per cui il livello di
dose è legato alla disponibilità (rilascio) di agente nocivo.
Può essere applicata anche in ambito sanitario, il quale presenta caratteristiche praticamente
speculari alle precedentemente elencate:
-
evento di esposizione “certo”, monitorato ed “accettato” a priori (inquinamento ..);
-
lunga durata;
-
basso livello di dose (in genere fissato per legge).
Tra questi due ambiti (infortunistico e sanitario) la principale differenza operativa, per quanto
concerne l’analisi di rischio, consiste nella valutazione della probabilità. La normativa riguardante
la sicurezza sul lavoro (Testo Unico sulla Sicurezza dei Lavoratori 2008 e sue successive
modificazioni ed integrazioni) ha riunito ed integrato questi due ambiti, fornendo un approccio
sistematico alla associata analisi di rischio. Vediamone un esempio semplificato per la costruzione
della Matrice di Rischio relativa ad infortuni e malattie professionali.
Come precedentemente accennato nella stesura della Matrice di Rischio risulta abbastanza critica la
classificazione dei diversi livelli di probabilità, soprattutto per quanto riguarda gli aspetti sanitari; al
fine di rendere il più possibile ripetibile (nel senso di “indipendente dall’analista”) l’analisi
effettuata con tale strumento. In Tabella I-1 sono riportati i criteri di assegnazione dei livelli di
probabilità sia per gli infortuni sia per gli effetti sanitari. In Tabella II-1 e III-1 sono poi riportati i
9
criteri di assegnazione dei livelli di danno e di criticità. In fine in Fig. 6.1 è riportato un esempio di
Matrice di Rischio riferita ad un caso pratico per il quale si è quantificato il numero di volte in cui si
viene a verificare una data situazione di rischio.
Livello
Probabilità
Definizione (in riferimento agli infortuni)
Definizione (in riferimento
alla salute)
1
Improbabile
La mancanza rilevata può provocare danno per la
concomitanza di almeno due eventi poco probabili
(indipendenti) o comunque solo in occasioni poco fortunate.
Non sono noti episodi già verificati o si sono verificati con
frequenza bassissima.
Il verificarsi del danno susciterebbe perlomeno una grande
sorpresa.
La probabilità di incidente (anche senza infortunio) è minore
di 1x10-3 eventi per persona e per anno
Agenti chimici: rischio
moderato ex D.Lgs. 25/02
Amianto: <0.1 fibre/cm3
2
Possibile
La mancanza rilevata può provocare danno, anche se in modo
non automatico o diretto.
E’ noto qualche episodio in cui alla mancanza ha fatto seguito
un danno.
Il verificarsi del danno susciterebbe una moderata sorpresa.
La probabilità di incidente (anche senza infortunio)
[1-2 x10-3] eventi per persona e per anno
Oli minerali: contatto occasionale
Polveri inerti: <5 mg/m3
Rumore: Le 80-85 dbA
Microclima: lavoro all’aperto
Turni: due turni a rotazione
Posture: seduta o in piedi fissa
Impegno visivo (VDT): medio
(<20 ore medie settimanali)
Sforzo fisico dinamico: medio
(a discrezione del medico)
Lavoro isolato: occasionale
Lavoro in quota: occasionale
Uso di utensili vibranti:
occasionale
Agenti chimici: rischio
moderato ex D.Lgs. 25/02
Amianto: <[0.1-0.2] fibre/cm3
Oli minerali: contatto abituale
Polveri inerti: 5 mg/m3
Rumore: Le 80-85 dbA
Microclima: stress termico
Turni: tre turni a rotazione
Posture: eretta fissa
Impegno visivo (VDT): elevato
(20 ore medie settimanali)
Movimentazione carichi:
elevato (a discrezione del medico)
Lavoro isolato: abituale
Lavoro in quota: abituale
Uso di utensili vibranti:
abituale
3
Probabile
Esiste una correlazione diretta tra la mancanza rilevata ed il
verificarsi del danno.
Si sono già verificati episodi per la stessa mancanza.
il verificarsi del danno non susciterebbe alcuna sorpresa.
La probabilità di incidente (anche senza infortunio)
[1-2 x10-2] eventi per persona e per anno
Tabella I-1 Criteri di assegnazione dei livelli di probabilità
10
Agenti chimici: rischio non
moderato
Amianto: <0.2 fibre/cm3
Oli minerali: esposizione
ad eorosol
Rumore: Le 90 dbA
Turni: speciali
Posture: incongrua
Sostanze cancerogene:
presenti
Codice
1
Gravità
Lieve
2
Medio
3
Grave
4
Gravissimo
Definizione
Infortunio o episodio di esposizione acuta con invalidità rapidamente reversibile (pochi giorni).
Esposizione cronica con effetti rapidamente reversibili (pochi giorni).
Sono presenti sostanze o preparati moderatamente nocivi.
Infortunio o episodio di esposizione acuta con invalidità reversibile.
Esposizione cronica con effetti reversibili.
Sono presenti sostanze di cui al D.Lgs. 17 agosto 1999 n.34, anche se in quantità inferiori alla
soglia di dichiarazione.
Sono presenti sostanze e/o preparati biologici di prima categoria (class. D.Lgs. 626/94)
Infortunio o episodio di esposizione acuta con invalidità parziale.
Esposizione cronica con effetti rapidamente irreversibili e/0 parzialmente invalidanti.
Sono presenti sostanze di cui al D.Lgs. 17 agosto 1999 n.34, in quantità superiore alla soglia di
dichiarazione.
Sono presenti sostanze e/o preparati biologici di seconda categoria (class. D.Lgs. 626/94)
Infortunio o episodio di esposizione acuta con efetti letali o di invalidità totale.
Esposizione cronica con effetti letali o totalmente invalidanti.
Sono presenti sostanze di cui al D.Lgs. 17 agosto 1999 n.34, in quantità superiore al limite di
notifica.
Sono presenti sostanze e/o preparati biologici di terza o quarta categoria (class. D.Lgs. 626/94)
Tabella II-1 Criteri di assegnazione dei livelli di danno
Fig. 6.1 Analisi di Rischio mediante matrice
Codice
Criticità
1
Trascurabile
2
Lieve
3
4
Modesta
Moderata
5
Alta
6
Molto alta
Definizione
Non sono richieste azioni di mitigazione per i rischi identificati
Sono da valutare azioni di mitigazione in fase di programmazione.
Non si ravvisano interventi urgenti
Mantenere sotto controllo i rischi, valutando ipotesi di mitigazione
Monitorare costantemente i rischi valutando la necessità di interventi mitigativi nel
breve/medio periodo.
Intervenire con urgenza per individuare ed attuare gli interventi di prevenzione e protezione che
riducano il rischio ad una criticità inferiore.
Intervenire immediatamente per eliminare/ridurre il pericolo e comunque ridurre il rischio ad
una criticità inferiore.
Tabella III-1 Criteri di assegnazione dei livelli di criticità del rischio
11
Il concetto di rischio si può, ovviamente, applicare sia ad eventi naturali, sia ad eventi conseguenti
alle realizzazioni dell’uomo; in questa sede risulta di particolare interesse la valutazione del
“rischio industriale” che viene ad essere influenzato da diversi fattori, quali:
la complessità del “sistema tecnologico” che, a causa delle molteplici interazioni tra diverse
possibili cause di rischio, risulta di incerta valutazione;
il sovrapporsi di diversi “aspetti negativi” che possono influenzare la valutazione del rischio,
che comporta una notevole difficoltà nello stabilire degli standard di riferimento per quanto ad
esempio riguarda le emissioni inquinanti massime ammissibili da ogni singola sorgente e le
relative modalità di rilevazione;
l’aumento della “instabilità sociale” a seguito di incidenti di origine tecnologica (quali ad es.
Seveso, Cernobil ecc)
la estremamente rapida evoluzione dei sistemi tecnologici che non permette di effettuare una
valutazione sufficientemente accurata del rischio connesso (ad es. l’analisi dell’effetto delle
onde elettromagnetiche sulla popolazione esposta).
L’ entità del rischio connesso ad una qualunque azione viene valutata mediante una serie di
procedure che vanno comunemente sotto il nome di “Analisi di rischio”. In particolare queste
procedure si articolano in tre distinte fasi successive:
1) valutazione delle possibili (o credibili) sequenze incidentali e della loro
evoluzione in relazione al “sistema” considerato (che può essere ad es. un impianto
industriale, il territorio nelle sue immediate vicinanze, parte del territorio nazionale, e così
via);
2) corretta individuazione delle azioni da intraprendere (contromisure) al fine di limitare il più
possibile lo svilupparsi delle catene incidentali prima individuate;
3) valutazione delle conseguenze (sia per l’impianto sia per la popolazione esposta) e della loro
accettabilità.
12
Il rischio tecnologico può essere catalogato secondo diversi criteri:
continuo (ad es. l’inquinamento)
frequente
evento nocivo
occasionale
incidenti
raro
pronta (effetti immediati o a breve
rilevazione
termine)
ritardata (effetti a lungo termine, quali ad
es. le mutazioni genetiche)
RISCHIO
valutazione del danno → deterministica
collettivo
rischio
individuale
volontario (personale addetto
all’impianto)
rischio
involontario (popolazione)
13
2. Corretta valutazione della sicurezza
Una corretta valutazione del rischio nel suo complesso non può prescindere da una analisi del
rapporto tra costi e benefici. Risulta immediatamente evidente come l’individuazione del valore
ottimale di tale rapporto sia affetto da un non trascurabile margine di possibile variabilità, e quindi
di incertezza; molti sono infatti i fattori che possono influenzarne la valutazione quali ad esempio:
il risparmio di danno sia fisico sia psicologico alla popolazione tenendo anche, se possibile,
conto degli eventuali danni conseguenti all’introduzione di una modifica sia in fase di
progetto sia in un impianto già esistente;
il costo in termini economici, tenendo anche conto dell’eventuale guadagno conseguente
all’aumentata affidabilità del sistema ed al risparmio legato al minore peso degli oneri
economici derivanti da incidenti ;
considerazioni di tipo socio-economico legate sia all’accettabilità del rischio all’interno
della struttura sociale considerata (accettabilità del rischio che è fortemente influenzata dal
grado di benessere raggiunto; con l’aumentare di quest’ultimo, infatti, il livello di rischio
socialmente accettabile, a fronte dell’ottenimento di prodotti o servizi che vengono dati per
scontati, tende a diminuire drasticamente); sia alla percezione del rischio.
Nell’ambito di queste valutazioni risulta molto difficoltoso tenere correttamente conto del danno
provocato alle persone e del costo ad esso associato; vediamo alcuni tra i possibili criteri proposti:
i)
assimilare la vita ad un bene produttivo, il cui reddito viene azzerato dal decesso; il
“valore” di una persona viene così legato al mancato guadagno a cui si affianca un criterio
correttivo (se ciò non venisse fatto si avrebbe ad esempio che un pensionato avrebbe un
valore negativo);
ii)
rifarsi ai giudizi legali di risarcimento dei danni, viene sostanzialmente ad essere una
evoluzione del rozzo criterio precedente;
iii)
basarsi sulla capitalizzazione del P.I.L. (Prodotto Interno Lordo), in questo modo si tiene
conto che la quantificazione del “valore” associato alla vita umana varia a seconda del
livello di ricchezza prodotto;
iv)
assumere il “valore” che viene implicitamente dato alla vita dai provvedimenti
protezionistici adottatati, (vedi Tab. IV e V) anche in questo caso si tratta di una evoluzione
del modello (iii) che tiene conto in modo più raffinato delle diverse condizioni di effettivo
sviluppo socio-economico di ogni paese.
14
Pratica di prevenzione
Miglioramento degli apparecchi medici a raggi X
Alimentazione dei Paesi che soffrono carestie
Ricerca del sangue nelle feci per la prevenzione dei tumori
Esami per la prevenzione dei tumori al cervello
Miglioramenti dei guardrail nelle strade
Impiego degli elicotteri di soccorso
Controllo della ipertensione
Esami per la prevenzione del tumore alla mammella
Dialisi renale
Introduzione di allarmi antincendio in abitazioni
Abbattimento della zolfo nelle centrali elettriche a carbone
Misure protettive aggiuntive negli aeromobili civili
Riduzione del contenuto di radio nell’acqua potabile
spesa di 1000 $ per evitare la dose di 1 rem-uomo
Dispositivo di eiezione dei piloti militari
Programma di sicurezza spinta per l’eliminazione dei rifiuti radioattivi
Migliaia di $ per vita salvata
3.6
5.3
10
25
34
65
75
80
200
250
500
1200
2500
7000
8000
200000
Tabella IV-1 Valutazione del costo, per salvare una vita umana, relativo ad alcune
pratiche di prevenzione
Pratica di prevenzione
Migliaia di $ per vita salvata
Impiego delle cinture di sicurezza
0.5
Adozione del limite massimo di velocità a 55 miglia/h
21
Guardrail
34
Dispositivi di sicurezza per l’assorbimento dell’energia di impatto
108
Illuminazione generalizzata
936
Allargamento della sede stradale sui ponti
3460
Variazioni di curvatura e di pendenza delle strade
7680
Tabella V-1 Valutazione del costo, per salvare una vita umana, negli incidenti stradali
Un fattore molto importante è, a questo proposito, la valutazione dello “standard di vita” della
popolazione interessata che può essere legato al consumo medio annuo pro capite di energia; in
questa ottica si possono suddividere le diverse situazioni in tre grossi raggruppamenti:
1) paesi sottosviluppati per i quali non è ancora possibile un qualsiasi tipo di sviluppo
industriale per mancanza delle indispensabili infrastrutture (strade, reti di distribuzione
dell’energia ecc), per questi paesi i maggiori rischi sono associati a calamità naturali;
2) paesi in via di sviluppo che presentano un forte interesse a sviluppare la produzione
industriale anche accettando un certo rischio per la popolazione (in questi casi si tendono a
sviluppare primariamente quelle attività produttive ad alto rischio che non possono essere
convenientemente situate nei paesi sviluppati);
3) paesi sviluppati nei quali si incontrano notevoli difficoltà a rendere accettabile la
realizzazione di insediamenti produttivi che comportino un rischio percepito non nullo.
15
In ogni caso, al fine di migliorare il progetto e la realizzazione di un impianto sarebbe bene tenere
conto di una serie di semplici considerazioni:
1. effettuare progetti più accurati ed una più spinta “garanzia di qualità” durante la
realizzazione dei componenti risulta, nella maggior parte dei casi, più redditizio di
quanto non possa essere l’adozione sic et simpliciter di “margini di sicurezza” (intesi
come aumento proporzionale delle caratteristiche di resistenza alle sollecitazioni dei
componenti);
2. individuare correttamente le “aree critiche”, cioè quelle parti dell’impianto che
risultano essere più facilmente causa di eventi incidentali gravi, ed agire
principalmente su quelle;
3. per prima cosa preservarsi dalle possibili cause di infortunio di tipo tradizionale;
4. non sempre risulta vantaggioso, anche ragionando in termini solo di benefici
tralasciando i costi, spingere oltre certi limiti la sicurezza di un impianto; ad
esempio l’introduzione di un numero sempre crescente di sistemi può portarli ad
interazioni reciproche difficilmente valutabili a priori.
Fig.7.1 Curva di ottimizzazione del rapporto costi-benefici in unità arbitrarie
L’ottimizzazione del rapporto costi/benefici può, in linea di principio, essere effettuata sulla base
della costruzione di un grafico come quello riportato in Fig. 7.1; nel quale sono riportati in unità
arbitrarie l’ andamento del miglioramento apportato ad un impianto in termini di benefici
economici, con l’introduzione di un certo numero di protezioni e modifiche tendenti ad aumentarne
il livello complessivo di sicurezza ed affidabilità, [m(t)] in funzione dello stesso valore senza
l’introduzione delle modifiche stesse [m0 ] del coefficiente di efficienza [] e del tempo necessario
ad introdurre le modiche :
m(t)=m0 e –t
(1.8)
16
in genere si otterrà un andamento esponenziale poiché le prime modifiche avranno un impatto più
rilevante rispetto a quelle introdotte in seguito; l’andamento dei costi [c(t)] in funzione di un
parametro [] :
c(t)= t
(1.9)
e la curva di ottimizzazione che non sarà altro che la somma delle due precedenti.
Le maggiori difficoltà sono insite nella corretta individuazione dei valori da associare ai due
parametri [ , ] che dipendono non solo da considerazioni puramente tecniche, ma anche, come si
è già visto, dalla valutazione di indici socio-economici che possono presentare un ampio margine di
variabilità.
Per tutte le considerazioni prima fatte assume una notevole importanza il corpo della
normativa di sicurezza a cui si fa riferimento e che dovrà essere il più esaustivo ed aggiornato
possibile; anche se da sola la normativa non è in grado di risolvere il problema dalla sicurezza
proprio a causa delle considerazioni prima viste.
3.
Qualità e guasto
Il concetto di qualità dei componenti, inteso come “rispondenza alle aspettative o bontà del
prodotto”, si può dire che sia nato con la produzione industriale di beni; anche se ha subito con
l’evolversi della tecnologia una non trascurabile serie di modificazioni ed aggiustamenti che
possono essere riassunti nelle seguenti principali fasi:
prima del 1940vengono definiti gli attributi e le caratteristiche della “qualità del
prodotto”;
dal 1940 al 50si introduce il concetto di “qualità del progetto”, i difetti ed i modi di
guasto sono sistematicamente tabulati ed analizzati, vengono intraprese, sulla base di questi
dati, delle azioni correttive;
dal 1950 al 60si introduce la “garanzia di qualità” adottando delle analisi preventive al
fine di assicurare una valutazione più corretta della qualità del prodotto, si introduce anche il
concetto di “affidabilità”in termini di probabilità che un dispositivo adempia, nell’intervallo
di tempo considerato, alla sua funzione tenendo in qualche modo conto delle condizioni
operative;
dal 1960 al 70diventa importante il concetto di “disponibilità del prodotto”, tanto da
essere inserito all’interno dei contratti di appalto, diventano così fondamentali i concetti di
“mantenimento delle caratteristiche nel tempo e supporto logistico per assicurare un veloce
e sicuro ripristino delle stesse in caso di mal-funzionamento”;
17
dal 1970 al 80a causa della aumentata complessità dei sistemi diventa indispensabile
tenere anche conto sia dell’interazione uomo-macchina sia del ciclo di vita (progetto,
realizzazione, trasporto, messa in opera, utilizzo ecc.) di un prodotto anche in termini
economici richiedendo una effettiva integrazione tra i gruppi che intervengono nelle diverse
fasi;
dal 1980 al 90vengono sviluppate le tecniche di “controllo e verifica” delle caratteristiche
di un prodotto e viene sistematicamente utilizzato il concetto di “ridondanza”;
dopo il 1990si passa al concetto di “qualità totale” che, coinvolgendo tutti i possibili
gruppi di progetto, porta alla necessità di effettuare una loro organizzazione ed integrazione.
1994→ introduzione della Legge 626/94 sulla “Tutela della salute dei lavoratori”
2000→ introduzione sistematica delle Metodologie Quantitative/Qualitative per la
valutazione del Rischio associato agli impianti (Matrice di Rischio; FTA; ETA; HAZOP
ecc)
2008→ Introduzione del Testo Unico sula Sicurezza dei Lavoratori e sue successive
modifiche/integrazioni.
Tutti i concetti sopra riportati verranno in seguito approfonditi e sviluppati; in questa prima fase è
comunque utile riportare alcuni dei principali punti caratterizzanti il processo di qualità totale. In
particolare le prime regole da osservare possono essere così riassunte:
“buono quanto è strettamente necessario”- il livello di affidabilità e qualità di un prodotto
deve essere direttamente commisurato alle reali esigenze del committente;
“non cambiare il direttore responsabile di un progetto prima della conclusione dell’iter
progettuale stesso”;
“utilizzare metodologie progettuali integrate”- le attività devono essere svolte in stretta
cooperazione tra i diversi gruppi di progetto;
“istituire un gruppo di analisi di qualità e di rischio (Q & RA) che sia attivo all’interno del
processo progettuale, fornendolo della necessaria autonomia ed indipendenza”.
18
CAPITOLO II
CONCETTI GENERALI DI STATISTICA
1. Utilità e funzioni dell’Analisi statistica nel processo di realizzazione-vendita-utilizzo dei
componenti/prodotti industriali
Poiché non è possibile, nei processi di produzione industriale, conoscere esattamente le
caratteristiche di ogni singolo componente/prodotto, ci si deve rivolgere all’utilizzo dell’Analisi
Statistica. Questa diffusa impossibilità dipende principalmente da due fattori, spesso concomitanti:
1. la produzione industriale prevede la realizzazione di un numero troppo elevato di
componenti;
2. le prove, per determinane le caratteristiche, possono essere anche di tipo distruttivo o
protrarsi per tempi eccessivamente elevati.
POPOLAZIONE
Valori caratteristici
[es. dimensioni,
resistenza a
sollecitazione, colore
ecc]
Determinazione
esatta, nei limiti degli
strumenti di misura
utilizzati, dei valori
caratteristici
COMPONENTI SPECIALI
Conoscenza in termini probabilistici dei valori caratteristici
ANALISI CAMPIONARIA
Se le prove effettuate non incidono
sulle prestazioni dei componenti,
esaminati uno alla volta, le loro
caratteristiche sono note con certezza
Prestazioni della popolazione in termini stocastici
Controllo a campione della coerenza tra
prestazioni attese e rilevate
COMPONENTI INDUSTRIALI
Fig. 2.1 Rappresentazione schematica del processo di qualificazione di componenti/prodotti
19
La Qualità dei componenti dipende così da due fattori:
1. le effettive prestazioni;
2. la più o meno precisa conoscenza in termini statistici di queste ultime.
Il processo di acquisizione delle informazioni indispensabili per qualificare i
componenti/prodotti può essere schematizzato come riportato in Fig. 2.1. In Fig. 2.2 è
rappresentata in modo più dettagliato la catena di qualificazione dei lotti di componenti e delle
procedure (di controllo, manutenzione ecc) che ne possono derivare; si evince come questo
processo di acquisizione possa continuare anche dopo che i componenti si trovino a lavorare in
opera.
POPOLAZIONE
CAMPIONE
CONTROLLI DI
CONFORMITA’
ANALISI
CAMPIONARIA
MODALITA’ DI
COLLAUDO
REGOLE DI
DECIONE
SI
CRITERI DI
MANUTENZIONE
NO
CARATERISTICHE
DELLA POPOLAZIONE
PASSAGGIO DEI LOTTI DAL
PRODUTTORE ALL’ACQUIRENTE
ACQUISIZIONE DEI DATI
AFFIDABILISTICI DAI COMPONENTI
IN OPERA
Fig. 2.2 Processo di acquisizione e verifica delle caratteristiche di una popolazione
2. Definizioni di base
L’analisi statistica ha, tra l’altro, la funzione di individuare alcune delle caratteristiche di un
generico insieme (composto da elementi unitari univocamente definiti, distinguibili e numerabili)
prendendo in considerazione solo una quota parte dei dati che potrebbero essere teoricamente o
praticamente a disposizione; la differenza tra queste due ultime situazioni consiste essenzialmente
nelle dimensioni infinite o finite dell’insieme considerato. Definiamo, così, come “popolazione”
l’intero insieme di elementi e come “campione” un qualunque suo sottoinsieme.
Se, dall’analisi di un generico campione, si vogliono trarre considerazioni sull’eventuale
comportamento di tutta la popolazione si avrà la “statistica induttiva”; se, al contrario, le
20
considerazioni saranno rivolte unicamente al comportamento del campione esaminato, senza cioè
trarre conclusioni che riguardino l’intera popolazione, si avrà la “statistica descrittiva”. In generale
nell’analisi del comportamento di componenti e/o sistemi di componenti risulterà di maggiore
interesse la prima situazione; si cercherà, così, di individuare il possibile comportamento di una
intera popolazione dall’analisi di uno o più campioni: “analisi campionaria”.
Le caratteristiche di un generico insieme possono essere rappresentate mediante una funzione, che
verrà detta “distribuzione campionaria”, in maniera discreta (ad es. quante volte si presentano le
diverse facce di un dado in un certo numero di lanci) o continua (ad es. la resistenza meccanica di
un componente soggetto ad un campo di sollecitazioni oppure il variare di una caratteristica
costruttiva in funzione del tempo di permanenza in funzione ecc). In ogni caso per effettuare
l’analisi delle caratteristiche dell’insieme considerato (cioè della funzione campionaria che lo
rappresenta) è utile definire alcuni operatori fondamentali:
1. serie- ordinamento degli elementi costitutivi l’insieme in ordine crescente o
decrescente;
2. partizione- suddivisione di una serie in parti successive , non devono essere presenti
elementi che facciano parte di più partizioni e la somma di tutte le partizioni deve
fornire l’intera serie di partenza senza modificarne la successione degli elementi
costitutivi;
3. campo- differenza tra i due valori estremi della serie o delle sue partizioni;
4. frequenza- numero di elementi facenti parte di una partizione.
Ovviamente mentre le definizioni sopra riportate risultano del tutto intuitive per un insieme
discreto, non altrettanto la sono per uno continuo; quest’ultimo dovrà, infatti, essere discretizzato
suddividendo il campo dell’ insieme in sottointervalli (partizioni) generalmente di uguale ampiezza.
Non esistono regole generali per stabilire il numero ottimale di partizioni; in generale si cercherà un
compromesso ragionevole tra una suddivisione troppo dettagliata ed una troppo grossolana, inoltre
si farà in modo di ottenere che il valore centrale di ogni partizione (valore che rappresenterà la
partizione stessa) sia un conveniente numero intero.
Una distribuzione campionaria di elementi può essere caratterizzata da uno o più indicatori quali:
moda- è il valore che si presenta con la massima frequenza (il numero maggiore di volte), in
generale tramite questa grandezza non si perviene ad una buona stima dell’intensità del
verificarsi di una condizione;
media aritmetica- rappresenta la più comune misura dell’intensità, se si indicano con:
Xj le osservazioni corrispondenti alle n partizioni (ad es. il valore centrale di ognuna),
fj i corrispondenti valori di frequenza, tali che fj =N (totale degli elementi costituenti la serie),
21
si ha:
Ā=j fj Xj/ j fj = j fj Xj/ N
j=1,n
media geometrica- sempre con le stesse definizioni precedenti
Â= NX1f1 X2f2…….xnfn
(2.1)
(2.2)
media armonicaH= 1/[(1/N) j (fj/Xj)]
(2.3)
L’utilizzo di una di queste diverse definizioni di media, che portano alla valutazione di valori
numericamente anche notevolmente differenti tra di loro, dipende essenzialmente dalle
caratteristiche del problema che si deve di volta in volta esaminare. E’, in ogni caso, utile tenere
presente la seguente relazione tra i diversi valori così calcolati:
H Â Ā
(2.4)
Risulta in moltissimi casi indispensabile effettuare una valutazione della dispersione dei dati
nell’intorno del valore medio calcolato; a questo scopo si possono utilizzare diverse formulazioni
tra loro legate:
1
scarto medio assoluto:
s=(j fj Xj-Ā ) / N = X- Ā
(2.5)
non risulta nella pratica particolarmente utile per cui si ricorre ad un’altra
definizione;
2
varianza: che non è altro che la media del quadrato degli scarti
2 = [j fj (Xj – Ā)2] / N
(2.6)
se il numero di prove o di campi è limitato (tipicamente minore di trenta) al posto della
definizione precedente si usa per la varianza la sua stima migliore:
2 = [j fj (Xj – Ā)2] / (N-1)
3
(2.7)
scarto quadratico medio: chiamata anche deviazione standard, fornita dalla radice
quadrata della varianza o della sua migliore stima; ha il vantaggio di essere espressa nelle
stesse unità di misura dei dati originali
= [j fj (Xj – Ā )2] / N [j fj (Xj – Ā )2] / (N-1)
(2.8)
per il suo calcolo si usano delle espressioni che risultano di più semplice valutazione
numerica; per esempio, sviluppando il quadrato degli scarti si ha:
= (X2 – Ā2) = [(j fj Xj2/N) – (j fj Xj/N)2]
(2.9)
risulta così necessario effettuare il calcolo solo del primo termine sotto radice, poiché Ā è
già noto; non è poi sempre detto che Ā corrisponda esattamente alla media aritmetica, se
questa condizione è verificata si otterrà il minimo valore dello scarto quadratico medio;
4
coefficiente di dispersione: la viene anche chiamata “dispersione assoluta”,
22
risulta utile effettuare anche la valutazione della “dispersione relativa” definita come il
rapporto tra la dispersione assoluta ed il valore medio; in particolare per ed Ā si ottiene il
“coefficiente di dispersione” che viene espresso in percentuale:
= / Ā
(2.10)
In molti casi risulta utile, al fine di semplificare i calcoli, effetture un cambiaento di variabile
tramite una trasformazione lineare del tipo:
Y=a+bX
In questo caso valgono le seguenti relazioni
Ȳ=a+b Ā
y = bx
3. Probabilità e frequenza
Gli eventi, dal punto di vista dell’analisi statistica e quindi della valutazione della probabilità
associata al verificarsi di uno o più di essi, possono essere suddivisi in due principali categorie:
A) eventi ripetibili:
che corrisponde a situazioni caratterizzate da condizioni al contorno
esattamente note e riproducibili; quali ad esempio la messa fuori
servizio di un componente durante una prova condotta in laboratorio
in condizioni, cioè, controllate e riproducibili, oppure l’uscita di un
numero alla roulette eseguendo un sufficientemente elevato numero di
tentativi;
B) eventi non ripetibili:
rientrano in questa categoria quasi tutti gli eventi che riguardano
situazioni legate alla variabilità delle condizioni di prova; quali il
funzionamento di un componente all’interno di un impianto (che avrà
la sua particolare ed in certa misura irripetibile “storia”), o la
posizione occupata da un purosangue durante una qualunque corsa.
Le differenze “pratiche” possono essere molto ridotte se, parlando ad esempio di un componente
sottoposto a sollecitazioni dinamiche, il campo di sollecitazione non è eccessivamente intenso; nel
caso contrario possono essere anche molto rilevanti (ad es. il caso delle prove di componenti a
banco per le normali automobili e per quelle di formula 1).
A rigore l’analisi statistica può con successo essere applicata unicamente alla prima categoria di
eventi; in particolare se vi si associa il concetto di “aspettativa” si può, in prima battuta valutare la
23
“frequenza relativa” (che d’ora in poi chiameremo semplicemente “frequenza”) del verificarsi (in
ogni tentativo o prova) di una ben determinata situazione, come rapporto tra eventi favorevoli (ad
es. l’uscita di un certo numero alla roulette) e numero totale di eventi possibili (il numero totale di
numeri presenti alla roulette). Per quanto riguarda la categoria (B) (eventi non ripetibili) la
valutazione della frequenza e/o della probabilità di evento sarà in qualche misura “soggettiva”; cioè
basata più sulla esperienza che su considerazioni matematiche. Come vedremo in seguito anche per
gli eventi di tipo (A) le statistiche sono costruite sulla base di “idee preconcette” che influenzano il
“punto di vista” dal quale si parte a priori, ne consegue il fatto che per valutare la correttezza di
una indagine statistica è indispensabile conoscere e valutare attentamente i presupposti su cui si
basa.
Si è ora introdotto il concetto di “probabilità” che trasforma una variabile ordinaria in una variabile
aleatoria; cioè in una quantità che può assumere valori diversi in dipendenza di un qualche
fenomeno casuale (ad esempio quale può essere la vincita in funzione di una certa giocata alla
roulette). Si ha così che:
x : variabile ordinaria (o quantitativa) (ad esempio la faccia 2 in un dado) x
p(x) : variabile aleatoria (la probabilità che in un certo numero di lanci esca la faccia 2 del
dado)
P(x) +]0,1[
In genere una variabile aleatoria, che può essere discreta o continua, gode delle stesse proprietà
algebriche di una ordinaria; una sua importante caratteristica consiste nel permettere la valutazione
del Valore Atteso che in qualche modo risulta simile a quello di media (aritmetica)..
Si chiama valore atteso, o media, o speranza matematica (Xva) di una variabile aleatoria discreta il
risultato della seguente espressione:
Xva (x) = Σi xi pi(xi)
per i [1,N]
A condizione che la serie converga; in caso contrario si dirà che la variabile aleatoria non ha un
valore atteso finito, ad esempio il numero che può uscire ad una giocata di un dado (x) e la
corrispondente ipotetica vincita p(x). Se la variabile aleatoria assume solo un numero finito di valori
equiprobabili (tali cioè che: pi(xi)=1/N per N = numero dei possibili stati del sistema, che in questo
caso coincide con il numero di elementi che compongono il sistema, i=1,N) il valore atteso
coinciderà con la media aritmetica:
Xva (x) = Σi xi/N = Ā
Se, al contrario i suddetti valori non sono equiprobabili il valore atteso sarà una “media pesata” dei
valori assunti da (x), in cui i valori più probabili pesano di più. Ad esempio se x rappresenta il
punteggio riportato sulle facce di un dado si ha:
Xva = 3.5 = Ā
24
Se il dado è truccato e si ha una frequenza pari a 0.5 per la faccia (2) ed a 0.1 per tutte le altre si ha:
Xva = 0.1 + 1. + 0.3 + 0.4 + 0.5 + 0.6 = 2.9
Vediamo quale sia il significato “pratico” del valore atteso.
Es.
Si vuole valutare il prezzo equo per partecipare ad un gioco d’azzardo; in una lotteria nazionale
sono in palio i seguenti premi in £:
1° premio: 3 miliardi
2° premio: 2 miliardi
3° premio: 1 miliardi
5 premi da 100 milioni
20 premi da 10 milioni
100 premi da 1 milione
Se vengono venduti 2 milioni di biglietti quale è il valore atteso della vincita per chi acquista un
biglietto? Se il biglietto costa 5000 £, conviene partecipare?
Se (x) è la variabile “denaro vinto con il biglietto che ho acquistato” la p(x) (che in questo caso è
una frequenza) è riportata nella seguente tabella:
xj
Pi(xi)
3 miliardi
1/(2 milioni)
2 miliardi
1/(2 milioni)
1 miliardo
1/(2 milioni)
100 milioni 5/(2 milioni)
10 milioni
20/(2 milioni)
1 milione
10/(2 milioni))
Quindi:
Xva = (3 miliardi / 2 milioni) + (2 miliardi / 2 milioni)+…..=
= 1500+1000+500+250+100+50 = 3400 £
Che rappresenta il valore atteso della vincita; poiché il prezzo del biglietto è di £ 5000. il gioco è
iniquo a sfavore di chi compra i biglietti.
Vediamo alcune semplici proprietà del valore atteso per valori discreti:
25
Xva (ax+b) = a Xva (x)+b
Xva (x1,x2….xn) = Xva (x1) + Xva (x2)+…. Xva (xn)
Ad esempio il valore atteso per l’uscita della medesima faccia lanciando contemporaneamente due
dadi vale:
Xva (2x) = 2 Xva (x) = 7.
Se si ha un funzione continua [f(x)] si può valutare il valore atteso come:
Xva[f(x)] = Σj f(xj) pj(xj)
E’, a questo punto, utile sottolineare come il concetto di probabilità, pur risultando intuitivamente
simile a quello di frequenza, in molti casi ne differisca sostanzialmente; a questo proposito
introduciamo il “teorema di Bernoulli”:
“se la probabilità del verificarsi di un evento (X) è (p) e se vengono effettuate (x) prove
indipendenti (senza cioè che si vengano a verificare cambiamenti nel campione o nelle condizioni
di prova); allora la probabilità P che la frequenza (=[casi favorevoli /casi totali ] = f/x dove f
rappresenta il numero di casi favorevoli nelle x prove) dell’evento differisca, di un () comunque
piccolo, da (p) tende a zero come n tendente all’infinito:
lim
P (| – p|)>ε)=0
(2.11)
x
La frequenza può cioè essere utilizzata per effettuare delle valutazioni statistiche su una
popolazione anche se il numero di prove da effettuarsi deve, a rigore, essere molto elevato.
Es.
Si abbia una moneta e si voglia valutare, mediante dei lanci di prova, se essa sia o meno truccata;
se è buona si deve avere, sulla base del Teorema di Bernoulli:
lim
x
P (| – p|)>ε)=
lim
x
P(|0.5- p|)
Se si effettuano10 lanci e si ottiene sempre testa può nascere qualche dubbio sia sulla moneta sia
sulla statistica a disposizione (il numero di lanci è troppo piccolo); se si effettuano 400 lanci
ottenendo sempre testa si può avere qualche serio dubbio sulla bontà della moneta; se si effettuano
in fine un milione di lanci, e si ha sempre lo stesso risultato, si può essere praticamente certi che la
moneta sia truccata.
Vediamo un altro caso. Si abbia un contenitore chiuso con all’interno delle biglie colorate e non si
abbia modo di conoscere né il numero di biglie contenute né la distribuzione dei colori. Se si
effettuano 200 estrazioni indipendenti (cioè ogni volta con reintroduzione della biglia estratta e
rimescolamento delle biglie stesse) si può ottenere la seguente distribuzione :
26
colore
=f/n=f/200
bianco
0.21
rosso
0.52
blu
0.27
Se si effettuano 10.000 estrazioni si può invece ottenere:
colore
=f/n=f/10000
bianco
0.24
rosso
0.50
blu
0.23
verde
0,03
Si ha così una distribuzione di frequenza che sarà molto più vicina all’effettiva distribuzione dei
colori ; per ottenere invece i valori relativi alla probabilità P si dovrebbero comunque effettuare un
numero quasi infinito di estrazioni. Infine si deve tenere presente come la valutazione di (f) e di (n)
possa essere affetta da scelte “a priori” e quindi non oggettive; come si vedrà in seguito l’esatta
individuazione delle situazioni corrispondenti ai “casi favorevoli” non sempre risulta intuitiva ed
agevole.
Per il calcolo della probabilità P si utilizzano dei particolari operatori algebrici Booleani di
intersezione () e di unione (); indicando con (X,Y,Z ecc) dei generici eventi e con [P(X),
P(Y),P(Z)] ecc i corrispondenti valori di probabilità, si possono scrivere le seguenti definizioni:
P(XY) : probabilità di avere sia l’evento X sia l’evento Y “contemporaneamente”,
ad es. probabilità di avere nella stesso gioco alla roulette sia il rosso sia il
pari (probabilità intersezione)
P(X/Y) : probabilità di avere x una volta che si sia verificato y (probabilità
condizionata)
P(XY) : probabilità di avere i due eventi disgiunti, ad es.
probabilità di avere in due diversi giochi alla roulette una volta il rosso ed una volta il
pari (probabilità unione)
e relazioni:
P(XY)= P(X) P(Y) se i due eventi sono statisticamente indipendenti, ad es. l’uscita di
un numero alla roulette ed il colore del vestito
P(XY)= P(X/Y) P(Y)=P(Y/X) P(X) se i due eventi sono dipendenti;
dalla precedente segue che, se due eventi sono statisticamente indipendenti, si ha:
27
P(X/Y) = P(X)
oppure
P(Y/X) = P(Y)
P(XYZ)= P(X/YZ) P(Y/Z) P(Z)
P(XY) = 1 – P(1-X)P(1-Y) = P(X)+P(Y)-P(XY)
per eventi non mutualmente escludentesi; e analogamente per tre variabili:
P(XYZ)= P(X)+P(Y)+P(Z)-P(XY)-P(XZ)-P(YZ)+P(XYZ)
Si noti come il concetto di statisticamente indipendenti è ben diverso da quello di mutualmente
escludentesi; nel secondo caso, infatti, si ha una totale dipendenza tra gli eventi che sono tali che il
verificarsi di uno esclude completamente la possibilità del verificarsi di una qualunque degli altri.
Valgono, inoltre, le seguenti regole generali dell’Algebra Booleana.
Legge cumulativa
Legge associativa X(YZ)= (XY)Z
Legge distributiva X(YZ)=(XY)(XZ) (XY)(XY)= X(YZ)
Legge di idempotenza
XX=X
XX=X
Legge di assorbimento
X(XY)=X
X( XY)=X
XY= YX
XY= YX
Es.
In un impianto la probabilità associata ad un fuori servizio del sistema idraulico è data da:
P(X) = 2/5 : probabilità di rottura della pompa
P(Y) = 3/4 : probabilità di non funzionamento della valvola motorizzata
P(XY) = 4/5 : probabilità che almeno uno dei due componenti (o tutti e due) sia fuori
servizio
Valutare:
1. la probabilità che sia la pompa sia la valvola siano contemporaneamente fuori servizio;
2. la probabilità che la pompa sia fuori servizio una volta che lo sia anche la valvola.
1. Dalla definizione di unione si ha :
P(XY) = P(X)+P(Y)-P(XY) P(XY) = P(X) + P(Y) - P(XY) =
= (2/5) + (3/4) – (4/5) = (7/20)
Se si fossero considerati i due eventi indipendenti si sarebbe avuto:
P(XY) = P(X) x P(Y) = (2/5) x (3/4) = 6/20
2. Dalla definizione di probabilità condizionata:
p(X/Y) = P(XY) / P(Y) = (7/20) / (3/4) = 7/15 = 0.46
28
La probabilità, legata ad un generico evento (X), P(X) rappresenta, in sostanza, un modo per
valutare il grado di conoscenza acquisito sull’evento, piuttosto che una sua “proprietà fisica”.
In questa senso la probabilità soddisfa i tre fondamentali assiomi di Kolmogorov:
o per ogni evento (X) si ha 0 P(X) 1;
o se P()=1 rappresenta la totalità degli eventi possibili
se P()=O rappresenta l’evento nullo;
o se (X1, X2,....Xn) costituiscono un insieme di eventi mutualmente escludentesi, si ha:
P(j Xj) = j P(Xj)
per j=1,n
Sviluppando la definizione di operatore unione ed applicandola alla probabilità di (Xj , j=1,n) eventi
non mutualmente escudentesi si ha:
P(j Xj) = j P(Xj) - i j P(Xi Xj) + ......+ (-1)n+1 j P(Xj)
per j=1,n i=1,n-1
Se, allora, si considera solo il primo termine della somma si ottiene il limite superiore :
P(j Xj) j P(Xj)
e se si considerano solo i primi due termini si ottiene il limite inferiore:
P(j Xj) j P(Xj) - i j P(Xi Xj)
In molti casi di interesse pratico si utilizza, per la valutazione di P(j Xj) il limite superiore,
riferendosi così alla approssimazione per gli eventi rari.
Introduciamo ora il Teorema della probabilità totale, secondo il quale se si suddivide l’intero
spazio del possibile in Xj (j=1,n) eventi mutualmente escudentesi:
Xi ∩ Xj = 0 i≠j
e
∑j P(Xj)=1
per j=1,n
Dato un qualunque evento A, la sua probabilità di verificarsi può essere valutata in termini delle
probabilità condizionate:
P(A) = P(A/X1)P(X!) + P(A/X2)P(X2)+......+ P(A/Xn)P(Xn)
Es.
Da una statistica elaborata sulla base dei dati degli ultimi 3 anni si è visto che la probabilità di
decesso per incidenti automobilistici a causa della mancanza di controllo sulla velocità eccessiva è
del 40% e a causa della mancanza del controllo sulla guida in stato di ubriachezza è del 25%;
assumendo, inoltre, che la probabilità di mantenere il numero e la gravità degli incidenti a livelli
accettabili quando almeno una delle due cause (mancanza di controllo per eccesso di velocità e/o
ubriachezza) viene a mancare sia dell’80%. Si Valuti:
a) la probabilità di mantenere il numero e la gravità degli incidenti a livello accettabile per i
prossimi 3 anni;
29
b) se, nei prossimi tre anni, non si riuscirà a mantenere a livelli accettabili il numero e la gravità
degli incidenti, quale è la probabilità che questo fatto sia interamente causato dal non riuscire a
controllare efficacemente la velocità dei veicoli?
a) Indichiamo con:
A1 l’evento di successo legato al controllo della velocità massima;
A2 l’evento di successo associato al controllo del tasso alcolico dei guidatori;
X l’evento legato al mantenimento a valori accettabili del numero e della gravità degli
incidenti.
Ā1 (Ā2) gli eventi complementari rispettivamente di A1ed A2 (tali che A1+Ā1=1)
Da cui:
P(A1) = 0.60
P(A2) = 0.75
P(X/A1Ā2) = P(X/Ā1A2) = 0.80
P(X/Ā1Ā2) = 0
P(X/A1A2) = 1
Tutte le possibili combinazioni dei due eventi legati al controllo della velocità e del tasso alcolico
sono:
P(A1A2) = 0.60 x 0.75 = 0.45
P(A1Ā2) = 0.60 x 0.25 = 0.15
P(Ā1A2) = 0.40 x 0.75 = 0.30
P(Ā1Ā2) = 0.40 x 0.25 = 0.10
Considerando gli eventi (A1A2, A1Ā2, Ā1A2, Ā1Ā2) mutualmente escudentesi e tali da coprire
l’intero spazio del possibile, si può applicare il Teorema della probabilità totale:
P(X) = P(X/A1A2)P(A1A2) + P(X/Ā1A2)P(Ā1A2) + P(X/A1Ā2)P(A1Ā2) + P(X/Ā1Ā2)P(Ā1Ā2) = 0.81
b) La probabilità di non riuscire a mantenere a livelli accettabili il numero e la gravità degli
incidenti automobilistici legata al fallimento nel controllo della velocità dei veicoli e data da:
P(Ā1A2/Ψ) = [P(Ψ/Ā1A2)P(Ā1A2)] / P(Ψ) = [1- P(Ψ/Ā1A2)] P(Ā1A2) / P(Ψ) = 0.32
Dove con (Ψ) si indica l’evento complementare di (X); al pari di (Ā) per (A).
4. Modelli probabilistici
Se la legge fisica che regola il fenomeno che si sta studiando è nota e pure note sono tutte le
variabili si è nel campo deterministico. Ad esempio dato un proiettile, conoscendone le
caratteristiche fisiche, l’impulso impresso e la sua direzione e verso, se ne può descrivere
esattamente la traiettoria in un mezzo noto. Se, al contrario, si ha solo una conoscenza approssimata
di alcune delle precedenti grandezze ci si troverà a lavorare nel campo probabilistico. Per (N)
proiettili, di cui si conoscono esattamente le caratteristiche fisiche ma approssimativamente
30
l’impulso, si potrà adottare un modello statistico per valutare la probabilità di avere un certo numero
di impatti in un’area data.
I risultati di osservazioni statistiche possono essere analizzati utilizzando un opportuno modello
matematico che rappresenti la legge di dipendenza dell’evento in esame dalla variabile indipendente
utilizzata (ad es. tempo, spazio, numero di prove ecc) che può essere, a sua volta, discreta o
continua. Tale modello matematico viene chiamato funzione densità di probabilità e rappresenta
la distribuzione, continua o discreta, della probabilità di accadimento dell’evento in esame. La
funzione integrale, o somma, della precedente viene chiamata funzione cumulativa di probabilità
e, se estesa a tutto il possibile intervallo della variabile indipendente, ha sempre valore pari
all’unità.
Molto spesso la funzione densità di probabilità viene espressa in termini dimensionali la fine di
facilitarne sia il calcolo (e questo vale soprattutto per la sua cumulata) sia la comprensione fisica. Si
veda, ad esempio, la funzione di distribuzione della probabilità della velocità del vento in un sito
(data da una distribuzione di Weibull a due parametri) che presenta le dimensioni dell’inverso di
una velocità.
4.1 Modelli discreti
Binomiale
Rappresenta la situazione nella quale sono possibili solo due eventi (detti stati del sistema :
testa/croce; funziona/non-funziona ecc); se si eseguono su un generico insieme (n) prove
indipendenti (l’insieme di partenza non cambia a seguito delle prove) e la probabilità (p) di
successo in ogni singola prova rimane costante per tutte le (n) prove la probabilità di avere
esattamente (x) successi nelle (n) prove, è fornita dalla seguente espressione:
f(x/n;p)= (nx) px (1-p)n-x
dove
(nx) = n!/[(n-x)! x!]
(2.12)
E la corrispondente funzione cumulata (probabilità di avere x o meno successi in (n) prove):
F(X x/n;p)= i (ni) pi (1-p)n-i
per i=0,x
(2.13)
Si possono poi calcolare :
Il volor medio: =i xi f(xi/n;p) = np
La varianza: 2 = i (xi -)2 f(xi /n;p) = np(1-p)
Es.
Per rendere più immediata la differenza tra probabilità (p) e frequenza (λ) può risultare utile il
seguente esempio (tratto da una lettera di Pascal a Fermat scritta nel 1654).
31
Si vuole valutare se sia più facile fare almeno un 6 lanciando un dado 4 volte, o fare almeno un
doppio 6 lanciando 2 dadi 24 volte.
Intuitivamente si potrebbe ragionare così:
la probabilità di ottenere 6 con un lancio di un dado vale (1/6), la probabilità di ottenere un
doppio 6 con un lancio di due dadi vale (1/36); allora si potrebbe pensare di valutare la
probabilità di successo nei due casi come:
4/6 = 24/36=0.66 (rapporto tra possibili casi favorevoli(numero di lanci) e casi totali che è
appunto la definizione di frequenza)
deducendo che i due casi in esame sono equiprobabili.
In realtà per calcolare la probabilità di successo si deve utilizzare la Binomiale, che fornisce:
probabilità di avere almeno un successo in 4 tentativi = probabilità cumulata di avere da 1 a
4 successi in quattro tentativi → F(1≤X≤4/4;1/6) = 1- f(0/4;1/6) = 1-(5/6)4 = 0.5177;
analogamente per il secondo caso:
probabilità di avere almeno un successo in 24 tentativi: 1- f(0/24;1/36)=1-(35/36)24=0.4914
che risulta, se pur di poco, inferiore al valore precedente (per entrambi i casi si ottiene un
valore della probabilità di evento ben inferiore a 0.66 relativo alla frequenza).
Esercizio
Si ha una batteria che consente 8 partenze con la quale si devono avviare 3 motori; la probabilità di
non fallire in ogni singolo avviamento vale 0.9.
Calcolare la probabilità di avere almeno 3 successi in 8 prove.
Le funzioni di distribuzione di probabilità possono essere utilizzate per verificare se, ed in quale
misura, il comportamento di una popolazione risponda o meno alle ipotesi statistiche fatte (se, ad
esempio, si ha una moneta, fatta l’ipotesi statistica moneta buona, la si potrà verificare controllando
che effettivamente si abbia p=0.5). Vediamo un esempio di questa modalità di applicazione.
Es.
Si abbia una produzione industriale e si voglia costruire una “regola di decisione” al fine di
verificare se il processo sia o meno sotto controllo. Per fare questo si decide “a priori”, o “sulla base
dell’esperienza” che il processo sia sotto controllo se, utilizzando una funzione di distribuzione
binomiale, si ha che p=0.1 (probabilità di avere un singolo generico componente guasto).
32
Si può allora costruire la seguente tabella per n=10 prove ed x=1,2,3,….,7 o più componenti guasti
(si noti come il termine “successo”, ha il significato generale di “evento cercato” e non quello di
“evento desiderabile”):
x (guasti)
f(x/n:p)=f(x/10;0.1)
0
0.3487
1
0.3874
2
0.1937
3
0.0574
4
0.0112
5
0.0015
6
0.0001
7
0.0000
dove il valore della f riportato nell’ultima riga ha il significato che la probabilità di avere 7 o più
guasti su 10 componenti non è esattamente zero, ma semplicemente che il corrispondente valore
presenta cifre significative diverse da zero oltre la quarta dopo la virgola.
Se, ad esempio, si decide di prendere come valore discriminante (x5), si ha che F(X 5/10;
0.1)=0.0016
Il che significa che se si ripete 10000. volte un test, su campioni tutti di 10 componenti, si dovranno
avere circa 16 test per i quali si sono trovati 5 o più componenti guasti. Se questo non si verifica (se
ad esempio non se ne trova neanche uno) allora si potrà dedurre che il processo è “probabilmente
fuori controllo” e che si devono “probabilmente” attuare delle azioni correttive.
Multinomiale
E’ una generalizzazione del modello Binomiale utilizzata per i casi in cui sono possibili più di due
eventi diversi (che si escludono l’un l’altro, ma che non risultano tra loro correlati). La funzione
densità di probabilità (probabilità di avere esattamente, in (n) prove indipendenti, (x1). volte
l’evento 1 che si presenta con probabilità (p1), (x2) volte l’evento 2 che si presenta con probabilità
(p2) ecc. ) è dato dalla seguente espressione:
f(x1,x2,…..,xk/n; p1,p2,….,pk)= (n!/x1!x2!….xk!) p1x1 p2x2….pkxk
(2.14)
dove (k) rappresenta il numero di possibili stati del sistema.
Il modello Binomiale si può ottenere da quello Multinomiale ponendo:
33
x1=x successi
x2=(n-x) insuccessi
p1=p probabilità di successo p2=(1-p) probabilità di insuccesso
Es.
Si valuti la probabilità di successo di avere contemporaneamente in 9 lanci di due monete:
2 teste in 2 lanci : stato 1 (2 testa contemporaneamente in 2 lanci di 2 monete)
1 testa in 4 lanci : stato 2
0 testa in 3 lanci : stato 3
Con riferimento alla funzione multinomiale si ha:
n=9
p1 = p(testa,testa) = p(testa) ∩ p(testa) = ½ x ½ = ¼ (probabilità di avere in un lancio di due
monete due “testa)
p2 = p(testa,croce) p(croce,testa) = 1/4 + 1/4 = ½ (la probabilità intersezione di due eventi
escludentesi vale zero)
p3 = p(croce,croce) = ¼
Si ha così :
f(2,4,3/9; (¼), (½), (¼)) = 0.0769
Geometrico
Deriva anch’esso dal modello Binomiale, e viene utilizzato nei casi in cui si voglia valutare la
probabilità di avere esattamente (n) prove per ottenere un successo:
f(n/p)= p(1-p)n-1
(2.15)
La relativa probabilità cumulata (probabilità di avere un numero di prove minore od uguale ad n) è
data da:
F(N n/p) = 1-f(x=0/n;p) = i p(1-p)i-1= 1-(1-p)n
per i=1,n
(2.16)
Come vedremo questa funzione di distribuzione discreta rappresenta l’equivalente della funzione
Gamma per le continue.
Es.
Se una lampadina si brucia quando V230 V, e la probabilità di avere un tale valore della tensione è
pari a 0.003 picchi/ora; la probabilità che la lampadina sia ancora in funzione dopo 20 ore di
missione vale:
34
F(N 20/0.003)= 1-F(N 20/0.003)= (1-0.003)20= 0.942
Di Poisson
La funzione di Poisson può essere vista come “limite” della Binomiale quando la (p : probabilità di
successo in ogni singola prova) sia molto piccola ed (n : numero di prove) molto grande; in questo
caso si valuta la frequenza (λ) dell’evento (di successo) in un intervallo definito a priori e tale che:
λ = np (numero medio di successi nell’intervallo considerato)
(2.17)
Ad esempio (λ) rappresenti il numero medio di persone che transitano giornalmente in una stazione,
e si vuole valutare la probabilità (P) che in un giorno ben definito (ad esempio il 24 ottobre)
transitino nella stazione esattamente (x) persone. Si può allora porre:
P = f(x/n;p) = (nx) px (1-p)n-x
dove:
n : numero totale di persone potenzialmente utenti della stazione il 24 ottobre (valore
ignoto)
p : probabilità che ogni singolo potenziale utente transiti effettivamente per la stazione
dalla (2.17) si ha che : p= λ/n da cui:
P = (nx) (λ/n)x (1- λ/n)n-x
In quest’ultima espressione (λ) è noto ed (n) è incognito, ma comunque molto grande; se si fa
tendere (n) all’infinito → (p = λ/n → 0) si ottiene:
lim
x
P=
lim
(nx) (λ/n)x (1- λ/n)n-x = e-λ λx / x!
(2.18)
x
che rappresenta l’espressione dell’approssimazione di Poisson della Binomiale per (n) molto grande
e (p) molto piccolo; si noti a questo proposito come in molti casi di interesse pratico queste due
condizioni vadano di conserva. Si tenga, però, anche presente come queste due condizioni non è
detto che siano “sempre” verificate e/o controllabili; inoltre le locuzioni “grande” e “piccolo”
sono poco definite.
Es.
In una linea produttiva la frequenza relativa con cui sono prodotti pezzi difettosi e p=0.01; quale è
la probabilità che su n=1000 pezzi prodotti ce ne siano esattamente x=4 difettosi?
Utilizzando la Binomiale si ha:
P = f(4/1000;0.01) = (10004) 0.0014 0.991000-4 ≈ 0.0186
35
Sfruttando l’approssimazione di Poisson con (λ = 1000 x 0.001 = 10) si ottiene:
P = e-10 (104 /4!) ≈ 0.0189
Che rappresenta una approssimazione accettabile con il vantaggio di utilizzare calcoli più
“trattabili”.
Nei due grafici di Fig. 2-1 viene riportato un esempio di approssimazione di Poisson della
Binomiale per (λ = np = 2); nel primo grafico (n = 10 e p = 0.2) nel secondo (n = 20 e p = 0.1);
come si vede l’approssimazione tende a migliorare all’aumentare di (n) ed al diminuire di (p).
Fig. 2-1 Andamento dell’approssimazione di Poisson al variare di (n) e di (p)
Si noti come implicitamente ci si sia sempre ricondotti ad un “intervallo unitario” (1 giornata; 1
singolo componente difettoso). Se ora si considera come variabile indipendente il tempo (t) si può
analizzare, ad esempio, il caso in cui una certa macchina sia soggetta ad un numero medio di guasti
() in un generico intervallo temporale [0,t]; se si suddivide tale intervallo temporale in un numero
(n) molto grande di intervalli elementari Δt tali che:
1.
in ogni Δt la probabilità di un singolo guasto vale (p = costante);
2.
in ogni Δt la probabilità che avvenga più di un singolo guasto è, in pratica, nulla
(trascurabile rispetto a p) → gli eventi “guasto” sono “non-sovrapponibili”, cioè
“distinguibili”;
36
3.
gli eventi “in un generico intervallo Δt” (si ha o non si ha il guasto) sono indipendenti; in
pratica il fatto di avere un guasto in un Δt nulla ci dice su quello che potrebbe accadere in un
altro Δt′.
Allora si può utilizzare l’espressione di Poisson per valutare la probabilità di avere esattamente (x)
guasti nell’intervallo [0,t] quando () è la frequenza di guasto nell’intervallo stesso:
f(x/)= e-(x/x!)
(2.19)
e la sua cumulata:
F(X≤x/λ) = Σi e-λ λi/i!
per i=0,x
Poiché si è supposto che (p) sia costante in ogni generico intervallo Δt si ha anche che:
“la (p) è uniformemente distribuita su tutto l’intervallo temporale considerato [0,t], ed il suo
valore risulta proporzionale all’ampiezza dell’intervallo elementare Δt”. In sostanza si è sostituito
ad (n) grande, un intervallo temporale [0,t], che contiene un numero grande di sottointervalli
elementari (Δt).
Ci si può allora riferire, per la valutazione di (), ad un generico “intervallo unitario”, ed il suo
valore risulterà proporzionale all’ampiezza dell’intervallo unitario scelto.
Sulla base di quanto ora detto, risulta importante effettuare una analisi “a priori” della situazione in
esame al fine di valutare se sia o meno possibile utilizzare l’approssimazione di Poisson, come si
vedrà nel successivo esempio.
Es.
Se il numero medio di telefonate che arrivano ad un centralino è di 30 ogni ora;
a) quale è la probabilità che in un periodo di 3 minuti non arrivi nessuna telefonata?
b) quale è la probabilità che in un periodo di 5 minuti arrivino più di 5 telefonate?
Se il numero di “utenti potenziali” del centralino è molto alto e la probabilità che ciascuno telefoni è
molto bassa, i comportamenti degli utenti sono indipendenti e si può ragionevolmente ipotizzare che
la probabilità di arrivo delle telefonate sia “uniforme nel tempo”. La frequenza () di telefonate in
un intervallo di 3 minuti varrà allora:
λ = 30 (telefonate/ora) x 3 (minuti) / 60 (minuti/ora) = 1.5
e la cercata probabilità di avere esattamente zero telefonate in tre minuti:
P = e-1.5 = 0.223
Analogamente per la domanda (b) si ha:
λ = 30 x 5 / 60 = 2.5
P (X>5) = 1 – P(X≤5) = 1- e-2.5 Σk (2.5k/k!) ≈ 0.042
per k=0,5
In ogni caso prima di effettuare le valutazioni ora riportate sarebbe stato necessario porsi alcune
domande riguardo la correttezza del metodo utilizzato:
37
i)
siamo sicuri che abbia senso parlare di numero medio di telefonate in arrivo ogni ora senza
precisare a quale intervallo (ad esempio notte o giorno) ci si riferisce?
ii)
siamo sicuri che il numero medio di telefonate in arrivo in 12 ore sia esattamente 12 volte il
numero medio di telefonate in arrivo in una ora? (Ci si potrebbe anche chiedere: “siamo
sicuri che sia lecito considerare sottointervalli di un’ora?)
iv)
i dati in nostro possesso sono sufficienti a calcolare la probabilità (P) che ci interessa?
Nel caso in esame l’unica risposta corretta è:
non è possibile, con i dati a disposizione, effettuare la valutazione richiesta.
Riassumendo la distribuzione di Poisson è relativa ai casi in cui un evento (che si presenta () volte
nell’intervallo unitario) si manifesta in un piccolo intervallo con probabilità proporzionale
all’ampiezza dell’intervallo stesso. Viene, nella pratica, utilizzata come approssimazione della
distribuzione Binomiale quando il numero di prove risulta così elevato da non permettere
l’applicazione del calcolo combinatorio; la funzione di distribuzione di probabilità rappresenta
allora la probabilità di avere esattamente (x) successi in un intervallo unitario quando ( = np) è la
frequenza (intensità di manifestazione del successo) nell’intervallo unitario generico:
f(x/)= e-(x/x!)
Anche per questa funzione si possono valutare:
Il volor medio: = = np
La varianza: 2 =
e la funzione cumulata di probabilità (probabilità di avere un numero di successi minore od uguale a
(x) nell’intervallo unitario):
F(X x/)= i e-(i/i!)
per i=0,x
(2.20)
Se la frequenza () è sicuramente uniformemente distribuita la funzione di Poison può essere
calcolata per un generico intervallo (δ):
f(x/)=e- [()x/x!]
(2.21)
e rappresenterà la probabilità di avere esattamente (x) eventi nell’intervallo generico (δ). Questa
funzione di distribuzione viene anche chiamata funzione di Erlangian; eliminando il riferimento
all’intervallo unitario si noti come () abbia acquisito le dimensioni di (1/δ).
Esercizio
Se 20 elementi guasti sono distribuiti in 260 casse, l’intensità del verificarsi dell’evento
“componente guasto” nell’intervallo unitario “una cassa” vale 20/260=0.07692; si valuti la
probabilità che una cassa estratta dalle altre contenga esattamente zero elementi guasti.
38
Esercizio
Da un casello autostradale transitano veicoli al ritmo di 200 all’ora; si supponga che l’1% di tutti i
veicoli in transito sia costituito da TIR e si voglia calcolare:
a) quale sia la distribuzione appropriata per calcolare la probabilità di avere esattamente 5 TIR su
100 veicoli in transito, e si voglia calcolarne il valore;
b) quale sia la distribuzione appropriata per calcolare la probabilità che transitino esattamente 5
veicoli in un intervallo di un minuto, e si voglia calcolarne il valore;
c) quale sia la distribuzione appropriata per calcolare la probabilità che transitino almeno 100
veicoli prima del prossimo TIR, e si voglia calcolarne il valore.
4.2 Modelli continui
Gamma
Questo modello è già continuo e permette di valutare la probabilità di avere esattamente l’x-esimo
evento al tempo t centrato su dt; come si vede si adotta un intervallo infinitesimo (dt) ed il tempo
come variabile indipendente:
f(/x)= f(x-1/) dt = e- [()x-1/(x-1)!] dt
(2.22)
= e- [()x-1/(x-1)!]
(2.23)
dove il primo termine al secondo membro rappresenta la probabilità di avere esattamente (x-1)
eventi nell’intervallo [(0,t)=]; la (2.23) ne rappresenta la formulazione utilizzata per effettuare dei
calcoli. La funzione cumulata, probabilità che l’x-esimo evento si verifichi in un intervallo minore
od uguale a (); cioè che si verifichi nell’intervallo temporale [0,t], vale:
F( /x) = 1-e- [1+ ()/1! + ()2/2! +……+ ()x-1/(x-1)!]
(2.24)
Quest’ultima funzione di distribuzione è, nella pratica, adottata quando un componente viene messo
fuori servizio da un certo numero (x) di sovraccarichi o di fattori di usura; si vuole allora valutare la
probabilità di avere esattamente l’x-esimo evento al tempo t dopo un intervallo lungo () (in che
equivale a valutare la probabilità di avere esattamente un intervallo temporale pari a () prima di
mandare fuori servizio il componente).
Es.
Se un componente può sopportare un numero massimo (x) di sollecitazioni, cioè va fuori servizio
alla (x+1)-esima sollecitazione, la probabilità che non vada fuori servizio in un intervallo (),
quando (λ) rappresenta la frequenza del’evento “sollecitazione” nel’intervallo unitario vale:
F(> /x+1) = 1 - F(≤ /x+1) =
39
= e- [1+ ()/1! + ()2/2! +……+ ()x/x!] = e-λδ ∑i ()i/i!
per i=0,x
Questa espressione è identica a quella che fornirebbe la funzione cumulata di Poisson (Erlangian) al
fine di valutare la probabilità di avere (x) o meno eventi nell’intervallo (δ). Non risulta comunque
coretto sostituire la Gamma cumulata con quella di Poisson, poiché quest’ultima è ancora una
funzione discreta che deve essere a rigore utilizzata come approssimazione della Binomiale.
Es.
Se un componente è assoggettato a sovraccarichi che presentano una frequenza di accadimento =2
(eventi/anno) e và fuori servizio al quinto sovraccarico, quale è la probabilità di avere ancora il
componente funzionante dopo tre anni di missione?
Si avrà cosi che =t=3 anni e la cercata probabilità vale:
F( 3 2/5) = 1- F( 3 2/5) = e-(3x2)[1 + (2x3) + (2x3)2/2 +
+(2x3)4/4!] =
= 0.285
Esponenziale
Ponendo, a partire dal modello Gamma (2.23), x=1 si ottiene il modello Esponenziale che permette
di valutare la probabilità di avere esattamente un intervallo lungo () tra due eventi successivi:
f(/)= e-
(2.25)
Anche per questa funzione si possono valutare:
Il volor medio: =1/
La varianza: 2 =1/2
e la funzione cumulata di probabilità (probabilità di avere un intervallo () tra due eventi
successivi:
F( /)= 1-e-
(2.26)
Dove il termine (e-) rappresenta la probabilità di avere un intervallo maggiore od uguale a ();
cioè la probabilità che l’evento non si presenti per tutto l’intervallo ().
Come vedremo più avanti questo concetto risulta particolarmente utile quando si vuole valutare
l’Affidabilità di un componente, cioè la probabilità che il componente non subisca, per un certo
intervallo temporale, un evento di guasto.
Es.
Se ogni 100 relè se ne trova uno guasto (=0.01), la probabilità di trovare un relè guasto nei primi
25 vale :
F( 25/ 0.01)= 1-e-(0.01x25)= 0.221
40
Il modello esponenziale è caratteristico dei “sistemi privi di memoria” nel senso che la probabilità
di avere un evento in un intervallo di tempo [Δt = t2 –t1], posto quindi a partire da (t=t1), è
esattamente uguale alla probabilità di avere un evento in un intervallo di uguale ampiezza [Δt’]
posto a partire da (t=0). Cioè, considerando la funzione cumulata di probabilità, non ha importanza
in quale punto della scala temporale è posizionato (δ).
Se quindi si stanno valutando le caratteristiche di un componente, cioè la sua “probabilità di
sopravvivere per un certo intervallo temporale” e si utilizza la funzione di distribuzione
esponenziale, si parte dal presupposto che il comportamento del componente “non abbia memoria”,
cioè non sia soggetto ad “usura”.
Es.
La concentrazione giornaliera di un inquinante in atmosfera è fornito da una distribuzione
esponenziale.
a) Se la concentrazione media giornaliera è di 2 mg/103 l (litro), determinare il valore di ;
b) Se la concentrazione dell’inquinante diventa non accettabile oltre i 6 mg/103 l, valutare la
probabilità che si abbia un eccessivo inquinamento in un qualsiasi giorno;
c) valutare la probabilità che l’inquinante possa arrivare ad una concentrazione non accettabile non
più di una volta in tre giorni successivi.
a)
Poiché = 1/ = 0.5
b)
P(δ6) = 1 – P(δ6) = 1 - 0 0.5 e0.5x dx =e-λδ = e-0.5x6 = 0.0498
c)
La probabilità di avere una concentrazione eccessiva non più di una volta in tre giorni
consecutivi vale:
P(δ1/3; 0.0498) = i (3i) 0.0498i (1-0.0498)3-i = 0.993
per i=0,1
Gaussiano
Mentre tutti i modelli fino ad ora visti sono una derivazione del modello Binomiale (ad eccezione
del Multinomiale che ne rappresenta comunque una estensione), nel senso che possono essere
applicati quando si hanno solo due possibili stati per il sistema in esame (funziona- non funziona,
avviene- non avviene ecc) il modello Gaussiano è di diversa natura ed è relativo ai casi nei quali
una grandezza (ad esempio una dimensione geometrica) è composta da una aliquota fissa costante
(valore medio nominale ) ed una aleatoria (legata alle incertezze ); queste grandezze vengono
valutate, come visto all’inizio del capitolo, utilizzando la (2.1) e la (2.8). La funzione di
distribuzione ha un dominio di definizione tra (+) e (-), è simmetrica rispetto al valor medio e
41
permette di calcolare la probabilità che la variabile indipendente assuma un ben determinato valore
(x) :
f(x)= (1/2) exp[-0.5(x-/)2] = N(,2)
(2.27)
e la relativa funzione cumulata di probabilità (probabilità che la variabile indipendente sia compresa
all’interno di un certo intervallo):
F(Xx)= (1/2) -∞ exp-0.5[(x-/)2]dx
(2.28)
dove () è il valor medio, che corrisponde al “valore atteso”, e () lo scarto quadratico medio.
La Gaussian viene spesso chiamata legge Normale ed indicata, come riportato nella (2.27) con
N(,2).
La () rappresenta il grado di dispersione dei dati nell’intorno di (), ed in questo senso si ha che:
Il 68.27% dei dati è compreso tra [- ; +]
Il 95.45% “ “
“
“ [-2 ; +2]
Il 99.73% “ “
“
“ [-3 ; +3]
In Fig. 2-2 è riportato l’andamento della legge Normale per diversi valori di e .
Fig. 2-2 Andamento della Normale per diversi valori di e .
Al fine di semplificare i calcoli della funzione cumulata è utile introdurre un cambiamento di
variabili, introducendo la variabile adimensionale (z):
z=(x-)/ per x= si ha z=0 dx= dz
si potrà così scrivere una Gaussiana che presenta valor medio pari a zero e scarto quadratico medio
pari ad uno, detta Gaussiana ortonormalizzata (detta anche Normale Standard) :
f(z)= (1/2) exp(-z2/2)
(2.29)
con la corrispondente funzione cumulata:
42
F(Zz)= (1/2) -∞ exp(-z2/2) dz
Utilizzando questa forma della Gaussiana si può ricorrere a tabulazioni della funzione cumulata
come quelle di seguito riportate [Tab. II].
Es.
La resistenza a pressione di un campione di 132 serbatoi segue una legge Gaussiana con =8.4
Kg/cm2 e =0.2 Kg/cm2 (valori ai quali corrisponde un coefficiente di dispersione =σ/μ=0.023); si
vuole conoscere il numero di serbatoi con resistenza inferiore ad 8. Kg/cm2.
Si ricava:
z=(8-8.4)/0.2=-2
e dalla tabella II, essendo la Gaussiana simmetrica rispetto al valor medio, si ricava che l’area
sottesa dalla curva tra (z=-) e (z=-2) vale:
A= 0.5-0.4772=0.0228
E rappresenta la probabilità, per ogni singolo serbatoio, di avere resistenza superiore a quanto
richiesto; il numero di serbatoi cercato sarà allora dato da:
N = Ax132= 0.0228x132=3.009=3
In questo esempio abbiamo utilizzato un altro importante parametro, il coefficiente di dispersione il
cui valore rende conto di quanto siano effettivamente dispersi i dati nell’intorno del valor medio.
La funzione Gaussiana trova moltissime applicazione nella valutazione delle caratteristiche di
componenti e/o sistemi. Può ad esempio essere utilizzata nel caso in cui la misura di una qualunque
grandezza fisica sia affetta da errori (sia cioè una variabile aleatoria) tali che:
(valore vero) ± (errore sistematico) ± (errore casuale)
In particolare i due termini che si vengono a sommare al (valore vero) sono tali da essere
rappresentabili da una legge Normale che fornisce:
o Per N(0,2) → solo errore casuale
o Per N(,2) → errore sistematico ed errore casuale
Es.
Il peso del contenuto di certe confezioni alimentari è dato da una legge Normale con (µ = 250 g) e
(σ = 3 g); si vuole calcolare la probabilità che una confezione:
a) pesi meno di 245 g
b) pesi più di 250 g
c) abbia peso compreso tra 247 g e 253 g.
(a) si ha che z = (245-250)/3 ≈ -1.67 da cui:
43
F(X<245) = 0.5-F(z=1.67) = 0.5-0.4525 = 0.0475
(b) poiché µ=250 g si ha che F(X>250) = 0.5
(c) si ha che z1 = 1 e z2 = -1 da cui:
F(z1,z2) = F(1) – F(-1) = 2 F(1) = 2 x 0.3413 = 0.6826
44
Tabella 2-I
Risulta a questo punto importante sottolineare due aspetti legati alle funzioni di distribuzione
discrete e continue. Per prima cosa, al contrario delle funzioni di distribuzione discrete, le continue
45
non hanno un “significato fisico” immediato; ma risultano essere piuttosto una astrazione
matematica. Il loro campo di definizione, [0; +] per l’Esponenziale e [-∞,+∞] per la Normale, non
rappresenta, in molti casi di interesse pratico, un dominio “fisicamente accettabile”, come si era ad
esempio prima visto per la valutazione della resistenza a pressione dei serbatoi.
In particolare per la Gaussiana si avrà così che, mentre per tutti i casi di interesse pratico la f(x)
varierà solo tra [0, ], per la corrispondente funzione ortonormalizzata f(z) il dominio sarà
comunque esteso a tutto il campo [- ; +]. Questo è possibile grazie all “perdita di significato
fisico” della variabile (z) rispetto alla (x) e permette di poter lavorare con un valore della probabilità
cumulata, estesa a tutto il dominio di definizione, uguale ad uno; è infatti essenziale che la
probabilità associata al verificarsi di tutte le possibili situazioni sia unitaria. Per valutare il grado di
approssimazione introdotto implicitamente con la sostituzione della (x) con la (z) si consideri che:
z=(x-)/ zx=0 = -/ = - 1/ lim zx=0 = -
Con il diminuire del coefficiente di dispersione () diminuisce anche “l’errore” introdotto; il che
equivale a dire che più la gaussiana e concentrata (piccata) nell’intorno del valor medio più è
corretto estendere il dominio di integrazione della variabile (z).
Un’altra considerazione, che risulta essere sostanzialmente una conseguenza di quanto ora
visto, riguarda il fatto che per le funzioni continue la probabilità che la variabile assuma un
valore prefissato è sempre nulla:
P(X=x)=0
Si ha così che nel continuo l’espressione “evento di probabilità nulla” non è sinonimo di
“evento impossibile”, come invece si viene sempre ad avere nel discreto; in pratica risulta
significativo unicamente calcolare la probabilità che (X) assuma valori in un intervallo di ampiezza
positiva. Nel continuo la (f) non rappresenta perciò “la probabilità che (X=x), o che si verifichi
esattamente la condizione cercata” ma piuttosto “una densità di probabilità”; ovvero, come prima
detto, è solo il suo integrale, su un intervallo finito, che ha il significato di probabilità di un certo
evento. Le funzioni di distribuzione discrete e continue sono “oggetti matematici” diversi e
non direttamente confrontabili. Ne derivano le modifiche che risulta necessario introdurre
per “simulare” una funzione discreta mediante una continua.
La distribuzione Normale risulta comunque a tal punto fondamentale che si può pensare di
utilizzarla per “simulare” altre funzioni di distribuzione. In questa ottica abbiamo visto per alcune
funzioni (la Binomiale, Poisson e la Esponenziale) come sia possibile valutare () e (); che
rappresenteranno i valori da inserire nella Gaussiana equivalente. Questa operazione non può
ovviamente essere sempre e comunque condotta con successo (sempre nei limiti di quanto prima
visto); la Gaussiana è, infatti, una funzione simmetrica e questa condizione deve essere
46
necessariamente condivisa anche dalle altre funzioni. Per ottenere questo si deve, ad esempio, avere
per la Binomiale che p (probabilità di successo in ogni singola prova) sia uguale a 0.5 (si ha così
una simmetria di comportamento tra i due possibili stati del sistema); più in generale si potrà
utilizzare l’approssimazione Normale per la Binomiale se:
np > 5 e n(1-p) > 5
(2.31)
A questo proposito si ricordi che:
o Se (n) è grande e (p) è piccolo (vicino a zero), si potrà utilizzare l’approssimazione di
Poisson [se (p) è vicino ad uno si potrà utilizzare Poisson per la complementare calcolata per
(1-p)];
o Se (n) è grande e (p) non è né piccolo, né grande, molto facilmente si potranno verificare le
condizioni (2.31) ed utilizzare l’approssimazione Normale.
Per potere utilizzare l’approssimazione Normale anche per Poisson si deve avere che ( =np)
(frequenza dell’evento nell’intervallo unitario) sia maggiore od almeno pari a 10 (come si può
vedere dalla Fig. 2-3 in questo caso si ottiene una curva di distribuzione simmetrica); inoltre il
valore del coefficiente di dispersione vale:
= /= 1/
e quindi con l’aumentare del valore della frequenza dell’evento nell’intervallo unitario si ottiene
una Gaussiana sempre meno dispersa nell’intorno del valor medio.
Per la sua stessa natura, al contrario, la funzione Esponenziale non può mai essere simulata
mediante una Gaussiana.
Fig.2-3 Andamento della funzione di Poisson per diversi valori di
Di Weibull
Rappresenta con successo le situazioni nelle quali l’intensità del verificarsi dell’evento può essere
crescente, decrescente o costante in funzione del valore assunto dalla variabile indipendente. Questa
funzione rappresenta quindi bene il comportamento di un componente durante tutta la sua vita. La
funzione di distribuzione di probabilità permette di valutare la probabilità che l’evento,
caratterizzato dai parametri (, , ), si manifesti allorquando la variabile indipendente assuma il
valore (x) ed ha la seguente espressione:
47
f(x/(, , )= (/) (x-)-1 exp[-(x-)/)]
(2.32)
dove:
: influenza l’ampiezza della curva di distribuzione
: influenza la forma
“
“
“
: influenza la posizione del punto di inizio della curva stessa (se, ad esempio, la variabile
indipendente è il tempo e la f rappresenta la probabilità di guasto si ha che: se 0 vi è un
primo periodo per il quale il componente non è soggetto a guasti, se 0 è presente la
possibilità di trovare un componente guasto ancora prima che cominci la sua vita in opera).
Fig. 2-4 Andamento della funzione di Weibull per diversi valori dei parametri
Generalmente, visto che la variabile indipendente è rappresentata dal tempo, si assume che la curva
inizi per x=0.; il parametro () assume il valore zero da cui:
f(x/,) = (/) x-1 exp[-x/]
(2.33)
La funzione di Weibull si riconduce a quella Esponenziale per =0 e =1, in Fig. 2-4 è riportato
l’andamento della funzione per diversi valori dei parametri; come si vede, al crescere di ()
l’andamento approssima sempre meglio quello della distribuzione normale.
Per esempio riportiamo la funzione di distribuzione della velocità del vento in un generico sito,
che è appunto espressa da una curva di Weibull a due parametri:
p(v) = (k/c)(v/c)k-1 exp[-(v/c)k]
Gli andamenti di questa distribuzione sono riportati in Fig. 2.5 e 2.6 per diversi valori dei parametri
(k:fattore di forma e c:fattore di scala).
48
Fig. 2.5 Andamento della funzione di distribuzione di Weibull per la velocità del vento
49