Politecnico di Torino
CeTeM
Sistemi Informativi Aziendali (9651A)
3
Descrizione dei sistemi informativi
Introduzione
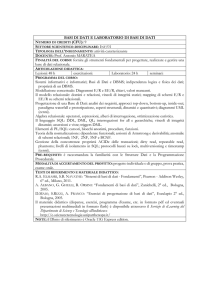
Questo modulo descriverà brevemente le caratteristiche dei sistemi informativi. È il terzo
dei quattro moduli su cui è articolato il corso di Sistemi Informativi Aziendali (9651A).
Fanno parte di questo modulo le lezioni dalla 21 alla 32 comprese.
Per le lezioni 21, 22 e 23 è possibile fare riferimento ai lucidi utilizzati dal Prof. Paolo
Tiberio, disponibili su carta presso il CETEM.
La lezione 24, sull'uso di Access, richiede la visione della videocassetta, essendo
decisamente improntata all'uso pratico del calcolatore.
Per le lezioni dalla 25 alla 30 (comprese) il riferimento è ai lucidi (per lo più coincidenti con
i lucidi presentati nelle videocassette) utilizzati dal Prof. Stefano Ceri, e da lui gentilmente
forniti. Tali lucidi sono disponibili in forma elettronica sul sito del CETEM (insieme a queste
dispense). Il riferimento per le lezioni dalla 25 alla 30 è alle lezioni dalla 9 alla 14 nei lucidi
appena menzionati.
Infine le lezioni 31 e 32 costituiscono una introduzione a Internet e all'uso di Web e Basi di
Dati.
Si ricorda che il libro di riferimento per la teoria è Basi di Dati (da ora BDD) di Atzeni, Ceri,
Paraboschi, Torlone, seconda edizione (1999), McGraw-Hill editore (ISBN 88 386 0824-5).
Memorie permanenti
Un calcolatore adibito all'uso di data server deve disporre di una buona potenza
elaborativa. Questo si traduce in una elevata velocità della CPU, una buona disponibilità di
memoria centrale (anche detta memoria di servizio), e soprattutto in una elevata capacità
e velocità della memoria permanente (dischi).
In particolare lo sviluppo delle prestazioni delle memorie permanenti è importante al fine di
sfruttare appieno l'incremento nelle prestazioni delle CPU (attualmente le prestazioni
generali tendono ad aumentare di circa 1.5 volte ogni anno).
I dischi attualmente in uso hanno velocità di rotazione tra 5400 e 10000 giri al minuto, con
capacità complessive fino a 75 GB (disco EIDE IBM DTLA-307075 UDMA 100 7200
giri/min, ~1.5 milioni di lire nel settembre 2000).
È anche molto importante la tecnologia in uso nei CD riscrivibili e non, che proprio in
queste settimane è giunta ad una velocità di 10x nei CD-RW e a 12x nei CD-R con
tecnologia burn-proof (Plextor 12/10/32A EIDE ~600000 lire), al fine di evitare lo spreco
dei CD-R dovuto a scorrette masterizzazioni.
I dischi nei data server sono sovente organizzati mediante RAID (Redundant Array of
Inexpensive Disks). In particolare sono usati i livelli di RAID 0 (striping, massime
prestazioni), 1 (mirroring, spreco di metà spazio ma sicurezza massima), e 5 (un solo
disco supplementare contenente i bit di parità).
Metodi di accesso
All'interno delle memorie permanenti i dati sono immagazzinati sotto forma di file. Tali file
vengono indirizzati tramite una tabella (directory) che viene consultata dal File System o
dal DBMS, e che contiene le informazioni sui file stessi.
Nel corso delle elaborazioni può essere necessario accedere ai file in modo sequenziale
(ad esempio per fare una ricerca lineare), oppure effettuare altre operazioni quali
l'ordinamento del contenuto. Queste operazioni sono influenzate fortemente dagli
algoritmi adottati.
© Politecnico di Torino
Data ultima revisione 01/06/2017
Pagina 1 di 4
Autore: Bartolomeo Montrucchio
Politecnico di Torino
CeTeM
Sistemi Informativi Aziendali (9651A)
3
Descrizione dei sistemi informativi
Calcolo dei costi di accesso
Durante l'esecuzione delle query SQL l'importanza dell'ordinamento dei dati risulta
fondamentale.
L'uso di ordinamenti e di indici permette di migliorare drasticamente le prestazioni, ma un
eccesso di indicizzazione è nocivo per il DB, a causa dell'elevato numero di modifiche che
devono essere effettuate ad ogni operazione di aggiornamento del database.
L’ordinamento delle relazioni e l’uso di indici permettono poi all’ottimizzatore del DBMS
relazionale di valutare quale sia la migliore strategia di accesso per le interrogazioni SQL
degli utenti.
Un esempio di DBMS: Microsoft Access
Microsoft Access è un database relazionale per PC di medie prestazioni e dotato di una
interfaccia utente molto amichevole.
L’interfaccia utilizzata per l’inserimento delle query è il QBE (Query By Example),
interfaccia per alcuni versi competitiva con SQL e particolarmente adatta all’uso interattivo.
Access permette l’uso sia di SQL sia di QBE, anche se l’interfaccia di default è QBE.
La videocassetta mostra le modalità di creazione di uno schema e l’uso di SQL e QBE.
Si noti come alcune query non siano realizzabili con l’uso del solo QBE. In particolare l’uso
di UNION può essere impossibile.
Sistemi transazionali e controllo di concorrenza
Una transazione è una unità di elaborazione che gode di quattro proprietà (da cui
l’acronimo ACID).
1. Atomicità; la transazione è una trasformazione atomica dallo stato iniziale a quello
finale.
2. Consistenza; se lo stato iniziale è corretto allora anche lo stato finale è corretto.
3. Isolamento; la transazione non risente degli effetti delle altre transazioni concorrenti.
4. Durata (persistenza); gli effetti di un “commit work” (cioè transazione completata con
successo) durano per un tempo illimitato.
Le transazioni possono essere svolte serialmente, cioè iniziando la transazione due solo
dopo aver completato la transazione uno, oppure in modo concorrente (transazione uno e
due svolte in contemporanea). Qualora le transazioni vengano svolte in modo concorrente
è necessario garantire l’assenza di conflitti mediante le primitive di lock, da utilizzare prima
di leggere (lock in lettura) o scrivere (lock in scrittura).
Tecnologia dei sistemi informativi
L’architettura client-server prevede che il CLIENT si limiti a presentare l’informazione,
mentre il SERVER gestisce i dati. La rete (LAN, MAN, WAN) trasferisce i dati (ad esempio
i comandi SQL dal client al server).
La base dati può essere replicata, oppure distribuita (su più macchine), oppure parallela
(mediante l’uso di macchine multiprocessore).
Oltre all’ ”ambiente operativo” (usato per modificare i dati in linea) può essere presente l’
“ambiente di analisi”, utilizzato per analizzare i dati a fini statistici (DATA WAREHOUSE)
fuori linea.
© Politecnico di Torino
Data ultima revisione 01/06/2017
Pagina 2 di 4
Autore: Bartolomeo Montrucchio
Politecnico di Torino
CeTeM
Sistemi Informativi Aziendali (9651A)
3
Descrizione dei sistemi informativi
Esistono anche sistemi cosiddetti LEGACY (cioè ereditati), basati perlopiù su mainframe
(con terminali collegati); essi sono normalmente obsoleti, ma spesso preziosi.
Controllo di affidabilità
L’affidabilità delle basi di dati è data dalle proprietà ACID. In particolare per garantire la
memoria stabile (astrazione per indicare una memoria incorruttibile) si usano vari sistemi
di backup tra cui il mirroring dei dischi e la replicazione tramite unità a nastro.
Il giornale di transazione (registrato in memoria stabile) registra le azioni svolte dalla
transazione sotto forma di transizioni di stato. Tramite il giornale si può effettuare il rollback di una transazione (annullare l’effetto di una transazione non completata) oppure
riparare l’effetto di un guasto dopo un commit.
Basi di dati distribuite
La distribuzione dei dati, cioè la possibilità di distribuire i dati su vari elaboratori collegati in
rete locale e non (eventualmente ogni elaboratore può anche utilizzare un database
differente dagli altri), è dovuta a vari fattori:
la natura intrinsecamente distribuita delle organizzazioni;
l'evoluzione degli elaboratori, con conseguente aumento delle capacità di calcolo e
riduzione dei prezzi;
l'evoluzione dei DBMS;
la creazione di standard di interoperabilità.
La distribuzione (su LAN o WAN) di una base di dati comporta però anche problemi:
difficoltà nel gestire l'autonomia dei vari agenti, assicurando nel contempo la massima
cooperazione;
necessità di gestire la trasparenza della distribuzione dei dati;
problemi di efficienza nelle transazioni;
esigenza di assoluta affidabilità (garantita dal protocollo di commit a due fasi).
Architetture evolute dei sistemi informativi
In questa sezione vengono descritte le basi di dati parallele, le basi di dati replicate e il
data warehouse.
Le basi di dati parallele permettono di utilizzare numerosi processori, cooperanti in
un'unica architettura informatica, al fine di aumentare le prestazioni. Questo sia nel caso di
carico transazionale (molte transazioni brevi, tipico della produzione), sia nel caso di
analisi dei dati (poche transazioni molto complesse, magari effettuate off-line su copie del
database, addirittura suddividendo la transazione sui vari processori).
Le basi di dati replicate sono invece utilizzate al fine di aumentare efficienza, affidabilità e
autonomia delle basi di dati. La base di dati principale viene cioè duplicata, eventualmente
in tempi variabili. Un tipico esempio può essere il catalogo a disposizione degli agenti di
vendita mobili, situato su di un computer portatile e per forza di cose sconnesso dalla rete
per tempi variabili.
Il data warehouse è invece un ambiente per l'analisi dei dati. Mentre infatti la gestione dei
dati "in linea" (On Line Transaction Processing, OLTP) viene effettuata dal DBMS,
l'elaborazione e l'analisi dei dati (pur essendo comunque effettuabili tramite il DMBS
utilizzando SQL), vengono meglio gestite mediante un opportuno server OLAP (On Line
© Politecnico di Torino
Data ultima revisione 01/06/2017
Pagina 3 di 4
Autore: Bartolomeo Montrucchio
Politecnico di Torino
CeTeM
Sistemi Informativi Aziendali (9651A)
3
Descrizione dei sistemi informativi
Analytical Processing) (p. 481 BDD). Questo server è il data warehouse, che svolge per
OLAP il ruolo che il DBMS svolge per OLTP. I dati per l'ambiente OLAP vengono peraltro
sempre forniti dal sistema OLTP.
Modelli e linguaggi per l'analisi dei dati
Come già detto le limitazioni dell'OLTP sono legate alla difficoltà d'uso e alla rigidità che,
pur permettendo un buon utilizzo operativo, rendono difficile un uso strategico (decisioni di
marketing o altro). La risposta a tutto ciò è l'OLAP. È in tal modo possibile il data mining
(letteralmente scavare nella miniera dei dati), il cui obiettivo è estrarre informazione
nascosta nei dati al fine di consentire decisioni strategiche. Un semplice esempio di data
mining riguarda i prodotti acquistati insieme o in sequenza (sorprendentemente un caso è
quello dei pannolini e della birra).
Introduzione a Internet e Web e basi di dati
Le due ultime lezioni del terzo modulo riguardano un'introduzione a Internet, con una
breve storia di Internet (nata, come noto ai più, per scopi militari) e una carrellata sui
protocolli più usati.
La seconda lezione di Piero Fraternali riguarda poi la connessione tra le basi di dati e il
Web, quindi l'uso di HTTP, HTML, CGI e altro.
Si raccomanda perciò la visione della cassetta contenente le due lezioni.
© Politecnico di Torino
Data ultima revisione 01/06/2017
Pagina 4 di 4
Autore: Bartolomeo Montrucchio