Trovare relazioni fra dati in Excel
tramite il test di correlazione di Pearson accoppiato al test t di Student
Prof. Lorenzo Marafatto
Esistono vari possibili metodi per cercare eventuali relazioni fra dati, che dipendono dalle
caratteristiche del campione (numerosità, normalità, ecc.).
In questo esempio viene analizzato un metodo molto semplice, che non vale in generale, ma in
molti casi è utile. In particolare è molto affidabile se i dati si avvicinano “sufficientemente” ad una
distribuzione normale. È chiaro che il termine “sufficientemente” non ha un significato rigoroso, e
per verificare con correttezza statistica la normalità di un campione di dati dovrebbero essere
utilizzati indici specifici, come il valore di curtosi e asimmetria. Per i nostri scopi è comunque
sufficiente anche riportare preliminarmente i dati del campione in un grafico di frequenza, e
limitarsi da verificare se graficamente la curva ottenuta si “avvicina” a quella della distribuzione
normale.
Il metodo per cercare una relazione fra dati preso in esame prevede in particolare di cercare se esista
una relazione lineare fra due colonne (ovvero fra due intervalli di celle anche di tipo “matrice”) di
valori numerici. Esiste una relazione lineare se, al variare dei dati di una delle due colonne, i dati
dell’altra variano in modo lineare (cioè si trova una legge che lega una variabile all’altra, ovvero
una colonna all’altra, che ha il comportamento di una retta). È chiaro che se vi è questo
collegamento fra le due variazioni vi è una relazione fra i dati.
Il test statistico necessario per effettuare la ricerca di questa correlazione lineare è il test di
correlazione di Pearson, accoppiato al test t di Student.
Il primo test, la correlazione di Pearson, calcola il valore del coefficiente di correlazione lineare,
denominato r. Il valore di r è un numero tra -1 e 1. Tanto più il valore del coefficiente di
correlazione si avvicina agli estremi (1 o -1), tanto più la correlazione è presente, in modo positivo
se vicino a 1 (quando il valore di una delle colonne o variabili aumenta, aumenta anche quello
dell’altra), negativo se vicino a -1 (quando il valore di una delle colonne o variabili aumenta,
diminuisce quello dell’altra). Il valore 0 di correlazione indica l’assenza di correlazione lineare, ma,
si noti bene, potrebbe essere presente un altro tipo di correlazione, non lineare (ad esempio
quadratica o altro), che questo test semplicemente non può rilevare!
Il secondo test, il test t di Student, serve a fornire la probabilità che la nostra eventuale relazione,
che crediamo di aver trovato grazie al valore “alto” di correlazione, sia invece dovuta solo al caso,
alla variabilità biologica: ci fornisce quindi la probabilità dell’ipotesi H0, che, come al solito,
significa “ciò che è misurato dipende solo dal caso”. Nell’ambito biomedico, come sempre, sono
interessanti probabilità di H0 che siano < 0,05 (5%) oppure < 0,01 (1%).
Vediamo in dettaglio la proceduta da seguire con Excel per effettuare questo test che rilevi una
eventuale correlazione lineare:
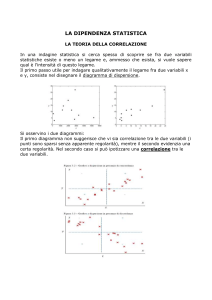
Consideriamo il seguente esempio di foglio elettronico:
Le due colonne, intestate x e y, contengono due ipotetici valori di qualche variabile, e quello che
intendiamo verificare è se esse siano in relazione oppure no.
In una cella del foglio Excel utilizziamo la funzione di Excel denominata “correlazione”, che ha
come parametri proprio le nostre due colonne (o gli eventuali intervallo di celle su più colonne se il
caso).
Poniamo nella cella B13 la funzione: = CORRELAZIONE(a2:a11;b2:b11).
Otteniamo questo risultato:
Notiamo che, qualitativamente, si hanno questi “range” per i valori di correlazione di Pearson r:
0 < r < 0,3 correlazione debole
0,3 < r < 0,7 correlazione moderata;
r > 0,7 correlazione forte.
L’analisi qualitativa ci dà una correlazione moderata, ma è troppo grossolana. Nell’ambito
scientifico non è sufficiente accontentarsi di dire “esiste una moderata correlazione fra x e y”, anche
perché il termine “moderato” non è affatto oggettivo. Dobbiamo quindi accoppiare, come già detto,
al test di correlazione un altro test, che dia la probabilità oggettiva dell’ipotesi che i risultati ottenuti
siano semplicemente dovuti al caso. Il test scelto è il test t di Student, che si adatta bene a questa
verifica.
Per effettuare il test t sugli stessi dati basta inserire la funzione di Excel test.t, che richiede 4
parametri:
i primi due, come prima, sono le colonne (o gli intervalli) su cui effettuare la verifica;
il terzo parametro è il numero di code (1 oppure 2) e inseriamo il valore 2 se “non sappiamo” in che
modo le due colonne o variabili sono collegate, in particolare non sappiamo se le medie dei valori
sono uguali o meno, oppure il valore 1 se “sappiamo” che certamente una delle due variabili o
colonne sarà “maggiore” dell’altra, ovvero avrà una media maggiore dell’altra;
il quarto parametro è un valore tra 3 possibili: 1 se i dati sono accoppiati, ad esempio se sono la
stessa popolazione “prima e dopo una certa cura”, 2 se non sono accoppiati ma la loro varianza
(indice di variabilità, distanza dalla media) è la stessa, 3 se non sono accoppiati e nemmeno la loro
varianza è uguale.
Nel nostro caso inseriremo, nella cella b14, la formula = =TEST.T(A2:A11;B2:B11;1;1)
Otterremo la tabella seguente:
L’interpretazione del risultato è quindi la seguente: le due colonne (variabili) sono correlate
secondo Pearson apparentemente in modo moderato, ma in realtà la probabilità che ciò sia dovuto al
caso (indicata negli articoli scientifici con P) è molto alta (0,306394, cioè 30%), e non accettabile
per gli standard dell’ambito biomedico, per i quali il minimo è 0,05 (5%).
Un’ultima annotazione importante sull’interpretazione del valore di P del test t: se il risultato fosse
più interessante, ad esempio test.t fornisse P = 0,03, cioè probabilità che sia un caso pari a 3%, la
nostra relazione sarebbe significativa, ma non si pensi che sia significativa al 97%! Noi possiamo
solo affermare che il caso “influisce” solo per il 3%, non che la certezza sia l’opposto, cioè 97%.