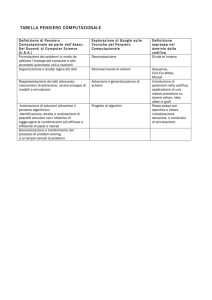
È una branca della linguistica che nasce nella meta del 900, dalla contaminazione tra la linguistica e
l’informatica.
Da un lato il linguista utilizza gli ausili informatici e dall’altro l’informatico si serve della
linguistica per migliorare aspetti informatici. Anche altre discipline umanistiche si sono servite
dell’informatica.
RELAZIONE TRA L’INFORMATICA E LE SCIENZE UMANE
La relazione tra l’informatica e le scienze umane nasce da un progetto di indicizzazione dei testi da
parte di Padre Roberto Busa S.J. nel 1949: egli fa un indice dei testi di S.Tommaso d’Aquino sul
computer, il cosidetto Index Thomisticus: indice di testi umanistici
A una pratica antica si unisce una nuova tecnologia. L’evoluzione delle caratteristiche e delle
potenzialità del computer è parallela allo sviluppo del progetto.
1949-1980 i primi calcolatori avevano delle schede perforate, poi si passa al nastro magnetico e
infine ai CD-Rom.
SCOPO DELL’INDEX THOMISTICUS: facilitare la consultazione di dati linguistici, lessicali e
dei testi di S.Tommaso ( concordanze di 150.000 parole danno origine a 10 milioni di occorrenze, le
concordanze nei testi si possono fare a livello fonetico, lessicale, sintattico e semantico)
L’Index è il risultato dell’elaborazione computazionale dei testi di S.Tommaso
SCENA ITALIANA: Antonio Zampolli che nel 1960 collabora alla realizzazione degli spogli
elettronici degli scritti di S.Tommaso
1980 –fonda l’istituto di Linguistica che oggi fa parte del CNR di Pisa
INFORMATICA UMANISTICA
Nasce dall’intersezione dell’informatica con storia, filosofia, linguistica, informatica, critica
letteraria, biblioteconomia. Il rapporto tra l’informatica e le scienze umane si realizza in punti
comuni ai due settori, come:
Manipolazione di simboli
Programmazione
Trattamento digitale della conoscenza
COME L’INFORMATICA SI AVVICINA ALLO STUDIO DELLA LINGUA?
Durante la seconda guerra mondiale: necessità di decodificare messaggi criptati. Questa pratica è
probabilmente più antica dell’indicizzazione.
Creazione dell’antenato del computer nel Regno Unito
Alan Turing nel Regno Unito è un personaggio fondamentale nella storia dell’informatica e
dell’intelligenza artificiale.Le sue teorie erano già vive nel 1500, teorie che collegavano le
macchine alle lingue.
Turing riconobbe il legame tra l’informatica e le scienze umanistiche, tra il linguaggio naturale e
quello artificiale. Sia l’informatica che la linguistica hanno in comune la manipolazione di simboli,
logico-numerici e linguistici.
Attività che secondo Turing potevano essere oggetto del calcolatore:
Matematica
Apprendimento delle lingue da parte del computer
Traduzione delle lingue
La criptoanalisi
I giochi( scacchi, poker..)
Il modello dell’informazione di Shannon e Weaver nasce proprio dall’applicazione
dell’informatica , escludendo l’elemento umano.
Nel corso del tempo, i due settori si sono sviluppati singolarmente e interagendo tra loro.
L’informatica umanistica punterà le sue ricerche sulla traduzione automatica
DISCIPLINE VICINE ALL’INFORMATICA:
SCIENZE LETTERARIE
STORIA
LINGUISTICA
FILOSOFIA
ARCHEOLOGIA
SCIENZE DELLA COMUNICAZIONE
Si tratta di una comunità transdisciplinare denominata informatica umanistica o informatica per le
discipline umanistiche
Humanities Computing/
Computing for Humanities
L’informatica umanistica ha un nucleo teorico, metodologico e strumentale che prevede la
rappresentazione digitale dei documenti e la codifica testuale, e un nucleo epistemologico,
che prevede l’uso di strumenti informatici per lo studio del testo, letterario ad esempio.
SCOPO: rendere più veloce ed efficace l’analisi dei dati, il reperimento e la classificazione
dei dati( DATABASE), migliorare e ridefinire le prospettive interpretative, le implicazioni
cognitive
Il lavoro dell’uomo è velocizzato
Il database da azione semi-automatica ( l’uomo f ail database)diventa automatico ( è il
computer che estrae dati da un testo e elabora un database).
Lo strumento influenza una nuova impostazione cognitiva
APPLICAZIONI INFORMATICHE PER L’INFORMATICA UMANISTICA:
INDICIZZAZIONE
CONCORDANZE
LISTE DI FREQUENZA( DI OCCORRENZA, DI RIPETIZIONE DELLE PAROLE NEL
TESTO)
CODIFICA TESTUALE ( DA UN SUPPORTO A UN ALTRO CON L’ESPLICITAZIONE
DELLE INFORMAZIONI LINGUISTICHE)
IMPLEMENTAZIONE DI IPERTESTI SUL WEB
AUTOMATIZZAZIONE DELLE PRATICHE ECDOTICHE (ECDOTICA: insieme di
studi per l’edizione critica di un testo)
AMBITI DI UTILIZZO DELL’INFORMATICA
linguistica
1. filologia
1.1. manoscritti codificati su supporto elettronico. Analisi critica e ecdotica
1.2. informatica testuale
1.3. informatica documentale: banche dati e sistemi di interrogazione
2. storia
2.1. banche dati
3. filosofia
4. archeologia
4.1. codicologia
4.2. papirologia
4.3. storia dell’arte
5. letteratura
5.1. analisi lessicali e grammaticali
5.2. stile e metrica
5.3. attribuzione d’autore
5.4. sistemi di information retrieval
6. arte
6.1. analisi numerica dei colori
7. musica
8. didattica
9. biblioteconomia
9.1. ricerche bibliografiche in rete
9.2. cataloghi digitali dispongono di interfacce utene adeguate( user friendly) nel rispetto di
standard diffusi e conosciuti
9.3. filtri di interrogazione
9.4. internet in biblioteca
DIGITALIZZAZIONE: opera lunga e costosa
Prima scannerizzazione del testo, poi si arriva a rendere disponibile il formato testo
LINGUISTICA COMPUTAZIONALE
Questioni legate ai formalismi del linguaggio
Tecniche di analisi e generazione automatica del linguaggio
Ricadute nella progettazione di linguaggi di programmazione informatica
Supera l’approccio tradizionale dell’informatica al testo: limitato al trattamento di stringhe di
caratteri all’interno delle quali individuare particolari pattern
COSA FA LA LINGUISTICA COMPUTAZIONALE?
Elabora modelli che permettano un trattamento del testo più raffinato, consentendo di
individuare, in modo automatico o semi-automatico le relazioni linguistiche presenti
nel testo
Elabora modelli di interpretazione del testo/dei segni linguistici
Campi di attività:
Lemmatizzazione delle forme (es. ricondurre una forma verbale flessa all’infinito del
verbo; lemma: forma di base non marcata) N.B : Le forme polisemiche hanno due
lemmi)
Individua le strutture sintattiche
Attribuisce tratti semantici pertinenti (“sentire”e “udire” sono tratti di percezione
acustica, sinonimi non totali accumunati)
Individua le espressioni relative allo stesso referente ( Roma e la capitale in un
contesto: la capitale d’Italia)
CODIFICA DI UN TESTO : rendere esplicite le informazioni linguistiche con
lemmatizzazione, individuazione di strutture sintattiche.....
ALCUNI PRODOTTI: correttori
Sistemi di riconoscimento vocale
Programmi di redazione di riassunti
14/10/2008
LINGUISTICA COMPUTAZIONALE : disciplina autonoma che si avvale di strumenti
informatici per l’elaborazione del linguaggio umano
Implica l’approfondimento di conoscenze e tecniche per applicare l’informatica al
linguaggio naturale
Ha fondamenti epistemologici e metodologici propri, costituisce una branca della linguistica
E’ una disciplina che lavora con le lingue storico-naturali e la lingua artificiale/formalizzata
OGGETTO DI STUDIO: LE LINGUE NATURALI
TESTI: dalle unità più piccole alla lingua, i testi sia orali che scritti
SCOPO: fornire modelli computazionali dei diversi fenomeni linguistici: modelli che
possono essere rappresentati in programmi che permettono al computer di comunicare in
una lingua naturale
Ci sono due filoni della linguistica computazionale: mettere a disposizione dei programmi
per fare delle ricerche linguistiche, cioè utilizzare la lingua artificiale per ricondurre la
lingua naturale a un modello formalizzato e dei schemi( in questo campo ci sono persone
che sanno poco di informatica); il secondo filone è l’immagazzzinamento di dati linguistici
per fare dei programmi
FILONE TEORICO LINGUISTICO, volto all’analisi linguistica
FILONE APPLICATIVO, volto a creare programmi di utilità generale servendosi delle applicazioni
linguistiche
2 PARADIGMI DI RICERCA DA CUI NASCE LA LINGUISTICA COMPUTAZIONALE
METODI STATISTICI/MATEMATICI E APPLICAZIONI INFORMATICHE AI
TESTI LETTERARI (Padre Busa e A.Zampolli) dal concetto della LINGUA VIVA
: prodotto storico realizzato nei testi letterari
INTELLIGENZA ARTIFICIALE/ARTIFICIAL INTELLIGENCE (AI): dal concetto
della lingua in vitro : modello decontestualizzato dagli usi effettivi per osservare la
competenza linguistica e gli utilizzi che se ne possono fare.
PARADIGMI LINGUISTICI E INFORMATICI
Teoria dell’informazione di P.Shannon e W. Weaver: le basi per la traduzione automatica
Teoria generativa di Chomsky e i linguaggi formali
Statistica linguistica
AI
MODELLO DI SHANNON E WEAVER
Fine degli anni 40
Libro “Mathematical theory of Communication”
COMUNICAZIONE: passaggio di dati da una sorgente( fonte) a una destinazione attraverso un
elemento codificatore, un canale, un elemento decodificatore (più rumore); il segnale è variazione
di stato fisico
Sorgente
Elemento codificatore ( istanza cognitiva del parlante per Jakobson)
Messaggio
Canale
Elemento decodificatore ( istanza cognitiva del ricevente)
Sistema ricevente
Rumore
Teoria importante per le applicazioni informatiche
Rilievo della componente statistico-probabilistica
Le proprietà statistiche dei testi (probabilità di occorrenza degli eventi) sono importanti per
garantire il successo della comunicazione.
CHOMSKY
La TEORIA GENERATIVA di Cnomsky si avvicinerà all’intelligenza artificiale.
Si Occupa di ricerca sul linguaggio: 1957 “Syntactic structures”: la completa formalizzazione della
lingua in regole per dedurre l’insieme delle frasi ben formate nella lingua. E’ una teoria linguistica
integrata poi dalla natural language processing (NLP) nella linguistica computazionale.
CHOMSKY distingue tra competenza linguistica del parlante ed esecuzione: per lui l’esecuzione
non attualizza tutte le regole della lingua, per cui solo la competenza è formalizzabile in una serie di
regole. Egli fa una critica all’analisi dei testi
Alla fine degli anni 80 si affermano i metodi statistico-quantitativi per l’analisi computazionale del
linguaggio e si delinea la centralità del dato testuale.
LA LINGUISTICA DEI CORPORA: disciplina che privilegia lo studio dei testi come “occorrenze
comunicative (Dressler e Beaugrande). La produzioni linguistiche (atti linguistici effettivamente
prodotti) sono gli unici dati a disposizione, da cui deduco il funzionamento del linguaggio.
La linguistica dei corpora si diffonde a partire dagli anni 30 con Leonard Bloomfield che è legato
alla scuola dello strutturalismo europeo di De Saussure, studioso a cui non interessano le
componenti sociali della lingua ma solo la sua struttura. Negli anni 50 Chomsky rivolge molte
critiche alla linguistica dei corpora; in America invece si diffonde l’idea che è meglio vedere come
si studia la lingua nelle varie culture. Alla fine Chomsky tornerà alla struttura e alla competenza
linguistica.
CHOMSKY : POSIZIONE MENTALISTA : conoscenza inconscia e intuitiva delle regole della
propria lingua;i corpora sono frammenti parziali e incompleti del linguaggio, mentre la conoscenza
umana di esso è infinita. La distribuzione dei tratti linguistici nei corpora è condizionata da vincoli
d’uso. I nodi problematici : è finito, è incompleto, è imperfetto ( fattori accidentali), non consente
predizioni sulla grammaticalità delle frasi. Dà solo indicazioni sulla frequenza di manifestazione
delle caratteristiche linguistiche.
LINGUISTICA DEI CORPORA: POSIZIONE COMPORTAMENTISTICA: a lui importa
l’esecuzione, la performance, i testi
TRATTAMENTO AUTOMATICO DELLA LINGUA/I LINGUAGGI FORMALI /NLP
E’ L’ELABORAZIONE DEL LINGUAGGIO UMANO SULLA BASE DELLA TEORIA DI
CHOMSKY. Prevede l’implementazione di regole generali che rendano un programma in grado di
produrre frasi ben formate della lingua. La NLP è legata alle teorie:
1) Degli automi
2) Intelligenza artificiale
3) Teoria dei linguaggi formali
Sviluppo applicativo : PARSING: ANALISI SINTATTICA AUTOMATICA
LA STATISTICA LINGUISTICA
Studia le caratteristiche quantitative dei codici linguistici. I calcolatori facilitano lo spoglio e
l’analisi. Si ottengono formalizzazioni di carattere logico o analisi quantitative delle occorrenze
testuali. Le regolarità statistiche si riconducono a caratteristiche dell’essere umano come il principio
dell’economia. Normalmente un numero piccolo di parole copre la maggior parte del testo
STUDI FONOLOGICI
STUDI STATISTICI SUL LESSICO es: lunghezza delle parole: le parole più lunghe hanno meno
occorrenze nei testi; numero delle parole differenti : aumenta col diminuire della frequenza di
occorrenza, della varietà e brevità delle parole; le parole più frequenti sono semanticamente più
generiche ( frequenza della parola cosa; automobile si usa poco)
Applicazioni in dizionari fondamentali e di frequenza, e nella didattica delle lingue, word books
nella prima metà del 900. Poi anche Lessici di frequenza, cioè lo studio delle frequenze e delle
concordanze delle parole in testi letterari e religiosi. I lessici di frequenza coniugano diversi aspetti
della linguistica computazionale, come la linguistica dei corpora, le analisi statistiche, le analisi
terminologiche, la lessicografia. 1971 “Lessico di frequenza della lingua italiana contemporanea”
1993 “Lessico di frequenza dell’italiano parlato”
Vocabolario di base : - vocabolario di base fondamentale : 94/95% delle parole dei testi più
semplici
-
Vocabolario di base di alto uso o di alta frequenza: 6/8% dei testi
-
Vocabolario di base di alta disponibilità o familiarità: poco usati nei testi
legati alla vita quotidiana
STATISTICA LINGUISTICA : STUDIA L’ESECUZIONE
L’INTELLIGENZA ARTIFICIALE: STUDIA LA COMPETENZA
INTELLIGENZA ARTIFICIALE
TRADUZIONE AUTOMATICA
SISTEMI DI DIALOGO UOMO-MACCHINA
In essa si sviluppa la NLP ( TRATTAMENTO AUTOMATICO DELLA LINGUA)
PARSING E INTERPRETAZIONE SEMANTICA
LINGUISTICA COMPUTAZIONALE
Oggi è metodologicamente autonoma, ha raggiunto un equilibrio tra testo e computer, rappresenta
una risorsa di conoscenza da gestire con tecniche, metodi dell’attuale tecnologia dell’informazione.
L’unione tra studi linguistici e informatica ha reso possibile l’integrazione dell’informazione
(attraverso ad esempio l’analisi multimediale dei dati), la disponibilità delle tecnologie e
l’accessibilità e l’interrogabilità dei dati linguistici.
APPLICAZIONI DEI SPECIALISTI: tutto ciò che è implicito per l’uomo deve essere specificato
alla macchina
LINGUISTICA DEI CORPORA disciplina che privilegia lo studio dei testi come “occorrenze
comunicative (Dressler e Beaugrande), servendosi di strumenti di analisi automatica o
semiautomatica dei testi
CORPORA: fonte di informazioni privilegiata in ogni fase di sviluppo e valutazione degli strumenti
per il trattamento automatico dei dati
Si occupa di lessico, sintassi, semantica, strutture morfologiche, collocazioni, catena fonica
APPLICAZIONI:
spoglio elettronico dei testi
calcolo frequenza parole e indicatori statistici ( lo scopo del calcolo della frequenza è capire la
leggibilità del testo e la difficoltà nella comprensione)
compilazione di indici e concordanze di opere letterarie
interrogazione di un data-base in linguaggio naturale
comunicazione dei risultati di una ricerca in linguaggio naturale
programmazione: istruzione del computer
correttori ortografici (spell-checkers) e sintattici
dizionari elettronici e repertori lessicali elettronici
thesauri: programmi di elaborazione elettronica dei testi
traduttori
text to speech : lettura di un testo scritto con voce naturale
riconoscitori vocali/ dettatura
interfacce speciali per persone con disabilità: lettori per ciechi
LC E BASI DEGLI SVILUPPI
1) Trasformare i dati in informazione linguistica
2) Codifica esplicita dei dati testuali
3) Forma standard di rappresentazione dei dati
4) Annotazione esplicita del contenuto linguistico e metalinguistico dei dati
LINGUAGGI STANDARD (XML)
Con la descrizione esplicita del contenuto e della struttura permettono la collocazione online e
l’interazione con gli strumenti di analisi linguistica.
LA CODIFICA
-disponibilità di un documento
-SCELTA DEI DATI DA RENDERE ESPLICITI, i dati pertinenti: se voglio fare un’analisi
lessicale, i corpora di cui farò la codifica non conterranno i dati morfologici codificati, espliciti; se
voglio fare un’analisi morfologica, seleziono solo i dati morfologici da codificare
-TRASPOSIZIONE DEI DATI IN MACHINE READABLE FORM (MRF), cioè IN FORMATO
ELETTRONICO ( se facciamo lo scanner dobbiamo disporre di un sistema di riconoscimento dei
caratteri): decodifica
-CODIFICA: è l’interpretazione del testo, cioè con essa i caratteri vengono associati a dei punti di
codice, cioè una interlingua per dialogare con il computer e ai punti di codice corrispondono i
caratteri in codice binario. Il punto di codice può essere ASCII STANDARD, ASCII ESTESO, O
UNICODE , la cui versione 5.0 rappresenta 100.000 caratteri . Il codice è un valore di
rappresentazione della realtà
-si ottiene un nuovo testo
CODIFICA DI ALTO LIVELLO: I DATI SEMPLICI DIVENTANO DATI STRUTTURATI
E’ la codifica delle strutture macrotestuali ( del testo e del contesto: autore, data di produzione,
finalità), formato del documento e delle strutture linguistiche
La codifica dell’informazione linguistica è chiamata annotazione.
-selezionare il tipo di informazione
-definire il repertorio di tratti rilevanti per la codifica
- definire le regole di compatibilità tra le categorie ( esempio l’aggettivo possiede attributi di genere
e numero, cioè gli attributi specifici per ogni valore)
-definire i criteri di applicazione al testo
COSA CODIFICO?
STRUTTURA : partizione del testo, contesto di produzione e il tipo di testo e l’argomento se è in
un corpus
FORMATO: grassetti, corsivi, sottolineati, caratteri speciali, note e annotazioni, glosse marginali,
indentazioni
CONTENUTO
Alcuni dati possono avere sia la codifica linguistica che quella strutturale
DIFFERENZA TRA TESTO E DOCUMENTO
TESTO: rappresentazione astratta della fonte (modello); è un insieme di segni grafici dove non ci
sono dati relativi al contenuto. Comprende le partizioni logiche interne, i blocchi strutturali e gli
elementi meta testuali e paratestuali
DOCUMENTO: è il prodotto dell’applicazione del testo disponibile al computer. Comprende la
distribuzione e la tipologia.
DOCUMENTI DIGITALI: sono legati alla disponibilità hardware e software
Elevata obsolescenza
Difficile portabilità
Proliferazione dei sistemi di codifica
Difficile condivisione dei dati e dei risultati
Deve essere un dispositivo comunicativo che può essere fruito dal maggior numero di individui,
senza limitazioni di spazio e di tempo. La portabilità implica l’indipendenza dall’hardware, dal
software, dai processi e contesti applicativi
DALLA TIPOLOGIA DELLA CODIFICA NASCONO VARI FORMATI
1) FORMATO SOLO TESTO (plain text o txt): c’è un file solo testo e editor di testo in grado
di leggere file solo testo. Essi sono Blocco Note o Text Pad.
Hanno un formato aperto, indipendente dal sistema operativo, quindi garantiscono la massima
portabilità ma la minima espressività
2) FORMATI PROPRIETARI( DOC, PDF) Word Processor, Desktop Publishing e
Presentazioni: solo lo specifico programma proprietario dell’azienda può leggere questo file.
Sono obsoleti, minima portabilità e interscambiabilità ma massima espressività e fruibilità
per l’utente umano. La codifica è per modalità di visualizzazione ma non per categorie
testuali astratte ( cioè codifico il rientro a capo ma il programma non sa che è un paragrafo);
la codifica di alto livello è solo linguistica. I formati di text processing sono sistemi di tipo
WYS/WYG (What you see what you get) e legano l’elaborazione del testo ad un
determinato programma. I programmi sono presentazionali, la codifica è invisibile
all’utente, i documenti sono difficilmente gestibili, hanno formati proprietari.
3) Sistemi basati su MARK-UP LANGUAGE o LINGUAGGI DI MARCATURA: è UN
LINGUAGGIO DI CODIFICA TESTUALE DI UNO O Più LIVELLI STRUTTURALI
DEL DOCUMENTO TESTUALE, BASATI SU UN INSIEME DI ISTRUZIONI, DETTE
TAG O MARK-UP. E’ UN LINGUAGGIO ORIENTATO ALLA DESCRIZIONE DI
FENOMENI DI STRUTTURAZIONE E ORGANIZZAZIONE.
C’è UNA GRAMMATICA O DETTA SINTASSI CHE REGOLA L’USO DEL MARK-UP
C’è UNA SEMANTICA CHE DEFINISCE IL DOMINIO DI APPLICAZIONE E LA
FUNZIONE DEL MARK-UP.Il mark-up è inserito direttamente nel testo. Ogni istruzione è
una sequenza di caratteri preceduta e seguita da caratteri speciali che permettono
all’elaboratore di distinguere il testo dal mark-up. Le istruzioni, distribuite secondo una
precisa sintassi, sono collocate accanto alla sequenza di caratteri a cui si riferiscono
I LINGUAGGI DI MARK-UP POSSONO ESSERE PROCEDURALI/ SPECIFICI
OPPURE DESCRITTIVI/ GENERICI/ ANALITICI
LINGUAGGI DESCRITTIVI :
orientati sul testo
i simboli di codifica non vengono più impiegati come strumenti di formattazione o
impaginazione, ma come indicatori della struttura testuale
consentono di dichiarare a quale tipo di struttura appartiene una qualsivoglia porzione della
fonte testuale e per questo vengono definiti linguaggi dichiarativi
Sono costituiti da un insieme di marcatori (tag) che immessi nel testo indicano la funzione (titolo,
nota, citazione, paragrafo) assolta dal blocco di testo a cui si riferiscono. Il mark-up descrive la
struttura di un documento testuale. La semantica predica l’appartenenza di una porzione di testo a
una classe di elementi. Questi linguaggi codificano la struttura editoriale, costituita da componenti
organizzati in modo gerarchico:
-frontespizio, introduzione, corpo, appendice, capitoli, sottocapitoli, atti, scene, titoli, epigrafi,
abstract, paragrafi, versi, battute, entrate di dizionario, enfasi,citazioni
VANTAGGI:
portabilità, interscambiabilità
massimo grado di espressività
è possibile esprimere tutti i livelli della codifica di alto livello, anche l’informazione
linguistica. Si possono marcare anche aspetti grafici della pagina (spazi bianchi, rientri,
salti-pagina) per ottenere uno specifico output del documento.
Indipendenza dalla formattazione: per avere una diversa visualizzazione del documento non
devo cambiare la codifica del testo, bisogna solo modificare dei parametri esterni e non devo
intervenire su ogni carattere come per gli altri tipi di codifica. Si pensi al lavoro laborioso di
un corpus..
facilità nella creazione
flessibilità: riusare un testo codificato in un nuovo contesto; lo posso reinserire in un altro
tipo di testo senza togliere i modificatori, o posso aggiungere alla vecchia marcatura la
nuova marcatura, o posso rendere inattive le marcature precedenti. Lasciando il testo
inalterato posso chiedere di visualizzarlo diversamente.
Visione di documenti dinamicamente riconfigurabili
Marcatura descrittiva: basata sulla funzione
Ad ogni elemento viene descritto il ruolo all’interno del testo, più che le regole per la sua
visualizzazione.
Essa è indipendente dal sistema.
E’ contestuale: le regole definiscono l’assegnazione di un ruolo all’interno di un contesto
È possibile specificare regole di correttezza sul documento ad esempio che ad una immagine
segua sempre una didascalia o ogni capitolo abbia un titolo (XML)
Marcatura procedurale: basata sull’aspetto
Esplicita le istruzioni operative per la formattazione e impaginazione, le quali sono invisibili
all’utente.
Ad ogni elemento del documento viene associata la procedura per visualizzarlo e ad elementi dello
stesso tipo si possono associare procedure diverse.
E’ dipendente dal sistema.
Non è contestuale: le regole da visualizzazione non dipendono dal contesto in cui vengono
fatte. (rtf)
Non è possibile porre vincoli alla correttezza di un documento.
REQUISITI DEI LINGUAGGI DI CODIFICA
POTENZA ESPRESSIVA: modellizzare il maggior numero di tipologie e generi testuali
Rappresentare i livelli strutturali e le loro caratteristiche
Esprimere le caratteristiche secondo diverse prospettive
metodologiche (sintagma nominale o verbale oppure soggetto, verbo e complemento)
Associare ai documenti digitali metadati di descrizione e
gestione
PORTABILITA NEL TEMPO E RIUSABILITA
STANDARDIZZAZIONE E APERTURA: un linguaggio di cofidica dovrebbe essere
adottato universalmente dalla comunità di utenti, cioè dovrebbe essere uno standard e
dovrebbe essere di pubblico dominio. (differenza tra standard formale cioè che ha norme
relative a una tecnologia ma è prodotto da un ente istituzionale e standard informale, che ha
norme relative a una tecnologia o linee guida e è diffuso da una comunità di utenti ma non è
certificato da un ente preposto)
SGML
E’ un linguaggio di marcatura descrittivo creato nel 1986,antenato dell’xml
È uno standard: ISO 8879 1986
HA UNA SINTASSI ASTRATTA
SPIEGA I RUOLI DEI DELIMITATORI: sono necessari tag iniziali e finali,
BAGAGLIO DI COMPETENZE DEL LINGUISTA COMPUTAZIONALE
1. SELEZIONE APPROPRIATA DEI DATI LINGUISTICI
2. CONOSCENZA DEI METODI STATISTICI, COMPUTAZIONALI, LOGICOALGEBRICI PER L’ANALISI DEI DATI
3. PADRONANZA DELLE TECNICHE INFORMATICHE
NUOVO ORIENTAMENTO DELLA LC: IMPOSTAZIONE EMPIRICA DI ATTENZIONE AL
DATO TESTUALE CON L’APPLICAZIONE RECENTE DEI METODI STATISTICI
RIFLESSIONE SULLA NATURA E COMPOSIZIONE DEI DATI
DATO LINGUISTICO: il prodotto del linguaggio oggetto di analisi per lo sviluppo di modelli e
teorie linguistiche
Parole, per analisi morfologiche e semantiche
Frasi, per analisi sintattiche
Enunciati, per analisi sulla funzione comunicativa
PROBLEMA PRELIMINARE DEL LINGUISTA COMPUTAZIONALE: individuare le fonti, che
possono essere di due tipi:
I testi
(1) Strutturati
(2) Trascrizioni di conversazioni spontanee
(3) Macro-testi
(4) Micro-testi
I parlanti
Questioni o esperimenti eseguiti in un contesto di laboratorio: esempio, il giudizio del
parlante su questioni della lingua, le parole usate per descrivere una scena, l’affinità
semantica che per loro c’è tra due parole
DATO LINGUISTICO ECOLOGICO E CONTROLLATO
ECOLOGICO: i dati estratti dai testi
CONTROLLATO: ricavati attraverso la somministrazione di test, il linguista può controllare le
variabili in gioco, eliminando fattori di disturbo con dei rischi però.Astrazione dal contesto e
idealizzazione senza alterare il fenomeno naturale. La LC combina dati ecologici e controllati
I CORPORA
CORPUS: La principale fonte di dati in LC; una collezione di testi selezionati e organizzati in
maniera da soddisfare specifici criteri che li rendono funzionali per le analisi linguistiche.
Diffondersi dei corpora con le analisi statistiche
Consapevolezza dell’importanza del dato ecologico
Sviluppo della tecnologia informatica
Il corpus precede pero l’avvento del computer
Il computer permette di immagazzinare sempre più dati, ottimizzare la ricerca e sviluppare modelli
computazionali della lingua
Oggi corpus è sinonimo di corpus elettronico, cioè di testi in formato digitale
TIPI DI CORPORA
1. Corpora
specialistici:
varietà
linguistica (sublanguage) o dominio
tematico
2. Generali
3. Di lingua scritta
4. Di lingua parlata
5. Misti
6. Corpora audio
7. Audio-visivo (multimodale)
8. Sincronico
9. Diacronico
10. Monolingue
11. Bilingue, paralleli o comparabili
12. Interi
13. Porzioni di testi
14. Annotati (codificati ad alto livello)
15. Di prima generazione
16. Di nuova generazione
17. Di monitoraggio o corpus aperto, una
collezione aperta di testi che muta nel
tempo, per mantenere aggiornati i
dizionari
Oggi tendono a essere sono misti, cresce il numero di quelli audio, paralleli allineati
Testi interi, il numero di lingue per i quali esistono corpora aumentano sempre, riccamente
codificati con linguaggi di marcatura e schemi di codifica standardizzati,
annotati, sempre più basi di dati e interfacce di ricerca
Specialistici: Childes: linguaggio infantile normale e patologico, corpora di lingua parlata
Reuters-21578 raccolta di agenzie stampa in inglese
Generali: plurifunzionali, risorse trasversali per fare dizionari e grammatiche, articolati spesso in
sottocorpora
Di lingua scritta:Brown Corpus, Parole, Coris
Sincronico: Brown Corpus ( USA, 1961)
La Repubblica (tra il 1985 e il 2000)
Diacronico: Italnet (Tesoro della Lingua Italiana delle Origini) testi anteriori alla morte di
Boccaccio (1375)
Parallelo: Canadian Hansards Corpus
Comparabile: Parole (12 ligue europee)
Testi integrali:Parole e Coris
Di prima generazione: Brown Corpus (USA, 1964), IL PRIMO CORPUS ELETTRONCO
PROGETTATO PER LO STUDIO DELLA LINGUA
Nuova generazione : BNC (100 milioni di parole)
Di monitoraggio: Bank of English ideato da John Sinclair (450 milioni nel 2002)
Coris e American National Corpus
IL CORPUS COME CAMPIONE
Dimensione quanitativa e qualitativa
La linguistica dei corpora è portavoce del controllo delle modalità di selezione dei testi, più grande
non significa necessariamente migliore, teoria sostenuta da Leech (1991)
Un corpus, per possedere proprietà reali della lingua, deve essere rappresentativo della popolazione,
cioè che deve tenere traccia della variabilità delle proprietà e dei tratti della lingua, che “ci fornisca
un’immagine il più accurata possibile delle tendenze della varietà in questione, comprese le loro
proporzioni (Mc Enery, 2001, p.30)
La linguistica dei corpora dice di adottare criteri di selezione dei testi, ad esempio solo il linguaggio
giuridico in modo che la variabilità è più limitata.
CORPORA BILANCIATI
I corpora generali per essere rappresentativi di una lingua devono possedere il requisito del
bilanciamento. Il bilanciamento presuppone una descrizione dettagliata della popolazione:
Confini spaziali e temporali
Tipologia di testi (strati della popolazione)
BNC : BILANCIAMENTO SOFISTICATO 90 milioni di testi scritti 10 milioni di parlato
trascritto. I testi scritti sono selezionati secondo il dominio e il medium, i testi di parlato trascritto in
base alle conversazioni spontanee e i discorsi in conferenze, politici...
Il bilanciamento deve essere qualitativo e quantitativo
I CORPORA IN LC
Fonte di evidenza per definire modelli linguistici e sviluppare strumenti informatici per
l’elaborazione della lingua
Evidenza qualitativa: quali regole devono entrare nella grammatica di un analizzatore sintattico del
testo o
Evidenza quantitativa : applicazione di metodi statistici sulle occorrenze di espressioni in un corpus
I LIMITI DELLA RAPPRESENTATIVITA’
Critica di Chomsky : “Galileo non sarebbe stato interessato a registrazioni video di foglie che
cadono, palle che si muovono...” I corpora sono insieme finiti, parziali e legati alla propspettiva di
osservazione dei dati.
La nostra conoscenza del linguaggio è infinita e l’uomo può produrre un numero illimitato di
espressioni.
Diciamo che allora i corpora soddifano solo delle “curiosità linguistiche”
Per questo, il controllo degli aspetti qualitativi di un corpus è fondamentale per la linguistica dei
corpora.
La selezione dei testi è legata alla loro effettiva disponibilità: anche se la maggior parte dei prodotti
di una lingua sono orali, i corpora più numerosi sono quelli scritti, perché di più facile reperimento.
Esempio quello più usato in inglese è il corpus delle annate del Wall Street Journal, quello italiano
La Repubblica, che non può essere preso a riferimento per la lingua italiana, perché è formata da un
unico genere testuale, ma può essere importante per le applicazioni linguistiche.
Un corpus di una lingua è prodotto dell’interpretazione che diamo questa lingua, quindi anche
quando è bilanciato, bosogna essere consapevoli che in realtà esso rimarrà sempre sbilanciato.
I corpora sono usati anche per esperimenti psicolinguistici: tipo come individuare la variabilità di
complementi retti da un verbo o la variabilità di altri tratti linguistici.
IL CORPUS COME BENCHMARK
Il corpus deve essere uno standard di riferimento per un’applicazione linguistca da parte di un
programma: per questo si scelgono dei corpora standard, come il BNC per analisi computazionali
in lingua inglese o il Reuters 21578 per i corpora specialistici.
Requisiti : qualità, la rappresentatività della lingua e per una comunità di ricerca, la disponibilità
CORPORA SPECIALISTICI
OBBIETTIVO DELLA LC in ambito specialistico: sviluppare modellli che conoscano i dati
specialistici estratti da corpora specialistici . E elaborare modelli che abbiano la capacità di adattarsi
a altre capacità linguistiche. Biber dice infatti che non esiste niente che si possa definire lingua
generale; la competenza generale di una lingua può essere il risultato dell’estensione a partire da
competenze specialistiche, capacità intrinseca della competenza linguistica umana.
CORPORA DI ADDESTRAMENTO o training corpora
Ci sono settori della LC a cui invece non interessa il bilanciamento e la dimensione qualitativa, ma
solo quella quantitativa, le analisi statistiche.
Significa Costruire modelli a partire dai corpora di addestramento : osservare parole, sintagmi o
frasi dei corpora e sulla base delle occorrenze quantitative fare previsioni su un fenomeno
linguistico, per capire il significato di una parola nel contesto, per fare traduzioni oppure per fare
l’analisi sintattica corretta di una frase
E’ difficile ricavare modelli statistici affidabili perché gli eventi linguistici dei corpora sono rari,
ovvero ricorrono pochissime volte.
Grazie al fatto che oggi i computer possono gestire dimensioni sempre più grandi di dati, c’è una
strada alternativa: né il bilanciamento, né le analisi statistiche di corpora finiti ma usare il World
Wide Web come corpus.
Nel 2003 si è stimato che le pagine indicizzate da Google equivalevano a 20 terabyte di di testo
accessibile, cioè 2000miliardi di parole se consideriamo 10 byte per parola.
Le pagine indicizzate sono solo una parte del testo digitale che fluttua nel cyberspazio.Il 75% delle
pagine indicizzate sono in inglese, seguite dal giapponese con solo il 6,8%. L’italiano è superato da
cinese e spagnolo.L’italiano può comunque contare su quasi 2 miliardi di parole.Si possono usare i
programmi che navigano di sito in sito e scaricano automaticamente le pagine di testo visitate ( web
robots, spiders, crawlers)
Google dà però anche errori ortografici, ma ci si può ricavare informazioni sui neologismi: più di
7000 pagine contengono il verbo messaggiare, può alleviare il problema della rarità dei dati
linguistici. Un problema pero è togliere i dati non rilevanti, il rumore, che è ingente.
LA CODIFICA
le macchine memorizzano e elaborano dati solo sotto forma di due simboli: 0 e 1, detti bit
dal’inglese BInary DIgit “cifra binaria”.
Le avventure di Pinocchio
Capitolo 1
È un’informazione meta-testuale: riguarda il titolo, e la suddivisione in capitoli
Nella codifica solo della sequenza di caratteri quest’informazione è perduta perché è veicolata
implicitamente dalla formattazione.
Poi c’è l’informazione della struttura linguistica che deve essere resa esplicita al computer e
disponibile per ulteriori elaborazioni.
CODIFICA DI ALTO LIVELLO: codifica della struttura linguistico-testuale che prevede:
1. Selezionare gli elementi da rappresentare
2. Scegliere il linguaggio di rappresentazione
CODIFICA DI LIVELLO ZERO O CODIFICA DEI CARATTERI o Character encoding:
per la codifica di livello zero un carattere è un’entità astratta, distinta dalle sue rappresentazioni
grafiche ( p in grassetto o in corsivo sono lo stesso carattere)
le lettere graficamente uguali ma appartenenti ad alfabeti diversi invece sono caratteri diversi
un set di caratteri o codice è una tabella di associazioni biunivoche tra i caratteri e i codici
numerici. Nelle tabelle, i codici possono essere in base decimale, ottale o esadecimale.
i codici numerici sono detti punti di codice
la codifica di livello zero associa a ciascun punto di codice un carattere binario. Il numero di
caratteri codificabili dipende dal numero dei punti di codice, il quale dipende dalle cifre binarie.
Caratteri: 2 alla n cifre binarie
Il più noto e diffuso set di caratteri è quello ASCII (American Standard Code for Information
Interchange), nucleo comune di tutti i seti di caratteri più estesi.
ASCII: ogni carattere è un byte, cioè 8 bit ma solo 7 bit sono usati per rappresentare il codice
nuerico, l’8 bit serve a controllare la trasmissione del codice
ASCII: 128 carattere ( 2 alla settima di caratteri)
33 punri di codice = 0/32 e 127 sono caratteri di controllo ( accapo, tabulazione, backspace)
I 99 punti di codice restanti sono per a caratteri dell’alfabeto, i segni di punteggiatura e le cifre (
lettere dell’alfabeto anglosassone, mancano gli accenti e le dieresi)
È stato esteso a 8 bit cioè 256 caratteri per codificare anche l’italiano, il francese
ISO-LATIN 1 O ISO-8859-1 è L’UNICA ESTENSIONE STANDARD DI ASCII PER LE
LINGUE DELL’EUROPA OCCIDENTALE : i primi 128 punti di codice sono gli stessi caratteri di
Ascii, da 128 a 159 sono caratteri di controllo, i restanti rappresentano caratteri con accenti e dieresi
ISO-8859 è una famiglia di set di caratteri codificati con un byte
ISO-LATIN 2 lingue slave in alfabeto latino
ISO- 8859-5 cirillico
ISO- 8859-6 arabo, il 7 greco moderno e l’8 l’ebraico
Svantaggi: non hanno i sistemi grafici delle lingue orientali e sono mutuamente esclusivi, cioè uno
stesso punto di codice corrisponde a caratteri diversi a seconda del set ISO-8859 usato
IL SET DI CARATTERI UNICODE
È universale, codifica testi dei caratteri di tutti i sistemi di scrittura esistente, antica e
moderna ( la versione 4 codifica più di 90.000 caratteri)
Non esiste esclusività tra alfabeti diversi: ad ogni punto di codice c’è un carattere distinto
I primi 256 punti di codice sono quelli di ASCII esteso ISO-LATIN 1
Principio di composizione statica e dinamica per la codifica: š puo essere codificato come la
somma di due punti di codice e per i carattere più comuni invece la codifica è statica, cioè il
punto di codice è unitario
Usa varie modalità di codifica, che usano più di un byte : cioè i punti di codice e i caratteri
sono uguali, mentre cambiano le sequenze binarie. La codifica UTF-8 è compatibile con
ASCII (127 caratteri) ma non si estende all’iso-latin 1.. fino a 127 si usa un byte, poi 2 byte,
poi 3 e così via..
ISO-LATIN 1 non è compatibile con Unicode
LA CODIFICA DI ALTO LIVELLO:
trasforma il dato linguistico in informazione linguistica
Cosa codificare, come codificare, perché codificare...
Perché codificare:
informazione : dato + struttura
informazione: dato in un contesto interpretativo
il valore dei dati si misura sulla base delle informazioni che contiene
testo : fonte di dati linguistici + livelli di organizzazione: struttura del testo ( capitoli, titoli)+
struttura del contesto ( autore, anno...)+ struttura linguistica
Cosa codificare
Fare uno schema di codifica:
1. Individuare il livello di informazione che si vuole codificare: esempio codifica morfosintattica
2. Definire i tratti rilevanti : categoria grammaticale, gli attributi (genere, numero, persona,
tempo), i valori degli attributi ( maschile, femminile..)
3. Definizione dei criteri di assegnazione dei tratti alle parole
4. le regole di compatibilità tra le categorie : al’aggettivo nn c’è un attributo di persona
Il successo e la diffusione di uno schema dipendono dalla coerenza interna, dalla trasparenza, dagli
obbiettivi di ricerca
Come codificare
Formato solo testo
Formati come doc (Microsoft Word) o pdf ( Acrobat Adobe)
Linguaggi di mark-up o linguaggi di marcatura che unisce la rappresentazione dell’informazione
strutturale con la portabilità : SGML, XML. Il formato è solo testo; l’informazione strutturale è
aggiunta con delle etichette o tag di marcatura.
Con i linguaggi di marcatura non c’è limite al tipo di informazioni codificabili: in base alla finalità
della codifica, definisco l tipologia di etichette.
Si può anche personalizzare la codifica
CAPITOLO 3
Costruire un linguaggio di marcatura
SGML nasce alla fine degli anni sessanta e nel 1986 diventa uno standard ISO-8879: 1986,
XML nasce negli anni novanta come evoluzione di SGML, suscita interesse della comunità
scientifica perché è versato per le applicazioni web, perché è una versione semplificata, si presta
meglio ad essere manipolato da programmi automatici
In XML, a differenza del Sgml :
1. il DTD è OPZIONALE
2. il tag di chiusura è sempre obbligatorio
3. è ammesso un solo modo di dichiarare un elemento con contenuto di tipo misto
4. Solo la virgola e la barra verticale come connettori per dichiarare il contenuto di un
elemento
CARATTERISTICHE DI XML
1. Marcatura dichiarativa: le etichette indicano la funzione astratta di una porzione di
testo, senza fornire indicazione di come dovrà apparire fisicamente
2. Marcatura strutturata : permette di raggruppare porzioni di testo e vederle come unità
strutturali complesse ( un capitolo come l’insieme di titolo di capitolo, paragrafo,
didascalia, tabella...)
3. Marcatura gerarchica: le unità strutturali possono contenere altre unità strutturali
4. XML E SGML non forniscono indicazioni sulla semantica dei marcatori, cioè la
tipologia, la quantità o il nome ; forniscono regole combinatorie per definire un
insieme di marcatori
SONO MATALINGUAGGI, LINGUAGGI PER LA DEFINIZIONE DI LINGUAGGI DI
MARCATURA VERI E PROPRI, COME HTML, DEFINITO COME SGML
L’insieme di codici di marcatura di HTML non è estensibile, per cui non è riusabile per scopi
diversi da quello della visualizzazione del testo. Per questo XML è una solzione dei limiti di
HTML nella tecnologia del web.
1. Siccome è un metalinguaggio si deve fare la DEFINIZIONE DEL TIPO DI DOCUMENTO
IN UNA DTD: in essa l’utente definisce i marcatori, i loto tratti e le relazioni tra essi
2. Indipendenza dai dati codificati: si può astrarre dal programma, perché il formato è solo
testo e e si usa la codifica UNICODE utf-8 garantendo la portabilità dei dati
I MARCATORI
ELEMENTI, ATTRIBUTI, RIFERIMENTI A ENTITà O CARATTERE, COMMENTI
ELEMENTI: unità del testo
Ogni tipo di elemento è un’etichetta o tag
Il nome del tipo di elemento è identificatore generico
Delimitatore di apertura e di chiusura
XML è case sensitive (sensibile alla distinzione tra maiuscola e minuscola), l’identificatore
generico deve riportare la maiuscola o la minuscola
DELIMITATORE DI APERTURA + CONTENUTO DELL’ELEMENTO+ DELIMITATORE DI
CHIUSURA
< titolo> Le avventure di Pinocchio </titolo> ELEMENTO
< titolo> Le avventure di Pinocchio </titolo> DELIMITATORI
< titolo> Le avventure di Pinocchio </titolo> CONTENUTO DELL’ELEMENTO
< titolo> Le avventure di Pinocchio </titolo>TAG
Nome del tag è detto identificatore generico
Il contenuto dell’elemento può essere formato da altri elementi (con altri delimitatori) :
meccanismo di annidamento degli elementi
Un elemento figlio deve essere completamente incluso nell’elemento padre
Ogni documento XML deve contenere un unico elemento radice che contiene tutti gli altri elementi
Ogni documento XML ha una struttura ad albero: i nodi sono gli elementi, le foglie sono il
contenuto degli elementi
C’è anche l’elemento vuoto, essempio un salto pagina : <tag> </tag>, abbreviata in <tag/>
ATTRIBUTI
Informazioni aggiuntive che non fanno parte del contenuto del testo e che specificano alcune
caratteristiche dell’elemento. Sono specificati all’interno del delimitatore di apertura e non ci può
essere più di un attributo in un elemento
<capoverso num= “1”> C’era una volta....</capoverso>
I valori degli attributi vanno sempre tra virgolette, doppie o singole
Non si può specificare l’ordine in cui devono comparire nella marcatura testo.
Sono utilizzati per codificare informazioni senza struttura complessa, che presentano un insieme di
valori o sono meta informazioni di un elemento esistente
RIFERIMENTI A CARATTERE
Sono riferimenti inseriti nel testo contenenti il valore numerico dei caratteri appartenenti al codice
Unicode
È buona norma codificare come riferimenti a carattere tutti i caratteri che non rientrano nel set
ASCII , per garantire la max portabilità del testo tra programmi che supportano codici diversi
&#codice_esadecimale;
&#codice_decimale;
con le entità si può associare a ogni riferimento a carattere nomi mnemonici per aumentare la
leggibilità del testo
RIFERIMENTI A ENTITA’
Entità : sequenze arbitrarie di byte associate a nomi mnemonici , i riferimenti a entità
I riferimenti a entità sono utili per riutilizzare lo stesso frammento di testo in posizioni diverse.
Le entità usate nella marcatura del testo sono dette generali
Le entità al’interno della DTD sono dette parametriche
Entità generali : interne, il cui valore è dichiarato localmente nella DTD
Esterne, valore rappresentato dal contenuto di un file XML o altri formati
Qui analizzeremo le entità generali interne. I riferimenti a entità :
&nome entità;
la stringa di testo associata al riferimento a entità deve essere dichiarata nella DTD
la stringa di testo associata al riferimento a entità predefinite non va dichiarata nella DTD
esempio: &apos; è un riferimento a entità predefinita
I riferimenti a entità predefinite sono caratteri riservati di XML che vanno inseriti come tali quando
nel testo non sono segni di marcatura
COMMENTI
I commenti dell’autore sono brevi note che l’autore può aggiungere e vengono ignorate dalle
applicazioni nell’elaborazione del testo.
< ! --- >
Non possono apparire all’interno di un delimitatore
LA DEFINIZIONE DEL TIPO DI DOCUMENTO
DTD : LA GRAMMATICA DEL LINGUAGGIO DI MARCATURA
Nella DTD vengono dichiarati in una lista non ordinata e tra parentesi angolari :
gli elementi
gli attributi
le entità richiamabili attraverso riferimenti all’interno del testo
Dopo la parentesi angolare segue un punto esclamativo,e l’elemento chiave che specifica il tipo di
oggetto: ELEMENT, ENTITY O ATTLIST
LA DICHIARAZIONE DI UN ELEMENTO
< ! ELEMENT tag_elemento (#PCDATA) >
Tag + modello di contenuto
Il modello di contenuto (#PCDATA) indica che il contenuto dell’elemento è testo senza marcatori
(s, s, s,s,...) il contenuto contiene elementi figli la virgola significa che I sottoelementi devono
seguire l’ordine specificato
(s s s s s s ) la barra verticale dice che l’elemento padre deve contenere uno degli elementi figli a
scelta
LA DICHIARAZIONE DI UN ATTRIBUTO
STRUTTURA E VALIDAZIONE DI UN DOCUMENTO XML
Un documento XML è formato da due parti: il prologo e l’istanza del documento
Prologo: le informazioni che permettono di interpretare il documento com documento XML. E’
costituito dalla dichiarazione XML e dalla dichiarazione del tipo di documento
L’istanza del documento è il dato testuale vero e proprio con la relativa marcatura
STANDARDIZZAZIONE DELLA CODIFICA DEL TESTO
La codifica sulla base di un metalinguaggio di marcatura standard come XML permette la
rielaborazione del testo da vari strumenti software e l’indipendenza dei dati rispetto a
un’applicazione specifica e un sistema operativo.
Per condividere però il contenuto della codifica, si deve passare attraverso la conoscenza del
repertorio delle categorie usate, cioè la codifica deve essere basata su uno schema di codifica e
annotazione il più possibile condiviso.La codifica sulla base dell’XML deve essere basata su una
DTD STANDARD.
Una codifica che usa un metalinguaggio di marcatura standard e uno schema di codifica standard
trasforma il testo digitale in una risorsa di informazione pronta all’uso.
E’ una codifica condivisibile sia a livello formale ( quello del metalinguaggio) sia quello semantico
(il contenuto della codifica)