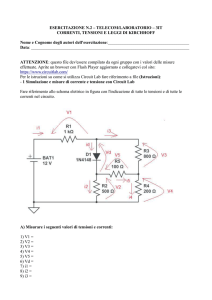
Facoltà di Ingegneria
Corso di Studi in Ingegneria Informatica
Elaborato finale in Basi di Dati
In-Memory database
Anno Accademico 2012/2013
Candidato:
Maritato Luigi
Matr. N46/762
A Monica,
infinitamente grazie.
Indice
Capitolo 1:MMDB vs DBMS
1.1 Un po di storia…………………………………………………………….4
1.2 Scenario applicativo………………………………………………………5
1.3 Confronto…………………………………………………………………5
1.4 Supporto Acid…………………………………………………………….6
1.4.1 On line backup………………………………………………………….7
1.4.2 Transaction logging………………………………………………….…7
1.4.3 NVRAM………………………………………………………………..7
Capitolo 2:In memory database
2.1 Architettura……………………………………………………………….8
2.2Query e relazioni………………………………………………………….9
2.2.1 Liste temporanee……………………………………………………….9
2.3 Main Memory index structure…………………………………………..10
2.3.1 Strutture indice esistenti……………………………………………….10
2.4 T-Tree……………………………………………………………………12
2.5 T-Tree:Algoritmi di ricerca e aggiornamento…………………………...14
2.5.1 Algoritmo di ricerca…………………………………………………...14
2.5.2 Algoritmo di inserimento……………………………………………...14
2.5.3 Algoritmo di eliminazione…………………………………………….15
2.6 Rebalancing……………………………………………………………...16
2.7 Performance degli algoritmi e delle strutture dati……………………….20
Capitolo 3:Recovery
3.1 Introduzione………………………………………………………………….25
3.2 Logging………………………………………………………………………26
3.3 Reloding………………………………………………………………….…..26
Capitolo 1
MMDB vs DBMS
Introduzione
Con il termine in-memory database(IMBD),detto anche sistema di basi dati in
memoria centrale(MMDB) si intende un database che utilizza la memoria principale
per la memorizzazione dei dati. I database in memoria centrale sono molto più veloci
di quelli su memorie di massa, ma possono gestire moli di dati molto inferiori, a patto
che ci sia comunque un modo per recuperarli in caso di guasti mediante ad esempio
tecniche di ripristino.
Vedremo nel seguito che un IMDB può essere implementato anche con strutture
differenti da quelle utilizzate per l'approccio relazionale (tabelle), quali quelle
suggerite dal modello reticolare (puntatori) e dal modello gerarchico (alberi) .
1.1 Un po di storia
Inizialmente gli sviluppatori dei sistemi embedded realizzavano delle soluzioni per la
gestione dei dati. Con l’avvento della concorrenza sul mercato che richiedeva
dispositivi sempre più intelligenti, le applicazioni dovevano essere dotate di
caratteristiche funzionali sempre più complesse per la gestione dei dati. La difficoltà
nella gestione dei dati ed il costo portarono gli sviluppatori di sistemi embedded a
progettare database commerciali.
I primi DBMS tradizionali erano caratterizzati dall’avere una logica di caching molto
complessa per aumentare le prestazioni, e con tante funzioni inutili per il dispositivo
che faceva uso di database embedded.
Successivamente queste caratteristiche portarono allo sviluppo di applicazioni che
superavano il concetto di memoria disposizione
memoria disponibile e che fossero in grado di sfruttare meglio le risorse della CPU.
Quindi nacquero database in memoria principale specificamente per soddisfare le
esigenze di prestazioni e di disponibilità delle risorse nei sistemi embedded.
1.2 Scenario applicativo
Un sistema di gestione dei dati in memoria principale offre enormi garanzie in
termini di prestazioni a vantaggio di tutte quelle applicazioni che necessitano di
accedere in maniera rapida ai dati.
Esempio:
-le applicazioni real time dove sono richieste performance molto elevate in
termini di throughput e soprattutto latenza;
-possono essere utili anche per lo sviluppo di Database tradizionali residenti
sul disco allo scopo di fare testing.
1.3 Confronto
Con i MMDB non esiste più il concetto di I/O verso i dischi bensì di tratta di database
tradizionali caricati in memoria principale. Le differenze riguardano:
-il casching
-Overhead dovuto al trasferimento dei dati
-elaborazione delle transazioni
1.3.1 Il Cashing
In generale tutti i DBMS supportano meccanismi di casching al fine di mantenere i
record più utilizzati in memoria principale x ridurre il numero di accessi al disco.
Se questa attività non viene più considerata si escludono sostanzialmente 2 problemi:
-la sincronizzazione ,usata per garantire la consistenza dei dati presenti in
memoria con quelli presenti sul disco;
-louckup nella casche al fine di determinare se il record richiesto si trovi nella
casche.
Quindi non considerando la casche in un IMBD non si ha più la difficoltà nel gestire
la complessità di questa operazione riducendo di conseguenza anche il lavoro che la
CPU deve fare quando si hanno a che fare DMBS completamente sviluppati in
memoria.
1.3.2 Overhead dovuto al trasferimento dei dati
Mentre nei DB tradizionali l’overhead dovuto al trasferimento tra casche DB e il
disco in MDB attraverso i puntatoti e quindi attraverso le API è possibile accedere ai
dati residenti nel database
1.3.3 Elaborazione delle transazioni
In un database orientato ai dischi, il processo di ripristino quando si verifica un abort
delle transazioni è basato su un file di log aggiornato ogni volta che essa viene
eseguita. Per garantire l’integrità della transazioni, IMBD conserva un immagine
dell’oggetto aggiornata e in caso di abort un IMDB si impegna a ripristinarla.
1.4 Supporto ACID
Nell'ambito dei database, ACID deriva dall'acronimo inglese Atomicity,
Consistency, Isolation, e Durability (Atomicità, Coerenza, Isolamento e Durabilità)
ed indica le proprietà logiche che devono avere le transazioni.
Affinchè le transazioni operino in modo corretto sui dati è necessario che i
meccanismi che le implementano soddisfino queste quattro proprietà:
atomicità: la transazione è indivisibile nella sua esecuzione e la sua esecuzione
deve essere o totale o nulla, non sono ammesse esecuzioni parziali;
•
coerenza: quando inizia una transazione il database si trova in uno stato
coerente e quando la transazione termina il database deve essere in un altro
stato coerente, ovvero non deve violare eventuali vincoli di integrità, quindi
non devono verificarsi contraddizioni (inconsistenza) tra i dati archiviati nel
DB;
•
isolamento: ogni transazione deve essere eseguita in modo isolato e
indipendente dalle altre transazioni, l'eventuale fallimento di una transazione
non deve interferire con le altre transazioni in esecuzione;
•
durabilità: detta anche persistenza, si riferisce al fatto che una volta che una
transazione abbia richiesto un commit work, i cambiamenti apportati non
dovranno essere più persi. Per evitare che nel lasso di tempo fra il momento in
cui la base di dati si impegna a scrivere le modifiche e quello in cui li scrive
effettivamente si verifichino perdite di dati dovuti a malfunzionamenti,
vengono tenuti dei registri di log dove sono annotate tutte le operazioni sul DB.
Le prime tre caratteristiche sono solitamente supportati da un IMBD, al contrario
della durabilità perché la memoria principale è una memoria volatile e perde tutti i
dati memorizzati durante un reset.
Con le loro elevate prestazioni IMDB sono una buona soluzione per le time-critical
applications, ma quando sorge la necessità della durata non è più una soluzione
adeguata.
Per ottenere la durabilità nei database in memoria principale ci sono diverse
soluzioni:
-On-Line Backup.
-Registrazione delle transazioni (Transaction logging)
-RAM non volatile (NVRAM)
1.4.1 On-Line Backup
On-line backup è un backup eseguito mentre il database è on-line ed è disponibile per
la lettura/scrittura. Questa è la soluzione più semplice ma offre una durabilità molto
bassa
1.4.2 Transaction Logging
Una transazione log è la storia delle azioni eseguite da un database managment
system. Al fine di garantire la proprietà ACID per incidenti o guasti sul hardware il
log deve essere scritto in una memoria non-volatile, solitamente un hard disk. Se il
sistema fallisce e poi viene riavviato l’immagine del database può essere ripristinata
da questo log file.
Il processo di ripristino funziona in modo simile ai DBMS tradizionali, dove in caso
di guasto il sistema di RECOVERY è incaricato di riportare il database ad uno stato
corretto (stato del DB precedente a transazioni di modifica che non sono state
terminate con successo)precedente al guasto.
Tuttavia questa tecnica comporta l’utilizzo di memorie persistenti come un disco
rigido che è un collo di bottiglia specialmente durante la ripresa del database.
Nonostante questo aspetto IMDB sono ancora più veloci rispetto ai tradizionali
DBMS perché il logging delle transazioni richiede una operazione di scrittura nel file
system ,mentre con i database basati sui dischi non solo bisogna scrivere sul log ma
bisogna tener conto anche dei dati e gli indici.
1.4.3 NVRAM
Per ottenere la durabilità ,IMDB può supportare una ram non volatile (NVRAM): di
solito una RAM statica sostenuta con alimentazione a batteria, o una EEPROM.
In questo modo il DBMS sarà in grado di recuperare i dati anche dopo un reboot.
Questa rappresenta una opzione molto interessante per la durabilità di un IMDB
perché NVRAM in contrasto con le soluzioni precedenti non comporta la latenza
relativa ai dischi né overhead nella comunicazione.
Capitolo 2
In-Memory database
2.1 Architettura
Il cambiamento più notevole ed evidente tra i metodi di accesso
di un MMDB e DRDB, è la mancanza del buffer manager per MMDB.
Da un punto di vista architetturale la necessità di un buffer manager in un DBMS è
nata poiché spesso la gestione dei dati è enorme e nel corso delle elaborazioni può
capitare che lo spazio richiesto per i blocchi di dati sia maggiore della spazio di
memoria disponibile. Nel DRDB il buffer manager è presente per fornire una
comunicazione efficiente tra la memoria e il disco, per la memorizzazione dei dati in
memoria e lo swapping verso il disco.( Si ricorda che) . Poichè tutti gli accessi in
MMDB sono in memoria, il buffer manager non è necessario.
L’assenza di una buffer manager comporta enormi vantaggi in termini di operazioni
,di risorse utilizzate e tempi di calcolo perchè viene meno la necessità di una copia
dei dati dal disco e del mapping degli indirizzi sul disco a indirizzi di memoria.
Anche la struttura degli indici progettati per la memoria principale sono diverse da
quelli progettati per i sistema basati sui dischi. Il primo obbiettivo per una struttura
degli indici nei database orientati ai dischi è quello di minimizzare il numero di
accessi al disco e occupare meno spazio possibile su di esso. La struttura degli indici
in memoria principale è contenuta in memoria principale ,non considerando per nulla
il disco.
L’obiettivo di un indice in memoria principale è ridurre il tempo di calcolo
complessivo e contemporaneamente utilizzare meno memoria possibile. Poichè le
relazioni sono presenti in memoria non è necessario un indice per memorizzare il
valore degli attributi. Invece i puntatori alle tuple possono essere memorizzati da
qualche parte nella heap ed essere utilizzati per ricavare il valore degli attributi
quando se ne ha bisogno. Vantaggi:
-un puntatore a una singola tupla fornisce l’indice di accesso sia al valore di un
attributo della tupla sia all’intera tupla, riducendo la dimensione dell’indice;
-spostare i puntatori è più conveniente che spostare il valore degli attributi
quando gli eventuali aggiornamenti richiedono delle operazioni sugli indici.
2.2 Query e Relazioni
Quando si esegue una query su un MMDB piuttosto che su un DRDB, il fattore
dominante non è il numero di operazioni di I/O verso il disco ma piuttosto il tempo
della CPU.
Come si accede alle relazioni? Attraverso gli indici(Ogni relazione deve avere
almeno un indice).Le tuple in una partizione della memoria vengono individuate
attraverso un indirizzo di memoria e ciò richiede che non possano cambiare
locazione una volta memorizzate sul database. Per una campo di lunghezza variabile,
la tupla stessa presenterà un puntatore a quel campo allocato nell’area heap. In alcuni
casi la tupla potrebbe portare all’overflow dell’area di memoria heap,
impossibilitando l’accesso a quella tupla e di conseguenza portare allo spostamento
della tupla in un'altra area di memoria .Dato che le tuple in memoria possono essere
accedute in maniera randomica è possibile utilizzare i puntatori. Per esempio ,la
chiave esterna (attributo che riferisce a tuple di altre relazioni) può essere sostituita da
un campo puntatore a un tupla(nel caso di relazione 1-1 il campo presenterà un unico
puntatore, nel caso di una relazione 1-n presenterà una lista di puntatori).Quindi con
MM_DBMS la chiave esterna può essere semplicemente sostituita da un puntatore.
Ciò mi consente una gestione efficiente dello spazio in memoria perché i puntatori
sono tipi di dati che rappresentano la posizione.
2.2.1 Le liste temporanee
Gli MMDB utilizzano la struttura Lista Temporanea per salvare il risultato delle
query sulle relazioni. Essa è costituita da una lista di puntatori a tuple con output
della query. Il puntatore punta alla relazione(i) sorgente dal quale la relazione
temporanea è nata e il risultato della descrizione identifica i campi che sono
contenuti nella relazione che rappresenta la lista temporanea. Anche in questo caso
per accedere è possibile associare un indice.
Ad esempio, se le relazioni Employee e il Departiment di Figura 1 sono unite dal
campo id del Dipartiment, alla fine ogni tupla risultante nella lista temporanea
verrebbe a memorizzare una coppia di puntatori a tupla ( una che punta alla tupla di
Employee e l’altro alla tupla del Dipartiment), e nella Result Descriptor troviamo la
lista dei campi presenti nel Result Relation .
Figura 1
2.3 Main memory index structure
Le strutture dati index si distinguono in 2 tipi:
-quelli che conservano l’ordinamento naturale dei dati;
-quelli che conservano un ordinamento casuale dei dati.
2.3.1 Strutture indice esistenti
Array :
utilizzati in particolare nei progetti IBM-ODE. La caratteristica è che occupano
poco spazio a condizione che la dimensione sia nota in anticipo;
AVL Tree:
è una struttura dati autobilanciante basata sugli alberi di ricerca binaria. La
ricerca in esso è efficiente perchè si svolge esattamente come quella applicata
agli alberi binari di ricerca, di conseguenza non viene perso del tempo in
calcoli aritmetici per la determinazione degli indici. Dall’altro lato un AVL
Tree occupa spazio, perché ogni nodo contiene il dato, un puntatore a un
figlio sinistro, uno a un figlio destro, e le informazioni di bilanciamento (Vedi
figura 2) .
Gli algoritmi di inserimento e cancellazione in un AVL-Tree bilanciano l'albero
riordinando i nodi dei sottoalberi (attraverso cioè una rotazione);la struttura
AVL-Tree è considerata bilanciata se, per ogni nodo, la profondità o
l’altezza dei due sottoalberi differisce al più di uno(invece nel B-Tree la
profondità deve essere uguale);
B-Tree:
Tale struttura è nota come struttura dati esterna alla memoria. La sua
caratteristica più evidente è che la dimensione del nodo può essere molto
grande per consentire a ogni nodo di contenere più valori.
La ricerca di un elemento è una ricerca binaria ma non è sempre fattibile
perchè dipende dalla dimensione di ogni nodo. Se nell’AVL-Tree il problema
era lo spazio, il B-Tree è molto più efficiente in tal senso perché le foglie
contengono solo dati(Vedi figura 3).
Per quanto riguarda le operazioni di inserimento e cancellazione di un B-Tree
esse mantengono l'albero bilanciato dividendo o unendo i nodi e spostando i
dati all'interno o tra nodi; nel caso degli indici che si utilizzano in un B-Tree in
memoria principale ,solo i puntatori ai dati vengono spostati.
Dove è possibile utilizzare questa struttura? Perchè? Dato che lo spazio
occupato è poco(la dimensione dei puntatori è piccola e i nodi foglia
mantengono solo i dati),la ricerca è rapida(i nodi vengono ricercati tramite una
ricerca binaria) e l’aggiornamento di un nodo è rapido(la spostamento dei dati
riguarda un nodo) la struttura è adatta per essere utilizzata per i database in
memoria principale;
Chained Bucket Hashing
E’ una struttura statica usata sia in memoria che sul disco. La staticità della
struttura mi consente di accedere molto rapidamente e riorganizzare i dati
efficientemente. Tuttavia questo vantaggio è anche il suo svantaggio perché se
è statica può avere un pessimo comportamento in un ambiente dinamico dato
che la dimensione della tabella di hash deve essere nota o stimata prima che la
tabella si riempa;
Extendible Hashing
impiega una tabella di hash dinamica dove la dimensione cresce con
l’aumentare dei dati, quindi in questo caso non occorre conoscere in anticipo la
dimensione della tabella.
2.4 T-Tree
E’ un evoluzione di un AVL-Tree e di un B-Tree. Si tratta di una struttura dati ad
albero binario dove in ogni nodo ci sono molti elementi. Prende i vantaggi sia di
AVL-Tree per la ricerca binaria che di un B-Tree che possiede buone caratteristiche di
memorizzazione e aggiornamento.
Mentre il nodo di un AVL-Tree ha due puntatori figli più un informazione di
bilanciamento e un dato, un nodo T-Tree è identico ma si distingue per il numero di
dati(vedi figura). Lo spostamento dei dati viene richiesto per inserimento e
l’eliminazione, ma in genere si applica solo all’interno dei nodi.
Per quanto riguarda le operazioni che si possono fare sulla struttura oltre
all’inserimento, la cancellazione e la ricerca c’è da aggiungere l’operazione di
rotazione per ottenere il bilanciamento dell’albero che si fa allo stesso modo di come
la si applica su un AVL-Tree(argomento oggetto di interesse nella sezioni successive).
Terminologia
Ci sono 3 differenti tipi di T-Node(Figura 4):
o
o
o
Un T-Node che ha 2 sottoalberi viene chiamato internal node;
Un T-Node che possiede un puntatore figlio non nullo e l’altro nullo
viene chiamato half-leaf node.
Un nodo che ha due puntatori nulli viene chiamato leaf-node.
Per ogni nodo interno A abbiamo una foglia corrispondete(o half-leaf Node) che
conserva il valore ,rappresenta il predecessore del minimo valore in A, e c’è un leaf
Node(o half-leaf Node) che conserva il successore al massimo valore in A. Il valore
del predecessore viene chiamato the Greatest Lower Bound del nodo interno A, e il
valore del successore viene chiamato Least Upper Bound di A(Figura 5).
Dal momento che i dati in un T-Node vengono memorizzati in modo ordinato, il suo
elemento più a sinistra è l'elemento più piccolo del nodo e il suo elemento più a
destra è il più grande.
2.5 T-Tree: Algoritmi di ricerca e di aggiornamento
2.5.1 Algoritmo di ricerca
In un T Tree la ricerca è simile alla ricerca negli alberi binari. La differenza
sostanziale è che i confronti vengono effettuati con il valore massimo e il valore
minimo del nodo piuttosto che con un singolo valore del nodo di un albero binario.
I passi per la ricerca sono i seguenti:
1)La ricerca comincia sempre dal nodo radice dell’albero;
2)se il valore ricercato è più piccolo del più piccolo valore del nodo la ricerca
prosegue lungo il sottoalbero di sinistra. Altrimenti se il valore è più grande del
massimo valore del nodo, allora la ricerca prosegue nel sottoalbero di destra.
Altrimenti la ricerca viene effettuata nel nodo puntato.
Può capitare che la ricerca non vada a buon fine per i seguenti motivi:
-O quando il nodo viene trovato ma non viene trovato il valore;
-Oppure quando il nodo non viene trovato perché il valore ricercato non cade
in nessun intervallo di valori del nodo
2.5.2 Algoritmo di inserimento
L’algoritmo di inserimento comincia con una ricerca. In particolare il percorso dalla
radice alla foglia viene salvato sullo stack.
Se il T-Tree non è bilanciato dopo un inserimento o una cancellazione, esistono delle
particolari operazioni di riequilibrio che controllano i nodi tra il nodo radice ed il
figlio dove è avvenuto l’inserimento o la cancellazione.
L’algoritmo di inserimento opera nel seguente modo:
1)ricerca il nodo limite ,si salva il nodo e la direzione(destra o sinistra) effettuata a
ogni livello sullo stack;
2)se il nodo viene trovato ,bisogna verificare se c’è lo spazio per un altro elemento.
In caso affermativo si inserisce il nodo e ci si ferma. Altrimenti, bisogna rimuovere
l’elemento più piccolo dal nodo, inserire il vecchio ,inserire il valore ,e rendere
l’elemento più piccolo il nuovo valore inserito.
- A questo punto si fanno le stesse operazioni del punto 1(nel caso peggiore,
l’elemento più piccolo verrà inserito in una foglia diventando il new greatest
lower bound value per questo nodo);
3)Se la ricerca giunge alla fine dell’albero e non è stato trovato nessuno nodo che
delimita il valore dell’inserimento, inserisci il valore nell’ultimo nodo(nodo foglia o
mezza foglia).
-Se il valore viene inserito, esso diventa il massimo o il minimo del nodo;
In caso contrario, crea un nuovo figlio(quindi il valore inserito diventa il primo
elemento del nuovo figlio);
4)Se viene aggiunto un altro nodo foglia, bisogna controllare il bilanciamento
dell’albero attraverso il percorso salvato sullo stack.
-Per ogni nodo nel percorso di ricerca(partendo dalla foglia alla radice),se due
sottoalberi di un nodo differiscono per la profondità di uno o più livelli ,deve
essere effettuata una rotazione. Una vola che la rotazione è stata effettuata
l’albero viene ribilanciato e l’elaborazione termina
Si fa notare che quando il valore minimo viene rimosso e va ad aggiungersi a un nodo
foglia, l’inserimento del valore nella foglia non richiede alcuno spostamento dei dati
perché diventa il valore più a destra della foglia; se invece veniva rimosso il valore
massimo dal nodo bisognava inserirlo come elemento più a sinistra del nodo foglia
cosa che richiede un spostamento dei dati all’interno del nodo. Quindi rimuovendo il
valore minimo invece del massimo si evita questo spostamento dei dati.
2.5.3 Algoritmo di eliminazione
L'algoritmo di cancellazione è simile all'algoritmo di inserimento nel senso che
l'elemento da cancellare viene cercato, il percorso di ricerca viene salvato sullo stack,
ed eventualmente si effettua il rebalancing.
L’algoritmo opera in questo modo:
1)Trova il nodo che delimita il valore da cancellare ,salvando il percorso di ricerca
sullo stack. Ricerca il valore da eliminare all’interno di questo nodo riportando un
errore se il valore non viene trovato;
2) Se la cancellazione non causerà un underflow (cioè se il nodo ha più del numero
minimo consentito di elementi prima della cancellazione), quindi è sufficiente
eliminare il valore e fermarsi; Altrimenti, se si tratta di un nodo interno, bisogna
eliminare il valore e prendere in prestito il più grande limite inferiore di questo nodo
da una foglia o mezza foglia per riportare il numero di elementi del nodo al minimo;
salva il percorso di ricerca sullo stack durante la ricerca del limite inferiore più
grande .
Nel caso in cui si tratta di una foglia o una mezza foglia, basta semplicemente
cancellare l’elemento(half-leaves vengono gestite al passo 3);
3)A questo punto lo stack conterrà un percorso dalla radice alla foglia o mezza foglia
in cui un elemento è stato rimosso. Se il nodo in cima allo stack (cioè l’ultimo nodo
memorizzato)è una mezza foglia e possiede un numero di elementi inferiore al
numero minimo, allora bisognerà prendere un elemento dal suo unico figlio e
memorizzare il figlio sullo stack;
4)Se la foglia in cima allo stack non è vuota bisogna fermarsi, altrimenti occorre
liberare il nodo e procedere in questo modo per ribilanciare l’albero:
° Per ogni nodo lungo il percorso dalla foglia fino alla radice, se i due
sottoalberi del nodo differiscono in altezza per più di uno, allora bisogna
eseguire un'operazione di rotazione (vedi in sezioni successive). Poiché una
rotazione ad un nodo può provocare uno squilibrio per un nodo più in alto nella
struttura, il controllo del bilanciamento per l'eliminazione deve esaminare tutti i
nodi del percorso di ricerca;
2.6 Rebalancing
L’equilibrio di un T-Tree viene verificato ogni volta che una foglia viene aggiunta o
cancellata, esattamente come indicato quando abbiamo parlato di algoritmi di
cancellazione e inserimento. Il percorso di ricerca memorizzato sullo stack viene
controllato dalla radice alla foglia-per ogni nodo del percorso, se il nodo con 2
sottoalberi presentano una profondità maggiore di uno allora è necessaria un
operazione di rotazione.
Nel caso di un inserimento, al più una rotazione è necessaria per ribilanciare l’albero,
e dopo la prima rotazione il processo termina. Una rotazione su un nodo può
innescare uno squilibrio per un nodo più in alto nella struttura in caso di
cancellazione, in questo modo elaborazione continua lungo tutto il percorso fino alla
radice.
La figura 6 mostra una rotazione LL e una rotazione LR più complessa nel caso di
un inserimento. Questi sono 2 dei 4 tipi di rotazione utilizzate per ribilanciare un
AVL-Tree o un T- Tree(Gli algoritmi per la Rotazione RR e RL sono simmetrici a LL
e LR e non vengono mostrati).
Figura 6
Quando viene realizzata una rotazione LR o RL e il nodo C è una foglia (quindi
entrambi i nodi A e B sono mezze foglie), una rotazione sposterebbe C in una
posizione di nodo interna(vedi la figura 7).
Figura 7
Il ribilanciamento dopo la cancellazione è identico al ribilanciamento dopo
l’inserimento , ma la causa dello squilibrio nell'albero è che un sottoalbero è cresciuto
di meno rispetto a quello più lungo. La Figura 8 mostra le rotazioni LL e LR nel
caso di un'operazione di cancellazione.
Figura 8
2.7 Performance degli algoritmi e delle strutture dati
Inserimento
Il grafico 9 mostra i risultati del test di inserimento.
In particolare si osserva che il costo di un serie di inserimenti dipende dal tempo di
ricerca e dal numero di spostamenti che vengono effettuati per inserire un dato
elemento .
Il costo di inserimento per la struttura array non viene illustrato perché è dieci volte
maggiore rispetto a tutti gli altri indici dovuto a un enorme spostamento di dati
quando esso è molto grande.
Gli indici di una tabella hash non richiedono movimento di dati perchè il nuovo
elemento viene semplicemente accodato ai valori nel nodo di conseguenza il tempo
di ricerca di questi indici è quindi costante e dipende dalla dimensione del nodo;
-se aumenta la dimensione del nodo aumenta anche il tempo di ricerca.
Invece per il T-Tree, il costo della ricerca è O(log2 N),dove N rappresenta il numero
di elementi, di conseguenza all’aumentare del numero di elementi nel nodo cresce il
tempo di inserimento(dal grafico si osserva che la variazione è molto piccola per
valori grandi di N).
La ricerca all’interno di un albero AVL è più rapida della ricerca compiuta in un BTree, ma il B-Tree riesce ad avere un ribilanciamento più rapido rispetto al B-Tree.
-Il T-Tree ha i costi di inserimento del B-Tree(dal momento che può scorrere i
dati all’interno del nodo)e i costi di ricerca dell’albero AVL(perché la ricerca è
binaria).
Conclusione: Il T -Tree offre performance ottime nell’inserimento
Grafico 9
Ricerca
Il grafico 10 mostra i risultati della ricerca. La ricerca nel T-Tree è simile alla ricerca
negli alberi AVL. Nel momento in cui viene individuato il nodo corretto, si applica la
ricerca binaria su tale nodo. Ciò rende il costo della ricerca di un elemento in un TTree leggermente superiore alla ricerca in un albero AVL.
Grafico 10
Eliminazione
Grafico mostra i risultati del test della cancellazione. In particolare per ogni struttura
è stato applicato l’algoritmo al fine di eliminare metà degli elementi. Le strutture di
hashing sono le migliori in termini tempi di eliminazione.
Dal grafico 11 si osserva che i tempi di eliminazione del B-Tree si riducono per nodi
di dimensione maggiori, invece per i T-Tree il tempo di eliminazione degli elementi
è direttamente proporzionale al numero degli elementi presenti in ogni nodo.
Costi di memorizzazione di ogni struttura
Il grafico 12 mostra il costo totale medio di memorizzazione (in byte) per ciascuna
delle strutture di dati. Il costo totale di memorizzazione è semplicemente il numero
totale di byte necessari per contenere i dati della struttura.
L’albero AVL e la struttura Array rappresentano rispettivamente il limite superiore e
il limite inferiore dei costi di memorizzazione la differenza è determinante dal fatto
che in un nodo del AVL-Tree non c’è solo il valore del dato ma ci sono anche
informazioni come le informazioni di controllo.
Il B-Tree e il T-Tree hanno dei costi di memorizzazione quasi identici dal momento
che strutturalmente sono piuttosto uguali.
Grafico 12
Conclusioni
Perché per i database in memoria principale si usa la struttura T-Tree?
Gli alberi AVL hanno una buona ricerca e tempi di esecuzione molto onesti nelle
operazioni di aggiornamento quali inserimento e cancellazione ,ma hanno elevati
costi di memorizzazione per cui non sono così tanto adatti ai database in memoria
principale .
Gli array hanno un tempo ricerca ragionevole e dei costi di memorizzazione bassi per
via della loro struttura, ma ogni attività di aggiornamento comporta tempi di
esecuzione molto elevati rispetto alle altre strutture T-Tree e B-Tree, hanno bassi
costi di memorizzazione ma non sempre .Il tutto è legato alla dimensione dei nodi che
solo per alcuni valori offre buone prestazioni .
Il T-Tree sembra essere il migliore per il semplice motivo che si comporta in maniera
molto buona in tutte le operazioni che si fanno su di esso e anche in termini di costi di
memorizzazione(Figura 13)
Figura 13 - Confronto fra gli indici
Capitolo 3
Recovery
Introduzione
In un database di memoria principale (MMDB) la copia principale del database
risiede nella memoria voltatile. Di conseguenza i sistemi MMDB sono più vulnerabili
ai guasti rispetto database tradizionali residenti sul disco. Una copia di backup del
database deve essere mantenuta in memoria secondaria per un eventuale ripristino.
Molto importante durante il recovery di un database in memoria principale è che il
tempo di recupero aumenta quasi linearmente con l'aumento delle dimensioni del
database cioè aumenta all’aumentare del numero di tuple nel database.
La percezione di dove risiedono i dati è fondamentale. Mentre per un DBMS i dati
vengono memorizzati su disco e sono necessarie delle operazioni di I/O per accedere
ai dati ,nei sistemi MMDB non è necessario eseguire le operazioni di I / O. Pertanto,
essi sono adatti per applicazioni che richiedono un throughput alto e un tempo di
risposta veloce.
Una architettura generale MMDB consiste di una memoria principale implementata
tramite una RAM standard e talvolta anche una memoria non volatile . La memoria
principale contiene la copia principale del database, mentre la memoria stabile tiene il
registro e una copia di backup del database. La memoria non volatile è destinata
anche a contenere aggiornamenti eseguiti attraverso le transazioni mentre il log
contiene le informazioni relativi a questi aggiornamenti .E’ evidente che per
soddisfare le elevate prestazioni richieste in presenza molte applicazioni in tempo
reale, i MMDB sono naturalmente più vulnerabili a fallimenti rispetto ai DRDB. Di
conseguenza, il recovery di un componente di un MMDB deve essere adeguatamente
progettato, implementato e mantenuto.
Le attività di recovery, hanno il solo scopo di riportare il database in uno stato
consistente dopo un crash di sistema che si è verificato durante il funzionamento. E’
il recovery manager di un sistema di elaborazione delle transazioni responsabile di
mantenere la consistenza del sistema di database a seguito di crash del sistema e
delle transazioni.
Tre sono gli aspetti del recovery del sottosistema che servono a garantire a un
MMDB la possibilità di recuperare da qualsiasi guasto: logging, checkpoint e
reloding. Il Logging conserva un registro delle attività di aggiornamento che si
verificano durante l'esecuzione di una transazione. Il Checkpointing “scatta una foto”
del database periodicamente e lo copia su un dispositivo di archiviazione per scopi di
backup. A seguito di un crash di sistema, la ricarica ripristina il database in uno stato
consistente. In particolare viene ricaricata nella memoria principale la copia di
backup che è stata registrata durante l'ultimo checkpoint.
Nel seguito saranno affrontati il Logging e il Reloding nei database in memoria
principale ma non il Ckeckpoint per motivi implementativi.
3.2 Logging
Nel logging MMDB, l’ informazioni di registro può essere registrata a due diversi
livelli di astrazione, soprannominati physical logging e logic logging. I record del
livello fisico mantengono, per ogni aggiornamento, lo stato delle modifiche del
database e la posizione fisica (ad esempio id pagina e offset) a cui viene applicato
l'aggiornamento. I record del livello logico registrano le transizione di stato del
database e la posizione logica interessata dall'aggiornamento.
Lo svantaggio della registrazione logica è determinato dalla sua complessità sia
durante la normale elaborazione che durante il recupero poichè devono essere prese
misure per garantire che ogni azione commessa venga eseguita esattamente una volta
e allo stesso modo.
Il Write Ahead Logging (WAL) è il tipo di protocollo di logging più
utilizzato, in cui i dati di log devono essere scritti nella memoria non
volatile prima che l'aggiornamento possa riguardare il database. Il protocollo WAL
assicura che gli effetti delle transazioni che non sono andati a buon fine(uncommited)
possono essere annullati.
Per le transazioni committed, il DBMS deve sempre riflettere gli aggiornamenti
indipendentemente dai crash di sistema. In questo modo, quando un transazione va a
buon fine, l’ informazioni REDO che è stato scritto da tale transazione dovrebbe
essere memorizzata su di una memoria non volatile.
3.3 Reloading
Rappresenta una della parti più importanti del processo di ripristino.
Lo scopo del Reloading è quello di garantire che il database sia consistente dopo un
crash. Il database viene caricato dall'ultima immagine controllata e le operazioni di
undo(annullamento) e redo(ripetizione) vengono applicate per ripristinare al più
recente stato coerente. Gli schemi di reloading esistenti possono essere suddivisi in
due classi distinte per complessità e efficienza: simple reloading e cuncurrent
reloading. Nel reloding semplice, il sistema non riprende il suo normale
funzionamento fino a quando l'intero database viene ripristinato nella memoria
principale. Nel reloading parallelo, le attività di ricarica e di elaborazione delle
transazioni vengono eseguiti in parallelo.
Conclusioni
E’ stato spiegato che gli IMBD, sono sistemi di basi dati in memoria centrale che
utilizzano la memoria principale per la memorizzazione dei dati. Inoltre sono veloci
di quelli su memorie di massa, ma possono gestire moli di dati molto inferiori, a patto
che ci sia comunque un modo per recuperarli in caso di guasti mediante ad esempio
tecniche di ripristino.
Successivamente è stato affrontato anche il problema di come sonio implementate le
strutture dati nei IMDB attraverso non un approccio relazionale (tabelle)ma tramite i
puntatori e gli alberi .
Infine sono state affrontate alcune tecniche di ripristino per recuperare il sistema da
aventuali malfunzionamenti
Riferimenti
[1] http://www.mcobject.com/in_memory_database
[2] http://www.odbms.org/blog/2012/03/in-memory-database-systems-interviewwith-steve-graves-mcobject/
[3]A study of index for Main Memory Database Managment System di Lehman e
Micheal
[4]Recovery system for main memory database di Gupta Anaurg,Han Chen
[5]MMDB Micheal Lobert e Anders Pedersen
[6]Query processing in Main memory Database Management System
Ringraziamenti
Ringrazio tutti I professori con cui ho avuto il piacere di sostenere gli esami fino ad
oggi ,in particolare il prof . Picariello Antonio che mi ha dato anche il piacere di
sostenere un l’esame di basi dati con lui. Ringrazio la mia ragazza Monica che
veramente merita una statua per quello che ha fatto per me durante questi anni ,i miei
genitori che mi hanno dato la possibilità di realizzare questo sogno e infine tutti i miei
amici che mi sono stati accanto.
Grazie a Tutti
Maritato Luigi