COMUNICATO STAMPA
Vedere una perdita come un guadagno: conoscere il contesto di
scelta fa cambiare i circuiti cerebrali che elaborano l’esito delle
nostre decisioni
Lo rivela uno studio dei ricercatori del CIMeC apparso oggi sulla rivista Nature
Communications
TRENTO (Italia) – Tramite punizione o ricompensa? Il dibattito su quale sia la strategia di
apprendimento più efficace continua. Come reagiamo all’esito delle nostre azioni e delle
nostre scelte, sociali o squisitamente economiche, infatti, influenza le nostre decisioni future.
È dunque naturale che si indaghino questi meccanismi, con l’obiettivo di capire anche quale
sia la strategia di apprendimento più rapida ed efficace. Di questo si è occupato uno studio
appena apparso su Nature Communications del neuroeconomista Giorgio Coricelli del
Centro Mente/Cervello dell’Università degli Studi di Trento e collaboratori che hanno
cercato di affrontare i due principali problemi irrisolti dell’apprendimento per punizione che
è tanto efficace quanto quello per ricompensa.
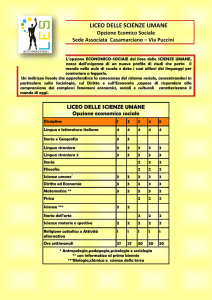
I DUE ASPETTI DA CHIARIRE: COMPUTAZIONALE E ANATOMICO
Negli ultimi anni si sono fatti moltissimi progressi nella comprensione delle basi neuronali
e computazionali dell’apprendimento per rinforzo basato sulle ricompense
(reinforcement learning). Di contro, i meccanismi computazionali e neuronali
dell’apprendimento per punizione, in cui bisogna apprendere il modo migliore per evitare la
perdita maggiore, non sono ancora stati chiariti.
Il primo problema è computazionale, infatti, l’apprendimento basato sulla punizione
presenta un apparente paradosso: «Quando si evita una punizione con successo, la risposta
strumentale (cioè l’azione che permette di evitare la punizione) non è più rinforzata. Come
conseguenza, i modelli teorici d’apprendimento di base predicono una performance migliore
per l’apprendimento per ricompensa (dove l’azione che conduce ad una ricompensa viene
scelta con maggiore probabilità in futuro, i.e. rinforzo positivo) rispetto all’apprendimento per
evitamento della punizione, contrariamente al fatto che i soggetti umani mostrano la stessa
performance di apprendimento nei due contesti» spiega il professor Giorgio Coricelli.
Il secondo problema è neuroanatomico: «Un dibattito aperto nelle neuroscienze cognitive
riguarda il fatto che le stesse aree cerebrali (lo striato e la corteccia ventrale prefrontale)
rappresentino sia valori positivi che negativi, o alternativamente che l’apprendimento e la
codifica dell’apprendimento per punizione avvenga in un sistema neuronale opposto
(“opponent system”, composto dall’insula e la corteccia dorso mediana prefrontale) a quello
della ricompensa».
L’IPOTESI DI LAVORO: TUTTO DIPENDE DAL CONTESTO
I ricercatori hanno ipotizzato che una soluzione dei due problemi possa venire considerando
la contestualizzazione del valore, in altre parole dalla capacità del cervello di
contestualizzare le opzioni di scelta, cioè di valutarle in modo relativo alle altre opzioni
presenti nel contesto decisionale. Quindi, per esempio, una perdita minore in un contesto di
perdite potrebbe essere considerata come un risultato positivo, alla stregue di una
ricompensa. Inoltre, «risultati divergenti di studi di risonanza magnetica funzionale relativi
alle differenze tra apprendimento per ricompensa vs. apprendimento per punizione
potrebbero essere riconciliati dal fatto che in assenza di informazione contestuale, la
punizione e le ricompense potrebbero essere computate da due sistemi separati;
mentre, in seguito all’acquisizione dell’informazione contestuale (cioè l’identificazione chiara
del contesto di scelta) la rappresentazione del valore assegnato ad ogni opzione di scelta
convergerebbe su un unico sistema composto dalla corteccia frontale e dallo striato».
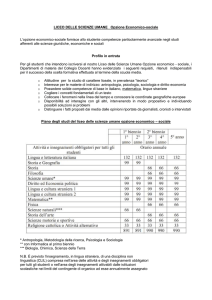
LO STUDIO
Nel corso dell’esperimento, partecipanti sani sono stati sottoposti alla risonanza magnetica
funzionale durante un compito comportamentale di apprendimento, riguardante una serie di
scelte tra due opzioni (due simboli che indicavano due slot machines, un compito chiamato in
inglese: two-armed bandit), in cui una delle due opzioni è migliore rispetto all’altra, e seguito
da un compito di verifica dell’apprendimento dei valori di ogni opzione di scelta.
Nel contesto delle ricompense, con l’opzione migliore si poteva vincere 0.5€ il 75% delle
volte o altrimenti ottenere 0€ e con l’altra opzione si vinceva 0.5€ solo il 25% delle volte;
mentre nel contesto delle punizioni, con l’opzione migliore si perdeva -0.5€ il 25% delle volte
e 75% si otteneva 0€ e con l’opzione più sfavorevole si perdeva -0.5€ il 75% e 0€ per il 25%
delle volte in cui si sceglieva tale opzione.
Il compito presentava due caratteristiche fondamentali: in primo luogo il compito confrontava
l’apprendimento per ricompensa (in cui i risultati possibili erano 0.5€ o 0€) con quello per
punizione (in cui i risultati possibili erano -0.5€ o 0€); in secondo luogo, in contesti di scelta
specifici, venivano presentati i risultati dell’opzione scelta e di quella rifiutata, questo per
indurre una valutazione relativa del risultato ottenuto con quello che si sarebbe potuto
ottenere con la scelta alternativa (outcome controfattuale). Questa procedura sperimentale
(cioè il confronto tra informazione parziale e informazione completa) è stata introdotta per
indurre l’apprendimento del valore medio del contesto di scelta (cioè il valore del contesto,
“context value”).
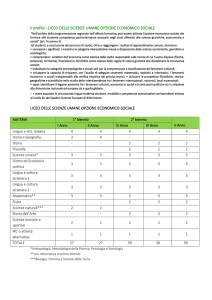
RISULTATI: DALL’INSULA ALLO STRIATO
«Abbiamo trovato evidenza comportamentale e neuronale coerente con l’idea che presentare
sia il risultato dell’opzione scelta sia quello dell’opzione non scelta (outcome
controfattuale) favorisca l’apprendimento di un “reference point” specifico del
contesto» hanno spiegato il responsabile dello studio Giorgio Coricelli e il primo autore dello
studio Stefano Palminteri dell’Institute of Cognitive Neuroscience (ICN) dell’University
College London (UCL). «A conferma delle predizioni del nostro modello computazionale dei
valori relativi, i risultati comportamentali illustrano come i partecipanti abbiano imparato
ugualmente bene nei contesti di ricompense o punizioni».
Inoltre, il circuito che elabora l’esito della nostra scelta cambia e diventa quello della
ricompensa perché, anche se di fatto non vinciamo, non perdiamo tanto quanto
avremmo potuto. Inoltre, i dati di risonanza hanno permesso di riconciliare dati sperimentali
di studi precedenti che erano considerati contraddittori. «Infatti, l’aumento osservato della
discriminazione tra i due contesti (di ricompense e di punizioni) nella condizione di
informazione completa si è visto essere associato ad uno spostamento dell’elaborazione
neuronale dell’outcome negativo (i.e. punizione) dall’insula verso lo striato ventrale, a
dimostrazione della codifica della punizione e delle ricompense nella stessa struttura
neuronale».
Quindi il cervello è in grado di contestualizzare le opzioni di scelta e di utilizzare
efficientemente un'unica procedura di apprendimento sia nel contesto delle ricompense
che in quello delle punizioni.
Palminteri, S., Khamassi, M., Joffily, M., Coricelli, G. (2015). Contextual modulation of value
signals in reward and punishment learning. Nature Communications (in press)
10.1038/ncomms9096
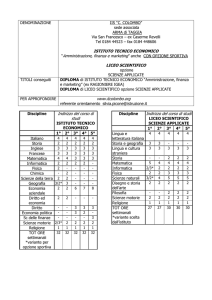
GIORGIO CORICELLI
Giorgio Coricelli è professore associato in Economia e Psicologia presso la University of
Southern California a Los Angeles e professore ordinario del Centro Interdipartimentale
Mente/Cervello (CIMeC) dell’Università degli Studi di Trento, dove è responsabile di un
progetto di ricerca Europeo (ERC), un consolidator grant di quasi 2 milioni di euro dal titolo
“Transfer learning within and between brains” (http://r.unitn.it/en/cimec/ldmg). Il professor
Coricelli si occupa di neuroeconomia, un approccio multidisciplinare (economia, psicologia e
neuroscienza) allo studio del comportamento economico. La sua ricerca riguarda il ruolo delle
emozioni, come il rimpianto, e dei processi cognitivi in contesti di scelte individuali e sociali. I
sui studi sono stati pubblicati in importanti riviste internazionali come Science, Nature
Neuroscience e PNAS.