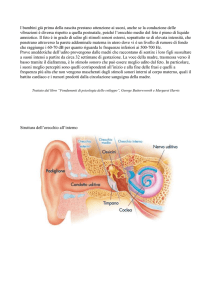
PERCEZIONE E ACUSTICA MUSICALE: SUONO E ORECCHIO
Roma - 2 aprile 2003
STRUTTURA TOPOLOGICA E METRICA DELLO SPAZIO
UDITIVO
Paolo Camiz
Dipartimento di Fisica - Università di Roma ”La Sapienza”
I.N.F.N Sezione di Roma - ECONA
Il titolo, alquanto ambizioso, nasce dall’esigenza di dare una struttura matematica chiara ad uno dei tanti spazi percettivi nei quali si sviluppano le nostre
esperienze sensoriali: l’idea può sembrare banale, almeno in certi casi, ma spero di
dimostrare che cosı̀ non è, e che nel caso uditivo il problema presenta alcune ambiguità che voglio discutere. Il caso apparentemente banale è quello della visione,
in cui una struttura topologica semplice (un continuo bidimensionale per ciascun
occhio) è indotta dalla natura stessa dell’apparato ottico, a parte il ”buco” rappresentato dal punto cieco; la situazione si complica leggermente quando si passa
alla stereovisione binoculare, che aggiunge una terza dimensione allo spazio visivo,
della quale però è accessibile, in un singolo atto visivo, solo una fetta più o meno
sottile in cui è garantita la fusione delle due immagini oculari; un’ulteriore coppia
di dimensioni (astratte) è aggiunta dalla visione cromatica che è supportata da un
continuo bidimensionale convesso. Senza addentrarmi ora in considerazioni metriche
che ci porterebbero via troppo tempo, voglio solo sottolineare il fatto che è possibile definire in modo non ambiguo una percezione visiva elementare costituita da
un punto luminoso di intensità e colore assegnato collocato in un certo punto dello
spazio, che una variazione infinitesima di uno qualsiasi dei parametri produce una
variazione infinitesima dello stimolo (a meno che questo non esca dal campo visivo), e infine che due punti non vengono distinti finché la loro distanza (comunque
misurata o valutata) non supera una certa soglia.
Vediamo ora che cosa si può dire delle percezioni uditive, limitandoci a quelle
monoaurali, per non doverci occupare anche della localizzazione delle sorgenti sonore.
E limitiamoci anche ai suoni di tipo stazionario, tali cioè che la loro distribuzione
spettrale non cambi durante un intervallo di tempo ”elementare” dell’ordine del
1
1/20sec. La domanda da fare è la seguente:”Sotto quali condizioni un suono del
genere può essere percepito come un solo ”punto”? Quali sono le dimensioni, la
topologia e la metrica dello spazio in cui questo punto viene collocato?” Una considerazione di tipo puramente fisico-matematico ci suggerisce di rappresentare i suoni
in base alla loro distribuzione spettrale, cioè le loro componenti di Fourier, e quindi
saremmo portati a dire che un suono puro è rappresentato da un punto sull’asse delle
frequenze, mentre un suono composto è rappresentato da molti (eventualmente infiniti) punti; oppure, in modo altrettanto coerente, potremmo dire che un suono è
un vettore in uno spazio a molte dimensioni (eventualmente infinite, o più realisticamente tante quanti sono i sensori dell’Organo del Corti), con una sola componente
non nulla per i suoni puri, con molte componenti per quelli composti. Tutto questo
va bene dal punto di vista fisico-matematico, ma è contraddetto dalla nostra esperienza uditiva, in base alla quale noi consideriamo come ”punti”, cioè esperienze
uditive elementari, non solo i suoni puri, ma anche moltissimi altri suoni che puri
non sono, come quelli emessi dalla nostra voce e dalla maggior parte degli strumenti
musicali; inoltre basta una piccolissima variazione in uno dei parametri che caratterizzano un suono composto, ma percepito come elementare, per farlo apparire come
due suoni indipendenti. Come si vede la situazione è abbastanza complessa: non
vale sempre il principio di sovrapposizione (come accade invece per i colori), e anche per la topologia e la metrica ci sono dei problemi: non è chiaro quante siano
le dimensioni dello spazio uditivo, è ambiguo il concetto di distanza tra due suoni
elementari, ed è facile convincersi che per passare con continuità da un punto ad un
altro di questo spazio sono possibili innumerevoli percorsi.
Consideriamo infatti come punto di partenza una nota cantata , per esempio Do1,
sulla vocale ”A”, e come punto di arrivo una nota un’ottava sopra, Do2, sempre cantata su ”A”. Un primo percorso, banale, consiste nell’effettuare un ”glissando” lungo
un’ottava mantenendo ferma la ”A”; un secondo percorso aggiunge alla variazione
continua di frequenza una variazione continua della vocale, secondo una traiettoria
chiusa del tipo ”A, È, É, I, Ű, U, Ó, Ò, A”; un terzo percorso, difficile da realizzare
con la voce, ma perfettamente simulabile con un sintetizzatore, consiste nel variare i pesi degli armonici in modo tale che la cosiddetta ”croma” rimanga Do, ma
passi da Do1 a Do2 solo modificando il timbro, e lasciando la vocale ferma in ”A”;
oppure, quarto percorso, aggiungere al precedente la traiettoria chiusa sulle vocali
del secondo percorso; e infine un percorso apparentemente paradossale, che consiste
nell’unire la tecnica della variazione timbrica a quella del glissando, effettuato in
senso inverso, cioè secondo una scala discendente per quanto riguarda la ”croma”.
Alcuni di questi percorsi sono mostrati nelle figure A e B.
Una parziale risposta a molte delle domande che le considerazioni precedenti suggeriscono viene fornita dalla natura stessa dei suoni che chiamiamo ”puntiformi”:
essi infatti hanno uno spettro armonico, cioè le frequenze delle componenti di Fourier
sono multiple di una frequenza fondamentale, non necessariamente presente nello
spettro (vedi il fenomeno percettivo del ”missing fundamental”): sembra allora di
poter dire che lo spettro armonico è una condizione necessaria, ma non sufficente,
2
affinché il suono percepito sia puntiforme: basta infatti far crescere una certa componente per farla apparire (a quale livello?) come un suono indipendente dal precedente; ma è anche vero che certi musicisti particolarmente dotati, ”distinguono” i
vari armonici, e per loro quindi i suoni puntiformi sono (quasi) soltanto quelli veramente monocromatici. Ma perché l’armonicità dello spettro produce (ma non sempre) la puntiformità della percezione? Un suono dallo spettro armonico ha lo stesso
periodo del fondamentale e questo fa intervenire l’analisi temporale del fenomeno; c’è
un altro elemento importante da prendere in considerazione: in un suono armonico
emesso da un’unica sorgente c’è una stretta relazione di fase tra le varie componenti,
mentre se le sorgenti sono numerose le fasi possono essere molto meno correlate. Da
quanto detto finora sembra di poter dire che la puntiformità di un suono sia una
proprietà non solo del suono, ma anche dell’orecchio che lo ascolta e probabilmente
anche della corteccia uditiva che elabora i segnali provenienti dall’orecchio e si evolve
in funzione dei segnali stessi.
Se le cose stanno in questo modo, ed è molto verosimile che lo siano, diventa
difficile rispondere in modo oggettivo alle domande che ci siamo posti all’inizio;
possiamo tuttavia affrontare il problema da un punto di vista culturale esaminando
l’esperienza musicale, più precisamente quella parte dell’esperienza musicale che si
concretizza nella musica occidentale moderna (tonale, armonica). Noi sappiamo che
questa musica si sviluppa su di un insieme di misura nulla lungo l’asse delle frequenze
(7 o 12 suoni all’interno di un’ottava); che i suoni che differiscono per una o più ottave
hanno lo stesso nome (croma); che la relazione tra le varie note è Doppler-invariante,
poiché riguarda i rapporti tra le frequenze, e che tra due suoni (puntiformi) si può
stabilire un criterio di consonanza o dissonanza che è una funzione rapidamente
oscillante del rapporto tra le frequenze, come indicato nella fig.1: da questo grafico
si può anche ricavare una valutazione della distanza (musicale) tra due suoni, che è
nulla per l’unisono, un po’ più grande per l’ottava, e via via crescente al calare della
consonanza, fino ad arrivare ad un massimo per il semitono e la quarta aumentata,
o addirittura ad un valore infinito per due fondamentali in rapporto irrazionale tra
loro, se accettiamo di uscire dall’insieme di misura nulla.
La situazione sembra paradossale perché si passa da una distanza ovviamente
nulla (l’unisono) ad una distanza che può essere molto grande, per una variazione
infinitesima del rapporto tra le frequenze: si esce dal paradosso se si considera il
fatto che i recettori dell’orecchio sono in numero finito e ognuno ha una risposta
di larghezza finita che in parte si sovrappone a quella del recettore adiacente. Se
adottiamo come criterio di consonanza una funzione che tenga conto degli armonici
in comune e della loro ampiezza, riusciamo a riprodurre la valutazione soggettiva
media: tale funzione può essere il prodotto scalare tra i vettori normalizzati nello
spazio di Hilbert delle distribuzioni spettrali, che non è altro che il coseno dell’angolo
tra i vettori: la tangente di questo angolo (che va da 0 a infinito) può essere assunta
come misura della distanza tra due suoni puntiformi.
E per i suoni puri che, essendo privi di armonici, non ne hanno alcuno in comune
e quindi hanno sempre distanza infinita? L’esperienza ci dice che non è cosı̀ e che
3
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
0
2
Figure 1:
4
6
8
10
12
Livello di consonanza all’interno di un’ottava.
la distanza segue, con oscillazioni meno ampie, l’andamento della fig.1. Come conciliare questi due fatti? Per esempio facendo intervenire lo sviluppo della corteccia
uditiva, addestrata dall’ascolto di suoni periodici (armonici), le voci umane e quelle
di molti animali, le quali emergono su un fondo rumoroso dallo spettro continuo: il
fatto che i recettori che distano di un’ottava, di una dodicesima, di una quinta, ecc.
cioè di quegli intervalli contenuti in uno spettro armonico, vengano stimolati simultaneamente da un suono semplicemente periodico, favorisce lo sviluppo di sinapsi
eccitatorie tra di loro, per cui la percezione corticale di un suono puro non differisce
di molto da quella di un suono con armonici.
Se questa idea è corretta, il concetto di consonanza, o di gradevolezza, trova una
corrispondenza nell’impegno computazionale della corteccia uditiva sotto l’azione
di uno stimolo sonoro: un suono puntiforme, che sia monocromatico o armonico,
impegna direttamente o indirettamente i neuroni armonici del suo fondamentale
(con ampiezze diverse), mentre una coppia di suoni ne eccita un maggior numero,
al massimo il doppio, quando i due suoni non hanno nessun armonico in comune, e
cosı̀ via, al crescere del numero dei suoni dell’accordo.
Vorrei ora spendere qualche parola sulla metrica e, tanto per cambiare, sulle
sue ambiguità; oltre alla metrica uditiva c’è quella ”manuale” dell’esecutore, che è
strettamente legata allo strumento: su uno strumento a tastiera le ottave sono tutte
uguali, circa 20 cm, mentre i semitoni possono essere leggermente diversi, secondo
che coinvolgano due tasti bianchi oppure uno bianco e uno nero; su uno strumento
ad arco i semitoni diventano sempre più piccoli, come distanza tra le dita, man
mano che dal capotasto ci si avvicina al ponticello, e sono ben diversi su un violino
o su un contrabbasso, anche se variano con la stessa legge; sugli stessi strumenti le
quinte sono invece tutte uguali, in quanto implicano solo lo spostamento di un dito
da una corda a quella adiacente; un discorso simile si potrebbe fare sugli strumenti
4
a fiato. Da un punto di vista matematico invece abbiamo due possibili metriche
sulla topologia unidimensionale: quella lineare, in cui le distanze sono rappresentate
dalla differenza tra le frequenze, e quindi le ottave (e anche tutti gli altri intervalli)
sono diversi secondo la loro collocazione; e quella logaritmica in cui le distanze
sono rappresentate dal logaritmo in base due del rapporto tra le frequenze, per cui
tutte le ottave hanno lunghezza unitaria. La metrica logaritmica è certamente più
adeguata alla rappresentazione musicale, tant’è vero che la scrittura musicale segue
appunto un codice logaritmico, sia nella rappresentazione delle altezze che in quella
delle durate; la scelta della base 2, che evidenzia il fatto che le note che distano di
un’ottava hanno lo stesso nome, può essere rappresentata graficamente arrotolando
l’asse dei logaritmi sulla superficie di un cilindro, in modo che le note di ugual nome
si trovino lungo la stessa verticale: in questo modo si introduce una coordinata
angolare che corrisponde alla ”croma”, mentre la coordinata verticale rappresenta
l’altezza (pitch); fig.C.
La struttura fisico-matematica del mondo dei suoni e degli strumenti musicali
ci ha mostrato un aspetto del problema, mentre l’esperienza musicale e qualche
congettura neurofisiologica ne hanno indicato un altro, forse soddisfacente, che però
necessita di qualche supporto oggettivo, che tenga anche conto del fatto che lo
sviluppo sinaptico fa parte della storia individuale, cioè della struttura anatomica e
dell’ambiente sorgente di stimoli. E rimangono ancora senza risposta le domande:
”Perché le note che distano di un’ottava hanno lo stesso nome? Perché, almeno
nella musica occidentale, l’ottava viene divisa, più o meno esattamente, in dodici
semitoni?
Una parziale risposta a queste e alle altre domande formulate poc’anzi è stata
data dalla tesi di laurea di Marco Beato che ha utilizzato nella sua ricerca la tecnica
delle reti neurali, in particolare della rete autoorganizzante di Kohonen: queste
reti hanno la capacità di organizzarsi (aggiornando i pesi sinaptici tra i neuroni
di un primo e quelli di un secondo strato) in modo tale che gli stimoli vengono
classificati in base ad un certo numero di categorie, rappresentate, sul secondo strato,
da regioni la cui maggiore o minore adiacenza indica la maggiore o minor somiglianza
tra le categorie, suggerendo quindi una topologia sullo spazio degli stimoli. Per
ragioni pratiche questa topologia è sostenuta da una superficie (2dim) toroidale, ma
il numero delle dimensioni potrebbe essere aumentato. Oltre ad un certo numero
di accorgimenti tecnici, necessari per controllare la convergenza della rete, la cosa
importante è la definizione del primo strato e degli stimoli che gli vengono proposti.
Nel nostro caso il primo strato voleva simulare un orecchio, ed era pertanto costituito da 60 unità risonanti distribuite su 5 ottave, quasi come una tastiera, mentre
il secondo aveva 30x30 unità distribuire sulla superficie di un toro. Gli stimoli erano rappresentati da suoni dotati di 16 armonici con ampiezze decrescenti con la
legge 1/n, con il fondamentale scelto a caso dentro le prime due ottave di sensibilità dell’orecchio; la risposta delle unità del primo strato era controllata da un
parametro che stabiliva la larghezza della gaussiana: da un minimo per cui ad un
suono monocromatico rispondeva solo il neurone accordato su quella frequenza e,
5
con ampiezza molto minore, i primi vicini, ad un massimo per cui la risposta coinvolgeva fino ai terzi vicini: in sostanza da un orecchio ”intonato” ad uno ”stonato”.
Con l’orecchio stonato i 25 suoni proposti hanno prodotto 25 ”bolle” in successione suggerendo una topologia unidimensionale aperta; migliorando l’intonazione
dell’orecchio c’è stata una radicale trasformazione delle bolle, che si sono raggruppate a coppie di suoni distanti un’ottava, e inoltre la successione di semitoni si è
rotta in 3 frammenti di 3 suoni ed è stata sostituita da due successioni di quinte di
6 suoni ciascuna, come si vede in fig.D.
Il fatto che l’ottava sia la prima fusione sistematica tra bolle risponde alla
prima domanda, ma mostra anche che questo risultato dipende dal potere risolutivo dell’orecchio e, ovviamente, dalla presenza degli armonici, che sono anche
responsabili della crescita del circolo delle quinte.
Per meglio esplorare la situazione abbiamo eliminato la seconda ottava e distribuito i venticinque suoni su una sola ottava, a distanza di un quarto di tono:
anche in questo caso l’orecchio stonato ha prodotto la solita topologia lineare, una
volta aperta e una volta chiusa; un orecchio di intonazione intermedia ha prodotto
una distribuzione di bolle in cui i contatti di quarto di tono diminuiscono mentre
quelli di quinta aumentano; naturalmente continuano ad essere presenti contatti
corrispondenti ad intervalli diversi, più o meno significativi. Con l’aumento del
potere risolutivo si assiste anche questa volta alla quasi scomparsa dei quarti di
tono e alla formazione di numerose successioni di quinte, quarte e terze maggiori.
Un altro aspetto significativo è la divisione dello spazio disponibile in (quasi)
due grandi bolle, in ciascuna delle quali si raccolgono i dodici suoni (caratterizzati
in figura da numeri pari o dispari) appartenenti alle due scale cromatiche distanziate
di un quarto di tono; vedi figg.E,F,G,H.
L’interesse di questi risultati sta nel fatto che la topologia dello spazio uditivo
diventa una caratteristica ”personale”, legata al potere risolutivo dell’orecchio, e
anche al tipo di stimoli che l’hanno colpito, perché stimoli con una struttura spettrale
diversa, o con spettro continuo o con spettro di righe non armoniche, sicuramente
favoriscono una topologia lineare aperta anche con un orecchio intonato. Anche
la divisione dell’ottava in dodici parti sembra che avvenga spontaneamente; per
confermare quest’ultimo risultato sarebbe necessario aumentare per esempio di un
fattore 10 il numero delle unità del primo strato, rendendo però molto più lungo il
tempo di convergenza della rete.
Ho seguito perciò un approccio completamente diverso, affrontando il problema
dell’incompatibilità del circolo delle 12 quinte, che non coprono esattamente 7 ottave,
ma danno un eccesso del 2/100: quante quinte sono necessarie per ottenere una
copertura migliore? Con 53 quinte si approssimano 31 ottave con un eccesso del
3/1000. Se dunque dividiamo l’ottava in 53 parti uguali, poco meno di un quarto
di semitono, e cerchiamo quali sono gli intervalli più importanti (prodotto delle
intensità) tra gli armonici di un fondamentale, troviamo il risultato di figg.2 e 3, che
mostra chiaramente che gli intervalli più importanti sono ottimamente approssimati
da uno dei 53 microintervalli proposti e sono anche quelli di maggior consonanza;
6
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
-0.1
0.2
0
Figure 2:
0.4
0.6
0.8
1
Intervalli tra 64 armonici rapportati all’ottava divisa in 12 semitoni.
tra questi è facile individuarne 12 che costituiscono la base della scala cromatica, e
prima ancora 7 che producono la scala diatonica.
Seguendo questa indicazione mi sono posto il seguente problema: supponendo che
un organismo dotato di voce, udito e memoria non riceva altri stimoli uditivi se non
quelli prodotti dalla propria voce, esiste una possibilità che i suoni emessi vengano
scelti in un sottoinsieme tra quelli disponibili e eventualmente quale? Ho quindi
simulato un processo di autoapprendimento selettivo in cui l’udito (e la corteccia uditiva) guidano la voce. Il processo è organizzato come segue: la voce ha
un’estensione di due ottave, ciascuna divisa in 53 parti, mentre l’orecchio è sensibile
su 4 ottave divise nello stesso modo, e la memoria è capace di ricordare un solo
suono; naturalmente i suoni sono dotati di 16 armonici. Inizialmente viene definita
una matrice simmetrica G di dimensione pari a quella dell’orecchio (212x212) con
elementi diagonali unitari ed elementi non diagonali piccoli e scelti a caso; il ciclo di
apprendimento consiste nell’emissione da parte della ”voce”di un suono scelto a caso
di componenti s1i , che viene ascoltato dall’”orecchio” e successivamnete memorizzato, e poi di un secondo s2i scelto anch’esso a caso; i due suoni vengono confrontati
per mezzo della matrice G nel modo seguente: essi vengono dapprima normalizzati e
poi viene calcolato il loro prodotto scalare secondo la metrica definita da G; il modulo del prodotto scalare < 1|G|2 >= s1i Gij s2j viene confrontato con una variabile
stocastica compresa tra 0 e 1: se supera il prodotto della variabile stocastica per una
certa soglia il secondo suono viene accettato e la matrice G viene incrementata della
quantità |2 >< 2|, altrimenti il suono viene rigettato e se ne estrae un terzo; in caso
di accettazione il secondo suono viene memorizzato e se ne estrae un successivo; il
procedimento viene iterato, e ad ogni accettazione viene registrato il suono accettato
e l’intervallo (in modulo) che esso forma con il suono precedente.
Nelle figg.4-7 sono mostrati gli intervalli prescelti per diversi valori della soglia e
7
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
-0.1
0.2
0
Figure 3:
0.4
0.6
0.8
1
Intervalli tra 64 armonici rapportati all’ottava divisa in 53 parti uguali.
del potere risolutivo dell’orecchio, messo inizialmente al suo massimo valore.
800
700
600
500
400
300
200
100
0
0
20
Figure 4:
40
60
80
100
Distribuzione degli intervalli; soglia=0. Potere risolutivo ottimale.
Come si vede a soglia zero non c’è alcuna selezione (fig.4), mentre già con soglia
pari 0.01 si nota la forte diminuzione di alcuni intervalli (fig.5),
i quali quasi scompaiono a soglia 0.4, lasciando un numero relativamente piccolo di
intervalli privilegiati, tra i quali si riconoscono immediatamente l’unisono, la seconda
maggiore, le due terze minori, la terza maggiore, la quarta giusta, la quinta giusta, la
sesta maggiore, la settima minore, l’ottava, ecc. mentre meno evidenti, ma presenti,
sono il semitono, la quarta aumentata, la sesta minore e la settima maggiore: in
pratica l’intera scala cromatica (fig.6). Val la pena di notare che le due terze minori,
8
800
700
600
500
400
300
200
100
0
0
20
Figure 5:
40
60
80
100
Distribuzione degli intervalli; soglia=0.01. Potere risolutivo ottimale.
che corrispondono ai rapporti di frequenza 6/5 e 7/6, risultano ben separate, mentre
la seconda maggiore risulta piuttosto larga, visto che è rappresentata, nella sequenza
armonica, dai rapporti 8/7, 9/8 e 10/9.
500
450
400
350
300
250
200
150
100
50
0
0
20
40
60
80
100
Figure 6:
Distribuzione degli intervalli; soglia=0.4. Potere risolutivo ottimale.
Posizione degli intervalli più significativi:1/1=0,16/15=5,10/9=8,9/8=9,8/7=10,7/6=12,
6/5=14,5/4=17,4/3=22,7/5=26,3/2=31,8/5=36,5/3=39,7/4=43,15/8=48,2/1=53.
Per ottenere questi risultati la divisione dell’ottava in 53 parti non è essenziale:
essa è tuttavia vantaggiosa perché, tra le tante possibili con un numero decisamente
maggiore di 12, è quella che permette di collocare con maggior precisione gli intervalli
più significativi, come illustrato in fig.6.
Queste simulazioni mostrano (ma non dimostrano) che la topologia e la metrica
9
dello spazio uditivo non possono essere definite in modo univoco, visto che il potere
risolutivo dell’orecchio, l’esperienza individuale, la presenza di armonici e la capacità
di sviluppo sinaptico contribuiscono in modo determinante al risultato; tuttavia
i risultati sono consistenti con quelli che derivano da un trattazione puramente
matematica del fenomeno sonoro e dall’esame del linguaggio musicale, in quanto
presentano le stesse ambiguità ma contemporaneamente ne indicano l’origine. Una
determinazione sperimentale della topologia e della metrica dello spazio uditivo non
può che passare attraverso un’indagine corticale (possibilmente non invasiva) di
lunga durata, capace di mettere in evidenza lo sviluppo sinaptico di uno o più
individui (non necessariamente umani) sottoposti a stimoli sonori opportunamente
scelti. È opportuno ricordare che indagini con la tecnica degli ”squid” hanno permesso di accertare qualitativamente la struttura tonotopica (logaritmica) della corteccia
uditiva in alcuni animali e nell’uomo.
800
700
600
500
400
300
200
100
0
0
20
Figure 7:
40
60
80
100
Distribuzione degli intervalli; soglia=0.4. Potere risolutivo ridotto.
Per quanto riguarda l’interazione voce-udito voglio presentare un ultimo risultato: peggiorando leggermente il potere risolutivo dell’orecchio diminuisce l’intonazione della voce, che non è più cosı̀ precisa nella scelta degli intervalli, i quali vengono
selezionati in modo incerto, anche se la distribuzione è ancora centrata sui valori
precedenti, come si vede nella fig.7, ottenuta con la soglia a 0.4, mentre la risposta
dell’orecchio ad un suono monocromatico non è più limitata al neurone centrale ma
coinvolge i due primi vicini con un’ampiezza ridotta al 20/100.
Se si analizza la distribuzione dei suoni accettati si vede che il risultato dipende
assai poco dal valore della soglia: a prima vista la cosa può sorprendere, perché ci si
aspetta che la voce, guidata dall’orecchio, finisca per preferire un ristretto insieme di
suoni; una riflessione più accurata mostra invece che la preferenza per certi intervalli
non implica l’esclusione totale degli altri, e quindi ep̀ossibile che ogni tanto venga
scelto un intervallo ”raro”, che trasferisca la voce su una differente intonazione; se
10
il ciclo di apprendimento è molto lungo (nel nostro caso sono stati estratti 40000
suoni), questo può accadere anche molte volte, e alla fine i suoni risultano grosso
modo equiprobabili, a meno delle inevitabili fluttuazioni statistiche.
La mia esperienza di direttore di coro mi ha insegnato che nel corso di una esecuzione ”a cappella”, cioè non sostenuta da strumenti, capita spesso che l’intonazione
locale sia perfetta, nel senso che tutti gli intervalli sono giusti (entro i limiti della
percezione), ma alla fine, specie se il brano è lungo, il coro sia calato (o cresciuto) rispetto al diapason di partenza: in altre parole si può dire che la somma
di tanti spostamenti infinitesimi produce uno spostamento finito; inoltre, nel corso
dell’addestramento dei cantanti, mi è capitato più volte di riscontrare un errore molto
particolare nell’intonazione dell’intervallo di ottava discendente, che viene sostituito
dalla quinta o dalla quarta discendente, molto lontani secondo una topologia lineare,
ma vicinissimi secondo una topologia armonica.
Mi sembra di poter dire, a conclusione di questo intervento, che le due simulazioni
che ho proposto sostengono il punto di vista musicale sulla topologia dello spazio
uditivo, con i limiti legati alle esperienze indiviuali. La musica, in quanto attività
che utilizza un insieme piccolissimo di suoni (rispetto a quelli possibili: circa 100
frequenze su un totale di 3000 recettori dell’orecchio interno) selezionato in seguito
ad un’esperienza, si propone quindi come una proprietà emergente, conseguenza
dell’interazione dell’apparato uditivo con un ambiente generatore di stimoli sonori
particolari o, in mancanza di quello, con l’apparato fonatorio. Sarebbe interessante
analizzare statisticamente il comportamento di un insieme abbastanza vasto di parlatori per vedere se, anche nel parlato, la distribuzione degli intervalli presenta dei
picchi di preferenza e, eventualmente, dove questi sono localizzati.
11