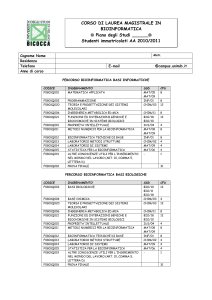
Bioinformatica e
Data Base
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
La bioinformatica include:
Un database biologico è un insieme di informazioni e dati strutturati e
organizzati in modo da essere consultabili e utilizzabili nel miglior
modo possibile, che provengono da
Database Biologici che raccolgono dati sperimentali prodotti nei laboratori
Software per la navigazione nei Data Base
studi in laboratori di ricerca (analisi sia in vitro che in vivo)
centri di bioinformatica (analisi in silico)
da pubblicazioni scientifiche
I database biologici oggi esistenti sono un migliaio, e viene catalogato
praticamente di tutto, dal genoma umano alle malattie, i geni, Rna,
polimorfismi ect...
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
Esistono tre grandi laboratori internazionali di bioinformatica
Uno europeo EMBL-EBI (http://www.ebi.ac.uk/embl/ )
Uno Americano NCBI (http://www.ncbi.nlm.nih.gov/genbank/)
Uno Giapponese GenomeNet (http://www.genome.jp/)
Molti database biologici sono state sviluppati da questi tre grandi
laboratori e contengono milioni di voci.
In rete esistono database biologici di due tipi
I database primari che raccolgono contengono le informazioni riguardanti il Dna
ossia le sequenze nucleotidiche (DNA, RNA) o proteiche e rendono disponibili
informazioni per identificare le specie da cui hanno origine le sequenze e le loro
funzioni.
I database derivati che raccolgono informazioni più specifiche sulla tassonomia,
le funzioni, le pubblicazioni scientifiche, le malattie correlate alle mutazioni, delle
sequenze nucleotidiche
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
I database primari contengono dei veri risultati sperimentali, ma
l’annotazione non è tipicamente curata, e le sequenze possono essere
di qualunque tipo (DNA, mRNa, CDS, EST …)
Problema sta nel formato dei dati che sono ideati per essere
manipolati solo dai computers.
Un esempio pratico è il formato flat file FASTA
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
Un secondo esempio pratico è il formato flat file GBFF
Un file GBFF contiene l’informazione su di una sequenza genomica,
divisa in tre parti
Header
features
sequence.
Il file finisce con il simbolo //.
La prima riga header del file GBFF è la riga del Locus.
La seconda riga header del file GBFF è la definition line.
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
La terza riga header del file GBFF è l’accession number, che è la
chiave primaria per identificare una certa sequenza.
Se la sequenza cambia (es: cambia un nucleotide) l’accesion number
è invariato ma il numero di versione (quarta riga del file GBFF) viene
incrementato di 1, mentre il gi (quarta riga del file GBFF) cambia del
tutto.
La riga delle keywords permette di aggiungere annotazioni manuali
alla sequenza considerata (!!! qui il vocabolario non è uniforme !!!).
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
Seguono una parte di source in cui sono riportate informazioni
sull’organismo da cui proviene la sequenza ed eventualmente la sua
tassonomia.
Poi una o più references, ed infine un comment (opzionale)..
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
La parte centrale del file GBFF è la parte della features, dove è scritta
l’informazione biologica relativa alla sequenza. Ci sono diversi tipi di
features:
La feature source specifica quale è
l’esatta provenienza della sequenza e
il tipo della sequenza che si sta
considerando.
La feature CDS contiene l’informazione
su come ottenere la sequenza di
amminoacidi corrispondente all’mRNA
considerato e la corrispondente
traduzione. Inoltre in questo campo
sono inclusi ids della traduzione,un
accession number e un identificativo gi
.
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
Infine la sequenza:
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
I tre principali database primari del DNA sono collegati ai tre laboratori
citati prima.
EMBL datalibrary (http://www.ebi.ac.uk/embl/)
GenBank. (http://www.ncbi.nlm.nih.gov/sites/entrez?db=nucleotide)
DDBJ (http://www.ddbj.nig.ac.jp/ )
Fra queste banche dati c’è un continuo scambio di dati, per cui tutte le
informazioni che potete trovare su una, le trovate anche sull’altra.
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
Tra i principali Database Biologic primari delle sequenze proteiche sono
Swiss-prot (http://web.expasy.org/docs/swiss-prot_guideline.html)
curata manualmente per cui poco ridondante e ricca di informazioni
TrEMBL nasce grazie alla traduzione automatica dei geni presenti in
EMBL datalibrary, per cui alcune delle proteine predette possono non
esistere nella realtà.
PIR http://pir.georgetown.edu/
Nel
2002
nasce
un
database
(http://www.ebi.ac.uk/uniprot/)
Master "Bio Info"
Reti e Basi di Dati Lezione 7
integrato
UniProt.
I Data Base e la Bioinformatica
I database Biologici derivati raggruppano solo dati relativi a specifici
argomenti, ad esempio:
Ensembl (http://www.ensembl.org) nato dalla collaborazione dell’ EMBL European Bioinformatics Institute (EBI) e il Wellcome Trust Sanger Institute
(WTSI) database del genoma dei vertebrati e di altre specie eucariotica,
OMIM,(Online
Mendelian
Inheritance
in
Man)
(http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=OMIM) raccolta dei geni
umani e delle malattie ad essi correlate, chiunque lavori nel campo delle
malattie genetiche e della biomedicina vi si ritrova costantemente a contatto
GENEATLAS: http://www.genatlas.org/ come OMIM, contiene informazioni utili a
chi opera nel campo della biomedicina e delle malattie genetiche.
PubMed,(http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?CMD=search&DB=pub
med) raggiungibile dal sistema dell’ NCBI Entrez è stato sviluppato dal National
Center for Biotechnology Information (NCBI) e dal National Library of Medicine
(NLM), permette l’accesso a informazioni bibliografiche scientifiche e mediche.
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
TAIR (The Arabidopsis Information Resource): http://www.arabidopsis.org/
Arabidopsis thaliana rappresenta la pianta modello nella sperimentazione
genomica, biomolecolare, evoluzionistica ed agrobiotecnologica, qui sono
disponibili ampie collezioni di mutanti ed il suo è stato il primo genoma vegetale
sequenziato. Il sito contiene un database annotato con sequenze genomiche,
trascritti e sequenze proteiche di Arabidopsis, nonchè link a risorse correlate
PDBsum (http://www.ebi.ac.uk/thornton-srv/databases/pdbsum)
raccolta dii
immagini che permette di avere una anteprima del contenuto delle srutture in
3D delle proteine che sono raccolte da Protein Data Bank (PDB).
SMART
Simple Modular Architecture Research Tool (http://smart.emblheidelberg.de/) basato sulla natura modulare delle proteine, ad esempio
contengono moduli funzionali (i domini) che sono rintracciabili perchè si
conservano evolutivamente. SMART permette di identificare i domini proteici e
di analizzarne la struttura, si sono classificati più di 500 famiglie di domini
coinvolti in fattori di trascrizione, proteine associate alla cromatina o
extracellulari, e tutti i domini sono annotati rispettando la distribuzione
filogenetica, la classe funzionale, la struttura terziaria e i residui funzionali più
importanti
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
Sistemi di Retrieval
Esistono dei sistemi integrati che permettono di interrogare i data base
biologici attraverso il web
I tre sistemi principali sono
Entrez http://www.ncbi.nlm.nih.gov/sites/gquery associato a GenBank.
SRS(http://srs.ebi.ac.uk/srsbin/cgi-bin/wgetz?-page+query+-libList+EMBL
associato a EMBL .
DBGET http://www.genome.jp/dbget/ associato a DDBJ .
I sistemi integrati forniscono una interfaccia WEB omogenea
Master "Bio Info"
Reti e Basi di Dati Lezione 7
I Data Base e la Bioinformatica
Gene Ontology http://www.geneontology.org/
La ricerca di tutte le informazioni disponibili su ciascuna piccola area di
ricerca è ostacolata dalla variazioni nella terminologia utilizzata
Gene Ontology(GO) è uno sforzo collaborativo per affrontare la
necessità di descrizioni coerenti di prodotti genici in database diversi.
GO ha sviluppato varie ontologie.
Component Ontology: Rules governing content and stylistic aspects of GO terms
in the cellular component ontology.
Molecular Function Ontology: Rules governing content and stylistic aspects of GO
terms, standard definitions and term relationships in the molecular function
ontology.
Biological Process Ontology: Rules governing content and stylistic aspects of GO
terms, standard definitions and term relationships in the biological process
ontology.
Species-Specific Terms: How the Gene Ontology deals with words or phrases
where the meaning varies depending on the organism.
Master "Bio Info"
Reti e Basi di Dati Lezione 7