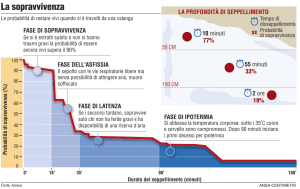
Analisi di sopravvivenza
Insieme di metodi statistici per l’analisi della distribuzione del tempo di
comparsa di un evento.
È una modalità di analisi per dati provenienti da studi di coorte che
consente di stimare la probabilità che un determinato evento si
produca in un determinato istante temporale.
Dati di sopravvivenza
Evento di interesse (morte, diagnosi, ricaduta, ...)
Tempo tra l’ingresso nello studio e l’evento di interesse
(tempo di sopravvivenza, durata)
Covariate (caratteristiche del paziente quali età, sesso, esposizione, ...)
caratteristiche peculiari dell’analisi
tempi di sopravvivenza non normali
soggetti con tempo di sopravvivenza non noto (osservazioni censurate)
Tempo di sopravvivenza
Il primo passo di un‘analisi di sopravvivenza è il calcolo del tempo di
sopravvivenza in base alla differenza tra istante di occorrenza
dell’evento e momento dell’ingresso nello studio.
Osservazioni troncate
Osservazioni troncate
Sono i soggetti che non hanno avuto l’evento di interesse durante il
periodo di osservazione (follow-up).
Censura del I tipo
Per questi soggetti il tempo di sopravvivenza non è noto, ma
sappiamo che sarà ! (uguale al/maggiore del) tempo di follow-up.
Censura casuale
Analisi di dati di sopravvivenza
Esistono altre situazioni che portano a dati troncati:
1. Il paziente ha avuto un evento differente da quello di interesse che ha reso
impossibile un ulteriore follow-up.
(Es.: Si è verificato un incidente oppure è morto per un’altra causa.)
2. Il paziente è perso al follow-up durante il periodo di studio.
(Es.: Non si presenta ai controlli programmati oppure è emigrato all’estero.)
I pazienti persi al follow-up potrebbero aver avuto l’evento di interesse dopo
che li abbiamo persi di vista.
Una proporzione alta di soggetti in questa condizione indica scarsa qualità
dello studio.
I tempi di sopravvivenza non sono normali
La distribuzione dei tempi di sopravvivenza è descritta da tre funzioni:
La maggior parte dei metodi statistici che vengono usati nell’analisi di
dati di sopravvivenza si basano sulle seguenti assunzioni:
1. Condizionatamente a quanto accaduto al tempo t, il meccanismo che
genera l’evento per individui diversi agisce in modo indipendente in (t, t+dt).
2. Il meccanismo di censura è indipendente dall'evento di interesse.
Lo schema di censura casuale con le variabili C (censura) e T (tempo di
sopravvivenza) indipendenti è uno dei più realistici e più semplici
schemi che soddisfa le due condizioni richieste.
Funzione di sopravvivenza
La funzione di sopravvivenza è la probabilità che l’evento di interesse
avvenga dopo un certo tempo t.
Se T è la variabile casuale “tempo di sopravvivenza”, allora:
S ! t "= P !T #t "
• Funzione di densità: f(t)
• Funzione di sopravvivenza: S(t)
• Funzione di rischio (hazard): h(t), !(t)
$ S(t) è non-crescente.
$ S(t) tende a zero quando t tende ad infinito.
$ S(0) = 1
Curva di sopravvivenza USA 1979-81
Esempi
Effetto del tabacco sulla curva di
sopravvivenza di maschi bianchi
oltre i trent’anni (studio del 1938)
Funzione di rischio
Effetto del tabacco sulla curva
di sopravvivenza di maschi
bianchi oltre i trent’anni (studio
del 1938).
La funzione di rischio è definita come la probabilità che l’evento accada al
tempo t condizionatamente al fatto che non si è verificato entro il tempo t.
P ! t &T 't (dt)T *t "
f !t "
=
# 0
dt
S !t "
dt % 0
h !t "= lim
Funzione di rischio per trapiantati
Esempi
trapianto cardiaco
Stima non parametrica
Modelli statistici
S ! t " = 1+F ! t "
f !t"
h !t " =
S !t "
f ! t " = h! t " S ! t "
d log S ! t "
h !t " = +
dt
I modelli statistici per l'analisi di dati
di sopravvivenza sono univocamente
specificati da una qualsiasi di queste
quantità.
Modelli parametrici
Modelli non parametrici
Le funzioni di sopravvivenza e le funzioni di rischio hanno spesso forme
molto particolari, difficilmente paragonabili a distribuzioni note. Questo è il
motivo per cui gli approcci non parametrici per la stima di S(t) e di h(t) hanno
preso il sopravvento nell’analisi dei dati di durata.
La presenza di dati censurati impedisce l’utilizzo dei classici metodi non
parametrici basati sui ranghi. In particolare, le procedure grafiche standard
quali gli istogrammi (o la funzione di ripartizione empirica) non possono
essere usati.
Abbiamo bisogno di un metodo che includa l’informazione derivante dai dati
censurati:
Stimatore di Kaplan-Meier
Stimatore di Kaplan-Meier
Stimatore di Kaplan-Meier
Si supponga di avere k pazienti che hanno l’evento di interesse nel periodo
di follow-up ai tempi distinti t1 < t2 < ! < ti-1 < ti < ! < tk.
In altri termini, avendo t1 < t2 < ! < ti-1 < ti < ! < tk, lo stimatore di KaplanMeier è definito da:
Poiché gli eventi sono tra loro indipendenti, la probabilità di sopravvivenza al
tempo ti può essere ottenuta moltiplicando la probabilità di superare il tempo
ti per la probabilità di aver superato i tempi precedenti [t1 " ti-1 ], ovvero:
! "
S i =S i+1 1+
di
ni
dove di è numero di eventi al tempo ti ed ni il numero di soggetti esposti al
rischio prima di ti.
Esempio
S, ! t "=t i &t
! "
ni +d i
ni
dove di è numero di eventi al tempo ti ed ni il numero di soggetti esposti al
rischio prima di ti.
$ nessun dato censurato: ni è il numero di soggetti a rischio prima di ti
$ dati censurati: ni è il numero di soggetti a rischio al tempo ti meno i
soggetti persi (unità censurate)
Esempio di calcolo
1, 2+, 3+, 4, 5+, 10,12+
C
D
Esempio di calcolo
Dati censurati: come influenzano la stima
In presenza di un dato censurato la curva non decresce come quando si ha
un evento. Infatti, a meno che la curva non abbia il segno marcatore del
valore censurato, la curva di per se non mostra cambiamenti ...
… In realtà, un dato censurato riduce il numero di pazienti che
contribuiscono alla stima della curva.
S(t) è costante nell’intervallo
temporale tra due eventi.
S(t) è una funzione a gradino che
cambia valore ogni volta si
verifica un evento.
La censura è indicata da una
barra verticale.
Dati censurati: come influenzano la stima
La parte della curva di sopravvivenza successiva al primo dato censurato è una stima
della sopravvivenza del gruppo, non la reale sopravvivenza.
Ogni evento successivo ad un evento censurato rappresenta una
proporzione maggiore della restante popolazione, da cui segue che ogni
scalino successivo ad un dato censurato sarà leggeremente più alto.
Quando ho un follow-up molto grande questo effetto difficilmente viene evidenziato
dall'analisi grafica.
Tempo di sopravvivenza mediano
Spesso si richiede di “riassumere” una curva di sopravvivenza,
sintesi che viene fatta utilizzando una statistica particolare.
Infatti, la reale sopravvivenza del gruppo studiato successiva al dato censurato non è
nota perché non è noto lo stato del soggetto perso.
dati asimmetrici ! tempo di sopravvivenza MEDIANO
La presenza di dati censurati diminuisce il numero di pazienti sotto osservazione
dopo la censura. ! Si riduce l'accuratezza della stima. ! La parte della curva più
affetta da questo fenomeno è ovviamente la parte finale.
Questo è un problema, dato che la parte finale della curva
rappresenta la sopravvivenza a lungo termine.
Definizione:
Il più piccolo tempo di sopravvivenza osservato per il quale il valore
della funzione di sopravvivenza è inferiore a 0.5
Intervallo di confidenza
Intervallo di confidenza
Per calcolare l'intervallo di confidenza per la funzione di sopravvivenza è
necessario stimare la varianza o deviazione standard di S(t).
Formula di Greenwood
Con la stima della varianza calcolata in questo modo si possono costruire
degli intervalli di confidenza sapendo che per ogni t > 0, S(t) è
approssimativamente una normale.
.
S, ! t " ± z !/2 V, [ S, ! t " ]
Confronto tra curve di sopravvivenza
Obiettivo abbastanza comune nell'analisi di dati di sopravvivenza è valutare
se gruppi diversi hanno funzioni di sopravvivenza significativamente diverse.
Ipotesi nulla: Tra i gruppi non vi è differenza nella sopravvivenza.
• Se tutti gli individui venissero seguiti per lo stesso periodo di tempo e non ci
fossero osservazioni censurate, avremmo uno studio caso-controllo, il ché ci
consentirebbe di usare i metodi sviluppati per questo tipo di studio.
• Se tutti gli individui venissero seguiti fino all’evento di interesse, potremmo
confrontare i momenti degli eventi di interesse nei gruppi diversi utilizzando
metodi non parametrici come il test di Mann-Whitney o di Kruskall-Wallis.
La presenza di dati censurati richiede l’uso di metodi ad hoc.
Gli intervalli di confidenza così costruiti a volte possono includere valori non
plausibili per la funzione di sopravvivenza, in particolare valori al di fuori di [0,1].
Questo può essere evitato applicando la formula precedente ad una
trasformata della curva di sopravvivenza per cui vi sia restrizione di valori:
la trasformazione logaritmica
,f !t "=ln!+ln! S, !t """
exponential Greenwood
Questa funzione non è limitata tra 0 e 1, quindi si può calcolare l’IC per f(t) per
poi ritrasformare l’intervallo nella scala originale.
Log-rank test
Alla base del log-rank test ci sono tre presupposti:
1. I due campioni sono campioni casuali indipendenti.
2. Le modalità di censura per le osservazioni sono le stesse per
entrambi i campioni.
3. Le due curve di sopravvivenza presentano rischi proporzionali
S2(t) = S1(t) !
dove ! è una costante chiamata tasso di rischio. (Il valore ! = 1
indica che le due curve sono uguali.)
Modelli parametrici
Esempio
Un'aspetto particolarmente interessante in ambito biomedico è verificare
l’influenza che una o più variabili esplicative (covariate) hanno sul tempo di
sopravvivenza dei soggetti.
In questo ambito sono stati proposti molti modelli di regressione in cui la
variabile dipendente è il tempo di sopravvivenza.
Modello semiparametrico di Cox
Modelli a effetti casuali (frailty models)
Modello semiparametrico di Cox
Il modello di Cox, detto anche modello a rischi proporzionali, è uno dei modelli più
importanti in ambito biomedico. La definizione formale prevede che la funzione di
rischio sia:
'
h !t , x "=h0 ! t "exp ! " X "
con "=[ " 1 ,. . . , " p ] e X n/ p
• I parametri vengono stimati massimizzando
numericamente la verosimiglianza parziale ad
es. con il metodo di Newton-Raphson.
• Le stime sono asintoticamente normali e non
distorte.
h0(t) è la funzione di rischio base, assunta essere uguale per ogni individuo nella
popolazione, mentre la funzione di rischio individuale, h(t,x), varia al variare di x.
Si noti che se p=1 e X indica l’appartenenza ai gruppi, il parametro " rappresenta, se
significativamente diverso da zero, la differenza tra i gruppi.
RR=
h ! t)x=1 " h0 ! t "exp ! " "
=
=exp ! " "
h ! t) x=0 "
h0 ! t "
Modello a effetti casuali
L’assunzione di rischio base costante per ogni individuo in molti casi risulta
essere poco realistico.
Eterogeneità individuale
L’eterogeneità individuale è data dalle covariate. Quando il nostro modello
non prende in considerazione covariate importanti per la funzione di rischio,
siamo in presenza di eterogeneità non osservabile.
h !t)Z , X "=Z0h! t)X "
h !t)Z , X "=Z0h0 ! t "exp ! " ' X "
La variabile Z, detta variabile frailty, è una variabile
casuale non osservabile che varia da individuo ad
individuo aumentandone o diminuendone il rischio.