STATISTICA
a.a. 2003-2004
– PARAMETRO t DI STUDENT
– t di STUDENT PER DATI INDIPENDENTI
– t di STUDENT PER DATI APPAIATI
– F DI FISHER PER IL CONFRONTO FRA
VARIANZE
DISTRIBUZIONI
CAMPIONARIE
– Consideriamo tutti i possibili campioni di
ampiezza N che si possono estrarre da
una popolazione.
– Per ciascun campione possiamo calcolare
media , deviazione standrad, ecc., e
trovare una distribuzione campionaria di
ciascun parametro.
DISTRIBUZIONI
CAMPIONARIE
– Si dimostra che la media della distribuzione
campionaria della media coincide con la media
della popolazione, mentre lo scarto quadratico
medio vale
x
N
– Per N>30 la distribuzione campionaria della media
è approssimabile alla distribuzione normale.
PARAMETRO t di STUDENT
– Supponiamo di avere due campioni casuali di
ampiezza N1 e N2, estratti da popolazioni normali
con uguale scarto quadratico medio (1 = 2).
– I due campioni hanno media e scarto quadratico
medio x1, x2 e s1,s2.
– Vogliamo provare l’ipotesi H0 che i campioni
provengano dalla stessa popolazione (ossia che
sia m1 = m2 e 1 = 2).
PARAMETRO t di STUDENT
– Noi non conosciamo né il valore della deviazione
standard né quello della media della popolazione.
– Definiamo ERRORE STANDARD la deviazione
standard della media,
σ2
σ
σm
N
N
PARAMETRO t di STUDENT
– Una buona stima dell’errore standard vero è
l’errore standard del campione
s2
s
sm
N
N
– Ma utilizzando l’errore standard campionario il
parametro z viene modificato, e da
z
xm
m
PARAMETRO t di STUDENT
si passa al parametro t
xm
t
sm
– Caratteristica importante del parametro t è che
non è distribuito normalmente. La sua
distribuzione sarà più dispersa di quella di z.
PARAMETRO t di STUDENT
– Essa è stata calcolata dal matematico inglese
Gosset, che la pubblicò sotto lo pseudonimo di
Student.
– Si tratta di una famiglia di distribuzioni, a seconda
del numero di gradi di libertà, che vale
GdL = N-1
dove N è il numero di osservazioni del
campione.
PARAMETRO t di STUDENT
– I valori della famiglia di distribuzioni t sono
tabulati.
– Per campioni molto grandi, il valore di sm oscilla
poco intorno al suo valore medio, che è m.
– Quindi per valori molto grandi la distribuzione t si
avvicina molto a quella di z, ed arriva a coincidere
per infiniti gradi di libertà.
– Per piccoli campioni le differenze sono notevoli,
data l’oscillazione casuale di sm intorno a m.
PARAMETRO t di STUDENT
– A questo punto possiamo assegnare dei “limiti
fiduciali” alla media di un campione, ossia
calcolare entro quanti errori standard dalla media
della popolazione la media campionaria ha una
certa probabilità di cadere.
– Scelta una certa probabilità P0, troveremo sulle
tavole il valore t0 per il quale
P(-t0 < t < t0) = P(t0) .
PARAMETRO t di STUDENT
xm
P ( t0
t0 )
sm
P ( smt0 x m smt0 )
P ( m smt0 x m smt0 )
ossia c’è una probabilità P0 che la media
campionaria x sia compresa in un intervallo che
va da m – smt0 a m + smt0 .
CONFRONTO FRA MEDIE
– Supponiamo di avere due campioni estratti da due
popolazioni la cui media per ipotesi coincide, e le cui
varianze 1 e 2 sono note.
– La media vera della differenza fra due valori delle due
popolazioni sarà per definizione zero, d = 0.
– La media campionaria della differenza fra due valori estratti
dai due campioni sarà tale per cui
d = x1 - x2.
– Analogamente la varianza della differenza sarà
2
d
2
1
2
2
CONFRONTO FRA MEDIE
– Quindi l’errore standard della differenza media
sarà
2
md
12
n1
22
n2
– Mentre la distribuzione standardizzata per la
differenza sarà
z
d d
2
1
n1
2
2
n2
CONFRONTO FRA MEDIE
Ed essendo d = x1 – x2 e d = 0
si avrà
z
x1 x2
2
1
n1
2
2
n2
Da cui si può calcolare il valore di z.
CONFRONTO FRA MEDIE
Cerchiamo sulle tavole il valore z0 di z tale per cui
P(-z0 < z < z0) = P0
dove P0 è una probabilità da noi scelta, in genere pari al 90,
95,99 o 99.9% a seconda del margine di sicurezza che
vogliamo avere nel pronunciare un giudizio sulla differenza
fra medie.
– Se il valore di z che abbiamo calcolato è in valore assoluto
maggiore di z0, ciò significa che la probabilità di avere
ottenuto casualmente i nostri risultati, supponendo vera
l’ipotesi zero, è minore di (1 – P0), ossia minore del limite
che ci eravamo prefissati (minore del 10%, 5%, 1% o 0,1%).
CONFRONTO FRA MEDIE
PER PICCOLI CAMPIONI
– In questo caso quindi rifiutiamo l’ipotesi zero,
avendo una probabilità di errore pari a (1 – P0).
– Questo metodo però funziona solo se si conosce
la varianza delle due popolazioni.
– Noi conosciamo raramente le varianze delle
popolazioni
– Ma per campioni grandi queste varianze
campionarie possono essere considerate stime
molto buone delle varianze vere.
– Si possono quindi sostituire a 1 e 2 i valori s1 e
s2.
CONFRONTO FRA MEDIE
PER PICCOLI CAMPIONI
– Per piccoli campioni sarà invece necessario
sostituire t al posto di z, e supporre inoltre che
oltre alle medie anche le varianze delle due
popolazioni siano uguali.
– Sarà allora
t
x1 x2
s2 s2
n1 n2
x1 x2
1
1
s (
)
n1
n2
2
CONFRONTO FRA MEDIE
PER PICCOLI CAMPIONI
t
x1 x2
2 n1 n2
s (
)
n1n2
n1n2
( x1 x2 )
n1 n2
t
2
2
( x1i x1 ) ( x2i x2 )
n1 n2 2
CONFRONTO FRA MEDIE
PER PICCOLI CAMPIONI
– E’ importante ricordare che il parametro t è
applicabile solo se è valido l’assunto che le
varianze delle due popolazioni siano uguali
(principio di omoscedasticità delle varianze).
– Aver utilizzato stime delle varianze vere ci ha
portato ad una distribuzione non normale e
dispersa.
– Per calcolare i limiti fiduciali della media, quindi,
dobbiamo valutare le tavole della distribuzione t di
Student.
CONFRONTO FRA MEDIE
PER PICCOLI CAMPIONI
– Il numero di gradi di libertà è dato in questo caso
dalla somma dei gradi di libertà delle varianze,
GdL = n1 + n2 –2 .
– Ora il procedimento è analogo a prima:
cerchiamo sulle tavole una t0 di t tale che, scelta
una probabilità limite P0, sia
P(-t0 < t < t0) = P0
CONFRONTO FRA MEDIE
PER PICCOLI CAMPIONI
– Se il valore di t da noi calcolato a partire dai due
campioni è superiore a t0 possiamo scartare
l’ipotesi nulla, perché la probabilità che troviamo
casualmente quel valore di t essendo vera l’ipotesi
nulla è più bassa della probabilità limite prefissata.
Nel fare questo abbiamo la probabilità di errore
(1 – P0).
– Per valutare se le varianze delle due popolazioni
campionate non differiscono significativamente si
usa il test F (v. avanti).
TEST t DI STUDENT PER
DATI APPAIATI
– Finora abbiamo sempre affermato che i test sono
applicabili se le serie di dati in esame sono
indipendenti.
– Potrebbe invece succedere che le serie siano
legate da qualche relazione.
– Ad esempio supponiamo di avere dieci topi e di
sottoporli a trattamento dimagrante:
TEST t DI STUDENT PER
DATI APPAIATI
TOPI
PESO PRIMA PESO DOPO
A
110
105
B
105
105
C
135
125
D
165
150
E
140
135
F
120
115
G
150
140
H
150
130
I
130
130
L
140
135
1345
180
TOT
TEST t DI STUDENT PER
DATI APPAIATI
Xprima = 134.5
Xdopo = 128.0
– Il peso di ogni topo dopo la dieta è in relazione al
suo peso prima della dieta: le due serie di dati
non sono indipendenti.
– Ad ogni dato della prima serie se ne può far
corrispondere uno ed uno solo della seconda.
– Calcoliamo tutte le differenze fra prima e dopo:
TEST t DI STUDENT PER
DATI APPAIATI
A -5
B 0
C 10
D 15
E 5
F 5
G 10
H 20
I 0
L 5
Tot 65
X 6.5
TEST t DI STUDENT PER
DATI APPAIATI
– Per l’ipotesi nulla la media delle differenze delle
due serie non deve differire significativamente da
zero.
– La media vera è per ipotesi zero.
– La media campionaria è d=6.5.
– Scriveremo
z
d d
d
n
z
d
d
n
TEST t DI STUDENT PER
DATI APPAIATI
– Ma poiché non conosciamo la varianza vera
useremo la sua stima
d
z
sd
n
– Questo però vale per grandi campioni. Per piccoli
campioni useremo la distribuzione
d
t
sd
n
TEST t DI STUDENT PER
DATI APPAIATI
con n-1 gradi di libertà.
In questo caso avremo
D= 6.5
GdL = n-1 = 9
s
2
d
t
2
d
( d ) 2
9
6.5
sd2
10
925 422.5
55.8
9
6.5
n
3.2 2 .7
7.5
TEST t DI STUDENT PER
DATI APPAIATI
– In questo caso il valore di t sta fra i due valori
corrispondenti alle probabilità 0.05 e 0.02.
– Pertanto concludiamo che esiste una differenza
significativa tra le medie dei pesi prima e dopo il
trattamento, ossia che la dieta somministrata ai
topi è efficace.
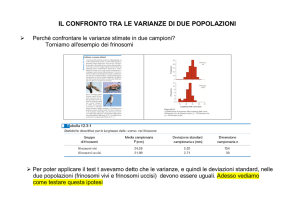
TEST F DI FISHER PER IL
CONFRONTO FRA
VARIANZE
– Per vedere se due varianze sono omogenee si utilizza il test
F.
– Dati due campioni con n1 e n2 osservazioni e varianze s1 ed
s2, il parametro F è definito come il rapporto fra le due
varianze campionarie:
2
s1
F 2
s2
– Quanto più questo rapporto si allontana da uno, tanto più
diverse sono le due varianze e tanto minori sono le
possibilità di aver ottenuto casualmente i due campioni dalla
stessa popolazione.
TEST F DI FISHER PER IL
CONFRONTO FRA
VARIANZE
– La distribuzione di F è stata tabulata: è una
famiglia di distribuzioni, a seconda del numero di
gradi di libertà a numeratore e denominatore,
n1 –1
e
n2 – 1.