
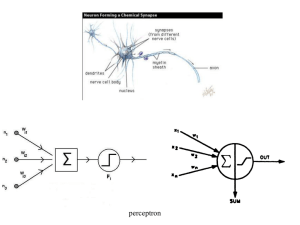
Il neurone e i suoi componenti
Il nucleo
I dendriti
L’assone
Le connessioni sinaptiche
Reti neuronali artificiali (RNA)
(Artificial Neural Networks, ANN)
dalla neurobiologia e neurochimica,
-struttura di elaborazione distribuita ed altamente interconnessa
(~1011 neuroni e ~1015 connessioni nel cervello umano,
~1ms tempi di commutazione, ~10-6 joule/ciclo)
- meccanismi di apprendimento e adattamento
(anche dalla neuropsicologia)
approccio storico
approccio funzionale
Riconoscitore lineare: y= wTx=Siwixi; i=1N
Percettrone: y=s(s) con s= wTx=Siwixi; i=1N
s= campo indotto locale
Riconoscitore a stadi: y=s(s2)
con s2=f(s1) con s1= wTx=Siwixi; i=1N
Riconoscitore generalizzato: y=f(W,x)
Metodo di addestramento istantaneo (al singolo campione)
Riconoscitore lineare
y= wTx
E=(d-y)2 =e2
Dw=-hdE/dw
DE=-h(dE/dw)2<0 dE/dw=-ex
Dw=-hdE/dw =hex
Riconoscitore a stadi
y=s(s2) con s2=f(s1) con s1= wTx=Siwixi; i=1N
Dw=-hdE/dw =-h (dE/dy)(dy/ds2) (ds1/ds2) (ds2/dw)
Dw= he s’(s2) (ds1/ds2) x
Metodo di addestramento a blocchi (al singolo campione)
Riconoscitore lineare
y= wTx=Siwixi; i=1N
E=E [d-y]2 = E [e]2
E=E [d- Siwixi]2 = E [d2 +2 Siwidxi +Si(wixi)2]
=E [d2 ]+ 2 Siwi E [dxi] + E [ Si(wixi)2]
L’ errore minimo si ha quando dE/dw=0 e cioè
dE/dwi= 2 E [dxi] +2 wiE [xi)2]=0
wi= - E [xi)2/E [dxi]
Caratteristiche delle RNA
- non linearita’
- apprendimento(senza maestro)/addestramento (con maestro)
- adattamento (plasticita’ e stabilita’)
- risposta probativa (affermazione di non riconoscimento)
- informazioni contestuali
- tolleranza ai guasti
- analogie neurobiologiche
- realizzazione VLSI
- uniformita’ di analisi e progetto
I metodi di apprendimento delle RNA
Apprendimento (addestramento non supervisionato)
a) e’ definito il numero delle classi K
b) e’ definito il criterio di appartenenza ad un stessa classe
e’applicato solo il campione X
Addestramento (apprendimento supervisionato)
e’ applicata la coppia campione-classe (X,Y*)
Ibridi (adattativi)
a) e’ definito il criterio di appartenenza ad un stessa classe
e’ applicata la coppia campione-classe (X,Y*),
ma non la struttura
Metodo di aggiornamento sequenziale dei pesi
Insieme d’ addestramento: (xk,y*k), k=1-Q,
Vettore uscita desiderato y*k= (y*km, m=1-M)
Vettore uscita yk= (ykm, m=1-M) prodotto da xk=(xki,i=1-N)
Funzione errore: E (W)= 1/2Sm (y*km-ykm)2 = 1/2 Sm (ekm)2
Formula d’ aggiornamento:
Dwji=- h.dE/dwji= -h dj yi = h s’(sj).ej yi
dove ej= Sm wmjdm e dm= - s’(sm).em
Formule d’ aggiornamento (per ogni coppia xk,y*k, si e’ omesso l’apice k)
strato d’ uscita O: ym= s(sm) em= y*m-ym dm= ems’(sm) Dwjm= h dm yj
strato nascosto H2:
ej=Smdmwjm dj= ejs’(sj)
Dwkj = h dj yk
strato nascosto H1:
ek=Sjdjwkj
dk= eks’(sk)
Dwik = h dk xi
Addestramento globale dei pesi sinaptici
Insieme d’ addestramento: (xk,y*k), k=1-Q,
Vettore uscita desiderato y*k= (y*km, m=1-M)
Vettore uscita prodotto da xk=(xki,i=1-N) yk= (ykm, m=1-M)
Funzione errore globale: Eg(Wj)= 1/2SkSm (y*km-ykm)2 = 1/2 Sk Sm (ekm)2
Retropropagazione dell’ errore (per ogni coppia xk,y*k, si e’ omesso l’apice k)
strato d’ uscita O: ym= s(sm) em= y*m-ym dm= ems’(sm)
strato nascosto H2:
ej=Smdmwjm dj= ejs’(sj)
strato nascosto H1:
ek=Sjdjwkj
dk= eks’(sk)
Formula per l’ aggiornamento globale:
Dwji= - h.dEg/dwji= h Sk dkj yki = h Sk s’(skj).ekj
dove ekj= Shj. whjdkh e dkj= - s’(skj).ekj
Note
a) metodo dei momenti: Dwij(n)= a Dwij(n-1) +hdi (n)x j(n) con a<1
b) suddivisione suggerita per l’ insieme di addestramento+validazione
1. Sessione
add.
val.
2. Sessione
3. Sessione
4. Sessione
3) normalizzazione: traslazione al valor medio: decorrelazione e
equalizzazione della covarianza (trasformazione con autovalori)
4) inizializzazione: pesi casuali e piccoli (funzionamento al limite
della zona lineare), h =.1, a~.9
Inferenza statistica delle RNA
x, ck
y1(x)
ym(x)
y*1 (x) = dl(x) = 0
y*m(x) = dm(x) = 0
yk(x)
yM(x)
y*k(x) = dk(x) = 1
y*M(x) = dM(x) = 0
RNA
ck =(dl(x)…. dk(x)….. dM(x))
E2= SX P(x)(Sk P(ck /x) Sm [ym(x)-y*m(x)] 2})
E2= SX P(x)(Sm {Sk P(ck /x) [ym(x)- dm(x)k]2})
E2 = SX P(x)(Sm {Sk [ym(x)- dm(x)] 2 P(ck /x) })
Ma Sk[ym(x)- dm(x)]2 P(ck/x)= ym2(x)-2ym(x) P(cm/x) + P(cm/x)=
poiche’ dm(x)=1 solo per k = m e Sk P(ck/x)=1, aggiungendo e togliendo
P2(cm/x) si ha:
[ym2(x)-2ym(x) P(cm/x) + P2(cm/x)] + [P(cm/x) - P2(cm/x)] =
= [ym(x)-P(cm/x)]2 + P(cm/x) [1- P(cm/x)]
dove solo il primo addendo dipende dalla rete per cui addestrandola
correttamente si ottiene il minimo di E2:
ym(x)=P(cm/x)
yA
1
3
x1
x2
yA*
2
x2
1
X
+
A
yA*=fA*(s) = 0.5
A*
+
yA=fA(s) = 0.5
x1
x2
y
a
+
c
b
b
c
A
a
x1
x2
x1
1
MPL per EXOR
x1 x2
0
0
1
1
0
1
0
1
y
x2
1
0
1
1
0
y=1
y=0
y
y=1
0
1
1
x1
y=0
x2
1
x1
yA
yA*
z
u(z-T)
u(-z-T)
1
x2
x1
2
3
x2
1
X
I
A
z=f(s) =T
z=f(s) =-T
A*
x1
z=f(s) = 0.5
MLP per riconoscimento di due classi con pdf gaussiane equiprobabili
(HAYKIN Cap.4.8)
yA
yB
Parametri di addestramento:
h=0.1, a=0.5
x2
x1
1
rA
x2
A
MLP: Pe = 0.196
Bayesiana: Pe = 0.185
XA mA
X
X
zona di
decisione sA
ottima Bayesiana
mB
x1
X
sB
1
3
1
8
x1(n)
X(n)
x16(n)
RNA con apprendimento non supervisionato
a) Numero di classi (cluster) predefinito
b) Criterio di verosimiglianza predefinito
(il numero di cluster dipende dalla distribuzione statistica dei campioni)
-
origine del modello: disposizione e interazione eccitatoria/inibitoria
dei neuroni della corteccia cerebrale;
metodo di apprendimento;
metodo di riconoscimento (tassellazione di Voronoi);
estensione a reti con apprendimento supervisionato.
1
j
N
Von der Malsburg
1
i
N
y1
yj
1
j
W1
Wj
yM
M
WM
X
Kohonen
1
j
yi
M
wji
1
i
N
xi
Caratteristiche
j = argmin[d(x,wh); h=1M]
yj=1; yh=0 per h j)
- riduzione della dimensionalita’ (neuroni su reticolo)
-competizione (per l’ attivazione del nodo d’ uscita)
-cooperazione (per l’ apprendimento)
-adattamento sinaptico: eccitazione/inibizione
Fig.10 Mappa autorganizzata (SOM) ed attivazione del nodo d’ uscita
i
spazio discreto delle uscite
j
x2
wi
x
spazio continuo dei
campioni
wj
x1
Si puo’ realizzare una strutturazione globale mediante interazioni locali
(Turing, 1952)
La strutturazione e’ realizzata da interazioni prodotte da attivita’
ed interconneaaioni neuronali
Principio 1. Le interconnessioni tendono ad essere eccitatorie
Principio 2. La limitazione delle ‘risorse’ permette l’aumento di
determinate attivita’ a scapito di altre
Principio 3. Le modifiche dei pesi sinaptici tendono ad essere cooperative
Principio 4. Un sistema autorganizzato deve essere ridondante
Competizione
neurone vincente: j = argmin[||x-wh||) ; h=1M]
oppure: j = argmax[xTwh ; h=1M]
distanza (Manhattan)reticolare, o laterale, dei nodi i e j:d(j,i)2
funzione di vicinato: hi(j) = exp[- d(i,j)2 /2s2]
Cooperazione
I neuroni i del vicinato di j sono eccitati e e cooperano all’:
Adattamento sinaptico
Dwi= h hi(j)(x-wi)
h e s diminuiscono con le sessioni di apprendimento
Fase di autorganizzazione: h=0.1-0.01, d(i,j) decrescente da massima
fase di convergenza statistica: h=0.01, 1 d(i,j) 0
Aggiornamento pesi della SOM
W=(w1,w2,...,wM) vettore prototipo
Ej(W)= 1/2Si hi(j) (x- wi)2
con i=1M e hi(j) funzione di vicinato di j
DEj(W)= grad(Ej(W)).DW= Si (dE(W)/dwi).Dwi
D wi = -hdEj(W)/dwi = h hi(j) (x- wi).
Addestramento delle SOM supervisionate
Learning Vector Quantizer (LVQ)
dati di addestramento: (X, C)
a) apprendimento della SOM (solo X)
b) addestramento (con X,C)
b2) addestramento dello strato d’ uscita
(con o senza competizione nello strato nascosto)
b1) etichettatura
b3) etichettatura e addestramento dello strato nascosto
(con competizione)
DWc= +/-a (X-Wc) se X appartiene o no a C
Reti Neuronali Adattative
Teoria della risonanza adattativa
(Adaptive Resonance Theory, ART)
Meccanismo psicofisiologico:
1) Attenzione selettiva: ricerca di una situazione
nel dominio di conoscenza
2) Risonanza: se l’ attenzione selettiva rileva una situazione nota
3) Orientamento: ricerca o creazione di una nuova situazione
Vantaggi: compatibilita’ fra plasticita’ e stabilita’
Svantaggi: complessita’ della struttura e dell’ algoritmo di
apprendimento
Apprendimento:
Attivazione dello strato di riconoscimento (feedforward)
Competizione (attenzione selettiva)
Retroproiezione allo strato di confronto (verifica della risonanza)
Creazione di un nuovo neurone di riconoscimento
strato di
riconoscimento
1
j
P
Zj
Wj
strato di
confronto
1
i
x1
N
xi
X
xN
P+1
strato di
riconoscimento
1
j
P
wji
zij
strato di
confronto
1
i
x1
N
xi
xN
j=argmax [XTWh,h=1,P] Attenzione selettiva
XTZj >r risonanza: adattamento pesi Wj e Zj
XTZj<r orientamento: XTZh con h > < j
se XTZh >r risonanza: adattamento pesi Wh e Zh
se XTZh <r per h=1,P si crea un nuovo nodo P+1
P+1
x2
WP+1= X
o
W1
o
Wj
o R
o
X
Raggio di
attenzione selettiva
WP
o
Fig. 15 Criterio di appartenenza ad un prototipo
(Raggiodi convergenza, raggio di attenzione selettiva)
x1
x,y’
rete di controllo
della risonaza e dell’ orientamento
wij=1
1
h
M
strato delle classi
strato nascosto
competitivo
1
j
P
wji
strato
d’ ingresso
1
i
Fig.16 SOFM supervisionata adattativa
N
P+1
wj
oX
wj
o
oX
o
Rj
Rj
att. selett. insuff. j><c
DRj = g(d(Wj,X)-Rj)
DWj= h(Wj -X)
risonanza j=c
DWj= h(X-Wj)
wj
o
X
o Rj
j
att. selett. eccess. j=c
DRj = g(d(Wj,X)-Rj)
DWj= h(X-Wj)
wP
o RP
orientamento j >< c
W P+1 = X; P+1 c;
RP+1=1/2d(X,WP)
WP+1= X
o
RP+1







![Pannello Tatto [file ]](http://s1.studylibit.com/store/data/001082941_1-ff61b4164c706779718d19e230afec3e-300x300.png)
