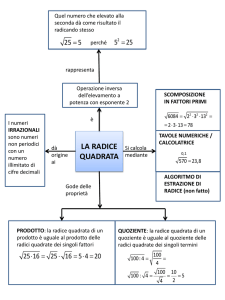
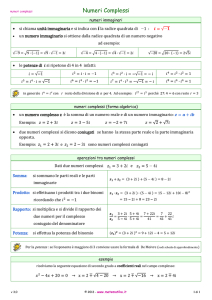
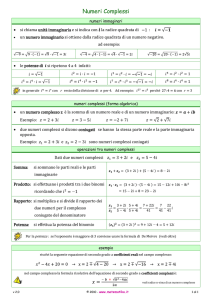
Stima della complessità computazionale della fattorizzazione con il
metodo dell’attacco casuale (rapporti tra statistica e numeri primi)
Supponiamo che p sia un numero da fattorizzare molto grande (es RSA). Sappiamo che il fattore più piccolo
deve necessariamente trovarsi tra 2 e la radice quadrata di p. Supponiamo di avere un calcolatore che
generi numeri casuali e che ogni numero casuale generato sia un numero primo tra 2 e la radice quadrata
di p. Per ogni numero casuale estratto si verifica se è o no un divisore di p e , in caso negativo, si passa al
successivo numero. Ipotizziamo che il nostro programma tenga “memoria” dei numeri estratti in modo che
l generatore di “primi casuali” non possa ripetere mai lo stesso numero.
Al primo tentativo la probabilità di aver trovato la soluzione sarà
𝑃1 =
1
𝑙𝑜𝑔𝑥
𝑥 = 𝑥
𝑙𝑜𝑔𝑥
Ove è stato usato il ben noto teorema dei numeri primi e 𝑥 = 𝑖𝑛𝑡(√𝑝) e log(x) è il logaritmo naturale di x.
𝑥
In luogo di x/log(x) avremmo potuto anche usare una stima di ∫2
𝑑𝑦
log(𝑦)
Al secondo tentativo
1
𝑃2 = 𝑥
−1
𝑙𝑜𝑔𝑥
… al k-esimo tentativo
1
𝑃𝑘 = 𝑥
−𝑘+1
𝑙𝑜𝑔𝑥
Questa formula ci dà una stima della probabilità che al k-esimo tentativo (k intero) abbiamo di “indovinare”
la soluzione. Come si vede man mano che aumentano i tentativi aumenta la probabilità di “vittoria”,
probabilità che è comunque condizionata dalla grandezza di p numero da fattorizzare. Come si può ben
vedere all’aumentare delle dimensioni di p la probabilità diminuisce in modo esponenziale