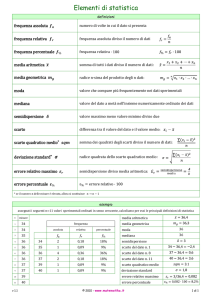
Esercizio 21-04-2005
Esercizio 1
L'assistenza ai clienti di una società del gas intende stimare la durata media del tempo che intercorre tra la
ricezione di una richiesta di allacciamento e l'effettivo allacciamento. Viene estratto un campione casuale di
15 case, per cui si ottengono i risultati in numero di giorni di attesa che leggiamo nel foglio Eserc1.
a) Calcolate un intervallo di confidenza di livello 95% per la media del tempo di attesa.
Calcolare la media aritmetica utilizzando la funzione MEDIA (INSERISCI/FUNZIONE/STATISTICHE) e lo
scarto quadratico medio con la funzione DEV.ST (INSERISCI/FUNZIONE/STATISTICHE ) mettendo in
entrambe come riferimento le celle relative ai dati.
Poiché il campione è composto soltanto da 15 elementi e la varianza non è nota la variabile media aritmetica
campionaria si distribuisce come una t di student con 14 gdl (gradi di libertà)
Per ottenere il valore della t con 14 gdl corrispondente al 5% di probabilità utilizzare la funzione INV.T
specificando la probabilità nel notro caso 0.05 e il numero di gradi libertà (14).
Lo scarto quadratico medio della variabile aleatoria media aritmetica campionaria è dato dal rapporto dello
scarto quadratico medio calcolato sui dati campionari e dalla radice del numero degli elementi
(=G35/RADQ(15)).
L’estremo inferiore dell’intervallo verrà calcolato: =G33-B46*F48 (G33 è la cella che contiene la media
campionaria, B46 contiene la t di student e F48 lo scarto quadratico della variabile aleatoria)
L’estremo superiore: =G33-B46*F48.
L’intervallo è [87.769, 109.964]
b) Quale ipotesi si deve fare sulla distribuzione della popolazione al punto a)
Poiché il campione è piccolo e la varianza di popolazione non è nota, l'ipotesi iniziale è quella che il
carattere X si distribuisca come una Normale. Infatti solo ammettendo la normalità distributiva di X, si ha che
la variabile aleatoria media aritmetica campionaria X ha distribuzione Normale. Inoltre solo ammettendo la
normalità distributiva di X, si ha che
(n 1)s 2
2
è distribuito come un
Infine, il rapporto tra una N(0,1) e la radice di un
2
2
con n-1 gdl.
diviso per i suoi gradi di libertà, tra loro indipendenti,
si distribuisce come una t di Student con n-1 gradi di libertà.
c) Supponete che l'ultimo valore sia 286 giorni al posto di 86. Rispondete di nuovo al punto a).
Quale effetto ha questo cambiamento sull'intervallo di confidenza?
Ricalcolare la media lo scarto quadratico medio e lo scarto quadratico della variabile aleatoria media
aritmetica campionaria. Quindi calcolo dei due estremi dell’intervallo come mostrato in precedenza.
L’intervallo è [83.42, 140.98]
Esercizio 2
Un venditore di automobili intende stimare la proporzione di clienti che possiedono ancora l'automobile
acquistata 5 anni fa. Dagli archivi del venditore viene estratto un campione casuale di 200 clienti, 82 dei
quali ancora possiedono l'automobile acquistata 5 anni fa.
a) Calcolate un intervallo di confidenza di livello 90% per stimare la proporzione di clienti del
venditore che possiedono ancora l'automobile acquistata 5 anni fa.
La variabile aleatoria frequenza relativa campionaria Fr ha media uguale alla frequenza di popolazione p
La frequenza relativa campionaria f, può essere assunta come stimatore puntuale ed è: =82/200.
Ha scarto quadratico medio [p(1-p)/n]1/2 pari a : =RADQ(F16 *(1-F16)/200) se in F16 troviamo il valore di p.
Poiché il campione è grande, la variabile aleatoria frequenza relativa campionaria si distribuisce
asintoticamente come una Normale quindi per calcolare il valore della normale z 0.95 corrispondente al valore
di probabilità 0.95 utilizziamo la funzione INV.NORM.ST(0.95).
L’estremo inferiore dell’intervallo sarà dato da: =F16-B22*C17 dove in F16 troviamo il valore di p, in B22 il
valore della statistica z e in C17 il valore dello scarto quadratico medio della variabile aleatoria frequenza
relativa campionaria.
L’estremo superiore dell’intervallo: =F16+B22*C17
L’intervallo sarà: [0.3527, 0.4672]
b) Il venditore di automobili intende valutare il livello di soddisfazione dei suoi clienti per le
macchine acquistate presso di lui. In che modo può usare i risultati del punto a)?
Il risultato ottenuto al punto a) indica che, con livello di fiducia pari al 95%, una percentuale di clienti
compresa tra il 35% e il 47% è rimasta soddisfatta dell'acquisto fatto 5 anni prima.
Esercizio 3
Uno psicologo industriale vuole studiare gli effetti incentivo sulle vendite rappresentati dalla particolare
forma di compenso corrisposto ai venditori. Viene considerato a tal fine un campione di 24 venditori, 12 dei
quali sono pagati con una quota fissa per ogni ora di lavoro (1), mentre i restanti 12 ricevono delle
commissioni sulle vendite realizzate (2). Nella foglio eserc3 sono riportati i volumi delle vendite relative ai 24
venditori del campione, opportunamente divise nei due sottocampioni considerati.
a) Lo psicologo può affermare, ad un livello di significatività 0.01 , che il pagamento per
commissioni rappresenta un incentivo al venditore che comporta un aumento delle vendite
medie?
Poiché entrambi i campioni sono di piccola numerosità, n<30, e non si conoscono le varianze in
popolazione, l'ipotesi H 0 : 1 2 viene controllata con la statistica test t di Student.
Calcolare la media relativa al primo gruppo con la funzione MEDIA ( celle A11:A22)
Calcolare la media relativa al secondo gruppo con la funzione MEDIA ( celle A23:A34)
ŝ 12 con la funzione VAR(celle A11:A22)
2
Calcolare lo scarto quadratico medio sui valori del secondo gruppo ŝ 2 con la funzione VAR(celle A23:A34)
Calcolare lo scarto quadratico medio sui valori del primo gruppo
Calcolare lo scarto quadratico come media dei primi due ŝ
rispettivamente
2
1
ŝ e in B57 ŝ
*2
=((B55*11)+(B57*11))/22. se in B55 abbiamo
2
2
Il valore di t concreto si ottiene =(B51-B53)/RADQ(B59*2/12) se in B51 abbiamo m1 e in B53 m2 e in B59 lo
scarto quadratico medio del test.
Il valore t0.01,22 teorico viene ottenuto con la funzione INV.T(0.02,22) Di default tale funzione utilizza una
probabilità corrispondente ad distribuzione t a due code per questo utilizziamo 0.02.
b) Quali ipotesi devono essere fatte al punto precedente, per giustificare l'utilizzo del test
scelto?
Per poter applicare la statistica test t quando i campioni sono di piccola numerosità e le varianze di
popolazione sono incognite, è necessario che valga la condizione di normalità distributiva per X1 "
ammontare delle vendite nella popolazione dei venditori pagati con compenso orario" e X2 "ammontare delle
vendite nella popolazione dei venditori pagati per commissione eseguita" e che le varianze di X1 e X2 siano
2
2
2
uguali 1 2
c) Calcolare il p-value e interpretarne il significato
Il p-value può essere calcolato con la funzione DISTRIB.T(2.7467,22,1) corrispondente al test t con 22
gradi di libertà test ad 1 coda.
Stesso risultato si può ottenere utilizzando la funzione TEST.T in cui in matrice1 e matrice2 vengono
specificate le matrici dei 2 campioni, in coda quante code ha il notro test e in tipo che tipo di test effettuiamo
nel nostro caso un test per campioni accoppiati con stessa varianza (tipo=1).
Esercizio 4
Nella provincia di Nassau è stata effettuata un'indagine finalizzata ad individuare l'esistenza di eventuali
relazioni fra lo stile architettonico delle case e la posizione geografica delle stesse. I risultati sono riportati
nel foglio eserc4
a) Si può ipotizzare che lo stile architettonico sia indipendente dalla posizione geografica delle
case?
Si scelga un valore di =0.05.
Entrambi i caratteri sono qualitativi, quindi è possibile verificare esclusivamente un tipo di indipendenza
distributiva. La statistica test utilizzata è:
u
v
2
c
i 1 h 1
n
ih
nih*
nih*
2
Per il calcolo della distribuzione attesa nell’ipotesi d’indipendenza riportare le intestazioni delle righe e delle
colonne della tabella a doppi a entrata quindi procedendo con la prima cella =I9*$C$14/$I$14 dove I9
contiene il valore concreto corrispondente alla prima riga e prima colonna della tabella C14 contiene il totale
di colonna infine I14 il totale complessivo dei dati.
Una volta calcolato il primo valore procediamo per colonna estendendo la formula alle altre celle.
Quindi calcoliamo la tabella degli scarti al quadrato =(C9-C36)^2/C36 (C9 contiene il valore concreto C36 il
valore nel caso d’indipendenza) estendendo tale calcolo a tutele celle della tabella.
Il valore di 2 possiamo leggerlo direttamente nella cella che contiene il totale degli scarti al quadrato.
Confrontiamo tale valore con 20.005,8 calcolata con la funzione INV.CHI corrispondente ad un livello di
probabilità pari a 0.05 ed ad un numero di gradi di libertà pari a 8.
2 2
Poiché
si rifiuta l'ipotesi di indipendenza distributiva tra lo stile architettonico e la posizione
c
geografica delle case considerate.
Esercizio 5
Un professore di contabilità è interessato a valutare la comprensibilità dei rendiconti annuali di due società.
Come supporto nella valutazione, egli decide di reclutare 100 contabili qualificati e di assegnarli per metà
all'uno e per metà all'altro rendiconto analizzato. Basandosi su misure standard di leggibilità, 17 dei 50
contabili assegnati alla lettura del rendiconto prodotto dalla società A giudicano "leggibile" tale rendiconto; lo
stesso giudizio è attribuito al rendiconto della società B da parte di 23 dei 50 contabili coinvolti.
a) Con un livello di significatività pari a 0.1, si può affermare che esiste una differenza
significativa nella leggibilità dei rendiconti annuali?
L'ipotesi nulla è: H0:pA=pB=p . Il campione è di grandi dimensioni, n>30; la variabile aleatoria "differenza
fra due variabili frequenza relativa campionaria" converge alla Normale standardizzata.
zc
f1 f2
f (1 f )(n1 n 2 ) / n1 n 2
Calcolare la percentuale dei contabili che reputano leggibile il rendiconto della società A: pA=17/50
Calcolare la percentuale dei contabili che reputano leggibile il rendiconto della società B: p B=23/50
Calcolo di p=(pA*50+pB*50)/100
Calcolare il valore della normale standardizzata relativo ad un livello di significatività dello 0.1
=(B24-B26)/RADQ(B28*(1-B28)*100/50*50) =-1.22
Confrontare tale valore con il valore teorico della distribuzione normale standardizzata ottenuta con la
funzione INV.NORM.ST(0.05)=-1.66
Dal momento che -1.22>-1.66 non si rifiuta l'ipotesi nulla, concludendo che non esiste una differenza
significativa fra le proporzioni di contabili che reputano leggibili i rendiconti delle due società.
b) Calcolare il p-value e interpretarne il significato.
Pvalue=DISTRIB.NORM.ST(B30) dove B30 contiene il valore di p
La probabilità di estrarre due campioni tali per cui la differenza, in valore assoluto, fra le due proporzioni
campionarie di successi è maggiore o uguale a 0.46-0.34=0.12, supponendo che l'ipotesi nulla sia vera è
0.11*2=0.22.
c) Cosa succederebbe se il numero di contabili che giudicano leggibile il rendiconto prodotto
dalla società B aumentasse a 33?
pB=33/50
p=(B24*50+B46*50)/100 B24 contiene pA e B46 pB
zc=(B24-B46)/RADQ(B49*(1-B49)*100/50*50) dove B49 contiene p
Poiché -3.2<-1.645 l'ipotesi nulla deve essere rifiutata; esiste una differenza significativa fra le due
proporzioni di contabili che reputano leggibili i rendiconti delle due società.