SEMINARIO MAGGIO 2009
DANIELA SCARCELLA E MATTEO BUFFA
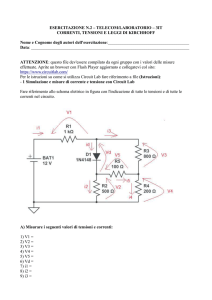
1
La rappresentazione dei dati nello spazio, ha diverse
applicazioni. Questo trova riscontro nei seguenti
applicativi:
DBMS commerciali
G.I.S. (sistemi informatici geografici)
Gestione di progetti nel settore architettonico,
industriale;
Etc.
2
STRUTTURE DATI MULTIDIMENSIONALI
L’aumento del numero di dimensioni nello spazio porta ad una
complessità maggiore, ed è per questo che si cerca di
ottimizzare la rappresentazione di informazioni
multidimensionali studiando nuove strutture dati.
La rappresentazione di oggetti n-dimensioni è strettamente
legata al concetto di indicizzazione di relazioni di database.
3
STRUTTURE DATI MULTIDIMENSIONALI
Esistono molte strutture dati che rappresentano metodi di
decomposizione dello spazio, tali per cui la
rappresentazione dei punti comporta , un risparmio di
spazio di memorizzazione, e tempo di esecuzione delle
operazioni (aggiornamento, creazione, modifica, ecc).
4
Rappresentazioni di dati nello spazio
K-d tree
Quadtree Point
Quadtree-MX
R-tree
5
Sistemi Informatici geografici
Consideriamo un sistema di informazioni geografiche il
quale immagazzina i dati di una determinata zona.
Prendiamo in esame una mappa come un’immagine
Bi-dimensionale.
6
7
K-d tree
Un albero a due dimensioni (es. k=2) immagazzina
informazioni bi-dimensionali,.
Un albero a tre dimensioni (es.k=3) immagazzina
informazioni tri-dimensionali
Etc.
8
Struttura di un albero 2-d
In un albero, il nodo ha una certa struttura di record.
nodetype = record
INFO : infotype
XVAL : real
YVAL : real
LLINK : nodetype
RLINK : nodetype
9
Condizioni da soddisfare
Se N è un nodo di livello pari:
Nel ramo di sinistra i nodi M hanno la proprietà
M.XVAL < N.XVAL.
Nel ramo di destra i nodi P hanno la proprietà
P.XVAL >= N.XVAL.
Il nodo N divide la regione in due parti, disegnando una
linea verticale.
10
Condizioni da soddisfare
Se N è un nodo di livello dispari:
Nel ramo di sinistra i nodi M (figlio di N) ha la proprietà
M.YVAL <N.YVAL
Nel ramo di destra i nodi P(figlio di N) ha la proprietà
P.YVAL>=N.YVAL
Il nodo N divide la regione in due parti, disegnando una
linea orizzontale.
11
CITTA’
X
Y
TORINO
66
83
BIELLA
74
115
ALESSANDRIA
98
65
CUNEO
42
15
12
INSERIMENTO ALBERO 2-D
Supponiamo di voler inserire questi elementi così
come messi nella tabella.
Inserimento primo elemento: se la tabella è vuota,
questo record sarà la radice dell’albero di dati.
LIV 0
13
INSERIMENTO ALBERO 2-D
Inserimento secondo elemento: siccome siamo in un
livello pari dell’albero dobbiamo confrontare i campi
XVAL;
ovvero BIELLA.XVAL >= TORINO.XVAL; quindi
collegheremo il figlio al campo Rlink(destro).
14
LIV 0
LIV 1
15
INSERIMENTO ALBERO 2-D
Inserimento terzo elemento: inizio con il confrontare
Torino.XVAL con Alessandria.XVAL, dal confronto mi
accorgo che Alessandria.XVAL > TORINO.XVAL però
il campo destro è già occupato, quindi confronto
(mi trovo al LIV 1) Alessandria.YVAL con Biella.YVAL ,
e quindi Alessandria.YVAL < Biella.YVAL; allora
collego questo nuovo elemento al campo sinistro.
16
66
83
LIV 0
74
98
115
LIV 1
65
LIV 2
17
Inserimento quarto elemento: l’ultimo elemento da
inserire è la città di Cuneo.
CUNEO.XVAL con TORINO.XVAL confronto i campi
XVAL perché ci troviamo al livello pari. Questo nuovo
e ultimo elemento lo colleghiamo al figlio sinistro della
radice, poiché CUNEO.XVAL < TORINO.XVAL
18
Quindi il nostro schema finale sarà:
66
83
LIV 0
74
98
65
115
LIV 1
LIV 2
19
CANCELLAZIONE ALBERI 2-D
La parte più complessa nella gestione degli alberi K-D
è la cancellazione di un nodo.
Il primo passo consiste nell’ individuare il nodo da
cancellare.
Supponiamo di voler cancellare un elemento nella
posizione (x,y). Se il nodo da cancellare è una foglia
(questo è il caso piu semplice) si elimina il nodo
selezionato, ponendo a NULL il puntatore al nodo
padre che ne memorizza il riferimento.
20
CANCELLAZIONE ALBERI 2-D
NULL
21
CANCELLAZIONE ALBERI 2-D
Se invece il nodo da cancellare è interno, la
cancellazione sarà più complessa.
Supponiamo infatti di voler cancellare un nodo N, non
vuoto cioè che ha almeno un figlio.
Il primo passo da fare è trovare un candidato(nodo R)
che può sostituire il nodo che vogliamo cancellare (N).
22
Passi da fare per cancellare un nodo interno
Passo 1: trovare un sostituto R per rimpiazzare il nodo
figlio di Ti(Tr o Tl).
Passo 2: sostituire i campi Info, XVAL e YVAL di N con
quelli di R (ovvero il sostituto).
Passo 3: Cancellare ricorsivamente R da Ti.
23
Il nodo candidato deve soddisfare le seguenti proprietà:
1: Ogni nodo M in Tl deve verificare M.XVAL < R.XVAL
se il livello è pari, mentre deve verificare che
M.YVAL < R.YVAL se il livello è dispari .
2: Ogni nodo M in Tr deve verificare che
M.XVAL >= R.XVAL se il livello è pari, mentre deve
verificare che M.YVAL >= R.YVAL se il livello è dispari.
24
Tl
Tr
LIV 0
LIV 1
LIV 2
LIV 3
25
CONSIDERAZIONI (sotto-albero destro)
In generale,se il livello di N è pari, ogni nodo Tr che ha il
campo XVAL più piccolo possibile in Tr è il nodo candidato
per la sostituzione.
In modo analogo se il livello di N è dispari, ogni nodo in Tr
che ha il campo YVAL più piccolo possibile in Tr è il nodo
candidato per la sostituzione.
Nel nostro caso, se volessi cancellare TORINO, il nodo che
dovrebbe rimpiazzare è associato ad ALESSANDRIA,
poiché questo nodo ha coordinata Y più piccola di tutte le
altre città nel sottoalbero destro di TORINO.
26
Nodo N
LIV 0
M (di livello dispari)
LIV 1
R(candidato)
LIV 2
M verifica la condizione 2
(ovvero M.YVAL >= R.YVAL)
ALESSANDRIA è la città con campo YVAL più piccola
27
Nodo N
LIV 0
LIV 1
LIV 2
ALESSANDRIA è la città con campo YVAL più piccola
28
Nodo N
LIV 0
LIV 1
LIV 2
ALESSANDRIA è la città con campo YVAL più piccola
29
CONSIDERAZIONI (sotto-albero sinistro)
Se il livello N è pari, un nodo di rimpiazzo in Tl sarà il
nodo in cui il campo XVAL ha valore più grande.
In modo analogo, se il livello N è dispari, consideriamo
il nodo di rimpiazzo Tl che ha campo YVAL maggiore.
30
RANGE QUERY IN ALBERI 2-D
Una query su un intervallo in un albero a 2-d è una ricerca che
permette di recuperare tutti i punti situati all’interno di una
circonferenza con centro nel punto
(xc, yc) e raggio r.
La risposta alla query recupera tutti i punti inseriti nell’albero che
hanno una distanza dal centro minore del raggio. In altre parole
si presuppone di trovare tutti quei punti dell’albero 2-d che
stanno nell’intorno.
Nell’elaborazione di una query su un intervallo è necessario
ricordare che ogni nodo N inserito all’interno dell’albero
definisce una regione Rn.
31
RANGE QUERY IN ALBERI 2-D
Se il cerchio in una query non ha intersezione Rn, allora non esistono
punti da cercare nel sottoalbero con radice N.
Se consideriamo la mappa precedente:
1) Il nodo con etichetta TORINO rappresenta tutti i punti del dominio
applicato
2) Il nodo etichettato BIELLArappresenta la regione di tutti i punti (x,y)
tali che x>66
3)Il nodo etichettato ALESSANDRIA rappresenta tutti i punti(x,y) tali che
x>=19 e y<65
4)Il nodo etichettato CUNEO rappresenta tutti i punti (x,y) tali che x<66.
32
33
INOLTRE…
Ad ogni nodo vengono associate altre 4 coordinate che
unite costituiscono la regione rappresentata da quel
nodo.
1) XLB e XUB: rappresentano l’angolo inferiore e
superiore per le ascisse(di X)
2) YLB e YUB : rappresentano l’angolo inferiore e
superiore delle ordinate(di Y).
34
Questi dati vanno a modificare la definizione del
nodo:
Newnodetype=record
XVAL, YVAL: real
XLB,XUB,YLB,YUB: real
LLINK, RLINK: newnodetype
35
ALBERI K-D per K>2
In modo analogo, possiamo considerare un albero tri-
dimensionale con k=3 con coordinate(x,y,z), oppure un albero a
4-D che rappresenterebbe punti della forma (x,y,z,t), etc.
La struttura del nodo in un albero K-D
INFO: infotype
VAL[K]:real
LLINK,RLINK:nodetype
Il campo VAL[K] è una matrice di dimensioni pari a K
36
PUNTI QUADTREE
Questo tipo di struttura è utilizzato per rappresentare i
punti in due dimensioni. Ogni nodo divide la regione
in quattro quadranti:NO(nord-ovest),NE(nord-est),
SO(sud-ovest),SE(sud-est).
In questo caso, il nodo N divide le regioni che
rappresenta, disegnando sia una linea orizzontale che
una linea verticale attraverso i punti XVAL e YVAL.
37
STRUTTURA NODO QUADTREE
Qt_node_type= record
INFO: type_info
XVAL: real
YVAL: real
NO,NE,SO,SE: Qt_node_type
38
STRUTTURA NODO QUADTREE
I campi NO,NE,SO,SE corrispondono ognuno ad un
figlio del nodo N. quindi ogni nodo potrebbe avere
quattro figli.
INFO
NO
SO
X
NE
Y
SE
39
INSERIMENTO NEI PUNTI QUADTREE
Inizialmente, l’albero è
vuoto quindi inseriamo
il primo nodo TORINO con
i campi XVAL e YVAL
rispettivamente(66,83).
NO
SO
NE
SE
40
Inseriamo il secondo elemento BIELLA che ha
coordinate(74,115), questa città cade nel quadrante NE
(risultante della divisione precedente). In questo modo
TORINO ha come figlio NE BIELLA.
TORINO
66
83
NE
BIELLA
74
115
41
42
Inseriamo il terzo elemento, ALESSANDRIA che ha
coordinate(98,65). Questo punto si trova a SE della
divisione di TORINO.
Procediamo con l’inserimento del quarto punto che è
CUNEO, con coordinate(42,15), e questo ultimo punto
si trova nel quadrante SO .
43
44
45
Se volessimo aggiungere ad. es.
un’altra città ALBA, con
coordinate (70,49), questa si
troverà a SO di ALESSANDRIA.
46
47
CANCELLAZIONE PUNTI QUADTREE
Quando cancelliamo un nodo N da un punto quadtree,
come nel caso dell’albero a 2-D, per prima cosa
dobbiamo trovare un valido sostituto del nodo da
cancellare.
Nel caso del nodo foglia la cancellazione è banale, infatti
basta settare il puntatore del nodo padre a NULL.
48
CANCELLAZIONE PUNTI QUADTREE
La cancellazione, invece, di un nodo interno è più complessa.
Infatti per prima cosa bisogna trovare un nodo di rimpiazzo, in
uno dei sottoalberi N (NO, NE, SO,SE) in modo tale che siano
verificate le seguenti proprietà:
1) ogni nodo R1 del sottoalbero N.NO è a NORD-OVEST di R
2)ogni nodo R2 del sottoalbero N.SO è a SUD-OVEST di R
3) ogni nodo R3 del sottoalbero N.NE è a NORD-EST di R
4) ogni nodo R4 del sottoalbero N.SE è a SUD-EST di R
49
QUERY SU INTERVALLI DI VALORI NEI PUNTI QUADTREE
Questo argomento viene trattato allo stesso modo
degli alberi a K-D. L’intervallo di ricerca viene
rappresentato con una circonferenza con coordinate
(xc, yc) e raggio r. Ogni nodo nei punti quadtree
rappresenta una regione, l’algoritmo di ricerca scarta i
sottoalberi la cui radice sono i nodi alle quali le regioni
associate non hanno intersezioni con il cerchio di
ricerca.
50
Quadtree - MX
L’ordine di inserimento dei nodi nei k-tree e nei Quadtree point
influenza la forma finale dell’albero. Di conseguenza questo
influisce sulla complessità di inserimento e ricerca
di un dato nodo N.
L’intento dei Quadtree-MX è di rendere indipendente la forma
dell’albero rispetto al numero di nodi presenti in esso, così come
l’ordine in cui i nodi sono inseriti. Questo tipo di approccio
rende gli algoritmi di ricerca e cancellazione più efficienti.
51
Quadtree – MX (Funzionamento)
Assumiamo che la mappa da rappresentare sia suddivisa
in una griglia di forma
per un dato k. Lo
sviluppatore può scegliere un k in modo arbitrario,
così da poter rispecchiare la granularità desiderata, ma
una volta scelto k non può essere cambiato.
52
Quadtree – MX (Struttura)
I Quadtree-MX hanno la stessa struttura dei Quadtree
Point, salvo per una differenza nella Root dell’albero.
Infatti la Root rappresenta la regione specificata da:
Tutte le sotto-regioni (NW,SW,NE,SE) hanno lo stesso
tipo di rappresentazione delle coordinate, basandosi
però su w = XUB – XLB.
53
Quadtree – MX (Inserimento)
Fissiamo k = 3 (griglia 8 x 8)
Supponiamo di voler inserire i seguenti nodi:
Nodo A = Coord (x = 1, y = 3);
Nodo B = Coord (x = 3, y = 3);
Nodo C = Coord (x = 3, y = 1);
Nodo D = Coord (x = 3, y = 0);
54
Quadtree – MX (Inserimento)
Nodo generico
NW
SW
NE
Root
SE
1. Si crea la Root che rappresenta la regione
(XLB = o,XUB = 4, YLB = 0, YUB = 4)
2. A risiederà nella sotto-regione
NW della Root. Quindi si crea il nodo NW.
55
Quadtree – MX (Inserimento)
Nodo generico
NW
SW
NE
Root
SE
1. Si crea la Root che rappresenta la regione
(XLB = o,XUB = 4, YLB = 0, YUB = 4)
2. A risiederà nella sotto-regione
NW della Root. Quindi si crea il nodo NW.
A
56
Quadtree – MX (Inserimento)
Nodo generico
NW
SW
NE
SE
Root
A = (1,3)
B = (3,3)
A
B
57
Nodo generico
Quadtree – MX (Inserimento)
NW
SW
NE
SE
Root
A = (1,3)
B = (3,3)
C = (3,1)
A
B
C
58
Nodo generico
Quadtree – MX (Inserimento)
NW
SW
NE
SE
Root
A = (1,3)
B = (3,3)
C = (3,1)
D = (3,0)
A
B
C
D
59
Quadtree – MX (Cancellazione)
La cancellazione nei Quadtree-MX è abbastanza
semplice, perché ogni nodo è rappresentato a livello
foglia nell’albero. Se N è un nodo internodi un
Quadtree-MX la cui radice è puntata da T, allora la
regione implicitamente rappresentata da N contiene
almeno un punto esplicitamente contenuto nell’albero.
60
Quadtree – MX (Cancellazione)
Per cancellare un punto (x,y) da un albero T si procede come segue:
1.
2.
3.
Si imposta il valore del collegamento di N al padre (M) a
NULL.
Si controlla se gli altri tre campi DIR del padre sono vuoti. Se
si, allora si passa al padre di M (P) e si imposta il collegamento
nodo figlio (M in questo caso) a NULL.
Si procede così ricorsivamente a salire.
61
Quadtree – MX (Cancellazione)
In conclusione…
Il tempo di accesso all’albero richiede uno scorrimento
dall’alto verso il basso (per trovare e cancellare il nodo)
ed uno scorrimento dal punto di cancellazione fino
alla radice (per eliminare i nodi impliciti ed espliciti
che contenevano al più un solo “figlio”).
Il tempo richiesto è quindi O(k).
62
Quadtree – MX (Range Query)
Sono gestite allo stesso modo dei Quadtree Point, salvo
per due differenze:
1. Il contenuto dei campi XUB,XLB,YUB,YLB è
differente.
2. Siccome i punti sono tutti immagazzinati al livello
foglia, la verifica di un punto per vedere se risiede nel
query range, viene fatta solo al livello foglia.
63
R - Tree
Questo tipo di strutture dati serve ad immagazzinare
“regioni rettangolari” di un’immagine o di una
mappa. Gli R-Tree sono davvero efficienti per
immagazzinare grandi quantità di dati su disco. Dal
momento che l’accesso al disco richiede molto tempo,
gli R-Tree garantiscono un metodo conveniente,
minimizzando il numero di accessi.
64
R – Tree (Struttura)
Rnodetype = record
Rec1,……Reck = rectangle;
P1,……….Pk = ->rnodetype;
End
R1
R2
G1 G2
R3
R4 R5
R6
R7
G3
G4
R8 R9
65
R – Tree (Struttura)
Ogni R-Tree ha associato un ordine che è un intero k.
Ogni nodo che non è una foglia, contiene un insieme di
k rettangoli (al massimo) o [k/2] rettangoli (almeno).
Root è l’unica eccezione a queste regole.
Ogni rettangolo è sia un rettangolo reale che un gruppo
di rettangoli.
66
R – Tree (Inserimento)
Supponiamo di voler
inserire il rettangolo R10
dentro la struttura ad albero
vista in precedenza e
rappresentata dalla mappa a
destra…
R7
R5
R6
R4
R1
R
2
R3
R8
R10
R9
67
R – Tree (Inserimento)
Il metodo migliore che ci viene
suggerito anche dalla figura è quello
di inserire il rettangolo R 10
espandendo l’area del gruppo 1 di
rettangoli. Infatti, se si cercasse di
inserire R 10 dentro il gruppo 3 si
averebbe un incremento sostanziale
dell’area coperta .
R7
R5
R6
R4
R1
R
2
R3
R8
R10
R9
68
R – Tree (Inserimento)
Ora vogliamo inserire il rettangolo
R11…
Abbiamo 2 opzioni:
1. Inserire il rettangolo nel gruppo
che ha ancora spazio (in questo
caso il gruppo 3).
R7
R5
R6
R4
R1
R
2
R3
R10
R11
R8
R9
69
R – Tree (Inserimento)
Ora vogliamo inserire il rettangolo
R11…
Abbiamo 2 opzioni:
1. Inserire il rettangolo nel gruppo
che ha ancora spazio (in questo
caso il gruppo 3).
2. Creare un sotto-gruppo con le
regioni R4 ed R11
R7
R5
R6
R4
R1
R
2
R3
R10
R11
R8
R9
70
R – Tree (Cancellazione)
La cancellazione negli R-Tree può
violare il vincolo i integrità (ovvero
che ci siano sempre almeno [k/2]
rettangoli (reali o gruppi).
Quindi, quando si elimina un
rettangolo dall’albero, bisogna
assicurare il vincolo.
R7
R5
R6
R4
R1
R
2
R3
R10
R11
R8
R9
71
R – Tree (Cancellazione)
G1 G2
R1
R2
R3
R4 R5
R6
R7
G3
G4
R8 R9
72
R – Tree (Cancellazione)
G1 G2
G3
G4
Condizione di
Underflow
R1
R2
R3
R4 R5
R6
R7
R8
73
R – Tree (Cancellazione)
G1
G2
G3
G4
Soluzione!!!
R1
R2
R3
R4 R6
R7
R8 R5
74
Per concludere…
Point Quadtree:
Pro: di facile implementazione
Contro: un albero con k nodi può avere l’altezza = k e
la complessità può arrivare a O(k).
Inoltre è richiesta sempre la comparazione di due campi,
non solo uno.
La cancellazione è spesso difficile.
K-d tree:
Pro: di facile implementazione
Contro: un albero con k nodi può avere l’altezza = k e
la complessità è peggiore dei point-Quadtree.
La complessità nel caso peggiore della ricerca arriva a
75
Per concludere…
Quadtree-MX:
Pro: garantiscono l’altezza O(n).
Inserimento, cancellazione e ricerca hanno un tempo proporzionale
O(n). Il range di ricerca è molto efficiente
dove N = numero di punti in risposta alla ricerca e h
è l’altezza dell’albero.
R-tree:
Pro: Ottimi per l’ottimizzazione degli accessi al disco, riducendo
notevolmente l’altezza dell’albero. Questo li rende molto popolari.
Contro: I rettangoli si possono sovrapporre tra di loro, dando vita a percorsi
differenti che portano allo stesso rettangolo. Questo può provocare
un accesso multiplo al disco, vanificando l’ottimizzazione.
76