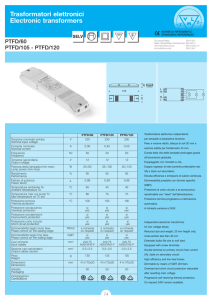
Alma Mater Studiorum – Università di Bologna
WEKA
Data Mining System
Sistemi Informativi a supporto delle Decisioni LS - Prof. Marco Patella
Presentazione di: Fabio Bertozzi, Giacomo Carli
1
WEKA: the bird
Gallirallus australis (Sparrman, 1786)
• Uccello nativo della Nuova
Zelanda
• Altezza: 50 cm
• Peso: 1 Kg
• Onnivoro
• In via di estinzione
• Maschio e femmina si
occupano della prole
• Secondo una leggenda
neozelandase rubano
oggetti luccicanti e sacchi
di zucchero
2
WEKA: Introduzione
Software di machine learning e data mining
Università di Waikato (Nuova Zelanda)
Scritto in Java
Licenza GNU
Main features:
Interfaccia grafica
Set di tool per data pre-processing,
Possibilità di utilizzare numerosi algoritmi di clustering, per
alberi decisionali DT, di ricerca di regole associative AR
Indici di valutazione sulla “bontà” dell’algoritmo
3
WEKA: apertura del software
1
2
3
4
Database in input
Nome della relazione
@relation bank
Lista degli attributi e loro tipologia
@attribute age numeric
@attribute sex {FEMALE,MALE}
@attribute region {INNER_CITY,TOWN,RURAL,SUBURBAN}
@attribute income numeric
@attribute married {NO,YES}
Attributo nominale
@attribute children {0,1,2,3}
@attribute car {NO,YES}
Attributo numerico
@attribute save_act {NO,YES}
@attribute current_act {NO,YES}
@attribute mortgage {NO,YES}
@attribute pep {YES,NO}
Area dati con enumerazione delle tuple
@data
40,MALE,TOWN,30085.1,YES,3,YES,NO,YES,YES,NO
51,FEMALE,INNER_CITY,16575.4,YES,0,YES,YES,YES,NO,NO
23,FEMALE,TOWN,20375.4,YES,3,NO,NO,YES,NO,NO
57,FEMALE,RURAL,50576.3,YES,0,NO,YES,NO,NO,NO
57,FEMALE,TOWN,37869.6,YES,2,NO,YES,YES,NO,YES
22,MALE,RURAL,8877.07,NO,0,NO,NO,YES,NO,YES
58,MALE,TOWN,24946.6,YES,0,YES,YES,YES,NO,NO
37,FEMALE,SUBURBAN,25304.3,YES,2,YES,NO,NO,NO,NO
Ricerca di una soluzione
che permetta
di utilizzare fonti differenti
Scelte:
• Formato file semplice e
intelleggibile
• Struttura piatta del database
Necessità di
preprocessing dei dati
5
Explorer: pre-processing dei dati
ARFF
CSV
Formati aperti
C4.5
binary
letti da un URL
database SQL usando JDBC
Conteggio tuple
Presentazione
dei dati all’utente
Funzioni
Pre-Processing:
i tool di
preprocessing
di Weka sono
chiamati “Filters”
Distribuzione dei valori degli attributi
Analisi cross-attributo
discretizzazione
normalizzazione
Rappresentazioni
grafiche
Selezione, trasformazione e
combinazione degli attributi
6
Explorer: i “classifiers”
Classifiers
modelli per predire
attributi numerici
e nominali
Esempio: Decision Trees
Algoritmi tradizionali
J48 è l’implementazione di Weka dell’algoritmo C4.5,
creato da Ross Quinlan dell’Università di Sydney.
L’algoritmo genera un decision tree.
• Metodo di selezione degli attributi in base all’IG
• Possibilità di utilizzare un Training Set con
dati mancanti
• Possibilità di utilizzare attributi con valori
numerici continui
Non c’è necessità di discretizzare
Metodo: User Classifier
Ogni passo di split dell’albero è svolto
dall’utente che seleziona un cluster tramite
una rappresentazione bidimensionale dei
dati
Limiti:
• Buona conoscenza del dominio
• Struttura semplice dei dati,
• Cluster facilimente riconoscibili
7
Explorer: clustering data
WEKA può eseguire numerosi algoritmi di clustering:
k-Means,
Clustering basato sulla densità
…
Visualizzazione dei cluster ottenuti con comparazione su
vari attributi
Possibilità di eseguire misure di bontà sui risultati degli
algoritmi
8
Explorer: ricerca di regole associative
WEKA contiene un’implementazione
dell’algoritmo Apriori
nella scheda “Associate”:
Lavora su dati
discreti
Identifica le relazioni
tra attributi e gruppi di
attributi
Ricerca le regole che
eccedono il supporto minimo
e hanno confidenza
superiore al valore
prestabilito
9
Explorer: attribute selection
Strumento utile per ricercare quali sono gli attributi
(o subset di attributi) maggiormente predittivi
Il metodo di selezione è articolato in due parti:
Search method:
Evaluation method:
best-first,
forward selection,
random, exhaustive,
genetic algorithm,
ranking
Esempio semplice:
Ordina gli attributi in base all’IG
• Search method: ranking
• Evaluation Method:
Information Gain
Correlazione
Information gain
Test chi-quadro
…
WEKA consente combinazioni (abbastanza) libere dei metodi
10
Explorer: data visualization
Semplice funzione che permette di analizzare in maniera visiva i dati
WEKA visualizza singoli attributi in un grafico 1-D e coppie di attributi
2-D
Limite: mancanza di visualizzazione 3-D che viene risolta
introducendo in un grafico 2-D diversi colori
Parametri di visualizzazione:
I valori delle classi sono rappresentati con diversi colori
L’opzione “Jitter” permettere di visualizzare i punti nascosti per gli
attributi nominali
Funzioni di zoom, dimensionamento dei grafici e dei punti
rappresentati
11
WEKA: Experimenter
L’Experimenter permette di comparare diversi modelli di
apprendimento
Adatto per problemi di regressione e classificazione
I risultati possono essere trasveriti in un database
Metodi di valutazione:
Cross-validazione
Curva di apprendimento
I metodi di valutazione possono essere reiterati per diverse
configurazioni dei parametri dei modelli di apprendimento
12
Analisi dei risultati
Export dei risultati in:
ARFF file
CSV file (Comma Separated Values)
JDBC database
Importato in Excel
Analisi statistica dei dati
Scheda Analyse di WEKA :
Matrice di analisi sui diversi run
dataset analizzati
modelli di apprendimento
% di istanze
classificate correttamente
Notazioni:
v:
risultato statisticamente migliore rispetto allo
schema base
*:
risultato statisticamente peggiore rispetto allo
schema base
Vettore (xx/yy/zz):
indica su quanti dataset lo schema è stato
migliore/equivalente/peggiore rispetto allo schema base
13
Analisi dei risultati: Cross Validazione
Algoritmo
1.
2.
3.
4.
Il dataset è diviso in k subset.
Ogni subset è diviso in training set e test set
For i:=1 to k
1. Definisci una funzione che predice i dati
2. testa la funzione sui K-1 dataset precedenti come test set
3. Calcolo del Mean Absolute Error
Computa l’errore medio su tutti i k subset
Funzione con rumore
Funzione senza rumore
Vantaggio: utilizzando tanti subset, il
metodo è poco influenzato
da come sono suddivisi i
dati. All’aumentare di K si
ottiene una maggiore
precisione della previsione
Svantaggio: l’algoritmo deve iterare k
volte per svolgere una
valutazione
14
WEKA: Knowledge Flow
Interfaccia grafica innovativa che rappresenta un flusso
informativo
Basato sulla piattaforma Java Beans
DB sorgenti, classifiers, etc. sono beans e possono essere
connessi graficamente
I Layout ottenuti possono essere salvati
Cambiando le impostazioni del datasource, si può eseguire lo
stesso flusso su diversi dataset
Esempio di un tipico flusso di dati:
data source
filter
classifier
evaluator
15
WEKA: the bird
Grazie per
l’attenzione
!
16