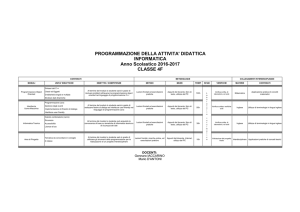
")
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
RETI NEURALI (Artificial Neural Networks)
Le macchine di Von Neumann, sono molto efficienti per risolvere quei problemi di calcolo in cui l’uomo ha molta difficoltà. Viceversa, non sono in grado di risolvere agevolmente quei problemi di riconoscimento (oggetti, voci, suoni) che
l’uomo invece risolve facilmente. Pensiamo alla difficoltà che sta nel riconoscimento di un semplice “cane” da un
“semplice” gatto: occorrerebbe programmare tutte le razze, le possibili variazioni di dimensioni e di incroci tra di esse, in
modo da poter effettivamente ottenere una risposta di “match”.
Prossiamo schematizzare le differenze tra Macchine di Von Neumann e Sistema biologico neuronale secondo la seguente
tabella:
Macchina di Von Neumann
Sistema biologico neuronale
Processore
Complesso
Semplice
Alta velocità
Bassa velocità
Uno a alcuni
Moltissimi
Memoria
Separata dal processore
Integrata nel processore
Localizzata
Non indirizzabile dal contesto
Elaborazione
Centralizzata
Distribuita
Sequenziale
Parallela
Basata su programmi
Auto-apprendente
Affidabilità
Vulnerabile al massimo
Robusta
Campo operativo
Manipolazione numerica e simbolica Problemi di percezione
Ambiente operativo Ben definito, ben vincolato
Poco definito, non vincolato
Uno studio approfondito delle reti neurali, richiede conoscenze di neurobiologia, psicologia e pedagogia, fisica, teoria dei
sistemi, informatica, intelligenza artificiale, matematica e statistica, elaborazione parallela, hardware (digitale, analogico,
VLSI, ottico).
Le reti neurali, fondano la loro origine dalla volontà di “ricopiare” il funzionamento del cervello umano, secondo la moderna NEUROBIOLOGIA:
Un insieme di cellule nervose interconnesse da una fitta rete di collegamenti allo scopo sia computazionale che di memorizzazione. Tutti i neuroni hanno la caratteristica di operare contemporaneamente.
I primi studi sulle reti neurali, risalgono agli anni ‘40, grazie al contributo di McCulloch e Pitt. Nel 1960, Rosemblatt presentò il teorema della convergenza del Perceptron e Minsky e Papert mostrarono le limitazioni di un Perceptron semplice.
Per i successivi vent’anni, non si fece quasi nulla, fino agli anni ‘80, in cui si sono sviluppati enormemente, grazie ad una
serie di fattori concomitanti, tra i quali ricordiamo:
• Sviluppo della neurobiologia e della microelettronica
• Fallimento dei “sistemi Esperti” e della ”Intelligenza Artificiale”, basati sulle macchine di Von Neumann, per il riconoscimento delle immagini e dei suoni.
Tra gli studi effettuati, vanno ricordati:
• 1982: modello energetico introdotto da Hopfield
• 1986: Algoritmo di apprendimento “Back-Propagation” per Perceptron multistrato (Werbos, Rumelhart e altri)
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 93
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
IL NEURONE BIOLOGICO: RETE NEURONALE
La corteccia cerebrale umana può essere paragonata ad una membrana di circa 3 mm di spessore con una superficie totale
di 2.200 cmq (2 volte la misura di una tastiera per computer). Nella corteccia vi sono circa 100 Giga ( circa il numero di
stelle della Via Lattea) cellule nervose, dette neuroni. Ogni neurone è connesso con migliaia di altri, creando una fittissima rete di interconnessione (da 1014 a 1015 connessioni) in cui transitano sia segnali chimici che elettrici. I neuroni comunicano attaverso brevi treni di impulsi della durata di alcuni ms. La frequenza di trasmissione, è di alcuni centinaia di Hz
che è di milioni più lenta di quella dei moderni processori. D’altra parte, una elaborazione complessa come il riconoscimento di un volto, viene eseguita dal cervello in poche centinaia di ms: questo comporta che la decisione non può impiegare più di 100 passi consecutivi. Possiamo quindi dire che il cervello esegue programmi paralleli di composti da circa 100
passi ciascuno (regola dei cento passi). L’informazione che transita da un neurone all’altro è composta da pochi bits: questo implica che le informazioni critiche sono catturate e distribuite nelle interconnessioni, da cui deriva il modello di riferimento delle reti neurali (ANN) chiamato “connectionist model”.
Ogni neurone (cellula nervosa) è una speciale cellula biologica che è in grado di processare informazioni. La struttura
della cellula è mostrata nella figura seguente, in cui a sinistra viene rappresentata una foto reale ed a destra lo schema di
riferimento.
Fotografia al microscopio di una cellula nervosa “umida”.
•
•
•
•
SOMA = corpo centrale
ASSONE = Prolungamento del SOMA che si ramifica in molti terminali.
DENDRITI (IN) Informazioni da altri neuroni.
SINAPSI (OUT) Informazione in uscita per altri neuroni: grazie all’azione di alcune sostanze chimiche possono assumere sia un’azione inibitoria che eccitatoria.
Ogni neurone si collega agli altri tramite le dendriti e si connette ai terminali dell’assone tramite le sinapsi: qui, grazie
alla presenza di sostanze chimiche dette neurotrasmettitori, si ha INIBIZIONE o ECCITAZIONE che OSTACOLA o FAVORISCE il collegamento.
Ogni neurone riceve segnali in ingresso da tutti i dendriti ed emette un impulso elettrico in uscita sull’assone. In pratica,
ogni neurone effettua la “somma pesata” degli ingressi e, se viene superata la soglia caratteristica, viene emesso il segnale
di uscita corrispondente. Nel tempo, possono variare, sia i collegamenti tra i vari neuroni, sia il peso di ogni collegamento
sinaptico. Questa adattività nel funzionamento delle sinapsi è probabilmente quello che è responsabile della “memoria”
umana.
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 94
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
In base a queste conoscenze sul funzionamento della corteccia cerebrale, si sono sviluppati dei modelli semplificati per
cercare di simularne il funzionamento. Allo stato attuale, sono stati definiti i seguenti modelli dedicati ciascuno ad un particolare tipo di problema:
Pattern Classification
Assegnare un pattern di ingresso ad una specifica classe
predefinita.
Esempi:
• Riconoscimento caratteri (OCR) e voce
• Classificazione di ECG e cellule sanguigne
• Ispezione di circuiti stampati.
Clustering/categorization
Non esistono classi predefinite. Il sistema deve indagare
sulle caratteristiche simili di ogni pattern e quindi raggrupparli. (Classificazione non supervisionata).
Esempi:
• Data mining
• Compressione dati
• Analisi esplorativa di dati
Approssimazione di funzioni
Date n coppie di valori misurati di dati, probabilmente affetti da rumore, si vuole trovare una funzione probabile per
la descrizione del fenomeno.
Predizione/forecasting
Dati n campioni temporali, si vuole prevedere il prossimo
valore. Questo problema ha importanza fondamentale nel
supporto alle decisioni in campo commerciale, scientifico ed
ingegneristico. Esempi tipici sono:
• Previsioni di mercato
• Previsioni del tempo
Ottimizzazione
Una grande varietà di problemi di matematica, statistica,
ingegneria, scienza, medicina ed economia possono essere
posti come problemi di ottimizzazione. Il compito è di trovare una soluzione che soddisfi una serie di vincoli e massimizzi o minimizzi la funzione obiettivo.
Memoria Associativa (Content-addressable memory)
Il problema è di accedere ad una locazione di memoria, specificando il suo contenuto, anche in maniera distorta o incompleta.
Tipica applicazione è nelle costruzione di database multimediali.
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 95
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
Controlli automatici
Dato un sistema dinamico definito dalle tuple di ingresso e
di uscita, si desidera generare un controllo che forzi il sistema alla traiettoria voluta definita da un modello matematico di riferimento.
L’esempio in figura mostra un controllo di velocità di un
motore.
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 96
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
IL NEURONE FORMALE: RETE NEURALE
Partendo dal neurone biologico, McCulloch e Pitts proposero il seguente modello matematico:
x1wi1
x2 wi 2
yi ≡ xi
.
∑w x
.
ij j
− ∆i
j
.
x j wij
Ogni ingresso xj vale 1 o 0, wij può essere positivo o negativo. Se la somma supera ∆i si avrà 1 in uscita.
Il modello è consistente in quanto si è dimostrato (Mc Culloch e Pitts - 1943) che qualsiasi calcolo esprimibile tramite
un programma su una macchina di Von Neumann, è realizzabile da una appropriata rete neurale introducendo dei neuroni di ingresso che prelevano i dati e dei neuroni di uscita
che comunicano i risultati.
Risulta evidente che, se si riesce a rendere modificabili i pesi wij con meccanismi di tipo biologico, le reti neurali sono
in grado di adattarsi a condizioni di funzionamento generiche, non previste in fase di progetto.
Assegnazione dei pesi w
1. FASE DI APPRENDIMENTO
La rete viene stabilizzata utilizzando un campione di
dati con uscita nota, ripetendo l’esperimento fino ad arrivare ad ottenere tutte le risposte corrette
2. FASE DI RICONOSCIMENTO
Introduco dati qualsiasi ed ottengo le risposte. Non è garantita la precisione delle risposte
La caratteristica di non essere “precisa”, è quello che volevamo ottenere: se due rappresentazioni di oggetti sono
molto simili, la rete neurale li inserirà nella medesima classe.
Strato di
uscita
Strato di
ingresso
Strato nascosto
In base alla tipologia di connessione (architettura) una rete neurale può essere classificata in due categorie fondamentali:
• Reti FEED-FORWARD, in cui non ci sono anelli di retroazione. Sono reti statiche e producono solo un set di valori di
uscita.
• Reti RECURRENT (o FEEDBACK), in cui vi sono delle connessioni di ritorno (retroazione). Sono reti dinamiche: in
risposta ad un pattern di input, una volta modificate le uscite, queste vengono retroazionate agli ingressi causando una
sequenza di valori di uscita fino alla stabilità.
La figura seguente mostra la tassonomia completa delle due categorie:
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 97
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
PATTERN RECOGNITION
Uno degli scopi fondamentali delle reti neurali, è quello di riconoscere in oggetto in base ai suoi attributi (pattern). La possibilità di modificare i pesi w ci garantisce l’adattabilità della rete per risolvere problemi di riconoscimento di “pattern”
qualsiasi, fermo restando i limiti sul numero di neuroni da utilizzare.
Ovviamente, uno schema del genere, non può essere paragonato nemmeno al cervello di un insetto, sia per il numero limitato di neuroni, sia per le dovute semplificazioni dovute al modello matematico stesso.
Per capire ulteriormente il concetto di “pattern”, vediamo il seguente esempio:
Per rappresentare un animale, utilizziamo un pattern di 8 elementi che ne rappresentano le seguenti caratteristiche:
1. capace di camminare
5. ha il sangue caldo
2. capace di nuotare
6. allatta i piccoli
3. capace di volare
7. ha il manto peloso
4. è un cacciatore
8. ha le piume
da qui vogliamo determinare se un animale appartiene o no alla classe dei mammiferi.
Ogni animale può quindi essere individuato specificando il suo “pattern”, specificando -1 se la caratteristica è assente e 1
se la caratteristica è presente. In uscita avrò il valore 1 se la richiesta (mammifero) è soddisfatta dal pattern di ingresso,
ovvero: x1w1 + x2w2 ... xjwj + = 1
L’apprendimento, in questo caso, consisterà nel trovare i pesi wj che soddisfano l’equazione, ovvero basterà risolvere il
sistema di equazioni in 8 incognite costituito dalle n possibili configurazioni LINEARMENTE INDIPENDENTI di ingresso.
Utilizzando la notazione matriciale, avremo: X .W = Y ovvero sostituendo i valori noti degli ingressi e dell’uscita:
x11
x
21
...
x81
x12
x 22
...
x82
... x18 w1 y1
... x 28 w2 y2
=
.
... ... ... ...
... x88 w8 y8
Risolvendo il sistema per ogni w, avremo determinato il “discriminante lineare” che permetterà di ottenere la corretta risposta per ogni combinazione degli ingressi.
Generalizzando per un pattern di ingresso di dimensione qualsiasi ed una uscita di dimensione k (n.ro di uscite = classificazione in più classi), avremo:
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 98
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
x11
x
21
...
x n1
x12
x 22
...
xn 2
... x1ìn w11
... x 2 n w21
.
... ... ...
... x nn wn1
w12
w22
...
wn 2
... w1k y11
... w2 k y21
=
... ... ...
... wnk yn1
y12
y22
...
yn 2
... y1k
... y2 k
... ...
... ynk
x1
w11
y1
x1
y2
yk
xn
wnk
La soluzione analitica di tale sistema è molto onerosa e poco rispondente alla realtà applicativa, dove l’apprendimento può
essere considerato come una iterazione di osservazioni di caratteristiche successive con conseguente correzione dei pesi
relativi.
IL PERCEPTRON
A questo punto risulta evidente che il particolare schema di rete neurale è strettamente legato all’algoritmo che si intende
utilizzare per l’apprendimento. Uno schema elementare è rappresentato dal perceptron ed il relativo algoritmo di apprendimento è il seguente:
1. Inizializza la matrice W con valori random tra 0 e 1, poni k=0
2. Presenta il pattern k-esimo Xk e l’uscita corretta Yk relativa a tale pattern
3. Determina l’errore e = Yk - WkTXk da moltiplicare ad un fattore di correzione ρ compreso tra 0 e 1.
4. Se l’errore è superiore ad una soglia prefissata, interrompi l’algoritmo (non c’è convergenza), altrimenti l’errore viene
utilizzato per aggiornare la matrice W, secondo la: Wk+1 = Wk + ρ(Yk - WkTXk) Xk
5. k = k + 1 , torna al punto 2
Da questo algoritmo si deduce che non è assicurata la convergenza, a meno di ridurre artificiosamente il fattore di correzione dell’errore. In questo caso, però nessuno ci assicurerà del corretto funzionamento del perceptron.
La non convergenza può essere spiegata graficamente, in quanto il discriminante lineare può essere rappresentato da un
iperpiano che separa i pattern appartenenti alla classe ricercata dagli altri:
PERCEPTRON CONVERGENTE
x1
1
PERCEPTRON NON CONVERGENTE
x1
1
o o
o o
o o o o
o o
x
o o o
o o
x x
o
o o
x
x
o
o
x
x
x
o
o
x
xx
x x
o
x
x=pattern appartenenti alla classe
o o
x
o o
o x xx o
o o
x o o o x
o o
x x
o
o x
o o x x o
o
x
o
x
o
x
x
xo
x x
o
x
x
1
x2
x=pattern appartenenti alla classe
1
x2
RETI MULTISTRATO
Per risolvere i problemi non linearmente separabili, occorre introdurre uno strato intermedio di neuroni, dotati di funzioni
di attivazione non lineari. Infatti, se si utilizzassero dei “pesi” lineari, sarebbe sempre possibile trovare una matrice prodotto che renderebbe inutile il compito dello strato intermedio.
La funzione non lineare da scegliere deve essere: derivabile ovunque, limitata, monotona crescente.
Possiamo scegliere la funzione di tipo “sigmoidale”:
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 99
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
f (x) =
1
(1 + e − ( x −θ ) )
Dalla figura a fianco, si vede che il parametro θ rappresenta
l’ascissa del punto di flesso che corrisponde ad una ordinata =
1/2.
Si può dimostrare che, con due strati intermedi ed un numero
sufficiente di nodi, si può eseguire una trasformazione arbitraria di un qualsiasi pattern di ingresso.
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 100
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
Presa una coppia di pattern associati X (= ingresso di dimensione n) e Y (= uscita di dimensione m), si può notare che la
matrice M = Y XT può essere vista come una memoria associativa in quanto gode delle 5 proprietà viste precedentemente.
Per richiamare l’informazione, occorre moltiplicare M per il pattern di ingesso, ovvero:
Y = M X = (Y XT )X = Y (XTX) = k Y
dove k è uno scalare che indica la somma dei quadrati delle componenti del pattern X, che si può sempre pensare di normalizzarlo ovvero imporre k = 1
Esempio:
x1
x1 y1 x2 y1 x3 y1
y1
y1
M = YX T = ⋅ [ x1 x2 x3 ] =
X = x2
Y=
x1 y2 x2 y2 x 3 y2
y2
y2
x3
x1
x3 y1
y
⋅ x2 = ( x12 + x22 + x32 ) ⋅ 1 = kY
se k = 1 ⇒ MX = Y
y2
x3 y2
x3
In caso di ingresso disturbato o incompleto, avremo una attenuazione o una amplificazione del vettore Y , comunque coerente con quanto volevamo ottenere. Dall’esempio precedente, infatti, se applichiamo un ingresso X’ con una componente
x1 y1
MX =
x1 y2
x2 y1
x2 y2
variata (es.: x3 = x*3 otterremo il fattore k = ( x12 + x22 + x3 x *3 ) che potrà essere maggiore o minore di 1.
L’amplificazione o attenuazione dell’uscita non è significativa se differenti pattern di ingresso generano uscite diverse, altrimenti si avrebbe un malfunzionamento della memoria. Per soddisfare questa caratteristica, basterà imporre che il prodotto di due pattern di ingresso differenti (distinguibili) debba avere prodotto nullo, ovvero: se X 0 ≠ X 1 ⇒ X 0T X1 = 0 .
Per soddisfare questa proprietà, dovremo scegliere dei pattern di ingresso che siano una base per lo spazio n-dimensionale.
Nell’esempio precedente, quindi avremo la possibilità di scegliere solo tre pattern distinguibili, basi dello spazio a tre dimensioni:
1
0
0
X 0 = 0
X1 = 1
X 2 = 0
0
0
1
Con questo procedimento, dimensionando opportunamente i pattern, si è in grado di memorizzare tutte le coppie di pattern
desiderate.
Le reti di Hopfield
Il modello di Hopfield si basa sul modello matriciale associando vettori uguali (Xk, Xk) e realizza una memoria autoassociativa. Per la realizzazione, si utilizza un solo strato di neuroni con le uscite di ciacuno collegate agli ingressi degli
altri (retroazione).
x1
y1
I neuroni utilizzati sono di tipo binario con uscita -1 e +1 e soglia nulla,
ovvero l’uscita sarà +1 con ingresso ≥ 0, -1 con ingresso < 0, ovvero:
yi = segno
wij y j
i≠ j
L’apprendimento è di tipo non supervisionato ed avviene applicando la
formula:
∑
x2
y2
x3
y3
wij =
∑ (2x − 1)(2x − 1)
s
i
s
j
wii = 0
s
Hopfield ha dimostrato che tale rete converge sempre.
Distanza di Hamming
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 103
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
La distanza di Hamming tra due caratteri di un codice binario, era stata definita come il numero di bit differenti tra i due
codici. Formalmente, estendendo al caso di uno spazio N-dimensionale con assi binari, possamo formalizzare la distanza
di Hamming nel seguente modo:
Distanza di Hamming tra due vettori X,Y a N componenti: H = N −
∑x y
i i
i
La distanza di Hamming, ci serve per determinare il grado di differenza tra due pattern, ovvero l’eventuale insensibilità di
una rete alla distorsione o incompletezza dell’input
Vediamo alcune reti che si basano sulla Distanza di Hamming:
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 104
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
Maxnet
x1
uj1
1
x2
-ε
j
x3
La rete Maxnet, accetta in ingresso pattern X con attributi di tipo
binario ed effettua una classificazione in base alla distanza di
Hamming tra le classi apprese ed il nuovo pattern: questo sarà classificato come appratenente alla classe i se la distanza con il pattern
di esempio Ci è più piccola di ogni distanza con le altri classi.
La rete è composta da tre strati:
1. Strato di ingresso: nessun calcolo, solo per bufferizzare
2. Strato intermedio: dovrà essere composto da tanti nodi quanti
sono le classi da discriminare. Ad ogni nodo j, viene effettuata
y1
1
-ε
-ε
y2
ujN -ε
1
-ε
-ε
yM
xN
la somma pesata:
1
∑x u
i ji
i
3. Strato di uscita: effettua una selezione dell’UNICO NODO che
presenta il massimo valore in uscita ( il VINCITORE), ponendo
tutti gli altri a 0.
La selezione del nodo vincitore viene effettuata grazie ai collegamenti laterali inibitori che agiscono tramite i pesi:
+1 per j = k
1
t jk =
ε=
−ε per j ≠ k
M
Dove M indica il numero delle possibili classi e quindi il numero di nodi dei livelli 2 e 3. Non entriamo nei dettagli di come effetuare la selezione del vincitore: occorrerà effettuare dell iterazioni successive in modo da differenziare gli ingressi
in modo da portare al massimo un’uscita e a zero le altre.
Questa rete, rispetto a quella di Hopfield, consente una riduzione della memoria necessaria: infatti, prendendo una rete con
100 ingressi e 10 classi, avremo bisogno di definire solo 100x10 pesi, mentre, nel caso di Hopfield, avremo avuto bisogno
di 100x100 pesi.
Reti ART (Adaptative Resonance Theory)
tji
x1
y1
x2
-ε
1
-ε
-ε
y2
1
-ε
-ε
-ε
xN
La rete, ideata da Grossberg e Carpenter, è derivata dalla Maxnet e
consente, tramite un apprendimento non supervisionato, di evitare di
conoscere a priori i possibili pattern di ingresso, ricavando
automaticamente la suddivisione in classi dei pattern di ingresso
(clustering).
Possiamo distinguere tra i due casi:
• Rete ART1 : vettori nello spazio di coordinate binarie
• Rete ART2 : vettori con coordinate reali continue nel range da 0 a 1
yM
1
L’algoritmo di apprendimento per una rete ART1 è il seguente:
1. Presenta il pattern X = { xi }
2. Calcola, dall’ingresso all’uscita, i valori y j =
∑b x
ij i
i
3. Trova il nodo di uscita cha ha valore yj più elevato (come per Maxnet)
4. Verifica che X appartenga al cluster j calcolando, dall’uscita all’ingresso, la somma pesata tramite tij e verificando la
∑t x
ij i
condizione:
i
X
> ρ dove ρ è un parametro di soglia e |X| è la norma del vettore X ovvero la
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
∑x
i
. Se il pattern
i
Pagina 105
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
è classificabile, aggiorna i pesi tij e bij per i valori i e j appena trovati e torna al passo 1; altrimenti disattiva il nodo che
ha risposta maggiore e torna al passo 2.
I vettori ed i pesi, vanno inizializzati nel seguente modo:
1
tij (0) = 11
tij (0) =
tij (n + 1) = tij (n) xi
bij (n + 1) =
1+ N
tij (n) xi
N
0.5 +
∑ t (n) x
ij
i
i =1
Il problema fondamentale delle reti finora analizzate sta nel fatto che esse restituiscono un solo risultato: per un determinato ingresso viene associata una sola classe e quindi in presenza di forti ambiguità negli ingressi, si possono avere delle
associazioni errate. La vicinanza ad altre classi, infatti non ci garantisce nulla riguardo la effettiva affinità con esse. Questo andamento si discosta da quanto sappiamo avviene nel cervello umano.
MAPPE CARATTERISTICHE DEL CERVELLO
Recenti studi effettuati per scoprire la rappresentazione dei dati nella mente, hanno evidenziato come nel cervello vi siano
delle zone distinte, ognuna dedicata ad un particolare tipo di riconoscimento. Esiste una zona dedicata all’udito, una alla
visione, una al moto e così via.
Interazioni
eccitatorie
Interazioni
a lunga
distanza
distanza laterale
Interazioni
inibitorie
50-100 µm
200-500 µm
Approfondendo la zona dedicata all’udito, inoltre si è scoperto che aree vicine della corteccia sono sensibili a stimoli
sonori di frequenze vicine. Le aree di risposta agli stimoli
sonori sono perfettamente ordinate e presentano un andamento quasi logaritmico con la frequenza. La rete di neuroni ha una dislocazione bidimensionale in cui ogni neurone
ha all’incirca 10000 interconnessioni e sviluppi una particolare attitudine grazie all’interazione con i neuroni vicini
secondo l’andamento indicato nella figura accanto.
Si possono evidenziare i tre tipi di comportamento:
• Eccitatorio: molto forte ma di influenza ridotta
• Inibitorio: intensità minore ma maggiore estensione
• A lungo raggio: le interazioni sono molto deboli ma possono raggiungere distanze dell’ordine dei centimetri.
LE MAPPE DI KOHONEN (Self Organizing Maps)
T. Kohonen, ha sviluppato un particolare tipo di rete neurale che ricalca il funzionamento descritto precedentemente.
La struttura generale della rete è simile a quelle viste finora:
la differenza sta nell’algoritmo di apprendimento. Ogni
elemento di processamento riceve in ingresso gli attributi
del pattern X e ne calcola la distanza euclidea dal vettore
dei pesi W associato a quell’unità di processamento.
β
b
a)
-3a
-a
a
-b/3
d ( X , Wk = X − Wk
L’unità che ha distanza minima, sarà quela che presenta risposta maggiore allo stimolo di ingresso.
L’interazione con le unità vicine può essere discretizzata ed
approssimata dei due casi della figura a lato:
β
3a
Distanza
dal neurone
b
b)
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
-a
a
Pagina 106
Distanza
dal neurone
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
a) Non si tiene conto solo delle interazioni a lungo raggio
b) Non si tiene conto nemmeno delle interazioni inibitorie
Il trascurare le interazioni inibitorie non comporta grossi
problemi in quanto la funzione è già discretizzata e non si
corre il rischio di interferenza con le unità vicine. In generale, quindi sarà preferibile utilizzare lo schema b).
L’algoritmo di apprendimento di una rete di dimensioni (I,J) dove J è il numero di vettori
(neuroni) ed I la dimensione di ciascun vettore, è il seguente:
1. Si inizializzano i pesi wij tra i nodi di ingresso i e di uscita j a piccoli valori casuali.
2. Si accetta il vettore di ingresso x(t) [t=0,1,...,n-1]
3. Si calcola la distanza tra il vettore e ciascun nodo:
dj =
∑ (x (t ) − w (t ))
j
2
ij
i≠ j
4. Si trova il nodo j’ del vettore di uscita a distanza minima e si modifica in modo adattivo il valore di questo vettore e dei
vettori j appartenenti ad un opportuno intorno di questo, secondo la formula:
wij (t + 1) = wij (t ) + α (t )( xi (t ) − wij (t ))
0 ≤ i ≤ j −1
j ∈ NEj ' (t )
L’intorno diminuisce nel tempo secondo la formula: NEj '(t ) = A1 + A2 e
dell’intorno e T2 il tasso di diminuzione nel tempo.
Il guadagno adattivo è decrescente secondo la:
t
−
T2
dove A1 e A2 delimitano i limiti
t
−
T1
α (t ) = Ae
(0 ≤ α (t ) ≤ 1 dove A determina il massimo cambiamento dei pesi e T1 il tasso di dimunuzione di
α(t).
5. Riprendi al punto 2
A scopo chiarificatore, utilizziamo il seguente programma per simulare una rete SOM quadrata:
/* Rete neurale di Kohonen */
#include <stdio.h>
#include <math.h>
#include <stdlib.h>
#include <values.h>
#include <malloc.h>
/* Variabili globali */
FILE *in, *out;
/* Pattern di input e Pesi di output */
char fi[256], fo[256]; /* Files relativi */
int maxiter;
/* Numero di iterazioni */
int maxri, maxco, maxnp; /* Righe e colonne e pesi */
int maxpa, maxat;
/* N.ro pattern di input ed attribuiti per pattern */
int bestri, bestco;
/* Rilevazione del Match */
float A;
/* Ampiezza massima alfa */
int A1, A2;
/* Limiti minimo e massimo dell'intorno beta */
int T1,T2;
/* Slope di alfa e beta */
int xmin, xmax, ymin, ymax;
float pin[512][16];
/* */
float pesi[16][16][16];
/* */
/* Richiesta dati */
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 107
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
int in_dati()
{
printf("\nMassimo numero di iterazioni
printf("\nRighe matrice di Neuroni ...
printf("\nColonne matrice di Neuroni .
printf("\nAmpiezza max alfa (<1) (0.8)
printf("\nAmpiezza minima intorno ....
printf("\nAmpiezza massima intorno ...
printf("\nTasso decrescita alfa ......
printf("\nTasso decrescita beta ......
/*
:
:
:
:
:
:
:
:
");
");
");
");
");
");
");
");
scanf("%d",
scanf("%d",
scanf("%d",
scanf("%e",
scanf("%d",
scanf("%d",
scanf("%d",
scanf("%d",
&maxiter);
&maxri);
&maxco);
&A);
&A1);
&A2);
&T1);
&T2);
maxiter=500; maxri=3; maxco=3; A=0.8 ; A1=0; A2=2 ; T1=200; T2=200; */
return(0);
}
/* Apertura file di input e lettura dimensione e numero di pattern */
int apri_fi()
{
int test=1;
while(test) {
printf("\nFile dei PATTERN: ");
scanf("%s", fi);
if(! *fi)return(1);
if((in=fopen(fi,"r")) == NULL) fprintf(stderr, "\nFile non trovato\n");
else test=0;
};
fscanf(in, "%d", &maxpa);
fscanf(in, "%d", &maxat);
return(0);
}
/* Lettura pattern e memorizazione locale */
int leggi_pa()
{
int r,c;
for(r=0; r<maxpa; ++r)
for(c=0; c<maxat; ++c)
fscanf(in, "%e", &pin[r][c]);
fclose(in);
return(0);
}
/* Inizializzazione della matrice dei pesi */
int init_rete()
{
int r,c,n;
for(r=0; r<maxri; ++r)
for(c=0; c<maxco; ++c)
for(n=0; n<maxnp; ++n)
pesi[r][c][n]=(float)(rand()%100)/1000;
return(0);
}
/* Scelta casuale dei pattern di ingresso per l'apprendimento.
Per un buon funzionamento, occorre una distribuzione uniforme */
int estrai()
{
int x;
x = rand()%maxpa;
return(x);
}
/* Calcolo di alfa in funzione del numero progressivo di iterazione */
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 108
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
float alfa(int t)
{
float x;
x = A*exp(-((float)t/T1));
return(x);
}
/* Calcolo di beta = ampiezza dell'intorno */
int beta(int t)
{
int x;
x = (float) A1 + (float) A2*exp(-((float) t/T2)) + 0.5;
return(x);
}
/* Calcolo estremi dell'intorno */
void estremi(int intorno)
{
xmin = bestri - intorno;
xmax = bestri + intorno+1;
ymin = bestco - intorno;
ymax = bestco + intorno+1;
if(xmin < 0) xmin = 0;
if(xmax > maxri) xmax = maxri;
if(ymin < 0) ymin = 0;
if(ymax > maxco) ymax = maxco;
}
/* Calcolo la distanza euclidea tra i due vettori */
float distanza(int p, int r, int c)
{
int x;
float d=0;
for(x=0; x<maxnp; ++x)
d = d + pow((pin[p][x]-pesi[r][c][x]),2);
return(d);
/* Ritorno distanza al quadrato */
}
/* Calcolo del best match */
void match(int p)
{
int r,c;
float dmin,dist;
dmin=MAXFLOAT;
for(r=0; r<maxri; ++r)
for(c=0; c<maxco; ++c){
dist = distanza(p,r,c);
if(dist < dmin){dmin = dist; bestri = r; bestco = c;};
};
}
/* Aggiornamento dei pesi */
void aggiorna(int p, float a)
{
int n,r,c;
float *w;
for(r=xmin; r<xmax ; ++r)
for(c=ymin; c<ymax; ++c)
for(n=0; n<maxnp; ++n) {
w = &pesi[r][c][n];
*w = *w + a*(pin[p][n] - *w);
};
}
/* Richiesta e controllo file di uscita della matrice dei pesi */
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 109
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
int apri_fo()
{
int test=1;
char appo[2];
while(test) {
printf("\nFile su cui memorizzare i pesi: "); scanf("%s", fo);
if((out=fopen(fo,"r")) == NULL) test = 0;
else {
printf("\nFile esistente, riscrivo? (s/n) "); scanf("%s", appo);
if((*appo == 's') || (*appo == 'S')) test = 0;
}
};
}
/* Scrittura matrice di pesi su file fo */
void write_pesi()
{
int r,c,n;
out = fopen(fo, "w");
fprintf(out,"maxri=%d\n",maxri);
fprintf(out,"maxco=%d\n",maxco);
fprintf(out,"maxnp=%d\n",maxnp);
for(r=0; r<maxri; ++r)
for(c=0; c<maxco; ++c) {
for(n=0; n<maxnp; ++n) fprintf(out, "%e ", pesi[r][c][n]);
fprintf(out, "\n");
}
fclose(out);
}
/********* MAIN **********/
void main()
{
int t, k, p;
float a;
in_dati();
apri_fi();
maxnp=maxat;
leggi_pa();
apri_fo();
init_rete();
k = 0;
for(t=1; t<maxiter; ++t) {
p = estrai();
a = alfa(t);
match(p);
estremi(beta(t));
aggiorna(p, a);
putch('.');
};
write_pesi();
}
Non esiste un parametro che misura il grado di co0nvergenza dell’algoritmo: il processo di apprendimento viene fatto terminare semplicemente dopo un numero di iterazioni determinato a-priori. Infatti, se si prende come parametro di convergenza la differenza fra i pattern presentati ed il vettore dei pesi del neurone “best match” relativo ad ogni pattern, potremo
arrivare ad una mappa finale che potrebbe non soddisfare le esigenze di impiego. Per chiarire questo concetto, vediamo il
seguente esempio:
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 110
Università degli Studi di Camerino - Diploma di Laurea in Informatica - Corso di Architettura degli Elaboratori
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani
FILE DI INPUT
4
4
1.0 0.0 0.0 0.0
0.0 1.0 0.0 0.0
0.0 0.0 1.0 0.0
0.0 0.0 0.0 1.0
Dopo 200 iterazioni, si ottiene il seguente file di uscita (vettori dei pesi):
maxri=3
maxco=3
maxnp=4
[0,0] 1.598494e-09 9.999999e-01 7.300990e-09 1.890095e-10
[0,1] 5.111695e-20 3.563502e-01 2.334724e-19 6.436498e-01
[0,2] 4.267690e-12 7.713561e-12 1.949232e-11 9.999999e-01
[1,0] 7.839941e-18 4.102964e-01 5.897036e-01 9.270119e-19
[1,1] 2.699940e-01 2.969539e-01 2.485232e-01 1.845291e-01
[1,2] 5.638595e-01 1.650451e-20 4.170719e-20 4.361404e-01
[2,0] 6.545468e-10 1.183049e-09 9.999999e-01 7.739501e-11
[2,1] 5.790287e-01 2.531337e-18 4.209712e-01 1.656001e-19
[2,2] 9.999999e-01 5.161178e-10 1.304239e-09 3.376440e-11
Riportiamo, per comodità visiva, i vettori dei pesi in una matrice 3x3, arrotondando e normalizzando a 10 i velori dei pesi:
E’ immediato riconoscere che i neuroni (0,0), (0,2), (2,0), (2,2) sono specializzati per i rispettivi pattern di ingresso; gli altri presentano dei valori intermeti, dati dall’interpolazione tra i valori dei neuroni adiacenti.
maxri=3
maxco=3
maxnp=4
[0,0] 1.162113e-15
[0,1] 2.896282e-25
[0,2] 1.414963e-17
[1,0] 1.212722e-22
[1,1] 2.749144e-01
[1,2] 5.002016e-01
[2,0] 4.883358e-15
[2,1] 4.404057e-01
[2,2] 9.999999e-01
9.999999e-01
5.608271e-01
2.557450e-17
4.843937e-01
2.192993e-01
3.284412e-25
8.826343e-15
1.375237e-22
2.864803e-15
5.307854e-15
1.322852e-24
6.462723e-17
5.156063e-01
3.718984e-01
8.299766e-25
9.999999e-01
5.595943e-01
7.239409e-15
(0,10,0,0)
(0,4,6,0)
(0,0,10,0)
1.374108e-16
4.391729e-01
9.999999e-01
1.433949e-23
1.338879e-01
4.997983e-01
5.774184e-16
8.996795e-24
1.874153e-16
(0,4,0,7)
(3,3,2,2)
(6,0,4,0)
(0,0,0,10)
(6,0,0,4)
(10,0,0,0)
Aumentando il numero
di iterazioni, (es.: 500)
si ha una più netta accentuazione dei neuroni
specializzati.
La rete, soto queste condizioni è ancora in grado di classificare pattern simili, non ancora presentati, in modo soddisfacente. Aumentando ancora il numero di iterazioni (es.: 5000) si verrebbero a creare delle nette distinzioni dei 4 cluster e si
avrebbe la incapacità della rete di classificare i pattern intermedi.
Appunti delle lezioni teoriche A.A. 1998-99 - Prof. Ing. Massimo Trojani -
Pagina 111
")



![Via Eugenio Barsanti, 24 - 00146 Roma Telefono [Fax] 06](http://s1.studylibit.com/store/data/004164020_1-c5a7c8484d07a6b1f1c9ad8187f8cd02-300x300.png)