Appunti di Statistica Sociale
Università Kore di Enna
LA REGRESSIONE LINEARE SEMPLICE
La regressione lineare fu introdotta per la prima volta da F. Galton (1822-1911), per studiare la
relazione tra la statura di un gruppo di padri e quella dei loro figli. Galton osservò che, al crescere
della statura dei padri, quella dei figli sembrava decrescere, in media, cioè regredire: da qui il nome
usato per indicare la relazione tra le due serie di misure quantitative, appunto regressione.
La regressione lineare è costituita da una famiglia di modelli che permettono di individuare la
forma probabile della relazione tra:
- due variabili quantitative (regressione lineare semplice), dove una ha il ruolo di variabile
dipendente (generalmente indicata con Y) e l’altra quello di variabile indipendente (X);
- tre o più variabili quantitative (regressione lineare multipla), dove una ha il ruolo di la
variabile dipendente (ancora Y) e le altre due o più (in generale k) sono le variabili
indipendenti (X1, X2, …, Xk).
Riferendoci all’esempio della relazione tra le stature dei padri e quelle dei figli, le prime sono
misure della variabile indipendente X, le seconde invece sono misure della variabile dipendente Y.
Si tratta quindi di un caso di regressione lineare semplice. In casi come questo, si usa dire che si
studia la regressione di Y su X.
Prima di affrontare la questione del “modello”, vediamo sotto quale forma si possono presentare i
dati sui quali fare analisi della regressione.
ORGANIZZAZIONE DEI DATI BIVARIATI
Obiettivo della statistica bivariata (o multivariata) è studiare la relazione tra due (o più) variabili. A
tale scopo è indispensabile raccogliere informazioni sulle variabili oggetto di studio. In tal caso, le
N (o n) unità statistiche di una popolazione (o campione) sono oggetto della rilevazione congiunta
delle informazioni relative alle due (o più) variabili, necessarie a studiare la possibile relazione tra
esse.
È noto che, in ambito di statistica univariata, esistono diverse forme in cui si possono organizzare i
dati, ovvero distribuire le unità statistiche rispetto ad un carattere studiato. Ad esempio, il risultato
di un processo di rilevazione può essere organizzato in un vettore di dati ordinati in senso non
decrescente, il cui numero di elementi è pari al numero di osservazioni. In questo caso, parleremo di
distribuzione di dati per unità. Oppure, le osservazioni sulle unità statistiche possono essere
organizzate in una distribuzione di frequenza per modalità, secondo la variabile rilevata.
In modo analogo, in statistica bivariata, i dati raccolti sulle singole unità statistiche possono essere
organizzati o per unità, ordinandoli in senso non decrescente, secondo i valori di una delle due
variabili opportunamente scelta (in genere la variabile indipendente, X), oppure in una distribuzione
di frequenza congiunta per modalità, secondo la variabile doppia XY.
Nel primo caso, ciascun dato individuale è rappresentato da una coppia di osservazioni, una per
ogni variabile in studio, rilevate su una medesima unità statistica. Nel secondo caso, si ordinano in
modo crescente sia le modalità di una variabile, ad esempio la X, ponendole in riga, che quelle
dell’altra, la Y, ponendole in colonna, e per ciascuna coppia di modalità doppia XY si contano le
frequenze, che si inseriscono nelle celle individuate dagli incroci riga-colonna di ciascuna modalità
doppia rilevata.
Docente: Fabio Aiello
A.A. 2010/11
1
Appunti di Statistica Sociale
Università Kore di Enna
DATI INDIVIDUALI PER UNA VARIABILE DOPPIA XY
Lo studio della relazione tra due variabili, X e Y, rende necessario classificare le N unità statistiche
simultaneamente secondo i due caratteri, ovvero costruire la distribuzione di frequenza congiunta
della variabile doppia XY.
Quando almeno una delle due variabili studiate, X e Y, è di natura continua, o quando il numero N
(o n) delle osservazioni è ridotto, non sussistono le condizioni per organizzare le osservazioni in una
distribuzione per modalità. In questo caso, il dato bivariato, per ciascuna delle N unità statistiche,
sarà espresso dalla coppia di valori (xi, yi), il primo riferito alla prima variabile, la X appunto, e il
secondo riferito alla seconda variabile, la Y. La serie di dati si presenterà quindi come una coppia di
vettori appaiati di uguale dimensione (si ricordi che le due variabili sono rilevate sulle medesime
unità statistiche). Ritornando ancora una volta all’esempio sopraccitato delle stature dei padri e dei
figli, noto che l’unità statistica è ciascuna coppia “padre-figlio”, avremo, ad esempio, coppie di
valori espressi in cm, del tipo (178, 173), in cui il primo valore è la statura del padre ed il secondo
quella del figlio.
In generale, date due variabili quantitative X e Y, osservate simultaneamente su N (o n) unità
statistiche (u.s.), la serie di N dati bivariati sarà:
u.s.
1
2
X
x1
x2
Y
y1
y2
…
…
…
j
xj
yj
…
…
…
N
xN
yN
dove la generica osservazione si indica con la coppia (xj, yj), ∀ j = 1, 2, …, N.
Le coppie si dicono ordinate quando sussiste l’ordinamento debole, almeno per i valori di X:
x1 ≤ x2 ≤ … ≤ xj ≤ … ≤ xN
Data la natura delle due variabili, possiamo sintetizzarle, sia considerandole separatamente,
attraverso i noti indici di sintesi numerica (μx, σx) e (μy, σy), sia considerandole congiuntamente per
studiare l’esistenza, la forma, la direzione e, infine, l’intensità della possibile relazione che le lega.
DISTRIBUZIONI DI FREQUENZA CONGIUNTE DI UNA VARIABILE DOPPIA XY
Quando sussistono le condizioni per classificare le unità statistiche in modalità, simultaneamente
secondo i tue caratteri, allora è possibile costruire la distribuzione di frequenza congiunta della
variabile doppia XY. Come già accennato, per fare ciò si ordinano in modo crescente sia le s
modalità di X, sia le t modalità di Y e, per ciascuna coppia di modalità doppia XY, si contano le
frequenze (che si inseriscono nelle celle individuate dagli incroci riga-colonna di ciascuna modalità
doppia osservata).
Date N unità statistiche, la rappresentazione della distribuzione congiunta, secondo le modalità dei
due caratteri associati XY, si presenta in forma di tabella a doppia entrata:
Docente: Fabio Aiello
A.A. 2010/11
2
Appunti di Statistica Sociale
Università Kore di Enna
Tabella 1. Distribuzione di frequenza congiunta della variabile doppia XY.
Tot.
n10
…
…
…
…
…
nih
...
nit
ni0
…
…
…
...
…
yt
n1t
…
...
...
…
yh
n1h
…
...
...
…
y1
n11
xi
ni1
…
X|Y
x1
xs
Tot.
ns1
n01
...
…
nsh
n0h
…
…
nst
n0t
ns0
N
dove xi e yh sono le generiche modalità di X e di Y, rispettivamente, e nih è la frequenza congiunta
corrispondente alla modalità doppia (xi, yh). La tabella 1 è costruita da s modalità (i = 1, 2, …, s) di
X, poste in riga, e t modalità (h = 1, 2, …, t) di Y, poste in colonna.
Analizzando la distribuzione congiunta in tabella 1, si osserva che, in corrispondenza di ciascuna
modalità xi (riga) di X vi è una specifica distribuzione di frequenza condizionata delle modalità
osservate di Y, indicate con yh (h = 1, …, t). Avremo quindi tante distribuzioni condizionate di Y
quante sono le s modalità (righe) di X:
Tabella 2. Distribuzioni condizionate (Y|xi).
(Y|x1)
y1
y2
…
yt
tot.
(Y|x2)
x1
n11
n12
…
n1t
n10
x2
n21
n22
…
n2t
n20
y1
y2
…
yt
tot.
…
…
…
…
…
…
…
(Y|xi)
y1
y2
…
yt
tot.
xi
ni1
ni2
…
nit
ni0
…
…
…
…
…
…
…
(Y|xs)
y1
y2
…
yt
tot.
xs
ns1
ns2
…
nst
ns0
La prima distribuzione è la condizionata di Y alla modalità x1 di X, e così via, sino all'ultima, che è
la distribuzione condizionata di Y alla modalità xs di X. Avremo così s distribuzioni condizionate
della Y, tante quante sono le modalità osservate della X, da cui si ipotizza che la Y dipenda. Se
sintetizziamo le singole distribuzioni condizionate di Y, allora, avremo per ciascuna di queste una
specifica media aritmetica (o valore atteso) condizionata, anche nota come media parziale:
E(Y|xi) = μ y| x1 , μ y| x2 , …, μ y| xi , …, μ y| xs
dove:
t
μ y| x =
∑y
h =1
n
hi hi
∀ i = 1, 2, …, s
ni 0
i
e una specifica varianza parziale:
t
σ i2 =
Docente: Fabio Aiello
∑(y
h =1
hi
− μ y| xi ) 2 nhi
ni 0
A.A. 2010/11
∀ i = 1, 2, …, s.
3
Appunti di Statistica Sociale
Università Kore di Enna
ANALISI DELLA DIPENDENZA: RELAZIONE ASIMMETRICA
Lo studio della dipendenza statistica consiste nell’esame di come variano le distribuzioni
condizionate della variabile dipendente (o risposta) Y, al variare della variabile indipendente (o
esplicativa) X.
Consideriamo, ad esempio, la tabella a doppia entrata. A partire da questa è possibile studiare la
“dipendenza in distribuzione” di una variabile quantitativa (Y) da un’altra variabile quantitativa
(X).
Nel caso di due sole variabili quantitative, ossia della regressione semplice, attraverso lo studio
della dipendenza, si può misurare l’effetto della variabile esplicativa X sulle distribuzioni
condizionate della variabile dipendente Y.
La regressione di Y su X si osserva quando le medie parziali di Y variano (crescono o decrescono)
al crescere delle modalità di X (si ricordi che le modalità sono sempre ordinate in senso crescente).
Se non si osserva alcuna variazione nelle medie parziali di Y, allora è probabile che Y sia
indipendente da X, ovvero le medie parziali di Y sono indifferenti al crescere delle modalità di X,
ovvero, restano pressoché costanti:
E(Y|xi) = μ y| x1 = μ y| x2 = … = μ y| xi = … = μ y| xs = μy = E(Y),
∀ i = 1, 2, …, s
dove μy è la media aritmetica di Y, che è una costante.
GLI OBIETTIVI DELLA REGRESSIONE:
Lo studio della relazione asimmetrica tra due variabili, attraverso i modelli di regressione lineare
persegue essenzialmente tre obiettivi:
1. descrittivo: si definisce il modello di regressione per esprimere analiticamente la realtà
osservata, rappresentandola in maniera verosimile;
2. interpretativo: il modello adottato deve fornire una “buona” interpretazione della realtà
osservata e deve mettere in evidenza le relazioni fra i diversi fenomeni, riconducibili a precise
ipotesi di lavoro;
3. previsionale: il modello deve essere in grado di fornire previsioni sull’andamento futuro del
fenomeno; ovvero, deve essere capace di calcolare un valore non ancora osservato della
variabile dipendente Y, in corrispondenza di nuovi valori osservati della variabile indipendente
X.
LE ASSUNZIONI SOTTOSTANTI ALLA REGRESSIONE LINEARE
Lo studio della dipendenza di Y da X, attraverso un modello di regressione lineare semplice,
presuppone che preliminarmente siano soddisfatte delle condizioni, note come assunti della
regressione, la cui sussistenza dovrebbe essere verificata ex ante l’analisi della regressione. Tali
assunti possono essere così espressi:
i. La variabile indipendente X è deterministica: le modalità osservate xi (∀ i = 1, 2, …, s) di X
sono predeterminate, cioè sono (o meglio dovrebbero essere) valori misurati senza errore. È
chiaro che, nelle Scienze Sociali, questo assunto non è realistico e raramente soddisfatto.
ii. La Normalità delle s distribuzioni condizionate: in corrispondenza di ciascuna delle s modalità
xi (∀ i = 1, 2, …, s) di X, esiste una sottopopolazione di valori di Y che si distribuisce
normalmente. In altre parole, ciascuna delle s distribuzioni condizionate di Y, alle modalità xi
di X, segue una distribuzione di probabilità Normale, con specifici parametri:
Y|xi ~ N( μ y| x , σ2),
i
Docente: Fabio Aiello
A.A. 2010/11
∀ i = 1, 2, …, s.
4
Appunti di Statistica Sociale
Università Kore di Enna
iii. La linearità della relazione tra le due variabili: le s medie condizionate di Y,
μ y| x1 , μ y| x2 , …, μ y| xi , …, μ y| xs , ∀ i = 1, 2, …, s, giacciono tutte su una medesima retta.
iv. L’indipendenza delle s distribuzioni condizionate: le s distribuzioni di Y sono normalmente
distribuite e tra loro statisticamente indipendenti. Cioè, i valori di Y, osservati in
corrispondenza di una data modalità xi di X, non dipendono in alcun modo dai valori di Y
osservati in corrispondenza di un’altra modalità xj di X, con i ≠ j. Questo equivale ad affermare
che tutte le distribuzioni condizionate Y|xi sono indipendenti e identicamente distribuite (i.i.d).
v. L’uguaglianza (omoschedasticità) delle s varianze parziali: le s distribuzioni hanno tutte uguale
varianza (vedi punto ii):
∀ i = 1, 2, …, s.
Var(Y|xi) = σ 12 = σ 22 = ... = σ s2 = σ2 = Var(Y)
questa uguaglianza è detta ipotesi della omoschedasticità.
Verificare che gli assunti della regressione siano soddisfatti significa valutare se i dati in esame
soddisfano le condizioni sopra esposte.
IL DIAGRAMMA DI DISPERSIONE
Il primo passo da compiere quando si studia la relazione tra due variabili quantitative è un’analisi
grafica della relazione. Tale analisi permette di cogliere, con buona attendibilità, caratteristiche
fondamentali della relazione, quali l’esistenza, la forma (o natura), la direzione e l’intensità (o
forza).
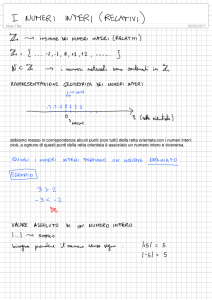
Lo strumento per l’indagine grafica è il diagramma di dispersione o scatterplot (vedi figura 1), che
rappresenta su un piano ortogonale X0Y la distribuzione congiunta delle N unità statistiche, secondo
i due caratteri quantitativi.
Figura 1. Diagramma di dispersione X vs Y.
50
45
40
35
Y
30
25
20
15
10
y = 1.0525x + 0.6071
R2 = 0.6853
5
0
10
12
14
16
18
20
22
24
26
X
28
30
32
34
36
38
40
42
44
Ciascuna unità statistica sarà rappresentata da un punto sul piano e la curva interpolatrice
dell'insieme di punti è uno strumento che permette di evidenziare proprietà interessanti della
relazione. Il ricorso ad una retta interpolatrice della nuvola di punti equivale a esprimere la
Docente: Fabio Aiello
A.A. 2010/11
5
Appunti di Statistica Sociale
Università Kore di Enna
relazione tra X e Y in modo lineare, attraverso la funzione y = f(x), dove y è la generica
realizzazione della variabile dipendente Y e x è la generica osservazione della variabile
indipendente X. Data l'espressione della f(x), ad ogni valore x di X corrisponde uno e un solo valore
y di Y. In altre parole, ad ogni ascissa xj (j = 1, …, N) corrisponde uno e un solo punto su una retta
di equazione y = f(x), la cui ordinata è f(xj).
Lo scatterplot rappresenta graficamente le N coppie di valori osservati congiuntamente sulle N unità
statistiche, sia per la variabile Y che per la X, (xj, yj), per j = 1, …, N. È necessario ricorrere ad un
sistema di assi cartesiani ortogonali X0Y, sul quale disporre gli N punti, le cui coordinate cartesiane
sono appunto le coppie (xj, yj) ordinate secondo i valori di X. Per convenzione i valori ordinati di X
sono posti sull’asse delle ascisse e i corrispondenti valori di Y sull’asse delle ordinate. La nuvola di
punti, rappresentata sul piano cartesiano, da origine al diagramma di dispersione o scatterplot. Se
tali punti mostrano con una certa chiarezza e regolarità l’esistenza di un andamento monotòno
(crescente o decrescente) e si distribuiscono approssimativamente intorno ad una retta, allora la
relazione può essere studiata attraverso un modello di regressione lineare.
La retta passante per i punti è nota come retta dei minimi quadrati, che, come vedremo più avanti, è
l’unica, tra le infinite rette passanti per i punti dello scatterplot, a soddisfare una data condizione. In
genere, i punti sul piano, di coordinate (xj, yj), si indicano con yj e sono detti valori osservati di Y,
mentre i punti sulla retta si indicano con yˆ j e sono detti valori attesi di Y, ∀ j = 1, …, N.
L’uso di uno scatterplot consente di comprendere alcune caratteristiche della relazione tra X e Y,
quali:
1. l’esistenza della relazione, quando la nuvola di punti mostra, con una certa regolarità,
l’esistenza di un andamento monotòno (crescente o decrescente);
2. la forma lineare (o non lineare) della relazione, quando la nuvola di punti si dispone con
buona approssimazione intorno ad una retta (o ad una curva);
3. la direzione della relazione, data (geometricamente) dalla direzione dell’inclinazione della
retta ideale, intorno a cui si dispone la nuvola di punti: se questa ha inclinazione positiva, la
relazione sarà direttamente proporzionale; se ha inclinazione negativa, la relazione sarà
inversamente proporzionale. Pertanto, al crescere di X, nel primo caso, Y crescerà, nel
secondo caso Y decrescerà.
4. l’intensità, o forza della relazione, data geometricamente dal grado di inclinazione
(coefficiente angolare) della retta ideale, intorno a cui si dispone la nuvola di punti.
Maggiore è in valore assoluto l’inclinazione della retta, maggiore è l’effetto della crescita di
X sulla variazione (positiva o negativa) di Y. O, in altre parole, più inclinata è la retta, più
intensa è la relazione tra X e Y.
IL MODELLO DI REGRESSIONE SEMPLICE
Attraverso il modello di regressione lineare è possibile esprimere i singoli valori osservati di Y, yj,
come funzione lineare dei valori osservati di X, xj, nella forma:
yj = β0 + β1xj + εj.
∀ j = 1, 2, …, N
[1]
ossia, i valori osservati yj della variabile dipendente Y sono funzione lineare dei valori osservati xj
della variabile indipendente X, attraverso i due parametri βk (k = 0, 1), più una quantità εj, nota
come errore. Quest’ultima si assume essere una variabile distribuita normalmente, εj ~ N(0, σ2), che
equivale ad assumere che gli errori che si commettono esprimendo la relazione tra X e Y in termini
di valore atteso yˆ j , piuttosto che del corrispondente valore osservato yj, si annullano in media. Si
ricordi che, mentre i valori osservati yj sono punti sul piano, i valori attesi yˆ j sono punti sulla retta:
quindi, la quantità εj può essere interpretata anche in termini di distanza tra i due punti.
Docente: Fabio Aiello
A.A. 2010/11
6
Appunti di Statistica Sociale
Università Kore di Enna
Inoltre, dall’assunto al punto iv, discende che gli errori relativi a diverse distribuzioni condizionate
di Y sono tra loro non correlati, ovvero, Cov(εi, εh), con i ≠ h due qualsiasi diverse modalità di X.
Questo significa che tutta la variazione sistematica osservata nella variabile risposta Y è funzione di
X e può essere spiegata dal modello di regressione lineare adottato.
Se l’assunto al punto iii è soddisfatto, attraverso un modello di regressione lineare semplice, la
variazione osservata delle s medie condizionate di Y può essere così espressa:
∀ i = 1, 2, …, s;
E(Y|xi) = μ y| xi = β0 + β1xi
dove è noto che Var(Y|xi) = σ2, ∀ i = 1, 2, …, s, per l’omoschedasticità vista all’assunto v.
Sotto l’ipotesi di regressione di Y su X, le s distribuzioni condizionate di Y avranno valori attesi
variabili (crescenti o decrescenti) in funzione delle modalità della variabile esplicativa X. Il modello
di regressione esprime le s medie condizionate di Y E(Y|xi) = μ y| xi in termini di valore atteso sotto
l’ipotesi di regressione, ovvero:
E(Y|x) = ŷ = βˆ0 + βˆ1 x ,
[2]
Come si può osservare, nella [2] non compare la quantità ε, poiché l’errore in valore atteso è nullo,
E(ε) = 0, ad indicare che il valore atteso ŷ si trova esattamente sulla retta di regressione.
LA RETTA DEI MINIMI QUADRATI
Come abbiamo visto, se l’analisi dello scatterplot indica l’esistenza di una relazione lineare (almeno
approssimativamente) tra le due variabili X e Y, allora è lecito adottare una retta passante per la
nuvola di punti, per descrivere la relazione. Questa retta è nota come retta dei minimi quadrati ed
esprime ogni valore atteso yˆ j di Y in funzione dei singoli valori osservati xj di X, attraverso una
coppia di parametri, noti come coefficienti di regressione del modello:
yˆ j = βˆ0 + βˆ1 x j ,
∀ j = 1, …, N
dove:
β0 è l’intercetta della retta di regressione con l’asse delle ordinate Y, ovvero il punto
d’intersezione della retta con l’asse Y, in corrispondenza del punto di ascissa x = 0;
β1 è il coefficiente angolare della retta di regressione, ovvero la pendenza della retta sul piano
rispetto all’asse delle ascisse X.
È necessario stimare queste due quantità, per determinare e tracciare sul piano in maniera univoca la
retta dei minimi quadrati.
IL CRITERIO DEI MINIMI QUADRATI
Il metodo dei minimi quadrati consiste nell’individuazione di una retta, passante per la nuvola di
punti dello scatterplot, scelta tra una famiglia di rette del piano X0Y. Questa è la retta dei minimi
quadrati, che garantisce che sia minima la distanza tra i punti osservati sul piano, yi, e i punti che
appartengono alla retta, yˆi . Grazie a ciò, possiamo definire la retta dei minimi quadrati come la
migliore retta adattabile ai punti osservati nel diagramma di dispersione. Il criterio dei minimi
quadrati recita che “la somma delle differenze al quadrato, fra i valori osservati yi della variabile
dipendente Y e i valori attesi yˆi , ottenuti adattando la retta dei minimi quadrati, è sempre minore
della somma delle differenze al quadrato tra i valori osservati e i valori attesi ottenuti adattando
qualsiasi altra retta”. (Ricordate la II proprietà della media aritmetica?).
Docente: Fabio Aiello
A.A. 2010/11
7
Appunti di Statistica Sociale
Università Kore di Enna
In altre parole, questo significa che la retta dei minimi quadrati rende minima la distanza tra ogni
punto osservato yi di Y, sullo scatterplot, e il corrispondente punto yˆi , sulla retta dei minimi
quadrati. Formalmente il criterio si esprime così:
∑( y
N
j =1
(
2
− yˆ j ) = ∑ y j − βˆ0 + βˆ1 x j
N
j
j =1
)
2
= minimo
[3]
Il metodo dei minimi quadrati permette di determinare le due quantità, β0 e β1, fornendo così le
stime dei coefficienti di regressione.
LE EQUAZIONI NORMALI E I COEFFICIENTI DI REGRESSIONE
Stimare i due coefficienti di regressione è di fondamentale importanza, sia dal punto di vista
geometrico, che da quello statistico. Infatti, come già detto, la retta dei minimi quadrati è
individuata univocamente solo quando sono note le due quantità, β0, l’intercetta, e β1, il coefficiente
angolare.
Dal punto di vista più strettamente statistico, β0 rappresenta il valore atteso di Y, yˆ j = β0, in
corrispondenza di un valore osservato xj = 0 di X; β1 esprime l’intensità (col suo valore numerico) e
la direzione (col suo segno) della relazione tra X e Y. Infatti, β1 esprime la variazione (incremento
se β1 > 0, o decremento se β1 < 0) media osservata nella variabile dipendente Y, per effetto di ogni
incremento unitario della variabile indipendente X.
I valori da assegnare a β0 e β1 sono noti come stime e si determinano risolvendo il sistema di due
equazioni in due incognite che si ottiene sviluppando il quadrato entro le parentesi dell’espressione
[3]:
N
(
S = ∑ y j − βˆ0 + βˆ1 x j
j =1
)
2
e derivando le quantità rispetto ai due coefficienti da stimare. Le due equazioni sono dette equazioni
normali:
⎧ dS
⎪ d β = −2∑ ( y j − β 0 − β1 x j ) = 0
⎪ 0
⎨
⎪ dS = −2∑ ( y − β − β x ) x = 0
j
0
1 j
j
⎪⎩ d β1
⎧⎪∑ y j − N β 0 − β1 ∑ x j = 0
⎨
2
⎪⎩∑ x j y j − β 0 ∑ x j − β1 ∑ x j = 0
⎧⎪∑ y j = N β 0 + β1 ∑ x j
⎨
2
⎪⎩∑ x j y j = β 0 ∑ x j + β1 ∑ x j
(
)
la cui soluzione rispetto ai due coefficienti fornisce la coppia di stime βˆ0 , βˆ1 :
Docente: Fabio Aiello
A.A. 2010/11
8
Appunti di Statistica Sociale
∑(x
N
βˆ1 =
j =1
j
− μ x )( y j − μ y )
∑(x
N
j =1
βˆ0 =
∑y
j
Università Kore di Enna
j
− μx )
− βˆ1 ∑ x j
N
2
=
N ∑ x j y j − ( ∑ x j )( ∑ y j )
N ∑ x 2j − ( ∑ x j )
2
;
= μ y − βˆ1μ x .
IL COEFFICIENTE DI DETERMINAZIONE
Dopo avere stimato la retta dei minimi quadrati, è necessario valutarne il grado di accostamento alla
nuvola dei punti dello scatterplot. Infatti, è vero che la retta è la migliore tra le possibili scelte, ma
si deve sempre valutare la capacità del modello adottato (la retta appunto) di descrivere la relazione
osservata tra X e Y.
Facciamo un esempio estremo: se la retta stimata descrivesse perfettamente la relazione osservata,
questo significherebbe che la distanza tra i punti osservati e quelli attesi (già definita come errore)
sarebbe nulla, perché sia i punti osservati, che gli attesi giacerebbero sulla retta e l’accostamento
sarebbe perfetto. In un simile caso, si parla indifferentemente di adattamento perfetto del modello.
Pertanto, una domanda più che lecita è: quanto è buono l’adattamento del modello ai dati osservati?
Una misura della bontà di accostamento della retta di regressione dei minimi quadrati ai punti
osservati sul piano cartesiano è il coefficiente di determinazione R2.
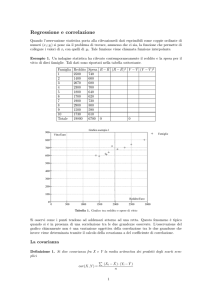
Per determinare il coefficiente R2 è necessario scomporre la devianza totale di Y in due componenti
distinte. Nella figura 2 sono indicate le quantità necessarie alla scomposizione della devianza totale
osservata di Y (si ricordi che la devianza Dev(Y) è il numeratore della varianza) nelle sue due
componenti:
- la devianza della Regressione, Dev(R);
- la devianza dell’Errore, Dev(E).
Nella figura, sono riportate sia l’equazione della retta di regressione dei minimi quadrati stimata, yˆi
= 0.6071 + 1.0525xi, che quella della retta parallela all’asse delle ascisse, passante per il punto di
ordinata My = 24.24 (la media di Y), che rappresenta l’ipotesi di assenza di regressione di Y su X,
cioè l’indipendenza. Infatti, al variare di X, Y è indifferente, non varia, perché è sempre uguale a
My.
Docente: Fabio Aiello
A.A. 2010/11
9
Appunti di Statistica Sociale
Università Kore di Enna
Figura 2. Scatterplot per la scomposizione della Devianza di Y
50
Dev(E)
45
Dev(Y)
40
35
Dev(R)
Y
30
25
My = 24.24
20
15
10
y = 1.0525x + 0.6071
R2 = 0.6853
5
0
10
12
14
16
18
20
22
24
26
X
28
30
32
34
36
38
40
42
44
Possiamo quindi pensare a queste due rette come i “modelli” che rappresentano le due opposte
condizioni, rispettivamente, quella di regressione di Y su X e quella di indipendenza di Y da X, e
vedere quale delle due è più aderente (o vicina, in termini geometrici) alla realtà osservata (i punti
dello scatterplot). Pertanto, al fine di valutare la bontà di adattamento del modello di regressione è
necessario porre a confronto le quantità relative alle diverse condizioni.
La devianza totale di Y può essere scomposta in due parti:
( y j − μ y ) = ( y j − yˆ j ) + ( yˆ j − μ y )
che sommando ed elevando al quadrato diventa:
∑ ( y j − μ y ) = ∑ ( y j − yˆ j ) + ∑ ( yˆ j − μ y )
N
2
j =1
N
j =1
2
N
2
j =1
dove il doppio prodotto si annulla in virtù delle due equazioni normali.
Possiamo anche scrivere:
Dev(Y) = Dev(R) + Dev(E)
Dove, la Dev(Y) può essere interpretata sia come misura della distanza tra ciascun valore osservato,
yi, sul piano e la media dei valori osservati, μ y = My, che come misura della variabilità osservata di
Y da spiegare (oppure no) in funzione di X; la Dev(R), è la misura della distanza tra ciascun valore
teorico, yˆi , sulla retta di regressione (cioè l’ipotesi di regressione di Y su X) e la media dei valori
osservati, μ y = My (cioè l’ipotesi di “assenza di regressione”). La terza devianza, Dev(E), misura la
distanza tra ciascun valore osservato, yi, sul piano e il corrispondente valore atteso, yˆi , sulla retta di
regressione (già definita errore, εi), in altre parole, misura la variabilità di Y che rimane da spiegare,
perché non spiegata dalla regressione.
Il coefficiente di determinazione R2 è una misura della porzione di variabilità totale di Y spiegata
dalla regressione su X, formalmente:
Docente: Fabio Aiello
A.A. 2010/11
10
Appunti di Statistica Sociale
Università Kore di Enna
R2
∑ ( yˆ
=
∑( y
j
− μy )
j − μy
∑( y
= 1−
)
∑( y
2
2
j
− yˆ j )
2
j − μy )
2
.
Esso è tale che:
•
•
•
0 ≤ R2 ≤ 1;
Se R2 = 0
Se R2 = 1
allora pessimo adattamento del modello;
allora perfetto adattamento del modello.
Più vicino all’unità è il valore di R2, migliore sarà l’accostamento della retta dei minimi quadrati ai
valori osservati e, quindi, migliore l’ adattamento del modello ai dati. Questo perché la quota di
variabilità totale di Y, Dev(Y), spiegata dalla regressione su X, Dev(R), è elevata, per converso,
quella che rimane da spiegare, Dev(E), è ridotta.
Infine, il coefficiente di determinazione R2 è legato al coefficiente di correlazione lineare di
Bravais-Pearson r dalla relazione:
R2 = r .
Docente: Fabio Aiello
A.A. 2010/11
11