V. TRASCRIZIONE E TRADUZIONE DEL DNA
0) CONCETTI BASE
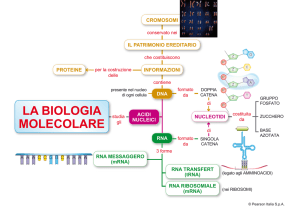
La trasformazione delle informazioni genetiche in proteine richiede due passaggi:
la trascrizione del DNA in mRNA e la traduzione dell’mRNA in una catena
polipeptidica.
Il codice genetico è a triplette, cioè ogni aminoacido è codificato da una sequenza
di tre basi azotate.
1) LA STRUTTURA DELLE PROTEINE
Come sappiamo, se si legano assieme una dopo l’altra più molecole di aminoacidi, si
ottiene una catena polipeptidica (o polipeptide), che si ripiega su se stessa assumendo
una particolare conformazione tridimensionale: il risultato è una proteina.
Le proteine, in genere formate da centinaia di subunità amminoacidiche, hanno una
particolare forma tridimensionale; questa dà a ognuna di esse la propria funzione
specifica, che, espressa in termini generali, consiste nella capacità di legarsi a altre
molecole.
Un gran numero di proteine con solo 20 aminoacidi
Le decine di migliaia di proteine diverse presenti negli organismi sono ottenute tutte
combinando assieme solo 20 aminoacidi. Che una così grande varietà di proteine derivi
da un numero relativamente ridotto di subunità non stupisce: basti pensare che la
lingua italiana ha migliaia di parole e poco più di una ventina di lettere dell’alfabeto; è
infatti l’ordine in cui queste si susseguono a determinare se si ottiene per esempio
“colorito” o “otricolo”. Analogamente, una proteina differisce dall’altra per la sequenza
di aminoacidi.
La Figura 6.1a riporta la formula di struttura di due aminoacidi, la glicina (gly) e
l’isoleucina (ile); dalla Figura 6.1b si vede che essi occupano le prime due posizioni in
una delle due catene polipeptidiche di cui è composta l’insulina. Questa proteina, che
rende possibile il passaggio del glucosio dal sangue nelle cellule del nostro organismo, è
rappresentata schematicamente in Figura 6.1c.
Ma come viene costruita in una cellula la catena di aminoacidi di una proteina? In altre
parole, in che modo gli aminoacidi gly, ile, val, ecc. vengono legati assieme in un ben
determinato ordine a formare una data proteina? Per ora sappiamo che i geni
codificano per le proteine e che un gene è un tratto di DNA caratterizzato da una
particolare sequenza delle basi azotate A, T, C e G. In che modo questa sequenza
determina quella degli aminoacidi di una proteina?
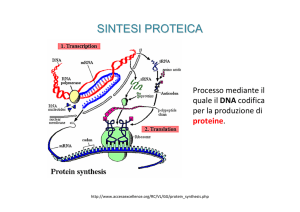
2) IL PROCESSO DI SINTESI DELLE PROTEINE
A grandi linee, il processo di
sintesi delle proteine può
essere descritto in modo
abbastanza semplice. Per
prima cosa, un tratto di
DNA contenuto nel nucleo
della cellula si srotola e in
corrispondenza di esso i due
filamenti della doppia elica
si separano; a questo punto,
il messaggio che esso
contiene (costituito dalla
sequenza di basi azotate
presente su uno dei due
filamenti) viene copiato su
una
molecola
di
RNA
messaggero (mRNA).
Questa molecola (paragonabile a un pezzo di nastro
magnetico su cui sono
copiate
le
informazioni
contenute in un tratto di
“nastro master” di DNA)
fuoriesce poi dal nucleo
della cellula (Figura 6.2).
La destinazione del “nastro” di mRNA è un ribosoma, un corpicciolo presente nel
citoplasma che può essere considerato come un “banco di lavoro” molecolare: è infatti
in esso che le istruzioni (il “nastro” di mRNA) e le materie prime (gli aminoacidi) si
incontrano e danno come risultato la formazione del prodotto (una proteina).
A mano a mano che il “nastro” di mRNA viene “letto” nel ribosoma, gli aminoacidi
vengono legati l’uno dopo l’altro nell’ordine indicato dall’mRNA a formare una catena
polipeptidica, che si va via via allungando. Quando la costruzione di questa è terminata,
essa si stacca dal ribosoma e si ripiega su se stessa formando una proteina. Ma come
arrivano gli aminoacidi al ribosoma? Vi sono trasportati da un secondo tipo di RNA,
l’RNA di trasporto (tRNA).
La prima parte di questo processo (quella in cui le istruzioni del DNA vengono copiate
nell’mRNA) è detta trascrizione; la seconda parte (quella in cui, in base alle istruzioni
contenute nell’mRNA, viene fabbricata la catena polipeptidica) è detta traduzione.
Trascrizione e traduzione sono i due stadi fondamentali del processo di sintesi delle
proteine.
Un gene determina la sequenza di amminoacidi di un particolare polipeptide,
responsabile di un carattere ereditario
Un organismo è la manifestazione di una particolare combinazione di proteine, ognuna
formata da una o più catene polipeptidiche. Un gene codifica l’informazione per una
singola catena polipeptidica, nel senso che la sua particolare sequenza lineare di
nucleotidi determina la particolare sequenza di amminoacidi del polipeptide.
Nella conversione dell’informazione da polinucleotide a polipeptide interviene una
molecola intermediaria, l’RNA (da ribonucleic acid, acido ribonucleico). Nelle cellule,
l’informazione genetica passa dal DNA all’RNA e da questo alle proteine.
La Figura 9.6 illustra il flusso dell’informazione codificata. Per prima cosa la cellula
trascrive (copia) le istruzioni codificate di un
gene in una molecola di RNA, che passa poi nel
citoplasma, nella sede di formazione del
polipeptide (i ribosomi).
Qui le istruzioni contenute nella molecola di
RNA dirigono l’attività di sintesi, determinando quale polipeptide (quale sequenza di
amminoacidi) si forma.
Nei ribosomi varie proteine e particolari
molecole di RNA traducono infatti le
istruzioni dell’RNA nell’esatto prodotto genico
del quale è stata ordinata la costruzione.
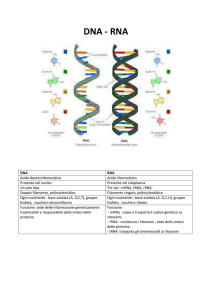
Per comprendere questo flusso d’informazione è necessario conoscere la struttura
dell’RNA, che differisce da quella del DNA principalmente per tre caratteristiche:
I nucleotidi dell’RNA contengono il ribosio (Figura 6.3), uno zucchero che ha un
atomo di ossigeno in più rispetto allo zucchero del DNA (il desossiribosio). Si
tratta di una differenza importante, perché permette agli enzimi di distinguere i
due tipi di sostanze.
Come il DNA, anche l’RNA contiene quattro basi azotate, ma una di queste,
l’uracile, è tipica dell’RNA. L’uracile sostituisce la timina, essendo complementare
all’adenina.
Le molecole di RNA sono formate da un solo filamento, per cui le basi azotate
possono essere esposte e formare legami a idrogeno con altre molecole.
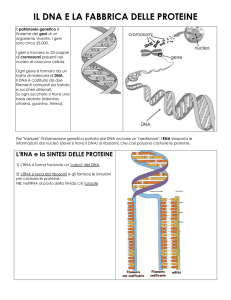
La trascrizione dei messaggi genetici nelle molecole di mRNA permette che l’informazione sia trasferita ai ribosomi
L’informazione contenuta nel DNA raggiunge i ribosomi tramite un tipo di RNA
opportunamente chiamato, vista la funzione, RNA messaggero (mRNA). Le molecole di
RNA si formano nella trascrizione, un processo che per certi versi assomiglia alla
sintesi di un nuovo filamento di DNA.
Durante la trascrizione (Figura 9.7) i due filamenti del DNA si separano temporaneamente e, su uno dei due filamenti di DNA che funge da stampo, si forma un filamento
complementare di mRNA.
Una molecola di mRNA è molto più piccola di una di DNA, dato che contiene in genere
meno di un migliaio di nucleotidi.
La RNA polimerasi, l’enzima che catalizza il processo, incorpora nella catena in via di
formazione soltanto ribunonucleotidi. Inoltre l’enzima è in grado di distinguere i due
filamenti del DNA, scegliendo il complementare a quello che codifica le corrette
sequenze amminoacidiche (filamento anticodificante). La trascrizione del filamento
codificante produrrebbe infatti RNA contenenti messaggi privi di senso.
L’informazione genetica registrata in un gene viene così trascritta in una molecola di
mRNA che, avendo una sequenza di nucleotidi complementari a quella del DNA, ne
trasporta il messaggio.
Terminata la sua sintesi, questo “messaggero” mobile abbandona lo stampo e porta
l’informazione codificata ai ribosomi, dove controlla la sintesi di uno specifico
polipeptide. Come vedremo tra breve, questo processo richiede anche l’intervento di
altri due tipi di RNA, l’RNA di trasporto e l’RNA ribosomiale.
Vi è una corrispondenza tra le triplette di nucleotidi (codoni) dei messaggi genetici e
gli amminoacidi delle proteine
Nella sintesi delle proteine, la successione lineare di nucleotidi di una molecola di
mRNA viene letta a gruppi di brevi sequenze di nucleotidi, chiamate codoni, ognuna
delle quali rappresenta una “parola molecolare”.
Ogni codone è lungo tre nucleotidi (tripletta) e specifica l’inserimento in un
determinato punto della catena polipeptidica in via di formazione di uno (e solo quello)
dei venti amminoacidi.
Il codone CAC, per esempio, determina sempre l’introduzione dell’amminoacido
istidina, il codone CUA specifica l’amminoacido leucina e così di seguito.
Il messaggio genetico viene letto codone dopo codone fino al completamento della
proteina. Con un alfabeto genetico di quattro lettere (A, G, C e U) sono possibili 64
combinazioni in triplette (4 x 4 x 4), ampiamente sufficienti per assegnare a ognuno
dei 20 amminoacidi almeno un corrispondente codone. L’ipotesi che il codice del DNA
fosse un codice di triplette, cioè che ogni amminoacido fosse specificato da una
sequenza di tre basi azotate del DNA fu avanzata per la prima volta dal biochimico
sudafricano Sydney Brenner.
L’elaborazione dell’RNA messaggero
Negli organismi eucarioti il trascritto primario, cioè il “nastro” di mRNA che si forma
dalla trascrizione, non è funzionale; prima di passare nel citoplasma, esso deve subire
una serie di modificazioni.
Dopo l’aggiunta di un “cappuccio” iniziale (che permetterà l’aggancio al ribosoma) e di
una coda di ribunonucleotidi tutti con la base azotata A, il trascritto primario viene
sottoposto a un processo che può essere paragonato al montaggio che un regista fa
del suo film.
In genere, il regista, prima unisce, nell’ordine da lui previsto, i tratti di pellicola girati
nelle varie scene; successivamente, passa a un lavoro di “taglia e cuci”, cioè,
visionando il materiale, decide quali scene includere e quali tagliare; in quest’ultimo
caso, unisce il tratto di pellicola che precede e quello che segue la scena eliminata.
Introni ed esoni
Qualcosa del genere avviene anche con l’mRNA degli eucarioti. Come mostra la Figura
6.10, speciali enzimi tagliano via dal trascritto primario certi tratti, i cosiddetti
introni, e saldano assieme le porzioni restanti: il risultato è un mRNA maturo che non
contiene più introni, ma solo esoni, come vengono chiamati i tratti del trascritto
primario che codificano per amminoacidi.
Da questo si conclude che gli introni
sono tratti non codificanti, non
contengono cioè istruzioni relative
all’assemblaggio di amminoacidi in
proteine. Perché allora il DNA li
contiene? Come si può scoprire
leggendo DNA apparentemente
“insignificante” si stanno costantemente trovando nuovi elementi che
sembrano indicare che anche queste
sequenze “inutili” hanno una loro
funzione.
La sintesi dei polipeptidi comporta la decodificazione dei codoni degli mRNA ad opera
degli RNA di trasporto
La formazione di un polipeptide secondo l’informazione contenuta nell’mRNA si chiama
traduzione e, tra i processi biosintetici che avvengono nelle cellule, è il più complesso.
Il processo di traduzione (sintesi delle proteine) richiede la presenza di mRNA,
amminoacidi, numerosi enzimi, ribosomi e di una fonte di energia chimica
rappresenta-ta da molecole di ATP (o GTP). Inoltre vi partecipa un secondo tipo di
RNA, che decodifica i codoni dell’mRNA e li traduce nel linguaggio delle proteine (gli
amminoacidi). Questo “decodificatore molecolare” si chiama RNA di trasporto
(tRNA).
Gli RNA di trasporto funzionano come qualunque apparecchio decodificatore:
riconoscono una serie di simboli e li converto in una serie corrispondente. La funzione
decodificatrice dei tRNA dipende strettamente dalla loro forma tridimensionale
(Figura 9.8).
Ad un capo della molecola vi è una sequenza di tre nucleotidi specifica per ogni tRNA,
l’anticodone, che può unirsi per complementarietà dei nucleotidi con un codone
dell’mRNA. Dalla parte opposta all’anticodone, il tRNA presenta un sito al quale si lega
uno specifico amminoacido. (Un tRNA legato covalentemente al corrispondente
amminoacido si chiama tRNA “carico”).
In tutti i tRNA i due capi opposti della molecola si trovano esattamente alla stessa
distanza. Un tRNA inserisce il suo amminoacido nella giusta posizione del polipeptide,
ogni volta che nell’mRNA compare il codone corrispondente.
Per fare un esempio, il codone UCU dell’mRNA si lega solo con l’anticodone AGA del
tRNA che trasporta l’amminoacido serina; ne consegue che, quando nella traduzione di
un mRNA si raggiunge un codone UCU, in quel punto del polipeptide in via di
formazione viene sempre introdotta la serina.
Il tRNA rappresenta quindi il collegamento tra il linguaggio dei codoni dell’mRNA e il
linguaggio degli amminoacidi.
Il codice genetico
I ricercatori impiegarono la prima metà degli anni Sessanta per decifrare tutto il
“codice genetico” e, quando il lavoro fu completato, a ogni parola molecolare (codone)
era associato il corrispondente amminoacido (Figura 9.9).
Tra gli aspetti più interessanti, emerse che il codice genetico è “universale”, cioè un
determinato codone corrisponde allo stesso amminoacido, indipendentemente dal tipo
di organismo, sia esso un batterio, un lievito, un fungo, un abete o un essere umano. In
tutti questi organismi, per esempio, il codone CAU determina sempre l’inserimento
dell’amminoacido tirosina.
Si ritiene che tutti gli organismi abbiano ereditato il codice universale da un antenato
comune, vissuto molto prima che il primo organismo eucariote facesse la comparsa
nello scenario della vita.
Il carattere universale del codice genetico comporta anche che i geni umani possano
funzionare in organismi come i batteri, e viceversa; ciò ha per noi sia conseguenze
negative sia positive.
Per esempio, proprio perché i loro geni funzionano anche nelle cellule umane, i virus –
che possono causare malattie che vanno dal comune raffreddore all’AIDS – sono in
grado di impadronirsi del “macchinario” delle cellule umane e utilizzarlo ai propri fini
(Figura 6.9); tale “macchinario” costruisce infatti proteine sia con le istruzioni del
DNA umano sia con quelle del DNA virale.
Per quanto riguarda il versante positivo, oggi, mediante le tecniche della biotecnologia,
siamo in grado di utilizzare virus e batteri per sintetizzare le più svariate molecole
biologiche come l’insulina e l’ormone della crescita umani; in questo caso, sono
determinati geni umani che vengono fatti agire in laboratorio all’interno di opportuni
microrganismi.
Dei 64 codoni, quattro richiedono particolare attenzione. Tre di essi (UGA, UAG e
UAA) non corrispondono ad alcun amminoacido e fungono da segnali di arresto, alla
conclusione della sintesi di un polipeptide (codoni di arresto o, anche, codoni non
senso). Un altro codone, AUG, che corrisponde all’amminoacido metionina, è il codone
d’inizio. AUG è sempre presente all’inizio della porzione codificante degli mRNA e dà
avvio alla sintesi proteica.
Si può notare anche che il codice genetico è ridondante, cioè un amminoacido può
essere specificato da più di una tripletta. In effetti, quasi tutti gli amminoacidi sono
codificati da più codoni dell’mRNA, che spesso differiscono tra loro per la terza
base azotata. Viceversa, ogni codone codifica per un solo amminoacido.
Ci si può fare un’idea di come gli scienziati siano riusciti a decifrare il codice genetico
leggendo l’approfondimento Come è stato decifrato il codice genetico?.
La traduzione è un processo in tre fasi che avviene sui ribosomi, veri e propri “banchi
di lavoro” molecolari
La traduzione avviene nei ribosomi, organelli formati da alcune decine di proteine
differenti e da un certo numero di molecole di RNA. Il tipo di RNA contenuto nei
ribosomi si chiama RNA ribosomiale (rRNA) ed è il terzo tipo di RNA prodotto dalle
cellule.
Mentre gli mRNA trasportano un’informazione codificata e i tRNA servono a
decodificarla, gli rRNA sono principalmente molecole strutturali, che formano
un’impalcatura alla quale si possono legare le varie proteine ribosomiali.
Queste ultime svolgono diverse funzioni: alcune servono a tenere assieme la
particella ribosomiale, mentre altre si legano agli mRNA o ai tRNA e partecipano
attivamente come enzimi alla sintesi dei polipeptidi.
I ribosomi sono componenti non specifici dell’apparato di traduzione, delle specie di
“banchi di lavoro”, sui quali può essere tradotto qualsiasi mRNA.
Un ribosoma attivo è formato da due subunità, una più grande, l’altra più piccola
(Figura 9.10). Le due subunità di un ribosoma si uniscono all’inizio della sintesi del
polipeptide, per poi separarsi quando la sintesi si conclude.
Un ribosoma attivo (formato dalle due subunità) ha un solco attraverso il quale può
scorrere la molecola di mRNA. Inoltre un ribosoma possiede due siti in cui possono
essere accolti due tRNA, in modo che i loro amminoacidi si vengano a trovare vicini
sulla subunità maggiore. Questa contiene un enzima che forma legami covalenti tra gli
amminoacidi adiacenti.
Mentre il ribosoma scorre lungo l’RNA messaggero, nuovi amminoacidi vengono
aggiunti al polipeptide in corso di formazione, nell’ordine determinato dall’mRNA.
L’energia necessaria per formare i legami tra gli aminoacidi proviene da molecole del
tipo dell’ATP.
I momenti principali del processo sono mostrati nelle Figure 6.13 e 9.11, anche se, per
maggiore chiarezza, sono stati omessi molti enzimi e alte molecole accessorie.
Nella traduzione si riconoscono tre fasi:
l’inizio;
l’allungamento della catena polipeptidica;
la conclusione del processo o terminazione.
Nella fase di inizio si forma il complesso tra mRNA, subunità minore e tRNA e il
messaggio viene posizionato correttamente
Il processo di traduzione comincia quando l’mRNA si lega alla subunità minore di un
ribosoma. Il legame avviene sempre in corrispondenza del codone d’inizio AUG ed è
seguito dall’unione del primo tRNA (il cui anticodone è UAC, complementare al codone
d’inizio). Questo tRNA trasporta la metionina, che è quindi il primo amminoacido di un
polipeptide in corso di formazione.
Il legame del codone AUG al ribosoma determina una “griglia di lettura”, assicura cioè
che la traduzione incominci dal nucleotide giusto. Se la lettura del messaggio iniziasse
uno o due nucleotidi più in là, verrebbero lette le triplette sbagliate e, di conseguenza,
gli amminoacidi incorporati nel polipeptide non sarebbero quelli richiesti.