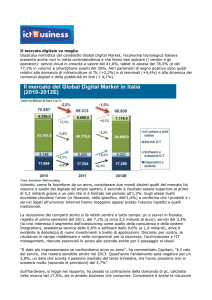
Il Panorama tecnologico del web 2.0
Un file in formato HTML è un file che, oltre a contenere il testo che verrà visualizzato dal browser, contiene
anche dei comandi (racchiusi sempre tra i simboli "<" e ">" chiamati "tag") che associano al testo un
particolare attributo.Generalmente l'aspetto di un tag è il seguente <nome tag>Testo influenzato dal
tag</nome tag>
• Metadata per convogliare informazioni utili ad applicazioni esterne (es. motori di ricerca) o al browser (es.
codifica dei caratteri, utile per la visualizzazione di alfabeti non latini)
• Metadata di tipo http-equiv per controllare informazioni aggiuntive nel protocollo HTTP
• Collegamenti verso file di servizio esterni (CSS, script, icone visualizzabili nella barra degli indirizzi del
browser)
• Inserimento di script (codice eseguibile) utilizzati dal documento
• Informazioni di stile (CSS locali)
• Il titolo associato alla pagina e visualizzato nella finestra principale del browser
Intestazioni (titoli di capitoli, di paragrafi eccetera)
strutture di testo (testo indentato, paragrafi, eccetera)
Aspetto del testo (grassetto, corsivo, eccetera)
• elenchi e liste (numerate, generiche, di definizione)
• Tabelle
• moduli elettronici (campi compilabili dall'utente, campi selezionabili, menu a tendina, pulsanti eccetera)
• collegamenti ipertestuali e ancore
• layout generico del documento
• Inserimento di immagini
• Inserimento di contenuti multimediali (audio, video, animazioni eccetera)
• Inserimento di contenuti interattivi (script, applicazioni esterne)
Il 26 gennaio 2000 il World Wide Web Consortium (W3C) rilascia la prima specifica del linguaggio di markup
destinato a sostituire l’HTML. Quel linguaggio si chiama XHTML.
La specifica di XHTML occupa una sola pagina. Non ci sono nuovi tag, nulla di rivoluzionario rispetto
all’HTML 4.0. Eppure, l’ XHTML è attualmente il linguaggio raccomandato dal Consortium per la
realizzazione di pagine web, è davvero un passo decisivo e fondamentale.Il tempo dell'anarchia, del codice
"sporco ma basta che funzioni", degli elementi proprietari imposti è finito.
• Codice pulito e ben strutturato
Con XHTML, almeno nella sua versione strict, si torna a un linguaggio che definisce solo la struttura.
Infatti, l’HTML è nato come linguaggio per definire la struttura di un documento. Non ha nulla a che vedere
con la presentazione. Eppure, è stato “stiracchiato” da tutte le parti, costretto a svolgere compiti per cui
non è stato creato. Il caso delle tabelle è quello macroscopico. Sono nate per la presentazione di dati
tabulari. Sono state impiegate come l'unico mezzo per costruire il layout della pagina. Semplicemente, se
inserite elementi non supportati (font, larghezza per le celle di tabelle o margini per il body, per citare solo
alcuni esempi) il documento non è valido. Quindi: la formattazione si fa con i CSS. Mai più tag <font>, mai
più gif di un pixel, niente più tabelle per il layout. Risultato: codice più pulito, più logico, più gestibile.
• Portabilità
La portabilità è la capacità/possibilità di un documento di essere visualizzato e implementato efficacemente
su diversi sistemi: PC, PDA, cellulari WAP/GPRS, WebTV. Ora, se pensate alle limitazioni in termini di
memoria, ampiezza dello schermo e usabilità di un terminale mobile, capirete perchè è importante un
linguaggio essenziale, centrato sulla struttura del documento, privo di orpelli inutili. Ciò che ha senso è
avere un titolo della pagina, un'intestazione, un paragrafo, una lista per scandire gli argomenti.
• Accessibilità
I documenti scritti in XHTML e validati sono naturalmente più accessibili. Da una parte la validazione
richiede l'uso obbligatorio di funzionalità come il testo alternativo per le immagini. Dall'altra, una pagina
che evita elementi non standard, ben definita nella struttura è di gran lunga, meglio gestibile da browser
alternativi come quelli vocali o testuali. Per questi aspetti è obbligatoria la lettura delle linee guida per
l'accessibilità del contenuto Web rilasciate dal W3C.
Mentre l’HTML serve per visualizzare i dati e si focalizza su come i dati devono apparire (con un gruppo
limitato di tag) l’XML serve per descrivere i dati e si focalizza sul cosa contiene il dato (con un gruppo di tag
che definisce all’occorrenza l’utente)
<?xml version="1.0"?>
<GATTO>
<NOME>Silvestro</NOMEE>
<RAZZA>Siamese</RAZZA>
<ETA’>6</ETA’>
<LICENZA>Izz138bod</LICENZA>
<PROPRIETARIO>Antonio Rossi</PROPRIETARIO>
</GATTO>
Con i tag XML è possibile riconoscere esattamente il tipo di dati esaminati. Nell’esempio di sopra, i dati
fanno riferimento a un gatto ed è possibile individuarne facilmente il nome, l'età e così via. La possibilità di
creare tag per definire di fatto qualsiasi struttura di dati è ciò che rende questo linguaggio estendibile.
Silvestro Siamese 6 Izz138bod Antonio Rossi
Le RIA o (Rich Internet Application) sono applicazioni web dalle caratteristiche simili alle applicazioni
desktop (cioè residenti sul computer), hanno dimostrato di saper migliorare l’interattività delle applicazioni
web, fornendo all’utente maggiori esperienze d’uso.In un certo senso le RIA rappresentano una
generazione di applicazioni che permette una “user experience” totalmente rinnovata, fondata sul meglio
delle caratteristiche funzionali e progettuali che finora erano prerogativa alternata del web o delle
applicazioni desktop.
Le RIA si caratterizzano per la :
Infatti la parte dell'applicazione che elabora i dati è trasferita a livello client e fornisce una pronta risposta
all'interfaccia utente, mentre la gran parte dei dati e dell'applicazione rimane sul server remoto, con
notevole alleggerimento per il computer utente.
• dimensione interattiva;
• multimedialità;
• velocità utente.
Spesso il codice della pagina da cui prende il via la richiesta è in gran parte simile a quello del documento in
cui viene mostrata la risposta dell’elaborazione del server. Ciò comporta uno spreco inutile di banda e
un’interfaccia utente molto più lenta di quanto potrebbe essere.
AJAX è la più nota tecnica di sviluppo per la realizzazione di applicazioni web interattive (Rich Internet
Application). Nonostante queste tecnologie circolassero negli ambienti informatici già da molto tempo, fu
Google che, con applicazioni come Google Map e Google Suggest, pose per primo l’attenzione su questo
HTML dinamico. James Garrett di Adaptive Path diede un nome a questo modello: Ajax. Il concetto è in
parte espresso nell’acronimo scelto, cioè un utilizzo asincrono di JavaScript che attraverso
l’interfacciamento con XML, può permettere a un client di richiamare informazioni lato server in modo
veloce e trasparente, allargando così gli orizzonti delle Rich Internet Applications (RIA).
Il vantaggio principale di AJAX rispetto alle altre tecnologie, sta nel fatto che è possibile avere una pagina
con più contenuti dinamici che si modificano contemporaneamente in seguito all'azione di un utente.
Questo consente innanzitutto di migliorare l’User-Experience e rendere la Web GUI (Graphical User
Interface) il più simile possibile all'interfaccia grafica che abbiamo normalmente sui nostri computer, sui
desktop dei nostri sistemi e quindi abbassare moltissimo le differenze dal punto di vista percettivo che si
hanno tra un'interfaccia Web tipicamente percepita come poco interattiva. “Google Suggest e Google
Maps, sono due esempi di un nuovo approccio alle applicazione web che noi ad Adaptive Path abbiamo
chiamato Ajax. Il nome è un’abbreviazione per Asynchronous JavaScript + XML e rappresenta un passo
fondamentale verso quello che sarà possibile sul web”.
Confrontato ad altri sistemi di pagine web, Ajax si distingue principalmente per tre caratteristiche:
1. Utilizza un motore (ajax engine) client-side come intermediario tra la UI (Interfaccia Utente) e il server.
2. L’attività dell’utente fa in modo che JavaScript si rivolga al motore evitando di chiedere al server il
caricamento di una pagina
3. Impiega il linguaggio XML tra server e motore
I principali componenti che rappresentano l’attuale tendenza del web 2.0
RSS
Mashup
Cloud Computing
Internet of Things
L'RSS, acronimo di Really Simple Syndacation, è un sistema basato sul linguaggio standard XML per la
distribuzione di contenuti; è un linguaggio che permette di distribuire con grande facilità i contenuti di un
sito e di riaggregarli e presentarli sotto altre forme. Essi, infatti, consentono di monitorare i contenuti di un
sito e di usufruirne anche al di fuori del sito stesso avvisandoci in tempo reale ogni qualvolta vi siano degli
aggiornamenti.Gli aggregatori RSS, detto anche lettore di feed: sono software o applicazioni Web che
raccolgono contenuti web come titoli di notiziari, blog, podcast, e vlog in un unico spazio per una
consultazione facilitata. Gli aggregatori riducono il tempo e gli sforzi necessari per seguire regolarmente
aggiornamenti di un sito web e permettono di creare uno spazio di informazione unico, in pratica un
"notiziario personale."
Il Mashup è un sito o un'applicazione web di tipo ibrido, cioè tale da includere dinamicamente informazioni
o contenuti provenienti da più fonti per creare un servizio completamente nuovo. Il mashup non avrebbe
potuto svilupparsi nel web 1.0 proprio per la mancanza delle fonti, dei contenuti che l'utente può produrre
e mette a disposizione degli altri utenti in rete e la mancanza soprattutto della cultura di circolazione dei
dati, anche in formato open, cultura che si fa strada solo negli ultimi anni. Per creare un mashup è
essenziale poter ricavare informazioni dai siti web (o almeno poter convertire in informazione strutturata il
contenuto del sito una volta estratto). Il meccanismo più efficace per accedere a un servizio web è
probabilmente la sua API Application Programming Interface (Interfaccia di Programmazione di
un'Applicazione)Per
API,
si indica ogni insieme di procedure disponibili al programmatore, che
permette ad altri programmi di accedere ai servizi offerti da un’applicazione.Ma perché un sito dovrebbe
fornire API pubbliche ed esporre le proprie informazioni – quindi la fonte del proprio valore –
gratuitamente online? Permettere agli utenti di manipolare intensivamente i contenuti di un sito web o di
invocare i suoi servizi da un client di un’applicazione esterna, è un ottimo modo per testare l’applicazione:
quando centinaia (o addirittura migliaia) di utenti cominciano a sviluppare servizi web sfruttando i
contenuti di un sito, questo è di fatto sottoposto a un test su larga scala, e presumibilmente, i bachi
contenuti nell’applicazione verranno scoperti e sanati. I mashup possono essere creati da sviluppatori
esperti in grado di rilasciare applicazioni in breve tempo. Gli utenti finali non sono coinvolti nella
produzione dei mashup ma traggono in ogni caso benefici dai tempi di sviluppo ridottiGli sviluppatori
esperti creano servizi adatti a essere composti in un mashup e forniscono allo stesso tempo un ambiente
ben delimitato (sandbox) dove gli utenti finali possono combinare i servizi. Il ruolo degli sviluppatori è
quindi creare servizi, mentre i mashup sono costruiti dagli utenti, i quali sono maggiormente a conoscenza
del dominio applicativo in cui i mashup saranno utilizzati Gli sviluppatori esperti rilasciano un ambiente che
permette a ognuno di creare i propri mashup.
Mapping
All’interno dell’incredibile mole di dati su cose ed attività che si vanno raccogliendo, contengono anche
informazioni geografiche possono essere rappresentati anche attraverso l’uso delle mappe. Uno degli
eventi che ha catalizzato l’avvento dei mashup è stato l’introduzione da parte di Google delle Google Maps
API. Il fatto che queste API fossero pubbliche ed aperte ha permesso agli sviluppatori web (nonché agli
hobbisti, agli smanettoni e ad altri) di mescolare tutti questi tipi di dati (qualsiasi cosa dai disastri nucleari
alle mucche della CowParade di Boston) e di mostrarli su delle mappe.
• Google (Google Maps)
• Microsoft (con Virtual Earth);
• Yahoo (con Yahoo Maps);
• AOL (MapQuest).
Cloud computing
Il cloud computing è un ambiente di esecuzione elastico che consente l'accesso via rete e su richiesta a un
insieme condiviso di risorse di calcolo configurabili (ad esempio rete, server, dispositivi di memorizzazione,
applicazioni e servizi) sotto forma di servizi a vari livelli di granularità. Tali servizi possono essere
rapidamente richiesti, forniti e rilasciati con minimo sforzo gestionale da parte dell’utente e minima
interazione con il fornitore
Mainframe computing 1965 1 computer / molti utenti
Client-server computing 1985 molti computer / molti utenti
Cloud computing 2005 internet / moltissimi utenti
Caratteristiche essenziali del cloud Computing
On-demand self-service - Un utilizzatore può unilateralmente fornire capacità di calcolo come server
time e network storage, se necessario, senza richiedere l’interazione umana con alcun fornitore del
servizio. Il servizio offerto è completamente automatizzato e permette di modificare la richiesta a
seconda della volontà del consumatore
Broad Network Access - Le capacità sono disponibili in rete e provviste generalmente di un accesso
web-based, pertanto sono accessibili in qualsiasi momento non solo con PC o notebook ma anche
tramite “thin” o “thick” client forniti di connettività internet (ad esempio cellulari e tablet, PDA). Gli
utenti possono accedere al servizio in qualunque momento e da qualsiasi luogo, condividere dati e
collaborare diventa molto più semplice..
Resource pooling - Le risorse computazionali del fornitore di servizi sono messe a disposizione per
servire molteplici utenti finali utilizzando un modello multiutente, con differenti risorse fisiche e virtuali
assegnate e riassegnate dinamicamente secondo la domanda dell'utilizzatore.
Elasticità rapida - Le capacità di calcolo possono essere fornite rapidamente ed elasticamente – in
alcuni casi in modo automatico – incrementandole velocemente; e rilasciate rapidamente
decrementandole in modo altrettanto veloce. Per l'utilizzatore, le capacità disponibili spesso appaiono
illimitate e possono essere acquistate in qualsiasi quantità e in ogni momento
Servizio misurato - I sistemi Cloud controllano e ottimizzano automaticamente l'utilizzo delle risorse
mediante misurazioni effettuate a un livello di astrazione adeguato al tipo di servizio (ad esempio,
storage, processore, banda, o utenti attivi). L'utilizzo delle risorse può essere monitorato, controllato e
relazionato – aggiungendo trasparenza sia per il fornitore di servizio che per l'utilizzatore dello stesso.
pay-per-use - L’utente può modificare in qualsiasi momento la richiesta secondo una logica di pay-peruse. Infatti, può sfruttare i servizi cloud su richiesta, scegliendo il fornitore e i servizi che ritiene
opportuno a seconda delle proprie necessità, e può richiedere l'utilizzo delle risorse solo quando
necessarie e solo per il tempo necessario. L’utente verrà poi addebitato dai fornitori di servizi
solamente in base all’effettivo sfruttamento delle risorse stesse.
Modelli di servizio del cloud Computing
IaaS (Infrastructure as a Service) - Il modello di servizio Infrastructure as a Service prevede che il
servizio offerto consista in un’infrastruttura con capacità computazionale, di memorizzazione, e di
rete, sulla quale l’utente possa installare ed eseguire il software a lui necessario, dal sistema
operativo alle applicazioni. Quando acquisto un servizio IaaS, ho a disposizione una virtualizzazione
dell’hardware di un computer tradizionale: quindi ho della CPU, della RAM, dello Storage e delle
schede di rete con connettività. Uno dei migliori esempi di cloud computing IaaS è la piattaforma di
Amazon EC2 (Elastic Compute Cloud)
PaaS (Platform as a Service) - Il modello di servizio Platform as a Service prevede che il fornitore del
servizio metta a disposizione dell’utente un’interfaccia di programmazione (API) con la quale
l’utente può scrivere applicazioni che interagiscono con il servizio. Google AppEngine è una offerta
tipicamente PaaS. Consente di costruire solide applicazioni web utilizzando le stesse tecnologie
utilizzate dalle più conosciute applicazioni Google
SaaS (Software as a Service) - Il Software as a Service è probabilmente quello più facilmente
comprensibile e di più largo consumo. Il modello di servizio Software as a Service prevede che il
servizio offerto sia un'applicazione software che può essere utilizzata su richiesta. In questo caso, il
fornitore del servizio installa l'applicazione nei propri data center, e fornisce agli utenti
un’interfaccia per utilizzarla, come ad esempio un’interfaccia web.
Modelli d’implementazione del Cloud Computing
Pubblic Cloud - I servizi cloud pubblici sono offerti da fornitori che mettono a disposizione dei
propri utenti/clienti la potenza di calcolo e/o di memorizzazione dei loro data center. Il tipo di
servizi cloud che vengono offerti dal fornitore (IaaS, PaaS, SaaS) dipende dalla politica del fornitore
stesso, così come il prezzo e la tariffazione.
Private Cloud - Un cloud privato viene installato dall'utente nel suo data center per suo utilizzo
esclusivo. Il principale vantaggio di un cloud privato è che i servizi vengono forniti da elaboratori
che si trovano nel dominio dell'utente, e quindi l'utente ha il pieno controllo delle macchine sulle
quali vengono conservati i dati e vengono eseguiti i suoi processi. In particolare, l'utente può
applicare su queste macchine le politiche di sicurezza che ritiene più opportune per la protezione
dei suoi dati.
Community Cloud - Nel Community cloud l’infrastruttura su cui sono installati i servizi cloud è
condivisa da un insieme di soggetti, aziende, organizzazioni, ecc, che condividono uno scopo
comune e che hanno le stesse esigenze, come ad esempio potrebbero essere i vari soggetti della
pubblica amministrazione. L’infrastruttura può essere gestita dalla comunità stessa, oppure da un
fornitore di servizi esterno
Hybrid Cloud - Il cloud Ibrido è una combinazione del modello pubblico e di quello privato, ovvero è
un modello in cui l'utente utilizza risorse sia del suo cloud privato che di un cloud pubblico. Il cloud
Ibrido può essere utilizzato con successo in vari casi
I pro
Nessun software da scaricare e installare sul proprio computer
- Nessuna necessità di upgrading del software quando vengono aggiunte nuove funzioni o
eliminati problemi esistenti
- È sufficiente un thin client con minimi requisiti hardware
- Si può accedere ai propri documenti praticamente da ogni computer dotato di una
connessione a banda larga
- È possibile condividere i documenti con altri utenti, senza bisogno di un proprio server
- Non si deve acquistare una licenza software (e i suoi upgrade). Ci si abbona al servizio
(SaaS); in alcuni casi il servizio è gratuito
- Nessun problema in caso di crash del proprio computer: i documenti sono al sicuro sul
server.
I contro
Sicurezza dei dati: tutti i propri dati risiedono su un server remoto, di cui non si ha il controllo
(anche se si possono effettuare regolari backup).
-Velocità: Le office suite attualmente disponibili richiedono spesso una connessione a
banda larga
- Completezza funzionale: Attualmente, le funzioni fornite dalle suites online sono meno
complete di quelle fornite dalle suite tradizionali.
- Non è agevole lavorare off-line: per ricevere e trasmettere le modifiche occorre essere
connessi.
Ubiquitous Computing (Ubicomp), Pervasive Computing, Internet every-where, Internet of Things (IoT).
Numerosi nomi sono usati per descrivere sinteticamente il nuovo paradigma di computazione.Un percorso
nello sviluppo tecnologico in base al quale, attraverso la rete Internet, potenzialmente ogni oggetto - smart
things (oggetto intelligente) - della nostra esperienza quotidiana acquista una sua identità nel mondo
digitale, può essere localizzato, e dotato di capacità d’interazione con l’ambiente circostante e di
elaborazione datiL’Ubiquitous Computing è quasi l’opposto della realtà virtuale, Infatti, se la realtà virtuale
mette le persone dentro un “computer-generated world”, il Pervasive Computing obbliga i computer a
vivere qui fuori, nel mondo, insieme alle persone. Un QR Code è la versione evoluta dei codici a barre: si
tratta sostanzialmente di un’immagine contenente dei dati in un formato facilmente acquisibile dalla
fotocamera di uno smartphone o cellulare di ultima generazione. I QR Code, a differenza dei codici a barre,
possono contenere non solo semplici sequenze di numeri, ma possono essere associate altre informazioni.
Ad esempio:
• URL sito web;
• Testo (pubblicitario, slogan, vario, ecc..);
• Numero telefonico;
• Collegamento con i propri Social Network;
• Indirizzi o percorsi associati a Google Maps;
• Messaggi SMS;
• Collegamenti a video su Youtube;
• Accesso Wi-Fi;
La realtà aumentata è La Realtà Aumentata, (Augmented Reality, abbreviata solitamente
con l’acronimo AR) è il risultato della sovrapposizione di oggetti virtuali al mondo reale.
L’utente non è più immerso in un ambiente virtuale realizzato al computer, sono le
informazioni ad “uscire” dal mondo virtuale ed invadere la realtà attraverso dispositivi che
permettono di aggiungere layer informativi al mondo fisico.