Informatica per le discipline
umanistiche 2
– lezioni 6 e 7 –
Parte III: il computer come strumento
per l’interazione e la comunicazione
Web 1.0
Web 1.0
Che cosa vuol dire 1.0?
In informatica, la numerazione x.y per
indicare la versione di un prodotto ha
questo significato: se le modifiche
apportate non sono particolarmente
rivoluzionarie, si considera il nuovo
prodotto solo una variante della
stessa versione, quindi si lascia
intatto x e si aumenta y di 1. Quando
invece si è di fronte a un
cambiamento radicale, si aumenta x
di 1 e si azzera y per segnare lʼinizio
di una nuova era del prodotto.
Web 1.0
1.1
1.2
2.0
Il Web (o più precisamente World Wide Web, noto
anche come WWW o W3) è nato nellʼagosto del
1991 presso il CERN di Ginevra, grazie a unʼidea
di Tim Berners-Lee
Secondo quanto riportato sul blog di Google, il
Web contava nel luglio 2008 più di 1000 miliardi
di pagine distribuite su più di 100 milioni di host
Che cosʼè il Web?
un colossale ipertesto, formato da miliardi di
ʻpagineʼ collegate fra loro?
un archivio distribuito di informazioni?
una rete di servizi fruibili in certi luoghi
virtuali chiamati “siti”?
Evoluzione del Web
Nellʼevoluzione del Web si distinguono oggi diverse
fasi:
Web 1.0: la fase iniziale, dal 1991 ai primi anni del
2000
Web 2.0: dai primi anni del 2000 a oggi (il termine
“Web 2.0” è stato usato per la prima volta nel 2004)
Web 3.0: ciò che il Web dovrebbe diventare nei
prossimi anni
...
La distinzione fra queste fasi è piuttosto vaga, e autori
diversi le definiscono in modi differenti: per comodità
faremo comunque uso di questa terminologia, almeno
in modo informale
Il Web 1.0
risorse rese disponibili problemi e soluzioni
la tipologia dellʼinterazione
Risorse rese disponibili
Il Web 1.0 è innanzitutto un ipertesto multimediale
distribuito:
ipertesto: il Web 1.0 è costituito da pagine
collegate fra loro da link, che consentono a un
utente di navigare nellʼipertesto
multimediale: le pagine contengono un testo
audiovisivo nel senso più ampio del termine:
testo linguistico, grafici, immagini, video
distribuito: le pagine dellʼipertesto risiedono su
molti host distinti, connessi tramite internet
Un insieme di pagine web correlate (in genere, ma
non necessariamente, memorizzate su un singolo
host) costituiscono un sito Web
Problemi e soluzioni
La seguente tabella schematizza i principali
problemi del Web 1.0 e le relative soluzioni:
problema
soluzione
costruire le pagine
linguaggio HTML
(HyperText Markup Language)
pubblicare le pagine
protocollo HTTP,
URL (Uniform Resource Locator)
trovare le pagine
motori di ricerca
visualizzare le pagine
browser
lato server
lato client
I linguaggi di marcatura
Un linguaggio di marcatura (markup language) è un sistema
di simboli convenzionali (chiamati tag) che possono essere
utilizzati per marcare certe sezioni di un testo, associando
una determinata proprietà a ciascuna sezione
Esempio:
<titoloOpera>La Divina Commedia</titoloOpera>
<nomeAutore>Dante Alighieri</nomeAutore>
<titoloVolume>Inferno</titoloVolume>
<titoloCapitolo>Canto I</titoloCapitolo>
<testo>
Nel mezzo del cammin di nostra vita
mi ritrovai per una selva oscura
ché la diritta via era smarrita
...
</testo>
I tag si comportano come delle parentesi: a ogni tag di apertura
deve corrispondere un tag di chiusura e fra questi è contenuta la
sezione marcata del testo:
<titoloOpera>Il cacciatore di aquiloni</titoloOpera>
È possibile incassare lʼuna nellʼaltra sezioni marcate di testo:
<capitolo>
<titoloCapitolo>Uno</titoloCapitolo>
<periodo>
Sono diventato la persona che sono oggi all’età di
dodici anni, in una gelida giornata invernale del
1975.
...
</periodo>
...
</capitolo>
...
Il linguaggio HTML
HTML (HyperText Markup Language) è un linguaggio
standard per la marcatura di ipertesti, ovvero di testi che
possono contenere collegamenti (link) ad altre pagine
HTML prevede un insieme prefissato di tag, il cui
significato è definito da una raccomandazione W3C
Esempi di tag HTML:
<head> ... </head>
<style>... </style>
<title>... </title>
<body> ... </body>
HTML (HyperText Markup Language) è un linguaggio
standard per la marcatura di ipertesti, ovvero di testi che
possono contenere collegamenti (link) ad altre pagine
HTML prevede un insieme prefissato di tag, il cui
significato è definito da una raccomandazione W3C
Esempi di tag HTML:
<head> ...
<style>...
<title>...
<body> ...
“Significato” va sempre
</head>
inteso in maniera molto
</style>
debole in informatica.
Ricordatevi della stanza
</title>
cinese.
</body>
Significato?
<題>Freedom</題>
Il W3C dice:
Authors should use the TITLE element to
identify the contents of a document. Since
users often consult documents out of context,
authors should provide context-rich titles.
Thus, instead of a title such as "Introduction",
which doesn't provide much contextual
background, authors should supply a title such
as "Introduction to Medieval Bee-Keeping"
instead.
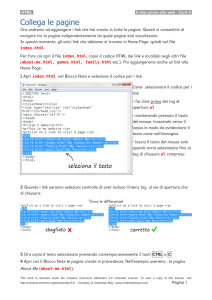
Le pagine HTML
Nel caso più semplice, una pagina web è un file di
testo marcato tramite tag HTML per costruire una pagina è possibile: scrivere direttamente un file HTML utilizzando
un editor di file di testo
oppure scrivere una pagina web con uno
strumento software specifico, che la traduce
automaticamente in HTML
per visualizzare una pagina è possibile:
utilizzare un browser, che è in grado di
visualizzare i file HTML interpretando i tag in
modo coerente con le raccomandazioni W3C
Pagine dinamiche
Lʼaccesso a una pagina web può innescare lʼesecuzione di
programmi, ad esempio per eseguire la prenotazione di un
biglietto aereo
Questi programmi possono generare, in tutto o in parte, la
pagina che viene visualizzata allʼinterno dal browser: si
parla allora di pagine dinamiche, mentre le pagine
contenenti un testo fisso sono dette pagine statiche
Ad esempio, il sito del corso cs.unibg.it/verdicch/idu2.html è costituito da una pagina
statica, mentre durante lʼacquisto di un biglietto su
easyjet.com si può vedere una sequenza di pagine
dinamiche
Le pagine dinamiche di easyjet.com hanno una
caratteristica in più: sono pagine interattive, che generano
contenuti diversi a seconda di particolari richieste eseguite
dallʼutente
Pubblicare pagine
Una pagina web si dice “pubblicata” quando è accessibile
tramite internet
Per accedere a una pagina occorre localizzarla nella rete
A questo scopo ogni pagina web è contraddistinta da un
URL (Uniform Resource Locator), ad esempio:
http://cs.unibg.it/verdicch/idu2.html
Una pagina web si dice “pubblicata” quando è accessibile
tramite internet
Per accedere a una pagina occorre localizzarla nella rete
A questo scopo ogni pagina web è contraddistinta da un URL
(Uniform Resource Locator), ad esempio:
http://cs.unibg.it/verdicch/idu2.html
la parte http:// identifica il protocollo di trasferimento di
ipertesti (ISO/OSI livello 7, vedi III-1:26)
la parte www.usi.ch identifica un dominio (vedi III-1:28)
la parte universita/library.htm identifica un file HTML (come
indicato dallʼestensione htm) descrivendo il cammino nel
file system dello host corrispondente al dominio (vedi
II-1:9)
Una pagina web si dice “pubblicata” quando è accessibile
tramite internet
Per accedere a una pagina occorre localizzarla nella rete
A questo scopo ogni pagina web è contraddistinta da un URL
(Uniform Resource Locator), ad esempio:
http://cs.unibg.it/verdicch/idu2.html
identifica il protocollo di trasferimento di ipertesti
(ISO/OSI livello 7, vedi III-1:26)
la parte www.usi.ch identifica un dominio (vedi III-1:28)
la parte universita/library.htm identifica un file HTML (come
indicato dallʼestensione htm) descrivendo il cammino nel
file system dello host corrispondente al dominio (vedi
II-1:9)
Una pagina web si dice “pubblicata” quando è accessibile
tramite internet
Per accedere a una pagina occorre localizzarla nella rete
A questo scopo ogni pagina web è contraddistinta da un URL
(Uniform Resource Locator), ad esempio:
http://cs.unibg.it/verdicch/idu2.html
identifica lʼhost in internet
Una pagina web si dice “pubblicata” quando è accessibile
tramite internet
Per accedere a una pagina occorre localizzarla nella rete
A questo scopo ogni pagina web è contraddistinta da un URL
(Uniform Resource Locator), ad esempio:
http://cs.unibg.it/verdicch/idu2.html
identifica un file HTML (come indicato
dallʼestensione html) descrivendo il
cammino nel file system (tra le cartelle in cui
sono organizzati i file) dello host
Una pagina web si dice “pubblicata” quando è accessibile
tramite internet
Per accedere a una pagina occorre localizzarla nella rete
A questo scopo ogni pagina web è contraddistinta da un URL
(Uniform Resource Locator), ad esempio:
http://cs.unibg.it/verdicch/idu2.html
la parte che identifica lʼhost è detta dominio
(o domain name), ed è organizzata in
maniera gerarchica
it
unibg
cs
Domini
Il sito web di UniBG è associato al dominio www.unibg.it
I file (insieme di informazioni trattate in maniera unitaria)
che costituiscono questo sito si trovano fisicamente su
uno host connesso a internet tramite una scheda di rete il
cui indirizzo IP (statico) è 193.204.255.20
Quando un utente desidera accedere al sito web di UniBG,
fornisce a un browser lʼURL
http://www.unibg.it/
Per creare un collegamento con il sito di UniBG è
necessario che il browser ricostruisca lʼindirizzo IP
193.204.255.20 a partire dal nome di dominio www.unibg.it
Lʼassociazione fra un nome di dominio e un indirizzo IP è
possibile grazie a un particolare servizio internet, chiamato
DNS (Domain Name Server) ?
Ma come si fa a visitare
una pagina web di cui
non
si
conosce
lʼindirizzo?
motori di ricerca /
search engine
Naturalmente, tramite i motori di ricerca, o search
engine. Il motore di ricerca dominatore del mercato è
senza ombra di dubbio Google, con il 72% di tutte le
ricerche effettuate (ottobre 2011).
72%
15%
10%
Ecco i due fondatori di Google.
Sergey Brin e Larry Page
Il principale business di Google sta negli annunci pubblicitari
inseriti nelle sue pagine.
Ecco il valore del patrimonio di ciascun co-fondatore di Google.
17 Mld $
17 Mld $
Ognuno di loro può comprare un miliardo e mezzo di papillon.
1500000000 x
Ossia regalare un papillon a ogni cittadino cinese…
in più, ancora 1 miliardo e 300 milioni di € da bruciare
Stiamo comunque parlando di papillon di H&M, abbastanza a
buon mercato.
1500000000 x
Il “villaggio globale” di
Marshall McLuhan
“Understanding Media: the Extensions of Man” (1964)
McLuhan, in tempi precedenti
allʼavvento di Internet, ha
proposto
il
concetto
di
“villaggio
globale”
per
descrivere lʼallargamento, grazie
ai media, del bacino delle nostre
conoscenze da una dimensione
limitata alla ristretta cerchia di
persone con cui abbiamo
contatti
diretti
(il
nostro
villaggio,
appunto)
a
una
dimensione
che
abbraccia
lʼintero globo.
Internet non fa che accentuare tale fenomeno, perché è
di fatto un canale di comunicazione molto efficiente e
diffuso in tutto il mondo. Se da un lato lo scambio di
informazioni ne è favorito, cʼè un rovescio nella
medaglia nel doversi confrontare con standard molto
più alti che in passato, perché persone con
caratteristiche straordinarie di cui non saremmo mai
venuti a conoscenza senza i mezzi di comunicazione,
sono ora non solo raggiungibili, ma anche esaltati
dagli stessi media. Brin e Page, che hanno fatto la loro
fortuna proprio grazie alla comunicazione offerta dalla
loro azienda, mostrano quanto ricco un informatico
potrebbe diventare, ma i media ci offrono standard
irrangiungibili per i più in molti altri aspetti della vita
umana, come ad esempio la bellezza o il potere.
Trovare una pagina web
I motori di ricerca (come Google, Yahoo!Search,
Bing) sono applicazioni server disponibili su
determinati host connessi con internet, cui si
accede in modalità client tramite un browser
Un motore di ricerca è in grado di localizzare le
pagine web che contengono determinate parole o
sequenze di parole
Gli URL di tali pagine, insieme a una concisa
descrizione di ciascuna pagina, vengono
presentati allʼutente in ordine di rilevanza
decrescente Lʼutente può poi sfruttare gli URL per accedere
alle pagine
Un motore di ricerca deve:
1) conoscere le pagine web
2) identificarle in base alle parole della ricerca
3) calcolarne la rilevanza
Un motore di ricerca deve:
1) conoscere le pagine web
2) identificarle in base alle parole della ricerca
3) calcolarne la rilevanza
Per conoscere le pagine presenti nel Web i
motori di ricerca utilizzano:
applicazioni che esplorano
sistematicamente il Web (dette crawler),
scoprendo continuamente pagine
recentemente inserite
basi di dati di grandissime dimensioni, in
cui le pagine scoperte dal crawler vengono
memorizzate e ʻindicizzateʼ, in modo da
poter essere reperite rapidamente in base
alle parole contenute (la base di dati di
Google memorizza attualmente più di 1000
miliardi di pagine)
Un motore di ricerca deve:
1) conoscere le pagine web
2) identificarle in base alle parole della ricerca
3) calcolarne la rilevanza
Lʼidentificazione delle pagine che
corrispondono alla richiesta dellʼutente
avviene mediante ricerca nella base di dati del
motore di ricerca
Come già detto, questa ricerca è agevolata da
speciali indici che consentono di identificare
le pagine contenenti determinate parole senza
doverne scandire il contenuto dallʼinizio alla
fine La scansione integrale di una pagina è
tipicamente eseguita una sola volta, quando
la pagina viene inserita nella base di dati e
indicizzata
Un motore di ricerca deve:
1) conoscere le pagine web
2) identificarle in base alle parole della ricerca
3) calcolarne la rilevanza
Il concetto di rilevanza di un testo (relativamente a una
richiesta) è studiato da tempo da una disciplina nota come
Information Retrieval
I metodi classici di information retrieval si basano soprattutto
sulle frequenze di distribuzione delle parole in un archivio di
documenti Nel caso delle pagine web possono essere utilizzati approcci
differenti, che si basano non solo sul contenuto delle pagine
ma anche sulle connessioni fra le pagine
Il motore di ricerca Google, ad esempio, deve buona parte del
suo successo a un particolare sistema di ordinamento delle
pagine, basato sul concetto di rango di una pagina (page
rank)
Questo sistema è stato realizzato da Sergey Brin e Larry
Page, fondatori di Google Inc., a partire dallʼalgoritmo
HyperSearch ideato da Massimo Marchiori
Massimo Marchiori
Il page rank
Idea di base:
una cosa è tanto più importante
quante più persone ne parlano
Il rango di una pagina A viene quindi calcolato in base al
numero di altre pagine B1, B2, ..., BN che contengono un link
verso A
A sua volta il contributo di una pagina Bk al page rank di A
dipende dal page rank della stessa Bk nonché dal numero di
link contenuti in Bk, secondo una formula piuttosto
complessa
Sembra che dietro ogni business di successo ci sia una formula
segreta.
La comunicazione
nel Web 1.0
Comunicazione di massa:
1) asimmetrica
2) in broadcast asimmetrica
lʼautore è solitamente
distinto dai consumatori (al
contrario, ad es., di uno
scambio di email, che è
simmetrico)
in broadcast
il messaggio è diretto in modo
generico a chiunque sia in
grado di riceverlo (al contrario,
ancora una volta, di uno
scambio di email, che è punto-apunto)
Tuttavia, rispetto ai mezzi di
comunicazione
di
massa
tradizionali, il Web 1.0 è atipico
perché elimina la figura del
distributore e consente a un
autore
di
raggiungere
direttamente i consumatori a
costo molto contenuto (sia per
lʼautore, sia per i consumatori).
Oltre il Web 1.0
Nellʼultimo decennio il Web si è
sviluppato introducendo una
dimensione partecipativa e
collaborativa, tipica della
comunicazione interpersonale
Blog
Forum
Social Network
Wiki
Web 2.0
Parte III: il computer come strumento
per l’interazione e la comunicazione
Web 2.0
Le tecnologie del Web (internet, TCP/IP, http, HTML,
browser, applet, motori di ricerca, ...) sono in grado
di consentire modalità dʼinterazione più avanzate
Da alcuni anni si parla del Web 2.0, tanto che il
termine (coniato nel 2004 da Tim OʼReilly) compare
attualmente in circa 116 milioni di pagine web
(Google, ottobre 2011; 28 milioni solo un anno
prima) Non si tratta solo di nuove tecnologie (rispetto a
quelle utilizzate nel Web 1.0), quanto di un insieme
di applicazioni innovative che creano nuove
possibilità per gli utenti di interagire fra di loro e
con i contenuti del Web
Partecipazione
Le tecnologie del Web eliminano la
necessità di un distributore
interposto fra gli autori e i
consumatori di messaggi.
I consumatori si accorgono che
pubblicare su internet è molto più
semplice dei classici processi di
editoria e distribuzione.
!
Eʼ possibile consentire a ogni
utente del Web di essere allo
stesso tempo autore e
consumatore
Il Web 2.0 è un insieme di
applicazioni che realizzano
praticamente questa potenzialità Il termine che rende meglio lʼidea è
“partecipazione”: il Web 2.0 è
detto anche “Web partecipativo”
In unʼattività partecipativa nel Web (o più in generale in
internet) una comunità di persone, chiamata comunità
online (online community), utilizza unʼapplicazione
web(o più in generale internet) per comunicare e
interagire Il software utilizzato a questo scopo è spesso
denominato software sociale e può essere classificato
a seconda dei tipi di attività che consente di svolgere:
comunicazione: ad es. i forum
creazione e pubblicazione di contenuti: ad es. i blog e i wiki
condivisione di risorse: condivisione di testi, immagini etc. raccomandazioni: su alberghi, ristoranti etc.
networking sociale: luoghi dʼinterazione su internet
Attività collettive
Lʼinterazione fra i membri di una comunità online
costituisce una forma di partecipazione a
determinate attività collettive
A loro volta, le attività collettive che si svolgono
online possono far parte di un sistema di attività
collettive più ampio, che va oltre i confini di
internet
Ad esempio, il forum di un corso universitario fa
parte del sistema di tutte le attività pertinenti al
corso, che la maggior parte non sono online ma
in presenza
Il Web 2.0 può fornire un supporto diretto soltanto
alle attività collettive che si svolgono online
Adesione alla comunità online
Una comunità online può essere:
aperta senza registrazione: la partecipazione è libera,
senza bisogno di registrarsi possono essere comunque vietati gli interventi anonimi
esempio: i blog partecipativi
aperta con registrazione: la partecipazione è libera, ma
lʼutente deve registrarsi come membro della comunità
è possibile che lʼutente sia visibile agli altri membri della
comunità con un soprannome di sua scelta (nickname)
esempi: LinkedIn, FaceBook
chiusa: la partecipazione è limitata, ad esempio ai membri
di una determinata organizzazione (in genere occorre
comunque registrarsi)
esempio: un forum sulla piattaforma
eLearning@UniBG, riservato agli studenti iscritti a un
determinato corso Ruoli
Come ogni attività collettiva, anche le attività collettive online
prevedono diversi ruoli
I ruoli si possono caratterizzare in base ai diritti, agli obblighi
e ai divieti che competono agli utenti a seconda del loro ruolo
Diritti, obblighi e divieti vanno distinti in due categorie:
1. le azioni consentite, imposte o vietate direttamente dal
server dellʼapplicazione (le azioni che il server consente
di eseguire solo ad alcune categorie di utenti sono
spesso chiamate “privilegi”)
esempi:
qualunque membro di un forum può inserire un
messaggio nel forum, ma non può modificare o
cancellare i messaggi inseriti da altri membri
lʼamministratore di un forum può modificare o
cancellare qualsiasi messaggio
2. le azioni consentite, imposte o vietate da norme di
comportamento, la cui osservanza non è
direttamente garantita dal server dellʼapplicazione
ma è invece gestita dallʼintera comunità online o da
alcuni suoi membri
esempio:
ai membri di un forum è vietato utilizzare termini
ingiuriosi o aggressivi
La mancata osservanza di norme di comportamento può
portare a sanzioni
Esempio:
i membri di un forum che utilizzino termini ingiuriosi
o aggressivi possono essere sospesi o estromessi
dal forum da parte dellʼamministratore Blog
I blog (contrazione di Web log) sono nati come siti web
in cui rendere pubbliche le proprie opinioni su un
argomento di attualità
Inizialmente, quindi, i blog erano lʼequivalente nel Web
delle rubriche tenute da giornalisti sui periodici
Più recentemente i blog sono diventati partecipativi, nel
senso che a qualunque utente del Web è concesso
inserire commenti in un blog altrui
In un blog esistono quindi due ruoli:
autore: inserisce la maggior parte dei contenuti,
sotto forma di articoli che trattano argomenti di
attualità
lettore/commentatore: accede liberamente ai
contenuti del blog e può aggiungere i suoi commenti Wiki
“Wiki” deriva dallʼespressione hawaiana “wiki wiki”, che
significa “rapido”: il termine è stato introdotto da B. Leuf and
W. Cunningham (in The Wiki Way: Collaboration and Sharing
on the Internet, Addison-Wesley, 2001) per denotare un nuovo
tipo di siti web
Un wiki è un sito web partecipativo in cui:
le pagine possono essere create e modificate in qualsiasi
momento da qualunque membro della comunità
le pagine possono essere create e modificate facilmente e
rapidamente utilizzando un browser
viene mantenuta una storia delle modifiche subite da
ciascuna pagina
la struttura è fortemente ipertestuale (elevato numero di
link ad altre pagine del wiki e a risorse web esterne)
I wiki possono essere aperti (in genere con
registrazione) o chiusi
Il più celebre wiki aperto (in parte con
registrazione) è certamente Wikipedia,
lʼenciclopedia collaborativa multilingue che, nella
sua versione inglese, ha quasi raggiunto 3 milioni
e 800mila voci (ottobre 2011)
Lʼuso di wiki (in questo caso chiusi) è ormai
comune in molte organizzazioni, come strumento
di coordinamento e documentazione dei progetti
I wiki vengono anche utilizzati per documentare in
modo collettivo i prodotti software
Condivisione di risorse
Attualmente esistono numerosi sistemi per
condividere risorse allʼinterno di comunità online
aperte, ad esempio:
Raccomandazioni
Molti sistemi consentono di raccomandare non solo
risorse esistenti nel Web, ma anche luoghi, oggetti e
attività del mondo reale
Sistemi di raccomandazione sono ad esempio molto
comuni nei siti turistici
Le raccomandazioni (contenenti anche valutazioni
espressa su scale numeriche) sono inserite
spontaneamente dai clienti di ristoranti, alberghi e
così via
Esempi:
Networking sociale
Una rete sociale (social network) è unʼapplicazione web
che consente agli utenti di:
definire un proprio profilo (pubblico o riservato a certi
altri membri della rete, denominati “contatti” o “amici”)
decidere con quali altri membri entrare in contatto
navigare nella rete dei contatti di qualunque membro
accedendo ai profili
formare gruppi con altri membri della rete
raccomandare un membro per qualche tipo di attività
etc
Le reti sociali possono avere un taglio
professionale, come LinkedIn,
oppure informale, come Facebook e MySpace
Twitter è una combinazione fra un micro-blog e un sistema
di networking sociale
Il servizio, creato nel 2006, consente di inviare e leggere
brevi post detti “tweets”
I tweets compaiono sulla pagina contenente il profilo del
loro autore I tweets contengono al massimo 140 caratteri e tendono
quindi ad assomigliare ai messaggi SMS (una forma di
comunicazione già molto diffusa)
Twitter ha lanciato la moda di un nuovo tipo di tag: lo hashtag, per evidenziare nel tweet delle parole chiave
che ne costituiscono lʼargomento principale
Iʼm tweeting while Iʼm lecturing. #bad #teacher
Deb Roy
Deb Roy è un ricercatore del
M.I.T. (Massachusetts Institute
of Technology) che ha fondato
Blue Fin Labs, unʼazienda che
mira a fornire un servizio di
analisi dei gusti del pubblico
televisivo sulla base dei suoi
tweet durante la visione dei
programmi.
Tecnologie
Come abbiamo già detto, il Web 2.0 si basa largamente sulle
stesse tecnologie utilizzate per il Web 1.0 (internet, TCP/IP, http,
HTML, browser, motori di ricerca, ...)
Esistono però alcune tecnologie innovative, che assumono
notevole importanza almeno in alcuni tipi di applicazioni
Fra queste tecnologie ricordiamo:
XML (eXtensible Markup Language): uno standard W3C che
consente di definire nuovi linguaggi di marcatura, in funzione
delle diverse applicazioni dʼinteresse
AJAX (Asyncronous JavaScript And XML): un insieme di
tecnologie che consente di modificare degli elementi di una
pagina web senza dover ricaricare lʼintera pagina, rendendo
così più agile ed efficiente lʼinterazione fra il client e il server
di unʼapplicazione web
i servizi web (Web Service, WS): una tecnologia basata su
XML per rendere disponibili servizi sul Web