UNIVERSITÀ DEGLI STUDI DI ROMA
“LA SAPIENZA”
FACOLTÀ DI SCIENZE MATEMATICHE FISICHE E
NATURALI
TESI DI LAUREA IN FISICA
Un dispositivo VLSI neuromorfo con 128
neuroni e 3000 sinapsi: ottimizzazione dello
spazio su silicio e progetto
Relatori:
Tesi di Laurea di:
Prof. Daniel J. Amit
Elisabetta Chicca
Dott. Gaetano Salina
Matr. 11091162
Anno Accademico 1998-1999
A mia nonna
Indice
Introduzione
iv
1 Reti neuronali e VLSI neuromorfo
1.1
1.2
1.3
Le reti neuronali . . . . . . . . . . . . . . . . . . . . . . . . .
1
1.1.1
Evidenze sperimentali del modello ad attrattori . . . .
2
1.1.2
Il neurone lineare . . . . . . . . . . . . . . . . . . . . .
5
1.1.3
La struttura sinaptica e la dinamica della rete . . . . .
8
1.1.4
L’apprendimento stocastico . . . . . . . . . . . . . . . 14
1.1.5
Il comportamento collettivo . . . . . . . . . . . . . . . 17
VLSI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
1.2.1
I processi di fabbricazione . . . . . . . . . . . . . . . . 21
1.2.2
Il MOS . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
1.2.3
Gli effetti parassiti . . . . . . . . . . . . . . . . . . . . 34
1.2.4
La progettazione . . . . . . . . . . . . . . . . . . . . . 41
Reti e VLSI . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
2 Ottimizzazione della matrice sinaptica
2.1
1
45
L’algoritmo per la generazione della matrice sinaptica . . . . . 47
2.1.1
L’algoritmo modificato . . . . . . . . . . . . . . . . . . 48
i
2.2
Analisi e confronto dei due metodi di
ottimizzazione . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
2.2.1
Studio del comportamento della rete neuronale nel metodo
di ottimizzazione B . . . . . . . . . . . . . . . . . . . . 50
2.2.2
Ottimizzazione della matrice sinaptica tramite
accoppiamento di colonne complementari . . . . . . . . 52
3 I singoli elementi
3.1
3.2
3.3
57
I circuiti elementari . . . . . . . . . . . . . . . . . . . . . . . . 58
3.1.1
Lo specchio di corrente . . . . . . . . . . . . . . . . . . 58
3.1.2
L’invertitore . . . . . . . . . . . . . . . . . . . . . . . . 61
3.1.3
L’invertitore con doppia limitazione in corrente . . . . 63
3.1.4
L’amplificatore differenziale . . . . . . . . . . . . . . . 64
3.1.5
Il partitore capacitivo . . . . . . . . . . . . . . . . . . . 67
Il neurone . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 68
3.2.1
Lo schematico . . . . . . . . . . . . . . . . . . . . . . . 69
3.2.2
La frequenza di emissione degli spike . . . . . . . . . . 71
3.2.3
Il layout . . . . . . . . . . . . . . . . . . . . . . . . . . 73
La sinapsi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
3.3.1
Lo schematico . . . . . . . . . . . . . . . . . . . . . . . 78
3.3.2
Il layout . . . . . . . . . . . . . . . . . . . . . . . . . . 82
4 LANN128
85
4.1
La matrice sinaptica . . . . . . . . . . . . . . . . . . . . . . . 86
4.2
I neuroni . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93
4.3
Il routing delle correnti . . . . . . . . . . . . . . . . . . . . . . 97
ii
4.4
I/O . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 100
4.4.1
Alimentazioni e regolazioni . . . . . . . . . . . . . . . . 100
4.4.2
Spike . . . . . . . . . . . . . . . . . . . . . . . . . . . . 103
4.4.3
Potenziali . . . . . . . . . . . . . . . . . . . . . . . . . 104
4.4.4
Correnti esterne . . . . . . . . . . . . . . . . . . . . . . 106
5 Conclusioni
108
5.1
Il chip di test . . . . . . . . . . . . . . . . . . . . . . . . . . . 108
5.2
Risultati e prospettive . . . . . . . . . . . . . . . . . . . . . . 112
iii
Introduzione
Lo studio delle reti neuronali è mirato alla modellizzazione e riproduzione
delle funzionalità della corteccia cerebrale, tra le quali rivestono particolare importanza la classificazione ed il riconoscimento di immagini. Questo
campo di ricerca coinvolge diverse discipline scientifiche come la psicologia
cognitiva, la biologia, la scienza dell’informazione e la fisica.
I recenti progressi nelle teorie matematiche, nei metodi di indagine neurofisiologici e nelle tecnologie dei circuiti integrati hanno dato un forte impulso
allo sviluppo di questa disciplina, che si è definitivamente affermata nel campo della fisica grazie al lavoro di Hopfield del 1982. L’articolo pubblicato
in quell’anno [1] pone le basi per l’utilizzo della meccanica statistica, un
collaudato e potente strumento di indagine, nello studio delle reti neuronali,
introducendo le prime analogie tra queste e i sistemi disordinati a molti gradi
di libertà. In questo contesto nasce il concetto di attrattore, inteso come stato
di equilibrio stabile verso cui evolve la dinamica del sistema (Rete neuronale ad attrattori o ANN, dall’inglese Attractor Neural Network ). Il bacino di
attrazione è una “valle” di una “funzione paesaggio” in cui è contenuto il minimo che rappresenta l’attrattore. Per ogni condizione iniziale appartenente
a questa valle il sistema collassa nello stato di equilibrio definito dall’attrattore stesso. Un sistema di questo tipo è classificabile come una memoria
iv
indirizzabile per contenuto in cui l’attrattore rappresenta l’informazione memorizzata; quest’ultima può essere richiamata fornendo informazioni simili o
parziali [2].
Nello studio delle reti neuronali sta assumendo un ruolo sempre più importante la realizzazione di dispositivi neuromorfi [3] in grado di riprodurre i
comportamenti osservati nella biologia e previsti dai modelli teorici. Questo
approccio costituisce un efficace “banco di prova” per la verifica delle teorie
sviluppate in condizioni realistiche ed in tempo reale. Costruire questi dispositivi può inoltre fornire valide indicazioni sulla plausibilità biologica del
modello realizzato imponendo la ricerca di soluzioni agli inevitabili vincoli
realizzativi (contenimento dei consumi e dello spazio occupato, comunicazione tra i componenti della rete), già affrontati e risolti nel corso dell’evoluzione
naturale dei sistemi biologici. La realizzazione di una rete neuronale ad attrattori con apprendimento stocastico, oggetto del presente lavoro, si inserisce
proprio in questo ambito. Il dispositivo realizzato è una rete di 128 neuroni e
2926 sinapsi, in grado di creare i propri attrattori grazie alla dinamica delle
sue 1443 sinapsi plastiche a due stati stabili.
Il lavoro di progettazione è seguito ad una accurata analisi della topologia da realizzare finalizzata all’ottimizzazione dello spazio utilizzato. Usando
una rappresentazione semplificata della matrice sinaptica, contenente la sola
informazione relativa alla presenza o meno di una connessione tra due generici neuroni, e tenendo ben presente la struttura dei singoli elementi e le
strategie da utilizzare per le connessioni tra le celle elementari è stato ideato e
realizzato un algoritmo per la riduzione dello spazio occupato su silicio dalla
matrice sinaptica. In questo modo è stato possibile ridurre del 50% le dimen-
v
sioni del dispositivo garantendo un migliore sfruttamento del silicio utilizzato
e quindi, a parità di costo, la realizzazione di un numero maggiore di neuroni.
La descrizione del lavoro svolto si articola in cinque capitoli. Nel Capitolo 1
sono descritti gli esperimenti di neurofisiologia e le teorie alla base del modello
realizzato, la tecnologia a larga scala di integrazione (VLSI, Very Large Scale
Integration) e le caratteristiche del dispositivo elementare utilizzato (MOS,
Metal Oxide Semiconductor ). Nel Capitolo 2 viene affrontato il problema
dell’ottimizzazione dello spazio occupato dalla matrice sinaptica e descritto
l’algoritmo realizzato. Nel Capitolo 3, dopo aver introdotto i circuiti elementari utilizzati, sono descritti gli schemi elettrici degli elementi base della rete
neuronale: il neurone e la sinapsi. Nel Capitolo 4 è mostrata l’architettura
del circuito integrato realizzato. Il Capitolo 5 è riservato all’analisi del lavoro
svolto e delle prospettive aperte.
vi
Capitolo 1
Reti neuronali e VLSI
neuromorfo
1.1
Le reti neuronali
La corteccia cerebrale è la parte più esterna del cervello e la più recente
dal punto di vista evolutivo. Le reti neuronali nascono dall’idea di modellizzare e riprodurre alcune funzionalità della corteccia cerebrale, tra cui la
classificazione ed il riconoscimento di immagini. Questo campo di ricerca
si è sviluppato in un ambito multidisciplinare che comprende la psicologia
cognitiva, la biologia, la scienza dell’informazione e la fisica. Grazie ad una
forte analogia tra le reti neuronali ed i sistemi disordinati a molti gradi di
libertà, il modello sviluppato dalla fisica fa uso della meccanica statistica.
Un contributo fondamentale in questa direzione è stato dato dal lavoro di
Hopfield del 1982 [1] in cui viene introdotto il concetto di attrattore, inteso
come stato di equilibrio stabile verso cui la rete neuronale evolve. Il sistema
ha una probabilità molto bassa di uscire da questo stato. Introducendo una
1
“funzione paesaggio” in cui ogni attrattore è un punto di minimo di una superficie, si ha che per ogni condizione iniziale appartenente alla “valle” in cui
è contenuto il minimo (bacino di attrazione), il sistema collassa nello stesso
stato di equilibrio. Sotto questo punto di vista è possibile considerare la rete
come una memoria indirizzabile per contenuto in cui ogni stimolo “vicino”
all’attrattore richiama l’attrattore stesso, che rappresenta l’informazione memorizzata [2].
Nel paragrafo 1.1.1 sono descritte le evidenze sperimentali di carattere
neurofisiologico del modello ad attrattori. Viene poi introdotto (par. 1.1.2),
per quanto riguarda il comportamento della singola cellula neuronale, il modello del neurone esponenziale, fino ad arrivare al neurone lineare, che è
stato oggetto di realizzazione su circuito integrato in questo lavoro di tesi.
L’analisi del comportamento collettivo di una rete a neuroni lineari è stata
svolta da M. Mattia e la descrizione che ne viene riportata nel paragrafo
1.1.3 è tratta da [4], [5] e [6]. Dopo aver analizzato l’attività spontanea si
considera il meccanismo tramite cui la rete neuronale evolve verso una struttura in grado di richiamare delle memorie (apprendimento). Nel paragrafo
1.1.4 viene descritto il modello dell’apprendimento stocastico e nel successivo
(par. 1.1.5) si considera il comportamento collettivo previsto per una rete in
seguito all’apprendimento.
1.1.1
Evidenze sperimentali del modello ad attrattori
L’evidenza sperimentale della teoria delle reti neuronali ad attrattori si basa
sui risultati ottenuti in esperimenti di neurofisiologia. Il contributo maggiore
è stato dato dal lavoro del gruppo di ricerca di Miyashita ([7], [8] e [9]) tra la
2
fine degli anni ’80 e i primi ’90. In questi esperimenti una scimmia (Macaca
fuscata) viene addestrata a riconoscere delle immagini. Le figure utilizzate sono generate con un calcolatore tramite algoritmi frattali, per evitare
un’analisi semantica da parte della scimmia. Il compito che la scimmia deve
eseguire consiste in un “confronto ritardato con un campione” (delayed match to sample), cioè riconoscere se due immagini presentate in istanti diversi
sono uguali. In ogni prova lo stimolo campione e lo stimolo di confronto
sono presentati successivamente su uno schermo con un intervallo di circa
16 s. Entrambe le immagini persistono sullo schermo per 0, 2 s. Lo scopo
dello stimolo di confronto è quello di mantenere l’attenzione della scimmia
durante il delay.
Durante le prove si registrano i tempi di emissione degli impulsi di diverse cellule neuronali della corteccia prefrontale e inferotemporale. Queste
zone, infatti, risultano deputate alla memoria visiva in quanto la loro stimolazione nell’uomo provoca il richiamo di immagini. Inoltre, lesioni in questa
area inficiano il riconoscimento di un oggetto sia nell’uomo che nella scimmia. Si osservano diversi comportamenti dei neuroni esaminati (vedi figura
1.1) all’interno di un modulo corticale 1 . Una parte di questi mostra un
comportamento selettivo rispetto agli stimoli; alcuni emettono con frequenza
elevata in risposta ad un unico stimolo, altri reagiscono a più stimoli. Dopo
il periodo di addestramento ogni stimolo ha quindi una sua rappresentazione
interna, che si manifesta con una particolare distribuzione delle frequenze di
emissione delle cellule durante il periodo di ritardo.
1
La corteccia cerebrale dei primati può essere suddivisa in moduli di 1 mm2 di area,
con circa 105 neuroni tra i quali la probabilità di interazione è alta.
3
Figura 1.1: Registrazioni dell’attività dello stesso neurone in risposta alla presentazione di quattro stimoli diversi (a-d) (figura tratta da [9]). In ogni riquadro
sono riportati i rasters (tempi di emissione registrati su 12 prove per ognuna delle
quattro immagini) e gli istogrammi della densità degli impulsi (valore medio delle
misure ottenute sulle 12 prove) su intervalli di 80 ms. In ogni riquadro sono evidenziate le fasi dell’esperimento: allertamento (1 s), presentazione dell’immagine
campione (1 s), ritardo (4 s), e presentazione dell’immagine di confronto (1 s). La
risposta del neurone varia al variare dello stimolo: (a) il neurone è attivo durante
la prima fase di stimolazione e matiene una attività elevata anche nella fase di
ritardo; (b) questo stimolo campione non eccita il neurone, che però è attivo nella
fase di ritardo; (c) il neurone è eccitato dallo stimolo campione ma rilassa in attività spontanea nella fase di ritardo; (d) il neurone è inibito dallo stimolo campione
e si attiva durante la fase di ritardo.
Questa selettività è mantenuta anche variando la dimensione, l’orientamento
o il colore dell’immagine presentata. Inoltre, la stessa distribuzione di attività nel periodo di ritardo si osserva in risposta ad un insieme di immagini
ottenute sovrapponendo del rumore ad una delle immagini apprese [10]. Infine non si osservano attività selettive dopo la presentazione di immagini non
4
note. Queste osservazioni giustificano l’utilizzo del modello ad attrattori nella
descrizione del processo di riconoscimento degli stimoli. La fase di addestramento modifica l’efficacia delle connessioni sinaptiche in modo da permettere
ai neuroni di mantenere attività elevate in risposta alla presentazione dello
stimolo appreso. Inoltre l’esistenza di classi di stimoli che inducono la stessa
distribuzione di attività durante il ritardo, suggerisce la presenza di bacini
d’attrazione.
1.1.2
Il neurone lineare
Nonostante la sorprendente varietà strutturale osservabile nelle cellule nervose è sempre possibile riconoscere una struttura comune nei diversi tipi di
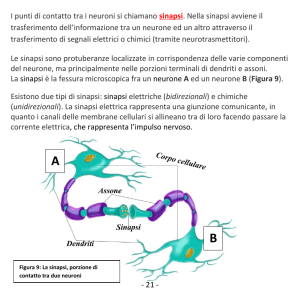
neuroni. Questa struttura è costituita dai seguenti elementi: il soma, le dendriti e l’assone (vedi fig. 1.2). Il soma è il “corpo cellulare” del neurone, e
cioè la parte in cui viene elaborata l’informazione in ingresso. Dal soma si
staccano diversi prolungamenti tra cui è possibile distinguere una parte di
ingresso, le dendriti, ed una di uscita, l’assone. Le dendriti che partono dal
soma si diramano diverse volte fino a formare una struttura ad albero detta
appunto albero dendritico. Lungo l’assone la cellula trasmette un segnale
elettrico (potenziale di azione) che è il risultato dell’elaborazione avvenuta
nel soma e che viene inviato alle dendriti di altre cellule tramite dei particolari contatti detti sinapsi. L’informazione in ingresso alla cellula è una
corrente (I) che viene “elaborata” dalla capacità della membrana cellulare. Il
risultato di questa elaborazione (V ) è la differenza tra il potenziale del fluido
extracellulare (Vext ) e quello del soma (VS ). Normalmente si prende come
riferimento Vext = 0, e il potenziale V = −VS viene detto depolarizzazione.
5
Guaina di mielina
Dendriti
Nodo di Ranvier
Assone
Nucleo all’interno
del corpo cellulare
Sinapsi
Figura 1.2: Struttura tipica di un neurone (figura tratta da [3]). Le sinapsi
degli altri neuroni si possono connettere alla cellula in diversi punti: su un albero
dendritico (1), direttamente sul soma (2), oppure su una dendrite (3). L’assone
è ricoperto da una guaina di materiale isolante (mielina) che riduce la capacità
verso il fluido extracellulare aumentando la velocità con cui il segnale si propaga.
Periodicamente si trovano delle interruzioni nello strato di mielina, dette nodi di
Ranvier, in cui il segnale viene rigenerato.
È quindi possibile descrivere il comportamento del neurone mediante l’introduzione delle due variabili dinamiche V ed I.
Quando la depolarizzazione raggiunge un valore di soglia (θ) si ha l’emissione del potenziale di azione, e cioè di un impulso (spike) che, trasmesso alle
altre cellule, ne modifica il potenziale di membrana di una quantità legata
all’efficacia del contatto sinaptico utilizzato. Dopo l’emissione dello spike il
potenziale di membrana decresce, subisce una iperpolarizzazione ed infine
torna al valore di riposo.
La dinamica del neurone, grazie ad opportune semplificazioni ([11] e [12])
6
può essere descritta dalla seguente equazione
τ
dV (t)
= V (t) + RI(t)
dt
(1.1)
τ = RC 10ms
in cui R è la resistenza efficace della membrana cellulare e C è la sua capacità.
La dinamica della depolarizzazione è dunque analoga a quella del potenziale
di un circuito RC integratore, nel nostro caso, però, va ricordato che quando
V raggiunge il valore di soglia θ il neurone genera un potenziale di azione, per
questo si parla di “neurone integra e spara” (integrate and fire). In assenza
di corrente afferente la depolarizzazione decade esponenzialmente, da cui il
termine neurone esponenziale. Questo modello è quindi riproducibile tramite
la realizzazione di un circuito elettrico, senza particolari difficoltà nel caso
di componenti discreti. Le dimensioni dei singoli elementi ed il consumo
dell’intero dispositivo
2
rendono però improponibile la realizzazione di reti
composte da centinaia di neuroni. Per questo motivo si ricorre all’utilizzo
della tecnologia dei circuiti integrati ed in particolare al VLSI (Very Large
Scale Integration). In questo caso, però, l’impiego di resistori risulta molto
dispendioso in termini di spazio occupato dal singolo elemento [14]. Allo
scopo di eliminare il termine resistivo nell’equazione 1.1 si esegue il limite
R → ∞, ottenendo
dV (t)
I(t)
=
dt
C
2
(1.2)
Come riferimento consideriamo un dispositivo realizzato dal gruppo nel quale è stato
svolto questo lavoro di tesi [13]. Una rete neuronale a componenti discreti con 27 neuroni
ad apprendimento stocastico consuma ∼ 400 W . Il neurone e la sinapsi occupano ciascuno
un’area di ∼ 10 cm2 .
7
Per compensare la mancanza del decadimento esponenziale si introduce nell’eq.ne 1.2 un decadimento lineare, ottenendo il neurone lineare di Mead
[3]:
dV (t)
I(t)
=
−β
dt
C
(1.3)
Il neurone esponenziale ha un limite inferiore nei valori che può assumere V ,
dato da V (t → ∞), per I = 0. Nel neurone lineare è necessario aggiungere
il vincolo per cui la depolarizzazione non può scendere al di sotto di un
certo valore, che in genere viene posto a zero. In questo lavoro di tesi è
stato realizzato su circuito integrato il modello del neurone lineare appena
descritto.
1.1.3
La struttura sinaptica e la dinamica della rete
Vogliamo ora inserire il modello del neurone lineare nel contesto di una rete
di neuroni. La corrente in ingresso al neurone i-simo è generata dagli impulsi
emessi dai suoi neuroni presinaptici ed è data dalla seguente espressione:
Ii (t) =
N
j=1
Jij
(k)
δ(t − tj − dij )
(1.4)
k
dove Jij è l’efficacia della connessione sinaptica che va dal neurone j al neuro(k)
ne i, N è il numero di neuroni nella rete, tj è il tempo in cui il neurone j-simo
ha emesso l’impulso k-simo e dij è il tempo necessario per la trasmissione dell’impulso (caratteristico di ogni sinapsi). Inserendo la 1.4 nella 1.3 (in cui,
per semplicità, è stato posto C = 13 ) la dinamica della depolarizzazione del
3
In questo modo la corrente viene definita come la variazione di potenziale nell’unità
di tempo.
8
neurone i-simo è data da
dVi (t)
(k)
Jij
δ(t − tj − dij )
= −βi +
dt
j=1
k
N
(1.5)
La rete che stiamo considerando deve rispettare i vincoli posti dalla plausibilità biologica ed elencati nei punti seguenti.
• I neuroni sono di due tipi: eccitatori (E) ed inibitori (I). Un neurone
eccitatorio (inibitorio) genera un impulso che produce un aumento (una
diminuzione) della depolarizzazione di tutti i suoi neuroni postsinaptici
(legge di Dale). Di questo si tiene conto imponendo J positiva (negativa) in caso di neurone presinaptico eccitatorio (inibitorio). I neuroni
inibitori sono circa il 20% del totale.
• All’interno di un modulo corticale la probabilità di connessione tra due
cellule è pari a circa il 10%.
• Ogni neurone ha ingressi sinaptici interni al modulo e provenienti dall’esterno in numero uguale. Le correnti provenienti dall’esterno sono
eccitatorie, infatti solo le cellule piramidali hanno assoni abbastanza
lunghi da poter raggiungere altri moduli.
• La probabilità che un neurone sia connesso direttamente con se stesso
è trascurabile (Jii = 0).
Consideriamo quindi una rete di N neuroni, in cui la probabilità che esista
una connessione da un neurone di tipo β verso un neurone di tipo α è data
da cαβ con α, β ∈ {E, I}. L’efficacia sinaptica di questa connessione è fissata
ad un valore scelto in modo casuale. Questo la rende una variabile aleatoria
9
quenched e la sua distribuzione di probabilità è data da
Pr {Jij ∈ [J, J + dJ]} = (1 − cαβ ) δ (J) + √
cαβ
2πJαβ ∆αβ
2
J−Jαβ )
(
−
2
e 2(Jαβ ∆αβ ) dJ
(1.6)
La probabilità che ci sia una connessione sinaptica tra il neurone j e il neurone
i (Jij = 0) è cαβ , il numero di connessioni verso neuroni di tipo α può essere
descritto da una variabile casuale binomiale con media cαβ Nα e deviazione
standard Nα cαβ (1 − cαβ ).
Ora che abbiamo definito tutte le caratteristiche del nostro sistema possiamo procedere verso la soluzione delle N equazioni accoppiate 1.5. Per
eliminare le δ di Dirac integriamo la nostra equazione:
Vi (t) = Vi (0) − βi t +
Nj (t) =
t
0
N
Jij Nj (t)
(1.7)
i=1
(k)
δ(τ − τj
− dij )dτ
k
dove Nj (t) è il numero di impulsi emessi dal neurone j-simo nell’intervallo
di tempo [0, t]. Grazie alla casualità presente nella struttura della rete, in
condizioni stazionarie, è possibile considerare il processo di emissione degli
impulsi come un processo stocastico di Poisson. Assumendo che i tempi
di emissione di diversi neuroni siano scorrelati la 1.7 è somma di processi
stocatici di Poisson indipendenti, e quindi un processo stocastico di Poisson
[15], [4], [6].
La depolarizzazione del neurone segue quindi un cammino aleatorio (random walk ) che può essere approssimato con un processo stocastico di Wiener,
se si assume che la corrente afferente (poissoniana) sia un processo stocastico
10
con distribuzione gaussiana. In questo modo abbiamo eliminato le discontinuità tipiche del random walk dall’andamento della Vi (t), che è ora descritto
dalla seguente equazione stocastica:
dVi (t) = µi (Vi (t)) + σi (Vi (t)) dW (t)
(1.8)
dove W (t) è un processo stocastico di Wiener con media e varianza infinitesimali, rispettivamente
E [Vi (t + ∆t) − Vi (t)|Vi (t) = x]
∆t→0
∆t
V
ar
[V
(t
+
∆t)
− Vi (t)|Vi (t) = x]
i
σi2 (x) = lim+
∆t→0
∆t
µi (x) =
lim+
(1.9)
(1.10)
Secondo l’equazione stocastica 1.8 la variazione di Vi (t) in un piccolo intervallo di tempo dt è una variabile casuale con distribuzione di probabilità
normale, con media µi (Vi (t)) e varianza σi2 (Vi (t)). Per valutare le espressioni 1.9 e 1.10 è necessario il calcolo di media e varianza della variazione del
potenziale (∆Vi (t)) in un intervallo di tempo ∆t:
N
Jij ∆Nj (t)
E[∆Vi (t)] = −βi ∆t + E
V ar[∆Vi (t)] = V ar
j=1
N
Jij ∆Nj (t)
j=1
dove ∆Nj (t) = Nj (t + ∆t) − Nj (t). L’indipendenza assunta precedentemente tra le emissioni degli impulsi garantisce che le variabili aleatorie Nj (t)
e Jij siano indipendenti [4], inoltre le efficacie sinaptiche sono tra di loro indipendenti (variabili aleatorie quenched ). In queste ipotesi è possibile
11
scrivere
E[∆Vi (t)] = −βi ∆t +
N
E[Jij ]E[∆Nj (t)]
j=1
V ar[∆Vi (t)] =
N
V ar[Jij ] V ar[∆Nj (t)] + E[∆Nj (t)]2 +
j=1
+V ar[∆Nj (t)]E[Jij ]2
Si ottengono, infine, le seguenti espressioni per µi e σi2 valide per qualunque
i ∈ α, con α ∈ {E, I}[4]:
µi = −βi + cαE JαE
(xνj + (1 − x) νEXT ) − cαI JαI
j∈E
2
1 + ∆2αE
σi2 = cαE JαE
νj
j∈I
(xνj + (1 − x) νEXT ) +
j∈E
2
1 + ∆2αE
+cαI JαI
νj
j∈I
dove x è la probabilità di avere una connessione eccitatoria interna al modulo,
νj è la frequenza di emissione del neurone j-simo del modulo e νEXT è la
frequenza media di emissione dei neuroni esterni al modulo, Jαβ è il valor
medio dell’efficacia sinaptica e (Jαβ ∆αβ )2 la sua varianza.
A questo punto si introduce l’approssimazione di campo medio in cui, per
N grande, ogni neurone riceve in media la stessa corrente. Si parla quindi
della frequenza media di emissione comune a tutti i neuroni eccitatori, νE , e
di quella dei neuroni inibitori νI . La dinamica è allora descritta dalle seguenti
equazioni:
12
dVα (t) = µα + σα dW (t)
∀α ∈ {E, I}
µα = −βα + cαE JαE NE (xνE + (1 − x) νEXT ) − cαI JαI NI νI
2
2
1 + ∆2αE NE (xνE + (1 − x) νEXT ) + cαI JαI
N I νI
σα2 = cαE JαE
(1.11)
(1.12)
(1.13)
In questo modo il sistema di N equazioni stocastiche accoppiate 1.8 è stato
ridotto ad un sistema di due equazioni differenziali stocastiche accoppiate
1.11. Le frequenze di emissione sono date dall’inverso del tempo medio che
impiega la depolarizzazione a raggiungere il valore della soglia per l’emissione
dello spike, e possono essere ora calcolate visto che conosciamo la dinamica
della depolarizzazione. Il tempo di primo passaggio T è definito come il
tempo necessario alla depolarizzazione per raggiungere il valore della soglia
θ partendo dal suo valore a riposo V (0) = 0. Il valor medio del tempo di
primo passaggio è dato da
σ 2 2µθ
− 2µθ
E [T ] = 2
+ e σ2 − 1
2µ
σ2
Conoscendo il tempo medio di primo passaggio in funzione del valor medio
µ e della varianza σ 2 della corrente afferente è possibile trattare il neurone
come un trasduttore corrente-frequenza, scrivendo la seguente funzione di
trasferimento
Φ (µ, σ) =
τARP
1
+ E [T ]
(1.14)
dove τARP viene detto periodo refrattario assoluto, ed è il tempo per cui
la dinamica rimane congelata a V (t) = 0 dopo l’emissione di un impulso.
13
Prendendo come riferimento per il potenziale il valore della soglia (θ = 1), e
per il tempo il periodo refrattario assoluto (τARP = 1), si ha
Φ (µ, σ) =
(µ + 1)
2µ2
σ2
2µ
+
σ2
2µ
e− σ2 − 1
(1.15)
Φ (µ, σ) può essere espressa in funzione delle frequenze sostituendo 1.12 e
1.13 in 1.15. In questo modo è possibile determinare le frequenze autoconsistenti della rete risolvendo graficamente un sistema di due equazioni in due
incognite:
νE = Φ (νE , νI )
ν = Φ (ν , ν )
I
E
I
Le soluzioni sono stabili quando i neuroni eccitatori si trovano in un regime di deriva negativa (µ ≤ 0) in cui il raggiungimento della soglia è dovuto
alle fluttuazioni (σ > 0). In fig. 1.3 è riportato un esempio di soluzione
grafica per le frequenze autoconsistenti nel caso di una rete eccitatoria.
1.1.4
L’apprendimento stocastico
Il meccanismo tramite cui si creano gli attrattori in una rete neuronale viene
detto apprendimento. Nella fase di apprendimento le connessioni sinaptiche vengono modificate in modo da ottenere, nel periodo di ritardo, attività
elevate nel sottoinsieme di neuroni che partecipano all’attrattore. Si cerca
quindi di modellizzare una dinamica della matrice sinaptica che, in risposta
agli stimoli, generi una rete strutturata in grado di richiamare le memorie
apprese. Secondo la regola di apprendimento di Hebb [16] la forza dell’accoppiamento tra due cellule neuronali dipende dalla loro attività. L’efficacia
delle sinapsi che connettono due neuroni con attività alta viene potenziata
14
200
20
♦
150
15
−1
Φ(s )
100
10
50
5
♦
0♦
0
5
0
0
50
100
ν (s−1 )
150
200
10
ν (s−1 )
15
20
Figura 1.3: (tratta da [4]). Esempio di soluzione grafica dell’ equazione di autoconsistenza nel caso di una rete di neuroni eccitatori ν = Φ(ν). La linea continua
rappresenta la Φ, la linea tratteggiata è la bisettrice del primo quadrante (ν). La
non linearità della Φ permette di avere più di una soluzione (♦) garantendo una
caratteristica fondamentale per una rete neuronale con due possibili regimi di attività (spontanea e selettiva). La figura a destra è l’ingrandimento di quella a
sinistra.
e vengono depotenziate le sinapsi che connettono due neuroni con attività
scorrelate. L’efficacia sinaptica rimane invariata nel caso in cui entrambi i
neuroni presentano attività bassa. Sono state sviluppate diverse teorie per
la modellizzazione dell’apprendimento, tutte basate sulla regola di Hebb.
Consideriamo una rete di neuroni eccitatori e rappresentiamo lo stimolo ξ come un vettore di dimensione N ad elementi binari: ξ ≡ {ξi }N
i=1 con
ξi ∈ {0, 1}. In questo schema si ha ξi = 1 se lo stimolo induce il neurone
i-simo ad emettere impulsi a frequenze elevate e ξi = 0 se il neurone i-simo
non è attivato dallo stimolo. Il livello di codifica f è definito come il numero
di 1 presenti in uno stimolo, mediato su tutti gli stimoli.
In questo lavoro di tesi è stato realizzato su circuito integrato il modello
dell’apprendimento stocastico di memorie a basso livello di codifica e sinapsi
15
a due stati stabili (J+ e J− ) [17], [18], [19]. Gli stimoli sono scelti in modo casuale e quindi le attività indotte sui neuroni sono scorrelate. Inoltre
le transizioni delle sinapsi sono dominate dalla stocasticità generata dalle
seguenti regole di transizione [18]:
• se Jij = J− e il nuovo stimolo attiva i neuroni collegati dalla sinapsi
(ξiµ = ξjµ = 1, dove ξ µ ≡ {ξiµ }N
i=1 è il µ-simo stimolo presentato alla
rete) allora si ha una transizione J− → J+ con probabilità q+ . Quindi la probabilità di potenziamento a causa della presentazione di uno
stimolo è f 2 q+ .
• Se Jij = J+ e lo stimolo impone due valori opposti ai neuroni collegati
dalla sinapsi, allora la probabilità di una transizione J+ → J− è q− (10)
per ξiµ = 1, ξjµ = 0 e q− (01) per ξiµ = 0, ξjµ = 1 (le probabilità di transizione q− (10) e q− (01) possono essere diverse 4 ). La probabilità totale
di depressione della sinapsi è f (1 − f )q− , con q− = q− (10) + q− (01).
• Una coppia di neuroni non attivati dallo stimolo lascia invariata la
corrispondente efficacia sinaptica.
Quando uno stimolo modifica un’efficacia sinaptica cancella parte delle memorie apprese in precedenza. Questo tipo di apprendimento genera una rete
con la proprietà del palinsesto: gli stimoli che eccedono la capacità della rete cancellano la memoria degli stimoli presentati più lontano nel tempo. Il
numero di stimoli che la rete può apprendere si determina quindi stabilendo qual’è la memoria più vecchia che la rete è in grado di richiamare. La
possibilità di richiamare una memoria è determinata dalla distribuzione delle
4
Questo è vero nel nostro caso essendo q− (10) = 0 (vedi par. 3.3).
16
depolarizzazioni tra i neuroni della rete in presenza di uno stimolo precedentemente appreso. Se questa distribuzione è tale che si possono distinguere i
neuroni attivati dallo stimolo da quelli non attivati il richiamo è, in linea di
principio, possibile [18]. Lo studio del rapporto segnale–rumore del campo
interno del singolo neurone permette di stabilire la correttezza di uno stimolo
richiamato, in questo modo si ottiene l’informazione che la capacità della rete cresce con il logaritmo del numero di neuroni [18]. Questo vincolo risulta
molto limitativo, ma è possibile renderlo meno stringente legando il livello di
codifica e le probabilità di transizione al numero di neuroni. Infatti, ponendo
f ∼ log N/N e q− = f q+ si ottiene [18]
2
N
pc = O
log N
in cui pc è la capacità critica della rete, e cioè il numero massimo di stimoli
che la rete è in grado di apprendere e richiamare senza errori.
1.1.5
Il comportamento collettivo
Ci interessa ora capire se la rete è in grado di sostenere attività dinamiche
differenti come quella selettiva e quella spontanea. L’analisi di questo argomento qui riportata è tratta da [20]. Formalizziamo la regola di Hebb per
l’apprendimento nella seguente schematizzazione:
• Se entrambi i neuroni non sono eccitati da nessuno stimolo la sinapsi non è coinvolta nell’apprendimento ed ha un valore preso da una
distribuzione gaussiana con media JEE e deviazione standard relativa
∆EE .
• Jij viene potenziata se i neuroni i-simo e j-simo sono eccitati dallo
17
stesso stimolo (ξi = ξj = 1). In questo caso l’efficacia sinaptica assume
un valore casuale preso da una distribuzione gaussiana con media J+ >
JEE e deviazione standard relativa ∆+ .
• Jij viene depressa nel caso di attività scorrelate dei due neuroni (ξi = ξj )
assumendo un valore casuale preso da una distribuzione gaussiana con
media J− < JEE e deviazione standard relativa ∆− .
Supponiamo che la rete abbia appreso p stimoli con le seguenti caratteristiche:
• ogni stimolo attiva la stessa percentuale f di neuroni eccitatori;
• gli stimoli non sono sovrapposti (non–overlapping stimuli), e cioè un
neurone può essere attivato da un unico stimolo.
Da questi vincoli deriva che la percentuale di neuroni eccitatori stimolati
deve essere minore di uno (f p < 1). Grazie a queste ipotesi la rete può
essere suddivisa in due sottopopolazioni, una costituita da pf N neuroni eccitati da uno degli p stimoli e l’altra costituita dai restanti (1 − pf )N neuroni
non attivati da alcuno stimolo. I neuroni selettivi ricevono f xCEE contatti
sinaptici5 da neuroni eccitatori della sottopopolazione attivata dallo stesso
stimolo e, per la regola di apprendimento descritta, tali sinapsi hanno efficacia di valore medio J+ . Per le connessioni con gli (p − 1)f xCEE neuroni
selettivi attivati da altri stimoli e quelle con i neuroni eccitatori non selettivi,
l’efficacia media è J− . Con un’analisi di campo medio si può valutare l’effetto
dell’apprendimento sull’attività spontanea per poi studiare la risposta della
rete alla stimolazione con uno dei prototipi appresi e verificare la possibilità
5
x è la frazione degli ingressi eccitatori provenienti dall’interno del modulo e CEE è il
numero di sinapsi tra neuroni eccitatori.
18
che esista l’attività selettiva anche dopo la rimozione dello stimolo. In primo luogo, quindi, occorre comprendere se dopo l’apprendimento esiste una
soluzione per le equazioni di autoconsistenza in cui tutti i neuroni selettivi
siano equivalenti, come i neuroni non selettivi, in termini di frequenze di
emissione e corrente afferente. Distinguiamo tre diverse sottopopolazioni: i
neuroni eccitatori selettivi, con frequenza media ν+ e corrente afferente con
media µ+ e deviazione standard σ+ , i neuroni eccitatori non selettivi, con
frequenza media ν0 e corrente afferente con media µ0 e deviazione standard
σ0 , i neuroni inibitori, con frequenza media νI e corrente afferente con media
µI e deviazione standard σI . Le frequenze stabili sono date dalle soluzioni
del sistema di tre equazioni accoppiate
ν = ΦE (µ+ , σ+ )
+
ν0 = ΦE (µ0 , σ0 )
νI = ΦI (µI , σI )
dove ΦE,I è la funzione di trasferimento, data dall’eq. 1.14 per neuroni eccitatori ed inibitori rispettivamente6 . Lo studio della stabilità delle soluzioni
[20] rivela la robustezza dell’attività spontanea in termini di stabilità nei confronti dell’apprendimento. Le frequenze di emissione mantengono comunque
una memoria della strutturazione della matrice sinaptica che ha luogo con
l’apprendimento mostrando un’aumento nel caso dei neuroni selettivi ed una
diminuzione per quelli non selettivi. Questa variazione non è comunque legata ad uno degli stimoli appresi in quanto i neuroni selettivi emettono tutti
con la stessa frequenza media, indipendentemente dallo stimolo che li ha attivati in fase di apprendimento.
6
Per le espressioni di µ+,0,I e σ+,0,I si rimanda a [20].
19
Consideriamo ora il caso in cui viene presentato e poi rimosso uno degli
stimoli appresi per verificare se la rete è in grado di sostenere una distribuzione di attività selettiva nel periodo successivo alla stimolazione. Si distinguono
quattro tipi di frequenze: νsel per i neuroni selettivi per lo stimolo presentato,
ν+ nel caso di neuroni selettivi per altri stimoli, ν0 per i neuroni non selettivi e νI per i neuroni inibitori. I punti fissi sono determinati dalle soluzioni
stabili del sistema di quattro equazioni accoppiate7
νsel = ΦE (µsel , σsel )
ν+ = ΦE (µ+ , σ+ )
ν0 = ΦE (µ0 , σ0 )
νI = ΦI (µI , σI )
Si ha solo il punto fisso stabile non selettivo fino a quando il rapporto J+ /JEE
è al di sotto di un valore di soglia. In questo caso il sistema rilassa nello stato
di attività spontanea quando viene rimosso lo stimolo. Se il potenziamento
dovuto all’apprendimento è tale che il rapporto J+ /JEE è maggiore del valore
di soglia si sviluppano in modo brusco p stati stabili in cui le sottopopolazioni di neuroni selettivi per un singolo prototipo presentano una frequenza
selettiva. Dopo la rimozione dello stimolo i neuroni selettivi per il prototipo
presentato hanno una frequenza di emissione νsel > ν+ .
7
Per le espressioni di µsel,+,0,I e σsel,+,0,I si rimanda a [20].
20
1.2
VLSI
I circuiti integrati (Integrated Circuit, IC) hanno rivoluzionato l’elettronica
rendendo possibili nuove applicazioni non realizzabili con circuiti a componenti discreti. L’integrazione permette infatti di costruire dispositivi miniaturizzati di grande complessità con costi ridotti grazie alla realizzazione
simultanea di più chip su un unico wafer di silicio cristallino. La sigla VLSI
(Very Large Scale Integration) si riferisce ad una classificazione in termini
di numero di dispositivi (> 105 componenti/IC), e rappresenta l’odierna
tecnologia costruttiva.
Uno dei dispositivi più usati è il transistor MIS (Metal Insulator Semiconductor ), in cui la corrente di canale è controllata da una tensione applicata
all’elettrodo di gate, che è separato dal canale tramite un sottile strato di
materiale isolante. Siccome la maggior parte di questi dispositivi sono realizzati in silicio, e utilizzano l’ossido di silicio come isolante per il gate, si usa
comunemente il termine MOS (Metal Oxide Semiconductor ). La realizzazione di MOS a canale n (p), nMOS (pMOS) richiede un substrato drogato con
impurezze di tipo p (n). Nella tecnologia CMOS (Complementary MOS) il
substrato è drogato p e quindi permette la realizzazione di nMOS, e per i
pMOS si utilizzano dei pozzetti drogati n (n-well ).
1.2.1
I processi di fabbricazione
La fabbricazione di circuiti integrati coinvolge numerosi processi quali la
“crescita” di cristalli di semiconduttore puro, il drogaggio, la realizzazione
dei contatti metallici, ecc. Il progresso della tecnologia dei dispositivi a stato
solido è legato anche al miglioramento della qualità dei materiali utilizzati e
21
dei processi costruttivi. Il semiconduttore deve essere disponibile in un unico
grande cristallo di purezza controllata. Il silicio, ad esempio, viene prodotto
con concentrazioni di impurezze inferiori ad una parte su 1010 [14]. L’alto
livello di purezza richiede un trattamento accurato del materiale in ogni passo
dell’intero processo.
La preparazione del substrato monocristallino è il primo passo comune a
tutte le tecnologie. Una tecnica diffusa consiste nel raffreddamento selettivo
del materiale fuso in modo da far avvenire la solidificazione lungo una particolare direzione cristallina. Cristalli di Ge e di GaAs sono in genere prodotti
con il metodo Bridgman orizzontale. Il materiale fuso, contenuto in un crogiolo, viene posto in una fornace ed estratto lentamente. Nel lato del crogiolo
che viene tirato verso l’esterno della fornace è posto un “seme” di cristallo. Se
la velocità di raffreddamento è ben controllata, e la posizione dell’interfaccia
tra materiale fuso e solido si sposta lentamente lungo il crogiolo gli atomi,
raffreddandosi, si dispongono nella struttura cristallina. Uno svantaggio di
questo metodo è dato dal contatto con le pareti del crogiolo, che introduce
“stress” durante la solidificazione e può causare deviazioni dalla struttura
cristallina.
Questo problema diviene particolarmente serio nel caso del silicio, che ha
un’alta temperatura di fusione (1415◦ C contro i 936◦ C del Ge e i 1238◦ C
del GaAs) e tende ad aderire al materiale delle pareti. Un metodo alternativo elimina questo problema estraendo il cristallo dal materiale fuso man
mano che solidifica. Nel metodo Czochralski un “seme” di cristallo viene
parzialmente immerso nel materiale fuso e poi sollevato lentamente, permettendo la crescita del cristallo attorno al “seme”. Generalmente durante
22
l’estrazione si applica anche una rotazione del cristallo per mediare eventuali
variazioni di temperatura all’interfaccia che potrebbero causare solidificazioni disomogenee. Questo metodo è utilizzato per silicio, germanio ed alcuni
composti.
Il cristallo ottenuto (detto anche lingotto) viene poi tagliato in wafer con
spessore di ∼ 200 ÷ 300µm tramite seghe di diamante. Una superficie del
wafer viene poi pulita e preparata per la lavorazione che realizza gli elementi
dei circuiti in ∼ 10µm di spessore.
La realizzazione dei vari dispositivi si ottiene tramite drogaggi selettivi
e crescita di ossido. Il drogaggio del semiconduttore si ottiene con diverse
tecniche, le più note sono la diffusione e l’impiantazione ionica.
Fino agli inizi degli anni ’70 la tecnica usata per drogare substrati di
semiconduttore era la diffusione. Anche prima della produzione dei circuiti
integrati questa tecnica veniva usata per la fabbricazione di transistor discreti. Tramite l’utilizzo di maschere, realizzate con ossido di silicio, si ottiene
il drogaggio di zone ben determinate. L’introduzione di impurezze nel silicio
avviene in un forno a temperatura di circa 1000◦ C, per un periodo di tempo
che va da 1 a 2 ore. Gli atomi del drogante (B, Al, Ge per drogaggio di tipo
p; P , As, Sb per un drogaggio di tipo n) procedono per diffusione in tutte le
direzioni all’interno del semiconduttore, e questo comporta la penetrazione
del drogante anche sotto la maschera. Fino all’integrazione su piccola scala (dimensioni tipiche del singolo transistor di 1 mm) la diffusione laterale
(dello stesso ordine della penetrazione del drogante, ∼ 1 µm) è irrilevante.
La diffusione laterale diviene un problema rilevante quando la larghezza della finestra (apertura nella maschera attraverso cui il drogante raggiunge il
23
substrato) è confrontabile con lo spessore di diffusione. Quando si è arrivati
a migliaia, decine di migliaia di dispositivi per cm2 le finestre sono diventate
di 1000 Å (1 Å= 10−10 m). A questo punto si sono rese necessarie tecniche
attuabili anche con finestre molto piccole, e processi di litografia sempre più
raffinati per realizzare le finestre. Sono quindi state messe a punto tecniche
di impiantazione ionica. In questo caso gli atomi hanno una velocità di deriva
e non più una velocità termica come nel caso precedente. Questa velocità è
loro impressa da un acceleratore lineare (E ∼ 20 ÷ 300keV ). L’impiantazione ionica viene eseguita a bassa temperatura, per cui le regioni drogate in
precedenza hanno minore tendenza ad allargarsi per diffusione termica.
Come già anticipato, l’ossido si silicio viene utilizzato come maschera per
realizzare drogaggi selettivi. Infatti le impurezze usate per drogare il Si
hanno un coefficiente di diffusione più basso nel SiO2 che nel Si. Inoltre il
SiO2 può essere facilmente rimosso dall’acido fluoridico (HF), che non reagisce con il sottostante strato di silicio. Per la crescita dell’ossido si può agire
in atmosfera secca o umida, in entrambi i casi il processo si svolge a circa
1000◦ C. Nella crescita in atmosfera umida l’ossidazione termica è ottenuta
in presenza di vapore acqueo, mentre nella crescita a secco si utilizza ossigeno puro. Dopo l’ossidazione si deve rimuovere selettivamente il SiO2 per
formare opportune aperture (le finestre) attraverso cui possono essere diffusi gli atomi del drogante. Il processo di fotolitografia consente, appunto,
di realizzare le finestre per il drogaggio. Il wafer viene ricoperto con una
pellicola di fotoresist (materiale fotosensibile) che viene poi esposta alla luce
ultravioletta attraverso una maschera. Se il fotoresist è positivo (negativo) la
regione esposta alla radiazione luminosa subisce una trasformazione chimica
24
Wafer di silicio
Fotoresist
SiO 2 - 1µm
Wafer di silicio
UV light
Maschera
Tracciato nella maschera
Fotoresist
SiO 2
Wafer di silicio
SiO 2
Wafer di silicio
Figura 1.4: (tratta da [21]). Schematizzazione dei passi necessari per la realizzazione di una finestra per il drogaggio. Al di sopra di uno spesso strato di ossido
viene depositato il fotoresist. Dopo l’esposizione alla luce UV l’etching permette
la rimozione del fotoresist e di una parte dell’ossido realizzando la finestra.
che ne permette (inibisce) l’asportazione tramite un apposito solvente. Con
l’etching si rimuove l’ossido di silicio non protetto dal fotoresist, realizzando
cosı̀ la finestra in cui eseguire il drogaggio. In figura 1.4 e 1.5 sono raffigurati rispettivamente la procedura per la realizzazione di una finestra e i passi
necessari per la creazione di una struttura CMOS.
Per formare le interconnessioni dei diversi componenti del circuito integrato
si utilizza il processo di metallizzazione, che consite nella deposizione di
25
Figura 1.5: (tratta da [22]). Descrizione del flusso di costruzione di una struttura
CMOS. Dopo la realizzazione di una n-well (a) viene fatto crescere l’ossido spesso
(b) per poi diffondere le impurezze attraverso le finestre realizzate nell’ossido (c).
Nella struttura finale (d) sono presenti il polisilicio per i contatti di gate e le
metallizazioni per le altre connessioni.
26
un sottile strato di alluminio, ottenuta per mezzo di evaporazione sotto una
campana ad alto vuoto. Le tecnologie più recenti permettono l’utilizzo di
diversi strati di metallizzazione (vedi fig. 1.6) grazie ai quali è possibile disegnare circuiti molto compatti.
nMOS
pMOS
MET3
source
MET3
drain
drain
MET2
MET2
gate
n+
MET1
source
CAP POLY1-POLY2
n+
MET1
gate
p+
p+
n-well
substrato p
Figura 1.6: Sezione del wafer con esempio di nMOS, pMOS e condensatore. Il
pMOS è realizzato all’interno di una n-well mentre le diffusioni per drain e source
dell’nMOS sono “immerse” nel substrato. Il condensatore è costituito dalla sovrapposizione di due strati di polisilicio. Per la realizzazione di circuiti compatti
riveste particolare importanza la possibilità di trasportare i segnale su diverse metallizzazioni a più livelli. In figura sono visibili le tre metallizzazioni, indicate con
M ET 1, M ET 2 e M ET 3, caratteristiche della tecnologia da noi utilizzata.
1.2.2
Il MOS
Questo paragrafo ha lo scopo di fornire una descrizione del funzionamento
del MOS tale da permettere di comprendere il comportamento dei circuiti
progettati in questo lavoro di tesi. Una descrizione più dettagliata è reperibile
27
in [21], [22], [23], [24].
Il MOS è un dispositivo a portatori maggioritari in cui la corrente nel
canale tra drain e source è modulata dalla tensione applicata al gate (vedi fig.
1.7). In un MOS di tipo n i portatori di carica sono elettroni ed una tensione
positiva (rispetto al substrato) applicata al gate provoca un aumento nel
numero di elettroni nel canale, aumentandone la conducibilità. Per tensioni
di gate al di sotto di un valore di soglia (Vt ) la corrente tra drain e source è
molto bassa (Ids ∼ 0). Il comportamento di un MOS di tipo p è analogo a
quello dell’nMOS, con la differenza che i portatori maggioritari sono lacune
e la tensione di gate è negativa rispetto al substrato. Descriviamo quindi il
comportamento dell’nMOS, da cui è facilmente deducibile quello del pMOS.
SiO2
Polisilicio
gate
drain
source
L
W
n+
n+
p
Figura 1.7: Struttura fisica di un transistor nMOS. Le due diffusioni n+ realizzate
nel substrato p costituiscono il source ed il drain. Il gate è in polisilicio ed è isolato
dal canale dal SiO2 .
28
La caratteristica dei transistor MOS viene comunemente divisa in tre
regioni (vedi fig. 1.8), distinte dai valori assunti dalle tensioni applicate ai
tre terminali del dispositivo.
• Regione sotto soglia o di cut-off : il flusso di corrente è essenzialmente
nullo per qualsiasi valore di Vds (tensione applicata tra drain e source),
poiché Vgs (tensione applicata tra gate e source) è minore della tensione
di soglia Vt .
• Regione lineare o ohmica: per Vgs > Vt e 0 < Vds < Vgs − Vt si ha
Vds2
(1.16)
Ids = β (Vgs − Vt ) Vds −
2
Il fattore di guadagno β, legato sia ai parametri del processo utilizzato
che alla geometria del dispositivo, è dato da
µε W
β=
tox L
in cui µ è la mobilità dei portatori nel canale, ε è la costante dielettrica
dell’ossido di gate e tox il suo spessore, W e L sono rispettivamente la
larghezza e la lunghezza del canale (vedi fig. 1.7). Questa regione è
detta lineare in quanto, per Vds Vgs − Vt , il termine quadratico nella
1.16 è trascurabile e si ha
Ids β (Vgs − Vt ) Vds
In questo caso il MOS ha un comportamento ohmico e la resistenza
equivalente tra drain e source è modulata dalla tensione Vgs .
• Regione di saturazione: per Vgs > Vt e 0 < Vgs − Vt < Vds il canale
è fortemente invertito e la corrente è idealmente indipendente dalla
29
tensione Vds :
Ids = β
(Vgs − Vt )2
2
(1.17)
Il MOS è quindi descrivibile come un generatore di corrente controllato
in tensione. In questa regione, però, si manifesta l’effetto di modulazione della lunghezza del canale, analogo all’effetto Early nei BJT [23].
Quando un MOS è nella regione di saturazione la lunghezza di canale diminuisce e va quindi aggiunto un fattore correttivo alla 1.17 che
diventa
Ids = β
(Vgs − Vt )2
(1 + λVds )
2
(1.18)
dove λ è un fattore empirico tipicamente compreso tra 0.02 V −1 e
0.005 V −1 [21].
Questa suddivisione trascura tutta la fenomenologia sotto soglia, considerando Ids = 0 per Vgs ≤ Vt . Ma è proprio questa regione che risulta per noi
molto interessante, dato che nelle nostre applicazioni è critico il problema
dei consumi (nella regione sotto soglia la potenza dissipata è dell’ordine dei
nW ). Prima di analizzare l’andamento della corrente di canale nella regione
sotto soglia riesaminiamo la caratteristica del MOS in modo più accurato.
Si possono definire due curve che indicano ognuna una transizione tra due
andamenti diversi della corrente di canale e definiscono quattro regioni. Andando da sinistra verso destra per ogni Vgs si osservano due andamenti di
Ids al variare di Vds . Inizialmente si ha una dipendenza approssimativamente
lineare, e aumentando Vds si arriva alla saturazione, che per i nostri fini va
definita in maniera più accurata. Nella regione di saturazione, a parte l’effetto Early, la corrente di canale è indipendente dalla tensione di drain, per
30
140
120
Vgs=1.0 V
Vgs=1.5 V
100
Vgs=2.0 V
Vgs=2.5 V
Vgs=3.0 V
Ids(µA)
80
60
40
20
0
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Vds(V)
7
6
5
Vgs=0.60 V
Vgs=0.65 V
Vgs=0.70 V
Vgs=0.75 V
Ids(nA)
4
3
2
1
0
0.0
0.5
1.0
1.5
2.0
2.5
3.0
Vds(V)
Figura 1.8: Caratteristica del MOS nella regione sopra soglia (grafico in alto)
e in quella sotto soglia (grafico in basso) ottenuta con una simulazione Spectre.
In entrambi i casi è possibile distinguere una zona a comportamento ohmico da
un zona di saturazione. In quest’ultima è visibile l’effetto Early, che si manifesta
con una leggera pendenza nella corrente tra drain e source che sarebbe altrimenti
costante. È inoltre possibile distinguere il diverso comportamento della corrente al
variare di Vgs nei due grafici, infatti nella regione sopra soglia si ha una dipendenza
lineare, mentre in quella sotto soglia l’andamento è esponenziale.
31
qualsiasi valore di Vgs . Muovendosi dal basso verso l’alto si incontrano due
diversi comportamenti della corrente di canale al variare della tensione applicata al gate. Nella regione sotto soglia Ids cresce esponenzialmente con Vgs ,
mentre sopra soglia l’andamento è quadratico.
Cerchiamo quindi di analizzare il comportamento della corrente di canale
nella regione sotto soglia [3]. Applicando una tensione Vds positiva si ha che
la barriera di potenziale φs tra il source ed il canale è minore della barriera di
potenziale φd tra il drain ed il canale, e quindi il numero di cariche in grado
di superare la barriera è maggiore nel caso di φs (vedi fig. 1.9).
Gate
tox
Source n+
Vs=0V
Drain n+
Vg=0V
Vg=1V
s
d
Vd=1V
x
L
0
Figura 1.9: Schema delle variazioni di potenziale in un nMOS. Per Vds positiva
la barriera di potenziale Φs tra source e gate è minore di quella tra drain e gate.
Si ha quindi un accumulo di cariche nel canale in prossimità del source che, per
diffusione, si muovono verso il drain.
32
La densità dei portatori di carica nel canale in prossimità del source sarà
maggiore di quella nelle vicinanze del drain, provocando un flusso di corrente
per diffusione dal source verso il drain. La densità di corrente per diffusione
è data da
Jdif f = qD
dN
dx
dove q è la carica dell’elettrone, N è la concentrazione degli elettroni e D è
la costante di diffusione; la concentrazione di elettroni è funzione della sola
direzione x (vedi figura 1.9). Per la relazione di Einstein si ha
D=
KT
µ
q
in cui K è la costante di Boltzmann, T è la temperatura espressa in Kelvin
e µ è la mobilità degli elettroni. La densità di portatori ai due estremi del
canale è data dalla legge di Boltzmann:
Ns = N0 e−q
Nd = N0 e−q
φ0 +(Vs −Vg )
KT
φ0 +(Vd −Vg )
KT
dove N0 è la densità dei portatori al livello di Fermi e φ0 è il potenziale
di contatto del diodo tra source (drain) e canale. Poiché tutti i portatori
generati in prossimità del source raggiungono il drain, la corrente è costante
al variare di x e il gradiente di concentrazione è dato da
qφ0
qVd
dN
Ns − Nd
N0 e− KT qVg − qVs
=
=
e KT e KT − e− KT
dx
L
L
33
La densità di corrente per unità di larghezza di canale è quindi
qφ0
qVd
N0 e− KT qVg − qV s
J = qD
e KT e KT − e− KT
L
Moltiplicando per la larghezza del canale W si ottiene l’espressione della
corrente che scorre tra drain e source
qV
qVd
g
s
Ids = I0 e qV
KT
e− KT − e− KT
0 W
I = qDN e− qφ
KT
0
0
L
In questa trattazione sono stati trascurati l’effetto Early e il fatto che
non tutta la tensione applicata sul gate si presenta al canale8 . Considerando
questi due effetti e ricordando che Vds = Vd − Vs si ha
qκVg
qVds
qV s
Vds
−
−
Ids = I0 e KT e KT 1 − e KT +
V0
dove tipicamente κ = 0.7 ÷ 0.9 e V0 è considerata costante fissato il processo
e la geometria del transistor considerato. Quando Vds kT /q la corrente
diventa indipendente da Vds (saturazione) a meno del termine lineare dovuto
all’effetto Early:
sat
Ids
1.2.3
= I0 e
qκVg
KT
s
− qV
KT
e
Vds
1+
V0
(1.19)
Gli effetti parassiti
La risposta dinamica di un circuito a MOS è fortemente dipendente dalle
capacità parassite presenti sui singoli dispositivi, dalle capacità di interconnessione sui metalli e sul silicio policristallino e dalle resistenze di transistor
e conduttori. È importante poter stimare l’entità di questi effetti parassiti
per valutare se le costanti di tempo introdotte siano trascurabili rispetto ai
8
Per una trattazione accurata si rimanda a [3].
34
tempi caratteristici dei segnali in gioco. Per questo riportiamo qui di seguito
una breve trattazione della caratterizzazione di resistenze e capacità parassite. Un altro problema da tenere sotto controllo nella fase di disegno del
layout (vedi par. 1.2.4) è il fenomeno del latch-up che viene qui descritto per
comprenderne le basi fisiche e le possibili “protezioni”.
Resistenza
Consideriamo uno strato uniforme di materiale conduttivo di resistività ρ,
spessore t, lunghezza l e larghezza w, la sua resistenza R (espressa in Ohm)
è data da
R=
ρ l
tw
Una volta fissato il processo utilizzato per la realizzazione del circuito integrato, la resistività ρ e lo spessore t sono fissati e noti, per cui si può riscrivere
l’espressione della resistenza come
R = Rs
l
w
dove Rs è la resistenza di un quadrato di lato qualunque (R = Rs per l = w),
detta sheet resistance. Nelle tabelle 1.1 e 1.2 sono riportati i valori delle sheet
resistance e delle resistenze di contatto nella tecnologia utilizzata nel nostro
caso.
35
Resistenza
Minima
Tipica
Massima
Unità
n-well
0.9
1.0
1.1
kΩ/
poly1
28
33
38
Ω/
diff. n
25
32
40
Ω/
diff. p
45
60
80
Ω/
MET1
100
150
mΩ/
MET2
100
150
mΩ/
MET3
40
70
mΩ/
Tabella 1.1: Valori della sheet resistance nella tecnologia AMS CMOS 0.6µm
tratti da un foglio tecnico di AMS.
Capacità
Le capacità parassite presenti in un circuito integrato sono:
• capacità di gate nei MOS;
• capacità di giunzione nei MOS, dovute alle giunzioni p-n presenti tra
le diffusioni di source e drain ed il substrato;
• capacità di routing 9 .
La capacità di gate dipende dalla regione di caratteristica in cui si trova il
MOS [21], e quindi dalla tensione applicata all’elettrodo di gate. Il valore
massimo di questa capacità, che può essere usato come stima conservativa, è
9
Questo termine (sbroglio in italiano) indica l’operazione di collegamento dei moduli
presenti nel circuito integrato.
36
Resistenza (Ω/cnt)
Tipica
Massima
MET1-ndiff
15
40
MET1-pdiff
30
80
MET1-poly1
10
20
MET1-MET2
0.5
1
MET2-MET3
0.5
1
Tabella 1.2: Valori della resistenza di contatto tra i vari layer nella tecnologia
AMS CMOS 0.6µm tratti da un foglio tecnico di AMS. I contatti hanno dimensioni
fisse (0.7µm × 0.7µm nella nostra tecnologia).
dato da
Cg =
ε
WL
tox
Le capacità presenti tra le diffusioni di source e drain ed il substrato possono essere modellizzate con l’espressione che descrive la generica capacità di
giunzione
Cj = Cj0
Vj
1−
V0
−m
dove Vj è la tensione applicata alla giunzione (negativa per polarizzazione
inversa), Cj0 è la capacità di giunzione per tensione applicata nulla, V0 è
il potenziale di contatto (∼ 0.6V ) ed m è una costante che dipende dalla
distribuzione delle impurezze nei pressi della giunzione e tipicamente vale
0.3 ÷ 0.5.
La modellizzazione delle capacità di routing è molto complessa (vedi [21])
ed un accurato trattamento teorico va oltre i nostri scopi. È comunque
necessario conoscere l’entità di questo fenomeno facendo riferimento ai dati
37
Capacità
MET1-MET2
MET1-MET3
MET2-MET3
Minima Tipica
Massima
0.041
0.053
0.086
f F/µm2
perimetro 0.045
0.051
0.063
f F/µm
area
0.020
0.027
0.043
f F/µm2
perimetro 0.042
0.046
0.054
f F/µm
area
0.040
0.053
0.086
f F/µm2
perimetro 0.050
0.055
0.064
f F/µm
area
Unità
Tabella 1.3: Valori delle capacità di routing nella tecnologia AMS CMOS 0.6 µm
tratti da un foglio tecnico di AMS.
forniti dalla fonderia per la tecnologia utilizzata. In tabella 1.3 sono riportati i
valori delle capacità di sovrapposizione (proporzionali all’area della superficie
di sovrapposizione) e di quelle di bordo (proporzionali al perimetro della
superficie di sovrapposizione).
Il latch-up
Il latch-up è un effetto parassita da tenere accuratamente sotto controllo in
quanto può portare al corto circuito delle due alimentazioni e quindi alla
distruzione del dispositivo [22], [21]. Nei primi dispositivi CMOS questo effetto risultava particolarmente critico, ma negli ultimi anni innovazioni nei
processi di fabbricazione e l’introduzione di tecniche di disegno collaudate
hanno notevolmente ridotto le possibilità di danneggiamento dei circuiti integrati. In figura 1.10(a) è possibile osservare come la realizzazione di una
n-well all’interno di un substrato di tipo p introduca dei BJT (Bipolar Junction Transistor, vedi [23]) parassiti.
38
Figura 1.10: (tratta da [21]). L’origine (a), la modellizzazione (b) e la caratteristica (c) del problema del latch-up. Il BJT pnp ha l’emettitore formato dalla
diffusione di source (p+ ) del MOS di tipo p, la base è formata dalla n-well ed
il collettore è il substrato p. L’emettitore del BJT npn è la diffusione di source
(n+ ) del MOS di tipo n, la base è il substrato p e il collettore è la n-well. Questi
transistor parassiti realizzano il circuito schematizzato in figura (b). Se la tensione
Vne dell’emettitore del BJT npn scende a −0.7 V il transistor entra in conduzione
innescando il feedback positivo che porta ad uno stato stabile in cui la corrente che
scorre nel circuito causa la fusione dei conduttori di alimentazione.
Nello schematico di fig. 1.10(b) viene mostrato il circuito realizzato dai BJT
e dalle resistenze parassite. Se a causa di un undershoot (abbassamento della tensione di massa) inizia a scorrere corrente nell’emettitore del transistor
npn, la tensione di emettitore diventa negativa rispetto alla base fino ad
39
avere una tensione base-emettitore di ∼ 0.7V . A questo punto il transistor
npn entra in conduzione e quindi scorre corrente nella resistenza Rwell . Si
ha cosı̀ un innalzamento della tensione base-emettitore del trasistor pnp, che
a sua volta entra in conduzione, innescando un feedback positivo che tende
ad aumentare la corrente Iramp (vedi fig. 1.10(c)). Per un certo valore della tensione base-emettitore del transistor npn, chiamato punto di trigger, la
tensione di emettitore torna bruscamente indietro e si ha uno stato stabile. La corrente che scorre nei conduttori che alimentano il circuito è tale da
causarne la fusione.
Per ridurre la probabilità di innesco del fenomeno del latch-up si deve
quindi cercare di minimizzare il valore delle resistenze Rwell e Rsubstrato e del
guadagno dei due transistor parassiti [23]. Sono state sviluppate tecnologie
resistenti al latch-up grazie all’aggiunta di un sottile strato fortemente drogato p+ sotto il substrato. In questo modo diminuisce il valore della resistenza
Rsubstrato e si genera un collettore che raccoglie tutte le correnti parassite circolanti nel substrato. Inoltre esistono delle regole di disegno collaudate che
garantiscono la prevenzione del latch-up e possono essere riassunte nei punti
seguenti:
• ogni well deve avere il proprio contatto di substrato connesso all’alimentazione direttamente con il metallo;
• i contatti di substrato devono essere più vicini possibile al contatto di
source dei MOS connessi alle alimentazioni, allo scopo di diminuire i
valori di Rwell e Rsubstrato ;
• è consigliabile mettere un contato di substrato ogni 5 ÷ 10 transistor,
una regola molto conservativa prevede un contatto per ogni transistor;
40
• l’utilizzo di guard-bar riduce la resistenza di substrato. Le guard-bar,
inoltre, si comportano come collettori per le correnti impedendo che
vengano iniettate correnti nelle basi dei transistor parassiti.
1.2.4
La progettazione
Esistono due tipi di approccio alla progettazione di circuiti integrati: bottomup e top-down. Nel primo si parte dall’elemento base, il transistor, realizzando sottocircuiti di crescente complessità interconnessi per realizzare le specifiche di progetto. Nell’approccio top-down, invece, si scompone in gruppi e
sottogruppi il livello più alto fino ad arrivare a delle celle base precedentemente disegnate e testate10 . Questo procedimento è particolarmente indicato
per la realizzazione di circuiti digitali, per cui esiste una vasta gamma di celle
di libreria. Nel nostro caso si è resa chiaramente necessaria una progettazione full-custom bottom-up, la quale richiede i passi descritti qui di seguito e
mostrati nel diagramma a blocchi in figura 1.11.
Definite le specifiche del sistema da realizzare si passa alla progettazione dello schematico. Si eseguono poi delle simulazioni per controllare che il
comportamento del circuito corrisponde a quello desiderato. A questo punto si può procedere verso la realizzazione del disegno del circuito integrato:
il layout. In questa fase vanno tenuti presenti i vincoli geometrici imposti
dalla tecnologia utilizzata. Un programma di controllo (DRC: Design Rule
Check ) permette di verificare che siano rispettati tutti i vincoli. Si utilizza
poi un altro programma (estrattore) per ottenere dal layout l’estrazione dei
parametri, l’identificazione dei dispositivi e dello schematico corrispondente
10
In genere si tratta di standard cells contenute nelle librerie fornite dalla fonderia stessa.
41
Definizione delle specifiche
Disegno dello schematico
Simulazione
NO
Accettabile?
SI
Disegno del layout
Estrazione
LVS
Simulazione con parassiti
NO
Accettabile?
SI
Produzione
Figura 1.11: Diagramma a blocchi relativo alle fasi di progettazione di un circuito
integrato.
al disegno realizzato. Questo consente di verificare la corrispondenza con lo
schematico precedentemente disegnato e simulato. La sigla LVS (Layout Ver42
sus Schematic) indica il programma che esegue questo compito. Nella fase
di estrazione è inoltre possibile aggiungere allo schematico ottenuto i componenti parassiti (vedi par. 1.2.3) per effettuare delle nuove simulazioni da
confrontare con quelle iniziali. Se il comportamento del circuito è fortemente modificato dalla presenza dei componenti parassiti è necessario rivedere
il disegno del layout allo scopo di minimizzare le deviazioni dalla risposta
desiderata. Un singolo errore nel progetto, nelle simulazioni o nel layout
generalmente rende il circuito integrato parzialmente o totalmente inutilizzabile. I programmi a disposizione rendono semplici e veloci diversi controlli,
ma la progettazione richiede comunque una grande cura dei particolari e
molta attenzione verso la struttura globale del dispositivo.
1.3
Reti e VLSI
Il compito della fisica nell’ambito della ricerca sulle reti neuronali è fondamentalmente quello di costruire dei modelli che, seppur basati su elementi
che costituiscono una semplificazione delle cellule nervose, siano in grado di
riprodurre gli stessi comportamenti presenti nella biologia. I modelli, sviluppati ed analizzati con studi teorici, vengono poi valutati attraverso simulazioni al calcolatore e realizzazioni elettroniche. Queste ultime presentano
diversi vantaggi rispetto alle simulazioni. Affrontare il problema dei vincoli
realizzativi (ad esempio necessità di limitare il consumo e le dimensioni dei
dispositivi) può fornire indicazioni sulla plausibilità biologica di scelte fatte
a priori. Inoltre, la realizzazione di un sistema reale introduce una enorme
quantità di variabili incontrollabili che consentono di valutare la robustezza
del modello in presenza di una aleatorietà non facilmente inseribile nelle si43
mulazioni. In questo contesto si è sviluppato, negli ultimi anni, il cosiddetto
hardware neuromorfo, in cui gli elementi costitutivi della rete riproducono i
comportamenti delle cellule biologiche [3].
Il presente lavoro di tesi è inserito in un progetto di ricerca che coinvolge la modellizzazione, la simulazione e la realizzazione di reti neuronali. Il
continuo riferimento ai lavori precedenti svolti nello stesso gruppo ha avuto
un ruolo fondamentale nel raggiungimento degli obiettivi prefissati. Per questo motivo è importante elencare brevemente i dispositivi precedentemente
prodotti. Dopo la realizzazione di una rete neuronale a componenti discreti
[13] (vedi par. 1.1.2) si è passati all’impiego della tecnologia VLSI sviluppando due chip [25] per testare le funzionalità degli elementi costitutivi della
rete: il neurone lineare di Mead [3], e la sinapsi precedentemente realizzata
a componenti discreti da Annunziato [26]. In seguito agli ottimi risultati
forniti dai primi test eseguiti su questi dispositivi è stato possibile realizzare
una rete neuronale su circuito integrato: la LANN21 [25](LANN, dall’inglese
Learning Attractor Neural Network, Rete Neuronale ad Attrattore con Apprendimento). La LANN21 è una rete di 21 neuroni, di cui 14 eccitatori e 7
inibitori, con connettività del 30% realizzata su un chip di 2.2 mm × 2.2 mm
in tecnologia CMOS 1.2 µm. I neuroni comunicano tra di loro attraverso
60 sinapsi plastiche (per le connessioni tra neuroni eccitatori) e 70 sinapsi
fisse. I test di questo dispositivo [27] hanno dimostrato la capacità della rete di sostenere un’attività spontanea in accordo con le previsioni di campo
medio, sia isolando i neuroni eccitatori che aggiungendo l’inibizione tramite
l’attivazione delle connessioni inibitorie.
44
Capitolo 2
Ottimizzazione della matrice
sinaptica
Le connessioni tra i neuroni di una rete vengono rappresentate attraverso la
matrice sinaptica. Una rete di N neuroni è descritta da una matrice N × N
il cui generico elemento Jij contiene il valore dell’efficacia della sinapsi tra
il neurone presinaptico j e quello postsinaptico i. Nella realizzazione su circuito integrato l’efficacia sinaptica è deteminata dalla dinamica della rete
e dalle impostazioni di alcune variabili dall’esterno (cfr. par. 3.3), mentre
la presenza o meno di una connessione tra due neuroni è fissata durante la
fase di progetto in quanto legata alla realizzazione di un circuito elettrico
tra i neuroni stessi. Le informazioni che a noi interessano per affrontare il
problema dell’ottimizzazione dello spazio utilizzato sono quindi la quantità
di connessioni e la loro posizione nella matrice. Una forma conveniente per
la nostra rappresentazione della matrice sinaptica è allora ad elementi binari, con Jij = 1 se esiste la connessione dal neurone j verso il neurone i e
Jij = 0 altrimenti. Se la rete è completamente connessa tutti gli elementi non
45
diagonali sono uguali ad uno. La plausibilità biologica impone però connettività abbastanza basse che possiamo immaginare di ottenere partendo dalla
matrice appena descritta e scegliendo in modo casuale elementi da azzerare
eliminando la corrispondente connessione sinaptica.
Nel nostro caso la connettività è del 18% e gli elementi nulli sono in
maggioranza. Riportare semplicemente la matrice sinaptica su chip significa
quindi lasciare un gran numero di spazi inutilizzati. Ciò è chiaramente comprensibile immaginando la matrice sinaptica come una scacchiera in cui ogni
quadrato nero rappresenta una sinapsi (Jij = 1), e quindi un’area occupata
da un circuito elettrico integrato, ed i quadrati bianchi sono associati alle
“non-sinapsi” (Jij = 0) ovvero aree prive di dispositivi. In una scacchiera
si alternano, su ogni riga (colonna), quadrati bianchi e neri, che sono quindi
presenti in numero uguale. Nella matrice sinaptica si ha una disposizione
casuale dei due tipi di quadrati, e quelli neri sono in minoranza dato che la
loro percentuale è rappresentata dalla connettività della rete. Riorganizzare la disposizione delle connessioni sinaptiche posizionando quadrati neri al
posto di quadrati bianchi è l’idea alla base della nostra ottimizzazione. In
questo modo, infatti, è possibile ridurre sia lo spazio inutilizzato che quello occupato dall’intera matrice sinaptica. Sono state realizzate, analizzate
e confrontate due diverse procedure di compressione della matrice sinaptica
indicate in seguito come metodo di ottimizzazione A e B. Il metodo A consiste nell’accoppiare tra di loro le colonne che hanno sinapsi su righe diverse,
lasciando inalterate le proprietà statistiche della matrice. Il metodo B provvede invece a generare gli accoppiamenti sinaptici in modo da poter sistemare
sulla stessa colonna le sinapsi provenienti da più neuroni. In questo modo il
46
risparmio di spazio è maggiore (vedi par. 2.1.1), ma si ha un inconveniente:
le proprietà statistiche della matrice sinaptica sono diverse da quelle contemplate nel modello teorico realizzato (vedi 1.1.3). Allo scopo di verificare
la possibilità di utilizzare una matrice sinaptica generata con il metodo B,
è stata compiuta un’analisi mirata a comprendere se le modifiche apportate
alle proprietà statistiche della matrice alterano il comportamento della rete
(vedi par. 2.2.1). Il risultato di questa prima analisi non ha permesso di
optare per questa soluzione, che potrà comunque essere analizzata in seguito
con uno studio teorico approfondito che va oltre lo scopo di questa tesi.
In questo capitolo viene presentato il metodo che ha portato alla definizione della topologia finale della matrice sinaptica realizzata su silicio.
Brevemente, sono comunque descritti e analizzati il metodo B ed i motivi
per cui non è stato utilizzato.
2.1
L’algoritmo per la generazione della matrice
sinaptica
Consideriamo la procedura utilizzata per definire la topologia della matrice
sinaptica di una rete neuronale con N neuroni e connettività C. Per ogni
elemento della matrice viene generato un numero casuale con distribuzione
uniforme nell’intervallo [0, 1[, se il numero ottenuto è minore di C l’elemento
conterrà una sinapsi, altrimenti no (ovviamente sono esclusi da questa procedura gli elementi diagonali, privi di sinapsi). Il risultato sarà caratterizzato
da una distribuzione binomiale per cui possiamo associare la presenza della
sinapsi al “successo”, il quale avrà quindi probabilità C. Se N è abbastan-
47
za grande, il numero di sinapsi per colonna (riga) segue una distribuzione
gaussiana con media
µ=C ·N
(2.1)
e deviazione standard
σ=
N · C · (1 − C)
(2.2)
Per la generazione dei numeri casuali con distribuzione uniforme è stata
utilizzata la funzione ran3 tratta da [28].
2.1.1
L’algoritmo modificato
Il metodo B consente di ridurre il numero di colonne da N ad N/F , generando una matrice sinaptica in cui su ogni colonna ci sono le sinapsi di F
neuroni diversi. Questo significa che gli F neuroni non possono avere sinapsi
sulla stessa riga, poiché la colonna generata è la sovrapposizione di F colonne “complementari”. Si ha quindi un vincolo che modifica la statistica del
numero di sinapsi sulle righe.
Per realizzare la matrice sinaptica viene modificato l’algoritmo appena
descritto. La probabilità di “successo” del nostro processo binomiale diviene
in questo caso F · C. Su ogni riga vengono eseguite N/F estrazioni, per cui,
indicando con µr e σr la media e la deviazione standard del numero di sinapsi
per riga, si ha
µr = F · C ·
σr =
N
=C ·N
F
N
· F · C · (1 − F · C) = N · C · (1 − F · C)
F
48
(2.3)
(2.4)
Fissata una colonna, ogni sinapsi viene assegnata ad uno degli F neuroni
appartenenti alla colonna con probabilità 1/F . Per ogni neurone si ha quindi
che la probabilità di avere una sinapsi sulla colonna è F · C · (1/F ) = C, il
numero medio di sinapsi per colonna è
µc = C · N
(2.5)
N · C · (1 − C)
(2.6)
e la deviazione standard
σc =
Questa procedura, rispetto a quella usuale, modifica la deviazione standard della distribuzione del numero di sinapsi sulle colonne.
Il metodo seguito per generare la matrice sinaptica è il seguente. Per ogni
elemento della matrice di dimensione N × (N/F ) viene generato un numero
nell’intervallo [0, 1[, se il numero è minore di CF viene assegnata una sinapsi
all’elemento in questione. Per ogni colonna, poi, è necessario assegnare le
sinapsi ai diversi neuroni. Si divide, quindi, l’intervallo [0, 1[ in F segmenti di
uguale lunghezza, e si assegna ogni segmento ad un neurone. L’appartenenza del numero estratto ad uno dei segmenti determina l’assegnazione della
sinapsi al neurone corrispondente.
49
2.2
Analisi e confronto dei due metodi di
ottimizzazione
2.2.1
Studio del comportamento della rete neuronale
nel metodo di ottimizzazione B
Per analizzare il comportamento della rete sono state eseguite delle simulazioni basate sul modello dei neuroni impulsivi con depolarizzazione lineare
[5], [4]. La plausibilità biologica della dinamica di una rete neuronale di questo tipo è stata verificata nei lavori di M. Mattia e S. Fusi, proprio nell’ottica
di una realizzazione in VLSI. Questo studio ha posto le basi per la realizzazione del modello su circuito integrato. Con il metodo di ottimizzazione
qui proposto, però, si pone il problema di applicare il modello stesso ad una
rete con caratteristiche diverse: la distribuzione di probabilità dell’efficacia
sinaptica 1.6 è ora valida solo lungo le colonne, ed è stata modificata per
quanto riguarda le righe. Le simulazioni eseguite avevano dunque lo scopo
di verificare se è possibile riprodurre la fenomenologia osservata nel caso in
cui la 1.6 è valida per tutta la matrice sinaptica. L’attenzione si è subito
concentrata sul parametro che meglio sintetizza il comportamento della rete:
la frequenza di emissione (vedi cap. 1). Le prime misure hanno coinvolto le
frequenze medie dei neuroni inibitori ed eccitatori in attività spontanea, confermando le previsioni del campo medio. Lo stesso risultato è stato ottenuto
ripetendo le misure nel caso di deriva negativa (vedi par. 1.1.3), situazione
in cui il processo di emissione potrebbe dipendere più sensibilmente dalla
variabilità nella connettività.
A questo punto è stata esaminata la stabilità della rete nel caso in cui
50
siano stati memorizzati 5 stimoli non sovrapposti. Nella configurazione simulata la rete collassa in uno degli attrattori senza aver ricevuto stimoli esterni
(vedi fig. 2.1). Questo non succede nel caso di una matrice non “modificata”,
la quale mantiene un’attività spontanea stabile in assenza di stimoli ed è in
grado di richiamare uno qualsiasi dei pattern appresi.
3RSROD]LRQH 3RSROD]LRQH 3RSROD]LRQH 3RSROD]LRQH ν +]
3RSROD]LRQH WPV
Figura 2.1: Risultati simulazione di una rete strutturata con 5 memorie, 6000
neuroni eccitatori e 1500 inibitori, C = 0, 1 e topologia definita dal metodo di
ottimizzazione B. Il grafico riporta le frequenze medie delle 5 popolazioni (gli
simoli non sono sovrapposti) relative alle 5 memorie. La rete viene stimolata per
0.5 s con la memoria 1 dopo un tempo di vita di 1s, e la durata della simulazione è
di 2, 5s. Si osserva che l’attività spontanea prima della stimolazione non è stabile
in quanto la popolazione 5 diviene attiva senza nessuna stimolazione esterna. La
rete risponde comunque allo stimolo presentato e mantiene attività selettiva anche
dopo la rimozione dello stimolo (con frequenza media di 29Hz).
51
2.2.2
Ottimizzazione della matrice sinaptica tramite
accoppiamento di colonne complementari
Nella realizzazione su circuito integrato il segnale di spike viene portato alle
sinapsi di tutta la colonna, che quindi rappresenta l’assone del neurone considerato. Lungo la riga si effettua la somma delle correnti afferenti al neurone
corrispondente, e quindi si riproduce l’albero dendritico. Allo scopo di ridurre lo spazio occupato dalla matrice sinaptica, si può pensare di posizionare
sulla stessa colonna le sinapsi relative a due diversi neuroni presinaptici.
Figura 2.2: Rappresentazione grafica delle colonne della matrice sinaptica: i quadrati colorati rappresentano le sinapsi, mentre quelli bianchi corrispondono ad elementi con Jij = 0. Nel metodo di ottimizzazione A due colonne “complementari”
(con sinapsi su righe diverse) vengono sostituite da un’unica colonna contenente
tutte le sinapsi. In questo modo si riduce di uno il numero di colonne della matrice.
Il numero di zeri eliminati è dato dal numero di zeri di una delle due colonne più
il numero di sinapsi dell’altra.
52
Colonne eliminate
Colonne eliminate
Numero di sequenze
Numero di sequenze
Figura 2.3: Andamento del numero di colonne eliminate in funzione del numero di
sequenze esaminate. Dopo una fase iniziale in cui si osserva un forte incremento nel
numero di colonne eliminate al crescere del numero di sequenze, si ha una situazione
di saturazione in cui il risultato della compressione non varia incrementando il
numero di sequenze.
Questo è possibile solo se i due neuroni non hanno in comune nessun neurone
postsinaptico (vedi fig.2.2). La procedura di ottimizzazione è stata realizzata
tramite un programma in linguaggio C che cerca le coppie di colonne complementari considerando la colonna i -sima e confrontandola con la colonna
j -sima (i = j; i, j = 1, ..., N ). Il risultato dell’ottimizzazione dipende dalla
sequenza dei valori assunti dai due indici i e j. Per questo motivo sono state
generate delle liste in cui sono presenti tutti i numeri interi da 1 ad N disposti
in ordine casuale. Ad ogni lista corrisponde una diversa sequenza dei valori
53
Figura 2.4: Istogramma della distribuzione del numero di colonne eliminate e
andamento del numero medio degli zeri presenti nella matrice. Come descritto nel
testo, all’aumentare del numero degli zeri aumenta il numero di colonne eliminate.
assunti dall’indice i o j. L’algoritmo realizzato sceglie il risultato migliore
dopo aver sperimentato diverse sequenze per entrambi gli indici.
Aumentando il numero di sequenze esaminate si osserva, inizialmente, un
aumento del numero di colonne eliminate, fino a raggiungere una situazione
di saturazione per cui l’ulteriore incremento del numero di sequenze non influisce più sul risultato (vedi fig. 2.3). L’efficacia dell’ottimizzazione dipende,
inoltre, dalla matrice di partenza. Anche questa dipendenza è stata presa in
esame allo scopo di comprendere le sue caratteristiche. L’ipotesi considerata
è che aumenti la probabilità di trovare colonne complementari se cresce la
quantità di zeri nella matrice. Dato che il numero di zeri segue una distribuzione gaussiana intorno al valore medio N 2 − N · (N − 1) · C = 13458, ci si
54
Figura 2.5: Nella seconda fase di ottimizzazione si uniscono le colonne con n
sinapsi nella stessa posizione. In questo modo si ottengono due colonne che devono
rimanere sempre affiancate, in quanto contengono sinapsi dello stesso neurone. La
colonna con n sinapsi viene poi unita ad una colonna “complementare”, ottendo
cosı̀ la riduzione di uno del numero di colonne.
aspetta un andamento gaussiano anche per il numero di colonne eliminate.
Nella fig. 2.4 è riportato il risultato ottenuto ottimizzando 300 matrici diverse, tutte con 128 neuroni e 18% di connettività. Con questo metodo si
ottiene, in media, l’eliminazione del 35,7% degli zeri, e quindi degli spazi
inutilizzati. Per migliorare questo risultato, sono state sovrapposte colonne
con un numero piccolo di sinapsi sulla stessa riga. Si parte da due colonne
con n sinapsi “sovrapposte” e si ottengono ancora due colonne di cui una
contiene, però, solo n sinapsi (vedi fig. 2.5). Trovare un accoppiamento per
la colonna con n sinapsi è molto probabile. È possibile, inoltre, ripetere questa procedura per differenti valori di n, fino ad ottenere la situazione con il
massimo numero di colonne con n sinapsi generate ed accoppiate. Si hanno,
55
però, casi in cui un neurone ha n sinapsi su una colonna e le restanti su
un’altra e per la realizzazione elettronica della matrice risulta necessario che
queste due colonne siano affiancate. La matrice viene quindi riordinata per
soddisfare questa richiesta.
Scelta della topologia della rete
La matrice scelta per la realizzazione su silicio ha un numero di zeri iniziale
pari al valore medio della distribuzione degli zeri (13458), che diminuisce a
8594 dopo la prima fase di ottimizzazione (eliminazione del 36% degli zeri).
Dopo la seconda fase di ottimizzazione il numero di colonne è stato ridotto
del 50% (su ogni colonna della matrice finale sono presenti le sinapsi di due
neuroni), ed è stato eliminato il 61% degli zeri. I 128 neuroni sono ripartiti
in 88 eccitatori e 40 inibitori. Per comodità di progetto nessun neurone
inibitorio ha sinapsi su due colonne diverse.
56
Capitolo 3
I singoli elementi
Questo capitolo ha lo scopo di introdurre i circuiti elementari che verranno
utilizzati negli elementi essenziali della nostra rete neuronale: il neurone e
la sinapsi. Sono inoltre descritti nel dettaglio sia lo schematico che il layout
di questi due dispositivi. Nelle figure che riportano i layout sarà usata la
corrispondenza tra colore e layer descritta in fig. 3.1. Una caratteristica
importante al livello di layout è data dalla cura posta nella prevenzione del
cross-talk 1 . A questo scopo si è cercato di sfruttare al meglio le tre metallizzazioni disponibili: i segnali viaggiano sul primo (M ET 1) e sull’ultimo
(M ET 3) strato di metallo, mentre lo strato centrale (M ET 2) è utilizzato
per le alimentazioni. È cosı̀ possibile “schermare” gli incroci tra i segnali
utilizzando, appunto, le alimentazioni. Inoltre tutte le connessioni interne
alla singola cella sono realizzate in M ET 1 e polisilicio, ed ogni cella è ricoperta da uno strato di M ET 2 per rendere possibile il passaggio dei segnali
su M ET 3 senza influenzare i dispositivi sottostanti. Il layout di ogni cella
1
Il cross-talk è un fenomeno dovuto all’accoppiamento capacitivo tra due conduttori
(cfr. par. 1.2.3) che può indurre distorsioni nei segnali.
57
è stato disegnato in modo che affiancando più celle sia per le alimentazioni
che per i segnali vengono generate automaticamente e senza interruzioni le
relative piste di metallo.
diffusione
contatto
polisilicio
VIA
polisilicio2
VIA2
MET1
ntap
MET2
ptap
MET3
righello
Figura 3.1: Definizione dei colori per i vari layer del layout. Il righello misura le
distanze in µm.
3.1
I circuiti elementari
3.1.1
Lo specchio di corrente
Gli ingressi in corrente del circuito integrato sono alimentati dall’esterno
tramite generatori che forniscono correnti entranti. Per ognuno di questi
ingressi si ha la necessità di ridurre l’intensità di corrente in modo da avere
58
grandezze gestibili dai dispositivi a dimensione minima utilizzati nella rete
neuronale. Lo specchio di corrente (current mirror ) [29] è un circuito molto
semplice utilizzato a questo scopo, che permette inoltre di riprodurre la stessa
corrente su più rami, propietà sfruttata per portare una regolazione a più
dispositivi. Qui di seguito analizziamo il comportamento dello specchio di
corrente per comprendere il suo utilizzo nel nostro circuito integrato. Lo
specchio di corrente riproduce in uscita la corrente di ingresso moltiplicata per
un fattore che dipende dalla geometria dei transistor utilizzati. In figura 3.2
sono mostrati gli schemi elettrici dei due tipi di specchi di corrente realizzati
con MOS: nMOS (fig. 3.2(a)) e pMOS (fig. 3.2(b)).
In
Out
Iin Iout
Q3
Q1
Q4
Q2
In
(a)
Iin Iout
Out
(b)
Figura 3.2: Schemi elettrici degli specchi di corrente realizzati con nMOS (a) e
pMOS (b). Lo scopo di questi circuiti è di riprodurre la corrente di ingresso nel
ramo di uscita. Se i due MOS sono identici, a meno di effetti parassiti, le due
correnti hanno la stessa intensità.
Nello specchio ad nMOS in fig. 3.2(a) la corrente in ingresso e quella in
uscita sono entranti nei MOS Q1 e Q2 rispettivamente. Nello specchio a
pMOS in fig. 3.2(b) la corrente in ingresso e quella in uscita sono uscenti
dai MOS Q3 e Q4 rispettivamente. Il MOS Q1 (Q3) in fig. 3.2 è detto
master in quanto è collegato al ramo in cui scorre la corrente di riferimento
59
ed il MOS Q2 (Q4) è detto slave essendo collegato al ramo in cui scorre la
copia della corrente in ingresso. Il master è connesso come diodo (Vgd = 0,
quindi il MOS è in saturazione) per cui la corrente che scorre nel ramo di
ingresso determina univocamente la tensione di gate del master, e quindi dello
slave. Il valore della corrente di uscita sarà uguale a quello della corrente in
ingresso fino a che lo slave lavora in regime di saturazione. L’intensità della
corrente specchiata è uguale a quella della corrente di riferimento solo se i
due MOS che costituiscono lo specchio sono identici, ed in condizioni ideali.
Consideriamo un caso più generale in cui i parametri legati alla tecnologia
sono identici ma la geometria è diversa. Possiamo scrivere le correnti di input
e output del circuito in figura 3.2(a) utilizzando l’eq.ne 1.18 per la corrente
tra drain e source del MOS in saturazione:
µε W2 (Vgs − Vt )2
Iout =
(1 + λVds2 )
tox L2
2
µε W1 (Vgs − Vt )2
(1 + λVds1 )
Iin =
tox L1
2
dove i pedici 1 e 2 si riferiscono rispettivamente ai MOS Q1 e Q2. Il rapporto
tra la corrente in uscita e quella in ingresso è quindi
Iout
=
Iin
W2
W1
L1
L2
1 + λVds2
1 + λVds1
In condizioni ideali (assenza di effetto Early) il rapporto delle correnti è
unitario per W2 /L2 = W1 /L1 .
Lo specchio può essere usato per generare più copie della stessa corrente
collegando diversi slave allo stesso master. Questa proprietà è stata sfruttata
per le regolazioni in corrente dei nostri circuiti: ognuna è presente su un
60
unico pin a cui è collegato un master ed n slave nel caso in cui n dispositivi
necessitano della stessa regolazione. Tutte le nostre regolazioni in corrente
entrano su specchi di tipo n con L1 = L2 = 1.8 µm che riducono la corrente
specchiata del fattore
W2
2.8 µm
=
= 71.4 · 10−3
W1
39.2 µm
Per tutte le regolazioni che scaricano gli elementi di memoria presenti sia nel
neurone che nella sinapsi, gli slave di questo specchio sono all’interno delle
celle che ricevono in input la corrente impostata. Se invece la regolazione deve
caricare la capacità di neurone o sinapsi va invertito il segno della corrente
uscente dallo specchio n con uno specchio di tipo p. Anche in questo caso,
per lo specchio p, si ha un master e tanti slave, ognuno all’interno del singolo
dispositivo che riceve la corrente.
3.1.2
L’invertitore
Congiungendo in serie due transistor MOS di tipo p ed n si realizza il blocco
funzionale detto invertitore logico [21] (vedi fig. 3.3), che fornisce in uscita
il segnale di ingresso negato2 . Per l’analisi dell’andamento della tensione di
uscita in funzione di quella in ingresso consideriamo il caso dell’invertitore
bilanciato. La condizione di bilanciamento (sempre soddisfatta dagli invertitori da noi realizzati) è verificata quando la fonderia garantisce che i MOS di
tipo p ed n hanno lo stesso valore per la tensione di soglia (Vt = Vtn = Vtp )
ed in fase di disegno del layout sono opportunamente fissate la larghezza
2
Nel trattare segnali digitali usiamo la convenzione che indica con 0 il valore basso del
potenziale (0 V ) e con 1 il valore alto (Vdd ). L’operazione di negazione fornisce in uscita
1 (0) se in ingresso si ha 0 (1).
61
Wn,p e la lunghezza Ln,p del gate dei due MOS in modo tale che in prima
approssimazione βn = βp .
Q1
In
Out
Q2
Figura 3.3: Schema elettrico dell’invertitore logico CMOS. Per VIn = 0 V il MOS
Q1 è chiuso mentre Q2 è aperto, quindi VOut ∼ Vdd . Per VIn = Vdd Q1 è aperto,
Q2 chiuso e VOut ∼ 0 V .
Ricordiamo che β è il fattore di guadagno del MOS introdotto nel par. 1.2.2
ed è dato da
βn,p
µn,p ε
=
tox
Wn,p
Ln,p
dove µ è la mobilità dei portatori di carica nel canale, ε è la costante dielettrica dell’ossido di gate e tox il suo spessore. Tipicamente µn ∼ 2µp per
cui il bilanciamento si ottiene ponendo Wp = 2Wn e Lp = Ln . Per Vin < Vt
Q1 è chiuso mentre Q2 è sotto soglia e quindi Vout ∼ Vdd . Analogamente per
Vin > Vdd − Vt Q2 è chiuso e Q1 è sotto soglia per cui Vout ∼ 0 V . Inoltre Q2
è saturo quando Vds2 > Vgs2 − Vt , e cioè
Vt < Vi < Vt + Vout
62
mentre Q1 è in saturazione quando Vsd1 > Vsg1 − Vt , e dunque
Vout − Vt < Vi < Vdd − Vt
L’invertitore CMOS è stato usato nel neurone (N 1 e N 2 in fig. 3.9 e N 1 in
fig. 3.8) e nella sinapsi (Q1 e Q2 in fig. 3.13).
3.1.3
L’invertitore con doppia limitazione in corrente
L’invertitore con doppia limitazione in corrente [25] è un circuito ottenuto
combinando un invertitore e due specchi di corrente.
Q1
biasp
Q2
Out
In
Q3
biasn
Q4
Figura 3.4: Schema elettrico dell’invertitore con doppia limitazione in corrente.
Se Vin = 0 V il pMOS Q2 è chiuso e l’nMOS Q3 è aperto, in uscita si ha la
corrente impostata sullo slave Q1 tramite biasp. Se Vin = Vdd il pMOS Q2 è
aperto e l’nMOS Q3 è chiuso, quindi la corrente di uscita è quella impostata da
biasn sullo slave Q4.
63
Inserendo lo slave di uno specchio di tipo p tra l’invertitore e l’alimentazione
e lo slave di uno specchio di tipo n tra l’invertitore e la massa si ottiene
l’invertitore con doppia limitazione in corrente mostrato in fig. 3.4. Questo
circuito è stato utilizzato nella sinapsi per effettuare il potenziamento o la
depressione della sua variabile analogica. L’invertitore con doppia limitazione
in corrente può essere infatti collegato ad un condensatore per iniettare o
sottrarre due correnti di diversa intensità. In questa configurazione si ha:
• per Vin ∼ 0 V il MOS Q2 conduce, mentre Q3 è aperto ed il condensatore viene caricato dalla corrente impostata su Q1 tramite la regolazione
biasp;
• per Vin ∼ Vdd il MOS Q3 conduce, mentre Q2 è aperto ed il condensatore viene scaricato dalla corrente impostata su Q4 tramite la regolazione
biasn.
3.1.4
L’amplificatore differenziale
L’amplificatore differenziale [3] è un dispositivo che genera una corrente di
uscita funzione della differnza tra due tensioni di ingresso e viene realizzato
tramite l’unione di due circuiti elementari: la coppia differenziale e lo specchio
di corrente. Lo schema elettrico della coppia differenziale è riportato in fig.
3.5. Il MOS Q3 è usato come sorgente di corrente controllata dalla tensione
di bias Vb . Il modo in cui la corrente che scorre in Q3 si suddivide tra i
MOS Q1 e Q2 dipende dalla differenza tra le due tensioni in ingresso V1 e V2 .
Consideriamo i transistor Q1 e Q2 in condizioni di saturazione sotto soglia,
64
V1
I1
I2
Q1
Q2
V2
Q3
Vb
Figura 3.5: Schema elettrico della coppia differenziale. La corrente che scorre nel
MOS Q3 è impostata tramite la tensione Vb e la suddivisione nelle correnti I1 e I2
dipende dalla differenza delle due tensioni in ingresso (V1 e V2 ).
per cui si ha (eq. 1.19)
κV1
− VV
T
(3.1)
κV2
− VV
T
(3.2)
I 1 = I 0 e VT
I2 = I 0 e V T
dove VT = kT /q è il potenziale termico. La corrente di bias risulta essere
− VV
Ib = I1 + I2 = I0 e
T
κV1
κV2
e VT + e VT
Risolvendo per la tensione V si ha
−V
e VT =
Ib
1
κV1
2
I0 e VT + e κV
VT
Sostituendo questa espressione in 3.1 e 3.2 si ottiene
κV1
I1 = Ib
e VT
κV1
κV2
e VT + e VT
κV2
I2 = I b
e VT
κV1
κV2
e VT + e VT
65
Se V1 −V2 è positivo e dell’ordine di qualche VT /κil MOS Q2 è aperto (I2 ∼ 0)
e I1 ∼ Ib . Viceversa se V2 − V1 è positivo e dell’ordine di qualche VT /κ, il
MOS Q1 è aperto (I1 ∼ 0) e I2 ∼ Ib . L’amplificatore differenziale utilizza
l’abbinamento tra la coppia differenziale e uno specchio per generare una
corrente di uscita uguale alla differenza tra le correnti di drain dei MOS Q1
e Q2, data da
I1 − I2 = Ib tanh
κ(V1 − V2 )
2VT
Nell’amplificatore differenziale rappresentato in fig. 3.6 la corrente I1 della
coppia differenziale (fig. 3.5) viene specchiata tramite i pMOS Q4 e Q5 e
sottratta alla corrente I2 (fig. 3.5) fornendo in uscita Iout = I1 − I2 .
Q4
Q5
Q1
V1
Vb
Q2
V2
Iout
Q3
Figura 3.6: L’amplificatore differenziale genera una corrente di uscita funzione della differenza delle tensioni in ingresso sfruttando le proprietà della coppia
differenziale (Q1, Q2 e Q3) e dello specchio di corrente (Q4 e Q5).
66
3.1.5
Il partitore capacitivo
Il partitore capacitivo [3] viene utilizzato nel modulo generatore di spike (vedi
par. 3.2) presente nel neurone. Consideriamo due condensatori in parallelo
con il nodo in comune alla tensione V0 (vedi fig. 3.7(a)). Indicando con Q la
carica totale presente sui due condensatori si ha
Q = V0 (C1 + C2 )
Se il secondo terminale di C2 viene bruscamente portato dalla tensione di
massa ad un valore ∆V (vedi fig. 3.7(b)), per la conservazione della carica
si ha
V0 (C1 + C2 ) = V C1 + (V − ∆V )C2
da cui si ottiene il valore della tensione V:
V = V0 + ∆V
V = V0
C1
C2
C1 + C2
V
C2
(3.3)
C2
∆V
C1
(b)
(a)
Figura 3.7: Partitore capacitivo. Inizialmente due condensatori sono in parallelo
con una tensione V0 applicata ai loro capi. Applicando una tensione ∆V tra la
massa e il condensatore C2 si ha, per la conservazione della carica, V = V0 +
C2
.
∆V C1+C2
67
3.2
Il neurone
Nel nostro circuito integrato il neurone è un elemento che deve svolgere le
seguenti funzioni:
• ricevere le correnti provenienti dalle sinapsi di altri neuroni ed integrarle
tramite la capacità di soma;
• confrontare la tensione di soma (Vsoma ) con una determinata tensione
di soglia e generare lo spike quando Vsoma raggiunge il potenziale di
soglia;
• riportare la tensione di soma al valore di reset dopo l’emissione dello
spike;
• generare un segnale digitale per comunicare alle sinapsi lo stato del
neurone stesso (cfr. par. 3.3).
La tensione Vsoma deve seguire la dinamica data dall’eq.ne 1.3, che integrata
fornisce la seguente espressione
1
Vsoma (t) = Vsoma (0) − βt +
C
t
I(t )dt
(3.4)
0
Dove I(t) è la somma della corrente esterna e della corrente proveniente dagli
altri neuroni della rete. La corrente esterna è sempre positiva (vedi par.
1.1.3), mentre per quella interna si hanno contributi positivi (provenienti dai
neuroni eccitatori) e negativi (provenienti dai neuroni inibitori).
68
3.2.1
Lo schematico
Lo schema elettrico del neurone [3], [25], riportato in fig. 3.9, è costituito da
vari moduli che realizzano le funzioni richieste e sopra elencate. Possiamo
quindi identificare quattro blocchi:
1. Modulo per l’iniezione delle correnti
Questo modulo è costituito dai transitor Q1 e Q2 che garantiscono l’interruzione della corrente in presenza di spike. Le correnti provenienti dalle sinapsi eccitatorie e dall’esterno caricano la capacità di soma
attraverso l’interruttore Q1, mentre le sinapsi inibitorie la scaricano
attraverso l’interruttore Q2.
2. Corrente di perdita
Il termine −βt dell’equazione 3.4 è realizzato tramite i transistor Q3 e
Q4. La corrente di perdita scorre solo in assenza di spike grazie all’interruttore Q4. Il transistor Q3 è lo slave di uno specchio di corrente.
Detta Iβ la corrente impostata tramite la regolazione beta (vedi fig.
3.9), il parametro β dell’equazione 3.4 è dato da
β=
Iβ
C1 + C2
Nella realizzazione dello schematico su layout le due capacità hanno i
seguenti valori:
• C1 = 377.3 f F
• C2 = 375.3 f F
3. Modulo generatore di spike
In assenza di spike (spk = 0) la corrente netta iniettata dal modulo
69
descritto nel punto 1 viene integrata dal parallelo delle capacità C1
e C2 . Quando la tensione Vsoma raggiunge il valore Vdd /2 si ha la
commutazione dei due invertitori N 1 e N 2 e la tensione spk passa da
0 V a Vdd . Applicando l’equazione del partitore capacitivo (3.3), si vede
che la tensione di soma passa bruscamente a
Vsoma =
Vdd
C2
+ Vdd
2
C1 + C2
Poiché spk = 1 l’interruttore Q6 è chiuso e permette alla corrente Ipulse
che scorre nello slave Q5 di scaricare le due capacità. La tensione Vsoma
inizia cosı̀ a scendere, e quando raggiunge il valore Vdd /2 si ha di nuovo
la commutazione dei due invertitori che riporta spk a 0. Applicando di
nuovo l’eq.ne 3.3 si ha, per il valore di reset del potenziale di soma
Vreset =
C2
Vdd
− Vdd
2
C1 + C2
La durata dello spike (tempo in cui spk = 1) dipende dalla velocità con
cui vengono scaricate le due capacità e può essere variata modificando
l’intensità della corrente Ipulse . L’intervallo tra due spike successivi è
funzione delle correnti Iecc , Iinib e Iβ .
4. Modulo generatore di stato
Le sinapsi plastiche tendono ad essere potenziate (depotenziate) se all’emissione di uno spike da parte del neurone presinaptico il neurone
postsinaptico presenta un potenziale al di sopra (sotto) del valore di
soglia3 Vref (vedi par. 3.3). Per “comunicare” lo stato di attività del
neurone postsinaptico viene generato un segnale digitale che è basso
3
La soglia viene impostata dall’esterno, solitamente a metà della dinamica di Vsoma
(Vdd /4).
70
(0 V ) per Vsoma > Vref e alto (Vdd ) se Vsoma < Vref . Il modulo generatore di stato (vedi fig. 3.8) è costituito da un comparatore seguito da
un invertitore.
Lo schematico del neurone differisce da quello realizzato in [25] per l’aggiunta
dell’interruttore Q4 che rende la durata dello spike indipendente dalla corrente di perdita Iβ .
Q1
Q2
N1
Vsoma
Q3
bias
Q4
stato_n
Vref
Q5
Figura 3.8: Schema elettrico del modulo generatore di stato. Il potenziale stato n
è un segnale digitale che vale 0 per Vsoma > Vref e 1 per Vsoma < Vref .
3.2.2
La frequenza di emissione degli spike
Ora che abbiamo descritto il funzionamento del neurone possiamo facilmente
calcolare i tempi caratteristici del segnale in uscita nel caso di corrente in
ingresso costante: l’intervallo tra l’emissione di due spike (∆T ) e la durata
dello spike (∆t). L’intervallo tra l’emissione di due spike è il tempo necessario
per passare da Vreset alla tensione di commutazione del primo invertitore:
∆T = Vdd
C2 C1 + C2
C2
= Vdd
C1 + C2 Iin − Iβ
Iin − Iβ
71
(3.5)
C2
Iecc
Q1
Vsoma
spk
N1
notspk
72
Iinib
Q2 beta
Q3
pulse
Q4
spk
spk
Q5
C1
notspk
N2
Q6
notspk
Figura 3.9: Schema elettrico del neurone. Si distinguono i seguenti blocchi funzionali: la capacità di soma, costituita dal
parallelo tra C1 e C2 ; il modulo per l’iniezione (Q1) e la sottrazione (Q2) della corrente afferente, eccitatoria ed inibitoria
rispettivamente; due MOS (Q3 e Q4) per realizzare la corrente di perdita e il modulo per l’emissione dello spike (Q5 e Q6,
N 1 e N 2, C2)
Dove Iin è la corrente netta proveniente dal modulo iniettore di corrente
descritto al punto 1 del par. 3.2.1. La durata dello spike è data da
∆t = Vdd
C2 C1 + C2
C2
= Vdd
C1 + C2 Ipulse
Ipulse
(3.6)
Vsoma è quindi un segnale periodico con periodo
T = ∆T + ∆t = Vdd C2
1
1
+
Iin − Iβ Ipulse
e frequenza
1
ν=
Vdd C2
1
1
+
Iin − Iβ Ipulse
−1
In figura 3.10 è possibile osservare la dinamica del neurone simulata con
Spectre di Cadence nel caso di corrente di ingresso costante.
3.2.3
Il layout
In figura 3.11 è riportato il layout del neurone. Le regolazioni arrivano al
neurone su piste di M ET 1 che viaggiano lungo ogni riga di neuroni e che
vengono portate all’interno della cella tramite ponticelli di polisilicio. Sul
M ET 3 si propagano i segnali spk e stato n (vedi fig. 3.8 e 3.9) diretti verso
la matrice sinaptica. Anche le correnti in ingresso al neurone viaggiano su
M ET 3 (vedi par. 4.8). Particolare cura è stata posta nel circondare completamente le due capacità con un guard-ring allo scopo di prevenire pericolosi
accumuli di carica.
73
3.5
3.0
2.5
2.0
3.5
1.5
∆t
1.0
3.0
0.5
Vsoma (V)
2.5
0.0
2.0
1.5
∆T
1.0
0.5
0.0
-0.5
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
t (s)
3.5
3.0
spk (V)
2.5
2.0
1.5
1.0
0.5
0.0
-0.5
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.20
0.25
0.30
0.35
t (s)
3.5
3.0
stato_n (V)
2.5
2.0
1.5
1.0
0.5
0.0
-0.5
0.00
0.05
0.10
0.15
t (s)
Figura 3.10: Simulazione Spectre della dinamica del neurone nel caso di corrente
di ingresso sul soma costante. Dall’alto verso il basso si possono osservare, nell’ordine, l’andamento del potenziale di soma, del segnale di spike e dello stato del
neurone (stato n). Nella prima figura sono evidenziati la durata dello spike ∆t
(eq.ne 3.6) e dell’intervallo tra due spike successivi ∆T (eq.ne 3.5).
74
Figura 3.11: Layout del neurone. Le piste gialle verticali rappresentano conduttori di M ET 3 che servono per portare il segnale di spike e lo stato del neurone
alla matrice sinaptica e per raccogliere le correnti afferenti. Le linee blu orizzontali
nella parte superiore sono, invece, conduttori di M ET 1, schermati con il M ET 2
dai segnali sovrastanti, che portano le regolazioni dall’esterno.
75
3.3
La sinapsi
Nel modello di apprendimento stocastico discusso in [30], [17] e [19] solo le
sinapsi che connettono due neuroni eccitatori sono plastiche mentre tutte le
altre hanno efficacia sinaptica fissa. Le sinapsi plastiche possono assumere
due valori di efficacia sinaptica (J+ e J− ) e le transizioni tra questi due stati
realizzano il seguente scenario:
1. Se entrambi i neuroni sono in uno stato di alta attività (elevata frequenza di emissione) la sinapsi tende ad essere potenziata. In questo
caso, quindi, se J = J+ non ci sono transizioni, mentre se J = J− si ha
la transizione J− → J+ con probabilità q+ .
2. Se J = J+ ed il neurone presinaptico è in stato di alta attività mentre
quello postsinaptico è in stato di bassa attività (bassa frequenza di
emissione), la transizione J+ → J− avviene con probabilità q− .
3. Se il neurone presinaptico è in stato di bassa attività non si hanno
transizioni qualunque sia lo stato neurone postsinaptico.
Per soddisfare queste richieste è stata utilizzata la strategia descritta in [26].
Lo stato della sinapsi è rappresentato da una variabile analogica (Vsin ) ed una
digitale (stato s). Vsin descrive la risposta su brevi scale di tempo (durata
spike) all’attività dei neuroni presinaptico e postsinaptico, determinando le
transizioni tra i due possibili valori della variabile digitale e quindi tra gli
stati di efficacia sinaptica potenziata (stato s = 0 per Vsin maggiore di un
76
Spike presinaptici
1
Variabile analogica Vsin
Vsoglia
0
Potenziale di soma del neurone postsinaptico Vsoma
1
Vref
0
0
50
100
150
Figura 3.12: Figura tratta da [31]. Simulazione della dinamica sinaptica: spike
del neurone presinaptico (in alto), evoluzione temporale della variabile analogica
della sinapasi (al centro) e potenziale di soma del neurone postsinaptico (in basso).
In corrispondenza dello spike Vsin riceve una “spinta” verso l’alto (il basso) se Vsoma
è maggiore (minore) del valore di soglia Vref (in [31] gli intervalli di dinamica di
neurone e sinapsi sono riscalati nell’intervallo [0, 1]).
valore di soglia fissato, in genere, al centro della dinamica del potenziale sinaptico) e depressa (stato s = 1 per Vsin minore del valore di soglia). La
sinapsi riceve in input il segnale spk del neurone presinaptico e lo stato n del
neurone postsinaptico (cfr. fig. 3.9). Lo spike del neurone presinaptico agisce
da “interruttore” per la dinamica: in assenza di emissione di impulsi presinaptici la probabilità di un cambiamento di stato della sinapsi è nulla. Ogni
spike emesso dal neurone presinaptico provoca una brusca variazione della
variabile analogica della sinapsi verso l’alto se stato n = 0 (Vsoma > Vref )
o verso il basso se stato n = 1 (Vsoma < Vref ). Se il potenziale sinaptico è
maggiore (minore) del valore di soglia, nell’intervallo tra due spike successi-
77
vi Vsin cresce (decresce) linearmente tendendo quindi a ripristinare il valore
stabile della sinapsi. Si ha un cambiamento della variabile digitale, e quindi
dell’efficacia sinaptica, solo se a causa delle fluttuazioni degli intervalli tra
spike presinaptici, una successione di spike riesce a spingere Vsin attraverso
la soglia prima che il refresh ripristini lo stato stabile (vedi fig. 3.12). La
scelta del segnale stato n, e quindi del livello del potenziale di soma, come
indicatore dello stato di attività del neurone postsinaptico si basa sul fatto
che un neurone in stato di bassa attività tende ad avere un potenziale mediamente vicino al valore di reset, mentre un neurone in alta attività tende
ad avere un potenziale mediamente vicino al valore per cui si ha l’emissione
dello spike.
L’elemento sinaptico, oltre a svolgere l’elaborazione delle attività dei neuroni per la generazione della dinamica tra i due stati di efficacia J+ e J− ,
ha la funzione di iniettore di corrente nella capacità del soma del neurone
postsinaptico. Nelle sinapsi non plastiche quest’ultima è ovviamente l’unica
funzione svolta.
3.3.1
Lo schematico
Anche per lo schema elettrico della sinapsi plastica ([26], [25]), riportato in
figura 3.13, possiamo fare una suddivisione in blocchi con funzioni distinte.
1. Elemento di memoria
La variabile analogica della sinapsi (Vsin ) viene tenuta in memoria
tramite un condensatore di capacità Cs = 372 f F .
2. Modulo generatore di stato
Tramite un comparatore (Q9, ..., Q13 in fig. 3.13) viene generato un
78
segnale digitale che rappresenta lo stato della sinapsi e viene inviato al
modulo di refresh (vedi punto 3) ed al modulo per l’iniezione della corrente (vedi punto 5). Se il potenziale del condensatore sinaptico è minore (maggiore) del potenziale di soglia (Vsoglia ) il segnale stato s è alto
(basso) e la sinapsi è depressa (potenziata). Infatti il valore di stato s
determina l’intensità della corrente iniettata (vedi punto 5) nel condensatore del neurone postsinaptico durante lo spike del presinaptico,
e quindi l’efficacia sinaptica.
3. Modulo di refresh
Quando il neurone presinaptico non emette spike la sinapsi deve mantenere lo stato raggiunto in seguito alle stimolazioni precedenti, questo
si ottiene con il modulo di refresh, costituito dai MOS Q14, Q15 e Q16.
Se la sinapsi è depressa il suo stato viene mantenuto grazie alla corrente Iref r n impostata nello slave Q14. Se invece la sinapsi è potenziata
(stato s = 0) alla corrente Iref r n si somma la corrente Iref r p che, caricando il condensatore, mantiene lo stato della sinapsi. Affinché l’effeto
delle due correnti di refresh sia simmetrico occorre che Iref r p sia di
intensità doppia rispetto a Iref r n .
4. Modulo hebbiano
Il modulo hebbiano è costituito da un invertitore con doppia limitazione
in corrente (transistor Q3, Q4, ..., Q8 in fig. 3.13). In presenza di uno
spike emesso dal neurone presinaptico i transistor Q3 e Q8 si chiudono. Se stato n è basso (potenziale del neurone postsinaptico maggiore
della tensione di soglia Vref ) Q5 è chiuso e Q6 aperto, quindi scorre la
corrente Ibiasp impostata tramite biasp sullo slave Q4. In questo caso
79
stato_s
Q1
Q9
Q10
Q3
Q2
biasp
Vsoglia
Q11
Q12
refr_p
Q4
bias
Q5
stato_n
Q14
Q13
Q15
Vsin
Q6
80
refr_n
spk
biasn
Q7
Q16
Cs
Q8
Figura 3.13: Schema elettrico della sinapsi. Il condensatore Cs rappresenta l’elemento di memoria. Il modulo hebbiano
è costituito dai MOS Q1, ..., Q8 tramite cui, in presenza di uno spike del neurone presinaptico, la capacità viene caricata
(scaricata) dalla corrente impostata sullo slave Q4 (Q7) se stato n è basso (alto). I MOS Q9, ..., Q13 servono per generare
la variabile digitale della sinapsi stato n. Il modulo di refresh è composto dai MOS Q14, Q15 e Q16.
il condensatore viene caricato e lo stato della sinapsi tende ad essere
potenziato. Se stato n è alto (potenziale del neurone postsinaptico
minore di Vref ) Q6 è chiuso e Q5 aperto. Il condensatore si scarica
attraverso la corrente Ibiasn impostata tramite biasn sullo slave Q7 e la
sinapsi tende verso lo stato depresso.
5. Modulo per l’iniezione della corrente
In figura 3.14 è riportato lo schema elettrico del circuito che realizza
l’iniezione della corrente nel neurone postsinaptico nel caso di sinapsi
plastiche. La corrente viene iniettata sul soma del neurone postsinaptico solo in presenza di uno spike del neurone presinaptico grazie
all’interruttore realizzato dal MOS Q1. Se stato s = 1 la corrente
scorre solamente nello slave Q4 (sinapsi depressa, efficacia sinaptica
J− = J); se stato s = 0 l’interruttore Q3 è chiuso e la corrente iniettata è data dalla somma delle correnti impostate sugli slave Q2 e Q4
tramite le regolazioni J e ∆J (sinapsi potenziata, efficacia sinaptica
J+ = J + ∆J).
Nel caso di sinapsi fisse si ha un solo valore possibile per la corrente iniettata
o assorbita e quindi sono sufficienti un interruttore e lo slave di uno specchio.
L’interruttore deve garantire che la corrente scorra solo in presenza di spike,
lo slave fa circolare la corrente impostata dal master. Questa struttura va
comunque differenziata per correnti inibitorie ed eccitatorie. Una corrente
eccitatoria deve caricare la capacità del soma e quindi fluisce attraverso lo
slave di uno specchio p. In questo caso anche il MOS utilizzato come interruttore è di tipo p, e per condurre solo in presenza di spike deve ricevere sul
gate il segnale spk negato. Nel circuito di fig. 3.15(a) che realizza questo
81
Q1
notspk
∆J
Q2
J
Q4
stato_s
Q3
Iecc
Figura 3.14: Le sinapsi plastiche iniettano corrente nei neuroni tramite il circuito
rappresentato in figura. Durante lo spike del neurone presinaptico il MOS Q1 è
chiuso e la capacità del neurone postsinaptico viene caricata con la corrente IJ
impostata sullo slave Q4 tramite la regolazione J. Se stato s è basso la sinapsi è potenziata ed alla corrente IJ si somma I∆J impostata sul MOS Q2 dalla
regolazione ∆J.
tipo di connessioni sinaptiche è quindi presente anche un invertitore che riceve in ingresso il segnale spk. La corrente inibitoria, invece, deve scaricare la
capacità di soma. Lo specchio e l’interruttore utilizzati sono in questo caso
di tipo n (vedi figura 3.15(b)).
3.3.2
Il layout
In figura 3.16 è riportato il layout di una sinapsi. Le regolazioni e lo spike del
neurone presinaptico giungono alla sinapsi attraverso il M ET 3, lungo tutta
la colonna (vedi par. 4.1). Lo stato del neurone postsinaptico e la corrente
che dalla sinapsi deve arrivare al neurone utilizzano il M ET 1 in direzione
orizzontale. Con l’ottimizzazione della matrice sinaptica (vedi cap. 2) abbia-
82
mo dimezzato il numero di colonne con un conseguente sbilanciamento tra i
due lati della matrice in caso di sinapsi quadrate. Per cercare di compensare
questo effetto4 la sinapsi è stata disegnata minimizzando la dimensione verticale, da qui la peculiare forma del condensatore visibile in figura 3.16.
Idendr
Q1
JxI
Q5
spk
Q6
Q3
spk
Q2
JIE
Q4
Idendr
(a)
(b)
Figura 3.15: Le sinapsi fisse sono costituite dal solo modulo per l’iniezione della
corrente. Le connessioni provenienti da neuroni eccitatori (a) devono caricare la
capacità del neurone postsinaptico durante lo spike del presinaptico. Il segnale
in uscita dall’invertitore costituito dai MOS Q1 e Q2 è connesso sul gate del
MOS Q3 per permettere il passaggio della corrente solo in presenza di spike. In
figura (b) è rappresentato un modulo iniettore di corrente relativo ad un neurone
presinaptico inibitorio. In questo caso la corrente impostata tramite la regolazione
JxI (x ∈ {E, I}) scarica la capacità del neurone postsinaptico quando Q6 conduce
(spk = 1).
4
Il disegno dell’intero circuito integrato deve rispettare il vincolo di un rapporto
massimo tra i due lati uguale a 2.
83
84
Figura 3.16: Layout della sinapsi. Le linee gialle (M ET 3) verticali servono per fornire le regolazioni alla sinapsi. Il conduttore di M ET 1 in alto (orizzontale) serve per comunicare alla sinapsi il valore del segnale stato n del neurone postsinaptico,
mentre sul conduttore in basso si raccoglie la corrente destinata al neurone postsinaptico.
Capitolo 4
LANN128
La rete di 128 neuroni, alla quale ci riferiremo nel seguito con la sigla
LANN128 (LANN, dall’inglese Learning Attractor Neural Network, Rete Neuronale ad Attrattore con Apprendimento), è stata realizzata in un chip di
8604.6 µm × 4915.8 µm in tecnologia 0.6 µm. Essa è composta da 88 neuroni
eccitatori, 40 inibitori e 2926 sinapsi ( connettività 18%) di cui 1443 plastiche. Come già detto nel par. 1.3 la realizzazione della LANN128 prende
spunto da lavori precedenti [25], [26], svolti nello stesso gruppo di ricerca,
che hanno portato allo sviluppo di una rete di 21 neuroni (LANN21). Un
tale incremento nel numero di neuroni ha imposto la scelta di una tecnologia
più spinta rispetto a quella precedentemente utilizzata. La vecchia tecnologia permetteva infatti l’utilizzo di due metallizzazioni con una dimensione
minima del gate di 1.2 µm e la realizzazione di un numero molto maggiore
di dispositivi (le dimensioni della matrice sinaptica crescono come N 2 , dove
N è il numero di neuroni della rete) è stata possibile grazie alla dimensione
minima di 0.6 µm e alle tre metallizzazioni della tecnologia utilizzata. Il
layout del neurone e della sinapsi è stato completamente ridisegnato cercan85
do di trovare il migliore compromesso tra l’ottimizzazione dello spazio e la
prevenzione del cross-talk.
4.1
La matrice sinaptica
La matrice sinaptica costituisce una rappresentazione delle connessioni esistenti tra i neuroni di una rete. Nel caso di N neuroni, di cui NE eccitatori ed
NI = N −NE inibitori, le connessioni sono descritte da una matrice quadrata
N × N il cui generico elemento ij rappresenta la sinapsi tra il neurone presinaptico j e quello postsinaptico i. In questo quadro la colonna rappresenta
l’assone del neurone mentre la riga il suo albero dendritico. Considerando
l’esistenza di due tipi di neuroni (eccitatori ed inibitori) si osservano quattro
possibili contatti sinaptici:
• eccitatorio–eccitatorio (E→E)
• eccitatorio–inibitorio (E→I)
• inibitorio–eccitatorio (I→E)
• inibitorio–inibitorio (I→I)
Riservando le prime NE colonne (righe) ai neuroni eccitatori questi quattro
diversi tipi di connessioni si ritrovano in quattro regioni distinte della matrice sinaptica (vedi fig. 4.1). Nella nostra realizzazione le uniche connessioni
plastiche sono quelle tra neuroni eccitatori (E→E), tutte le altre hanno efficacia sinaptica fissa ed il circuito che le realizza si riduce ad un semplice
iniettore di corrente (cfr. par. 3.3). Risulta cosı̀ evidente che gli elementi
con dimensioni maggiori si troveranno nella zona riservata alle connessioni
86
E→E, che definiscono quindi l’altezza delle prime NE righe e la larghezza
delle prime NE colonne.
NE NE+1
0
0
N
E→E
I→E
E→I
I→I
NE
NE+1
N
Figura 4.1: Rappresentazione schematica della matrice sinaptica di una rete con
N neuroni, di cui NE eccitatori ed NI = N −NE inibitori. I quattro riquadri (E→E,
I→E, E→I ed I→I) definiscono le zone destinate ai quattro tipi di connessioni.
Nella zona E→E si trovano le sinapsi plastiche e quindi gli elementi con dimensioni
maggiori (il singolo elemento è composto da 20 MOS ed un condensatore). Il layout
di queste celle è stato disegnato per primo definendo l’altezza degli elementi I→E e
la larghezza degli E→I. Questi elementi sono composti da un numero molto ridotto
di MOS (2 MOS per I→E e 4 MOS per E→I) e sono stati disegnati minimizzando
la dimensione non vincolata dalla cella E→E. Gli elementi I→I (costituiti da 2
MOS) sono stati disegnati per ultimi rispettando le dimensioni imposte dalle celle
E→I ed I→E.
87
In realtà, grazie alla compressione della matrice descritta nel cap. 2, nella
realizzazione su silicio le prime NE colonne della matrice sinaptica sono organizzate in NE /2 colonne (questo vale anche per le NI colonne relative ai
neuroni inibitori) e l’area di silicio utilizzata è la metà di quella necessaria
per la matrice non compressa. Gli elementi della zona I→E (E→I) in figura
4.1 hanno quindi un vincolo per la dimensione verticale (orizzontale), e per
ottimizzare lo spazio occupato è stata minimizzata la dimensione orizzontale
(verticale). I layout mostrati in figura 4.2 sono il risultato ottenuto seguendo questo criterio per la riduzione del silicio utilizzato. Le dimensioni degli
elementi della zona I→I sono determinate una volta fissate la larghezza delle
colonne in I→E e l’altezza delle righe in E→I. Lungo l’assone viene trasmesso
il segnale di spike, che deve essere quindi portato a tutti gli elementi della
colonna relativi allo stesso neurone. Sull’albero dendritico si raccolgono le
correnti provenienti dai neuroni presinaptici, nella nostra realizzazione questo
si traduce in un conduttore presente lungo la riga su cui vengono sommate
le correnti in accordo con la legge di Kirchhoff sui nodi.
Grazie all’ottimizzazione descritta nel cap. 2 su ogni colonna sono presenti le sinapsi connesse agli assoni di due diversi neuroni e quindi altrettanti
conduttori (MET3) che trasportano il segnale spk (vedi fig. 3.9) in uscita
dai due neuroni. Per portare le regolazioni si sfrutta il fatto che la sinapsi
è stata disegnata minimizzando la dimensione verticale a scapito di quella
orizzontale (vedi par. 3.3.2). Per questo su ogni colonna sono presenti piste di M ET 3 (schermate dagli elementi sottostanti tramite il M ET 2) che si
connettono ad ogni sinapsi portando le regolazioni. Sulla riga i-sima sono
disposte le sinapsi relative al neurone postsinaptico i, che ricevono quindi il
88
segnale stato n e inviano la corrente che si somma sul conduttore di M ET 1
presente lungo la riga. Tutto ciò è visibile nel layout di una zona della matrice sinaptica riportato in fig. 4.3.
Nelle regioni I→E, E→I e I→I mostrate in fig. 4.4 l’unica regolazione che
deve arrivare ad ogni elemento è l’efficacia sinaptica della zona considerata.
In queste zone, quindi, su ogni colonna sono presenti solo tre conduttori di
M ET 3: due per i segnali di spike e uno per l’efficacia sinaptica.
89
90
(a)
(b)
Figura 4.2: Layout delle dendriti E→I (a) ed I→E (b). La dendrite E→I è stata disegnata minimizzando l’altezza; la
larghezza è determinata dagli elementi E→E. Nella dendrite I→E, invece, è stata sfruttata la dimensione verticale (imposta
dall’altezza degli elementi E→E) riducendo quella orizzontale.
spike regolazioni spike regolazioni spike regolazioni spike regolazioni
stato
neurone
postsinaptico
corrente
91
Figura 4.3: Layout di una porzione della matrice sinaptica nella zona E→E. Le linee gialle verticali sono conduttori di
M ET 3. I primi due conduttori di ogni colonna trasportano il segnale di spike dei due neuroni presinaptici. Tutte le altre
piste servono per le regolazioni. Su ogni riga ci sono due conduttori di M ET 1 (linee blu), quello che si trova al di sopra
dell’elemento sinaptico trasporta lo stato del neurone postsinaptico, mentre quello che si trova al di sotto serve per raccogliere
e sommare le correnti provenienti da tutte le sinapsi della riga.
I→E
E→I
I→I
92
E→E
Figura 4.4: Layout di una porzione della matrice sinaptica in cui sono visibili tutti e quattro i tipi di connessione (E→E, in
alto a sinstra; I→E, in alto a destra; E→I, in basso a sinistra; I→I, in basso a destra). Solo i segnali di spike (vedi fig. 4.3) sono
disponibili lungo tutta la colonna, le regolazioni sono diverse per ogni regione. La maggior parte delle regolazioni riguardano
le sinapsi plastiche (zona E→E), per gli altri tipi di connessioni l’unica regolazione necessaria è l’efficacia sinaptica, diversa
per ogni zona.
4.2
I neuroni
Il layout del neurone ha una larghezza inferiore a quella del layout della
sinapsi di tipo E→E. Per le prime NE /2 colonne i due neuroni associati ad
ogni colonna sono stati posizionati sopra la colonna stessa. Come già detto,
però, le NI /2 colonne relative ai neuroni inibitori sono caratterizzate da una
larghezza inferiore rispetto alle precedenti, con un rapporto di
17.7 µm
60.7 µm
=
0.29. Disponendo tutte le coppie di neuroni affiancate si avrebbe una riga
di neuroni molto più larga della matrice sinaptica, che renderebbe inutile
l’ottimizzazione della matrice stessa.
Q1
Q3
Vin
Vout
Q2
Q4
(a)
(b)
Figura 4.5: Schematico (a) e layout (b) del buffer digitale.
93
Gli NI neuroni inibitori sono stati allora disposti in quattro righe ortogonali
alle due righe di neuroni eccitatori (vedi fig. 4.6).
Per evitare che il segnale di spike e lo stato del neurone si degradino a
causa delle capacità di carico, prima di inviarli alle sinapsi vengono mandati
a dei buffer digitali il cui layout e schematico sono riportati in figura 4.5.
In figura 4.7 sono descritti i risultati di una simulazione Spectre di Cadence
che mostra il comportamento di questo dispositivo con un segnale digitale in
ingresso.
94
neuroni
inibitori
neuroni
eccitatori
95
Figura 4.6: Layout dei neuroni. I neuroni inibitori sono stati disposti in quattro file ortogonali alle due righe di neuroni
eccitatori. Questa soluzione permette di avere una larghezza complessiva perfettamente compatibile con quella del layout
della matrice sinaptica (vedi fig. 4.9)
3.5
3.0
V (V)
2.5
2.0
3.5
1.5
3.0
1.0
2.5
0.5
2.0
0.0
1.5
-0.5
0
3.5
5
10
15
20
25
30
t (µs)
1.0
0.5
3.0
0.0
3.5
2.5
-0.5
3.0
1.5
2.5
1.0
2.0
V (V)
96
2.0
0.5
1.0
-0.5
0.5
10.000
10.005
20.000
20.005
20.010
Vin
1.5
0.0
9.995
19.995
Vout
10.010
0.0
-0.5
0
5
10
15
20
25
30
t (µs)
Figura 4.7: Simulazione Spectre del comportamento del buffer (vedi fig. 4.5). Nei due grafici centrali è riportato l’andamento
della tensione di ingresso (in alto) e di quella in uscita (in basso) dal buffer con un carico capacitivo di 2 pF in parallelo ad
un carico resistivo di 100 kΩ. Nei due ingrandimenti laterali è mostrato nel dettaglio il comportamento del dispositivo in
fase di commutazione. Il ritardo osservato (∼ 5 ns) non è rilevante se confrontato con i tempi caratteristici dei nostri segnali
(ad esempio un valore tipico per la durata dello spike è di 50 µs).
4.3
Il routing delle correnti
Il routing, in italiano sbroglio, è l’operazione con cui si disegnano le connessioni tra le celle elementari, o in generale tra diversi blocchi funzionali. Nel
nostro caso indichiamo con il routing delle correnti il disegno di tutti i conduttori necessari per portare le correnti dalla matrice sinaptica ai neuroni.
88
E
I
Neuroni
E→E
I→E
E→I
I→I
88
40
40
Matrice sinaptica
Figura 4.8: Rappresentazione schematica dei quattro gruppi di conduttori che
devono realizzare le connessioni per le correnti.
Nelle quattro zone della matrice descritte in figura 4.1 si raccolgono, su
97
ogni riga, le correnti destinate ai neuroni. Abbiamo, quindi, in uscita dalla
matrice sinaptica quattro gruppi di conduttori (un gruppo per ogni tipo di
connessione) che devono essere portati verso i neuroni sfruttando i due metalli disponibili per il trasporto dei segnali (M ET 1 e M ET 3). In figura 4.8 sono
mostrate schematicamente le connessioni che devono essere realizzate tra la
matrice sinaptica ed i neuroni. Gli inevitabili “incroci” tra correnti distinte
devono ovviamente avvenire su metalli diversi, e sono quindi realizzati con
M ET 1 e M ET 3, sempre schermati dalle alimentazioni su M ET 2. Per ridurre lo spazio occupato dal routing sono stati sovrapposti i conduttori per le
correnti inibitorie destinate ai neuroni inibitori e quelli per le correnti inibitorie destinate ai neuroni eccitatori (vedi fig. 4.9). I conduttori per le correnti
E→I, I→E ed I→I passano lateralmente alla matrice sinaptica, mentre per
le correnti E→E è stato possibile sfruttare lo spazio presente sopra le sinapsi
utilizzando il M ET 3 come per le regolazioni. I conduttori per le regolazioni,
però, sono presenti lungo tutta la colonna E→E (proprio perché devono raggiungere tutte le sinapsi), mentre quelli per le correnti E→E partono dalla
riga relativa al neurone postsinaptico considerato, dove si connettono al conduttore di M ET 1 che somma le correnti provenienti dalle sinapsi della riga
stessa.
98
matrice
sinaptica
buffer
digitali
neuroni
40
E→E
I→I
I→E
99
E→I
88
40
Figura 4.9: In questa immagine del layout sono visibili i conduttori che realizzano il trasporto delle correnti dalla matrice
sinaptica ai neuroni.
4.4
I/O
L’interfaccia tra il chip ed il mondo esterno è realizzata tramite delle strutture
composte da un pad
1
e da una circuiteria di protezione. Con il termine PAD
indichiamo il generico elemento di I/O, costituito da un pad e la relativa
circuiteria di protezione. Nella LANN128 sono stati usati esclusivamente
PAD di libreria forniti da AMS. Nell’I/O del nostro chip sono compresi
segnali digitali ed analogici. Nel corso di questo paragrafo vengono descritti
qualitativamente ed anche quantitativamente questi segnali.
4.4.1
Alimentazioni e regolazioni
Alle alimentazioni sono stati riservati 36 pin, suddivisi in 14 per alimentazioni
digitali, destinate ai multiplexer (vedi 4.4.2) ed ai PAD di I/O digitale, e 22
per quelle analogiche, destinate a tutto il resto del chip. Per le regolazioni dei
neuroni e della matrice sinaptica sono necessari 16 pin analogici di ingresso:
• Neuroni
1. Beta neuroni eccitatori.
Regolazione in corrente per il termine β nella dinamica della tensione di soma dei neuroni eccitatori:
1
Vsoma (t) = Vsoma (0) − βt +
C
dove β =
1
Iβ
C1 +C2
t
I(t )dt
0
viene impostato iniettando la corrente Iβ .
Il pad è la zona, costituita da un quadrato di metallo (99 µm × 99 µm nel nostro caso),
su cui viene saldato il filo collegato al pin del contenitore in cui è racchiuso il chip.
100
2. Beta neuroni inibitori.
Regolazione in corrente del termine β nella dinamica dei neuroni
inibitori (come per i neuroni eccitatori).
3. Durata spike.
C2
La durata dello spike è ∆t = Vdd Ipulse
e viene regolata tramite un
ingresso per la corrente Ipulse .
4. Soglia.
Impostando la tensione Vref si definisce la soglia nella dinamica
del potenziale di soma al di sopra della quale le sinapsi afferenti
vengono potenziate in presenza di spike dei neuroni presinaptici.
5. Bias comparatore.
Ingresso in corrente per la polarizzazione del comparatore del neurone che serve per discriminare il potenziale maggiore di Vref da
quello minore (punto precedente).
• Matrice sinaptica
1. Refresh p.
Regolazione in corrente per il refresh positivo della sinapsi. In
assenza di spike del neurone presinaptico e nel caso di efficacia
potenziata questa corrente consente alla sinapsi di mantenere il
suo stato.
2. Refresh n.
Regolazione in corrente per il refresh negativo della sinapsi. In
assenza di spike del neurone presinaptico e nel caso di efficacia
101
depressa questa corrente consente alla sinapsi di mantenere il suo
stato.
3. Bias p.
Corrente iniettata sul condensatore della sinapsi in presenza di uno
spike del neurone presinaptico quando il potenziale del neurone
postsinaptico è al di sopra della soglia.
4. Bias n.
Corrente sottratta dal condensatore della sinapsi in presenza di
uno spike del neurone presinaptico quando il potenziale del neurone postsinaptico è al di sotto della soglia.
5. Soglia.
La tensione impostata su questo pin discrimina, attraverso il confronto con la tensione ai capi del condensatore sinaptico (Vsin ), lo
stato di sinapsi potenziata (Vsin maggiore del valore di soglia) da
quello di sinapsi depressa (Vsin minore del valore di soglia).
6. Bias comparatore.
Ingresso in corrente per la polarizzazione del comparatore che
confronta il potenziale sinaptico con il valore di soglia (punto
precedente).
7. JE→E .
Regolazione in corrente per l’efficacia delle sinapsi plastiche nello
stato depresso (J− = JE→E ).
8. ∆J.
Regolazione in corrente per l’efficacia delle sinapsi plastiche nello
stato potenziato (J+ = JE→E + ∆J).
102
9. JI→E .
Regolazione in corrente per l’efficacia delle connessioni di tipo
inibitorio–eccitatorio.
10. JE→I .
Regolazione in corrente per l’efficacia delle connessioni di tipo
eccitatorio–inibitorio.
11. JI→I .
Regolazione in corrente per l’efficacia delle connessioni di tipo
inibitorio–inibitorio.
Un’altro pin di input è utilizzato per il segnale di bias degli amplificatori
operazionali che disaccoppiano i potenziali di neuroni e sinapsi in uscita (vedi
4.4.3) da eventuali carichi.
4.4.2
Spike
Per studiare il comportamento della rete è necessario poter osservare l’attività dei neuroni. Nella LANN21 (vedi par. 1.3), nonostante gli spike arrivino
all’esterno attraverso dei multiplexer 2 2 : 1, i pin a disposizione hanno permesso di rendere visibili solo gli spike di 14 dei 21 neuroni della rete. Per
poter ottenere informazioni più complete nella fase di test è di fondamentale importanza poter osservare l’attività di ogni neurone della rete. Nella
2
Un multiplexer n : 1 è un circuito digitale con n segnali in ingresso, una uscita ed
s ingressi di controllo. I segnali di controllo, tramite una codifica binaria, selezionano il
segnale di ingresso che deve essere trasmesso in uscita. Affinché ogni segnale sia selezionabile attraverso l’impostazione di un numero binario sugli s segnali di controllo deve essere
2s ≥ n.
103
LANN128 sono stati usati 32 multiplexer 4 : 1 per portare verso l’esterno gli
spike dei 128 neuroni. Multiplexer con un rapporto maggiore sarebbero stati
utili per ridurre il numero di pin, ma avrebbero reso molto più complicata
l’elettronica esterna che consente di riottenere dall’uscita del singolo multiplexer i segnali in ingresso. Questa operazione è d’altra parte necesaria per
poter osservare contemporaneamente l’attività di tutti i neuroni della rete.
Il rapporto 4 : 1 è risultato essere il miglior compromesso tra l’esigenza di
ridurre il numero di pin utilizzati e quella di evitare complicazioni troppo
gravose nell’elettronica esterna necessaria per i test della rete. I multiplexer
sono le uniche celle di libreria (fatta eccezione delle strutture di I/O) incluse
in questo chip. I pin utilizzati per portare verso l’esterno i segnali di spike
sono quindi 34:
• 32 per le uscite dei multiplexer ;
• 2 di select necessari per scegliere uno dei quattro gruppi di spike.
4.4.3
Potenziali
Per poter analizzare con maggior dettaglio i comportamenti della rete ed il
corretto funzionamento dell’elettronica sono stati resi visibili alcuni potenziali
di neuroni e sinapsi. I 23 pin a nostra disposizione per portare in uscita questi
potenziali sono stati suddivisi nel seguente modo:
• 9 neuroni eccitatori;
• 2 neuroni inibitori;
• 12 sinapsi.
104
Una volta impostate le efficacie sinaptiche dall’esterno è importante poter
misurare l’intensità di corrente iniettata nella capacità di soma del neurone
postsinaptico a causa dell’emissione di uno spike da parte del neurone presinaptico. Una misura diretta di questo parametro è fornita dall’aumento nel
potenziale del neurone postsinaptico provocato dallo spike del presinaptico.
Figura 4.10: In questa figura sono mostrati i neuroni eccitatori e le sinapsi con
potenziali in uscita dal chip. Ogni cerchio numerato rappresenta un neurone ed
ogni freccia una sinapsi. Non sono mostrate altre connessioni comunque presenti
tra i neuroni del campione scelto.
Nella LANN21 [25] questa misura è possibile per le sole connessioni E→E,
105
dato che l’unico neurone con potenziale visibile è eccitatorio ed ha sinapsi afferenti esclusivamente di tipo eccitatorio. Per gli altri tipi di connessione sono
state fatte delle stime per l’efficacia sinaptica utilizzando le equazioni di campo medio (una descrizione dettagliata della procedura utilizzata è riportata
in [27]). Queste stime non saranno più necessarie per la LANN128 in quanto
i potenziali visibili permettono di effettuare la misura diretta dell’efficacia
su ogni tipo di sinapsi ed in alcuni casi (ad esempio JE→E ) su più connessioni per lo stesso tipo di contatto sinaptico. Per avere un quadro completo
dell’interazione all’interno del nostro campione di neuroni eccitatori sono stati portati verso l’esterno i potenziali delle sinapsi rendendo completamente
controllabile la struttura mostrata in fig. 4.10. Tutti i segnali analogici in
uscita sono disaccoppiati dall’esterno tramite un amplificatore operazionale
utilizzato come buffer analogico.
4.4.4
Correnti esterne
Per ogni neurone è prevista una corrente di ingresso esterna che si somma
a quella proveniente dai contatti interni eccitatori. Per evitare di introdurre
correlazioni nell’attività della rete si dovrebbe alimentare indipendentemente
ogni singolo neurone, ma i pin a disposizione (102) sono inferiori al numero
di neuroni (128). Per questa ragione solo 76 neuroni ricevono corrente da pin
separati, i restanti 52 sono suddivisi in 26 coppie, ognuna alimentata tramite
lo stesso pin. Le correnti destinate a singoli neuroni vengono specchiate da
uno specchio n con il rapporto usato per tutte le regolazioni in corrente (vedi
par. 3.1.1) e poi sommate alle correnti interne eccitatorie. Per le correnti
destinate a coppie di neuroni si usa lo stesso tipo di specchio, con lo stesso
106
rapporto, ma a differenza del primo caso si hanno un master e due slave. Le
correnti in uscita dal singolo slave sono poi destinate ai neuroni.
107
Capitolo 5
Conclusioni
5.1
Il chip di test
La LANN128 è stata progettata con una tecnologia (AMS, CMOS 0.6 µm)
più spinta di quella impiegata nei precedenti dispositivi realizzati nel laboratorio in cui è stato svolto il presente lavoro di tesi. Per giungere allo sviluppo
della rete neuronale precedente (LANN21, [25]) è stato necessario produrre
due chip che hanno permesso di effettuare i test preliminari sul neurone e la
sinapsi e, nello stesso tempo, di acquisire esperienza sulla tecnologia utilizzata (MOSIS, CMOS 1.2 µm). Grazie ai risultati di questa prima indagine
[25] e di quelle seguenti, mirate alla verifica sia del comportamento dei singoli elementi [31] che di quello collettivo della rete [27], abbiamo un’ottima
confidenza nel corretto funzionamento degli elementi costitutivi e delle interazioni tra essi nel caso di dinamica sinaptica “congelata”. La LANN21
presenta però un problema per quanto riguarda la generazione del segnale
di stato del neurone (vedi par. 3.2), necessario per l’attivazione della dinamica sinaptica. A causa dell’effetto parassita dovuto all’accoppiamento
108
capacitivo tra l’uscita del comparatore e il dispositivo per l’iniezione della
corrente eccitatoria, durante la commutazione del comparatore si ha una interruzione nell’afflusso della corrente stessa nella capacità di soma. Questo
inconveniente altera il comportamento del neurone e dell’intero dispositivo
nel caso di dinamica sinaptica attivata. Nella progettazione della LANN128
si è cercato di minimizzare il valore delle capacità parassite utilizzando, dove
possibile, i segnali di alimentazione per schermare gli incroci di conduttori su
strati di metallizzazione diversi. Inoltre, le simulazioni del neurone effettuate
dopo l’aggiunta delle capacità parassite allo schematico non hanno evidenziato nessuna deviazione dal comportamento ideale. Questa verifica non è
stata possibile durante la progettazione della LANN21 in quanto la versione
precedente del software utilizzato non lo consentiva. Nonostante le accortezze prese per l’eliminazione del problema resta importante una verifica della
corretta funzionalità del dispositivo progettato, necessaria anche a causa del
passaggio ad una tecnologia più spinta e ad una diversa architettura della
rete. Per questo motivo è stato disegnato ed inviato in fonderia per la produzione un circuito integrato di 3160.4 µm × 3156 µm con una rete di 21
neuroni (LANN21b). Questo chip di test è stato realizzato con l’intenzione di riprodurre la LANN128 su scala più piccola, le celle elementari sono
esattamente le stesse e dove possibile è stata riprodotta la stessa topologia
della LANN128. La rete neuronale del chip di test è composta da 14 neuroni
eccitatori, 7 inibitori e 129 sinapsi (connettività 30%) di cui 85 plastiche.
Osservando il layout di fig. 5.1 colpisce lo scarso sfruttamento dello spazio
disponibile. Questo si spiega considerando che la fonderia impone lo stesso
prezzo per qualsiasi chip con area ≤ 10µm2 , abbiamo quindi deciso di
109
Figura 5.1: Layout della LANN21b. In questo chip è stata realizzata una rete di
21 neuroni con connettività del 30%. Dall’esterno sono visibili gli spike di tutti
i neuroni (17 direttamente in uscita e 4 attraverso un multiplexer ), il potenziale
di 5 neuroni e 3 sinapsi, e lo stato di una sinapsi. Questo permetterà di effettuare test esaustivi sul funzionamento dei singoli elementi (neurone e sinapsi) e sul
comportamento collettivo della rete.
utilizzare la massima estensione disponibile a parità di costi. Un perimetro
maggiore di quello strettamente necessario consente di posizionare più PAD
e quindi di gestire un numero maggiore di segnali di I/O. Grazie a questa
scelta è stato possibile dotare la LANN21b di 84 pin (package PGA84) per i
110
seguenti segnali:
• alimentazioni analogiche (12 pin) e digitali (6 pin);
• regolazioni neuroni e matrice sinaptica (16 segnali analogici di ingresso);
• uscita digitale segnali di spike (18 pin) e ingressi digitali per i due
segnali di select del multiplexer ;
• stato della sinapsi (1 segnale digitale di uscita);
• potenziali di neuroni e sinapsi (8 segnali analogici di uscita: 3 neuroni
eccitatori, 2 inibitori e 3 sinapsi) e segnale di bias dei buffer analogici
di disaccoppiamento;
• correnti esterne (20 segnali analogici di ingresso).
Confrontiamo brevemente i segnali di I/O della LANN21b con quelli della
LANN128 descritti nel par. 4.4. Le regolazioni dei neuroni e della matrice
sinaptica sono ovviamente identiche a quelle previste per la LANN128. I
pin a disposizione per la LANN21b permetterebbero (eliminando una coppia di alimentazioni) l’uscita diretta di tutti i segnali di spike e ingressi in
corrente indipendenti per ogni singolo neurone. Si deve comunque tenere in
considerazione che lo scopo di questo chip è di garantire la verifica del corretto funzionamento di tutti i dispositivi presenti nella LANN128, e quindi
anche dei multiplexer 4 : 1 e degli effetti sul comportamento della rete degli
accoppiamenti degli ingressi in corrente. Per questo motivo si ha che:
• solo per 17 neuroni gli spike sono portati direttamente in uscita, mentre
per i restanti 4 i segnali di spike arrivano su un unico pin tramite un
multiplexer ;
111
• una coppia di neuroni riceve la corrente esterna dallo stesso pin, mentre
i restanti 19 sono alimentati indipendentemente.
Come per la LANN128 i neuroni con potenziale di soma visibile sono stati
scelti in modo da poter misurare l’efficacia sinaptica di ogni tipo di connessione (vedi par. 4.4.3).
5.2
Risultati e prospettive
In questo lavoro di tesi è stata sviluppata una procedura per la compressione
della matrice sinaptica grazie alla quale è stata dimezzata l’area di occupazione su silicio. Questo ha reso possibile la progettazione di un circuito integrato
(8.6 mm × 4.9 mm) con una rete neuronale di 128 neuroni. Come descritto
nel paragrafo precedente, è stato sviluppato ed è in fase di produzione un
chip con una rete di 21 neuroni (3.16 mm × 3.16 mm) che sarà sottoposto
a test prima di inviare alla fonderia il progetto della LANN128. Lo studio
del comportamento della LANN21b sarà mirato alla ricerca di eventuali modifiche da apportare alla LANN128 allo scopo di migliorarne le prestazioni
previste. Inoltre sarà possibile, avendo a disposizione due reti neuronali con
le stesse dimensioni (LANN21 e LANN21b), realizzate con tecnologie differenti, controllare gli eventuali effetti del diverso grado di miniaturizzazione.
La produzione di questi circuiti integrati si inserisce in un progetto di
ricerca molto ampio che comprende l’analisi delle osservazioni effettuate su
reti biologiche (vedi cap. 1), la modellizzazione teorica dei comportamenti
osservati e la verifica dei modelli elaborati. Quest’ultimo aspetto si realizza
tramite due diversi strumenti: le simulazioni al calcolatore e la realizzazione
elettronica. Lo studio del comportamento dei dispositivi elettronici neuro112
morfi può fornire conferme alla plausibilità biologica dei modelli teorici imponendo la ricerca di soluzioni pratiche per limitare, ad esempio, la dissipazione
di potenza e le dimensioni. È cosı̀ possibile verificare la robustezza del modello in presenza di una aleatorietà non facilmente inseribile nelle simulazioni
ma necessariamente presente in ogni sistema reale. Per quanto riguarda il
numero di neuroni le realizzazioni elettroniche non offrono le stesse possibilità
delle simulazioni, con cui è ora possibile studiare anche reti di 20000 neuroni. La LANN128 realizza comunque un notevole incremento del numero di
neuroni rispetto ai circuiti integrati precedentemente prodotti nell’ambito di
questo gruppo di ricerca. Inoltre sono state poste le basi per ottenere ulteriori incrementi sia utilizzando tecnologie sempre più spinte che collegando
in parallelo più dispositivi tramite protocolli di comunicazione dedicati.
Sono stati raggiunti importanti miglioramenti per quanto riguarda la possibilità di analizzare l’attività della rete: la LANN128 consentirà di osservare
in modo molto più dettagliato la dinamica del sistema, grazie alla completa
trasparenza dell’attività neuronale (il segnale di spike prodotto da ciascun
neurone viene portato in uscita). L’aver reso visibili più potenziali di neuroni e sinapsi (nella LANN21 erano osservabili i potenziali di un neurone
ed una sinapsi) consente inoltre la misura di parametri prima ottenibili solo
attraverso stime indirette, riducendo cosı̀ l’incertezza sui valori determinati.
La LANN128 è stata infine ottimizzata per garantire la possibilità di attivazione della dinamica sinaptica (non disponibile nella LANN21) e quindi
lo studio dell’attività selettiva che la rete sarà in grado di sostenere dopo
l’apprendimento.
113
Ringraziamenti
Desidero ringraziare il Prof. D. J. Amit ed il Dott. G. Salina per avermi
dato la possibilità di lavorare nell’ambito di un campo di ricerca di grande interesse. Devo molto a Davide Badoni che mi ha insegnato le basi per
la progettazione VLSI e ha seguito il mio lavoro in ogni passo, fornendomi
continuamente preziose indicazioni e possibilità di confronto sui modi di risolvere i problemi che si sono presentati nella fase di disegno dei dispositivi
realizzati. Grazie ai suoi insegnamenti sono stata in grado, partendo da una
conoscenza puramente teorica dei circuiti integrati, di realizzare, con grande
soddisfazione personale, due chip.
Un grazie generale è dedicato a tutto il gruppo NALS, da cui sono stata
accolta in questo periodo di tesi.
Non posso inoltre tralasciare di ringraziare i miei genitori e tutta la mia
famiglia per avermi dato la possibilità di studiare. Un sostegno fondamentale
per superare i momenti difficili mi è stato dato dalla persona con cui spero
di continuare a condividere molte cose. Ed infine voglio ringraziare tutti i
miei amici (una lista sarebbe troppo lunga) che mi sono stati sempre vicini
incoraggiandomi e facendomi sentire amata.
114
Bibliografia
[1] J. J. Hopfield. Neural networks and physical system with emergent
selective computational activities. Proc. Natl. Acad. Sci., 79, 1982.
[2] D. J. Amit. Modeling Brain Function. Cambridge University Press,
1989.
[3] C. Mead. Analog VLSI and Neural System. Addison-Wesley, 1989.
[4] M. Mattia. Dinamica Di Una Rete Di Neuroni Impulsivi con Depolarizzazione Lineare. 1997. Tesi di Laurea (Università degli Studi di Roma
‘La Sapienza’).
[5] ICANN97. Modeling Network with VLSI (Linear) Integrate and Fire
Neurons, 1997. S. Fusi e M. Mattia.
[6] S. Fusi e M. Mattia. Collective behavior of networks with linear (VLSI)
integrate and fire neurons. Neural Computation, 11:643–662, 1999.
[7] Y. Miyashita. Neural correlate of visual associative long-term memory
in the primate temporal cortex. Nature, 335, 1988.
[8] Y. Miyashita e H.S. Chang. Neural correlate of pictorial short-term
memory in the primate temporal cortex. Nature, 331, 1988.
115
[9] K. Sakai e Y. Miyashita. Neural organization for the long-term memory
of paired associates. Nature, 354, 1991.
[10] D. J. Amit, S. Fusi e V. Yakovlev. A paradigmatic working memory
(attractor) cell in IT cortex. Neural Computation, 9(1101), 1997.
[11] D. J. Amit e M. V. Tsodyks. Effective neurons and attractor neural
networks in cortical environment. Network, 3, 1992.
[12] H. C. Tuckwell. Introduction to Theoretical Neurobiology. Cambridge
University Press, 1988.
[13] D. J. Amit, D. Badoni, S. Bertazzoni, S. Buglioni, S. Fusi e G. Salina. Electronic implementation of a stochastic learning attractor neural
network. Network, 6(125), 1995.
[14] B. G. Streetman. Solid State Electronic Devices. Prentice Hall, 1995.
[15] D.J. Amit e M.V. Tsodyks. Quantitative study of attractor neural
network retrieving at low spike rates: I. substrate–spikes, rates and
neuronal gain. Network, 2(259), 1991.
[16] D. O. Hebb. The organization of behaviour. New York: Wiley, 1949.
[17] D. J. Amit. Dynamic learning in attractor neural networks. PREPRINT
N. 933, 1994. Dipartimento di Fisica, Università degli Studi di Roma
‘La Sapienza’.
[18] D.J. Amit e S. Fusi. Learning in neural network with material synapses.
Neural Computation, 6:957–982, 1994.
116
[19] N. Brunel, F. Carusi e S. Fusi. Slow stochastic hebbian learning of classes
of stimuli in a recurrent neural network. Network, 9:123–152, 1998.
[20] D. J. Amit e N. Brunel. Model of globalspontaneous activity and local
structured activity during delay periods in the cerebral cortex. Cerebral
Cortex, 7(2), 1996.
[21] N. H. E. Weste e K. Eshraghian. Principles of CMOS VLSI Design.
Addison Wesley, 1994.
[22] J. P. Uyemura.
Fundamentals of MOS Digital Integrated Circuits.
Addison Wesley, 1988.
[23] J. Millman e A. Grabel. Microelectronics. McGraw-Hill, 1987.
[24] R. L. Geiger, P.E. Allen e N. R. Straden. VLSI Design for Analog and
Digital Circuits. McGraw-Hill, 1990.
[25] A. Salamon. Sviluppo VLSI di una rete neuronale con neuroni impulsati.
1997. Tesi di Laurea (Università degli Studi di Roma ‘La Sapienza’).
[26] M. Annunziato. Implementazione hardware di una rete neuronale ad
attrattori a regime impulsivo con apprendimento stocastico. 1995. Tesi
di Laurea (Università degli Studi di Roma ‘La Sapienza’).
[27] NIPS99. Neurophysiology of a VLSI spiking neurla network: LANN21,
1999. D. J. Amit, S. Fusi e P. Del Giudice.
[28] Numerical Recipes in C: The Art of Scientific Computing. Cambridge
University Press, 1988.
[29] J. Di Giacomo. VLSI handbook. Mc Graw-Hill, 1989.
117
[30] D. J. Amit e S. Fusi. Constraints on learning in dynamic synapses.
Network, 3, 1992.
[31] S. Fusi, M. Annunziato, D. Badoni, A. Salamon e D. J. Amit. Spike–
driven synaptic plasticity: theory, simulation, VLSI implementation. Da
pubblicare su Neural Computation.
118