Prof. Beatrice Lazzerini
Self-organizing feature maps
Prof. Beatrice Lazzerini
Self-organizing feature maps
SELF-ORGANIZING FEATURE MAPS
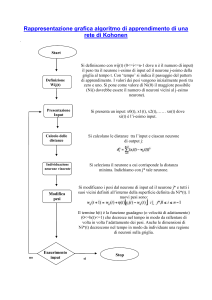
Una self-organizing feature map (introdotta da T. Kohonen) è costituita da
uno strato bi-dimensionale di neuroni collegati ad un insieme comune di
ingressi. La posizione di ogni neurone nella mappa è individuata dalle sue
coordinate.
SELF-ORGANIZING FEATURE MAPS
FEATURE MAP
...
Prof. Beatrice Lazzerini
Dipartimento di Ingegneria dell’Informazione
Via Diotisalvi 2,
56122 Pisa
n INGRESSI
...
...
Ogni vettore di ingresso “eccita” un gruppo locale di neuroni. La mappa si
auto-organizza nel senso che, dopo una fase di apprendimento non
supervisionato, che prevede la presentazione di un insieme di ingressi alla
rete, le posizioni spaziali dei gruppi di neuroni eccitati della mappa
rappresentano una mappa topologica dei vettori di ingresso. Questo
significa che le relazioni di distanza nello spazio n-dimensionale degli
ingressi sono rappresentate approssimativamente da relazioni di distanza
sulla mappa neurale bi-dimensionale.
La mappa neurale è un reticolo bi-dimensionale di neuroni. La risposta di
un neurone nella posizione l del reticolo è il prodotto scalare:
yl = X ⋅Wl = X Wl Cos ϑ
del vettore di ingresso X e del vettore dei pesi Wl del neurone. ϑ è l’angolo
compreso tra X e Wl. I pesi Wl sono i pesi sulle connessioni tra gli ingressi
e il neurone.
I vettori di ingresso sono normalizzati a lunghezza unitaria (i pesi possono
non essere normalizzati in maniera esplicita poiché, come vedremo, il
processo di apprendimento prima o poi li normalizzerà).
Il processo di apprendimento prevede, a fronte della presentazione di un
ingresso X, di modificare i pesi dei neuroni vicini alla posizione m del
1
2
Prof. Beatrice Lazzerini
Self-organizing feature maps
reticolo per cui la risposta X ⋅Wm è massima. Più precisamente, i pesi
vengono modulati in funzione della distanza dei neuroni da m. A tale
scopo si utilizza una funzione hlm, che assume valori maggiori per
posizioni l vicine ad m; di solito è una gaussiana:
l −m
hlm = exp −
σ2
2
la cui varianza σ 2 / 2 controlla il raggio del gruppo di neuroni eccitati.
Le variazioni dei pesi in seguito alla presentazione dell’ingresso X sono
definite come segue:
Prof. Beatrice Lazzerini
Self-organizing feature maps
metodo può essere usato sia in caso di vettori normalizzati (nel qual caso
equivale al metodo precedente), sia in caso di vettori non normalizzati.
Visualizzazione delle feature maps
Esistono due metodi per visualizzare una feature map. Nel primo metodo
ogni neurone è etichettato con il pattern di test che lo eccita maggiormente.
In questo modo si realizza una partizione del reticolo in regioni ciascuna
delle quali contiene neuroni che sono specializzati a riconoscere lo stesso
pattern.
Nel secondo metodo (esemplificato nella figura sottostante), la mappa è
visualizzata come una rete virtuale nello spazio degli ingressi.
Wl new = Wl old + α hlm ( X − Wl old ) = (1 − α hlm ) Wl old + α hlm X ,
con α ∈(0,1) .
Wl old
∆W X − W old
l
Wl new
X
∆W =α hlm ( X −Wl old )
La funzione hlm definisce, quindi, un vicinato del punto m all’interno del
quale i pesi dei neuroni vengono adattati in modo decrescente con la
distanza da m. In particolare, i vettori dei pesi dei neuroni del vicinato
vengono avvicinati al vettore di ingresso.
Di consequenza, neuroni “vicini” tenderanno a specializzarsi a riconoscere
ingressi simili. Questa specializzazione permetterà, alla fine del processo
di apprendimento, di definire il mapping tra lo spazio degli ingressi e lo
spazio discretizzato della mappa: ogni vettore X sarà mappato nella
locazione m associata al neurone per cui X ⋅Wm è massimo. Tale neurone è
detto neurone vincitore.
Una variante dell’algoritmo specificato sopra consiste nel determinare il
neurone vincitore minimizzando la distanza euclidea X − Wm . Questo
3
La rete virtuale è costituita sia dall’insieme dei vettori dei pesi
(rappresentati come punti nello spazio degli ingressi), sia da linee che
connettono coppie di pesi (Wi,Wj) associati a neuroni i e j che sono vicini
nel reticolo. La rete virtuale permette di visualizzare l’ordinamento
topologico della mappa. Ovviamente questo metodo può essere usato solo
per spazi al massimo tri-dimensionali.
4
Prof. Beatrice Lazzerini
Self-organizing feature maps
Applicazioni delle feature maps
Le feature maps sono usate per varie applicazioni che includono le
seguenti:
- clustering: suddivisione di un insieme di dati in una collezione di
classi, o cluster, contenenti pattern simili;
- compressione di immagini: conversione di un’immagine con milioni
di colori in un’immagine compressa, ad esempio, con 256 colori.
Prof. Beatrice Lazzerini
Self-organizing feature maps
RETI COMPETITIVE E MAPPE AUTO-ORGANIZZANTI
IN MATLAB
I neuroni di una rete competitiva imparano a riconoscere gruppi di vettori
di ingresso simili. Le mappe auto-organizzanti imparano a riconoscere
gruppi di vettori di ingresso simili in modo tale che neuroni fisicamente
vicini nella mappa rispondono a vettori di ingresso simili. In altri termini,
le mappe auto-organizzanti imparano sia la distribuzione (come fanno le
reti competitive) sia la topologia dei vettori con cui sono addestrate.
RETI COMPETITIVE
L’architettura di una rete competitiva è la seguente:
Il blocco ndist produce un vettore i cui elementi sono la distanza
negativa tra il vettore di ingresso p e i vettori dei pesi costituiti dalle righe
della matrice IW.
L’attivazione di un neurone competitivo è ottenuta sommando al vettore
prodotto da ndist il vettore dei bias b. Osserviamo che se tutti i bias
fossero zero, la massima attivazione che un neurone potrebbe avere è zero.
Tale situazione si verifica quando il vettore di ingresso p coincide con il
vettore dei pesi del neurone.
La funzione di trasferimento competitiva C riceve in ingresso il vettore
delle attivazioni dei neuroni e restituisce un vettore che contiene tutti zeri
escluso un 1 in corrispondenza del neurone vincitore, ovvero il neurone
con l’attivazione “più positiva”. Se tutti i bias sono zero, il neurone che ha
5
6
Prof. Beatrice Lazzerini
Self-organizing feature maps
il vettore dei pesi più vicino al vettore di ingresso ha l’attivazione “meno
negativa”, e quindi vince la competizione.
Prof. Beatrice Lazzerini
Self-organizing feature maps
ovvero la rete è addestrata per classificare gli input in due classi: quelli
vicino all’origine (classe 2) e quelli vicini a (1,1) (classe 1).
Creazione di una rete neurale competitiva
Può essere interessante vedere i valori finali dei pesi:
Una rete neurale competitiva si crea con la funzione newc:
>> net.iw{1,1}
net = newc(pr,s,klr,clr)
dove:
ans =
0.8031
0.1536
pr = matrice Rx2 dei valori minimi e massimi per gli R
elementi di ingresso
s = numero di neuroni
klr = Kohonen learning rate, default = 0.01
clr = conscience learning rate, default = 0.001.
I pesi sono inizializzati ai valori centrali dei range di variazione degli
ingressi con la funzione midpoint. I bias sono inizializzati con la funzione
initcon.
0.8031
0.1969
Il primo peso (prima riga della matrice dei pesi è vicino agli ingressi
prossimi a (1,1), mentre il secondo è vicino agli ingressi prossimi a (0,0).
Ovviamente si possono ottenere valori leggermente diversi poiché l’ordine
in cui vengono presentati alla rete i vettori di addestramento è casuale.
Graficamente si ottiene la seguente situazione:
Esempio
Vogliamo dividere in due classi quattro vettori bi-dimensionali:
p = [.1 .8 .1 .9; .2 .9 .1 .8];
plot(p(1,:),p(2,:),'+');
axis([0 1 0 1]);
net = newc([0 1; 0 1],2);
net = train(net,p);
y = sim(net,p);
yc = vec2ind(y) % converte il vettore y in indici di classi (gli indici delle
% classi sono le posizioni in cui le colonne di y contengono ‘1’)
Osserviamo che una rete competitiva puó essere addestrata sia con train
che con adapt.
Con riferimento al codice precedente, si ottiene, ad esempio:
yc =
2
1
2
1
7
8
Prof. Beatrice Lazzerini
Self-organizing feature maps
Il simbolo ‘+’ rappresenta un input mentre il simbolo ‘.’ Rappresenta un
peso.
Legge di apprendimento di Kohonen (learnk)
I pesi del neurone vincitore sono modificati con la regola di
apprendimento di Kohonen (realizzata dalla funzione learnk):
IW(i,:)new = IW(i,:)old + α (p - IW(i,:)old)
(abbiamo supposto che il vincitore sia il neurone i).
Il vettore dei pesi del neurone vincitore (che già era il più vicino al vettore
di input) viene avvicinato ancora di più all’input in modo che aumenti la
probabilità del neurone stesso di vincere in caso di presentazione in
ingresso di un vettore simile.
Alla fine, se ci sono abbastanza neuroni, ogni cluster di vettori di ingresso
simili avrà un neurone la cui uscita è 1 a fronte della presentazione di un
vettore del cluster e zero in tutti gli altri casi.
Legge di apprendimento dei bias (learncon)
Una delle limitazioni delle reti competitive è il fatto che potrebbero esserci
neuroni, detti dead neurons, che non vincono mai la competizione. Questo
potrebbe accadere quando i vettori dei pesi di tali neuroni partono con
valori molto distanti dai vettori di ingresso.
Per risolvere questo problema in Matlab si usano i bias. Più precisamente,
per ogni neurone si mantiene la media delle sue uscite (che equivale alla
percentuale di uscite = 1 del neurone). Tale media è usata dalla funzione
learncon per aggiornare i bias in modo che i bias di neuroni
frequentemente attivi diminuiscano mentre i bias di neuroni raramente
attivi aumentino. Quest’ultimo fatto fa sì che, all’aumentare del bias, un
neurone inizialmente poco attivo cominci a rispondere ad un numero
sempre crescente di vettori di input fino a che tutti i neuroni risponderanno
più o meno allo stesso numero di input. Tra l’altro, come conseguenza, si
ha che se una regione dello spazio di input ha un maggior numero di
vettori presentati in ingresso rispetto ad un’altra regione, la prima regione
attrarrà più neuroni e sarà classificata in sottoregioni più piccole rispetto
alla seconda.
9
Prof. Beatrice Lazzerini
Self-organizing feature maps
MAPPE AUTO-ORGANIZZANTI
Le mappe auto-organizzanti (self-organizing feature maps, o SOFM, per
brevità) differiscono dalle reti competitive per il fatto che neuroni vicini
nella mappa imparano a riconoscere zone vicine nello spazio di input. In
tal modo, come detto precedentemente, le mappe auto-organizzanti
imparano sia la distribuzione (come fanno le reti competitive) sia la
topologia dei vettori con cui sono addestrate.
I neuroni di una SOFM sono originariamente organizzati in accordo ad una
certa topologia. Le funzioni gridtop, hextop e randtop organizzano i
neuroni secondo una topologia a griglia, esagonale o casuale,
rispettivamente. Le distanze fra neuroni sono calcolate con una delle
seguenti funzioni: dist (distanza euclidea), boxdist, linkdist e mandist
(spiegate nel seguito).
Il neurone vincitore è individuato con la stessa procedura usata dalle reti
competitive. Comunque, oltre al vincitore, vengono aggiornati i pesi di
tutti i neuroni all’interno del vicinato del vincitore. La regola di
aggiornamento usata è la regola di Kohonen. Non viene peraltro fatto uso
di bias.
Il vicinato di un neurone include i neuroni che giacciono all’interno di un
certo raggio d dal neurone. La figura sottostante mostra due vicinati bidimensionale di raggio d=1 e d=2, rispettivamente, intorno al neurone 13.
TOPOLOGIE
•
Griglia rettangolare
pos = gridtop(2,3)
pos =
0 1 0 1
% array di 2x3 neuroni
0
1
10
Prof. Beatrice Lazzerini
0
0
1
Self-organizing feature maps
1
2
2
Prof. Beatrice Lazzerini
•
Nella griglia il neurone 1 ha posizione (0,0), il neurone 2 ha posizione
(1,0), il neurone 3 ha posizione (0,1), etc.
Self-organizing feature maps
Griglia esagonale
La topologia esagonale è la topologia di default.
pos = hextop(8,10);
plotsom(pos)
Ad esempio, un insieme di 8x10 neuroni con topologia a griglia può essere
creato e visualizzato come segue:
pos = gridtop(8,10);
plotsom(pos)
11
12
Prof. Beatrice Lazzerini
•
Self-organizing feature maps
Prof. Beatrice Lazzerini
Self-organizing feature maps
1.0000 1.4142
0 1.0000 1.0000 1.4142
1.4142 1.0000 1.0000
0 1.4142 1.0000
2.0000 2.2361 1.0000 1.4142
0 1.0000
2.2361 2.0000 1.4142 1.0000 1.0000
0
Griglia casuale
pos = randtop(8,10);
plotsom(pos)
La funzione boxdist calcola la distanza come esemplificato dalla seguente
figura che si riferisce ad una topologia a griglia:
Quindi :
FUNZIONI DI DISTANZA
Esistono quattro funzioni per calcolare la distanza fra un neurone e i suoi
vicini.
La funzione dist calcola la distanza euclidea.
pos = gridtop(2,3)
pos =
0 1 0 1 0
0 0 1 1 2
d = boxdist(pos)
d=
0 1 1 1
1 0 1 1
1 1 0 1
1 1 1 0
2 2 1 1
2 2 1 1
2
2
1
1
0
1
2
2
1
1
1
0
La distanza tra il neurone 1 e i neuroni 2, 3 e 4 è 1, poiché questi ultimi
sono nell’immediato vicinato. La distanza tra il neurone 1 e i neuroni 5 e 6
è 2. La distanza dei neuroni 3 e 4 da tutti gli altri neuroni è 1.
1
2
La funzione linkdist calcola la distanza come numero di passi per
raggiungere il neurone considerato.
d=dist(pos)
d=
La funzione mandist calcola la distanza di Manhattan. Dati due vettori x e
y, la loro distanza di Manhattan è sum(abs(x-y)).
0 1.0000 1.0000 1.4142 2.0000 2.2361
1.0000
0 1.4142 1.0000 2.2361 2.0000
13
14
Prof. Beatrice Lazzerini
Self-organizing feature maps
Addestramento di una mappa auto-organizzante
Prof. Beatrice Lazzerini
Self-organizing feature maps
Visualizzazione di un esempio di addestramento
L’addestramento di una mappa auto-organizzante si verifica per un vettore
di input alla volta. Per prima cosa, viene individuato il neurone vincitore.
Poi i pesi del vincitore e dei suoi vicini sono avvicinati al vettore di input: i
pesi del vincitore sono modificati in modo proporzionale al learning rate,
mentre i pesi dei vicini sono modificati in modo proporzionale a metà del
learning rate. Sia il learning rate che la distanza che determina il vicinato
sono alterati durante l’addestramento attraverso due fasi: ordering phase e
tuning phase.
Fase 1: ordering phase
Questa fase dura un determinato numero di passi. La distanza del vicinato
è inizializzata alla massima distanza tra due neuroni e decresce fino a
raggiungere il valore della distanza della fase 2 (tuning neighborhood
distance). Il learning rate parte da un determinato valore (ordering-phase
learning rate) e decresce fino a raggiungere il valore del tuning-phase
learning rate. Mano a mano che la distanza del vicinato e il learning rate
decrescono durante questa prima fase, i neuroni della rete tipicamente si
ordinano nello spazio degli ingressi con la stessa topologia con cui sono
ordinati fisicamente.
Fase 2: tuning phase
Questa fase dura per il resto dell’addestramento. La distanza del vicinato
rimane al valore “tuning neighborhood distance” (che dovrebbe includere
solo i vicini stretti (tipicamente tale valore è 1)). Il learning rate continua a
diminuire, ma molto lentamente. In questo modo si effettua una
sintonizzazione fine della rete, mantenendo stabile l’ordinamento imparato
nella fase precedente. Di solito, il numero di epoche necessarie per la
sintonizzazione fine è superiore a quello dell’ordinamento.
15
16
Prof. Beatrice Lazzerini
Self-organizing feature maps
Prof. Beatrice Lazzerini
Self-organizing feature maps
plotsom(net.layers{1}.positions); % mostra le posizioni dei neuroni
net.trainParam.epochs = 25;
net = train(net,p);
plot(p(1,:),p(2,:),'.g','markersize',20) % disegna gli ingressi con punti verdi
hold on
plotsom(net.iw{1,1},net.layers{1}.distances)
% mostra le posizioni dei pesi connettendo i pesi relativi
% a neuroni che sono a distanza 1
hold off
Si ottiene, ad esempio:
Creazione di una mappa auto-organizzante
Una mappa auto-organizzante si crea con la funzione newsom:
net = newsom(pr,[d1,d2,...],tfcn,dfcn,olr,osteps,tlr,tnd)
dove:
pr = matrice Rx2 dei valori minimi e massimi per gli R
elementi di ingresso
di (i=1,2,…) = size of ith layer dimension, defaults = [5 8]
tfcn: topology function, default = 'hextop'
dfcn: distance function, default = 'linkdist'
olr: ordering phase learning rate, default = 0.9
osteps: ordering phase steps, default = 1000
tlr: tuning phase learning rate, default = 0.02
tnd: tuning phase neighborhood distance, default = 1
Esempio
Creiamo una rete auto-organizzante con vettori di input di due elementi nel
range [0 2] e [0 1], rispettivamente. Supponiamo che la rete abbia 6
neuroni organizzati con topologia 2x3 esagonale.
p = [rand(1,40)*2; rand(1,40)];
net = newsom([0 2; 0 1],[3 5]);
17
18