Misure di prossimità nell’analisi dei dati simbolici
Proximity Measures in Symbolic Data Analysis
Laura Bocci, Alfredo Rizzi
Dipartimento di Statistica, Probabilità e Statistiche Applicate
Università degli Studi di Roma “La Sapienza”
e-mail: [email protected] , [email protected]
Abstract: The aim of this paper consists in showing the building of dissimilarity
measures between boolean and probabilistic symbolic objects. The paper also presents
different approaches to calculate the dissimilarity between symbolic objects: each of
them considers different situations characterized by different kind of variables.
Parole chiave: Boolean and probabilistic symbolic objects, dissimilarity measures.
1. Premessa
Nell’analisi dei dati tradizionale ogni unità statistica (o oggetto) è caratterizzata da
modalità quantitative di un certo numero di variabili e/o da “codici-etichetta” relativi a
variabili qualitative, ad esempio del tipo presenza/assenza. Molto spesso, come è ben
noto, si ricorre anche alla “codifica” per tutti o parte dei caratteri quantitativi.
L’analisi dei dati simbolici analizza oggetti del tipo: “I frutti prodotti in una definita
zona agricola hanno un peso compreso tra 30 e 40 grammi, sono di colore bianco o
rosso e se il colore è bianco allora il peso è inferiore a 35 grammi”.
Non è possibile esprimere questo tipo di informazione nell’ambito dell’analisi dei dati
classica.
Per altri oggetti simbolici si può associare a ciascun carattere la sua distribuzione di
probabilità. Se un’unità statistica presenta le modalità di un carattere variabili secondo
una distribuzione di probabilità, un valore di sintesi, quale ad esempio un percentile, fa
perdere molta dell’informazione a disposizione. Ad esempio il peso di un animale è un
carattere variabile nel tempo o, in una classe di animali, il peso varia da una unità
all’altra.
Nell’analisi dei dati classica, l’informazione a disposizione è contenuta in una matrice di
n righe (ognuna relativa ad una unità statistica) e di k colonne (ognuna relativa ad una
variabile). Ogni cella della matrice di rappresentazione contiene una sola modalità
relativa ad un individuo: proprio per la sua unicità tale valore è anche detto “atomico”.
Nell’analisi dei dati simbolici, i dati simbolici sono descritti da una tabella dove
ciascuna cella non contiene necessariamente un unico valore osservato della variabile su
ciascun oggetto, ma può contenere anche un insieme di valori o una distribuzione su un
insieme di valori.
In questo lavoro, dopo aver richiamato alcune delle metriche dell’analisi dei dati
simbolici, già introdotte in letteratura, presenteremo una proposta che tiene conto delle
differenti situazioni operative caratterizzate, in generale, da differenti tipi di variabili.
2. Gli oggetti simbolici
Gli oggetti simbolici sono tali perché descritti da espressioni che contengono operatori
diversi da quelli usati per l’analisi dei dati classica. Essi possono essere descritti da
espressioni proprie del dominio di applicazione poiché l’assiomatica dei numeri e degli
insiemi usuali non è più sufficiente: quindi il linguaggio degli oggetti simbolici è basato
su diverse espressioni logiche, più o meno complesse, che servono per rappresentare le
descrizioni simboliche.
In base al tipo di variabili a cui si fa riferimento si distinguono due grandi classi di
oggetti simbolici: gli oggetti simbolici booleani e gli oggetti simbolici probabilistici.
Oggetti simbolici booleani: un’asserzione simbolica booleana è un’espressione logica
formata da una congiunzione di M eventi elementari booleani (ciascuno associato ad
una delle variabili osservate):
M
M
i 1
i 1
s ei
Yi Vi
dove l’evento elementare booleano ei associato alla variabile Yi esprime la condizione
che “la variabile insieme Yi assume valori nel sottoinsieme Vi del rispettivo dominio di
osservazione ( Vi Oi )”.
Oggetti simbolici probabilistici: un’asserzione simbolica probabilistica è un’espressione
logica formata da una congiunzione di M eventi elementari probabilistici (ciascuno
associato ad una delle variabili osservate):
M
s ai
i 1
M
i 1
Y a ,
i
ij
a ij j 1...k
i
Tale espressione esprime la condizione che la variabile statistica o aleatoria Yi, che può
essere sia quantitativa che qualitativa, in corrispondenza dell’evento elementare
probabilistico ai al quale è associata, ha una distribuzione, rispettivamente, di
frequenza o di probabilità
ai1,
Yi
a i1 ,
aij ,
a ij ,
aiki
a iki
L’insieme di osservazione Vi a della variabile Yi su ai è suddiviso in k i classi non vuote
a ij che ne costituiscono una partizione: a ciascuna di esse è associato un peso a ij che
rappresenta la probabilità, in un contesto probabilistico, o la frequenza, in
un’interpretazione frequentista, con cui la variabile assume valori nella classe
corrispondente.
Laddove Yi è una variabile statistica continua allora l’evento elementare probabilistico
ai può essere rappresentato come un istogramma, mentre se Yi è una variabile statistica
discreta o qualitativa allora ai sarà rappresentato come un diagramma.
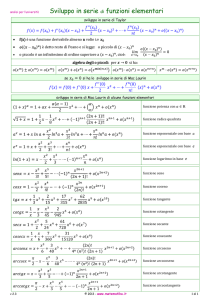
3. Misure di dissimilarità nell’analisi dei dati simbolici
Si definisce un indice di dissimilarità adimensionale in : d e ai , bi ( i 1,2, , M ).
Per esso sarà:
I) d e ai , bi 0 ai bi
II) d e ai , bi d e ai , bi
ai E ( E è l’insieme degli oggetti)
ai , bi E E
III) 0 d e ai , bi 1
Si definisce l’indice di dissimilarità tra due oggetti simbolici nel seguente modo:
d r a, b r
1 P
d e ai , bi r
P i 1
(1)
Gli indici di prossimità rivestono grande importanza nell’analisi dei dati. Molte tecniche
di queste analisi hanno come input una matrice di prossimità. Gli indici di prossimità tra
oggetti dell’analisi dei dati simbolici si basano spesso su una funzione di confronto tra
le variabili, e dunque tra coppie ordinate di eventi elementari (booleani o probabilistici)
associati alla medesima variabile, ed una funzione di aggregazione che consente di
sintetizzare le misure di confronto ottenute a livello di ciascuna variabile. Lo schema è il
seguente:
1/ r
P
r
d r a, b Yai Ybi
i 1
funzione di
confronto
funzione di aggregazione
Dunque la misura di dissimilarità tra le asserzioni simboliche a e b , siano esse
booleane o probabilistiche, è costituita da una funzione di aggregazione ispirata
all’indice di Minkowsky, la quale sintetizza le misure di dissimilarità d e ai , bi tra
ciascuna coppia di eventi elementari che le compongono.
Teorema: Si considerino le P misure di dissimilarità d e tra coppie di eventi elementari.
Allora la funzione di confronto d r tra le asserzioni simboliche a e b , definita nella (1)
con r 1 , è un indice di dissimilarità. Se inoltre le misure di dissimilarità d e sono tali
da soddisfare la disuguaglianza triangolare, e quindi sono degli indici di distanza (o
metriche), allora anche d r è una metrica.
Dimostrazione. La dimostrazione della prima parte del teorema è piuttosto immediata.
Mentre per far vedere che d r è una metrica qualora le misure di dissimilarità d e sono
tutte delle metriche, si deve dimostrare che d r soddisfa la disuguaglianza triangolare:
ciò è immediato utilizzando la disuguaglianza di Minkowsky.
4. Misure di dissimilarità tra oggetti simbolici booleani
Nelle varie misure di dissimilarità tra oggetti simbolici booleani presenti in letteratura
sono state definite diverse misure di dissimilarità tra eventi elementari booleani: al
contrario si considera sempre una funzione di aggregazione di queste dissimilarità
ispirata all’indice di Minkowsky e definita nella (1).
De Carvalho (1994) per il calcolo delle prossimità tra eventi elementari booleani si
ispira alle tabelle dei dati binari dell’analisi dei dati classici, secondo lo schema:
Accordo
Disaccordo
Accordo
A a b
C c(a) b
Disaccordo
B a c(b)
D c(a) c(b)
dove c (a ) e c (b ) rappresentano gli oggetti simbolici complementari ad a e b ,
rispettivamente, mentre si è indicato con (a ) il potenziale di descrizione dell’oggetto
simbolico a . Sulla base di questo schema, sono stati definiti classici indici di
prossimità, quali, ad esempio:
Indice di Jaccard:
d e ai , bi
Indice di Dice:
d e ai , bi
BC
2A B C
Indice di Sokal e Sneath:
d e ai , bi
BC
A BC
2B C
A 2B C
Indice di Kulczynski:
d e ai , bi
1 B
C
2 A B A C
che variano tutti tra 0 e 1.
Ichino e Yaguchi (1994) considerano, invece, la seguente funzione di confronto tra due
eventi elementari booleani associati alla medesima variabile:
d e ai , bi
ai bi ai bi 2 ai bi ai bi
Oi
(2)
ove Oi è il dominio di osservazione della variabile Yi e 0 0,5 .
Per la quantità a denominatore della (2) De Carvalho ha proposto: ai bi , dove
ai bi è l’evento elementare booleano giunzione cartesiana.
Gowda e Diday (1991) propongono un indice di dissimilarità tra eventi elementari
definito come la somma di tre componenti, cioè:
d e ai , bi
Ail Bil
ai bi ai bi 2 ai bi
ai bi
ai bi
Ampiezza Oi
d epos ai ,bi
d es ai ,bi
(3)
d ec ai ,bi
La componente d epos interviene solo quando la variabile, in base alla quale si sta
operando il confronto, è quantitativa: in essa Ail e Bil rappresentano, rispettivamente,
gli estremi inferiori degli insiemi in cui la variabile assume valori sugli eventi
elementari corrispondenti. Qualora la variabile considerata fosse qualitativa, tale
componente assume valore zero.
L’indice proposto da Gowda e Ravi (1995) è simile in molti aspetti a quello appena
visto. In questo caso, però, se la variabile in base alla quale si opera il confronto è
definita in intervalli si ha
Ail Bil
ai bi
d e ai , bi Cos 1
90 Cos
90
Ampiezza Oi
2 ai bi
s
d a ,b
d epos ai ,bi
e
i
(4)
i
mentre se tale variabile è qualitativa allora l’indice in questione è
ai bi
ai bi
d e ai , bi Cos
90 Cos
90
2 ai bi
a b
ii
d es ai ,bi
(5)
d ec ai ,bi
Le tre componenti d epos , d es , d ec degli indici (3) (4) e (5) relative, rispettivamente, alla
posizione, all’estensione (span) e al contenuto dei due eventi a confronto, sono definite
in modo tale che ciascuna di esse assuma sempre valori compresi in 0,1 .
Per tener conto di eventuali dipendenze logiche sono state presentate varie proposte. Ad
esempio si può ritenere che se la variabile non è applicabile (ad esempio: se età minore
di 18 anni allora non ha votato) occorre non considerare l’apporto della relativa
variabile nel calcolo della misura di prossimità.
Una volta calcolata la dissimilarità tra coppie di eventi elementari, per ognuna delle M
variabili, la misura di prossimità tra due oggetti simbolici booleani a e b si ottiene
come media generalizzata delle prossimità tra le singole variabili e cioè applicando la
(1). In essa P M sono le variabili che intervengono effettivamente nel calcolo delle
dissimilarità: quindi P M qualora non vi siano dipendenze logiche.
Si può notare che tutti gli indici d e tra coppie di eventi elementari presentati sono degli
indici di dissimilarità, per cui in virtù del teorema visto si può affermare che gli indici
d r sono anch’essi degli indici di dissimilarità.
4.1 Alcune considerazioni sugli indici di dissimilarità di Gowda e Diday, Gowda e
Ravi, Ichino e Yaguchi
Gli indici di dissimilarità tra coppie ordinate di eventi elementari booleani definiti da
Gowda e Diday e da Gowda e Ravi non sono normalizzati, nel senso che essi assumono
valori differenti a seconda del tipo di variabile in esame. L’indice d e definito nella (3)
assume valori nell’intervallo [0,3] se la variabile in base alla quale si opera il confronto
è definita in intervalli oppure è quantitativa a valori multipli; qualora tale variabile fosse
qualitativa a valori multipli allora l’indice assume valori in un insieme il cui valore
minimo è 0 e il valore massimo dipende dalla cardinalità degli insiemi di modalità
relativi ai due eventi elementari. L’indice d e definito nella (4) assume valori
nell’intervallo [0,1] se la variabile di confronto è definita in intervalli, mentre esso
assume valori in 0,1 2 se la variabile è qualitativa. Ciò non accade per l’indice
2
di Ichino e Yaguchi che assume sempre valori nell’intervallo 0, 1 .
Inoltre l’indice di Gowda e Diday e quello di Gowda e Ravi non restituiscono lo stesso
risultato in situazioni che sembrano intuitivamente similari. Si considerino, ad esempio,
i tre eventi elementari booleani
ai Yi [5,25]
bi Yi [12,25]
ci Yi [12,32]
Benché sia immediato osservare che bi ha la medesima “distanza” sia da ai che da ci ,
tuttavia sia per l’indice di Gowda e Diday che per quello di Gowda e Ravi si otterrà
d e ai , bi d e bi , ci , a causa della componente d epos per entrambe. Al contrario
utilizzando l’indice di Ichino e Yaguchi si avrà d e ai , bi d e bi , ci 7(1 ) / 25 .
Considerata, poi, una variabile quantitativa, ci si aspetta di trovarsi in presenza di
massima dissimilarità quando tale variabile assume, in corrispondenza dei due eventi
elementari booleani da confrontare, due valori che si trovano ai limiti dell’insieme dei
possibili valori che si possono osservare: è proprio questo il caso in cui sia l’indice di
Gowda e Ravi che quello di Ichino e Yaguchi assumono valore massimo. Così non è,
invece, per l’indice di Gowda e Diday.
4.2 Alcune metriche tra oggetti simbolici booleani
Per ognuno dei differenti tipi di variabili (qualitative, quantitative discrete, definite in
intervalli) si definisce un diverso tipo di indice di distanza tra gli eventi elementari
booleani ad esse associati.
Per le variabili qualitative si possono assumere diversi indici di distanza. Ad esempio:
d e ai , bi 1
p
r
ove r è la più grande delle cardinalità degli insiemi di modalità contenute nei due eventi
elementari a confronto e p sono le modalità comuni. Ad esempio se il colore di un fiore
può essere rosso o bianco o giallo e per due eventi elementari ai e bi si ha:
ai Colore rosso, bianco
bi Colore rosso, giallo
si ha r 2 e p 1 e pertanto d e ai , bi 0,5 .
Anche se
ai Colore rosso
bi Colore rosso, giallo
si ha d e ai , bi 0,5 .
Una soluzione diversa si ottiene se si assume:
r card ai bi
Nel primo esempio si ha d e ai , bi 2 / 3 , e nel secondo esempio si ha d e ai , bi 0,5 .
Qualora si assuma 0,5 tale espressione è ottenibile dalla formula di Ichino e
Yaguchi.
Nel caso di variabili definite in intervalli, si può definire:
d e ai , bi 1
ai bi
ai bi
dove al numeratore si trova la lunghezza dell’intervallo comune mentre a denominatore
ai bi rappresenta la lunghezza del più piccolo intervallo che contiene i due
intervalli relativi agli eventi elementari ai e bi a confronto.
In tal modo però si assegna lo stesso valore della distanza sia quando
ai Yi 50,100
bi Yi 100,150
sia nella situazione in cui
ai Yi 50,100
bi Yi 1000,1050
Gli eventi elementari (e quindi gli intervalli corrispondenti) del secondo caso
sembrerebbero più “distanti” di quelli del primo.
Se si definisce, invece:
1 (ai ) (bi )
d e ai , bi 1
2 ai bi
allora nel primo caso si ha d e ai , bi 1 / 2 e nel secondo avremo d e ai , bi 19 / 20 .
La distanza così definita varia tra 0 e ½ se i due intervalli di definizione dei due eventi
elementari a confronto hanno parti in comune, tra ½ e 1 se sono disgiunti.
5. Misure di prossimità tra oggetti simbolici probabilistici
Si considerino due asserzioni simboliche probabilistiche a e b .
L’indice di dissimilarità tra tali due oggetti simbolici probabilistici è ancora l’indice (1):
la componente nuova in tale espressione è l’indice d e che valuta la prossimità tra una
coppia di eventi elementari probabilistici associati alla medesima variabile aleatoria o
statistica.
L’indice di dissimilarità d e , che si propone, si basa su tre elementi cardine: il concetto
di energia potenziale di un’asserzione probabilistica e due nuovi eventi elementari,
chiamati, rispettivamente, giunzione e congiunzione cartesiana probabilistica che
vengono costruiti a partire dalle due asserzioni messe a confronto.
5.1 Energia potenziale di un oggetto simbolico probabilistico
L’energia potenziale di un’asserzione probabilistica a è
ki
1
a 2
E (a) E (ai ) (Vi )
j 1 (aij )
i 1
i 1
M
M
a ij
(6)
dove E(ai ) è l’energia potenziale di un evento elementare probabilistico.
Nella precedente espressione si definisce (Vi a ) e (aij ) come la lunghezza degli
intervalli Vi a e a ij , rispettivamente, se la variabile Yi è continua, altrimenti essi
rappresentano le cardinalità dell’insieme Vi a e del suo sottoinsieme a ij , rispettivamente,
se Yi è discreta o qualitativa.
L’energia potenziale E(ai ) è una quantità positiva che ci consente di avere un’idea del
grado di informazione statistica presente in un evento elementare probabilistico. In
particolare tale grado di informazione rappresenta un misura del grado di omogeneità, e
quindi di concentrazione, del carattere osservato su di un oggetto simbolico
probabilistico.
Si può notare che il concetto di energia potenziale di un oggetto simbolico probabilistico
è ispirato al concetto di omogeneità del Gini (Leti, 1979).
5.2 Modello di spazio cartesiano probabilistico
Si definisce il modello di spazio cartesiano probabilistico come la terna U M ,,
dove U M è lo spazio M-dimensionale delle descrizioni simboliche dove viene
rappresentato un oggetto simbolico probabilistico; e sono due operatori
probabilistici, rispettivamente la giunzione e la congiunzione cartesiana probabilistica,
definiti sullo spazio U M , che producono due nuovi oggetti simbolici probabilistici a
partire da una coppia di oggetti simbolici probabilistici.
Si considerino due oggetti simbolici probabilistici a e b .
L’oggetto simbolico probabilistico giunzione cartesiana a b è la congiunzione logica
di M eventi elementari giunzione cartesiana probabilistica ai bi così definiti:
ai bi Yi cij* , ij*
j 1...Ti
L’oggetto simbolico probabilistico congiunzione cartesiana a b è la congiunzione
logica di M eventi elementari congiunzione cartesiana probabilistica ai bi la cui
descrizione simbolica è:
ai bi Yi cij* , ij
j 1...Gi
a ˆ ij bˆ ij
*
Yi cij , ij G
i
a ˆ ij bˆ ij
j 1
j 1...Gi
Il dominio di osservazione della variabile Yi su ai bi è l’insieme Vi* , mentre il suo
dominio di osservazione su ai bi è l’insieme Vi : tali insiemi corrispondono,
rispettivamente, alla giunzione e congiunzione cartesiana, definite da Ichino e Yaguchi
(1994), degli insiemi Vi a e Vib . Di questi insiemi si considera un’appropriata partizione
nelle
c ij .
classi
In
base
a
tale
ripartizione
vengono,
poi,
calcolate
le
c ij
in
probabilità/frequenze con cui la variabile Yi assume valori in ogni classe
corrispondenza di ciascuno dei due eventi elementari ai e bi : per cui avremo che
P Yi cij* | ai a ˆ ij mentre P Yi cij* | bi b ̂ ij .
La distribuzione di probabilità o di frequenza ij* j 1,, Ti
della variabile Y
i
in
corrispondenza di ai bi può essere calcolata in due modi differenti. In un caso può
essere ottenuta applicando il metodo che abbiamo denominato della “sintesi”: la
probabilità/frequenza ij* non è altro che una media delle probabilità/frequenze dei due
eventi elementari di partenza relative alla medesima classe c ij . Quindi:
ij*
1
2
a ˆ ij
1
2
b ˆ ij
Altrimenti essa può essere ottenuta con un metodo denominato “del risultante”. Si
considerino due vettori ognuno dei quali rappresenta la distribuzione di
probabilità/frequenza della variabile in corrispondenza di ciascuno dei due eventi
elementari ai e bi : le componenti del vettore a p̂ i saranno le probabilità/frequenze
a ˆ ij , mentre le componenti del vettore b p̂ i saranno le probabilità/frequenze b ˆ ij .
Il metodo “del risultante” consiste nell’individuare quel vettore pˆ *i , la cui generica
ij* , che minimizza la somma dei quadrati delle distanze di
componente è
a p̂ i
Bhattacharyya tra esso e ciascuno dei due vettori
e
b p̂ i
. Il problema di ottimo
può essere così formulato:
*
max pˆ i ,
ˆp *i 1
ˆi
ap
pˆ ,
2
*
i
ˆi
bp
2
La soluzione a tale problema è l’autovettore normalizzato corrispondente al più grande
autovalore della matrice W XX' , dove X è la matrice le cui colonne sono i vettori
*
a p̂ i e b p̂ i . Logicamente le probabilità/frequenze ij , che stiamo cercando, non
sono altro che i quadrati delle componenti del vettore pˆ *i .
Con entrambe i metodi menzionati si può dare anche un’interpretazione geometrica del
vettore le cui componenti sono le probabilità/frequenze ij* : in entrambe i casi tale
vettore è un multiplo del risultante tra i due vettori a p̂ i e b p̂ i .
La distribuzione di probabilità o di frequenza ij j 1,, Gi
della variabile Y
i
in
corrispondenza di ai bi è calcolata in modo tale che la probabilità/frequenza ij sia il
rapporto tra due quantità delle quali quella al numeratore non è altro che la probabilità
che la variabile in questione assuma valori nella classe c ij contemporaneamente in
corrispondenza di entrambe gli eventi elementari di partenza ai e bi , assumendo che
questi ultimi siano tra loro indipendenti.
5.3 Indice di dissimilarità tra eventi elementari probabilistici
Il nuovo approccio per il calcolo della dissimilarità tra coppie ordinate di eventi
elementari probabilistici consiste in una funzione di confronto che è il prodotto di due
componenti, la seconda delle quali interviene solo quando la variabile, alla quale sono
associati i due eventi elementari probabilistici a confronto, è quantitativa. La prima
componente è basata sull’energia potenziale di ognuno dei due eventi elementari messi a
confronto e sull’energia potenziale dei loro corrispondenti eventi elementari giunzione
cartesiana probabilistica e congiunzione cartesiana probabilistica. La seconda
componente è basata sulla distanza tra i valori medi degli scarti interquartilici dei due
eventi a confronto e dunque tiene conto della posizione nel piano dei due istogrammi (o
diagrammi) corrispondenti.
Se Yi è una variabile qualitativa si definisce:
E ai bi
d e ai , bi 1
A B C
(7)
Se Yi è una variabile quantitativa si definisce:
E ai bi
d e ai , bi 1
A B C
a Ri b Ri
Vi*
(8)
dove Vi* è pari alla differenza tra l’estremo superiore e l’estremo inferiore di Vi* , sia
che esso sia un intervallo o un insieme discreto di numeri reali; mentre a Ri e b Ri sono,
rispettivamente, i valori centrali dei range interquartilici di ai e bi .
Inoltre in entrambe le espressione si definiscono:
A (Vi a ) 2
1
(cij* )
a ˆ ij
2
1
(cij* )
b ˆ ij
2
Vi a \Vi b
B (Vib ) 2
Vi b \Vi a
C (Vi ) 2
Vi
1
max ij* , ij
*
(cij )
2
L’indice definito nella (7) e (8) è un indice di dissimilarità che assume valori
nell’intervallo [0, 1] e che, nel caso di variabili quantitative, ci consente di valutare la
dissimilarità tra eventi elementari probabilistici anche quando questi eventi non hanno
“nulla in comune”. Ciò accade quando i supporti della distribuzione della variabile, in
corrispondenza dei due eventi a confronto, sono disgiunti: in tal caso l’indice presentato
si riduce alla sola seconda componente. Allora pur non avendo nulla in comune, la
seconda componente dell’indice consente di calcolare la dissimilarità tra i due eventi
fornendo la distanza tra le posizioni delle masse delle rispettive distribuzioni nello
spazio cartesiano.
E’ necessario fare delle osservazioni su due possibili casi di incoerenza con la realtà in
cui incorre l’indice di dissimilarità d e , definito nella (8), nel caso in cui Yi è una
variabile quantitativa. Infatti in tale situazione si possono verificare due casi estremi:
la prima componente è compresa in (0,1) mentre la seconda componente è nulla;
la prima componente è 1 mentre la seconda componente è 0.
In queste due situazioni l’indice d e fornirebbe una misura della dissimilarità tra i due
eventi elementari probabilistici messi a confronto pari a zero, in contrasto con la prima
componente che comunque ci fornisce informazioni sull’esistenza di dissimilarità tra
tali eventi. Per ovviare a questo inconveniente è sufficiente considerare in questi due
casi estremi solo la prima componente, come nel caso di variabile qualitativa.
5.4 Applicazioni
La validità della misura di dissimilarità tra oggetti simbolici probabilistici è stata
valutata in quattro differenti applicazioni.
Due diversi metodi di clustering gerarchico, il metodo del legame singolo e quello del
legame completo, basati sulla misura di dissimilarità tra asserzioni probabilistiche
presentata, vengono applicati a quattro insiemi di dati dalle caratteristiche molto
eterogenee. Si tratta di insiemi di dati che in due casi hanno già la struttura di oggetti
simbolici booleani, mentre negli altri due sono insiemi di dati classici. Dopo aver
costruito, a partire da tali dati, degli oggetti simbolici probabilistici, i risultati delle
procedure di classificazione gerarchica, applicati a tali insiemi di oggetti, sono stati
confrontati con i risultati ottenuti dai medesimi metodi applicati ai rispettivi insiemi di
oggetti simbolici booleani: in tutti i casi il confronto ha evidenziato buona rispondenza
dei risultati. Ad esempio uno dei quattro insiemi di dati è rappresentato dalle
osservazioni di quattro variabili quantitative su un insieme di 150 iris (gli “iris” di
Fisher). Da questi dati vengono costruiti 7 oggetti simbolici probabilistici. Entrambe i
metodi di clustering gerarchico applicati hanno permesso di individuare tre gruppi
differenti di fiori: due di questi corrispondono a due delle tre specie rappresentate dai
150 iris esaminati. Il terzo gruppo individuato contiene in larga parte i fiori della terza
specie, tuttavia in esso si trovano anche alcuni fiori appartenenti alla seconda specie.
6. Conclusioni
Nel lavoro viene dapprima richiamato il concetto di dato simbolico in relazione al tipo
di variabili che si incontrano in questa analisi. Per gli oggetti simbolici booleani e per
ognuna delle diverse variabili (definite in intervalli, qualitative a valori multipli) si
propone una specifica misura di dissimilarità che viene confrontata con quella di Ichino
e Yaguchi e di De Carvalho e Diday. Per gli oggetti simbolici probabilistici viene
proposta una misura di dissimilarità che si basa sull’informazione statistica presente in
ciascun evento elementare. Il metodo di sintesi delle singole misure di prossimità tra
eventi elementari (booleani o probabilistici) si basa sulla media aritmetica delle distanze
o su una immediata generalizzazione alla distanza di Minkowsky.
Riferimenti bibliografici
Bocci, L. (1999) A Dissimilarity Measure between Probabilistic Symbolic Objects, in:
Book of Short Papers – CLADAG 99, 129-132.
De Carvalho F.A.T. (1994) Proximity Coefficients between Boolean Symbolic Objects,
in: New Approaches in Classification and Data Analysis, Diday, E. & Lechevallier,
Y. & Schader, M. & Bertrand, P. & Burtschy, B. (Eds.), Springer Verlag, 387-394.
De Carvalho F.A.T. (1996) Histogrammes et Indices de Proximité en Analyse des
Données Symboliques, in: Actes de l'Ecole d'Ete sur Analyse des Données
Symbolique, Lise - Ceremade, Université Paris - IX Dauphine, Paris.
Diday E. (1995) Probabilist, possibilist and belief objects for knowledge analysis,
Annals of Operations Research, 55, 227-276.
Ichino M., Yaguchi H. (1994) Generalized Minkowski Metrics for Mixed FeatureType Data Analysis, IEEE Transactions on Systems, Man, and Cybernetics, 24, 4,
698-708.
Leti G. (1979) Distanze e indici statistici, La Goliardica Editrice, Roma.
Rizzi A. (1998) Metriche nell'analisi dei dati simbolici, Statistica, 4, 577-588.