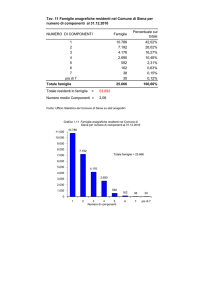
Procedura di deduplica Sysman
Premessa
L’esistenza di un database “sporco” può pregiudicare drasticamente l’efficienza di
un’azienda e l’efficacia delle sue attività di marketing o telemarketing.
Al contrario, un database “pulito” e ben organizzato garantirà che ogni prospect sia
univoco, e che non si effettuino invii di materiale doppio (postalizzazioni, email, fax, ecc.)
o telefonate inutili (campagne di telemarketing).
Come fare allora ad evidenziare ed eliminare i prospect doppi?
La soluzione ideale consiste nell’ottimizzare il database attraverso il procedimento detto di
deduplica.
Innanzi tutto, è necessario controllare tutti gli indirizzi del database, procedendo alla loro
normalizzazione mediante particolari tabelle di riferimento univoche e costantemente
aggiornate (modulo di normalizzazione Sysman).
Questa processo permette di ottimizzare l’omogeneità delle anagrafiche, ed è funzionale
alla successiva vera e propria attività di deduplica.
Questa, infatti, permette, a seguito dell’analisi dei dati salienti delle
anagrafiche di evidenziare, ed eventualmente eliminare, i prospect doppi, o
anche soltanto sospettati tali.
La funzione di deduplica si basa sulla creazione di un Match Code (generato sulla base dei
dati anagrafici di un record), attraverso il quale è reso possibile il confronto tra due record,
a diverse percentuali di somiglianza.
Il modulo di deduplica e super deduplica
Forte della collaborazione con le più importanti directory italiane e di oltre 10 anni
d'esperienza, Sysman, società del gruppo Altesys, ha messo a punto un sofisticato
strumento software di deduplica, in grado di “ripulire” (e quindi ottimizzare) i database
“sporchi”, rendendo così possibile il raggiungimento di livelli di efficienza assolutamente
eccellenti.
Le logiche sofisticate implementate, permettono un confronto tra record molto più efficace
di un semplice controllo di eguaglianza: questo è basato, infatti, su criteri di similitudine, e
non di esatta corrispondenza dei dati.
Tale strumento permette una deduplica del database avanzata. Alla base, si trovano
sempre algoritmi di matching code.
1
Tale concetto, però, viene evoluto ed infinitamente migliorato con la versione
superdeduplica grazie alla possibilità, lasciata all’utente, di selezionare quali e quanti campi
concorrano alla determinazione dello stesso match code (chiamato Match Code Utente).
Tale analisi di deduplica avanzata permette così di generare gruppi di sospetti doppioni.
Grazie poi al successivo “Trattamento Sospetti”, sarà possibile analizzare tali gruppi e,
grazie alla visualizzazione completa dei dati relativi, determinare quali anagrafiche
mantenere e quali eliminare dal database.
Un procedimento di deduplica completo implica tre step fondamentali:
1. eventuale definizione degli algoritmi per il calcolo del Match Code Utente;
2. calcolo del Match Code Utente per tutte le anagrafiche interessate;
3. ricerca dei sospetti doppioni tra le anagrafiche interessate.
Definizione del match code utente
La definizione di un Match Code Utente comporta la selezione dei campi da utilizzare per il
calcolo, la scelta dei particolari algoritmi da applicare a ciascun campo e l'attribuzione di
un Nome al Match Code per la sua archiviazione (vedere figura1).
Nell'esempio di figura 1, viene definito un Match Code composto da tre campi: Cognome,
Indirizzo e Città. Nella colonna di destra viene specificato l'algoritmo di trasformazione
da applicare a ciascun campo per la costruzione del Match Code (Standard (prima
parola), Standard (parola più lunga), ….).
In questo caso, il Match Code sarà archiviato col nome “Cognome + Indirizzo”
Opzione Match
Code Utente
Descrizione del
Match Code Utente
Campi di definizione del
Match Code Utente
Algoritmo per la creazione del
Match Code Utente
2
Calcolo del Match Code Utente
Nella procedura avanzata di deduplica è possibile calcolare il Match Code in base
all’implementazione di diversi algoritmi. Un algoritmo è composto da un massimo di sei
campi, che singolarmente vengono sottoposti ad uno specifico trattamento selezionabile
dall’utente.
Il calcolo dell’algoritmo è preceduto dall’epurazione della stringa dalle parole non
strettamente funzionali al calcolo del Match Code. Ciò avviene mediante
l’applicazione di filtri, che saranno definiti dall’utente.
Ad ogni inserimento o variazione anagrafica, il Match Code standard assegnato a ciascuna
anagrafica viene automaticamente calcolato o ricalcolato: in questo modo, i Match Code
sono costantemente mantenuti allineati con le Anagrafiche.
Ricerca dei sospetti doppioni
Dopo aver effettuato l'allineamento (cioè la generazione del Match Code Utente desiderato
per le anagrafiche considerate), è possibile passare alla fase di ricerca doppioni vera e
propria.
Come già nella deduplica standard, anche in quella avanzata è possibile indicare la
percentuale di somiglianza di Match Code che due anagrafiche devono presentare per
poter essere classificate come “sospette”.
Tale percentuale viene stabilita per gradi e oscilla tra 100% (grado massimo, uguaglianza
totale) e 55% (grado minimo, anagrafiche soltanto simili).
Percentuale di
somiglianza.
3
E’ possibile inoltre selezionare il "Tipo Elaborazione":
Effettiva: i risultati dell’elaborazione sostituiranno i risultati di precedenti
elaborazioni di deduplica (non avranno alcun effetto sui risultati di una precedente
deduplica standard);
Simulata: i risultati di precedenti operazioni di deduplica non saranno modificati,
poiché tali risultati dell’elaborazione saranno riportati in stampa o su file esterno.
Trattamento dei sospetti doppioni
L’elaborazione di una procedura di deduplica porta all’individuazione di gruppi di
anagrafiche sospette. La funzionalità di “Trattamento Sospetti” presenta tutti i gruppi di
sospetti presenti nel database: l'operatore può trattare il gruppo (eliminando o accorpando
i doppioni), oppure indicare che si tratta di omonimi o di anagrafiche diverse tra loro.
Ad esempio, in base alla data di nascita, potrebbe desumere che due Luigi Rossi, residenti
allo stesso indirizzo, sono padre e figlio.
L'indicazione che due o più anagrafiche non sono tra loro doppie, viene definita
"Forzatura": tale indicazione viene automaticamente posta dalla procedura a fronte delle
anagrafiche indicate, e ha lo scopo di non ripresentare il gruppo per successive
elaborazioni.
4