6. Architetture e paradigmi
per l’analisi dei dati
1
SOMMARIO
•
•
•
•
•
•
•
•
Sistemi informativi direzionali
Sistemi informativi e data warehouse
Architettura di un Data Warehouse
Analisi multidimensionale
Implementazione di un Data Warehouse
Indici per il Data Warehouse
Progetto di un Data Warehouse
Knowledge Discovery in database
2
SISTEMI INFORMATIVI
DIREZIONALI
3
Modello aziendale
4
Scambio di Informazioni tra livelli
• Il livello direzionale si occupa di quelle attività
necessarie alla definizione degli obiettivi da
raggiungere ed alle azioni, eventualmente correttive,
da intraprendere per perseguirli.
• Il livello operativo viceversa si occupa delle attività
attraverso cui l’azienda produce i propri servizi e
prodotti.
• il livello direzionale fornisce informazioni sulle strategie
da seguire al livello operativo al fine di perseguire gli
obiettivi aziendali.
• il livello operativo fornisce a sua volta al livello
direzionale informazioni sui risultati raggiunti.
5
Tipi di sistemi direzionali
la pianificazione strategica determina gli obiettivi generali dell’azienda
il controllo direzionale definisce traguardi economici ovvero risultati da
conseguire a medio termine e loro verifica
il controllo operativo assicura che le attività procedano nel modo prefissato.
6
Tipologia delle informazioni
• I sistemi direzionali trattano
fortemente aggregate.
informazioni
• Essi infatti devono fornire ai dirigenti aziendali
dati sintetici - indicatori gestionali - quali
medie, ricavi globali, che possano quantizzare
l’andamento dell’azienda in certi intervalli
temporali.
7
INDICATORI – MISURE - FONTI
Indicatore1
Misura 1
Fonte 1
Indicatore2
Misura 2
Fonte 2
...
...
...
Indicatore n
Misura p
Fonte m
8
Dimensioni di analisi delle informazioni
aziendali
•
•
•
•
•
L’analisi delle prestazioni aziendali può inoltre essere
condotta in diverse dimensioni:
la dimensione tempo ;
la dimensione prodotto : finalizzata all’analisi di costi e
ricavi (i quali sono evidentemente indicatori contabili o
monetari);
la dimensione processi : finalizzata al controllo di
indicatori di efficienza ed efficacia come la tempestività;
la dimensione responsabilità : ad ogni centro così come
indicato dall’organigramma aziendale possono essere
associati alcuni indicatori che forniscono dei rendiconti
sulle prestazioni dei singoli dirigenti;
la dimensione cliente : al fine di analizzare redditività,
volume di affari e bacino di utenza.
9
CRITICAL SUCCESS FACTORS
• Nel metodo dei CSF (Critical Success Factor)
l’analista, mediante opportune interviste ai manager
aziendali interessati al sistema, individua quali siano le
aree in cui essi ritengono necessario eccellere per il
successo nel business.
• Queste aree costituiranno i CSF ai quali vengono
abbinati opportuni indici di prestazione. Sarà quindi
compito del progettista selezionare gli indicatori ritenuti
migliori sulla base di alcuni criteri:
– Semplicità: è opportuno selezionare indicatori
ricavabili da algoritmi semplici.
– Costo dell’informazione: inteso come costo per
produrre un certo indicatore.
– Frequenza: inteso come tasso di campionamento
dell’indicatore.
– Strutturazione dell’informazione.
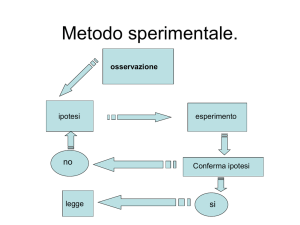
10
CSF SETTORE PRODUZIONE AZIENDA X
CSF
Indicatore
Metrica
Fonte
Motivo
Prestazioni determinanti per
la competitività del processo
Costi
Costo
Costo totale /
unitario
#prod.
SIA
‘produzione’
Indicativo della qualità del
prodotto e dell’efficienza dei
Qualità
Difetti
Totale difetti /
riscontrati
#prod.
Giudizio
Punteggio 1..10
clienti
SIA
controlli interni
Interviste a
Livello di qualità percepito
campione
dal cliente
Determinante per l’immagine
Rifiuti da
Totale rifiuti /
smaltire
#prod.
Rispetto
Materiali
Totale mat. Ricic. /
ambiente
riciclabili
#prod
Consumo
MW / #prod
SIA
dell’azienda
SIA
SIA
Efficienza energetica
energetico
11
KEY PERFORMANCES INDICATORS
• Nel metodo dei KPI (Key Performances Indicators)
l’analisi è rivolta alla determinazione di indicatori
globali quali efficienza, qualità e servizi.
• Indicatori di efficienza: misurano la produttività e i
costi di alcuni processi aziendali di interesse.
• Indicatori di qualità: misurano la conformità degli
output del processo di trasformazione alle attese del
cliente (un esempio sono gli scarti)
• Indicatori di servizio: misurano i tempi di risposta
dell’azienda (time to market)
12
ESAME DI COPERTURA DEI CSF
• I parametri individuati con i due metodi possono essere
incrociati al fine di verificare che i processi aziendali
siano monitorati attraverso indicatori correlati alle aree
di successo aziendale critiche.
• Qualora si dovessero trovare dei CSF di rilievo scoperti
vanno introdotti altri indicatori atti a coprirli, viceversa
in presenza di ridondanze è possibile decidere di
selezionare opportunamente degli indicatori rispetto ad
altri.
13
LA STRUTTURA INFORMATICA DEL SID
Il sottosistema front-end comprende tutte quelle elaborazioni
necessarie alla presentazione delle informazioni utili all’utente
finale.
Il sottosistema back-end provvede ad alimentare
automaticamente la base dati direzionale in maniera periodica
estraendo le informazioni di interesse per il SIA.
14
Struttura dettagliata dei SID
15
SISTEMI INFORMATIVI E DATA
WAREHOUSE
16
Motivazioni del DW
• I sistemi informativi permettono di aumentare la
produttività delle organizzazioni automatizzando
in maniera integrata la gestione operativa e
quotidiana dei processi di business.
• I dati ad essi connessi — se adeguatamente
accumulati e analizzati — possono essere
utilizzati per la pianificazione e il supporto alle
decisioni
• In particolare, da una corretta gestione dei dati
storici l’azienda può conseguire un grande
vantaggio competitivo.
17
Sistemi di “business intelligence”
• I sistemi di business Intelligence (BI) costituiscono la
tecnologia che supporta la dirigenza aziendale nel
prendere decisioni operative, tattiche e/o strategiche in
modo efficace e veloce.
• Ma come?...
– mediante particolari tipologie di elaborazioni dette “analitiche”
che usano in maniera integrata i dati dell’organizzazione
combinati con eventuali dati esterni
• Operando su quali dati? …
– quelli accumulati dai processi operativi e gestionali
18
Tipi di elaborazione
• Nei Transaction Processing Systems:
– On-Line Transaction Processing
• Nei Business Intelligence Systems:
– On-Line Analytical Processing
19
OLTP
• Tradizionale elaborazione di transazioni,
che realizzano i processi operativi
dell’azienda o ente.
– Operazioni predefinite, brevi e relativamente
semplici
– Ogni operazione coinvolge “pochi” dati
– Dati di dettaglio, aggiornati
– Le proprietà “acide” (atomicità, correttezza,
isolamento, durabilità) delle transazioni sono
essenziali
20
OLAP
• Elaborazione di operazioni per il supporto
alle decisioni
–
–
–
–
Operazioni complesse e casuali
Ogni operazione può coinvolgere molti dati
Dati aggregati, storici, anche non attualissimi
Le proprietà “acide” non sono rilevanti, perché le
operazioni sono di sola lettura
21
OLTP e OLAP
OLTP
OLAP
Utente
impiegato
dirigente
Funzione
operazioni giornaliere
supporto alle decisioni
Progettazione
orientata all'applicazione
orientata ai dati
Dati
correnti, aggiornati,
storici, aggregati,
dettagliati, relazionali,
multidimensionali,
omogenei
eterogenei
Uso
ripetitivo
casuale
Accesso
read-write, indicizzato
read, sequenziale
Unità di lavoro
transazione breve
interrogazione complessa
Record acc.
decine
milioni
N. utenti
migliaia
centinaia
Dimensione
100MB - 1GB
100GB - 1TB
Metrica
throughput
tempo di risposta
22
OLTP e OLAP
• I requisiti sono quindi contrastanti
• Le applicazioni dei due tipi possono
danneggiarsi a vicenda
23
Separazione degli ambienti
OLTP
OLAP
Base di dati
Data
Warehouse
APPLICAZIONE OLTP
APPLICAZIONE OLAP
UTENTI FINALI
(Transazioni)
ANALISTI
(Query complesse)
24
Data warehouse
Una base di dati
– orientata al soggetto dell’elaborazione: il dirigente
aziendale
– integrata — aziendale e non dipartimentale
– con dati storici — con un ampio orizzonte temporale,
e indicazione (di solito) di elementi di tempo
– con dati usualmente aggregati — per effettuare stime
e valutazioni
– fuori linea e a sola lettura— i dati sono aggiornati
periodicamente e sono solo interrogati
– mantenuta separatamente dalle basi di dati
operazionali
25
... orientata al soggetto ...
• E’ una collezione di dati orientata al soggetto
dell’elaborazione che è un dirigente aziendale che deve
perseguire i suoi CSF.
26
... integrata ...
• I dati di interesse provengono da tutte le
sorgenti informative — ciascun dato proviene
da una o più di esse
• Il data warehouse rappresenta i dati in modo
univoco — riconciliando le eterogeneità dalle
diverse rappresentazioni
–
–
–
–
nomi
struttura
codifica
rappresentazione multipla
27
problematiche di integrazione
28
... dati storici ...
• Le basi di dati operazionali mantengono il
valore corrente delle informazioni
– L’orizzonte temporale di interesse è dell’ordine dei
pochi mesi
• Nel data warehouse è di interesse l’evoluzione
storica delle informazioni
– L’orizzonte temporale di interesse è dell’ordine degli
anni
29
con fissato arco temporale
• Tutti i dati contenuti in un data warehouse si riferiscono
ad un preciso arco temporale.
• Un DWH rappresenta dati in genere su un lungo
periodo (ad esempio cinque, dieci anni) rispetto ai dati
contenuti in un data base operativo validi e consistenti
per un periodo molto più corto ( ad es. giorni o
settimane).
• Ogni struttura di base in un DWH contiene
implicitamente o esplicitamente un riferimento ad un
valore temporale contenuto nella tabella dei tempi la
quale ricordiamo rappresenta per gli utenti direzionali
una dimensione di analisi.
30
... dati aggregati ...
• Nelle attività di analisi dei dati per il supporto
alle decisioni
– non interessa “chi” ma “quanti”
– non interessa un dato ma
• la somma, la media, il minimo e il massimo, ...
di un insieme di dati
• Le operazioni di aggregazione sono quindi
fondamentali nel warehousing e nella
costruzione/mantenimento di un data
warehouse.
31
... fuori linea ...
• In una base di dati operazionale, i dati
vengono
– acceduti
– inseriti
– modificati
– Cancellati
pochi record alla volta
• Nel data warehouse, abbiamo
– operazioni di accesso e interrogazione — “diurne”
– operazioni di caricamento e aggiornamento dei dati
— “notturne”
che riguardano milioni di record
32
con operazioni a sola lettura
• Dal punto di vista delle operazioni consentite su un
DWH a differenza dei dati di un data base tradizionale
che possono essere inseriti, modificati ed acceduti, i
dati di un DWH possono essere solo caricati ed
acceduti poiché essi rappresentano successive
istantanee della realtà elaborativa.
33
... mantenuta separatamente ...
• Diversi motivi:
– non esiste un’unica base di dati operazionale che
contiene tutti i dati di interesse
– la base di dati deve essere integrata
– non è tecnicamente possibile fare l’integrazione in linea
– i dati di interesse sarebbero comunque diversi
• devono essere mantenuti dati storici e aggregati
– l’analisi dei dati richiede per i dati organizzazioni
speciali e metodi di accesso specifici
– degrado generale delle prestazioni senza la
separazione
34
SISTEMI OPERATIVI E SISTEMI “DATA
WAREHOUSING”
SISTEMI OPERATIVI
SISTEMI DI DATA
WAREHOUSING
Memorizzano dati correnti
Memorizzano dati storici
Memorizzano dati dettagliati
I dati sono debolmente o
fortemente aggregati
I dati sono dinamici
I dati sono pressoché statici
Le elaborazioni sono ripetitive
Effettuano elaborazioni ad hoc
Massimizzano il throughput
Hanno un throughput di
rispetto alle transazioni
transazioni medio-basso
Sono transaction driven
Sono Analysis driven
Sono orientati alle applicazioni
Sono orientati al soggetto
Supportano le decisioni day-to-day
Supportano decisioni strategiche
Servono un grosso numero di utenti
Servono un numero di utenti
operativi
manageriali relativamente basso
35
ARCHITETTURA PER IL
DATA WAREHOUSING
36
Architettura per il data warehousing
Metadati
Sorgenti
esterne
Analisi
dimensionale
ETL
Basi di dati
operazionali
Data
Warehouse
Data mining
Data Mart
Sorgenti informative
Strumenti di analisi
37
Sorgenti informative
• i sistemi operazionali dell’organizzazione
– sono sistemi transazionali (OLTP) orientati alla
gestione dei processi operazionali
– non mantengono dati storici
– ogni sistema gestisce uno o più soggetti (ad
esempio, prodotti o clienti)
– sono spesso sistemi “legacy”
• sorgenti esterne
– ad esempio, dati forniti da società specializzate di
analisi
38
Alimentazione del data warehouse
Attività necessarie ad alimentare un data warehouse (si
parla di strumenti ETL):
– Estrazione (Extraction) — accesso ai dati nelle sorgenti
– Pulizia (Cleaning) —rilevazione e correzione di errori e
inconsistenze nei dati estratti
– Trasformazione (transformation) —trasformazione di formato,
correlazione con oggetti in sorgenti diverse
– Caricamento (Loading) — con introduzione di informazioni
temporali e generazione dei dati aggregati
I metadati sono informazioni mantenute a supporto di
queste attività
39
Metadati
• "Dati sui dati":
– descrizioni logiche e fisiche dei dati (nelle sorgenti e
nel DW)
– corrispondenze e trasformazioni
– dati quantitativi
• Spesso sono non dichiarativi e immersi nei
programmi
40
Data Warehouse Server
• Sistema dedicato alla gestione del warehouse
• Può basarsi su diverse tecnologie
– ROLAP
• i dati sono memorizzati in DBMS relazionali (schemi a
stella)
– MOLAP
• I dati sono memorizzati in forma multidimensionale tramite
speciali strutture dati tipicamente proprietarie
– i produttori di RDBMS stanno iniziando a fornire
estensioni OLAP ai loro prodotti
41
Strumenti di analisi
• Consentono di effettuare analisi dei dati utilizzando il
Data Warehouse server e offrono interfacce amichevoli
per presentare, in forma adeguata e facilmente
comprensibile, i risultati delle analisi
• Due principali tipologie di analisi (e quindi di strumenti)
– Analisi multidimensionale
– Data mining
42
Data mart
• Un sottoinsieme logico dell’intero data
warehouse
– un data mart è la restrizione del data warehouse a
un singolo problema di analisi
– un data warehouse è l’unione di tutti i suoi data mart
– un data mart rappresenta un progetto fattibile
• la realizzazione diretta di un data warehouse completo non
è invece solitamente fattibile
43
Variante dell’architettura
Monitoraggio & Amministrazione
Metadati
Sorgenti
esterne
Analisi
dimensionale
Basi di dati
operazionali
Data mining
Sorgenti dei dati
Data Mart
Strumenti di analisi
44
Visualizzazione dei dati
• I dati vengono infine visualizzati in veste
grafica, in maniera da essere facilmente
comprensibili.
• Si fa uso di:
–
–
–
–
–
–
–
tabelle
istogrammi
grafici
torte
superfici 3D
bolle
…
45
Visualizzazione finale di un’analisi
1000
900
800
700
600
500
400
300
200
4 trim.2003
100
3 trim.2003
0
2 trim.2003
Lettori DVD
1 trim.2003
Televisori
Lettori CD
Videoregistratori
46
ANALISI
MULTIDIMENSIONALE
47
Rappresentazione multidimensionale
• L’analisi dei dati avviene rappresentando i dati
in forma multidimensionale
• Concetti rilevanti:
– fatto — un concetto sul quale centrare l’analisi
– misura — una proprietà atomica di un fatto
– dimensione — descrive una prospettiva lungo la
quale effettuare l’analisi
• Esempi di fatti/misure/dimensioni
– vendita/quantità,incasso/prodotto, luogo, tempo
– telefonata/costo,durata/chiamante, chiamato, tempo
48
Rappresentazione multidimensionale
dei dati
Luogo
(negozio)
VENDITE
Milano-2
Milano-1
Roma-2
Roma-1
Lettori DVD
Televisori
Quantità, incasso
Lettori CD
Articolo
(prodotto)
Videoregistratori
1 trim. 2003
2 trim. 2003
3 trim. 2003
4 trim. 2003
Tempo
(trimestre)
49
Dimensioni e gerarchie di livelli
Ciascuna dimensione è organizzata in una gerarchia che
rappresenta i possibili livelli di aggregazione per i dati.
regione
anno
provincia
trimestre
categoria
marca
mese
città
prodotto
negozio
Luogo
Articolo
giorno
Tempo
50
Operazioni su dati multidimensionali
– Slice & dice — seleziona e proietta
– Roll up — aggrega i dati
• volume di vendita totale dello scorso anno per categoria di
prodotto e regione
– Drill down — disaggrega i dati
• per una particolare categoria di prodotto e regione, mostra le
vendite giornaliere dettagliate per ciascun negozio
– (Pivot — re-orienta il cubo)
51
Slice and dice
Il manager regionale esamina
la vendita dei prodotti in tutti
i periodi relativamente ai
propri mercati
Il manager finanziario esamina
la vendita dei prodotti in tutti
i mercati relativamente al periodo
corrente e quello precedente
Luogo
Articolo
Tempo
Il manager di prodotto esamina
la vendita di un prodotto in tutti
i periodi e in tutti i mercati
Il manager strategico si concentra
su una categoria di prodotti, una
area e un orizzonte temporale
52
Risultato di slice and dice
(Selezione del prodotto DVD e proiezione)
LETTORI DVD
1 trim.
03
2 trim.
03
3 trim.
03
4 trim.
03
Roma-1
38
91
66
198
Roma-2
155
219
248
265
Milano-1
121
273
266
326
Milano-2
222
122
155
200
53
Roll-up
(Selezione del prodotto DVD ed aggregazione rispetto alla
dimensione luogo)
LETTORI DVD
Roma
1 trim.
03
193
2 trim.
03
310
3 trim.
03
314
4 trim.
03
463
Milano
343
395
421
526
54
Altra operazione di roll-up
(Aggregazione rispetto alla dimensione luogo)
VENDITE TRIM. 1 trim.
03
2 trim.
03
3 trim.
03
4 trim.
03
Lettori DVD
Televisori
536
567
705
716
735
606
989
717
Lettori CD
187
155
186
226
Videoregistratori
175
191
202
319
55
Drill-down
(Disaggregazione rispetto alla dimensione tempo)
Lettori DVD
Gen Feb
03
03
165 178
Mar
03
193
Apr
03
205
Mag
03
244
Giu …
03
256 …
Televisori
154
201
212
245
255
216 …
Lettori CD
54
88
45
24
65
66
…
Videoregistratori
56
64
55
52
64
75
…
Vendite Mensili
56
IMPLEMENTAZIONE DI UN
DATA WAREHOUSE
57
Implementazione MOLAP
• I dati sono memorizzati direttamente in un
formato dimensionale (proprietario). Le
gerarchie sui livelli sono codificate in indici di
accesso alle matrici
58
Implementazione ROLAP:
“schemi” dimensionali
• Uno schema dimensionale (schema a stella)
è composto da
– una tabella principale, chiamata tabella fatti
• memorizza i fatti e le sue misure
– Le misure più comuni sono numeriche, continue e additive
– due o più tabelle ausiliarie, chiamate tabelle
dimensione
• una tabella dimensione rappresenta una dimensione
rispetto alla quale è interessante analizzare i fatti
– memorizza i membri delle dimensioni ai vari livelli
– Gli attributi sono solitamente testuali, discreti e descrittivi
59
Schema a stella
Tempo
CodiceTempo
Giorno
Mese
Trimestre
Anno
Luogo
CodiceLuogo
Negozio
Indirizzo
Città
Provincia
Regione
Vendite
CodiceTempo
CodiceLuogo
CodiceArticolo
CodiceCliente
Quantità
Incasso
Articolo
CodiceArticolo
Descrizione
Marca
Categoria
Cliente
CodiceCliente
Nome
Cognome
Sesso
Età
Professione
60
Schema a fiocco di neve
Articolo
Tempo
Mese
Mese
Trimestre
Anno
Giorno
Mese
Luogo
Regione
CodiceRegione
Regione
CodiceArticolo
Descrizione
Marca
CodiceTempo
CodiceLuogo
Negozio
Indirizzo
Codice Città
Città
CodiceRegione
Categoria
Codice categoria
Categoria
Codice categoria
Vendite
CodiceTempo
CodiceLuogo
CodiceArticolo
CodiceCliente
Quantità
Incasso
Cliente
Codice cliente
Nome
Cognome
Sesso
Età
Professione
61
DataCube?
Una possibile istanza
62
Caratteristiche di uno schema
dimensionale
• Una tabella dimensione memorizza i membri di
una dimensione
– la chiave primaria è semplice
– gli altri campi memorizzano i livelli della dimensione
– tipicamente denormalizzata
• La tabella fatti memorizza le misure (fatti) di un
processo
– la chiave è composta da riferimenti alle chiavi di
tabelle dimensione
– gli altri campi rappresentano le misure
– è in BCNF
63
Esempio
SELECT A.Categoria, T.trimestre, sum(V.Quantita)
FROM Vendite as V, Articolo as A, Tempo as T
WHERE V.CodiceArticolo = A.CodiceArticolo and
V.CodiceTempo = T.CodiceTempo and T.Anno = 2003
GROUP BY A.Categoria, T.trimestre
ORDER BY A.Categoria, T.trimestre
64
Additività dei fatti
• Un fatto è additivo se ha senso sommarlo
rispetto a ogni possibile combinazione delle
dimensioni da cui dipende
– l’incasso è additivo perché ha senso calcolare la
somma degli incassi per un certo intervallo di
tempo, insieme di prodotti e insieme di negozi
– l’additività è una proprietà importante, perché le
applicazioni del data warehouse devono
solitamente combinare i fatti descritti da molti record
di una tabella fatti
65
FORMATO DELLE INTERROGAZIONI DI
ROLL-UP
• Le interrogazioni assumono solitamente il
seguente formato standard
SELECT D1.L1,.., Dn.Ln, Aggr1(F.M1),.., Aggrk(F.Ml)
FROM Fatti as F, Dimensione1 as D1, ..,
DimensioneN as Dn
WHERE Join-predicate(F,D1) and ..
and Join-predicate(F,Dn)
and selection-predicate
GROUP BY D1.L1, ..., Dn.Ln
ORDER BY D1.L1, ..., Dn.Ln
66
DATA CUBE
SELECT Citta, Categoria,
count(Quantita) as VenditeCC
FROM Vendite as V, Articolo as A, Luogo as L
WHERE V.CodiceArticolo = A.CodiceArticolo and
V.CodiceLuogo = L.CodiceLuogo
GROUP BY CUBE(Citta, Categoria)
67
Possibile risultato del data cube
68
GROUP BY ROLL UP
SELECT Citta, Categoria,
count(Quantita) as VenditeCC
FROM Vendite as V, Articolo as A, Luogo as L
WHERE V.CodiceArticolo = A.CodiceArticolo and
V.CodiceLuogo = L.CodiceLuogo
GROUP BY ROLLUP(Citta, Categoria)
69
Possibile risultato
70
INDICI PER IL DATA
WAREHOUSE
71
Motivazioni
• A causa della complessità delle elaborazioni
direzionali, è necessario massimizzare la
velocità di esecuzione delle interrogazioni
OLAP ; l’impiego di indici quindi assume
un’importanza primaria.
• L’aggiornamento periodico del DW consente di
ristrutturare gli indici ogni volta che si effettua il
“refresh”.
72
Query OLAP e indici
• Analizzando la struttura delle query OLAP è possibile
affermare che gli indici vanno costruiti su:
– Attributi non chiave delle “Tabelle dimensione” al fine di
accelerare le operazioni di selezione.
– Chiavi esterne (importate) della “Tabella Fatti” per
accelerare l’esecuzione dei join.
– Sebbene meno efficaci, si può pensare di costruire indici sulle
misure della “ Tabella Fatti” con predicati di selezione su tali
valori
• Esempio : “Indicare tutte le vendite con quantitativi superiori a
1.000.”
73
Indice Bitmap
Viene posto su un attributo e:
• E’ composto da
– una matrice binaria con
• tante colonne quanti sono i possibili valori dell’
attributo
• tante righe quante sono le ennuple della relazione
• Per ogni possibile valore un bit (T/F) indica se il
corrispondente record ha quel valore.
74
Esempio
• Indice Bitmap sull’attributo Posizione di una tabella Impiegati.
– i possibili valori sono:
´Ingegnere´ - ´Consulente´ - ´Manager´ - ´Programmatore´ ´Segretario´ - ´Ragioniere´
0
1: T = Vero
0: F = Falso
75
Indici Bitmap:implementazione nel DW
• Generalmente, le bitmap sono associate ad un albero
B-tree :
– la radice ed i nodi intermedi sono simili ad indici tradizionali
– Le foglie invece contengono per ciascun valore dell’indice un
vettore i cui bit sono posti ad uno in corrispondenza delle tuple
che contengono quel valore a zero altrimenti
• Algoritmo
–
–
–
–
Discendi il B + tree.
Carica l’array binario corrispondente al valore dell’indice.
Determina quali bit sono alti.
Trova tutte le tuple corrispondenti.
76
Considerazioni sulle bitmap
• Vantaggioso nel caso di attributi con pochi valori
differenti (indici con piccolo ingombro).
• Ottimo per query che non necessitano di accedere al
file dati.
• Possibilità di utilizzare operatori binari di livello basso
– per l’esecuzione dell’elaborazione dei predicati.
77
esempio
• “Quanti maschi in California non sono
assicurati?”
78
Svantaggi
• Gli indici BITMAP presentano forti limiti quando
per un attributo siano possibili un elevato
numero di valori differenti.
– Infatti è necessario utilizzare una diversa colonna
per ogni possibile valore.
• Non sono indicati quando la tabella subisce
frequenti modifiche:
– Nel nostro caso le modifiche si ottengono solo al
refresh quando è già prevista una ristrutturazione.
79
Svantaggi (2)
• Quando il numero di valori possibili è molto
alto la matrice di bit che ne deriva è
estremamente sparsa.
– NOTA: Alcune versioni permettono di comprimere la
matrice di bit al fine diminuirne la dimensione.
80
Join Index
• L’esecuzione di query su schemi a stella richiede
spesso di eseguire join su più tabelle.
• Gli indici che risultano più utili in questi casi sono i
Join Index.
– Questi vengono creati identificando in anticipo le tuple
che soddisfano il predicato di join.
81
esempio
Tabella indice
La tabella indice individua le tuple per cui
Vendite.ID_Negozi = Negozi.ID_Negozi
Per verificare le tuple che soddisfano il predicato di join non è
più necessario scandire le tuple delle due relazioni
82
Join index: implementazione nel DW
• Gli indici di join vengono costruiti sulle chiavi
delle tabelle dimensioni.
• Contengono nelle foglie del B-tree per ogni
valore dell’indice, invece dei puntatori alle tuple
delle dimensioni, puntatori agli insiemi di tuple
delle tabelle dei fatti che contengono quel
valore di chiave.
83
Star Join Index
• Il “Join Index” calcola in anticipo il join tra un
fatto ed una dimensione: lo “Star Join index”
estende il join index a più tabelle
dimensionali .
• Concatena colonne relative a più dimensioni
ottenendo una tabella di join più complessa.
84
Ovvero …
Tabella Indice
85
Indici Bitmap e di Join: costi e benefici
• I costi sono dovuti alla necessità di costruire e
memorizzare persistentemente gli indici bitmap
e di join
• I benefici sono legati al loro uso effettivo da
parte del Server del DW per la risoluzione delle
interrogazioni
86
PROGETTO DI UN DATA
WAREHOUSE
87
Progetto di un DWH
Input
Esigenze OLAP
Analisi
sorgenti
Integrazione
Dati OLTP
Altre sorgenti
Selezione delle sorgenti informative
Traduzione in modello E/R comune
Integrazione degli schemi E/R
Identificazione di fatti, misure e dimensioni
Ristrutturazione dello schema concettuale
Progettazione
Derivazione di un grafo dimensionale
Progettazione logica multidimensionale
Progettazione fisica relazionale a stella
88
Informazioni in ingresso
• Le informazioni in ingresso necessarie alla progettazione di un
data warehouse
– requisiti dell’analisi —
le esigenze aziendali di analisi dati (OLAP)
– basi di dati aziendali —
con una documentazione sufficiente per la loro comprensione
(OLTP)
– altre sorgenti informative —
l’analisi richiede spesso la correlazione con dati non di
proprietà dell’azienda ma comunque da essa accessibili — ad
esempio, dati ISTAT o sull’andamento dei concorrenti
89
Analisi sorgenti informative
• Selezione delle sorgenti informative
– analisi preliminare del patrimonio informativo aziendale
– correlazione del patrimonio informativo con i requisiti
– identificazione di priorità tra schemi
• Traduzione in un modello di riferimento
– attività preliminare alla correlazione e all’integrazione di schemi —
si svolge con riferimento a schemi concettuali E/R
90
... se non sono disponibili schemi E/R
• Si applica l’attività di comprensione concettuale di uno schema di
dati attraverso la rappresentazione dello schema relazionale
mediante il modello E/R.
• Uno schema ER è più espressivo di uno schema relazionale
• L’attività descritta è detta di “reverse engineering” di schemi
relazionali ed è svolta in maniera semiautomatica da appositi
strumenti di progettazione CASE.
91
Integrazione di sorgenti informative
• L’integrazione di sorgenti informative è l’attività di fusione dei
dati rappresentati in più sorgenti in un’unica base di dati globale
che rappresenta l’intero patrimonio informativo aziendale
• L’approccio è orientato alla identificazione, analisi e risoluzione
di conflitti — terminologici, strutturali, di codifica
• L’integrazione delle sorgenti informative produce una descrizione
globale del patrimonio informativo aziendale.
92
•
Integrazione di schemi di sorgenti
informative
orientata all’analisi e risoluzione di conflitti tra schemi ovvero di
rappresentazioni diverse di uno stesso concetto
93
Integrazione di sorgenti informative
• L’integrazione di sorgenti informative è guidata da quella dei loro
schemi – ma è necessario risolvere anche i conflitti relativi alla
codifica delle informazioni
– un attributo “sesso” può essere rappresentato
• Con un carattere - M/F
• Con una cifra - 0/1
• Implicitamente nel codice fiscale
• Non essere rappresentato
– Il nome e cognome di una persona
•
•
•
•
“Mario”, “Rossi”
“Mario Rossi”
“Rossi Mario”
“Rossi, M”
94
Integrazione di sorgenti informative
• La parte più problematica è legata alla qualità dei dati disponibili
Mario Rossi è nato il 3 ottobre 1942
Mario Rossi è nato il 10 marzo 1942
Mairo Rossi è nato il 10 marzo 1942
95
Progettazione del DWH
• identificazione di fatti, misure e dimensioni
• ristrutturazione dello schema concettuale
– rappresentazione di fatti mediante entità
– individuazione di nuove dimensioni
– raffinamento dei livelli di ogni dimensione
• derivazione di un grafo dimensionale
• progettazione logica: derivazione dello schema multidimensionale.
• progettazione fisica: determinazione dello schema relazionale a
stella.
96
Identificazione di fatti, misure e
dimensioni
marca
categoria
codice
sesso
anno nascita
città residenza
Cliente
(0,1)
Articolo
codice
nome
prezzo
costo
Vendita
scontrino
data
numero pezzi
incasso
percentuale
tempo
Occupazione
nome
Negozio
nome
città
97
Ristrutturazione dello schema
concettuale
categoria
Categoria
prezzo
codice
Articolo
Marca
marca
costo
Dati articolo
nome
scontrino
nome
Vendita
Occupazione
principale
incasso
numero pezzi
codice
Cliente
anno
nascita
Giorno
Negozio
Mese
mese
data
nome
Trimestre trimestre
sesso
Residenza
Città
città
Regione
Anno
anno
regione
E’ lo schema concettuale del data warehouse
98
Derivazione di un grafo dimensionale
99
Progettazione logica:
schema MOLAP per Vendita, Costo e Prezzo
•
La traduzione dello schema dimensionale al modello logico
multidimensionale è immediata:
– Dimensioni corrispondono a ipernodi del grafo
– Livelli e descrizioni corrispondono a nodi del grafo
– I fatti corrispondono ai nodi fatto:
Vendita[Data:giorno, Prod:articolo, A:cliente, Loc:Negozio]:
[incasso:numero]
Costo[Prodotto:Articolo, Tempo:mese]: [Valore:numero]
Prezzo[Prodotto:articolo,Tempo:mese]:[Valore:numero]
100
Progettazione fisica ROLAP:
star schema per Vendita
ARTICOLO
CodArticolo
Marca
Categoria
Nome
CLIENTE
CodCliente
Sesso
Occupazione
Anno nascita
Città nascita
Provincia nascita
Regione nascita
VENDITA
CodArticolo
CodCliente
CodTempo
CodNegozio
Incasso
TEMPO
CodTempo
Giorno
Mese
Trimestre
Anno
NEGOZIO
CodNegozio
Indirizzo
Città
Provincia
Regione
101
ESEMPIO DI PROGETTO
102
Specifiche progetto di una DWH:
statistiche vendite farmaci
Il Ministero della Salute ha commissionato la
progettazione di un Data Warehouse per effettuare
analisi e statistiche circa le vendite di farmaci da parte
delle varie farmacie italiane.
In particolare si vogliono analizzare le statistiche relative
alle tipologie di farmaci venduti suddivisi per area
geografica e orizzonte temporale, nonché semplici
statistiche sull’utenza consumatrice.
103
Individuazione ed analisi sorgenti
informative
• Da colloqui col committente:
– Ogni farmacia utilizza una base di dati operazionale per la
gestione delle vendite dei farmaci implementata attraverso un
DBMS Access.
– Dall’analisi del modello E/R è possibile individuare lo schema
concettuale contenente le sole informazioni di interesse:
• Prodotti/Farmaci
• Vendite/fatture
• Clienti
104
Schema E/R della base dati
105
Schema concettuale della DWH
106
Modello finale di tipo starflake-schema
107
Progettazione fisica e gestione dati
•
Si ottiene così, nella fase di progettazione fisica, uno star flake schema di
figura con una sola dimensione denormalizzata: quella relativa alla
collocazione geografica delle farmacie. Questo per consentire un maggiore
livello di aggregazione delle informazioni.
•
Su tale DW è poi possibile effettuare in maniera semplice interrogazioni
come:
–
–
–
–
•
selezione del farmaco più venduto in Campania.
determinazione dell’età media dei consumatori di AULIN.
I clienti della farmacia ALFANI.
Impatto della terapia del dolore nelle varie regioni italiane.
Infine vanno schedulate apposite procedure di refresh per aggiornare il
contenuto del data warehouse ad intervalli di tempo prefissati.
108
KNOWLEDGE DISCOVERY
IN DATABASE
109
Knowledge Discovery in Database
Il processo di KDD è un processo interattivo e
iterativo, strutturato in diverse fasi:
110
Knowledge Discovery in Database
• Fase 1: si identifica il problema, tenendo conto della relativa
conoscenza già acquisita in precedenza e gli obiettivi che si
vogliono perseguire.
• Fase 2: si seleziona l’insieme dei dati, oggetto del processo di
estrazione (discovery) della conoscenza.
• Fase 3: si “puliscono” e si normalizzano i dati attraverso, ad
esempio, l’eliminazione dei dati rumorosi e dei valori estremi, la
gestione dei campi vuoti …
• Fase 4: si individuano le caratteristiche salienti per rappresentare il
fenomeno che si sta analizzando in funzione dell’obiettivo definito,
tendendo a ridurre il numero delle variabili prese in considerazione.
111
Knowledge Discovery in Database
• Fase 5: si sceglie il cosiddetto “data mining task”, cioè il tipo di
analisi sui dati da effettuare - classificazione, previsione, etc …-.
• Fase 6: si scelgono le tecniche di data mining da impiegare per
ricercare i pattern nei dati, in funzione del criterio generale alla
base del processo di KDD (ad esempio, l’analista potrebbe essere
maggiormente interessato alla comprensione del modello rispetto
alle capacità di previsione dello stesso).
• Fase 7: si effettua il data mining, cioè si compie la ricerca dei
pattern d’interesse.
• Fase 8: si interpretano i pattern “scoperti” con la possibilità di
ritornare alle fasi precedenti per ulteriori iterazioni.
112
Knowledge Discovery in Database
• Fase 9: si consolida e si formalizza la conoscenza acquisita
(realizzazione/integrazione di un sistema applicativo, redazione di
documentazione, presentazione alle parti interessate …).
• Il ruolo fondamentale nel processo di KDD, che è
caratterizzato da un alto livello di iterazione, è svolto
dalla fase 7, ovvero quella in cui si compie il data
mining.
113
KDD e Data Mining
• In questa ottica, il KDD è un processo non banale di
identificazione dai “dati” dei “pattern” validi,
precedentemente sconosciuti, potenzialmente utili ed
ultimamente comprensibili.
– per “dato” si intende in questo contesto un insieme di fatti;
– per “pattern” si intende un sottoinsieme dei dati o un modello
applicabile a questo sottoinsieme.
• Si noti ancora che per processo di estrazione di un
pattern si intende il processo di individuare un modello
che ben si adatta ai dati in esame.
114
Data mining
– E’ un approccio alternativo all’analisi
multidimensionale per estrarre informazioni di
supporto alle decisioni da un data warehouse
– Talora le tecniche di ricerca di “informazione
nascosta” in una collezione di dati si applica a dati
“destrutturati” ad es. collezioni di transazioni.
115
Problemi classici di data mining
– Uso di regole associative: individuare regolarità in
un insieme di transazioni anonime
– pattern sequenziali: individuare regolarità in un
insieme di transazioni non anonime, nel corso di un
periodo temporale
– classificazione: catalogare un fenomeno in una
classe predefinita sulla base di fenomeni già
catalogati
116
Uso di regole associative
• Dati di ingresso:
– insiemi di transazioni
• Obiettivo:
– trovare delle “regole” che correlano nelle
transazioni la presenza di un insieme di oggetti con
un altro insieme di oggetti.
117
Regole associative:esempio di regola
Pannolini Birra
• il 2% tra tutte le transazioni contiene entrambi gli oggetti (supporto
cioè rilevanza statistica)
• il 30% delle transazioni che contiene Pannolini contiene anche
Birra (confidenza cioè forza)
118
Significatività delle regole
X, Y Z
– Supporto S: la regola è verificata in S% delle
transazioni rispetto a tutte le transazioni
• rilevanza statistica
– Confidenza C: C% di tutte le transazioni che
contengono X e Y contengono anche Z
• “forza” della regola
119
Pattern sequenziali
• Dati di ingresso:
– Insieme di sequenze di transazioni ciascuna
delle quali si riferisce ad un fissato cliente.
• Obiettivo:
– trovare sequenze di oggetti che compaiono
nell’insieme almeno in una assegnata percentuale.
120
Pattern sequenziali: esempi
• “Il 5% dei clienti ha comprato un lettore di CD
in una transazione e CD in un’altra”
– il 5% è il supporto del pattern
• Applicazioni
– misura della soddisfazione del cliente
– promozioni mirate
– medicina (sintomi - malattia)
121
Classificazioni
• Dati in ingresso
– Record di osservazione elementari
• Obiettivo
– Determinare gli attributi significativi dei record
osservati e costruire un albero di decisione che
consenta, in funzione dei valori degli attributi
significativi della tupla, di classificarla.
122
Classificazioni:esempio
• Classificazione delle polizze di una compagnia
attribuendo loro un rischio alto o basso.
Partendo dalle transazioni che descrivono le
polizze, il classificatore determina gli attributi
per definire il rischio (età guidatore, tipo auto) e
costruisce un albero di decisione.
123
Classificatore polizze a rischio
Età<20
T
F
T
TipoAuto = “Sportiva”
F
Albero di decisione costruito in base ad un “training set” ed
utilizzabile nel “test set”
124