SCUOLA INTERUNIVERSITARIA SICILIANA
DI SPECIALIZZAZIONE PER
L’INSEGNAMENTO SECONDARIO
Classe di Concorso: 42A
Angelo Carpenzano
Unità didattica 2: Basi di dati
MODULO DIDATTICO: I DATABASE
Docente: Prof. Cantone
Prerequisiti
Gli studenti devono conoscere:
1. Nozioni
associazione
di
entità,
attributo,
chiave,
2. Il modello E/R e le regole di derivazione del
modello logico
3. Le principali tecniche per la documentazione
efficace dell’analisi di un problema
Competenze
1. Rilevare i limiti dell’organizzazione
integrata degli archivi
non
2. Comprendere i concetti e le tecniche per la
progettazione di basi di dati
3. Applicare correttamente le tecniche di
derivazione delle tabelle del modello relazionale
a partire dal modello E/R
4. Conoscere i concetti fondamentali del modello
relazionale
5. Saper applicare le principali operazioni sulle
tabelle
Contenuti
1. Modelli per database
2. Differenze tra i modelli
3. Modello relazionale
4. Operazioni relazionali
Metodologie
Lezione frontale
Lezione dialogata
“Brainstorming”
Spazi
Aula
Laboratorio
Strumenti
Libro di testo
Dispense e appunti
Computer
Proiettore
Verifiche
Periodiche e costanti, tese sia alla valutazione
globale del percorso formativo che ad una sua parte.
Vengono usate diverse tipologie:
Colloqui individuali
Interventi di vario genere
Questionari e Test
Prove in laboratorio
Valutazione
La valutazione sarà di due tipi:
Di tipo formativo (in relazione all’applicazione,
all’impegno, all’attenzione, al metodo di lavoro
dimostrato da ogni studente durante l’attività
didattica)
Di tipo sommativo (ricavata dalla misurazione delle
varie prove), in cui gli studenti dovranno dimostrare
di:
avere acquisito conoscenze e informazioni
circa i contenuti
avere maturato abilità e competenze specifiche
alla disciplina
Tempi
Lezione
Laboratorio
Verifica
Recupero e/o
Potenziamento
20 ore
0 ore
4 ore
6 ore
Cominciamo…
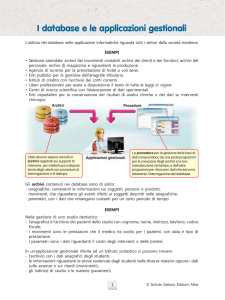
Le basi di dati
Basi di dati (database): archivi di dati, organizzati in modo
integrato attraverso tecniche di modellazione dei dati e gestiti sulle
memorie di massa dei computer attraverso appositi software
(DBMS), con l’obiettivo di raggiungere una grande efficienza nel
trattamento e nel ritrovamento dei dati.
Il database è una collezione di archivi di dati ben organizzati e ben strutturati, in
modo che possano costituire una base di lavoro per utenti diversi con
programmi diversi.
Es: i dati relativi agli articoli del magazzino di un’azienda possono essere
utilizzati dal programma che stampa le fatture e dal programma che stampa i
listini di magazzino.
FATTURE
LISTINI
ARTICOLI
Caratteristiche delle basi di dati
Efficienza e produttività di un’organizzazione di archivi:
possibilità di ritrovare facilmente le informazioni desiderate
(anche attraverso criteri di ricerca diversi) in termini di velocità
nell’elaborazione, di sicurezza dei dati e integrità delle
registrazioni.
Devono essere garantite:
• Consistenza degli archivi: i dati in essi contenuti devono essere
significativi ed essere effettivamente utilizzabili nelle applicazioni
dell’azienda.
• Sicurezza: impedire che il database venga danneggiato da
interventi accidentali o non autorizzati.
• Integrità: le operazioni effettuate sul database da utenti
autorizzati non devono provocare perdita di consistenza ai dati.
DBMS
DBMS (DataBase Management System):
prodotti software per la gestione di database.
Gli archivi che costituiscono la base di dati possono risiedere:
• su un unico computer;
• su computer diversi, facenti parte di una rete, i cui nodi possono
anche essere fisicamente lontani (database distribuiti).
Gli utenti della base di dati distribuita:
• elaborano localmente gli archivi che hanno a disposizione nel
proprio sistema;
• nello stesso tempo accedono in maniera remota a sistemi centrali
attraverso le linee di comunicazione.
Limiti degli archivi convenzionali
Le tecniche di gestione delle basi di dati nascono per superare i
problemi e i limiti insiti nelle tradizionali organizzazioni degli
archivi in modo non integrato.
Esempio di applicazione pratica
Si vogliono gestire i conti correnti di un’azienda bancaria
appartenenti alle diverse filiali e i movimenti contabili che
vengono effettuati sui conti.
Nella sede centrale della banca si vogliono organizzare le
informazioni riguardanti i conti delle filiali.
Per ciascun conto occorre registrare il numero di conto, il nome
dell’intestatario, l’indirizzo, il codice della filiale e la descrizione
della filiale.
I/V
Limiti degli archivi convenzionali
Soluzione del problema con l’approccio tradizionale
Le informazioni vengono organizzate in un archivio i cui record
hanno il seguente tracciato:
NUMCONTO
NOME
INDIRIZZO
CODFILIALE
DESCRIZ
9
40
30
5
20
Al contempo, nelle filiali bisogna registrare le informazioni sui
movimenti effettuati sui conti: numero del conto, nome del
correntista, città, data del movimento, importo e causale.
Il record del file corrispondente possiede il seguente tracciato:
NUMCODICE
9
DESCRIZ
40
CITTA
20
DATA
8
IMPORTO
10
CAUSALE
3
II/V
Limiti degli archivi convenzionali
Quando si vogliono associare tra loro i dati contenuti nei due
archivi possono nascere problemi di questo tipo:
• i sono due campi con nomi diversi che rappresentano lo stesso
dato (NumConto e NumCodice);
• lo stesso dato viene rappresentato in formati diversi (Indirizzo
nel primo tracciato e Città nel secondo);
• ci sono due campi con lo stesso nome che rappresentano dati
diversi (Descriz nel primo archivio rappresenta la filiale e nel
secondo l’intestatario del conto);
NUMCONTO
NOME
INDIRIZZO
CODFILIALE
DESCRIZ
9
40
30
5
20
NUMCODICE
9
DESCRIZ
40
CITTA
20
DATA
8
IMPORTO
10
CAUSALE
3
III/V
Limiti degli archivi convenzionali
Quando si vogliono associare tra loro i dati contenuti nei due
archivi possono nascere problemi di questo tipo:
• c’è ridondanza di dati (la descrizione della filiale è ripetuta per
ogni conto nel primo tracciato, il nome e la città del correntista
vengono ripetuti per ogni movimento);
• il fatto che gli stessi dati compaiano in due archivi diversi può
causare anomalie in fase di aggiornamento e quindi problemi di
inconsistenza (se il dato viene modificato in un archivio e non
nell’altro).
NUMCONTO
NOME
INDIRIZZO
CODFILIALE
DESCRIZ
9
40
30
5
20
NUMCODICE
9
DESCRIZ
40
CITTA
20
DATA
8
IMPORTO
10
CAUSALE
3
III/V
Limiti degli archivi convenzionali
Quali sono le cause?
RIDONDANZA DEI DATI
(Gli stessi dati compaiono in maniera duplicata)
INCONGRUENZA
(se il dato viene aggiornato in un archivio
e non in un altro, oppure se sono presenti
valori diversi per lo stesso dato)
INCONSISTENZA DEI DATI
(i dati a disposizione non sono più affidabili, perché non si
sa in modo certo quale dei diversi valori sia quello corretto)
Tutto ciò deriva dal fatto che i dati sono organizzati in archivi
diversi, in maniera non integrata.
IV/V
Limiti degli archivi convenzionali
Soluzione
Individuare con precisione quali sono gli elementi che
caratterizzano l’applicazione.
Associamo a ciascuno di essi un archivio, il cui tracciato contiene
i campi che individuano l’elemento e una chiave (tipicamente un
codice).
La chiave identifica univocamente il record all’interno
dell’archivio e consente di stabilire legami con gli altri archivi.
• archivio delle filiali, con codice filiale e descrizione filiale;
• archivio dei conti, con codice conto, nome del correntista,
indirizzo, città, codice filiale di appartenenza;
• archivio dei movimenti, con numero del movimento, data,
importo, causale, codice del conto sul quale è stato effettuato il
movimento.
V/V
Limiti degli archivi convenzionali
CODFILIALE
5
DESCRIZ
20
NUMCONTO
NOME
INDIRIZZO
CITTA
FILIALE
9
40
30
20
5
NUMMOV
DATA
IMPORTO
CAUSALE
CODICE
6
8
10
3
9
• archivio delle filiali, con codice filiale e descrizione filiale;
• archivio dei conti, con codice conto, nome del correntista,
indirizzo, città, codice filiale di appartenenza;
• archivio dei movimenti, con numero del movimento, data,
importo, causale, codice del conto sul quale è stato effettuato il
movimento.
V/V
Archivi integrati
La teoria dei database introduce una nuova metodologia di
organizzazione degli archivi di dati, con l’obiettivo di superare i
limiti visti.
Caratteristiche fondamentali:
• indipendenza dalla struttura fisica dei dati: i programmi
applicativi sono indipendenti dai dati fisici;
• indipendenza dalla struttura logica dei dati: i programmi
applicativi sono indipendenti dalla struttura logica con cui i dati
sono organizzati negli archivi;
• utilizzo da parte di più utenti: i dati organizzati in un unico
database possono essere utilizzati da più utenti con i loro
programmi, consentendo anche una visione solo parziale del
database da parte del singolo utente;
• eliminazione della ridondanza: gli stessi dati non compaiono
più volte in archivi diversi;
I/II
Archivi integrati
• facilità di accesso: il ritrovamento dei dati è facilitato e svolto
con velocemente;
• integrità dei dati: vengono previsti controlli per evitare anomalie
ai dati causate dai programmi e dalle applicazioni degli utenti;
• sicurezza dei dati: sono previste procedure di controllo per
impedire accessi non autorizzati ai dati contenuti nel database e di
protezione da guasti accidentali;
• uso di linguaggi per la gestione del database: il database viene
gestito attraverso comandi per la manipolazione dei dati in esso
contenuti e comandi per effettuare interrogazioni alla base di dati,
al fine di ottenere le informazioni desiderate.
II/II
I modelli per il database
Il database è un modello della realtà considerata.
I contenuti della base di dati rappresentano gli stati in cui si trova
la realtà da modellare.
I cambiamenti che vengono apportati alla base di dati
rappresentano gli eventi che avvengono nell’ambiente in cui opera
l’azienda.
CONTENUTI DEL DB
CAMBIAMENTI NEL DB
STATI DELLA REALTA’
EVENTI NELLA REALTA’
L’uso dei dati organizzati in un database presuppone un attento
lavoro di progettazione iniziale, che viene fatto con riferimento
ai dati che si vogliono memorizzare e successivamente elaborare.
I/II
I modelli per il database
Novità rispetto all’organizzazione convenzionale degli archivi:
Il progetto è indipendente:
• dal computer,
• dai supporti fisici destinati a contenere le informazioni
• dalle caratteristiche del DBMS.
Ciò consente alla base di dati di evolvere nel tempo insieme alla
realtà aziendale per la quale è stata progettata, con il crescere delle
esigenze degli utenti e della necessità di informazioni.
A partire dallo schema concettuale entità/associazioni, un database
può essere progettato e realizzato passando al modello logico,
cioè alle strutture che consentono di organizzare i dati per
consentire le operazioni di manipolazione e di interrogazione.
II/II
Flat file
La soluzione più semplice consiste nel costruire un database con
una struttura di dati formata da un unico file.
Questa struttura, detta flat file, è adatta solo per basi di dati
estremamente semplici.
Una struttura flat file non è efficiente per la maggior parte delle
applicazioni gestionali.
Nello sviluppo della teoria dei database sono emersi
principalmente tre tipi diversi di modelli per le basi di dati:
1. Modello gerarchico
2. Modello reticolare
3. Modello relazionale
Modello gerarchico
E’ particolarmente adatto per rappresentare situazioni nelle quali è
possibile fornire ai dati una struttura nella quale ci sono entità che
stanno in alto ed entità che stanno in basso, secondo uno schema
ad albero, nel quale i nodi rappresentano le entità e gli archi
rappresentano le associazioni.
Struttura di dati gerarchica: insieme ordinato di alberi.
Un tipo di albero nel database gerarchico è formato da un unico
record radice e da un insieme ordinato di sottoalberi di livello
inferiore.
Un sottoalbero a sua volta consiste in un singolo record (radice
del sottoalbero) e da un insieme di sottoalberi e così via.
Modello gerarchico: esempio
Modello che rappresenta le aree di
interesse per un’azienda che vende
tramite agenti, i quali hanno i clienti e gli
ordini ricevuti.
Ogni ordine è composto da una o più
righe che fanno riferimento ai prodotti
venduti.
L’albero ha come radice il record Agente,
il quale a sua volta ha due sottoalberi con
la radice in Cliente e Ordine.
Entrambi hanno sottoalberi di livello più
basso con le righe dell’ordine e gli articoli
delle righe.
AGENTE
CLIENTE
ORDINE
ORDINE
RIGA
RIGA
ARTICOLO
ARTICOLO
Modello gerarchico
Il modello gerarchico è particolarmente adatto a
rappresentare le associazioni 1:N (uno a molti).
Presenta dei limiti, soprattutto nella rigidità della
struttura di dati creata (talvolta non riesce ad
evitare la ridondanza dei dati).
Modello reticolare
Nel modello reticolare le entità rappresentano i nodi e le
associazioni rappresentano gli archi di uno schema a grafo
orientato: si tratta di una estensione del modello di albero
gerarchico (sono consentite anche associazioni tra entità che
stanno in basso, e non solo dall’alto verso il basso).
Un database reticolare consiste di due insiemi di dati:
• un insieme di record
• un insieme di legami
I tipi record sono fatti di campi tra i quali ci deve essere anche un
campo chiave, mentre i legami sono realizzati memorizzando le
coppie di chiavi delle entità associate.
Modello reticolare: esempio
Non esiste una gerarchia predefinita tra le entità.
Un record figlio può avere un numero qualsiasi di padri: in
questo modo vengono evitate situazioni di ripetizione di dati
uguali.
CA
CC
AGENTE
CA
CLIENTE
CO
CO
ORDINE
CR
RIGA
CR
CC
CO
CA
ARTICOLO
• La gestione delle informazioni è più complessa (in quanto deve
essere utilizzata una struttura a grafo).
• Un database costruito secondo il modello reticolare può produrre
prestazioni più elevate.
Modello relazionale
Rappresenta il database come un insieme di tabelle.
E’ considerato attualmente il modello più semplice ed efficace,
perché:
• è più vicino al modo consueto di pensare i dati;
• si adatta in modo naturale alla classificazione e alla
strutturazione dei dati.
AGENTE
ORDINI
CLIENTE
RIGHE
ARTICOLI
Confronto tra i modelli
1. I modelli gerarchico e reticolare sono diventati obsoleti per
il mercato e per la ricerca, che sono orientati verso il
modello relazionale negli anni più recenti.
2. I primi due modelli furono definiti attraverso un processo
di astrazione da sistemi già implementati, mentre il
modello relazionale è stato definito a livello teorico prima
di qualsiasi implementazione sul computer.
3. Le operazioni sui database gerarchici e reticolari sono
complesse, agiscono su singoli record e non su gruppi di
record.
I database orientati agli oggetti
Database orientati agli oggetti (OODB, Object Oriented
DataBase): gestiscono oggetti e classi.
• utilizzano concetti tipici della programmazione ad oggetti (es.
metodo, ereditarietà);
• accettano sottoclassi di oggetti;
• ogni oggetto ha una propria identità.
Favoriscono l’avvicinamento tra programmi applicativi e DB,
perché permettono di usare tipi di dati definiti dall’utente e di
associare ai dati routine di codice che rappresentano le modalità di
accesso ai dati: viene applicato il concetto di oggetto al DB.
Consente di utilizzare tecnologie più avanzate insieme alle
prestazioni tipiche dei linguaggi utilizzati nella programmazione
ad oggetti, come il C++.
Modello relazionale: concetti di base
Il modello relazionale si basa sul concetto matematico di
relazione tra insiemi di oggetti.
Cos’è una relazione?
Definizione matematica
Dati n insiemi A1, A2,…, An, si dice relazione un sottoinsieme
dell’insieme di tutte le n-uple a1, a2, …, an che si possono costruire
prendendo nell’ordine un elemento a1 dal primo insieme A1, a2 dal
secondo insieme A2, e così via.
n = grado della relazione
Ai = dominio i-esimo della relazione
a1, … an = tupla
L’insieme delle tuple si chiama cardinalità della relazione.
I/III
Modello relazionale: concetti di base
La relazione è rappresentata con
una tabella, avente tante colonne
quanti sono i domini (grado) e
tante righe quante sono le n-uple
(cardinalità).
I nomi dei domini sono i nomi
delle colonne, i valori che
compaiono in una colonna sono
omogenei tra loro (appartengono
allo stesso dominio).
A1
A2
………
AN
a1
a2
………
an
Domini
cardinalità
tupla
grado
La relazione (collezione di tuple) è un’entità, ogni tupla è
un’istanza dell’entità, le colonne sono gli attributi dell’entità, il
dominio è l’insieme dei possibili valori di un attributo.
II/III
Modello relazionale: concetti di base
La
chiave
della
relazione è un attributo
o una combinazione di
attributi che identificano
univocamente le tuple:
ogni riga della tabella
possiede valori diversi
per l’attributo (o gli
attributi) chiave.
CLIENTI
FATTURE
PAGAMENTI
RIGHE FATTURE
Il modello relazionale di un database è un insieme di tabelle, sulle
quali si possono effettuare operazioni e tra le quali possono essere
stabilite delle associazioni.
III/III
Modello relazionale: requisiti
a. tutte le righe della tabella contengono lo stesso numero di
colonne;
b. gli attributi rappresentano informazioni elementari (atomiche),
ovvero non scomponibili ulteriormente;
c. i valori assunti da un campo appartengono al dominio dei valori
possibili per quel campo, ovvero sono omogenei tra loro;
d. in una relazione, ogni riga è diversa da tutte le altre, ovvero
esiste un attributo o una combinazione di attributi che
identificano univocamente la n-upla;
e. le n-uple compaiono nella tabella secondo un ordine non
prefissato, ovvero non è rilevante il criterio con il quale le
righe sono sistemate nella tabella.
Integrità sull’entità
Ogni dato elementare contenuto nel modello relazionale deve
essere accessibile attraverso la combinazione di:
- nome della tabella,
- nome e valore della chiave,
- nome della colonna contenente il dato.
Nessuna componente della chiave primaria di una tabella può
avere valore nullo.
Le regole di derivazione del modello logico
Le tabelle vengono ricavate dal modello E/R applicando le regole di
derivazione:
1. ogni entità diventa una relazione;
2. ogni attributo di un’entità diventa un attributo della relazione;
3. ogni attributo della relazione eredita le caratteristiche dell’attributo
dell’entità da cui deriva;
4. l’identificatore univoco di un’entità diventa la chiave primaria della
relazione derivata;
5. l’associazione uno a uno diventa un’unica relazione, che contiene gli
attributi della prima e della seconda entità;
6. nell’associazione uno a molti, l’identificatore univoco dell’entità di
partenza diventa chiave esterna (foreign key) dell’entità di arrivo
associata;
7. l’associazione con grado molti a molti diventa una nuova relazione,
composta dagli identificatori univoci delle due entità e dagli eventuali
attributi dell’associazione.
Operazioni relazionali
Agiscono su una relazione per ottenere una nuova relazione.
Effettuano le interrogazioni alle basi di dati per ottenere le
informazioni desiderate, estraendo da una tabella una sottotabella o
combinando tra loro due o più tabelle.
Relativo a
AGENTE
Abbinato a
CLIENTI
AGENTI
Codice
Agente
CLIENTE
Nome
Agente
Indirizzo
Agente
Codice
Zona
Codice
Cliente
Ragione
Sociale
Codice
Attività
Partita
IVA
Indirizzo
Cliente
Codice
Agente
Selezione
La selezione genera una nuova relazione costituita solo dalle nuple della relazione di partenza che soddisfano una determinata
condizione: vengono selezionate le righe con i valori degli attributi
corrispondenti alla condizione prefissata.
La relazione ottenuta possiede tutte le colonne della relazione di
partenza e quindi ha lo stesso grado; la cardinalità della nuova
relazione può essere minore o uguale alla tabella di partenza
(solitamente è minore).
Selezione: esempio
Se si vuole l'elenco dei clienti della
provincia di Milano, si effettua sulla
relazione Clienti una selezione per
Provincia =“MI”
estraendo dalla tabella tutte le righe che
hanno quel valore per l'attributo provincia,
ottenendo così una nuova tabella.
Proiezione
La proiezione genera una nuova relazione
estraendo dalla tabella iniziale due o più
colonne corrispondenti agli attributi
prefissati.
La tabella ottenuta potrebbe avere più righe
uguali: in questo caso occorre richiedere
che ne venga conservata solo una.
La relazione risultante ha grado minore o
uguale al grado della relazione di partenza;
la cardinalità è uguale a quella di partenza.
Proiezione: esempio
Se si vuole l'elenco dei codici di attività
dei clienti con i relativi codici degli agenti,
occorre applicare alla relazione Clienti
l’operazione di proiezione secondo gli
attributi CodiceAttività e CodiceAgente.
Congiunzione
La congiunzione (join) serve a combinare due relazioni aventi uno
o più attributi in comune, generando una nuova relazione
contenente le righe della prima e della seconda tabella, che
possono essere combinate secondo i valori uguali dell’attributo
comune.
a1
b1
b1
c1
a1
b1
c1
a2
b2
b2
c2
a2
b2
c2
a3
b3
b3
c3
a3
b3
c3
Il grado della relazione generata è uguale a N1+N2–1, dove N1 e
N2 sono i gradi delle relazioni di partenza; la cardinalità non è
prevedibile a priori.
I/III
Congiunzione: esempio
L’elenco dei clienti e dei relativi agenti
si ottiene applicando l’operazione di
congiunzione tra la relazione Clienti e la
relazione Agenti secondo l’attributo
comune CodiceAgente.
Combinazioni di operazioni
Gli operatori possono essere applicati alle tabelle anche in
successione, combinandoli tra loro in vario modo.
Vengono così effettuate interrogazioni sulle relazioni ottenute
come risultato di un’interrogazione precedente.
Quesito
Ottenere l’elenco delle ragioni sociali e degli agenti per i clienti
che hanno il codice di attività pari a 3109.
Occorre applicare la seguente sequenza di operazioni:
• Selezione di Clienti per CodiceAttività = 3109
• Congiunzione della relazione ottenuta su CodiceAgente e di
Agenti su CodiceAgente
• Proiezione della relazione ottenuta su RagioneSociale,
NomeAgente
Operazioni tra tabelle
con struttura omogenea
Due tabelle hanno struttura omogenea se hanno colonne con lo
stesso numero di attributi, dello stesso tipo e nello stesso ordine.
In questo caso si possono applicare le usuali operazioni sugli
insiemi.
Unione
Genera una nuova tabella che contiene
le righe della prima e della seconda
tabella con riduzione a una di quelle
ripetute.
Operazioni tra tabelle
con struttura omogenea
Intersezione
Genera, a partire da due tabelle
omogenee, una nuova tabella che
contiene soltanto le righe comuni.
Differenza
Genera una nuova tabella che contiene
soltanto le righe della prima tabella che
non sono contenute nella seconda.
Fine