SISTEMA DI CODA M/M/1
Introduzione
Per lo studio dei sistemi di coda è importante conoscere il concetto di processo stocastico; esso è
definito come una funzione casuale X(t) i cui valori sono variabili aleatorie. Il più semplice
processo stocastico si ha ottenendo una sequenza casuale dove Xn forma un insieme di variabili
indipendenti; in tal modo non vi è dipendenza nella realizzazione n-esima al tempo t dalle
realizzazioni precedenti. In tale ambito si inseriscono i processi di Markov, nei quali il valore che
assume la variabile aleatoria è chiamato anche stato.Un insieme di tali variabili {Xn} forma una
catena di Markov se la probabilità che il prossimo stato sia pari alla variabile aleatoria x(n+1)
dipende solo dal corrente stato e non dagli stati precedenti.Il tempo già speso in un dato stato non
deve influenzare il tempo ancora rimanente prima della prossima transizione. La funzione di
distribuzione degli intervalli fra i passaggi di stato può essere dunque una funzione esponenziale
negativa, che ha la caratteristica di essere "senza memoria".
Metodologie di calcolo
I sistemi di coda M/M/1 sono sistemi in cui gli arrivi sono poissoniani e i tempi di servizio sono
esponenziali negativi. Dire che gli arrivi sono poissoniani vuol dire che la probabilità che vi siano k
arrivi in un intervallo di tempo (0,t) è pari a:
( t ) k e ( t )
P(k (t ))
k!
che è proprio la funzione di distribuzione di Poisson. In pratica c'è una tripla implicazione:
-
intervalli tra due arrivi successivi distribuiti secondo una legge esponenziale negativa di
coefficiente λ;
tasso degli arrivi costante e pari a λ;
distribuzione del numero degli arrivi in un tempo t di tipo Poisson.
Dunque l'intervallo di tempo che intercede tra l'arrivo di un utente e l'altro segue la legge di
distribuzione esponenziale negativa:
f(t) = λ e − λt
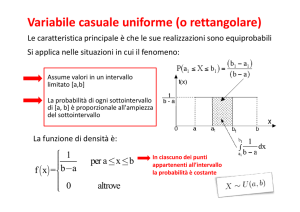
I valori casuali che possono essere generati dal computer hanno una distribuzione uniforme con
valori compresi nell'intervallo [0,1]. Per poterli utilizzare come intervalli di tempo si utilizza il
metodo dell’inversione. Tale metodo utilizza la funzione di distribuzione cumulata F(t) pari a:
F(t) = 1 − e − λt
Utilizzando il valore generato con distribuzione uniforme come valore di probabilità e la relazione
di F(t), si ricava il valore dell'intervallo di tempo Δt, distribuito secondo una legge esponenziale
negativa.
In altre parole equivarrebbe ad entrare con il numero casuale nell'asse delle ordinate rappresentativo
di F(t), ed intersecando la distribuzione di probabilità cumulata, si ottiene il relativo valore di t .
Si riportano di seguito i passaggi utilizzati per ottenere il valore di Δt partendo dalla F(t):
F(t) = P = 1 − e − λt
1 − P = e − λt
ln(1 − P) = − λt
t
ln (1 P)
Si ricorda che si è posto t = Δt
Si deve considerare inoltre il tempo di servizio che risulta distribuito sempre secondo legge
esponenziale negativa ma con parametro μ, che rappresenta il numero di elementi che il sistema è in
grado di servire nell'unità di tempo.
Il tempo di uscita per ciascun utente è dato dal tempo di servizio, a cui viene aggiunto il massimo
tra il tempo di uscita dell'utente precedente, ed il tempo di ingresso dell'utente stesso.
Si ricorda inoltre che in un sistema di coda deve essere rispettata la condizione λ < μ altrimenti la
coda tende all'infinito.
Si intende ora affrontare tale problema attraverso l'ausilio del software Excel.
Si conoscono a tal proposito i valori:
λ = 10
μ = 12
arrivi/ora
= 0,027
utenti serviti/ora = 0,003
Si può impostare la seguente tabella:
arrivi/secondo
utenti serviti/secondo
t ingresso
Arrivi
(secondi)
1° utente
0,00
2° utente
60,03
3° utente
267,84
4° utente
334,26
5° utente
742,25
6° utente 1005,48
7° utente 1156,98
8° utente 1590,52
9° utente 1601,43
10° utente 3242,58
11° utente 3703,55
12° utente 3780,87
13° utente 4050,41
14° utente 4848,78
15° utente 5241,50
16° utente 5280,65
17° utente 5457,51
18° utente 5974,86
19° utente 6001,35
20° utente 6341,78
Variabile
casuale
x
0,85
0,56
0,83
0,32
0,48
0,66
0,30
0,97
0,01
0,28
0,81
0,47
0,11
0,34
0,90
0,61
0,24
0,93
0,39
0,62
Tempi tra
2 arrivi successivi
t (secondi)
60,03
207,81
66,43
407,99
263,23
151,50
433,54
10,91
1641,15
460,97
77,32
269,54
798,37
392,72
39,15
176,86
517,35
26,49
340,42
171,38
x
0,53
0,44
0,92
0,11
0,43
0,26
0,36
0,68
0,61
0,17
0,09
0,56
0,11
0,22
0,31
0,29
0,27
0,07
0,85
0,50
t servizio
(secondi)
189,71
243,37
25,41
654,69
253,54
403,21
309,15
115,12
148,74
523,74
734,09
175,81
673,52
449,24
352,18
373,31
392,60
791,07
49,73
205,11
t uscita
(secondi)
189,71
433,07
458,49
1113,18
1366,72
1769,93
2079,07
2194,20
2342,94
3766,33
4500,42
4676,23
5349,75
5798,99
6151,17
6524,48
6917,08
7708,15
7757,88
7962,99
Tempo perso
nel sistema
(secondi)
189,71
373,05
190,65
778,92
624,47
764,44
922,09
603,67
741,51
523,74
796,87
895,37
1299,34
950,21
909,67
1243,83
1459,57
1733,28
1756,53
1621,21
Le iterazioni si sono ripetute per un N = 300.
Di seguito riportiamo il grafico ottenuto diagrammando sulle ordinate il numero di utenti, e sulle
ascisse i tempi di arrivo e di uscita. Per conoscere il numero di utenti in coda in un determinato
istante è necessario fissare l'instante t che interessa e ottenere il numero di utenti in coda per
differenza tra le due curve. Invece il numero totale di utenti in coda è pari all'area tra le due curve.
180000,00
Tempi (secondi)
160000,00
140000,00
120000,00
100000,00
80000,00
60000,00
40000,00
20000,00
0,00
0
100
200
300
400
Numero utenti
Tempi di arrivo
Tempi di uscita
500