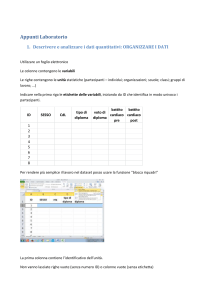
Progetto software d'esame per il corso di Informatica Avanzata 2011-12
Analisi monovariata della variazione di espressione .
Il progetto ha l'obiettivo di individuare all'interno di una popolazione specifica, quei campioni (array)
caratterizzati da variazioni significative dell'espressione di un insieme predefinito di geni. L'analisi
e' monovariata, cioe' ogni gene viene trattato separatamente.
Il progetto si articola in 3 parti:
1. Statistiche d'ordine per la ricerca di campioni caratterizzati da variazione d'espressione di geni
specifici.
Dato un insieme di microarray con un numero predeterminato di geni, utilizzare statistiche d'ordine
(mediane, quartili) per individiduare, per ogni gene considerato, quali campioni hanno livello di
espressione superiore o inferiore alla mediana, superiore al III quartile o inferiore al I quartile.
Progettare ed implemetare una funzione R con le seguenti caratteristiche:
Ingresso: una matrice M le cui n righe corrispondono ai campioni e le cui m colonne ai livelli di espressione
di m geni. Il numero delle righe o colonne non e' predeterminato.
Uscita: Una lista con due elementi:
a. Una tabella (data frame) OrderStat con un numero di righe n pari a quello della matrice M e nello
stesso ordine e avente gli stessi nomi della righe di M (se la matrice M e' una named matrix) e con un
numero di colonne m*2 (m e' il numero di colonne di M).
Per ogni gene g la tabella OrderStat prevede due colonne. La prima riporta se il gene g ha un livello
di espressione superiore (H) o inferiore (L) rispetto alla mediana per ogni campione. La seconda riporta
se il gene g ha un livello di espressione inferiore al primo quartile (L), superiore al III quartile
(H) o intermedio fra il I e III quartile (I).
La codifica di questa informazioni si puo' scegliere liberamente purche' sia chiaramente descritta nella
documentazione. Si consiglia inoltre inoltre di associare nomi anche alle colonne di OrderStat.
b. Una named matrix Summary le cui m righe corrispondono ai geni e le cui colonne riportino le seguenti
statistiche: minimo, I quartile, mediana, III quartile, massimo.
2. Z-test per la ricerca di campioni caratterizzati da variazioni di espressione significative di geni
specifici.
Ipotizzando per ogni gene una distribuzione normale dei livelli di espressione, individuare tramitez-test
per quali campioni il livello di espressione differisce significativamente dalla media della popolazione.
Progettare ed implementare una funzione R con le seguenti caratteristiche:
Ingresso:
- una matrice M le cui n righe corrispondono ai campioni e le cui m colonne ai livelli di espressione
di m geni. Il numero delle righe o colonne non e' predeterminato.
- alpha: livello di significativita' (varia fra 0 e 1).
- type: tre valori possibili: "upper", "lower", "two-sided":
“upper”: lt test seleziona i campioni la cui variazione di espressione e' significativamente superiore
rispetto alla media della popolazione a livello di significativita' alpha
“lower”: seleziona i campioni la cui variazione di espressione e' significativamente inferiore rispetto
alla media della popolazione a livello di significativita' alpha
“two-sided”: seleziona i campioni la cui variazione di espressione e' significativamente superiore
o inferiore rispetto alla media della popolazione a livello di significativita' alpha
- SE.corr: valore logico. Se TRUE il calcolo degli z-score va effettuato nel modo standard, cioe'
considerando lo standard error. Se SE.corr=FALSE, la deviazione standard NON viene divisa per la radice
quadrata di n (numero di righe della matrice M), cioe' si divide semplicemente per la deviazione standard.
Uscita: una matrice Res con un numero di righe pari al numero n dei campioni ed un numero di colonne
m pari al numero dei geni della matrice di ingresso M.
Se il gene j del campione i e' significativamente espresso (in accordo con i parametri alpha e type),
allora Res[i,j] = 1, altrimenti Res[i,j] = 0.
Suggerimenti: progettare una funzione z.test che implementi uno z-test applicato ad un singolo gene
arbitrario. Scrivere poi una funzione multiple.z.test che applichi z.test alle colonne della matrice
M (ad es: con un ciclo for o con un apply). Per implementare la funzione z.test e' utile la funzione
pnorm del package stats (v. documentazione).
3. Analisi del data set ALL (Acute Lymphoblastic Leukemia) .
Dal dataset ALL (v. package ALL di Bioconductor) che contiene i dati di 128 pazienti (ahime' bambini)
affetti da leucemia linfoblastica acuta, estrarre gli 81 probeset Affymetrix elencati nel file
AffyID-ALL.txt nella directory http://homes.dsi.unimi.it/~valenti/esameIA201112. Dal data set ALL
dovete cioe' estrarre i dati di espressione (una matrice) relativi ai soli probeset elencati nel file
AffyID-ALL.txt.
Applicare le funzioni sviluppate ai punti 1 e 2 a tale matrice . In particolare per la funzione implementata
al punto 2, provare ad applicare diversi valori di alpha, e cosiderare "upper", "lower" e "two-sided"
z-test. Si ottengono risultati differenti settando SE.corr a TRUE o FALSE? Se la risposta e' affermativa,
spiegare perche'. Vengono selezionati gli stessi campioni dalla funzione implementate al punto 1 ed al
punto 2? Se riuscite, cercate di interpretare i risultati ottenuti.
4. Scrivere un report sintetico che illustri i metodi implementati ai punti 1 e 2 ed i risultati ottenuti
al punto 3. Il codice va commentato: il codice di ogni funzione deve essere preceduto da commenti che
spieghino sinteticamente a cosa serve la funzione stessa, il tipo ed il significato di ogni argomento
di ingresso, il tipo ed il significato dell'output della funzione.