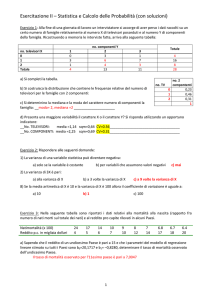
RELAZIONI TRA VARIAIBLI
Esiste la possibilità che la correlazione tra due variabili x e y sia dovuta all’influenza di una terza variabile z
o
Relazione spuria
Presenza di covariazione in assenza di causazione. La correlazione tra X e Y è dovuta all’influenza di
una terza variabile Z, precede temporalmente e logicamente l a X e che correla sia con X sia con Y
o
Relazione mediata
La relazione causale tra X e Y è presente, e tuttavia X esercita il suo effetto su Y tramite Z. tale
relazione è detta anche indiretta. La variabile X influenza Z che a propria volta influenza Y. La
variabile Z è chiamata mediatore o variabile interveniente
o
Relazione moderata
Relazione causale tra X e Y moderata dalla variabile Z. la variabile Z modifica il modo in cui la X
agisce sulla Y
LA REGRESSIONE LINEARE
La regressione lineare è una tecnica che consente di evidenziare e stimare l’effetto causale che una o più
variabili indipendenti (VI) esercitano su di una sola variabile dipendente (VD).
Può avere uno scopo predittivo (si individua una combinazione lineare di VI per predire in modo ottimale il
valore assoluto della VD) o esplicativo (si vuole stimare l’effetto causale della VI sulla VD)
Si parla di regressione lineare semplice quando vi è una sola variabile indipendente; di regressione lineare
multipla se le VI (o regressori) sono due o più
La variabile dipendente è sempre misurata a livello di scala cardinale (ad intervalli, di rapporti, assoluta), la
variabile indipendente viene misurata a livello di scala cardinale o dicotomica
La regressione lineare consente di stimare o predire i valori dei casi sulla VD conoscendo solo i valori della
VI.
RELAZIONE DI DIPENDENZA LINEARE SEMPLICE:
o
o
o
o
y -> variabile dipendente (VD)
x -> variabile indipendente (VI)
α -> intercetta, valore assunto da VD quanto VI vale 0
β -> coefficiente angolare, indica di quanto varia la VD all’aumentare di una unità della misura di VI
-> retta riferita alla i-esima unità statistica
Prima di analizzare la regressione è opportuno calcolare l’r di Pearson tra le due variabili, per
valutare quanto linearmente esse covariano tra loro. Se la correlazione è molto bassa non ha senso
applicare l’analisi di regressione lineare.
Coefficiente di correlazione di Pearson: rapporto tra la covarianza tra le due variabili e il prodotto
delle rispettive deviazioni standard.
r assume valori compresi tra
indipendenti
, assume valore 0 quando le due variabili solo linearmente
poiché la relazione tra x e y non è perfettamente lineare è necessario introdurre nell’equazione un termine
d’errore:
se utilizziamo i dati campionari diventa:
attraverso il metodo di stima dei minimi quadrati ordinari si stimano i parametri a e b che identificano la
retta che rappresenta al meglio la relazione lineare tra le due variabili. Si tratta di quell’unica retta capace
di rendere minima la somma dei quadrati delle distanze che separano, dato ciascun valore della VI, il valore
della VD stimato sulla base dell’equazione della retta e i valori della VD effettivamente registrati.
= scostamento totale del valore su Y dell’unità i dalla media di Y
= parte dello scostamento dell’unità i dalla media di Y dovuta all’influenza della variabile X
= errore residuo (e), quella parte di scostamento dell’unità i dalla media di Y non dovuta
all’influenza di X
quando si utilizza il metodo dei minimi quadrati, il valore stimato di Y (ovvero ) viene individuato in qual
valore di Y tale che, dato ciascun valore di X, esso rende minima la differenza tra sé e tutti i valori di Y
effettivamente registrati in corrispondenza di X, differenza calcolata come somma degli scarti al quadrato
(devianza) => è il valore medio dei valori di Y relativi a ciascun valore di X (proprietà media).
Il coefficiente di regressione (β) stimato con il metodo dei minimi quadrati ordinari indica quanto
mediamente i valori della VD variano all’aumentare di una unità di misura dei valori della VI.
il metodo dei minimi quadrati consente di identificare la retta che riduca al minimo l’errore che viene
commesso nello stimare Y da X.
Applicando il metodo dei minimi quadrati ordinari, i valori di b e di a sono calcolati con le formule:
NB: Covarianza:
Varianza:
Per fari in modo che il valore numerico del coefficiente di regressione (b) non risenta dell’unità di misura
delle variabili, è possibile standardizzarlo ( ), moltiplicando il risultato di b per il rapporto delle deviazioni
standardi di x e y. Il (beta standardizzato) equivale nella regressione lineare semplice al coefficiente di
correlazione lineare di Pearson (r)
Se le variabili di partenza fossero state standardizzate =>
In termini di devianze:
1. devianza totale:
2. devianza spiegata:
3. devianza residua :
1. è possibile calcolare la devianza totale della VD =
. consideriamo tutti i casi del
campione, sommiamo tra loro gli scarti quadratici dei valori individuali della VD dalla media
generale
2. otteniamo la devianza spiegata della VD =
. Sommiamo tra loro gli scarti quadrati che
separano la media generale della VD dai valori della VD stimati dall’equazione di regressione =>
otteniamo quella parte di variabilità complessiva della VD dovuta alla variabilità della VI
3. otteniamo la devianza residua della VD =
. Sommiamo tutti gli scarti quadratici medi
che separano ogni valore effettivamente registrato dalla VD dal corrispondente valore stimato dalla
regressione => otteniamo quella parte di variabilità complessiva della VD non dovuta alla variabilità
della VI
il rapporto tra la devianza spiegata e la devianza totale è chiamato coefficiente di determinazione ( R
quadro), che varia da 0 a 1, e che può essere utilizzato per valutare quanto il modello d regressione stimato
si adatta ai dati.
Più grande è l’R quadro, più ampia è la quota di variabilità della VD dovuta alla variabilità della VI, ovvero
tanto meglio il fenomeno rappresentato dalla VD risulta essere spiegato/determinato dal fenomeno
rappresentato dalla VI.
REGRESSIONE LINEARE MULTIPLA
L’analisi della regressione lineare multipla consente di evidenziare e stimare l’effetto causale su di una
variabile dipendente esercitato da parte di n variabili indipendenti.
La specificazione funzionale di una relazione di dipendenza lineare è:
Poiché le variabili sono più di due, l’equazione non individuerà una retta, ma un piano (nel caso di due
variabili indipendenti) o un iper-piano (quando le VI sono più di due).
Poiché la relazione di dipendenza lineare non è perfetta, si deve aggiungere un termine di errore:
Se si parla di campioni:
Il modello di dipendenza lineare tra la VD e le VI stabilisce che il valore della Y è il risultato del
sommarsi di n+1 effetti causai, ovvero gli effetti dovuti ai valori degli n regressori più l’effetto del
valore dell’intercetta (additività del modello)
L’effetto causale esercitato da ciascun repressore è sempre lo stesso per tutti i casi esaminati, cioè
è indipendente dai valori che i casi assumono sugli altri regressori (assenza di interazione tra i
regressori)
Ciascun coefficiente di regressione b esprime di quanto il valore della VD mediamente varia
all’aumentare di un’unità di misura del valore del corrispondente repressore, e tale variazione è
costante (linearità della relazione di dipendenza)
Ciascun coefficiente di regressione b è definito netto o parziale perché indica di quanto la VD
mediamente varia all’aumentare di un’unità di misura del relativo repressore, al netto
dell’influenza che tutti gli altri regressori possono esercitare sulla relazione che lega la VD al
repressore in questione
La funzione obiettivo del metodo dei minimi quadrati ordinari applicato alla regressione lineare multipla:
Applicando il calcolo differenziale e ricorrendo all’espressione matriciale delle equazioni si ha che:
1.
2.
3.
Applicando le espressioni matriciali 1 e 2 derivate in base al metodo dei minimi quadrati si ottengono le
stime per i parametri contenuti nel vettore b, che contiene il nucleo della soluzione
NB:
o
o
o
= matrice inversa (matrice che moltiplica per la matrice originaria restituisce la matrice di
identità I)
I = matrice di identità, una matrice diagonale che contiene solo i valori 1 sulla diagonale principale e
0 al di fuori di essa
X’ = matrice trasposta che si ottiene scambiando le righe con le colonne della matrice originaria
Coefficienti di associazione
a = varianza che Y condivide solo con
b = varianza che Y condivide solo con
a+c = varianza in comune solo con e Y
b+c = varianza in comune solo con e Y
c+d = varianza in comune e
e = varianza che Y non condivide né con
né con
coefficiente di correlazione semiparziale (
)
correlazione tra
e Y quando
viene parzializzata solo da . Al quadrato è la parte di varianza
totale di Y [=(a+c+b+e)] spiegata unicamente da
al netto di
a/(a+c+b+e)
coefficiente di correlazione parziale (
)
correlazione tra e Y quando
viene parzializzato da e da Y. Al quadrato, è la parte di
varianza totale di Y non spiegata da [= (a+e)], spiegata unicamente da al netto di
=a/(a+e)
coefficiente di regressione (
)
inclinazione della retta di regressione di Y su per valori costanti di
atteso di Y in seguito al cambiamento di una unità di al netto di
coefficiente di regressione standardizzato (
, ovvero il cambiamento
)
Le correlazioni parziale e semiparziale (elevate al quadrato) misurano la quantità di varianza spiegata da
una variabile indipendente dopo che è stato eliminato il contributo fornito dalle altre variabili indipendenti.
I coefficienti b e invece indicano l’entità del cambiamento di una variabile indipendente, tenendo le altre
variabili indipendenti sotto controllo
Anche per la regressione lineare multipla è possibile calcolare un coefficiente di determinazione multiplo
(che non equivale più al quadrato del coefficiente di correlazione r di Pearson), indica la proporzione di
varianza della variabile dipendente spiegata dalle variabili indipendenti prese nel loro complesso . Dato che
il suo valore è influenzato dal numero di regressori è più opportuno utilizzare l’ -corretto
Se ad esempio i regressori sono due =>
Ovvero il coefficiente di determinazione si ottiene dalla somma dei prodotti delle correlazione semplici r (o
di ordine 0) e dei coefficienti tra la variabile dipendente e ogni variabile indipendente
Il coefficiente di determinazione multiplo corretto rappresenta una stima del coefficiente multiplo della
popolazione, esente da errore di approssimazione dovuto al numero di predittori considerati (k
rappresenta il numero di predittori, N il numero di soggetti) :
Il coefficiente di correlazione multiplo di ottiene dal coefficiente di correlazione nel modo seguente:
Il coefficiente di correlazione multiplo R è sempre maggiore/uguale a 0, ed è maggiore di ciascuno dei
singoli coefficienti di ordine 0. Se le variabili sono molto correlate tra loro, R tende a essere prossimo al più
elevato coefficiente di correlazione semplice tra le variabili indipendenti e la variabile dipendente
La significatività statistica dei coefficienti di regressione è valutata usando la statistica del test t si Student, il
sui valore si ottiene dividendo il coefficiente di regressione b per il proprio errore standard (stima della
deviazione standard della distribuzione campionaria dei coefficienti di regressione b)
La significatività statistica del coefficiente di determinazione
usando la distribuzione F di Snedecor
nella regressione multipla è valutata
ASSUNZIONI ALLA BASE DELLA REGRESSIONE LINEARE:
1. assenza di errore di specificazione:
a. la forma della relazione tra X e Y deve essere lineare
b. non devono essere state omesse variabili indipendenti rilevanti
c. non devono essere state incluse variabili indipendenti irrilevanti
2. assenza di errore di misurazione
3. la variabile indipendente deve essere qualitativa o dicotomica e la variabile dipendente deve essere
quantitativa
4. la varianza di ogni variabile indipendente deve essere maggiore di 0
5. il campionamento deve essere casuale semplice
6. se vi è più di una variabile indipendente nessuna di esse deve essere una combinazione lineare
perfetta delle altre (assenza di perfetta multicollinearità). È bene che le variabili indipendenti non
siano troppo correlate. Se le variabili indipendenti sono fortemente correlate, si parla di
multicollinearità
7. assunzioni sui residui (o termini di errore)
a. media uguale a 0:
b. omoschedasticità:
VAR
c. normalità
d. assenza di autocorrelazione:
e. le variabili indipendenti non devono essere correlate
se le assunzioni 1-7 sono verificate è corretto utilizzare i test statistici t e F
verifica delle assunzioni tramite il grafico dei residui:
strategie analitiche per la regressione:
regressione standard
entità della relazione complessiva tra le VI e la VD
tutte le VI sono considerate simultaneamente nell’equazione
regressione gerarchica
esamina qual è il contributo aggiuntivo che una VI inserita in seguito a un’altra VI apporta alla
spiegazione della VD
regressione statistica
regressione gerarchica in cui l’ordine di inserimento delle VI non è scelto dal ricercatore, ma è
determinato in base a criteri statistici
o metodo forward: l’equazione è inizialmente vuota, le VI vengono inserite di volta in volta
partendo da quella che presenta la correlazione più elevata con la VD
o metodo backward: l’equazione è inizialmente piena, le VI vengono eliminate di volta in
colta partendo da quella che contribuisce meno alla spiegazione della VD
o metodo stepwise: compromesso tra i due metodi precedenti. Come per il primo metodo
l’equazione è inizialmente vuota, le VI vengono inserite partendo da quella che presenta la
correlazione più elevata con la VD. Tuttavia a ogni step, possono essere eliminate le VI
precedentemente inserite che, all’inserimento di nuove VI, non contribuiscono più in
misura significativa alla spiegazione della VD