Il rischio di credito
Francesco Romito
Università RomaTre, 1Q 2009
Agenda CreditRisk
•
Definizioni
•
I sistemi di rating interni
•
La previsione delle insolvenze
–
I modelli di scoring
•
L’approccio univariato
•
L’approccio multivariato:
– Il modello discriminante
– Il modello logistico
•
Calibrazione e Masterscale
–
I modelli fondati sul mercato dei capitali
•
Structural models
•
Reduced form models
•
La stima dei tassi di recupero e dell’esposizione al momento del
default
•
Il VaR di un portafoglio creditizio
Default risk e credit risk
• Default risk: rischio che un affidato, un emittente ovvero
una controparte non onori i suoi obblighi di pagamento
• Credit risk: rischio di default ovvero di riduzione del
valore di mercato causata da cambiamenti del merito
creditizio dell’emittente, dell’affidato ovvero della
controparte
• Rischio collegato: Liquidity Risk
– Effetti prezzo e quantità
– Esempi recenti default Russia nel 1998, scandalo Enron 2001,
subprime crisis 2007.
• Default events
– I default sono rari e accadono inaspettatamente
– Comportano perdite significative il cui importo è ignoto prima del
default
Default: le possibili definizioni
• Status giuridico: amministrazione
straordinaria, Liquidazione, Chapter 11
• Regolamentazione finanziaria: sofferenze,
incagli, ristrutturate, Past due
• Classificazioni interne degli intermediari
• Prassi di specifici mercati (es., CDS)
Definizione regolamentare post
Basilea II
•
•
Per esposizioni in default si intendono: sofferenze, incagli, crediti
ristrutturati, crediti scaduti e/o sconfinanti (past due).
Rientrano tra i crediti scaduti e/o sconfinanti quelli per cui:
– il debitore è in ritardo su una obbligazione creditizia rilevante verso la banca o il
gruppo bancario da:
• (i) oltre 180 per i crediti al dettaglio e quelli verso gli enti del settore pubblico;
• (ii) oltre 180 - fino al 31.12.2011 - per i crediti verso le imprese;
• (iii) oltre 90 per gli altri;
– la soglia di “rilevanza” è pari al 5% dell’esposizione.
•
Resta ferma la possibilità di utilizzare, per le filiazioni del gruppo operanti in
altri Stati comunitari o del Gruppo dei Dieci, la definizione di default adottata
dalle locali autorità di vigilanza.
•
Non determinano un default le seguenti modifiche delle originarie condizioni
contrattuali: il riscadenzamento dei crediti e la concessione di proroghe,
dilazioni, rinnovi o ampliamenti di linee di credito. Tali modifiche non devono
dipendere dal deterioramento delle condizioni economico-finanziarie del
debitore ovvero non devono dare luogo a una perdita.
Rilevanza del rischio di credito
• Durante la crisi giapponese negli anni ’90 le
perdite cumulate sono state pari a $ 550 billion
• Attuale crisi: stimati più di $ 1000 billion ??
• Principali cause:
– Elevato livello di leverage e scoppio della real estate
bubble
– Deficienze nel risk management
– Inadeguati standard di concessione
– Carenze della supervisione finanziaria
E’ più importante del rischio di
mercato?
• Derivatives market
–
–
–
–
–
Orange County (Dec 1994) Reverse repos 1,810
Showa Shell Sekiyu (Feb. 1993) Currency forwards 1,580
Kashima Oil (Apr. 1994) Currency forwards 1,450
Metallgesellschaft (Jan. 1994) Oil futures 1,340
Barings (Feb. 1995) Stock index futures 1,330
• Credit market
–
–
–
–
–
Japan (1990s) Bad loans 550,000
China (1990s) 4 state banks insolvent 498,000
US (1984-91) 1400 S&L, 1300 banks fail 150,000
South Korea (1998-) Restructuring of banks 90,000
Worldwide (2007-20??) Subprime and delevereging ??
Le misure del rischio di credito:
credit rating
I credit ratings delle tre grandi agenzie di rating (Standard
& Poor’s, Moody’s e Fitch) forniscono indicazioni sul
merito creditizio degli emittenti
I Credit ratings poossono essere divisi in due classi:
1 Investment grade (da “Aaa” a “Baa” ovvero da “AAA” a “BBB”)
2 Speculative grade
Corporate spreads
Mortage e FED rates
Corporate spreads e maturity
La probabilità di default o di insolvenza cresce al peggiorare del rating…
Historical Default Probabilities
Average default frequencies delle classi di rating S&P
per diversi orizzonti temporali da 1 a 10 anni (in %).
Come cambia il rischio (ed il
rating)?
Fonte: Standard &
Poor’s
Componenti del rischio di credito
•
Arrival Risk: incertezza derivante dalla manifestazione o meno del default
– Probability of Default (PD)
•
Timing Risk: incertezza connessa al tempo della manifestazione del default
•
Recovery Risk: severità delle perdite in caso di default
– Distribuzione del recovery rate (RR=1-LGD)
•
Market Risk: cambiamenti nel valore di mercato di uno strumento dovuti a
cambiamento del merito creditizio o delle condizioni di mercato (incl. migration
risk).
•
Default Correlation Risk: rischio che più emittenti/affidati/controparti vadano in
default simultaneamente ovvero in sequenza
– Arrival & Timing Risks
Agenda CreditRisk
•
Definizioni
•
I sistemi di rating interni
•
La previsione delle insolvenze
–
I modelli di scoring
•
L’approccio univariato
•
L’approccio multivariato:
– Il modello discriminante
– Il modello logistico
•
Calibrazione e Masterscale
–
I modelli fondati sul mercato dei capitali
•
Structural models
•
Reduced form models
•
La stima dei tassi di recupero e dell’esposizione al momento del
default
•
Il VaR di un portafoglio creditizio
Sistema di rating
Definizione
• Insieme strutturato e documentato delle metodologie,
dei processi organizzativi e di controllo, delle modalità
di organizzazione delle basi dati che consente la
raccolta e l’elaborazione delle informazioni rilevanti
per la formulazione di valutazioni sintetiche della
rischiosità di una controparte e delle singole
operazioni creditizie.
• Il rischio connesso con un’esposizione è
espresso attraverso quattro componenti:
Elementi
Rischio di
Credito
–
–
–
–
probabilità di default (PD), che attiene al debitore;
tasso di perdita in caso di default (LGD),
attengono alla
esposizione al momento del default (EAD) singola operazione
scadenza effettiva (M).
Portafogli creditizi: altri elementi per
la determinazione della rischiosità
• Granularità: grado di concentrazione (hp
BIS II granularità infinita)
• Correlazione tra prenditori, aree
geografiche, settori di attività (nell’accordo
approccio semplificato per portafogli e
livelli di PD)
Sistema di rating
•
Attraverso il sistema di rating la banca:
– attribuisce al debitore il grado interno di merito creditizio (rating),
ordinando le controparti in relazione alla loro rischiosità;
– perviene a una stima delle componenti di rischio.
•
Il rating rappresenta la valutazione, riferita a un dato orizzonte
temporale, effettuata sulla base di tutte le informazioni
ragionevolmente accessibili – di natura sia quantitativa sia qualitativa
– ed espressa mediante una classificazione su scala ordinale, della
capacità di un soggetto affidato o da affidare di onorare le
obbligazioni contrattuali.
•
Ad ogni classe di rating è associata una probabilità di default.
•
Le classi di rating sono ordinate in funzione del rischio creditizio:
muovendo da una classe meno rischiosa a una più rischiosa, la
probabilità che i debitori risultino in default è crescente.
Il nuovo Accordo: Basilea 2
Il Nuovo Accordo di Basilea consente di scegliere tra tre approcci
per il calcolo del requisito patrimoniale minimo per il rischio di
credito
Internal Rating
Based (IRB)
Standard
IRB
Foundation
IRB
Advanced
L’attivo ponderato viene calcolato come per Basilea I
in base a ponderazioni fisse. Sono introdotti rating
“esterni” per le controparti Corporate Banche e Paesi e
definito un nuovo trattamento delle garanzie, dei
derivati e delle cartolarizzazioni
L’attivo ponderato viene calcolato come funzione di
4 elementi costituenti il rischio di credito , con
utilizzo di stime interne per determinare la PD,
mentre gli altri elementi (LGD/EAD/M) sono
standard in quanto definiti a priori dalla normativa
L’attivo ponderato viene calcolato come funzione
dei 4 elementi costituenti il rischio di credito con
utilizzo di stime interne
Sistema IRB: overview
Classi di attività
SISTEMA DI RATING
PD
LGD
EAD
M
Funzioni di
ponderazione
Criteri minimi
Ponderazioni
e requisiti
Agenda CreditRisk
•
Definizioni
•
I sistemi di rating interni
•
La previsione delle insolvenze
–
I modelli di scoring
•
L’approccio univariato
•
L’approccio multivariato:
– Il modello discriminante
– Il modello logistico
•
Calibrazione e Masterscale
–
I modelli fondati sul mercato dei capitali
•
Structural models
•
Reduced form models
•
La stima dei tassi di recupero e dell’esposizione al momento del
default
•
Il VaR di un portafoglio creditizio
Le fasi della stima di un modello
quantitativo per la PD
•
L’obiettivo è ottenere un indicatore
– che differenzi in modo significativo imprese
“normali” e in crisi
– che permetta di ottenere una graduazione del
livello di rischio associato ad ogni impresa
•
Le fasi della stima di un modello:
1)
2)
3)
4)
Definizione del default
Formazione del campione di stima
Stima del modello
Verifica dell’efficacia su un campione indipendente
La formazione del campione di
stima
•
Una volta definito il default, si selezionano le
imprese appartenenti ai due gruppi alternativi
(default vs. non default)
1) ... cercando di costruire campioni ampi;
2) e che rappresentino l’universo delle imprese da
classificare
NB. L’utilizzo di “filtri” arbitrari nella selezione delle
imprese (ad esempio, per eliminare “dati anomali”)
può distorcere:
• L’individuazione della regola di classificazione
• La valutazione della performance del modello nel
separare i due gruppi
La formazione del campione di stima
• Per ogni impresa selezionata è opportuno raccogliere
informazioni precedenti il default, per identificare i
“sintomi” più efficaci della crisi.
• Normalmente si ritiene adeguato un orizzonte di
valutazione annuale
• Non è importante rispettare esattamente la proporzione
numerica tra i due gruppi nell’universo, ma è opportuno
un bilanciamento delle caratteristiche “operative” (es.
dimensione, settore di appartenenza)
La stima del modello
• Ogni metodologia richiede alcune scelte a priori da parte
dell’analista, relativamente
– All’individuazione degli indicatori
– Alla gestione di eventuali dati anomali
– Alla procedura di stima utilizzata
– All’obiettivo che si vuole conseguire
• Non sembra possibile individuare una tecnica
“dominante”. Obiettivi che può essere opportuno
perseguire sono comunque:
– Una buona stabilità della performance a livello
previsionale
– Una sufficiente stabilità nelle diverse fasi del ciclo
economico
La verifica dell’efficacia previsionale
• La valutazione del risultato del modello sul campione di
stima distorce verso l’alto l’accuratezza di classificazione.
• Sono state elaborate alcune tecniche che permettono di
simulare la performance previsionale del modello (es.
Jackknife). Possono essere utili soprattutto nella scelta
tra diversi modelli alternativi.
• La verifica dell’efficacia deve essere out-of-sample,
magari con dati relativi a un periodo di tempo successivo
(out-of-time).
Agenda CreditRisk
•
Definizioni
•
I sistemi di rating interni
•
La previsione delle insolvenze
–
I modelli di scoring
•
L’approccio univariato
•
L’approccio multivariato:
– Il modello discriminante
– Il modello logistico
•
Calibrazione e Masterscale
–
I modelli fondati sul mercato dei capitali
•
Structural models
•
Reduced form models
•
La stima dei tassi di recupero e dell’esposizione al momento del
default
•
Il VaR di un portafoglio creditizio
L’approccio univariato
• Discriminare le imprese sane da quelle deboli in base a
un singolo indicatore
• Esame individuale o sistema strutturato
• Confronti con dati di settore e con parametri di
riferimento, esame dei conti aziendali, uso integrato di
altre informazioni di natura qualitativa
• L’analisi univariata non fa alcun tentativo di combinare i
singoli indicatori in una misura quantitativa di sintesi.
L’approccio univariato
• Sistematica differenza di livello e di andamento degli
indicatori delle società anomale rispetto a quelli delle
società sane.
• Il paragone dei soli valori medi concentra l’intera
distribuzione dei valori degli indicatori in un solo punto.
• Esame della sovrapposizione delle distribuzioni calcolate
separatamente sulle società sane e su quelle anomale,
• Individuazione di un punto ottimale di separazione (cutoff) per gli indicatori, in grado di ridurre al minimo gli
errori di attribuzione delle società ai due insiemi (sane anomale).
La classificazione sulla base di un
singolo indicatore di rischio
Frequenze
Cut-off
Anomale
Se Xi > cut-off => gruppo delle
“sane”, altrimenti “anomale”
Sane
Xi, ad es. ROE
Errori di primo e secondo tipo
Classificazione ottenuta
Fallite
Reale situazione
delle aziende
Sane
Totale
Fallite
Sane
Totale
n. di corrette
classificazioni
n. di errori del
II tipo
n. aziende
classificate fallite
n. di errori del
I tipo
n. di corrette
classificazioni
n. aziende
classificate sane
n. di aziende
fallite
n. di aziende
sane
n. totale imprese
del cam pione
Considerando il valore critico (cut-off) è possibile
1. Calcolare la % di errore per ogni gruppo (Ei / Ni)
2. Calcolare il tasso medio di errore di classificazione
(E1 + E2) / (N1+N2)
L’approccio univariato:
difficoltà implementative
– definizione del concetto di insolvenza
– indicatori di bilancio e di Centrale dei Rischi:
pro e contro
– composizione dei campioni
– presenza di valori anomali
– indicatori con denominatore negativo
– forme anomale della distribuzione
I risultati dell’analisi univariata
• Ricerche evidenziano che il migliore indicatore per la
previsione delle insolvenze è il rapporto tra cash flow ed
i debiti totali
• Gli altri indicatori tratti da dati di bilancio mettono in luce
risultati inferiori, con percentuali di classificazione
fortemente degradanti col procedere a ritroso dell’anno
di osservazione delle variabili di bilancio.
• L’analisi del comportamento nel tempo delle distribuzioni
degli indicatori:
– società sane: distribuzioni stabili nel tempo
– società anomale: progressivo spostamento verso la parte
peggiore dei valori con l’avvicinarsi al momento dell’insolvenza,
riducendo l’area della sovrapposizione con le distribuzioni delle
sane.
Cash flow / oneri finanziari
In d ic e
C a s h
F lo w
/ O n e r i F in a n z ia r i, A n n o
-1
3 5 %
Frequenze (%)
3 0 %
S o ffe re n z e
2 5 %
2 0 %
"S a n e "
1 5 %
1 0 %
5 %
3.25
3.63
4.00
4.38
3.63
4.00
4.38
3.63
4.00
4.38
3 5 %
2.88
2.50
2.13
1.75
1.38
1.00
0.63
0.25
-0.13
/ O n e r i F in a n z ia r i, A n n o
3.25
F lo w
-0.50
-0.88
-1.25
C a s h
3.25
In d ic e
-1.63
-2.00
-2.38
-2.75
0 %
-2
S o ffe re n z e
Frequenze (%)
3 0 %
2 5 %
"S a n e "
2 0 %
1 5 %
1 0 %
5 %
In d ic e
C a s h
F lo w
/ O n e r i F in a n z ia r i, A n n o
2.88
2.50
2.13
1.75
1.38
1.00
0.63
0.25
-0.13
-0.50
-0.88
-1.25
-1.63
-2.00
-2.38
-2.75
0 %
-3
3 5 %
S o ffe re n z e
2 5 %
2 0 %
"S a n e "
1 5 %
1 0 %
5 %
2.88
2.50
2.13
1.75
1.38
1.00
0.63
0.25
-0.13
-0.50
-0.88
-1.25
-1.63
-2.00
-2.38
0 %
-2.75
Frequenze (%)
3 0 %
Indicatori di Centrale dei Rischi
• Tipologie:
1. indicatori della “dimensione” del finanziamento
2. indicatori della composizione del finanziamento
3. indicatori di tensione finanziaria
• Riflettono il giudizio del sistema bancario nei confronti dell’impresa.
Informazioni ulteriori rispetto agli indici di bilancio?
• La composizione dei finanziamenti si modifica con l’approssimarsi
della crisi
• Gli indici che evidenziano l’esistenza di tensioni finanziarie sono le
più efficaci nel separare i due gruppi. (ad es., “utilizzo di c/c /
accordato di c/c”)
Agenda CreditRisk
•
Definizioni
•
I sistemi di rating interni
•
La previsione delle insolvenze
–
I modelli di scoring
•
L’approccio univariato
•
L’approccio multivariato:
– Il modello discriminante
– Il modello logistico
•
Calibrazione e Masterscale
–
I modelli fondati sul mercato dei capitali
•
Structural models
•
Reduced form models
•
La stima dei tassi di recupero e dell’esposizione al momento del
default
•
Il VaR di un portafoglio creditizio
L’approccio multivariato
• Uso individuale delle variabili economicofinanziarie: considerazione separata dei vari
elementi dell’impresa (redditività, struttura
finanziaria, liquidità, etc.)
• Passo successivo: combinare insieme tutti
i segnali che arrivano dalle diverse variabili
e cercare di ottenere una misura sintetica
dello stato di salute dell’impresa
• Valutazione simultanea anziché
sequenziale
L’analisi discriminante lineare
• Classificazione di un oggetto in due (o più) popolazioni
note a priori (ciascuna popolazione è dotata di
caratteristiche proprie, descritte in un contesto
multivariato da una serie di variabili)
• L’oggetto da classificare viene osservato sulle stesse
variabili ed in base alla maggiore o minore distanza
complessiva, costruita pesando opportunamente le
distanze individuali delle singole variabili, viene attribuito
alla popolazione più prossima.
• Come ricavare i pesi relativi dei diversi indicatori?
• L’analisi del comportamento individuale degli indicatori
resta un passo importante
L’analisi discriminante lineare
Aspetto descrittivo: costruire una regola di classificazione
che permetta di individuare le caratteristiche delle unità
statistiche che meglio discriminano tra i gruppi
Aspetto predittivo: classificare una nuova unità statistica,
di cui non si conosce la provenienza, in uno dei gruppi
individuati a priori.
Æ L’aspetto predittivo è lo scopo principale perseguito
nell’utilizzo della analisi discriminante per la costruzione
di modelli per la previsione delle insolvenze aziendali.
Il modello discriminante:
interpretazione grafica
•
•
•
•
•
•
(X1, X2) piano che riporta le imprese appartenenti ai due campioni
delle popolazioni A e B
XA e XB medie complessive (centroidi)
Y retta che meglio separa i due insiemi (minor numero di errori di
attribuzione)
Tale retta ha la proprietà che le proiezioni delle nuvole dei punti
sulla retta S, perpendicolare ad essa, disegna delle distribuzioni con
la minor area di sovrapposizione
S è la retta che rappresenta il luogo delle combinazioni lineari delle
variabili, ovvero rappresenta la funzione discriminante lineare
ottima, date le caratteristiche X1 e X2.
Riduzione della dimensione delle caratteristiche osservate, ovvero
grazie al passaggio dello spazio ad n dimensioni delle variabili X ad
1 dimensione della linea di punti S (la riduzione dimensionale in
realtà passa da n a g-1 ove g è il numero delle popolazioni; nel caso
in questione g = 2).
Il modello discriminante:
interpretazione grafica
Due variabili (X1; X2) e due popolazioni (A; B)
Il modello discriminante
•
Le imprese da classificare sono rappresentate da punti sulla retta
degli score, sulla base dei quali è immediato e non equivoco
effettuare degli ordinamenti.
•
La scelta dei pesi (ai) non è effettuata soggettivamente dall’analista,
ma è oggettiva e dipendente dalle caratteristiche delle due
popolazioni (NB l’elemento soggettivo dell’analista finanziario può
entrare in gioco nella scelta delle variabili (X) con le quali osservare
le imprese).
•
Più è ampia l’area della sovrapposizione tra le due distribuzioni,
maggiore è l’incertezza della classificazione (errore di
classificazione P(B|A)≠0)
•
Nel caso limite di due distribuzioni nettamente separate non vi sono
errori, nell’altro caso di perfetta sovrapposizione vi è la massima
incertezza di attribuzioni.
Il modello discriminante
•
L’approccio di Fisher alla classificazione in un contesto multivariato: tra
tutte le combinazioni lineari possibili delle variabili osservate sulle due
popolazioni si utilizza quelle che rende massima la distanza media delle
due popolazioni.
•
Dal punto di vista analitico si tratta di massimizzare il rapporto tra la
varianza tra le popolazioni e la varianza nelle popolazioni.
•
Le osservazioni delle variabili sull’oggetto (impresa) j-esimo vengono
sintetizzate in un unico valore (score), che ne determina la classificazione
sulla base della distanza dagli score medi delle due popolazioni:
• Zj=λ1X1j + λ 2X2j + .... λ iXij + .... + λ nXnj = λ‘X
con
• Zj = score dell’impresa j-esima
• λi = coefficiente della variabile Xi
• Xi = variabile descrittiva della caratteristica i-esima dell’impresa (xi indica il
vettore colonna di tali variabili)
La stima di un modello mediante
l’analisi discriminante lineare
• L'analisi discriminante individua il vettore di coefficienti λ che massimizza la distanza tra i due
gruppi
′
′
E( X i1 λ ) − E( X j 2 λ )2
(Z 1 − Z 2 )
′
Var( X λ )
=
σ Z2
Con
– Xi1 il vettore delle variabili indipendenti rilevato per l'azienda
i appartenente al gruppo 1, indicativo delle imprese in crisi;
– Xj2 il vettore delle variabili indipendenti rilevato per l'azienda
j appartenente al gruppo 2, indicativo delle imprese
“normali”;
– Zα la media dei valori della funzione discriminante per le
osservazioni del gruppo α (con α = 1,2), dato che Ziα = Xiα'λ.
L’analisi discriminante lineare
• La zona di sovrapposizione tra le due curve viene
minimizzata ponendo
λ = Σ-1 (μ1 - μ2),
con
Σ la matrice varianze-covarianze per le due popolazioni;
μα il vettore media delle variabili considerate per la popolazione α.
• La classificazione dell'impresa i avverrà nel gruppo
1 (nell'ipotesi in cui Z1 > Z2) se
(
Z
1 −Z2)
Xi ' λ ≥ (μ1 + μ2)' λ , cioè se Zi ≥
2
L’analisi discriminante lineare
Si osserva che
• i coefficienti della funzione discriminante non
sono unici dato che possono essere trasformati
linearmente mantenendo la stessa capacità di
separare i due gruppi (infatti, se λ∗ = α + λ β, si
ottiene Z* = α +Z β , dato che Ziα = Xiα'λ.
• i coefficienti della funzione discriminante sono
proporzionali a quelli che derivano dalla
regressione con i minimi quadrati Y = a + b X,
con yi = 1 se in crisi, yi = 0 se “normale”
Lo Z score di Altman
Zi = 1,2 Xi,1 + 1,4 Xi,2 + 3,3 Xi,3 + 0,6 Xi,4 + 1,0 Xi,5
•
•
•
•
X1 = capitale circolante / totale attivo
X2 = utili non distribuiti / totale attivo
X3 = EBIT / totale attivo
X4 = valore di mercato patrimonio / valore
contabile debiti l.t.
• X5 = fatturato / totale attivo
Lo Z score di Altman
• Al crescere di Z diminuisce la probabilità
d’insolvenza
• Valore soglia = 2,6
– Z > soglia sup.: impresa sana
– Z < soglia inf.: impresa debole
• Due valori soglia:
– soglia inf. 1,81 < Z < 3 soglia sup.: grey area
La classificazione nei gruppi
• In generale un’impresa da classificare può
essere assegnata considerando la probabilità
che – data l’appartenenza al gruppo g – presenti
il vettore di variabili esplicative Xi
Si assegna a “S” se
f(Xi | S) > f(Xi | F),
f(Xi|S) / f(Xi|F) >1
(max likelihood)
45,00%
40,00%
35,00%
30,00%
25,00%
Densità(S)
20,00%
Densità(F)
15,00%
NB: in pratica, si deve
stimare P(Xi | g) dal
campione in esame
10,00%
5,00%
0,00%
Le probabilità a priori
• Se la numerosità dei due gruppi è diversa, la
regola di classificazione deve tenere conto della
diversa probabilità a priori di estrarre
casualmente un’azienda sana o in crisi
Si assegna a “S” se
pS f(Xi | S) > pF f(Xi | F),
9,00
8,00
7,00
6,00
5,00
4,00
3,00
2,00
1,00
0,00
-1,00
-2,00
-3,00
-4,00
-5,00
-6,00
-7,00
-8,00
-9,00
f(Xi|S) / f(Xi|F) > pF / pS
Le probabilità a priori
Se la distribuzione delle variabili utilizzate è una normale
multivariata,
... e se le matrici di covarianza per i due gruppi sono uguali,
la regola di assegnazione equivale alla funzione lineare
vista in precedenza:
•
(μ S − μ F )′ Σ −1 X i > 1 (μ S − μ F )′ Σ −1 (μ S − μ F ) + ln pF
2
pS
pF
p1
1
1
λX i > λ (μ S − μ F ) + ln ⇒ Z i > ( Z S − Z F ) + ln
pS
p2
2
2
•
La probabilità a priori ha un effetto solo sul termine noto,
non sui coefficienti della funzione discriminante. E’
possibile quindi adeguare a posteriori la regola di
classificazione.
Ipotesi del modello
discriminante lineare
1. Uguali matrici var-cov per le due
popolazioni
2. Indipendenza del vettore X delle
osservazioni
3. Normalità multivariata
Ipotesi del modello
discriminante lineare
• Sul punto 1, alcuni test hanno verificato una sufficiente
robustezza delle stime, se la numerosità dei campioni è ampia
o uguale (altrimenti, i livelli di significatività sono inattendibili e i
coefficienti λ distorti)
• Non è chiaro l’effetto della non normalità; se la distribuzione ha
fat tails ma è simmetrica, l’effetto non è particolarmente
rilevante; è invece sensibile ad una forte asimmetria.
• La LDA funziona bene anche con variabili categoriche
• Gli outlier possono aver un effetto rilevante sulle stime. Alcune
procedure che permettono di ottenere stime robuste di media e
var-cov possono migliorare l’efficacia di classificazione
La probabilità a posteriori
• La probabilità a priori è la probabilità che, prima
dell’osservazione del vettore Xi utilizzato per la
classificazione, si estragga un’impresa appartenente ad
uno dei due gruppi
• È possibile classificare l’impresa i, della quale non è nota
l’appartenenza al gruppo “S” o “F” considerando la
probabilità “a posteriori” che, date le variabili Xi, essa
appartenga al gruppo g (“S” o “F”)
• Dal teorema di Bayes si ottiene che
P(g | Xi) = P(g) P(Xi | g)
P(Xi)
=
=
P(g) P(Xi | g)
_
P(S) P(Xi|S) + P(F) P(Xi|F)
pg P(Xi | g)
_
pS P(Xi | “S”) + pF P(Xi | “F”)
Teorema di Bayes
P[A ∩ B]
P[ B]
Prob [A | B] =
A
B
τ
τ
0
t
s
La probabilità a posteriori
La decisione di assegnare l’osservazione in base alla
probabilità a posteriori è:
Assegna a “S” se P(“S” | Xi) > P(“F” | Xi)
Sulla base della relazione precedente, ciò equivale a
pS P(Xi | “S”) > pF P(Xi | “F”)
P(Xi | “S”) / P(Xi | “F”) > pF / pS
Si ottiene quindi lo stessa regola di classificazione
ottenuta considerando le probabilità a priori
Il costo degli errori di classificazione
• Il costo delle errate classificazioni è diverso tra i due gruppi
• Anche in questo caso, l’effetto è solo sul termine noto
• Considerando congiuntamente probabilità a priori e costi di
classificazione, la costante deve essere modificata di
ln C(1|2)*π2 / C(2|1)*π1.
• Se la probabilità a priori è 2% per le imprese in crisi e 98%
per le imprese sane e se il costo di effettuare un errore di
classificazione è 100 volte superiore per le imprese in crisi,
Δcutoff = (100 * 2%) / (1 * 98%) = 0.71
Difficoltà implementative analisi
disciminante
•
•
•
•
•
Definizione di default
Numerosità dei campioni di stima
Omogeneità dei campioni
Individuazione degli indicatori
Veridicità delle ipotesi di normalità
multivariata delle distribuzioni delle
variabili e uguaglianza delle matrici di
varianza e covarianza
Agenda CreditRisk
•
Definizioni
•
I sistemi di rating interni
•
La previsione delle insolvenze
–
I modelli di scoring
•
L’approccio univariato
•
L’approccio multivariato:
– Il modello discriminante
– Il modello logistico
•
Calibrazione e Masterscale
–
I modelli fondati sul mercato dei capitali
•
Structural models
•
Reduced form models
•
La stima dei tassi di recupero e dell’esposizione al momento del
default
•
Il VaR di un portafoglio creditizio
La regressione multipla per la stima
della probabilità d’insolvenza
•
Stimare un modello che ha come dipendente una variabile
dicotomica che descrive l’appartenenza all’insieme delle società
sane o anomale:
Y=
1 se impresa anomala
0 se impresa sana
mentre gli indicatori di bilancio sono le variabili indipendenti.
•
•
Linear probability model: interpreta la y come probabilità di
appartenenza al gruppo.
Difficoltà:
– la varianza degli errori della stima non è costante,determinando un
problema di eteroschedasticità;
– la stima della y non determina valori compresi tra 0 ed 1, necessari per
interpretare i risultati in termini di probabilità.
Regressione lineare vs regressione
logistica
regressione lineare stimata tra la variabile
dipendente (0;1) ed un indicatore di bilancio (X);
le stime escono dall’intervallo ammissibile per le
probabilità.
Il modello logistico
•
Il modello logistico (logit) consente di ottenere dei valori che
appartengono tutti monotonicamente all’intervallo 0 ; 1
•
Rispetto all’analisi discriminante, le ipotesi sottostanti l’applicabilità
del modello sono meno gravose.
•
L’unica condizione richiesta è che, per ogni variabile esplicativa, le
osservazioni siano indipendenti, mentre non risultano necessarie le
ipotesi di normalità distributiva dei regressori e di uniformità delle
matrici di varianza e covarianza nei gruppi
•
L’idea che sta al di sotto del modello logistico consiste nel supporre
che esista una relazione causale tra la probabilità di un’impresa di
diventare insolvente (variabile inosservabile) ed una serie di
grandezze osservabili che sono strettamente connesse con l’evento
insolvenza.
Il modello logistico
• Identificate con p le probabilità di insolvenza,
con X il vettore delle variabili indipendenti e con
a e b il termine costante ed i coefficienti del
modello si ha:
p = F(α + βX)
ove F identifica la funzione standard cumulativa
logistica
Il modello logistico
• f (h) indica la funzione di densità logistica
• odd-ratio (rapporto tra le
probabilità dell’evento ed
il suo complemento).
Analisi discriminante vs modello
logistico.
Analisi discriminante
•
L’analisi discriminante ipotizza che le
imprese osservabili siano tratte da due
universi distinti dati;
•
La rilevazione delle variabili di bilancio
sulle imprese può essere di aiuto per
trovare le caratteristiche rilevanti e per
individuare da quale universo esse
provengono.
•
•
L’analisi discriminante cerca di
prevedere l’appartenenza a un gruppo,
dopo aver osservato le variabili
ritenute rilevanti per caratterizzare le
diversità tra i due universi.
Nell’analisi discriminante gli indicatori
vanno interpretati come segnali
individuali che giustificano la loro
presenza per il contributo marginale
che danno al segnale complessivo.
Modello logistico
•
Il modello logistico ipotizza che le imprese
siano tratte casualmente da un unico
universo cui appartengono e cerca di
stimare il grado di salute ovvero la
probabilità di insolvenza/fallimento.
•
Relazione causale tra variabili di bilancio
e stato di salute dell’impresa.
•
Non si stima l’appartenenza dell’impresa
ad un gruppo, ma il grado dello stato di
difficoltà economico- finanziaria in cui
versa l’impresa.
•
Nella logistica, gli indicatori
rappresentano le variabili esogene che
sono funzionali a spiegare la situazione
dell’impresa dal punto di vista del
creditore
Analisi discriminante vs modello
logistico.
• Rispetto all’analisi discriminante lineare, gli studi
empirici di solito non rilevano risultati molto
diversi. Ricerche hanno comunque evidenziato
– Se i dati sono normali e ΣF = ΣS, LDA è ottimale per
campioni piccoli (ma la performance risulta molto
simile)
– Se ΣF # ΣS, logit sembra leggermente superiore
– Per distribuzioni non normali, Logit sembra
chiaramente superiore
• Secondo alcune ricerche, preferibile l’uso della
logit analysis per i dati bilancio
Selezione delle variabili
discriminanti
• Metodo simultaneo (diretto): in base ad "a priori"
teorici (inclusione delle variabili che ci si attende
siano rilevanti)
• Metodo stepwise: si parte da un elevato numero
di variabili e
– si eliminano via via quelle con minor potere
esplicativo (backward elimination) oppure
– si inseriscono progressivamente quelle con maggior
potere esplicativo (forward selection) oppure
– si inserisce una variabile alla volta che poi viene
eliminata se perde potere discriminante a seguito
dell'inserimento di altre (stepwise selection)
La performance dell’analisi
•
Accuracy ratio (AR): misura la capacità del modello di individuare le
imprese deboli nelle classi peggiori di Score.
•
La frequenza cumulata della popolazione, ordinata secondo uno
score crescente, viene messa a confronto con la frequenza cumulata
dei passaggi a default effettivamente registrati.
•
Un modello efficace tenderà a concentrare la maggior parte dei
default entro gli ultimi percentili della distribuzione dello score. Nella
figura, il modello esaminato viene confrontato con un modello “ideale”
per il quale il 100% dei default cade nell’ultimo x% della popolazione
e con un modello completamente “casuale”, dove score e default
sono completamente indipendenti (retta a 45°).
•
L’AR misura la concentrazione statistica dei clienti “Bad” nelle classi
di rating di rischio più elevato. Esso presenta un campo di variazione
tra 0 e 100 e si ottiene rapportando le seguenti aree:
AR=A/(A+B)
La performance dell’analisi
Caso non informativo
Caso ideale
Score
A
B
Agenda CreditRisk
•
Definizioni
•
I sistemi di rating interni
•
La previsione delle insolvenze
–
I modelli di scoring
•
L’approccio univariato
•
L’approccio multivariato:
– Il modello discriminante
– Il modello logistico
•
Calibrazione e Masterscale
–
I modelli fondati sul mercato dei capitali
•
Structural models
•
Reduced form models
•
La stima dei tassi di recupero e dell’esposizione al momento del
default
•
Il VaR di un portafoglio creditizio
Dagli score alle PD
•
•
•
•
Nella maggior parte dei casi, il punto di partenza è costituito dagli score
prodotti da modelli logistici. Tali valori, pur essendo compresi tra 0 e 1,
possono essere, di norma, interpretati quali indicatori “ordinali” di
rischio (ranking) e non direttamente quali PD (indicatori “cardinali”).
Fa eccezione il caso – minoritario – delle banche che stimano
direttamente i modelli sulla popolazione (gli score logistici possono
essere interpretati direttamente quali probabilità di default).
Nella maggioranza dei casi, le banche stimano i modelli su campioni la
cui ripartizione tra bonis e default non rispetta le caratteristiche della
popolazione. In questi casi, per interpretare gli score quali PD è
necessario ricorrere ad alcuni meccanismi di aggiustamento o di
ricalibrazione.
Un concetto importante: Tendenza centrale: concetto equivalente alla
frequenza di default osservata sul portafoglio in un determinato arco di
tempo (in base alle regole, un ciclo economico, e comunque non meno
di 2/5 anni)
Metodologie di calibrazione
I meccanismi di aggiustamento
•
Aggiustamento 1: correzione dell’intercetta
Di cui:
Metodologie di calibrazione
Segue: I
meccanismi di aggiustamento
•
Aggiustamento 2: riponderazione dei default
•
Aggiustamento 3: approccio misto
1. Filtro bayesiano per riportare alla tendenza centrale la
PD individuale campionaria;
2. Creazione di n bucket score/pd;
3. Stima di exponential smoothing function;
4. Uso della ESF per passare dagli score alle PD
Metodologie di calibrazione
(segue)
Aggiustamento 3: approccio misto
Score
medianoi
N
PD ind
PD adj i
2.000
-2,4
0,09%
0,07%
2.000
-1,2
0,28%
0,21%
PD adj i = e a + b*score i
Le modalità di
costruzione
dei bucket
(numero,
composizione)
diventano un
elemento
cruciale
…
PD adj
ΣNi
P( D | i, s )
P( D i ) =
P( D | i, s )
.
P( D )
P( D | s )
P( D )
1 − P( D )
+ (1 − P( D | i, s ))
P( D | s )
1 − P( D | s )
.
.
.
.
.
.
.
.
Score
Metodologie di calibrazione
•
Aggiustamento 4: multicalibrazione
1. L’approccio misto esaminato in precedenza si presta
alla realizzazione di calibrazioni multiple;
2. Alcuni gruppi bancari hanno realizzato calibrazioni
separate per aree geografiche ovvero settori di
attività;
3. Ratio: i) ovviare a situazioni di bassa perfomance dei
sistemi/inadeguata rappresentatività nei campioni; ii)
adottare approcci più conservativi
La Masterscale
•
Consente di passare dagli score/PD individuali alle PD regolamentari.
•
Tutte le banche esaminate utilizzano apposite scale maestre; non
sempre tali scale sono uniche (cioè, utilizzabili per tutti i diversi modelli
nell’ambito del portafoglio corporate)
•
Tutte le master scale presentano, per ogni classe di rating, estremi
inferiori e superiori definiti in termini di score/pd individuali che
“guidano” l’assegnazione degli obligors alle diverse classi
•
Ad ogni classe di rating è associata una pooled pd, o PD di classe, da
abbinare, per fini regolamentari, a tutti gli obligors inclusi nella stessa
classe.
Aspetti
Rilevanti
¾ Modalità di costruzione delle scale
¾ Quantificazione delle pooled pd
La Masterscale
Modalità di costruzione delle scale
•
Approccio # 1
Gli estremi delle classi (“cut-off”) vengono definiti sulla base della
distribuzione degli score/PD individuali.
Una volta fissati i limiti, viene definita, in base a differenti modalità, la PD di
classe.
•
Approccio # 2
Vengono prima individuate le PD di classe – facendo, ad esempio,
riferimento a scale esterne – e, successivamente, gli estremi di ciascuna
classe (in genere, posti pari alla media dei logaritmi di due pd di classe
contigue)
La Masterscale
Modalità di costruzione delle scale
•
L’approccio # 1 è basato, tipicamente, su tecniche
statistiche quali la cluster analysis e la kernel analysis.
Talvolta la scelta dei cut-off non è “indipendente” da
valutazioni judgemental
Un vantaggio è quello di costruire classi di rating
giustificabili – in teoria – dal punto di vista statistico
•
L’approccio # 2 parte dall’assunto di volere massimizzare
la valenza “comunicativa” della scala maestra, che viene
“ancorata” a metriche pubbliche, con vantaggi evidenti
anche in termini di benchmarking.
La Masterscale
Modalità di quantificazione della pooled pd
•
Approccio # 1 (“storico”)
La pd pooled è posta eguale alla frequenza di default “storica” osservata per ciascuna
classe di rating (non sono necessarie pd individuali)
Richiede il ricalcolo dei rating a ritroso su tutta la popolazione per un congruo numero
di anni. Può comportare problemi per quanto riguarda le componenti qualitative
1000
ODFi t-2=
100
10
Default T-2
Bonis T-3
1
1000
1
2
3
4
5
ODFi t-1=
100
10
Default T-1
Bonis T-2
1
1000
1
2
3
4
5
100
ODFi t=
10
1
1
2
3
4
5
Default T
Bonis T-1
n
Pdi (=ODFi) = Σ ODFij
n
La Masterscale
Modalità di quantificazione della pooled pd
•
Approccio # 2 (“modelli statistici”)
La pd pooled è posta eguale alla media/mediana delle pd individuali delle controparti
rientranti in ciascuna classe di rating
Non richiede necessariamente il ricalcolo dei rating a ritroso su tutta la popolazione
per tutta la serie storica disponibile
Diventa essenziale verificare la distribuzione per ciascuna classe di rating e riscontrare
la coerenza con le ODF storiche.
AAA
AA
A
BBB
BB
….
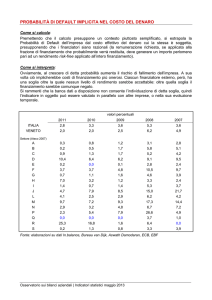
Masterscale a confronto
100,00%
0
10,00%
1
2
3
4
19,37%
11,86%
8,75%
4,72%
2,95%
1,00%
1,48%
0,85%
0,53%
0,29%
0,10%
0,13%
2,43%
1,40%
0,98%
0,68%
0,38%
0,25%
0,13%
1,93%
0,84%
0,26%
0,09%
0,06%
0,04%
5
18,13%
12,15%
8,15%
5,46%
3,66%
2,45%
1,64%
1,10%
0,74%
0,50%
0,33%
0,22%
0,15%
0,10%
0,07%
6
27,60%
17,20%
14,30%
9,36%
7,10%
4,79%
3,40%
1,41%
0,94%
0,52%
0,19%
0,10%
0,05%
0,02%
0,01%
7
16,66%
11,29%
8,01%
6,08%
4,62%
3,51%
2,67%
2,03%
1,54%
1,17%
0,89%
0,63%
0,39%
0,22%
0,14%
0,09%
0,07%
0,05%
0,04%
0,03%
0,02%
8
25,00%
15,00%
7,50%
4,00%
2,50%
1,75%
1,25%
0,88%
0,63%
0,43%
0,28%
0,15%
0,07%
0,01%
0,00%
0,00%
0,00%
0,00%
….